 在现代大型语言模型(LLM)的宏伟殿堂中,从 PaLM、Llama 到 GPT-NeoX,一个共同的基石在支撑着它们对序列顺序的理解:旋转位置编码 (Rotary Position Embedding, RoPE) 。
在现代大型语言模型(LLM)的宏伟殿堂中,从 PaLM、Llama 到 GPT-NeoX,一个共同的基石在支撑着它们对序列顺序的理解:旋转位置编码 (Rotary Position Embedding, RoPE) 。
RoPE 不仅仅是另一种位置编码方案,它是一次优雅的数学推导的产物。它巧妙地以"绝对位置编码"的形式,实现了"相对位置编码"的特性,并顺便解决了传统位置编码与线性 Attention 之间的根本性冲突。
本文将深入探讨 RoPE 背后的数学原理、作者的思考出发点,以及它如何一步步从一个简洁的恒等式,演变为现代 LLM 的核心组件。
1. 问题的起点:我们到底想要什么?
Transformer 模型本身是置换不变 (Permutation-Invariant) 的,它无法感知序列的顺序。为了解决这个问题,我们需要注入位置信息。
-
原始 Transformer (APE): 使用固定的 sin/cos 绝对位置编码 (APE) ,将其添加 到词元嵌入中。这很管用,但模型必须"学会"如何从 PE(m) 和 PE(n) 的组合中推断出相对位置 (m−n)。
-
T5 (RPE): 使用相对位置编码 (RPE) ,直接在 N×N 的 Attention 矩阵上添加 一个偏置项 bias(m−n)。这更直接,但带来了新的问题:
- 外推性差: 在 2k 长度上训练的模型,无法推广到 4k。
- 与线性 Attention 不兼容: 线性 Attention ( O(N) ) 的核心就是避免 构建 N×N 矩阵。T5 的 RPE 必须操作这个矩阵,因此两者水火不容。
RoPE 的作者们另辟蹊径。他们提出了一个绝妙的"出发点":
我们能否设计一个操作 f,它作用于向量 q 和它的绝对位置 m,使得 q 和 k 在各自位置 m,n 上经过 f 操作后,它们的内积 ⟨f(q,m),f(k,n)⟩ 只取决于 q,k 和它们的相对位置 (m−n)?
用数学语言来描述这个目标,就是找到一个满足下列恒等式的解 f:
⟨f(q,m),f(k,n)⟩=g(q,k,m−n)
同时,为了让这个操作是一个"纯粹"的位置编码,我们希望它在 0 位置不改变原向量:
f(q,0)=q
2. 核心推导:
从复数到 2D 旋转 直接求解 d 维向量的 f 非常困难。作者巧妙地将问题简化:先在二维上求解 。 二维向量可以被看作复数 q∈C。 二维向量的点积 ⟨q,k⟩ 等价于 Reqk∗(其中 k∗ 是 k 的复共轭)。 我们的目标恒等式 f 变成了:
Ref(q,m)f∗(k,n)=g(q,k,m−n)
为了求解方便,我们假设一个更强的条件(后续只需取实部即可):
f(q,m)f∗(k,n)=gcomplex(q,k,m−n)
现在,我们将 f 和 g 都写成复数的指数形式:
- f(q,m)=Rf(q,m)eiΘf(q,m) ( Rf 是模, Θf 是相位)
代入上式,得到:
Rf(q,m)Rf(k,n)eiΘf(q,m)−Θf(k,n)=Rg(q,k,m−n)eiΘg(q,k,m−n)
这个复数等式必须模相等 且相位相等。
前置概念
在我们开始推导 f(q,m)f∗(k,n)=gcomplex(q,k,m−n) 之前,需要先理解三个关键的复数工具:
1. 复共轭 (Complex Conjugate)
-
定义: 记为 z∗。如果 z=a+bi,则 z∗=a−bi。
-
指数形式: 如果 z=ReiΘ( R 是模, Θ 是相位),那么 z∗=Re−iΘ。
-
核心作用: 将相位取反。
-
为何重要:
- 它是 RoPE 作者定义**复数内积(点积)**的基础: ⟨q,k⟩=Reqk∗。
