接上篇MyBatis-Plus 源码阅读(一)CRUD 方法自动生成原理深度剖析,本文我们讲解一下 mp 的代码生成器是如何工作的。
环境
- 核心依赖:mybatis-plus-spring-boot3-starter 3.5.14
- 基础框架:Spring Boot 3.5.6
- JDK 版本:17
- 开发工具:IntelliJ IDEA
- 模板引擎:Velocity
快速上手:3 步生成代码
在剖析源码前,我们先通过一个完整示例感受代码生成器的便捷性,为后续源码分析建立直观认知。
准备数据表
sql
create table `order`
(
id bigint auto_increment comment '订单主键'
primary key,
order_no varchar(64) not null comment '订单编号(业务唯一标识)',
user_id bigint not null comment '下单用户ID',
order_status tinyint default 0 not null comment '订单状态:0-待付款 1-待发货 2-待收货 3-已完成 4-已取消',
total_amount decimal(10, 2) default 0.00 not null comment '订单总金额(含所有费用)',
pay_amount decimal(10, 2) default 0.00 not null comment '实际支付金额',
create_time datetime default CURRENT_TIMESTAMP not null comment '创建时间',
update_time datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '更新时间',
constraint uk_order_no
unique (order_no)
)
comment '订单主表';引入依赖
xml
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>3.5.14</version>
</dependency>
<!-- 添加Velocity模板引擎依赖 -->
<dependency>
<groupId>org.apache.velocity</groupId>
<artifactId>velocity-engine-core</artifactId>
<version>2.3</version>
</dependency>编写生成器脚本并执行
按照官方文档的示例简单修改了一下。
java
public class MpGenerator {
public static void main(String[] args) {
FastAutoGenerator.create("jdbc:mysql://localhost:3306/test",
"root", "1234")
.globalConfig(builder -> builder
.author("SheepHappy")
.outputDir(Paths.get(System.getProperty("user.dir")) + "/src/main/java")
.commentDate("yyyy-MM-dd")
)
.packageConfig(builder -> builder
.parent("edu.neuq.mptest")
.entity("entity")
.mapper("mapper")
.service("service")
.serviceImpl("service.impl")
// 添加pathInfo配置,指定XML文件的输出路径
.pathInfo(Collections.singletonMap(OutputFile.xml,
