今天带大家熟悉一下flink从mysql采集实时数据,发送到kafka,消费kafka写入到doris。为啥不直接写入doris,就是为了跑下全过程,一般我们的实时数据都会发送到kafka这种消息平台中,然后我们通过flink实时消费消息队列的数据来做一些逻辑计算最后落地。我们今天的流程其实也就是正常的实时采集消费的一个流程,落地到doris进行实时查询。我只是将各个官网的demo集中到了一起,方面我们自己练手玩。不能用作生产环境,仅个人练习玩法。
Mysql准备工作
账号授权
一般都是采集的时候创建个从库,监控binlog的变化。flinkcdc底层是Debezium,之前公司用的canal,道理应该是一个样。
以下顺序也是从官网复制过来的,创建账号用来做数据同步。
sql
1、Create the MySQL user:
mysql> CREATE USER 'user'@'localhost' IDENTIFIED BY 'password';
2、Grant the required permissions to the user:
mysql> GRANT SELECT, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'user' IDENTIFIED BY 'password';
Note: The RELOAD permissions is not required any more when scan.incremental.snapshot.enabled is enabled (enabled by default).
3、Finalize the user's permissions:
mysql> FLUSH PRIVILEGES;
如下是我自己执行的过程
-- 重新创建用户(如果已有先删除)
DROP USER IF EXISTS 'flink'@'%';
-- 创建用户
CREATE USER 'flink'@'%' IDENTIFIED BY 'flink';
-- 授予Flink CDC所需的最小权限
GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT, EVENT ON *.* TO 'flink'@'%';
-- 刷新权限
FLUSH PRIVILEGES;模拟数据
数据直接从flinkcdc官网复制,我只创建了orders表,模拟了两条数据。https://nightlies.apache.org/flink/flink-cdc-docs-release-3.5/docs/get-started/quickstart/mysql-to-kafka/
sql
-- create database
CREATE DATABASE app_db;
USE app_db;
-- create orders table
CREATE TABLE `orders` (
`id` INT NOT NULL,
`price` DECIMAL(10,2) NOT NULL,
PRIMARY KEY (`id`)
);
-- insert records
INSERT INTO `orders` (`id`, `price`) VALUES (1, 4.00);
INSERT INTO `orders` (`id`, `price`) VALUES (2, 100.00);
-- create shipments table
CREATE TABLE `shipments` (
`id` INT NOT NULL,
`city` VARCHAR(255) NOT NULL,
PRIMARY KEY (`id`)
