构建drbd存储 :
配置前提:时间同步、基于主机名访问;
需要的软件包:
kmod-drbd##
drbd##-utils
不同的版本组合:
========================================
Package 架构 版本
=======================================
drbd84-utils x86_64 9.12.2-1.el7.elrepo
kmod-drbd84 x86_64 8.4.11-1.2.el7_8.elrepo
==============================================
Package 架构 版本 =============================================
drbd90-utils x86_64 9.27.0-1.el7.elrepo
kmod-drbd90 x86_64 9.1.21-1.el7_9.elrepo
(基于CentOS7及以前版本的包镜像源很难找到,这里有一个:http://hkg.mirror.rackspace.com/elrepo/archive/elrepo/el7/x86_64/RPMS/)
1、安装DRBD :
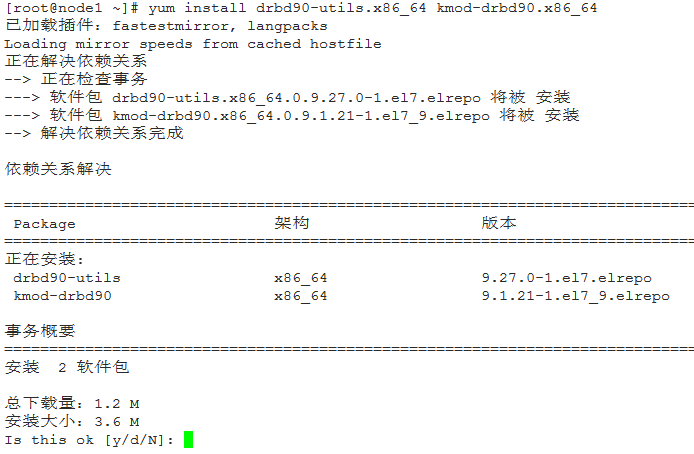
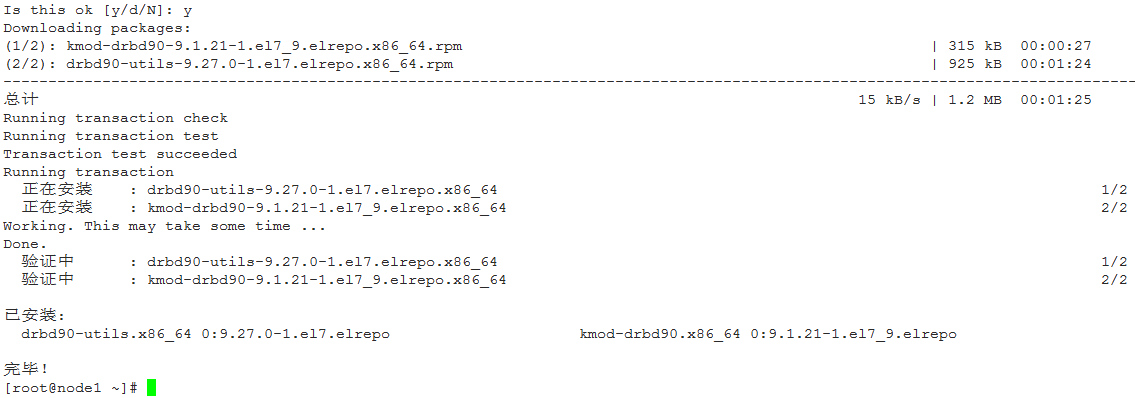
安装完毕后,看看都安装了些什么:
drbd-utils:

2、配置文件 :
/etc/drbd.conf:主配置文件,但是其中没有具体配置,只是指明包含了其他的配置文件:

/etc/drbd.d/global_common.conf:提供全局配置,及多个drbd设备相同的配置
/etc/drbd.d/*.res:资源定义;
global:全局属性,定义drbd自己的工作特性
common:通用属性,定义多组drbd设备通用特性;
*.res:资源特有的配置;
配置文件模版:global_common.conf:
global {
usage-count no;
