1、数据集准备
{
"instruction": instruction, # 提示词
"keypoint": keypoint, # 关键字
"input": input, # 用户输入+问题
"output": out_put # 指定输出
}2、添加数据集格式
在data文件夹-dataset_info.json中添加制作好的数据集,文本训练添加参考格式如下
"alpaca_zh_demo": {
"file_name": "alpaca_zh_demo.json"
}总数据量:6448条
3、启动面板命令
CUDA_VISIBLE_DEVICES=x llamafactory-cli webui # x指定显卡4、参数配置
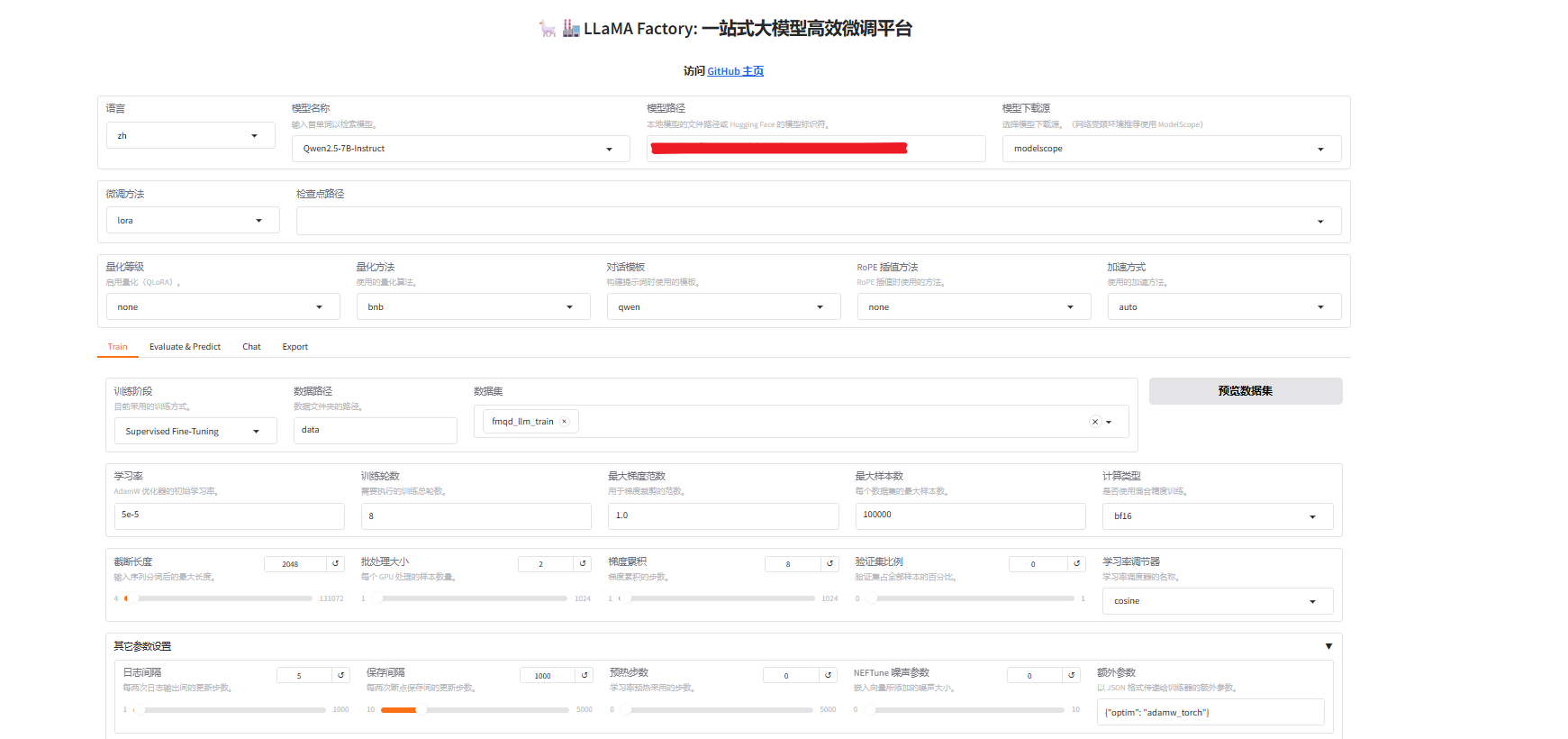
