Apache Paimon 小文件治理之道
- 概述
准实时数仓已由以微批数仓发展到以数据湖为核心的准实时数仓,相对微批数仓,数据湖数仓方案需要存储的数据和计算资源的消耗成指数级下降。准实时数仓中的数据湖主要实现方案有Hudi、Iceberg、Paimon等几种数据湖开源方案,这几种数据湖方案在生产应用的中的通病是存在小文件问题,小文件治理水平的好坏能看出数据湖技术应用水平的高低。我们银行使用Paimon作为数据湖存储,在应用数据湖的过程中也遇到了部分表产生海量的小文件问题,表500M数据就有几百万的小文件,数据膨胀到200G,平均一个文件只有5KB左右,导致doris/flink查询的非常慢甚至OOM,因此我们开启了小文件治理之路。
Paimon是一种数据湖格式,本身并不存储数据,数据存储在对象存储(如OSS、HDFS、S3等)中,本文实践过程中使用的HDFS。Paimon在写数据的过程中因微批写入或者频繁的数据修改会导致产生大量的小文件(几KB、几十KB),海量小文件在数据写入和读取时候到将磁盘的顺序读写转化为随机读写,使得数据读写性能下降数十倍。
数据湖中小文件过多的主要影响有:
第一、NameNode性能下降,数据最终都存储到hdfs系统中,每个文件、目录和块在nameNode中都有元数据集,海量的小文件会导致NameNode内存消耗剧增,性能下降,甚至导致服务不可用。
第二、存储空间占用增加,小文件多通常原因可能是compaction压缩的问题,同一条数据记录存储多个版本,导致数据占用空间成数倍放大。
第三、对磁盘IO的消耗增加,文件太小,数据写入、读取的时候都会将顺序读写转化为随机读写,随机读写占用磁盘IO会是顺序读写的数十倍,会大幅增加对磁盘IO的消耗。
本文将我们针对paimon的小文件治理过程进行详细阐述,主要分为小文件问题分析过程、小文件治理过程及结果、未来治理规划三个核心章节进行分析,当然分享我们的经验后,也希望能得到社区高人的斧正。
- 小文件问题分析
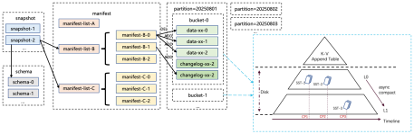
分析Paimon的小文件问题,我们先看下paimon的文件布局情况。如图所示,主要snapshot、manifest、数据文件几个文件目录组成,数据文件按照partition进行分区,partition内部分成多个bucket,每个bucket都是一个LSM树,Paimon利用LSM树的合并能力对小文件进行压缩;manifest是包含有关 LSM 数据文件和变更日志文件的更改的文件,如在对应的snapshot中创建了哪个 LSM 数据文件,删除了哪个文件;snapshot在某个时间点的状态。用户可以通过最新的snapshot访问表的最新数据,也通过时间旅行,用户还可以通过早期snapshot的先前状态。
要治理好小文件,先找到分析工具,再分析表的小文件分布情况,再分析小文件产生原因并治理。本小结将详细介绍我们是如何分析我们生产小文件问题分析的过程。我们介绍两种分析小文件方案工具。
第一种方案,通过hdfs 工具进行分析。
- 统计库中表小文件排序,使用dfs -count命令并sort 排序统计出来小文件数量多的表。
|----------------------------------------------------------|
| Bash hdfs -dfs -q -v /path/db/* |sort -k6,6nr|head -5 |

- 分析表中小文件分布的具体目录,可以看到manifest、snapshot、tag、bucket等目录下小文件数量。
|----------------------------------------|
| Bash hdfs -dfs -q -v /path/db/table/* |
第二种方案,通过flink sql client分析
- 启动一个flink session集群用于执行flink sql,并记录applicationId。
- 修改Flink包目录下的flink-conf.yaml配置文件
|-------------------------------------------------------------------------------------|
| Bash execution.target: yarn-session yarn.application.id: application_******* |
- 运行bin/sql-client.sh,启动flink sqlclient。
- 在sql client中执行flink sql语句,获取manifest、snapshot、tag、files文件数量
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Bash set 'sql-client.execution.result-mode'='tableau'; select count(file_name) from `tablemanifest; ##查看manifest文件数量。 select count(\*) from \`tablesnapshot`; ## 查看snapshot文件数量。 select count(*) from `tabletag\`;##查看tag文件数量 select count(\*) from \`tablefile`; ##表数据文件数量。 |
- 小文件治理实践
由第二节中分析,Paimon小文件主要存在于snapshot、manifest和数据目录三个目录,snapshot目录的一个snapshot文件存储一个snapshot信息,如果snapshot小文件多就是保留的snapshot数量太多,可能是snapshot配置保留过多,也有可能是残留的consumerId导致snapshot过期失败而没有清理snapshot;manifest文件是snapshot和数据文件的关联桥梁,manifest文件数量多一种原因可能是manifest.target-file-size配置太小了,通常用户不会轻易去修改这个配置,默认8mb是没有问题的,更多的原因是snapshot数量太多导致的;数据文件目录里面的小文件太多会直接导致数据查询慢,是治理小文件问题的主关键的问题,无论是治理snapshot小文件多还是manifest小文件多,最终都会导致数据文件目录小文件增加,当然也可能snapshot、manifest目录小文件都不多,数据目录文件小文件也特别多,这个就需要具体排出根本原因了。如下图,我们梳理了一个小文件问题排查树。
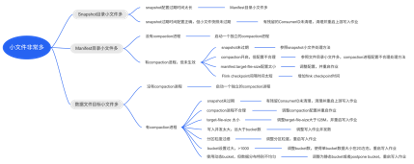
3.1****小文件治理案例
现象描述:实时入湖作业运行半年,小文件持续增长到200w,导致数据查询非常慢。
定位步骤:
- 排查paimon写入作业SQL,基本是默认配置,有开启作业compaction。
- 使用第二节中hdfs工具分析小文件多的目录,snapshot、manifest、数据文件目录小文件都多,并snapshot目录中4个月之前snapshot都依旧保留,可以判断是snapshot过期失败导致小文件增加。
- 检查snapshot过期配置,重新修改snapshot过期配置,并重启写入作业,观察发现snapshot数量依旧没有减少。
|------------------------------------------------------------------------------------------------|
| Plain Text snapshot.num-retained.max=50 snapshot.num-retained.min=20 snapshot.time-retained=2h |
- 检查表对应的consumerId,发现有consumerId没有再消费,paimon的consumerId没有消费就会停留在当前snapshot,导致snapshot停止过期,可以通过下面命令清理掉过期的consumerId。
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Plain Text CALL sys.clear_consumers(`table` => 'database_name.table_name', ` including_consumers**`** => 'including_consumers', ` excluding_consumers**`** => 'excluding_consumers'); |
-
再观察可以发现,旧的snapshot在逐步被清理,小文件数量也在快速下降。最终1w+ snapshot减少到20个snapshot,总文件数量从200w下降到1k左右,文件大小从600G减少到500M左右。
-
总结
过去我们使用hive格式作为离线数据的存储格式,hive格式对数据进行简单分区存储,一般太会有小文件问题。在湖格式从hive演变成paimon这些开放的湖格式后,支持数据的ACID、时间旅行,数据实时性也提高到分钟级,但作为trade-off会带来小文件多的问题,治理好小文件是应用好开放数据湖格式的关键技术。本文我们总结了我们在过去遇到小文件问题分析及实践,但相关治理手段/工具还是比较原始,后续我们将推动治理工具的自动化建设,来提升治理效率和用户体验。