# Decide what kind of udev symlinks you want for "implicit" volumes
# (those without explicit volume <vnr> {} block, implied vnr=0):
# /dev/drbd/by-resource/<resource>/<vnr> (explicit volumes)
# /dev/drbd/by-resource/<resource> (default for implict)
udev-always-use-vnr; # treat implicit the same as explicit volumes
# minor-count dialog-refresh disable-ip-verification
# cmd-timeout-short 5; cmd-timeout-medium 121; cmd-timeout-long 600;
}
common {
handlers {
# These are EXAMPLE handlers only.
# They may have severe implications,
# like hard resetting the node under certain circumstances.
# Be careful when choosing your poison.
#
# pri-lost-after-sb "/usr/lib/drbd/notify-pri-lost-after-sb.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
# local-io-error "/usr/lib/drbd/notify-io-error.sh; /usr/lib/drbd/notify-emergency-shutdown.sh; echo o > /proc/sysrq-trigger ; halt -f";
# fence-peer "/usr/lib/drbd/crm-fence-peer.sh";
# split-brain "/usr/lib/drbd/notify-split-brain.sh root";
# out-of-sync "/usr/lib/drbd/notify-out-of-sync.sh root";
# before-resync-target "/usr/lib/drbd/snapshot-resync-target-lvm.sh -p 15 -- -c 16k";
# after-resync-target /usr/lib/drbd/unsnapshot-resync-target-lvm.sh;
# quorum-lost "/usr/lib/drbd/notify-quorum-lost.sh root";
# disconnected /bin/true;
}