Paths.get(System.getProperty("user.dir")) + "/src/main/resources/mapper"))
)
.strategyConfig(builder -> builder
.addInclude("order")
.entityBuilder()
.enableLombok()
)
.templateEngine(new FreemarkerTemplateEngine())
.execute();
}
}执行脚本,发现对应的 mapper、entity 和 service 类的代码全部都生成了。
源码分析
代码生成器的源码相对来说还是比较简单的,没有过深的层级。
核心流程可以分为下面四步:
- 读元数据:连接数据库,读取目标表的结构(表名、字段名、字段类型、注释、主键等);
- 数据建模 :将读取到的数据库元数据,封装成 MP 内部的 "数据模型"(比如
TableInfo、FieldInfo); - 模板渲染:加载预设 / 自定义的代码模板(Velocity/Freemarker/Beetl),用 "数据模型" 填充模板中的占位符;
- 文件输出:将渲染后的模板内容,按指定路径和文件名写入本地文件。
第一步:读元数据 ------ 从数据库提取表结构信息
核心代码主要在com.baomidou.mybatisplus.generator.query.DefaultQuery#queryTables
java
@Override
public @NotNull List<TableInfo> queryTables() {
try {
boolean isInclude = !strategyConfig.getInclude().isEmpty();
boolean isExclude = !strategyConfig.getExclude().isEmpty();
List<TableInfo> tableList = new ArrayList<>();
// 1.查询所有表名
List<DatabaseMetaDataWrapper.Table> tables = this.getTables();
List<TableInfo> includeTableList = new ArrayList<>();
List<TableInfo> excludeTableList = new ArrayList<>();
tables.forEach(table -> {
String tableName = table.getName();
if (StringUtils.isNotBlank(tableName)) {
TableInfo tableInfo = new TableInfo(this.configBuilder, tableName);
tableInfo.setComment(table.getRemarks());
if (isInclude && strategyConfig.matchIncludeTable(tableName)) {
includeTableList.add(tableInfo);
} else if (isExclude && strategyConfig.matchExcludeTable(tableName)) {
excludeTableList.add(tableInfo);
}
tableList.add(tableInfo);
}
});
// 2.过滤出需要的表名
filter(tableList, includeTableList, excludeTableList);
// 3.对于每张表,获取字段等元信息
tableList.forEach(this::convertTableFields);
return tableList;
} finally {
databaseMetaDataWrapper.closeConnection();
