文章目录
-
- 1.生成式语言模型的对话模板不一致
-
- [1.1 对话模板介绍](#1.1 对话模板介绍)
- [1.2 使用open-webui来检查模型效果](#1.2 使用open-webui来检查模型效果)
-
- [1.2.1 使用ollama部署](#1.2.1 使用ollama部署)
- [1.2.2 使用vllm部署](#1.2.2 使用vllm部署)
- [2.自定义数据集修改LLama Factory的对话模板](#2.自定义数据集修改LLama Factory的对话模板)
- 3.vllm推理模型时自定义对话模板
-
- [3.1 LLamaFactory微调效果与vllm部署效果不一致如何解决?](#3.1 LLamaFactory微调效果与vllm部署效果不一致如何解决?)
- [3.2 转化为jinja格式](#3.2 转化为jinja格式)
- [3.3 修改对话模板](#3.3 修改对话模板)
1.生成式语言模型的对话模板不一致
1.1 对话模板介绍
对话模板是定义当前这个模型在进行文本回复时是以什么方式进行回复的。如果对话模板的规则改变了,那么模型的回复一定是发生变化的。
模型私有化部署微调训练的目的:让模型具有处理特定问题的能力。
关于探讨模型得知识和能力一般理解为两种:
- 第一种比较浅显、简单的知识和能力。
例如:你叫什么名字:以前叫张三,现在叫张麻子
微调主要更改模型的第一种能力(微调可以看作我们人类现实中的一段经历) - 第二种能力类似于模型本身的智能(智商)