- 它是我们推导 f∗(k,n) 的工具: (eiΘ)∗=e−iΘ。
2. 模方程 (Modulus Equation)
- 定义: 这不是一个正式术语,而是我们求解复数等式 Z1=Z2 时,通过令等式两边的模(幅度 R)相等,得到的第一个实数方程。
- 原理: Z1=Z2⟹∥Z1∥=∥Z2∥。
- 为何重要: 在我们的推导中,它将 f 函数的"幅度"信息 Rf 分离出来,帮助我们证明 f 必须是一个纯旋转操作(不改变向量长度)。
3. 相位方程 (Phase Equation)
- 定义: 类似地,这是求解 Z1=Z2 时,通过令等式两边的相位(角度 Θ)相等,得到的第二个实数方程。
- 原理: Z1=Z2⟹Angle(Z1)=Angle(Z2)。
- 为何重要: 它将 f 函数的"角度"信息 Θf 分离出来。我们对这个方程的求解( ϕ(m)=mθ),是 RoPE 旋转角度必须与位置 m 成线性关系的直接原因。
总结: 我们利用"复共轭"来构建初始的复数等式,然后使用"模方程"和"相位方程"这套方法,将这个复数等式拆解为两个独立的实数问题(一个关于长度,一个关于角度),从而分别求解。
我们就此得到了两个独立的实数方程:
(1) 模方程 (Magnitude Equation)
R_f(q,m)R_f(k,n)=R_g(q,k,m−n)
为了满足这个条件,最直接的解是 Rf(q,m) 必须与 m 无关 ,即 Rf(q,m)=Rf(q)。 应用初始条件 f(q,0)=q,我们得到 Rf(q,0)=∥q∥。 因此, Rf(q,m)=∥q∥。
结论 1: f 操作不改变向量的长度 。它是一个纯粹的旋转操作。
(2) 相位方程 (Phase Equation)
Θf(q,m)−Θf(k,n)=Θg(q,k,m−n)
这是一个经典的函数方程。我们通过"变量分离"来求解:
- 令 n=m,得到 Θf(q,m)−Θf(k,m)=Θg(q,k,0)。
- 这个 Θg(q,k,0) 与 m 无关,所以它等于 m=0 时的值: Θg(q,k,0)=Θf(q,0)−Θf(k,0)。
- 应用初始条件 f(q,0)=q,其相位 Θf(q,0) 就是 q 自己的幅角 Θ(q)。
- 因此: Θf(q,m)−Θf(k,m)=Θ(q)−Θ(k)。
- 移项: Θf(q,m)−Θ(q)=Θf(k,m)−Θ(k)。
- 这个等式左边只与 q,m 相关,右边只与 k,m 相关。要使其对任意 q,k 成立,两边都必须等于一个只与 m 相关的函数 ,记为 ϕ(m)。
- Θf(q,m)=Θ(q)+ϕ(m)。又因 Θf(q,0)=Θ(q),可知 ϕ(0)=0。
- 将 Θf(q,m)=Θ(q)+ϕ(m) 代回原始相位方程:
Θ(q)+ϕ(m)−Θ(k)+ϕ(n)=Θ_g(q,k,m−n)
Θ(q)−Θ(k)+ϕ(m)−ϕ(n)=Θg(q,k,m−n)
为使此式成立, ϕ(m)−ϕ(n) 必须是一个只关于 (m−n) 的函数。唯一的线性解是 ϕ(m) 是一个等差数列,即 ϕ(m)=mθ (公差为 θ )。
结论 2: f 操作将 q 的原始相位 Θ(q) 增加了 mθ。
(3) 最终解 综合模和相位:
f(q,m)=Rf(q,m)eiΘf(q,m)
f(q,m)=∣q∣ei(Θ(q)+mθ)
f(q,m)=(∣q∣eiΘ(q))⋅(eimθ)
f(q,m)=qeimθ
这个解极其简洁: f 操作就是将二维向量 q 旋转 mθ 角度。
我们来验证一下它是否满足我们的初衷:
=Reqeimθ⋅k∗e−inθ=Re(qk∗)ei(m−n)θ
这个结果只依赖于 q,k 和 (m−n)。推导成功!
3. 推广到 d 维:线性叠加的威力
我们已经成功找到了 2D(复数)情况下的解。那么,如何将其推广到 Transformer 使用的 d 维向量(例如 d=512)上呢?