);
-- insert records
INSERT INTO `shipments` (`id`, `city`) VALUES (1, 'beijing');
INSERT INTO `shipments` (`id`, `city`) VALUES (2, 'xian');
-- create products table
CREATE TABLE `products` (
`id` INT NOT NULL,
`product` VARCHAR(255) NOT NULL,
PRIMARY KEY (`id`)
);
-- insert records
INSERT INTO `products` (`id`, `product`) VALUES (1, 'Beer');
INSERT INTO `products` (`id`, `product`) VALUES (2, 'Cap');
INSERT INTO `products` (`id`, `product`) VALUES (3, 'Peanut');FlinkCDC准备工作
下载安装
https://github.com/apache/flink-cdc/releases 从官网下载,我下载的是3.4.0下载以后直接解压即可。
bash
tar -xzf flink-cdc-xxx-bin.tar.gz如果没有下载flink,可以下载安装一下https://archive.apache.org/dist/flink/flink-1.20.1/flink-1.20.1-bin-scala_2.12.tgz
bash
tar -zxvf flink-1.20.1-bin-scala_2.12.tgz
exprot FLINK_HOME=$(pwd)/flink-1.20.1
cd flink-1.20.1connector准备
3.5官网有这个mysql-to-kafka,3.4没有,所以我是3.4但我看的3.5官网。
cdc lib
flink lib
https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.27/mysql-connector-java-8.0.27.jar
脚本开发
sql
################################################################################
# Description: Sync MySQL all tables to Kafka
################################################################################
source:
type: mysql
hostname: 0.0.0.0
port: 3306
username: root
password: 123456
tables: app_db.\.*
server-id: 5400-5404
server-time-zone: UTC
sink:
type: kafka
name: Kafka Sink
properties.bootstrap.servers: 127.0.0.1:9092
topic: yaml-mysql-kafka
pipeline:
name: MySQL to Kafka Pipeline
parallelism: 1部署
根据上一步复制过来的脚本直接提交flink任务,记得要启动flink先。最后我们会把所有步骤连起来启动。
https://nightlies.apache.org/flink/flink-cdc-docs-release-3.4/docs/deployment/standalone/