例如:该模型在微调之前就已经达到了人类本科生的理解能力了,该能力很难通过微调而改变的。比如:微调前该模型可以解决高数相关的推理计算问题,微调后依然具备该能力。再例如:这种能力可以理解为deepseek R1与llama2得能力差异性。
1.2 使用open-webui来检查模型效果
1.2.1 使用ollama部署
需要提前使用打开ollama服务以及open-webui服务
powershell
conda activate open-webui
export HF_ENDPOINT=https://hf-mirror.com
export ENABLE_OLLAMA_API=True
export OPENAI_API_BASE_URL=http://127.0.0.1:11434/v1
open-webui serve增加8080端口,用户转发需要手动访问

http://127.0.0.1:8080即可访问到
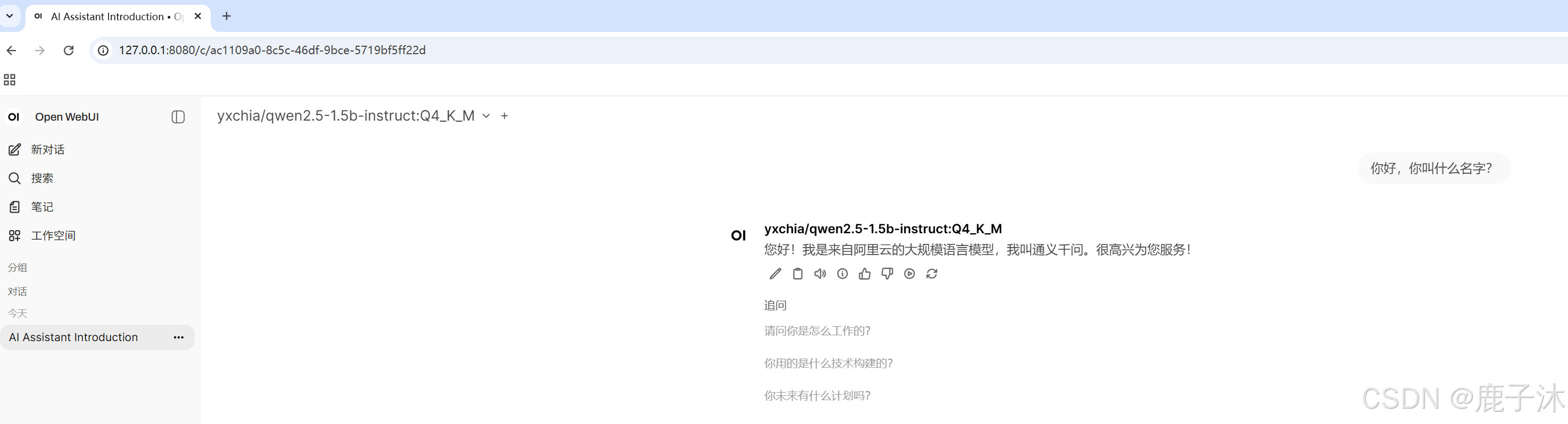
注:需使用ollama提前部署模型
1.2.2 使用vllm部署
powershell
conda activate open-webui
export HF_ENDPOINT=https://hf-mirror.com
export ENABLE_OLLAMA_API=FALSE
export OPENAI_API_BASE_URL=http://localhost:8000/v1
open-webui serve2.自定义数据集修改LLama Factory的对话模板
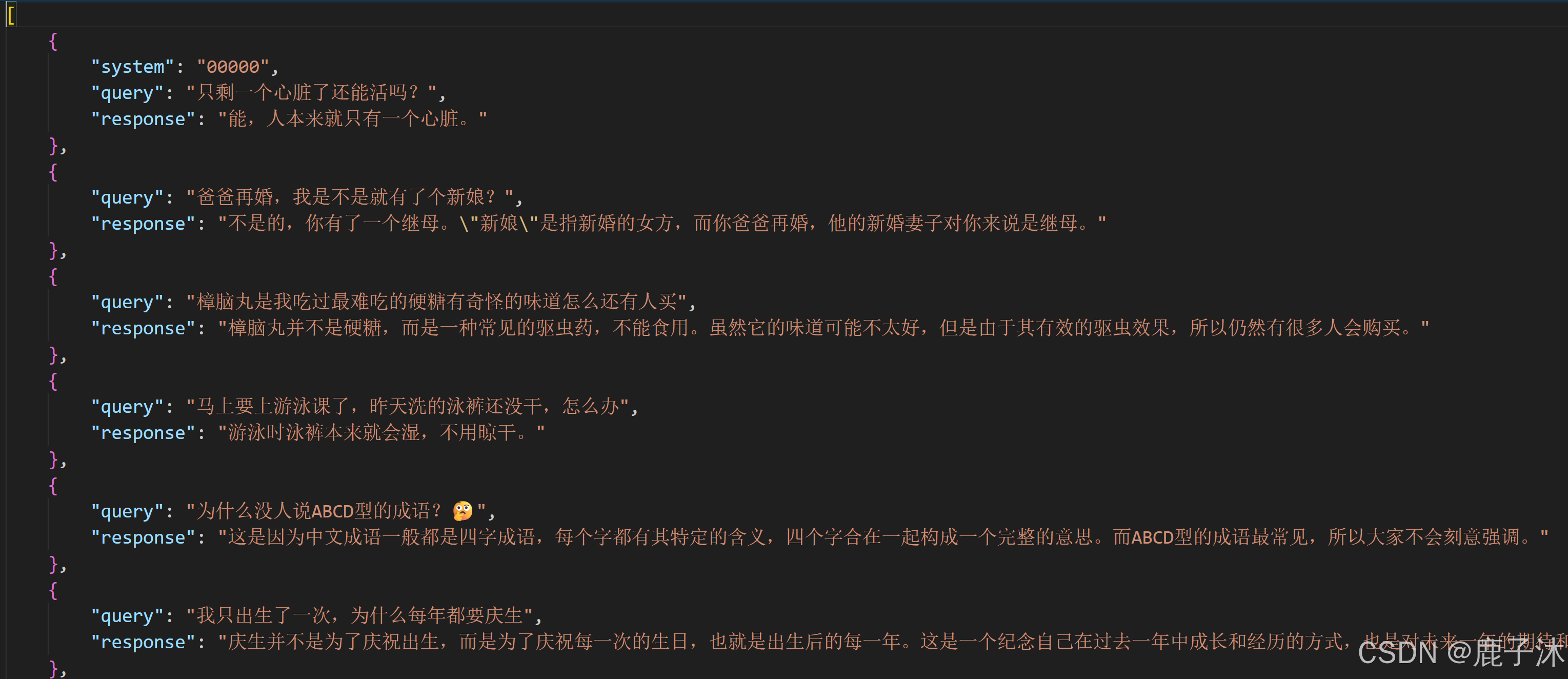
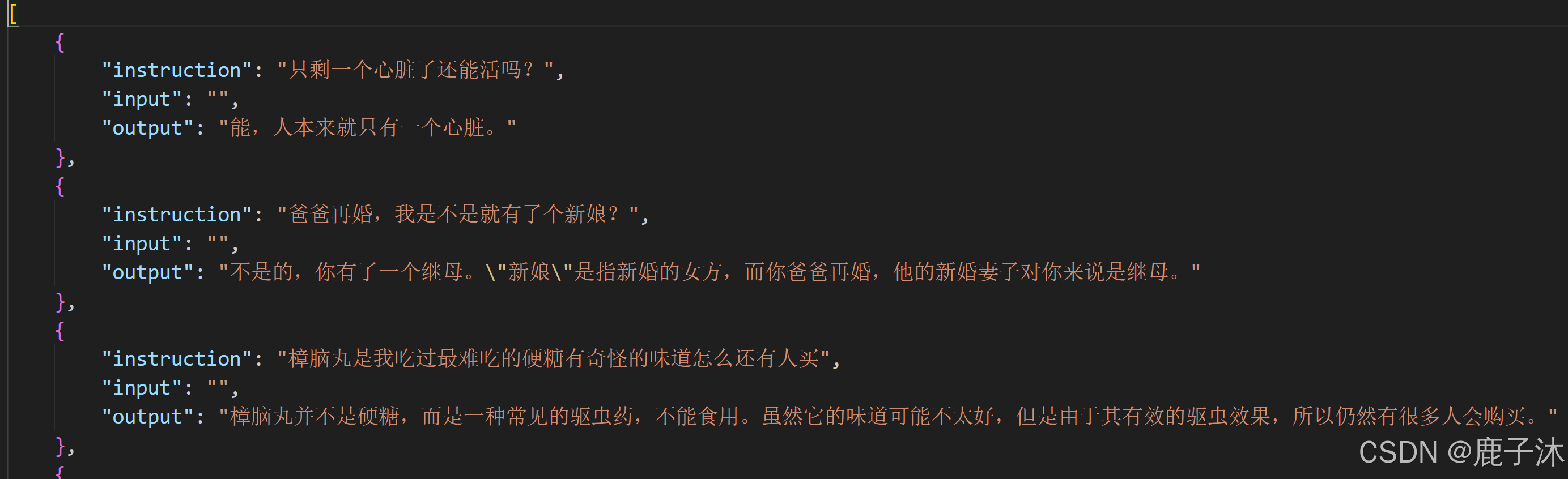
针对于以上数据集形式转换为以下llama factory的格式,需要使用代码实现。其中instruction对应query,output对应response。
powershell
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]转换代码:(不同的数据集格式代码不同)
python
import json
# 读取原始JSON文件
input_file = "data/ruozhiba_qaswift.json" # 你的JSON文件名
output_file = "data/ruozhiba_qaswift_train.json" # 输出的JSON文件名
with open(input_file, "r", encoding="utf-8") as f:
data = json.load(f)
# 转换后的数据
converted_data = []
for item in data:
converted_item = {
"instruction": item["query"],
"input": "",
"output": item["response"]
}
converted_data.append(converted_item)
# 保存为JSON文件(最外层是列表)
with open(output_file, "w", encoding="utf-8") as f:
json.dump(converted_data, f, ensure_ascii=False, indent=4)