}
}查询所有表名
this.getTables() 最终调用 com.baomidou.mybatisplus.generator.jdbc.DatabaseMetaDataWrapper#getTables,通过 JDBC 标准接口 DatabaseMetaData 查询表名和表注释:
java
public List<Table> getTables(String catalog, String schemaPattern, String tableNamePattern, String[] types) {
List<Table> tables = new ArrayList<>();
try (ResultSet resultSet = databaseMetaData.getTables(catalog, schemaPattern, tableNamePattern, types)) {
Table table;
while (resultSet.next()) {
table = new Table();
table.name = resultSet.getString("TABLE_NAME");
table.remarks = formatComment(resultSet.getString("REMARKS"));
table.tableType = resultSet.getString("TABLE_TYPE");
tables.add(table);
}
} catch (SQLException e) {
throw new RuntimeException(e);
}
return tables;
}DatabaseMetaData 是 JDBC 提供的数据库元信息查询接口,不同数据库(MySQL、Oracle)的驱动会实现该接口,因此 MP 能适配多种数据库。
表过滤
filter 方法的核心逻辑是 "排除规则优先于包含规则":
- 若配置了
exclude:从所有表中移除符合排除规则的表; - 若未配置
exclude但配置了include:仅保留符合包含规则的表; - 若都未配置:生成数据库中所有表的代码。
拿到表字段等元信息
this::convertTableFields 是字段信息查询的核心,负责读取每个字段的详细属性并封装:
java
protected void convertTableFields(@NotNull TableInfo tableInfo) {
String tableName = tableInfo.getName();
Map<String, DatabaseMetaDataWrapper.Column> columnsInfoMap = getColumnsInfo(tableName);
Entity entity = strategyConfig.entity();
columnsInfoMap.forEach((k, columnInfo) -> {
String columnName = columnInfo.getName();
TableField field = new TableField(this.configBuilder, columnName);
// 处理ID
if (columnInfo.isPrimaryKey()) {
field.primaryKey(columnInfo.isAutoIncrement());
tableInfo.setHavePrimaryKey(true);
if (field.isKeyIdentityFlag() && entity.getIdType() != null) {
LOGGER.warn("The primary key of the current table [{}] is configured as auto-incrementing, which will override the global primary key ID type strategy.", tableName);
