unsloth/Llama-3.3-70B-Instruct-GGUF在hf的网址:https://huggingface.co/unsloth/Llama-3.3-70B-Instruct-GGUF
在hf-mirror镜像的网址:https://hf-mirror.com/unsloth/Llama-3.3-70B-Instruct-GGUF
先上结论,速度慢,基本上1秒一个token的往外出,基本没法使用
部署unsloth/Llama-3.3-70B-Instruct-GGUF
部署很简单,进入星河社区部署页面:飞桨AI Studio星河社区-人工智能学习与实训社区
点击:新建部署,选外部资源库,输入模型url,比如
https://huggingface.co/unsloth/Llama-3.3-70B-Instruct-GGUF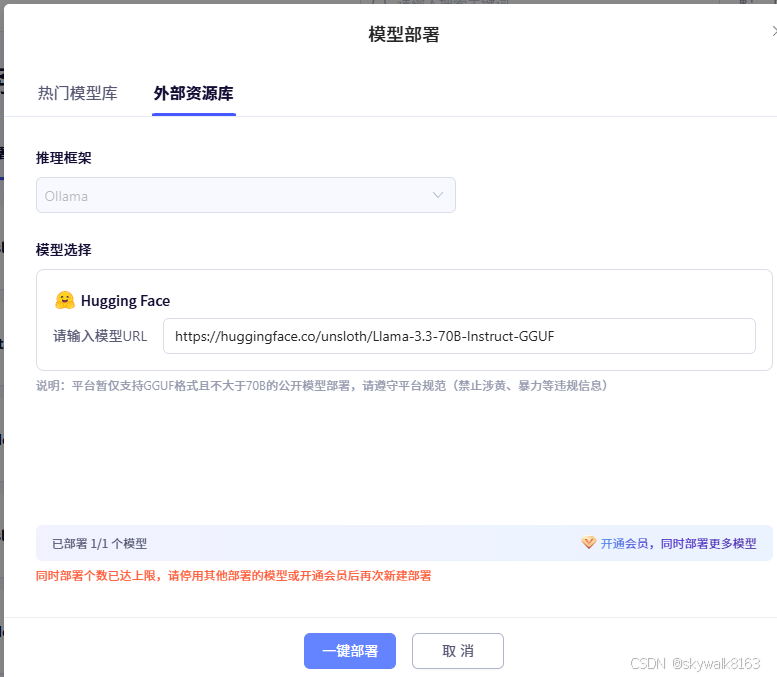
然后点击:一键部署,后面一会儿就部署好了。
使用外部库部署要比内部(也就是热门模型库)要慢很多。而且文本输出速度也很慢,只能说聊胜于无吧。
估计也就是7b、8b模型的速度还可以一用。另外文心自己的21b模型,速度也还将就,至少咱也有免费的大模型用,还要啥自行车!