startup {
# wfc-timeout degr-wfc-timeout outdated-wfc-timeout wait-after-sb
}
options {
# cpu-mask on-no-data-accessible
# RECOMMENDED for three or more storage nodes with DRBD 9:
# quorum majority;
# on-no-quorum suspend-io | io-error;
}
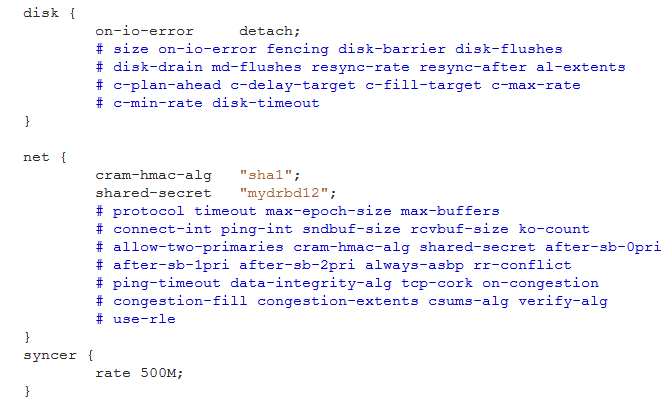
disk {
# size on-io-error fencing disk-barrier disk-flushes
# disk-drain md-flushes resync-rate resync-after al-extents
# c-plan-ahead c-delay-target c-fill-target c-max-rate
# c-min-rate disk-timeout
}
net {
# protocol timeout max-epoch-size max-buffers
# connect-int ping-int sndbuf-size rcvbuf-size ko-count
# allow-two-primaries cram-hmac-alg shared-secret after-sb-0pri
# after-sb-1pri after-sb-2pri always-asbp rr-conflict
# ping-timeout data-integrity-alg tcp-cork on-congestion
# congestion-fill congestion-extents csums-alg verify-alg
# use-rle
}
}usage-count:类似于为改进体验而收集信息功能,一般配置为no;
handler:drbd出现各种问题时的处理;
startup:drbd启动时双方的一些配置信息,如超时等属性;
options:定义一些同步属性;
disk:配置磁盘相关信息,如on-io-error detach,配置如果发生磁盘io错误,就将此盘拆掉;
net:配置网络,如配置使用多少带宽来进行数据同步;使用哪种密钥进行数据加密;如:
cram-hmac-alg "sha1";shared-secret "password";
syncer {
rate 500M; ;带宽设置
}
示例:
3、准备磁盘分区 ,使用DRBD,需要两个节点上的两个大小一样的分区设备,对node1和node2节点,有如下磁盘设备:
磁盘 /dev/sdc:21.5 GB, 21474836480 字节,41943040 个扇区
Units = 扇区 of 1 * 512 = 512 bytes
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):512 字节 / 512 字节
做分区,大小为5G:

添加完分区后:
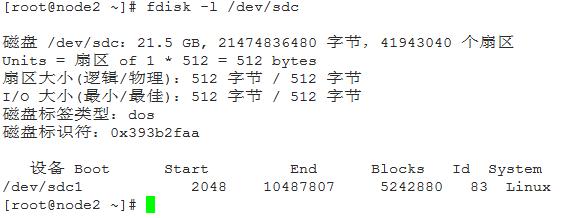
准备好分区后,就可以在drbd的资源中使用。
4、定义一个资源 ,使用*.res文件,如:/etc/drbd.d/mystore.res:
有两种写法,第一种,每个节点独立配置:
resource webstore {
on node1 {
device /dev/drbd0;
disk /dev/sdc1;
address 192.168.61.129:7789;
meta-disk internal;
}
on node2 {
device /dev/drbd0;
disk /dev/sdc1;
address 192.168.61.130:7789;
meta-disk internal;
}
}
第二种,各节点相同配置可以一次配置:
resource webstore {
device /dev/drbd0;
disk /dev/sdc1;
on node1 {
address 192.168.61.129:7789;
meta-disk internal;
}
on node2 {
address 192.168.61.130:7789;
meta-disk internal;
}
}
本次测试的资源文件:mystore.res:
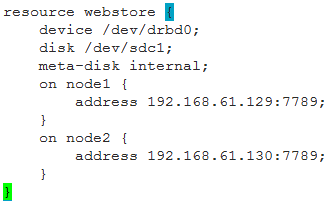
拷贝配置文件到另一个节点上,保证两个节点的配置相同
5、在两个节点上初始化已经定义的资源并启动服务
1)初始化资源,在node1和node2上分别执行:
drbdadm create-md webstore
出现错误:

应该是global_common.conf中的syncer配置出问题了,当前的drbd不认这种配置。
需要进行以下安装或升级:
yum install gcc gcc-c++ make glibc flex -y
yum -y install kernel-devel kernel kernel-headers
启动前加载一下内核模块:modprobe drbd
去掉这个syncer配置项,然后初始化资源:
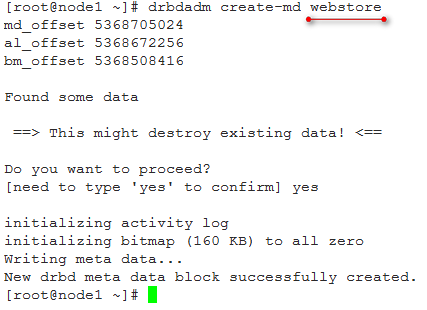
这里的资源是.res配置中resources后跟的名字,而不是配置文件的名字。
2)启动服务,在node1和node2上分别执行:
systemctl start drbd
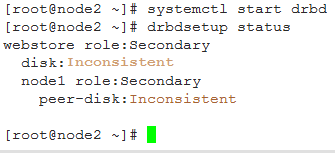
第一个节点启动时,会卡住,第二个节点启动时,才会完成,双方需要通信。
3)分别在node1和node2上启动资源,这里就是配置文件中配置的资源名字:webstore
drbdadm up webstore
4)查看启动状态:
drbdsetup status
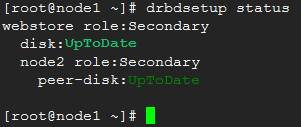
此时两个节点的状态都是secondary
5)改变node1为primary,加载文件系统
drbdadm primary webstore --force
mkfs.xfs /dev/drbd0
mount -t xfs /dev/drbd0 /mnt
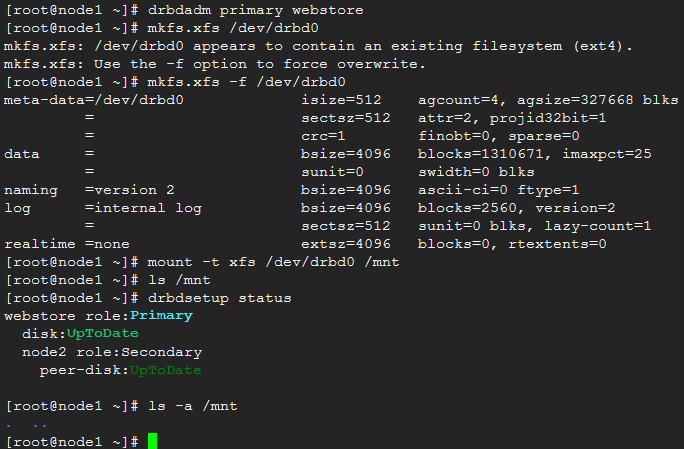
测试写:echo node1 > ceshi.txt
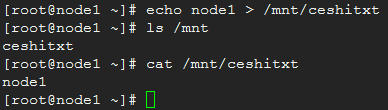
在node2上检验:
drbdadm down webstore
mount -t xfs /dev/sdc1 /mnt
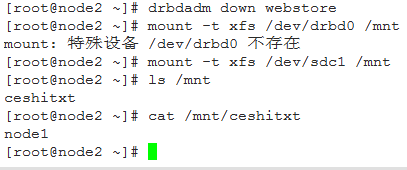
可以看到,node2上的镜像分区中已经有ceshitxt文件了,并且内容一致。但是,一定要注意的是,这两个ceshitxt文件不是同一个文件,而是不同磁盘上的两个不同的文件,只不过内容一致。
6)主备切换
在node1上,卸载已挂载的文件系统,然后将drbd切换到secondary状态
umount /mnt
drbdadm secondary webstore
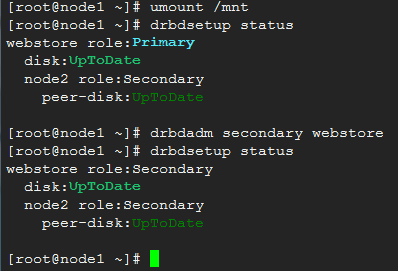
在node2上,将drbd切换为primary状态,然后挂载文件系统
drbdadm primary webstore
mount -t xfs /dev/drbd0 /mnt
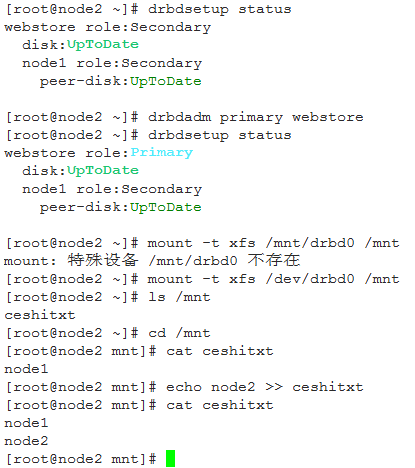
查看node1镜像上的文件:
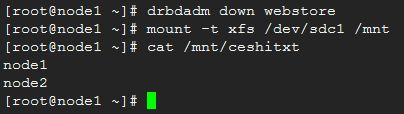
至此,DRBD的基本使用就完成了,实现了数据的镜像。
在高可用集群中使用drbd
一旦安装了drbd,在集群的资源中ocf会多出来一类:linbit
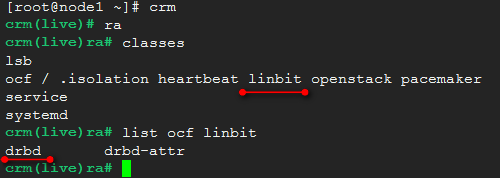
在集群中定义drbd为资源时,就要使用这个linbit类。
关于资源drbd,定义时其有几种特殊的监控选项:
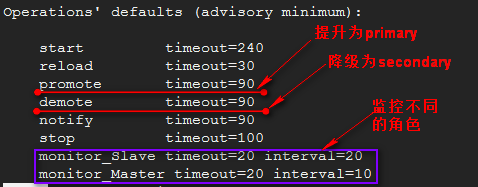