sql
bin/flink-cdc.sh mysql-to-kafka.yamlKafka准备工作
下载
上一步flink cdc任务已经提交以后,其实是在kafka环境已经准备好的前提下开始的,所以我们还需要在任务提交的时候把kafka环境搭建起来。直接下kafka压缩包,解压启动就可以了。
选择要下载的压缩包
https://kafka.apache.org/downloads
启动
解压启动
> tar -xzf kafka_2.11-2.1.0.tgz
> cd kafka_2.11-2.1.0启动
启动kafka,先要把zookeeper启动起来,需要zookeeper做一些元数据的管理,leader的选举管理集群的健康情况。
kafka自己就带了zookeeper,我们自己玩可以直接用这个启动就可以了,如果生产是需要有一个独立的zookeeper集群的。
bin/zookeeper-server-start.sh config/zookeeper.properties启动完zookeeper就可以启动kafka服务了
bin/kafka-server-start.sh config/server.properties这些命令都是直接从官网复制过来的。为了验证是不是kafka集群ok,我们可以创建topic,然后发送数据,消费查看情况,这里我们就不演示了。直接在官网都有。https://kafka.apache.org/21/documentation.html#quickstart
flink消费kafka任务
streaming代码开发
这下mysql,kafka环境都好了,我们的flink cdc脚本也写好直接按照说的脚本直接部署就可以了。所以我们要看一下我们的flink cdc是否正常运行了,以及mysql采集的数据是否已经到了kafka。
直接从doris官网复制flink的streaming代码https://doris.apache.org/zh-CN/docs/3.x/ecosystem/flink-doris-connector
maven依赖
我们需要将kafka的数据写入doris,通过streaming java的方式,所以。我们需要streaming的依赖,kafka connector,doris connector。
XML
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.doris</groupId>
<artifactId>flink-doris-connector-1.20</artifactId>
<version>${doris.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>3.3.0-1.20</version>
</dependency>以来搞定,代码直接我们从官网复制就可以了。
java
public class SendToDoris {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(30000);
DorisSink.Builder<String> builder = DorisSink.builder();
DorisOptions dorisOptions = DorisOptions.builder()
.setFenodes("127.0.0.1:8030")
.setTableIdentifier("test.orders")
.setUsername("root")
.setPassword("")
.build();