关键就在于您提到的**"内积满足线性叠加性"**。
d 维向量 q 和 k 的内积 ⟨q,k⟩ 定义为:
⟨q,k⟩=∑j=0d−1qjkj
我们可以将这个 d 维向量**强行"切分"**成 d/2 组 2D 向量:
- q(0)=(q0,q1)
- q(1)=(q2,q3)
- ...
- q(i)=(q2i,q2i+1)
d 维内积 ⟨q,k⟩ 就可以被拆解为这些 2D 组的内积之和:
⟨q,k⟩=⟨q(0),k(0)⟩ (q0k0+q1k1)+⟨q(1),k(1)⟩ (q2k2+q3k3)+⋯+⟨q(d/2−1),k(d/2−1)⟩ (qd−2kd−2+qd−1kd−1)
⟨q,k⟩=∑i=0d/2−1⟨q(i),k(i)⟩
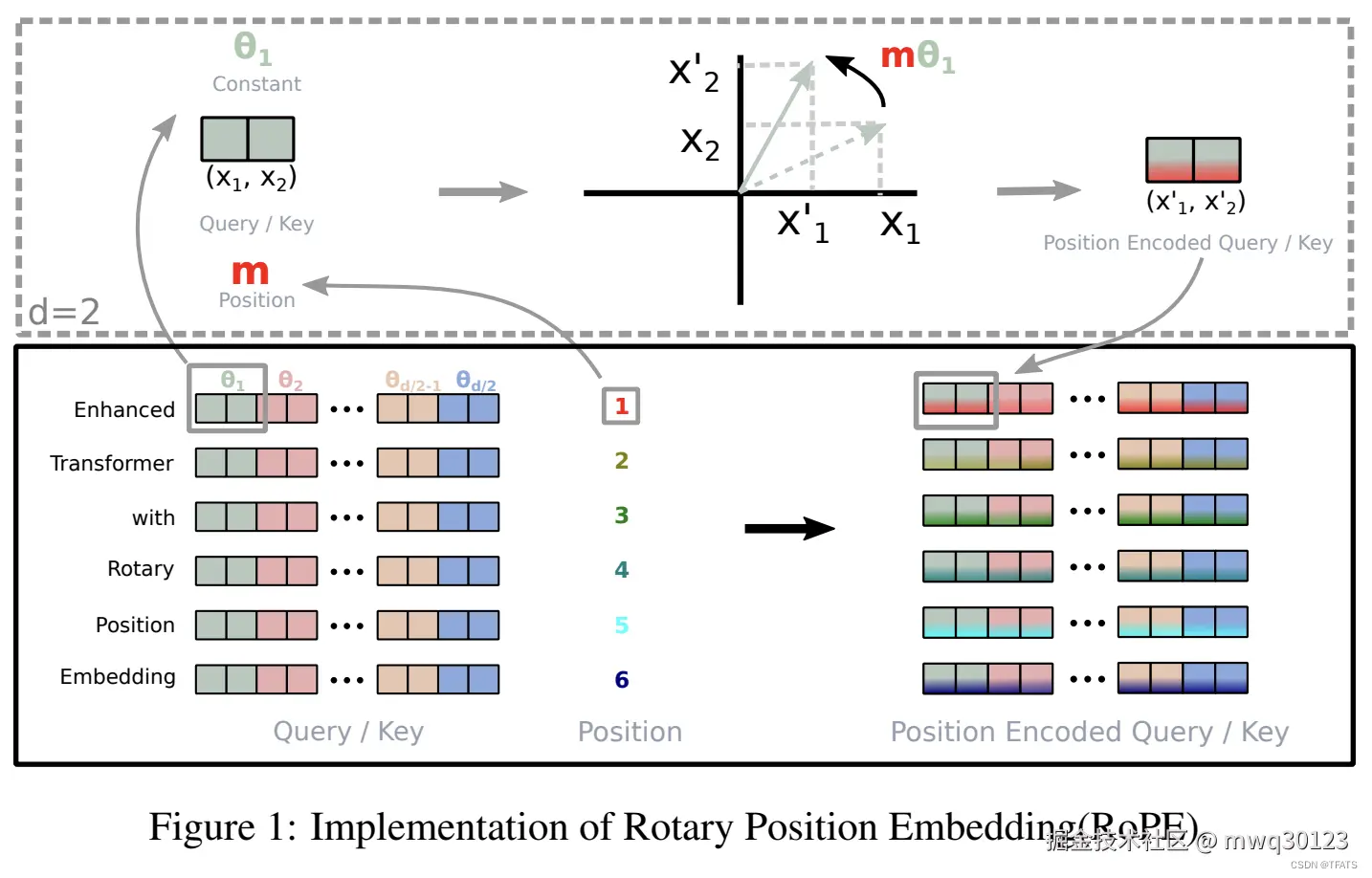
RoPE 的 d 维实现正是利用了这一点:我们不对 d 维向量 q 进行一次 d 维旋转,而是将其拆分 为 d/2 个 2D 向量,然后对每一组 2D 向量独立地应用我们推导出的 2D 旋转。
d 维的 RoPE 变换 f(q,m) 就是一个块对角矩阵 (Block Diagonal Matrix) Rm 与 q 相乘。矩阵的每个 2×2 的对角块,都是一个 2D 旋转矩阵,形式与您的(10)式一致(只是 θ 根据不同维度 i 而变化,记为 θi):
f(q,m)=Rmq= cosmθ0−sinmθ000⋮00sinmθ0cosmθ000⋮0000cosmθ1−sinmθ1⋮0000sinmθ1cosmθ1⋮00⋯⋯⋯⋯⋱⋯⋯0000⋮cosmθd/2−1−sinmθd/2−10000⋮sinmθd/2−1cosmθd/2−1 q0q1q2q3⋮qd−2qd−1
这个矩阵 Rm 在做什么?
- 它将 q0,q1 作为一个 2D 向量,并将其旋转 −mθ0 角度。
- 它将 q2,q3 作为一个 2D 向量,并将其旋转 −mθ1 角度。
- ...
- 它将 qd−2,qd−1 作为一个 2D 向量,并将其旋转 −mθd/2−1 角度。
(注:在实践中,不同组 i 使用不同的旋转频率 θi=10000−2i/d,这与原始 Transformer 的 sin/cos 编码的波长设计一致。 )