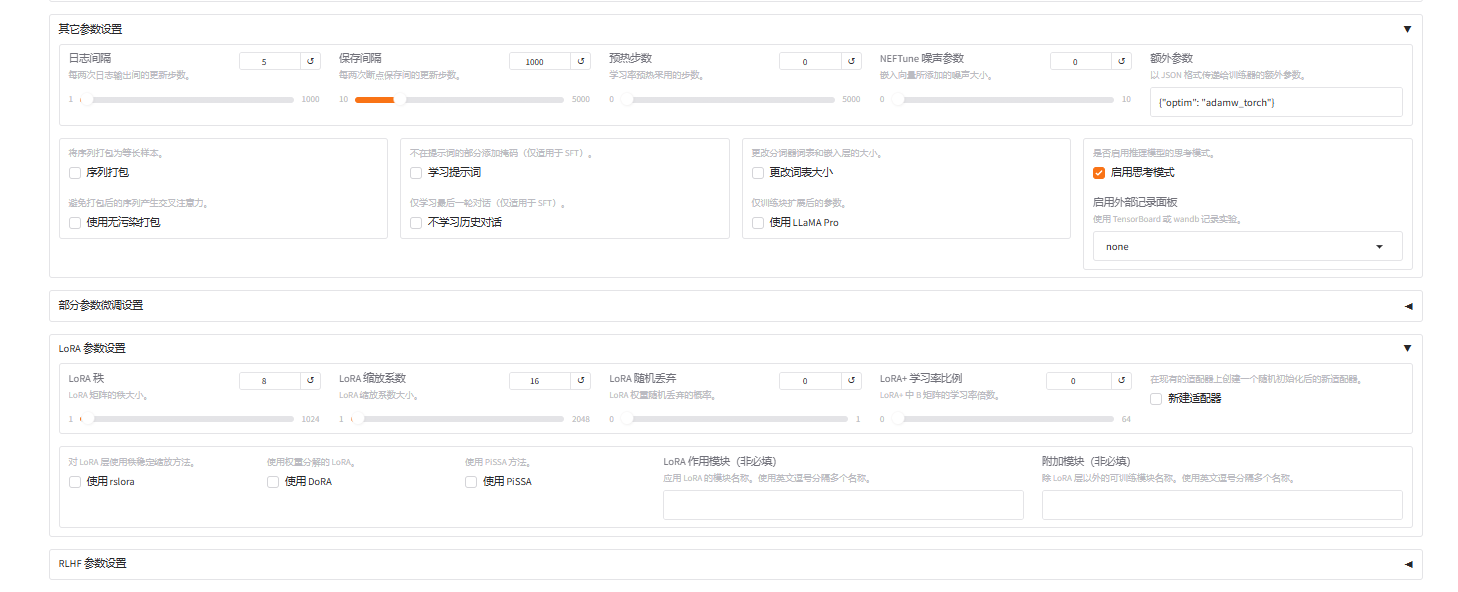
主要参数:
epoch:8
截断长度:2048
数据量:6448
显存占用:14942MiB
其他默认即可,开始训练
显示训练完时间大概9小时左右
5、训练过程,观察并不是很收敛,且忘记设置截断长度,训练样本较长

6、修改参数重新训练
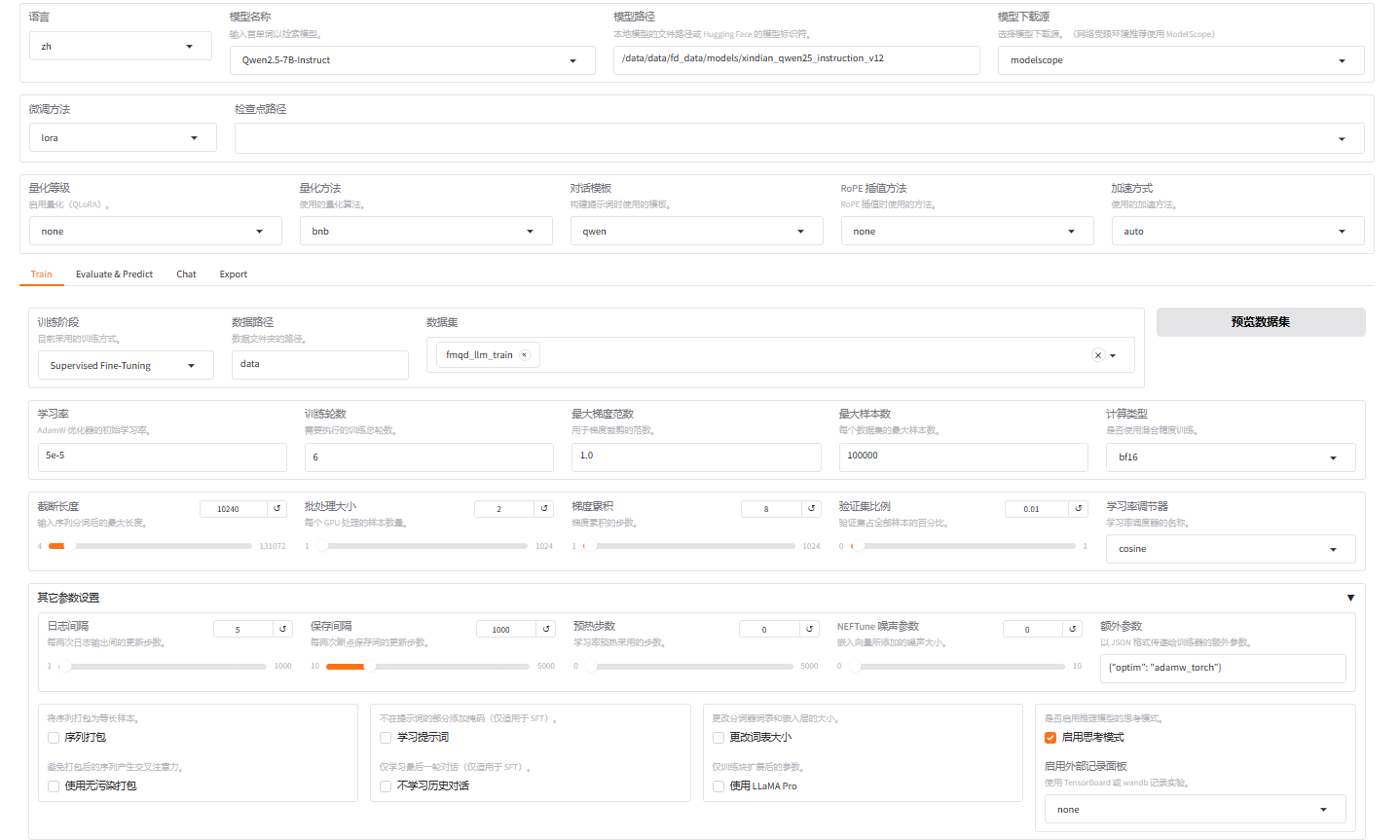
修改截断长度为10240,增加验证集比例,训练时长显示大约24H,显存占用:61620MiB
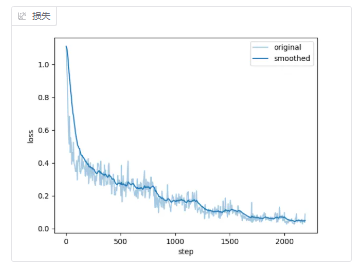
训练曲线:
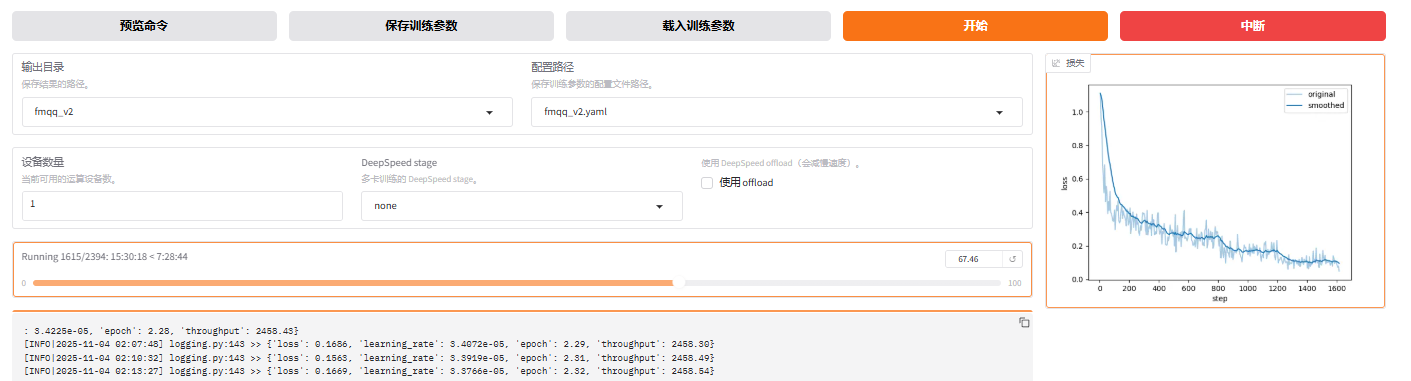
最终曲线
输入数据格式:
inputs:
<|im_start|>system
You are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>
<|im_start|>user
作为一个的AI助手,你的目标是帮助客户阅读并回答问题。
文件内容:督促施工单位确保本工程按期或提前完成.......。
用户问题:业绩要求
<|im_end|>
<|im_start|>assistant
业绩要求:见投标人须知前附表.....<|im_end|>但是输入格式为:
{
"instruction": "作为一个的AI助手,你的目标是帮助客户阅读并回答问题。",
"keypoint": "业绩相关评审标准",
"input": "文件内容:【一级标题】.....\n\n 用户问题:业绩要求\n",
"output": "业绩要求:见投标人须知前附表。"
}系统会将原始数据的instruction和input合并作为用户输入