Properties properties = new Properties();
// 上游是json数据的时候,需要开启以下配置
properties.setProperty("read_json_by_line", "true");
properties.setProperty("format", "json");
properties.setProperty("load_url", "127.0.0.1:8040");
// 关键:添加网络配置
properties.setProperty("http.headers.Expect", "100-continue");
properties.setProperty("socket_timeout", "60000");
properties.setProperty("connect_timeout", "30000");
// 上游是 csv 写入时,需要开启配置
//properties.setProperty("format", "csv");
//properties.setProperty("column_separator", ",");
DorisExecutionOptions executionOptions = DorisExecutionOptions.builder()
.setLabelPrefix("label-doris")
.setDeletable(false)
.setMaxRetries(5)
//.setBatchMode(true) 开启攒批写入
.setStreamLoadProp(properties)
.build();
builder.setDorisReadOptions(DorisReadOptions.builder().build())
.setDorisExecutionOptions(executionOptions)
.setSerializer(new SimpleStringSerializer())
.setDorisOptions(dorisOptions);
//
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers("host.docker.internal:9092")
.setTopics("test")
.setGroupId("orders-test-gi")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStreamSource<String> kafkaSource = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
SingleOutputStreamOperator<String> after = kafkaSource.process(new ProcessFunction<String, String>() {
@Override
public void processElement(String s, ProcessFunction<String, String>.Context context, Collector<String> out) throws Exception {
JSONObject json = JSON.parseObject(s);
//{"before":null,"after":{"id":2,"price":1E+2},"op":"c","source":{"db":"app_db","table":"orders"}}
JSONObject after = json.getJSONObject("after");