}
}
field.setColumnName(columnName).setComment(columnInfo.getRemarks());
String propertyName = entity.getNameConvert().propertyNameConvert(field);
// 设置字段的元数据信息
TableField.MetaInfo metaInfo = new TableField.MetaInfo(columnInfo, tableInfo);
IColumnType columnType;
ITypeConvertHandler typeConvertHandler = dataSourceConfig.getTypeConvertHandler();
if (typeConvertHandler != null) {
columnType = typeConvertHandler.convert(globalConfig, typeRegistry, metaInfo);
} else {
columnType = typeRegistry.getColumnType(metaInfo);
}
field.setPropertyName(propertyName, columnType);
field.setMetaInfo(metaInfo);
tableInfo.addField(field);
});
tableInfo.setIndexList(getIndex(tableName));
tableInfo.processTable();
}第二步:数据建模 ------ 封装为 MP 内部数据模型
在上面的 com.baomidou.mybatisplus.generator.query.DefaultQuery#convertTableFields 方法中,先将 columnInfo 转换为 tableFiled,再添加到 tableInfo 里。至此,数据库表的元信息已经全部获取到,终于可以进入核心的模板渲染环节了。
第三步:模板渲染 ------ 数据模型 + 模板 = 代码字符串
模板引擎本质就是 "填坑工具" --------- 模板是写好固定结构的 "稿子"(比如后面会看到的 Entity 模板),里面留着 ${变量} 这种 "坑位",模板引擎的作用就是把数据模型里的内容(比如表名、字段名),自动填进这些 "坑位",最后生成完整的代码 / 文本。
MP 的模板引擎模块采用模板方法模式,核心优势是 "统一流程、灵活扩展":
- 抽象父类
AbstractTemplateEngine:定义统一的渲染流程(batchOutput方法),封装不变逻辑(如获取配置、构建数据模型映射); - 具体实现类:
VelocityTemplateEngine、FreemarkerTemplateEngine、BeetlTemplateEngine,分别实现不同模板引擎的渲染细节(如占位符解析、模板加载)。
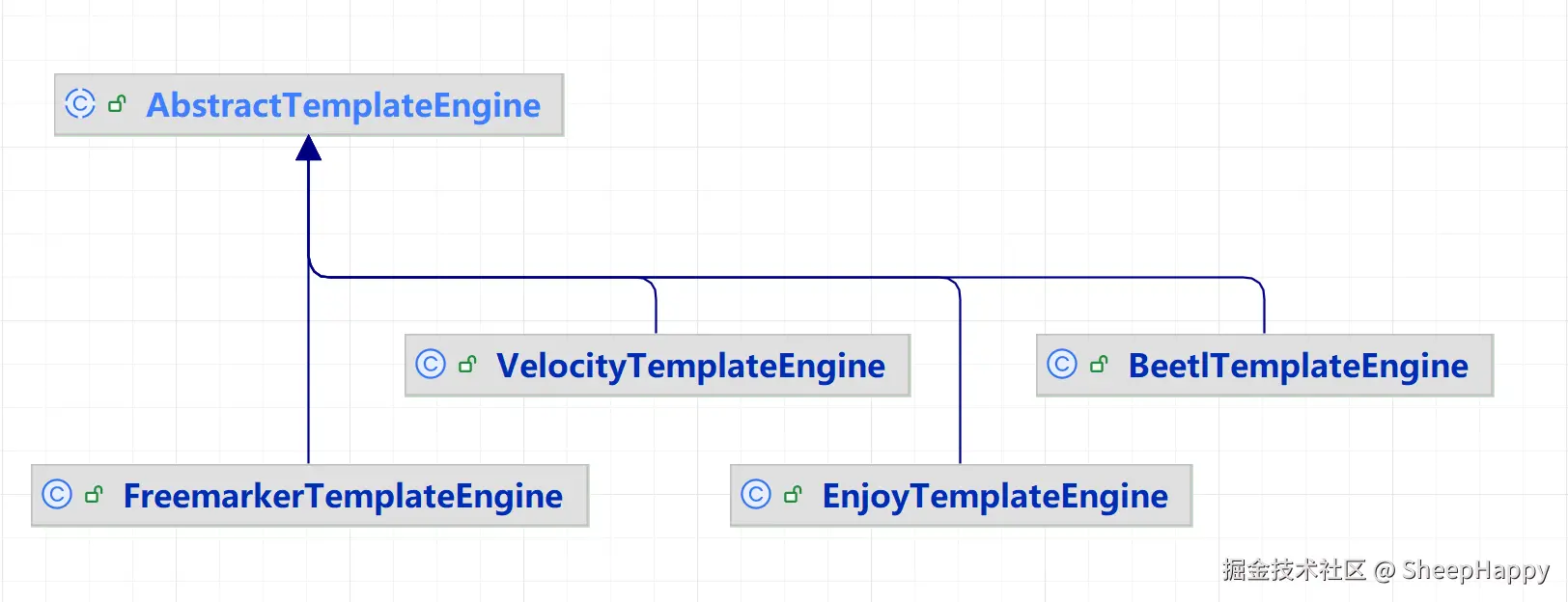
模板渲染的入口为com.baomidou.mybatisplus.generator.engine.AbstractTemplateEngine#batchOutput,负责遍历所有目标表,生成对应模块的代码:
java
public AbstractTemplateEngine batchOutput() {
try {
ConfigBuilder config = this.getConfigBuilder();
List<TableInfo> tableInfoList = config.getTableInfoList(); // 第二步构建的表数据模型列表
// 遍历每张表,生成对应代码