print(f"转换完成,数据已保存为 {output_file}")以下为llama factory的对话模板
3.vllm推理模型时自定义对话模板
3.1 LLamaFactory微调效果与vllm部署效果不一致如何解决?
llama factory所使用的对话模板与大模型之间的对话模板是不一样的。
需要修改对话模板:
powershell
vllm serve /root/autodl-tmp/Qwen/Qwen2.5-1.5B-Instruct-800 --enforce-eager
--chat-template /root/autodl-tmp/LLaMA-Factory/qwen.jinja3.2 转化为jinja格式
vLLM 要求模型在其 tokenizer 配置中包含聊天模板。
tokenizer 配置:vLLM 要求模型的tokenizer_config.json中必须包含chat_template字段
vllm要求模型在其tokenizer配置中包含聊天模板。聊天模板是一个jinja2模板,用于指定角色、消息和其他特定于聊天的token如何在输入中编码。
代码:转化为jinja格式
python
# mytest.py
import sys
import os
# 将项目根目录添加到 Python 路径
root_dir = os.path.dirname(os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))))
sys.path.append(root_dir)
from llamafactory.data.template import TEMPLATES
from transformers import AutoTokenizer
# 1. 初始化分词器(任意支持的分词器均可)
tokenizer = AutoTokenizer.from_pretrained("/root/autodl-tmp/Qwen/Qwen2.5-1.5B-Instruct")
# 2. 获取模板对象
template_name = "qwen" # 替换为你需要查看的模板名称
template = TEMPLATES[template_name]
# 3. 修复分词器的 Jinja 模板
template.fix_jinja_template(tokenizer)
# 4. 直接输出模板的 Jinja 格式
print("=" * 40)
print(f"Template [{template_name}] 的 Jinja 格式:")
print("=" * 40)
print(tokenizer.chat_template)jiaja2格式
powershell
{%- if tools %}
{{- '<|im_start|>system\n' }}
{%- if messages[0]['role'] == 'system' %}
{{- messages[0]['content'] }}
{%- else %}
{{- 'You are Qwen, created by Alibaba Cloud. You are a helpful assistant.' }}
{%- endif %}
{{- "\n\n# Tools\n\nYou may call one or more functions to assist with the user query.\n\nYou are provided with function signatures within <tools></tools> XML tags:\n<tools>" }}
{%- for tool in tools %}
{{- "\n" }}
{{- tool | tojson }}
{%- endfor %}
{{- "\n</tools>\n\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\n<tool_call>\n{\"name\": <function-name>, \"arguments\": <args-json-object>}\n</tool_call><|im_end|>\n" }}
{%- else %}
{%- if messages[0]['role'] == 'system' %}
{{- '<|im_start|>system\n' + messages[0]['content'] + '<|im_end|>\n' }}
{%- else %}
{{- '<|im_start|>system\nYou are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>\n' }}
{%- endif %}
{%- endif %}
{%- for message in messages %}
{%- if (message.role == "user") or (message.role == "system" and not loop.first) or (message.role == "assistant" and not message.tool_calls) %}