System.out.println("接入数据:"+JSON.toJSONString(after));
out.collect(JSON.toJSONString(after));
}
});
// 添加数据打印用于调试
after.print().name("Debug Output");
//中间可以做一些业务的算子操作
after.sinkTo(builder.build());
try {
env.execute("doris test");
System.out.println("ok");
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}打包部署
代码写好了,我们就可以直接打包jar了,打包好了只需要doris环境准备好了,我们直接就可以提交flink作业了。自己玩就直接命令提交了,想要通过平台提交的小伙伴可以关注一下StreamPark(https://streampark.apache.org/docs/get-started/quick-start)
doris准备工作
下载
我们直接使用官网的docker快速启动版本,直接下载官网的启动脚本https://doris.apache.org/files/start-doris.sh ,按照官网直接启动指定自己要启动的版本。https://doris.apache.org/zh-CN/docs/3.x/gettingStarted/quick-start。
复制jar到flink lib下 https://repo1.maven.org/maven2/org/apache/flink/flink-cdc-pipeline-connector-doris/3.4.0/flink-cdc-pipeline-connector-doris-3.4.0.jar
启动
https://doris.apache.org/zh-CN/docs/3.x/gettingStarted/quick-start 在启动集群的过程中遇到了一些小问题,比如 内存不足,以及权限问题。之后修改后的yaml文件如下:
docker-compose -f docker-compose-doris.yaml up -d
XML
version: "3"
networks:
custom_network:
driver: bridge
ipam:
config:
- subnet: 172.20.80.0/24
services:
fe:
image: apache/doris:fe-3.0.4
hostname: fe
ports:
- 8030:8030
- 9030:9030
- 9010:9010
environment:
- FE_SERVERS=fe1:172.20.80.2:9010
- FE_ID=1
networks:
custom_network:
ipv4_address: 172.20.80.2
privileged: true
deploy:
resources:
limits:
memory: 2G
reservations:
memory: 1G
be:
image: apache/doris:be-3.0.4
hostname: be
ports:
- 8040:8040
- 9050:9050
environment:
- FE_SERVERS=fe1:172.20.80.2:9010
- BE_ADDR=172.20.80.3:9050
depends_on:
- fe
networks:
custom_network:
ipv4_address: 172.20.80.3