最终结论:
当我们计算 d 维的内积 ⟨f(q,m),f(k,n)⟩ 时,根据内积的线性叠加性:
⟨f(q,m),f(k,n)⟩=⟨Rmq,Rnk⟩=∑i=0d/2−1⟨(Rmq)(i),(Rnk)(i)⟩
右侧的每一项 ⟨⋅⟩i 都是 2D RoPE,它们都只依赖于 (m−n) 。因此,它们的总和 也必然只依赖于 (m−n)。
我们成功地将 2D 的解,通过"分而治之"和"线性叠加"的方式,推广到了任意 d 维。
4. RoPE 解决了什么核心问题?
RoPE 以其优雅的数学形式,一举解决了多个难题:
-
实现了"绝对操作,相对结果":
它通过 f(q,m)(绝对位置 m)和 f(k,n)(绝对位置 n)的独立操作,实现了 ⟨⋅,⋅⟩ 结果只依赖 (m−n) 的相对特性。
-
与线性 Attention 完美兼容(杀手级特性):
这是 RoPE 最大的工程胜利。传统 RPE (T5-bias) 需要操作 N×N 矩阵,无法用于线性 Attention。
RoPE 不操作 N×N 矩阵。它在 Attention 运算之前,分别"预处理" Q 和 K 矩阵( Q~=RmQ,K~=RnK)。
线性 Attention 的 O(N) 运算 Q~(K~TV) 可以照常进行,它甚至"不知道" Q~,K~ 已经被旋转过,但相对位置信息已经蕴含在内积中了。
-
良好的外推性(后续改进的基础):
由于 ⟨q~,k~⟩=Re(qk∗)ei(m−n)θ,随着相对距离 (m−n) 的增加,Attention 得分会自然地振荡和衰减。这提供了一种比 APE 更自然的"距离越远、关注越少"的归纳偏置。虽然它本身的外推并非完美,但它为后来的 NTK-Aware 和 YaRN 等改进方法提供了坚实的理论基础。
总结
RoPE 是那种在学术界和工业界都"大获全胜"的罕见技术。它从一个简单而深刻的数学恒等式出发,通过严谨的复数推导,最终得到了一个极其简洁的物理解释------旋转。这个简单的旋转操作,不仅统一了绝对位置和相对位置的优点,还解开了 RPE 与线性 Attention 之间的死结,为当今万亿参数模型的上下文扩展打开了大门。