tableInfoList.forEach(tableInfo -> {
// 1. 构建模板上下文:将配置、表数据模型转换为模板可识别的 Map 结构
Map<String, Object> objectMap = this.getObjectMap(config, tableInfo);
// 2. 处理自定义配置(如注入自定义属性、生成自定义文件)
Optional.ofNullable(config.getInjectionConfig()).ifPresent(t -> {
t.beforeOutputFile(tableInfo, objectMap); // 输出文件前的自定义处理
outputCustomFile(t.getCustomFiles(), tableInfo, objectMap); // 生成自定义文件
});
// 3. 生成核心模块代码(Entity、Mapper、Service、Controller)
outputEntity(tableInfo, objectMap); // 生成实体类
outputMapper(tableInfo, objectMap); // 生成 Mapper 接口 + XML
outputService(tableInfo, objectMap); // 生成 Service
outputController(tableInfo, objectMap); // 生成 Controller
});
} catch (Exception e) {
throw new RuntimeException("代码生成失败", e);
}
return this;
}以 outputEntity(tableInfo, objectMap) 方法进行深入分析,最后进入到
java
com.baomidou.mybatisplus.generator.engine.VelocityTemplateEngine#writer(
java.util.Map<java.lang.String,java.lang.Object>,
java.lang.String, java.io.File)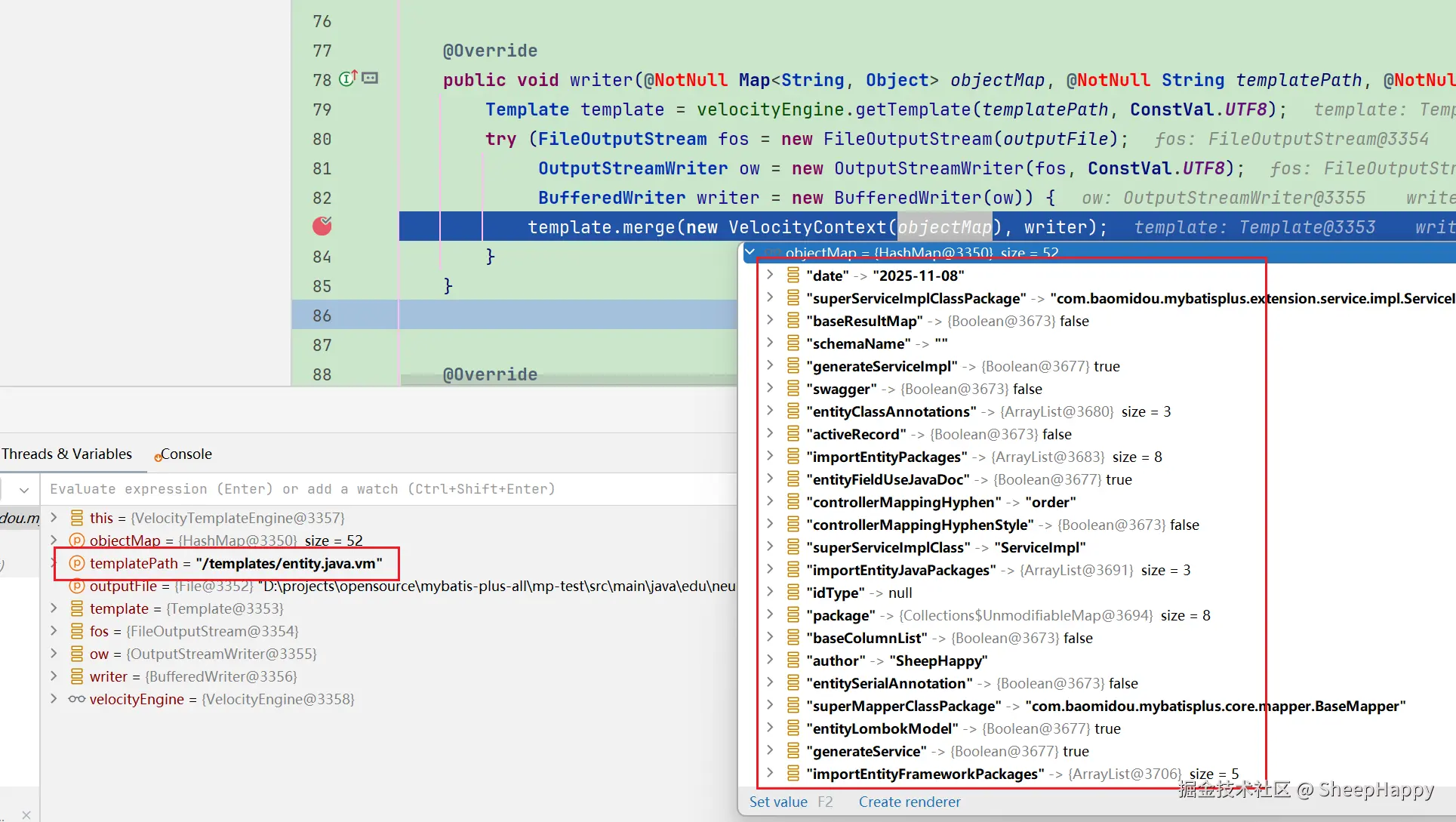 通过打断点可以发现,所有的配置信息和数据库元信息都作为 objectMap 的参数注入到模板中。
通过打断点可以发现,所有的配置信息和数据库元信息都作为 objectMap 的参数注入到模板中。
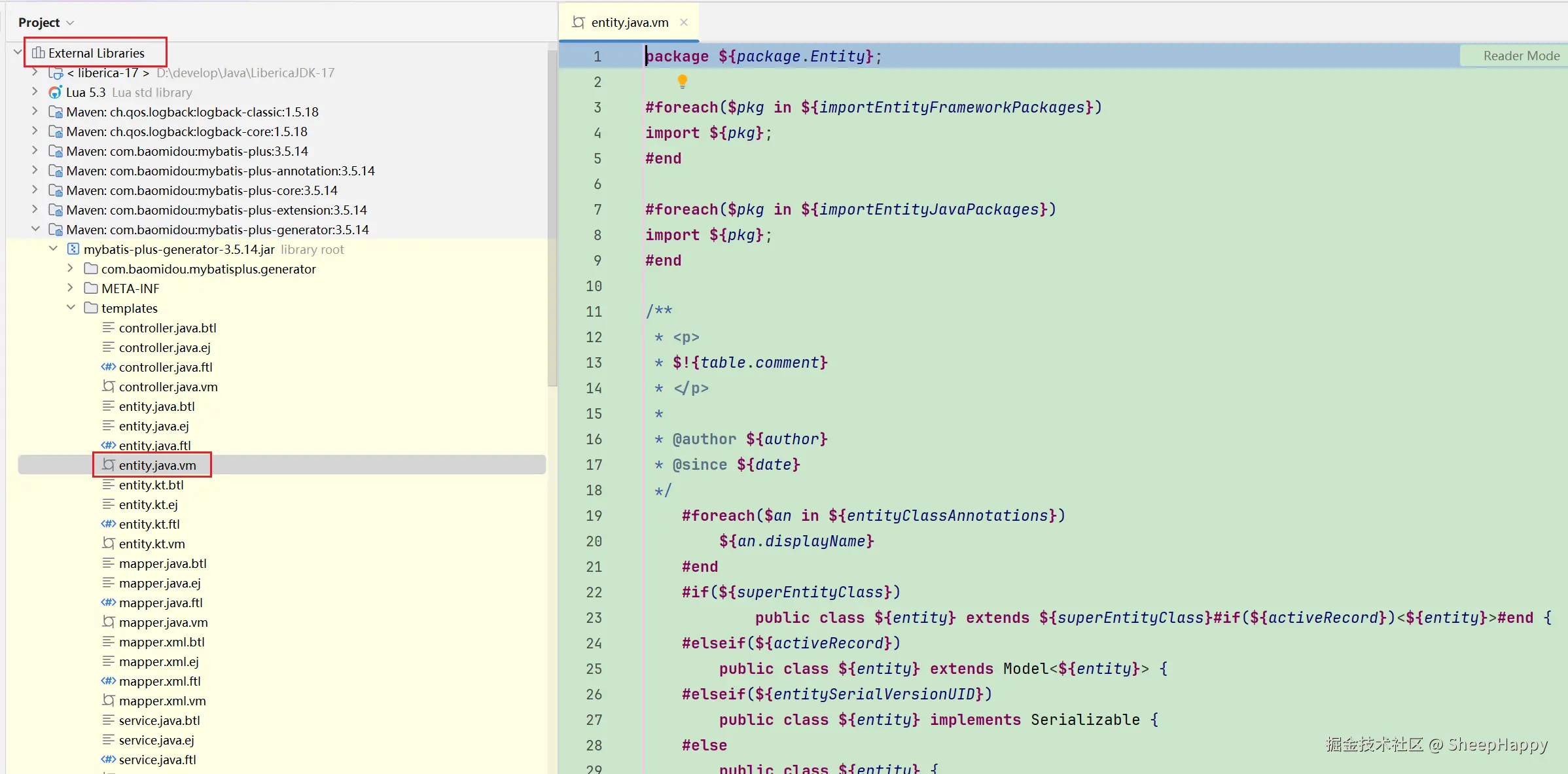 代码模板文件也很容易在外部库找到。 简单介绍一下 Velocity 语法,模板里的
代码模板文件也很容易在外部库找到。 简单介绍一下 Velocity 语法,模板里的 #xxx 是 Velocity 的 "指令"(循环、判断),${xxx} 是 "占位符"(后续会用数据库元数据填充),其他没被 # 或 $ 包裹的内容(如 package、public class)会直接原样输出。
下面是 Entity 模板代码的简化版本
java
# 1. 包声明(Entity 放在哪个包下)
package ${package.Entity};
# 2. 自动导入依赖包(框架包 + Java 基础包)
#foreach($pkg in ${importEntityFrameworkPackages})
import ${pkg};
#end
#foreach($pkg in ${importEntityJavaPackages})
import ${pkg};
#end
# 3. 类注释(表说明、作者、生成日期)
/**
* <p>
* $!{table.comment} # 数据库表的注释
* </p>
* @author ${author} # 配置的作者名
* @since ${date} # 代码生成日期
*/