privileged: true
deploy:
resources:
limits:
memory: 4G
reservations:
memory: 2G


创建表
sql
-- 创建数据库(如果不存在)
CREATE DATABASE IF NOT EXISTS test;
-- 使用数据库
USE test;
-- 在 Doris 中创建 orders 表
CREATE TABLE IF NOT EXISTS orders (
id INT NOT NULL,
price DECIMAL(10,2) NOT NULL
) ENGINE=OLAP
DUPLICATE KEY(id) -- Doris 使用 DUPLICATE KEY 而不是 PRIMARY KEY
DISTRIBUTED BY HASH(id) BUCKETS 4
PROPERTIES (
"replication_num" = "1"
);查看数据
这下环境都准备好了,开始启动任务。
1、flink环境启动,我们直接standalone启动就可以了。
sql
cd /path/flink-*
./bin/start-cluster.sh2、启动我们的kafka环境
sql
1、启动zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties
2、启动kafka服务
bin/kafka-server-start.sh config/server.properties
3、创建topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
4、查看topic
bin/kafka-topics.sh --list --zookeeper localhost:21813、我们的flink cdc就可以启动了
bash
sh flink-cdc-3.4.0/bin/flink-cdc.sh mysql-to-kafka.yaml --flink-home=/xxx/flink/flink-1.20.1/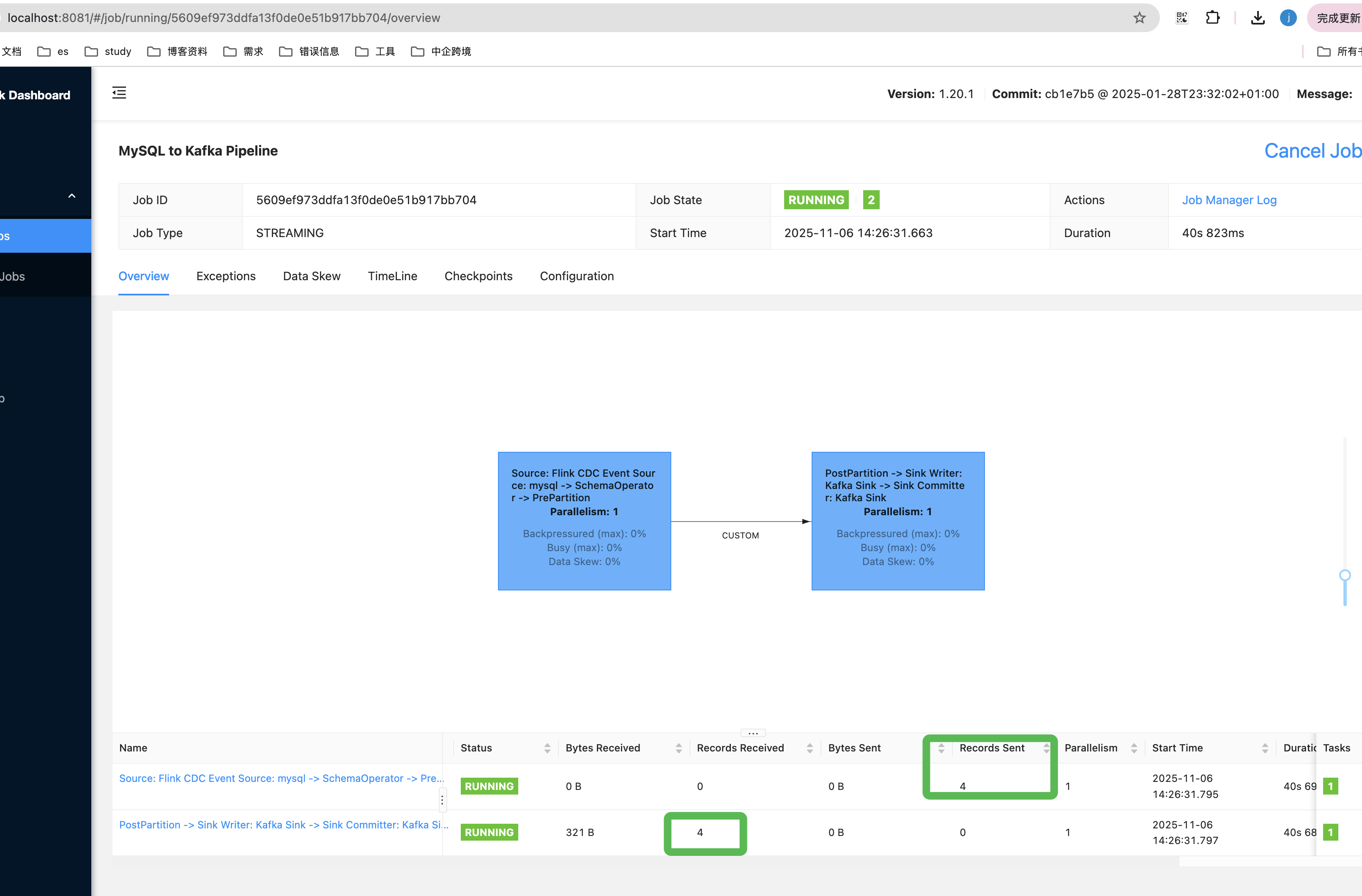
kafka查看我们的数据

4、启动我们的doris
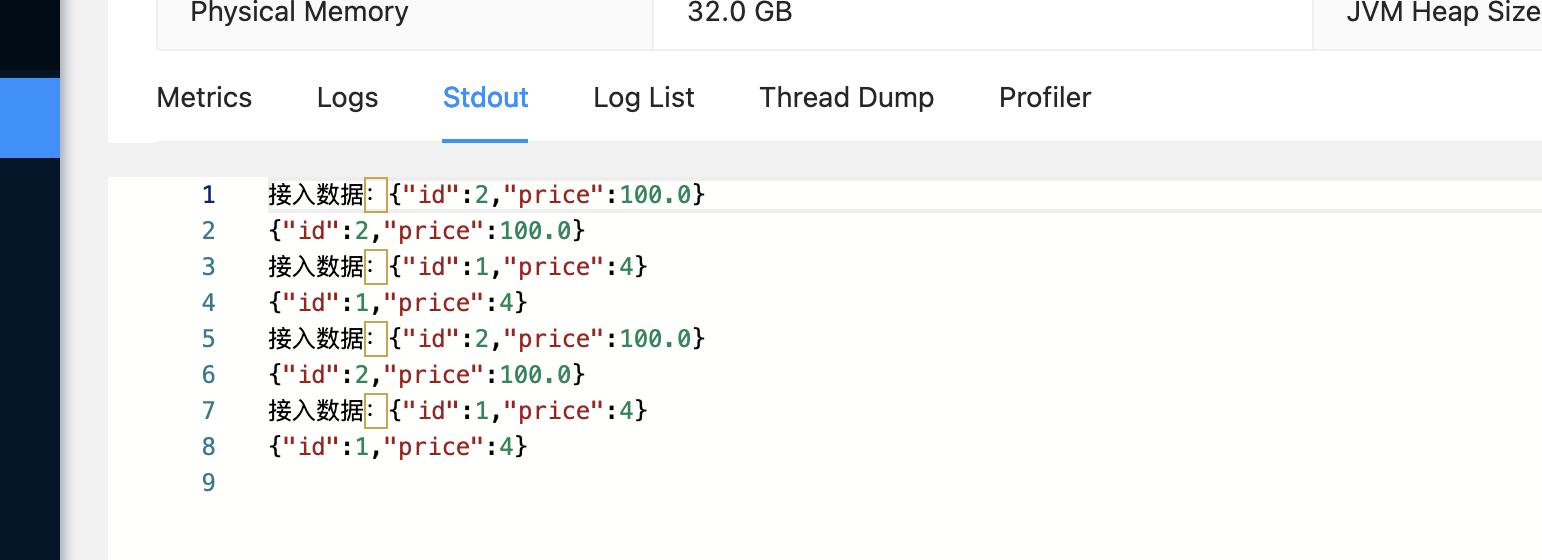
5、启动fliknk作业读取kafka写入doris
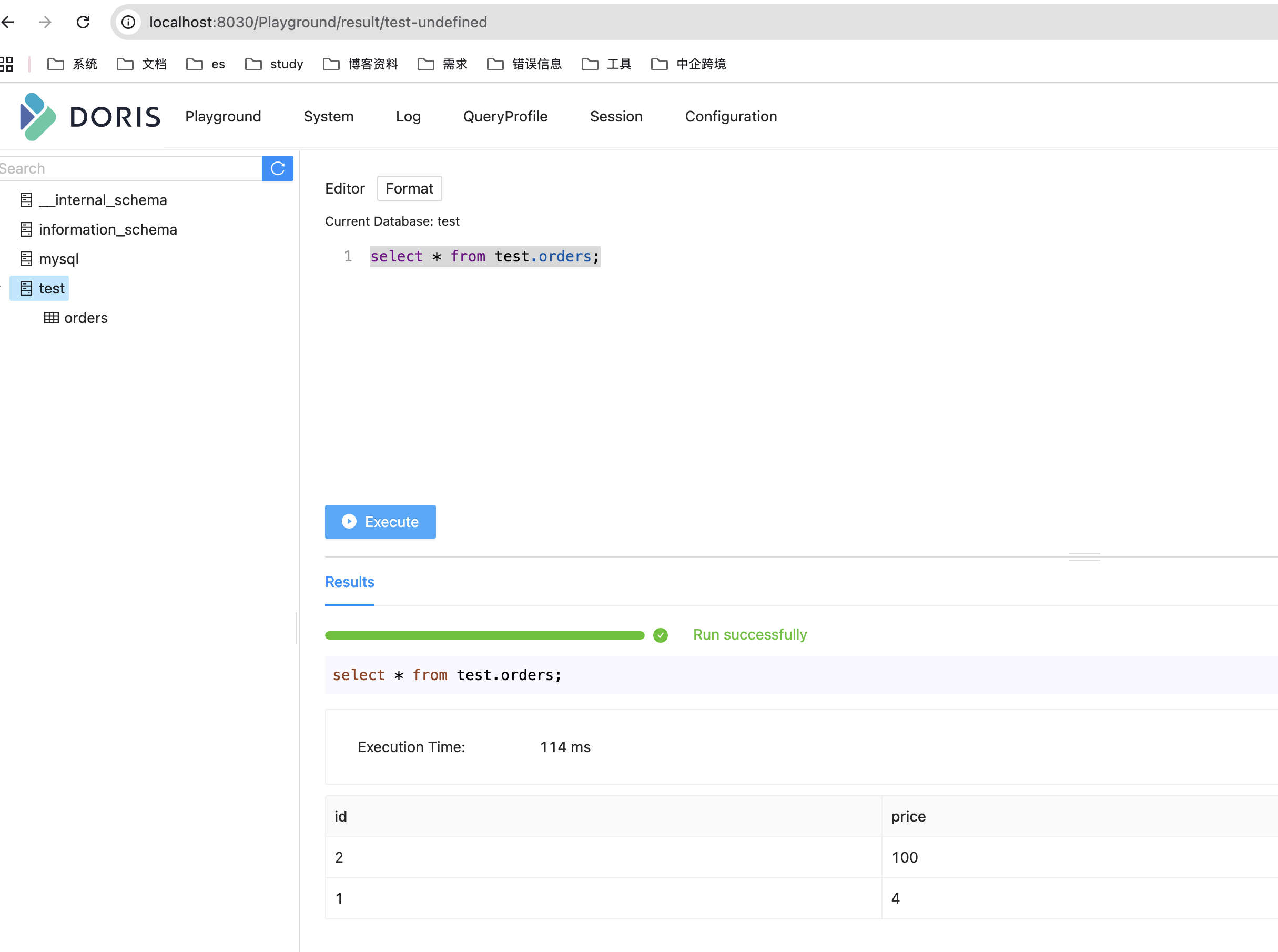
6、最后去doris查看一下数据
总结
太不容易了,在mac本上搭建环境,虽然只是一个简单的测试。让我遇到了好很多问题。
1、mysql版本问题
2、docker 安装的doris 与本地flink网络的问题,之后把flink装在了fe的容器
3、即使flink安装在doris也有网络的问题,flink conf中的地址改为0.0.0.0
4、kakfa与flink任务的不通问题,最后修改了kafka server的配置文件
sql
echo 'listeners=PLAINTEXT://0.0.0.0:9092' >> /usr/local/etc/kafka/server.properties
echo 'advertised.listeners=PLAINTEXT://宿主ip:9092' >> /usr/local/etc/kafka/server.p光是网络的事情折腾了许久,所以呢,不是专业的运维咱就好好写业务代码。本来目的就是采集mysql数据到kafka,flink作业消费kafka做业务逻辑写入doris。结果代码没啥,光是网络折腾好几天,差点就放弃了。总算熬过来了,环境搭建起来,就可以测试作业了。还等啥,搞起来!