{{- '<|im_start|>' + message.role + '\n' + message.content + '<|im_end|>' + '\n' }}
{%- elif message.role == "assistant" %}
{{- '<|im_start|>' + message.role }}
{%- if message.content %}
{{- '\n' + message.content }}
{%- endif %}
{%- for tool_call in message.tool_calls %}
{%- if tool_call.function is defined %}
{%- set tool_call = tool_call.function %}
{%- endif %}
{{- '\n<tool_call>\n{"name": "' }}
{{- tool_call.name }}
{{- '", "arguments": ' }}
{{- tool_call.arguments | tojson }}
{{- '}\n</tool_call>' }}
{%- endfor %}
{{- '<|im_end|>\n' }}
{%- elif message.role == "tool" %}
{%- if (loop.index0 == 0) or (messages[loop.index0 - 1].role != "tool") %}
{{- '<|im_start|>user' }}
{%- endif %}
{{- '\n<tool_response>\n' }}
{{- message.content }}
{{- '\n</tool_response>' }}
{%- if loop.last or (messages[loop.index0 + 1].role != "tool") %}
{{- '<|im_end|>\n' }}
{%- endif %}
{%- endif %}
{%- endfor %}
{%- if add_generation_prompt %}
{{- '<|im_start|>assistant\n' }}
{%- endif %}3.3 修改对话模板
- 导出自己微调后训练的模型权重
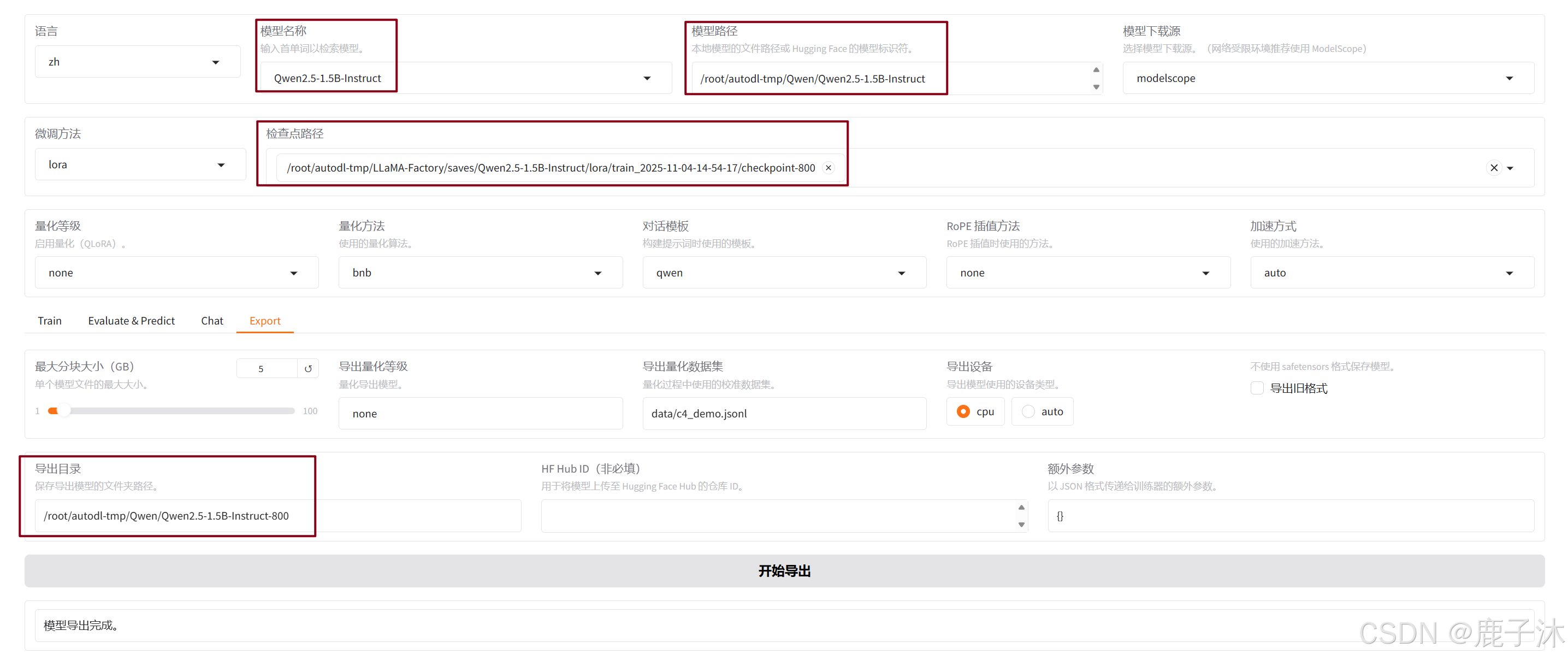
- 对比效果
微调前的效果:
powershell
vllm serve /root/autodl-tmp/Qwen/Qwen2.5-1.5B-Instruct其中,test.py为:
python
#多轮对话
from openai import OpenAI
#定义多轮对话方法
def run_chat_session():
#初始化客户端
client = OpenAI(base_url="http://localhost:8000/v1/",api_key="suibianxie")
#初始化对话历史
chat_history = []
#启动对话循环
while True:
#获取用户输入
user_input = input("用户:")
if user_input.lower() == "exit":
print("退出对话。")
break
#更新对话历史(添加用户输入)
chat_history.append({"role":"user","content":user_input})
#调用模型回答
try:
chat_complition = client.chat.completions.create(messages=chat_history,model="/root/autodl-tmp/Qwen/Qwen2.5-1.5B-Instruct")
#获取最新回答
model_response = chat_complition.choices[0]
print("AI:",model_response.message.content)
#更新对话历史(添加AI模型的回复)
chat_history.append({"role":"assistant","content":model_response.message.content})
except Exception as e:
print("发生错误:",e)
break
if __name__ == '__main__':
run_chat_session()
微调后未修改对话模板效果:
powershell
vllm serve /root/autodl-tmp/Qwen/Qwen2.5-1.5B-Instruct-800
微调后修改对话模板效果:
powershell
vllm serve /root/autodl-tmp/Qwen/Qwen2.5-1.5B-Instruct-800 --enforce-eager
--chat-template /root/autodl-tmp/LLaMA-Factory/qwen.jinja效果相同,则说明llamafactory中自带的对话模板和模型里面的对话模板是一样的。