在集群中drbd资源是一类比较特殊的资源,是主从类型的资源,但任何主从资源都必须是基本资源,由基本资源克隆出几份,分成master/slave资源。需要额外指定一些meta属性信息。
pacemaker中定义克隆资源的专用属性:
clone-max:最多克隆出的资源份数;
clone-node-max:在单个节点上最多运行几份克隆;
notify:当一份克隆资源启动或停止时,是否通知给其他的副本,默认是true;
globally-unique:每一份副本是否要运行不同的功能,默认是true;
ordered:所有的副本是不是串行启动,即一个接一个启动,默认true;
interleave:默认true一般符合应用场景;
master-max:最多启动几份master资源,默认是1;
master-node-max:同一节点最多运行几份master类型资源,默认是1;
1、在集群中定义drbd资源:
先定义primitive资源:
crm(live)# cd configure
crm(live)configure# primitive hastore ocf:linbit:drbd params drbd_resource="webstore" op monitor role="Master" interval=10s timeout=20s op monitor role="Slave" interval=20s timeout=20s op start timeout=240s op stop timeout=100s
然后定义主从资源,是由primitive资源克隆而来:
crm(live)configure# ms ms_hastore hastore meta clone-max="2" clone-node-max="1" master-max="1" master-node-max="1" notify="true"
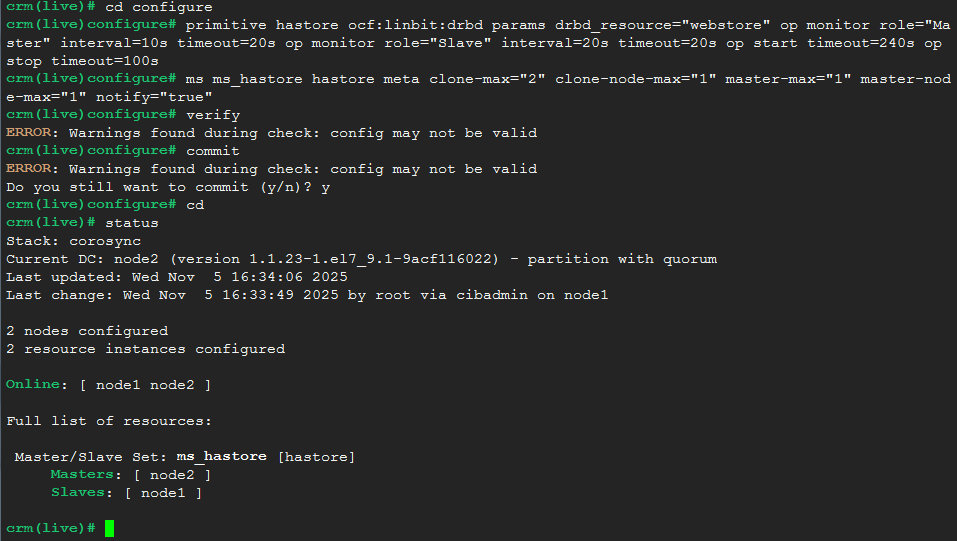
我的测试中,Corosync属性配置中好像有无效的配置,略过了。
当前状态可见Master运行于node2,Slave运行于node1。
进行节点切换,将node2切换为standby模式,可以看到Master资源转移到noe1,而node2处于stop状态。
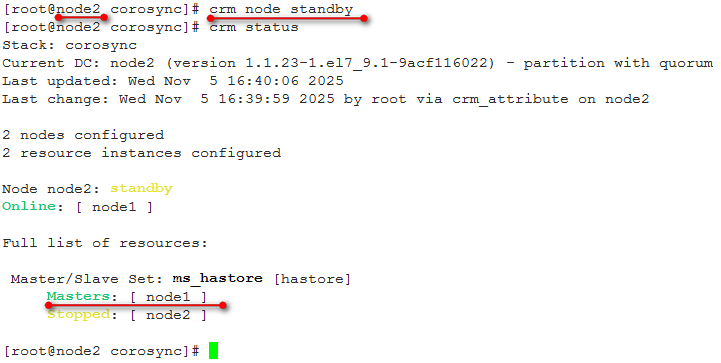
将node2上线,node2状态变为Slave。
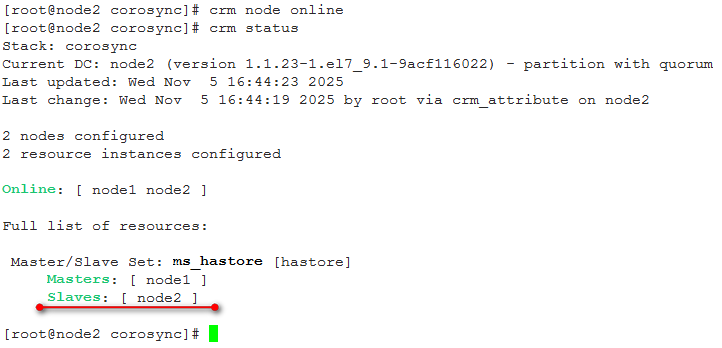
使用drbd查看其状态:
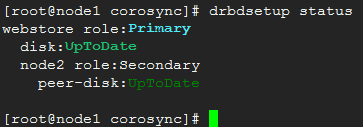
当前node1为Primary,node2为Secondary。
至此,构建的集群只是保证了主从资源的切换,而文件系统的挂载还没有实现。