# 4. 类上的注解(如 @TableName、@Data)
#foreach($an in ${entityClassAnnotations})
${an.displayName}
#end
# 5. 类定义(生成 Entity 类名)
public class ${entity} { # ${entity} 是 Entity 类名(如 User)
# 6. 循环生成所有字段(核心:数据库字段 → Java 属性)
#foreach($field in ${table.fields})
# 字段注释(有注释才生成)
#if("$!field.comment" != "")
/**
* ${field.comment} # 字段的注释
*/
#end
# 字段上的注解(如 @TableId、@TableField)
#foreach($an in ${field.annotationAttributesList})
${an.displayName}
#end
# 字段定义(private + Java 类型 + 属性名)
private ${field.propertyType} ${field.propertyName}; # 如 private String userName;
#end
# 7. 生成 getter/setter 方法(非 Lombok 模式)
#foreach($field in ${table.fields})
# 布尔类型 getter 用 isXXX,其他用 getXXX
#if(${field.propertyType.equals("boolean")})
#set($getprefix="is")
#else
#set($getprefix="get")
#end
# getter 方法
public ${field.propertyType} ${getprefix}${field.capitalName}() {
return ${field.propertyName};
}
# setter 方法
public void set${field.capitalName}(${field.propertyType} ${field.propertyName}) {
this.${field.propertyName} = ${field.propertyName};
}
#end
}第四步:文件输出
默认情况下,mp 生成代码时会检查目标文件是否存在,如果存在就不生成,避免覆盖原有文件。
自定义模板:按需定制专属代码(实操指南)
现在,我们已经基本了解 mp 代码生成的全流程。但有些时候,mp 内置的模板可能不满足我们的需求,我们也可以自定义自己的模板。
将 MP 内置的模板文件复制到项目 resources/templates 目录下,按相同目录结构存放,修改后生成器会优先加载自定义模板,而非内置模板。
例如,往模板的 class 里面添加
arduino
public static final String TABLE_NAME = "${table.name}";就能在生成的 entity 文件里添加表名称这个常量。(仅作演示,mp 有提供entityColumnConstant 这个参数专门用于生成常量)
结语
MP 代码生成器的核心魅力,在于「原理简单且高度可扩展」------ 通过 JDBC 读元数据、数据建模标准化、模板引擎渲染、文件输出,四步完成重复代码生成。而自定义模板则进一步打破了 "通用代码" 的局限,让生成的代码直接贴合项目规范,真正实现 "一键生成,无需修改"。
除了 CRUD 代码生成,模板引擎技术的应用场景还有很多:比如生成接口文档、数据库脚本、配置文件等。掌握这种 "固定格式 + 动态数据" 的思想,能大幅减少重复开发工作,提升开发效率。
如果这篇文章对你理解 MP 代码生成器原理有帮助,麻烦点赞 + 关注支持一下~ 你的认可就是我持续输出源码解析系列的最大动力!❤️❤️❤️🤩🤩🤩🚀🚀🚀