2、定义文件系统资源,使主资源所在节点能够挂载相应的文件系统。
在每个节点上创建/mydata目录,集群创建文件系统资源,使主资源节点挂载/dev/drbd0到此目录。只能主资源节点挂载。文件系统资源必须跟主资源在一起,而且,必须是drbd资源提升为Primary角色后,才能进行文件系统挂载。即先定义文件系统资源,然后定义位置约束,使文件系统必须与drbd主资源在一起,最后定义顺序约束,文件系统挂载必须在drbd资源升级为Primary角色之后挂载。
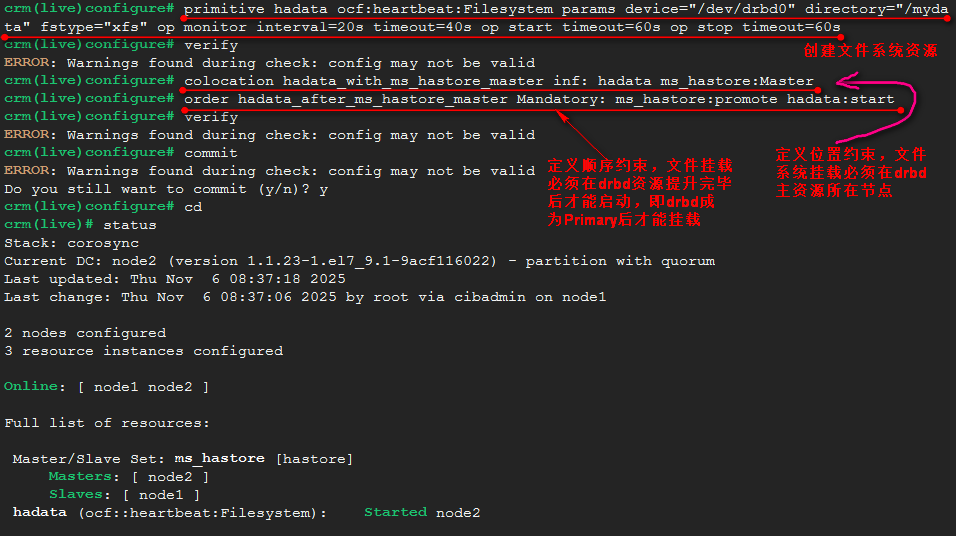
配置完成提交后,可以看到hadata资源在node2上启动了,与ms_hastore的Master角色在一个节点上,即node2上。
将node2转为旁路,即standby:
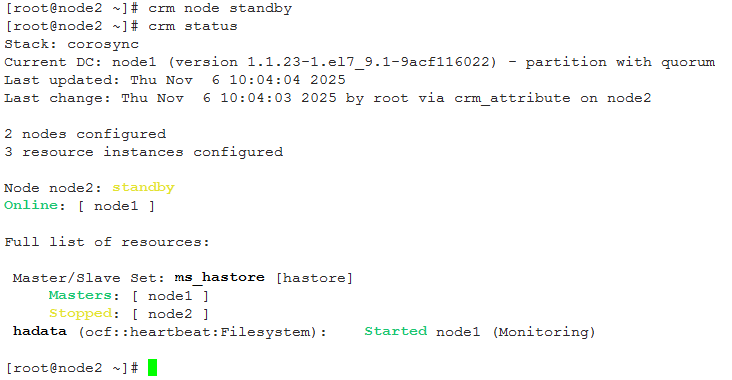
可以看到,ms_hastore的Master转移到node1上,hadata,即文件系统资源在node1上挂载。
构建mysql高可用集群:
mysql的高可用集群,就是保证在提供mysql服务的节点出现故障无法提供服务时,集群将服务转移到另一节点,同时保证数据一致,关键点就是数据,mysql程序在每个节点都需要安装,然后数据库数据文件保存在共享存储或镜像存储中,这里就是使用drbd镜像存储,在一个节点出现问题,mysql服务转移到另一个节点,同时数据也是使用本节点上的镜像数据,保证服务及数据的一致,保证服务高可用。
1、 安装mysql(现在一般是使用MariaDB),可以是rpm包安装,也可以直接解压缩文件安装;
2、 确保名为mysql的系统用户和系统组存在,不存在需要手动创建;
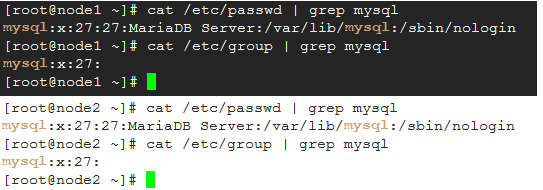
两个节点上的mysql用户和组必须名称和id完全一致;
3、 mysql的配置文件:/etc/my.cnf,其中最重要的是配置了数据的保存位置
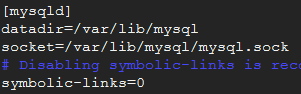
这里显示的数据库数据保存位置是:/var/lib/mysql,即datadir指定的位置,这个目录要求其属主属组都是mysql。
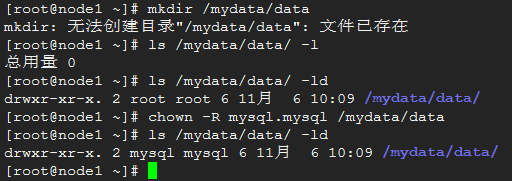
4、 将drbd设备/dev/drbd0挂载到/mydata,创建/mydata/data目录,将mysql数据保存位置调整到/mydata/data,同时调整其属主属组为mysql;
查看当前状态:
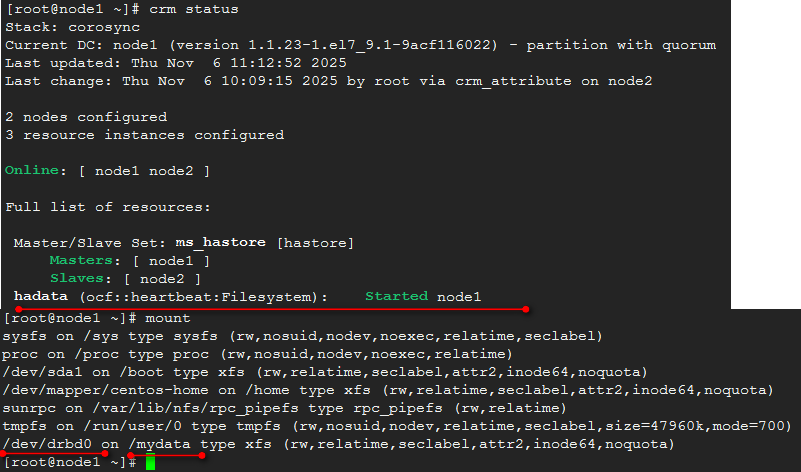
创建/mydata/data,修改属主属组:
修改/etc/my.cnf中datadir=/mydata/data
运行mysql_install_db初始化数据库:
mysql_install_db --user=mysql --datadir=/mydata/data
此时的节点上,数据库初始化完成,数据库文件保存在了/mydata/data中,第二个节点中安装完毕后,修改/etc/my.cnf中的datadir=/mydata/data
修改登录用户:
grant all on *.* to 'root'@'192.168.%.%' identified by 'xxxxxx';
flush privileges;
此操作允许192.168开始的网段的root用户远程登录。
5、 构建mysql的高可用集群,需要添加一个公共的IP资源,添加mysql资源:
primitive havip ocf:heartbeat:IPaddr params ip="192.168.61.10" op monitor interval=10s timeout=20s
primitive hamysql systemd:mariadb op monitor interval=20s timeout=100s
然后需要位置约束,havip要与ms_hastore_master要在一起,并且是强制的;hamysql要与hadata在一起:
colocation havip_with_ms_hastore_master inf: havip ms_hastore:Master
colocation hamysql_with_hadata inf: hamysql hadata
定义顺序约束,mysql的启动要在hadata启动之后才能启动;havip要在mysql之前
order hamysql_after_hadata Mandatory: hadata:start hamysql:start
order hamysql_after_havip Mandatory: havip:start hamysql:start
提交后:

可以看到,ip,mysql服务、数据以及drbd的master在同一节点node2上,将node2切换到standby:
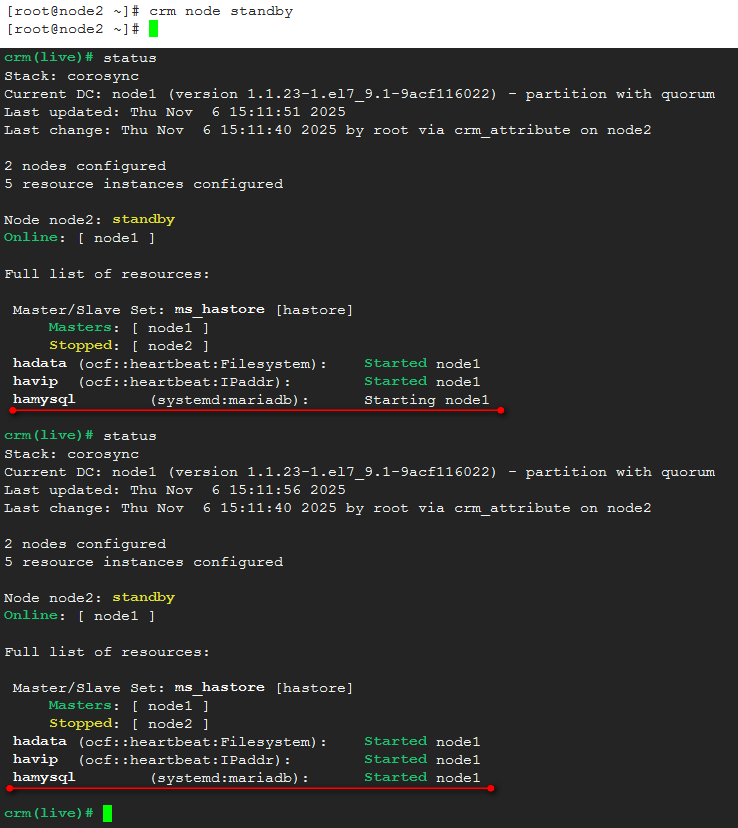
集群服务的切换需要一定的时间,可以看到hamysql在node1的启动过程,在另一台机器上登录的mysql依然连接着,并可以继续操作。
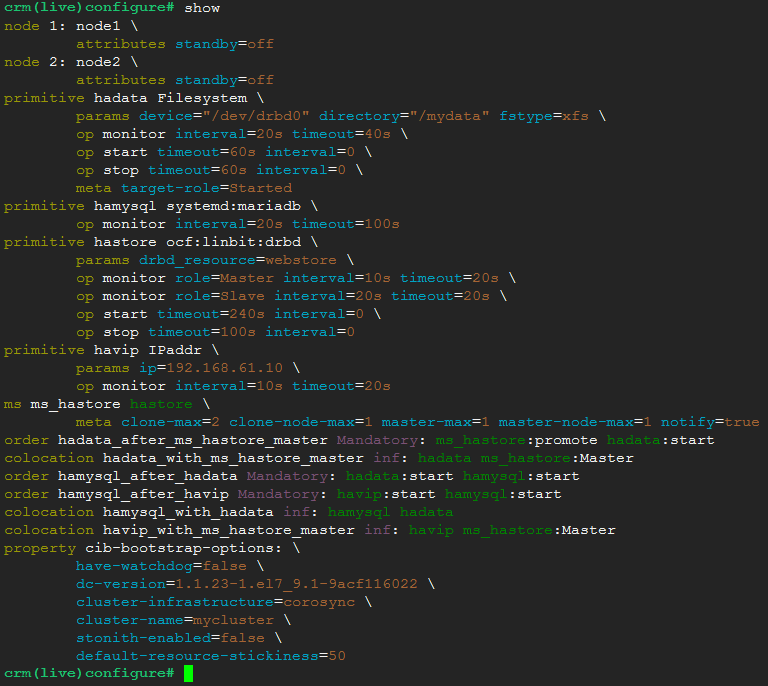
以上就是基于DRBD实现的高可用mysql服务集群。以下是整个资源配置:
对于pacemaker内部的结构:
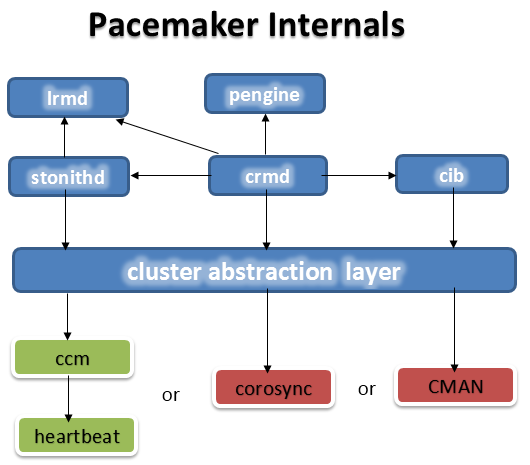
对于pacemaker调用下层的消息层功能,heartbeat本身没有集群成员关系管理这个功能,需要加一层ccm层,Corosync与cman本手具有集群成员关系管理功能。