1. LLM 训练基础概念
1.1 预训练(Pretrain)
LLM 首先要学习的并非直接与人交流,而是让网络参数中充满知识的墨水,"墨水" 理论上喝的越饱越好,产生大量的对世界的知识积累。 预训练就是让 Model 先埋头苦学大量基本的知识,例如从 Wiki 百科、新闻、书籍整理大规模的高质量训练数据。 这个过程是"无监督"的,即人类不需要在过程中做任何"有监督"的校正,而是由模型自己从大量文本中总结规律学习知识点。 模型此阶段目的只有一个:学会词语接龙。例如我们输入"秦始皇"四个字,它可以接龙"是中国的第一位皇帝"。
1.2 有监督微调(Supervised Fine-Tuning)
经过预训练,LLM 此时已经掌握了大量知识,然而此时它只会无脑地词语接龙,还不会与人聊天。
SFT 阶段就需要把半成品 LLM 施加一个自定义的聊天模板进行微调。例如模型遇到这样的模板【问题-> 回答,问题-> 回答】后不再无脑接龙,而是意识到这是一段完整的对话结束。 称这个过程为指令微调,就如同让已经学富五车的「牛顿」先生适应 21 世纪智能手机的聊天习惯,学习屏幕左侧是对方消息,右侧是本人消息这个规律。
1.3 人类反馈强化学习(Reinforcement Learning from Human Feedback, RLHF)
在预训练与有监督训练过程中,模型已经具备了基本的对话能力,但是这样的能力完全基于单词接龙,缺少正反样例的激励。 模型此时尚未知什么回答是好的,什么是差的。
希望模型能够更符合人的偏好,降低让人类不满意答案的产生概率。 这个过程就像是让模型参加新的培训,优秀员工作为正例,消极员工作为反例,学习如何更好地回复。可以使用 RLHF 系列之-直接偏好优化(Direct Preference Optimization, DPO)或与 PPO(Proximal Policy Optimization)。DPO 相比于 PPO:
- DPO 通过推导 PPO 奖励模型的显式解,把在线奖励模型换成离线数据,Ref 模型输出可以提前保存。
- DPO 性能几乎不变,只用跑 actor_model 和 ref_model 两个模型,大大节省显存开销和增加训练稳定性。
RLHF 训练步骤并非必须,此步骤难以提升模型"智力"而通常仅用于提升模型的"礼貌",有利(符合偏好、减少有害内容)也有弊(样本收集昂贵、反馈偏差、多样性损失)。
GRPO(Generalized Reinforcement Preference Optimization)是一种改进的强化学习方法,用于优化模型输出更符合人类偏好。它是对 PPO(Proximal Policy Optimization)+ RLAIF(Reinforcement Learning from AI Feedback)等方法的泛化和增强,本质上是对 RLHF(人类反馈强化学习)的一种高效实现。GRPO 的目标:从两个或多个候选输出中,优化模型朝更高偏好方向移动,而不是只学单个"正确答案"。
1.4 知识蒸馏(Knowledge Distillation, KD)
经过预训练、有监督训练、人类反馈强化学习,模型已经完全具备了基本能力,通常可以学成出师了。
知识蒸馏可以进一步优化模型的性能和效率,所谓知识蒸馏,即学生模型面向教师模型学习。 教师模型通常是经过充分训练的大模型,具有较高的准确性和泛化能力。 学生模型是一个较小的模型,目标是学习教师模型的行为,而不是直接从原始数据中学习。
在 SFT 学习中,模型的目标是拟合词 Token 分类硬标签(hard labels),即真实的类别标签(如 0 或 100)。 在知识蒸馏中,教师模型的 softmax 概率分布被用作软标签(soft labels)。小模型仅学习软标签,并使用 KL-Loss 来优化模型的参数。
通俗地说,SFT 直接学习老师给的解题答案。而 KD 过程相当于"打开"老师聪明的大脑,尽可能地模仿老师"大脑"思考问题的神经元状态。知识蒸馏的目的只有一个:让小模型体积更小的同时效果更好。 然而随着 LLM 诞生和发展,模型蒸馏一词被广泛滥用,从而产生了"白盒/黑盒"知识蒸馏两个派别。 GPT-4 这种闭源模型,由于无法获取其内部结构,因此只能面向它所输出的数据学习,这个过程称之为黑盒蒸馏,也是大模型时代最普遍的做法。黑盒蒸馏与 SFT 过程完全一致,只不过数据是从大模型的输出收集。
1.5 LoRA (Low-Rank Adaptation)
LoRA 是一种高效的参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)方法,旨在通过低秩分解的方式对预训练模型进行微调。 相比于全参数微调(Full Fine-Tuning),LoRA 只需要更新少量的参数。 LoRA 的核心思想是:在模型的权重矩阵中引入低秩分解,仅对低秩部分进行更新,而保持原始预训练权重不变。
2. LLM 训练流程简介
训练任何模型,需要清楚两个问题:
- 明确模型的输入与输出
- 定义模型的损失函数
LLM,即大语言模型,本质上是一个"token 接龙"高手,它不断预测下一个词符。这种推理生成方式被称为自回归模型,因为模型的输出会作为下一轮的输入,形成一个循环。
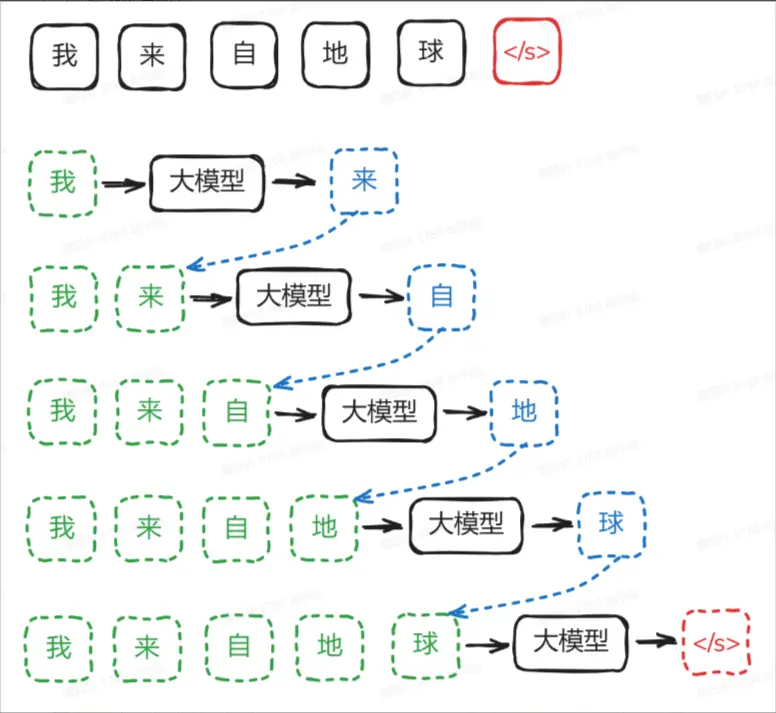
刚开始,一个随机大模型,面对输入,它预测的下一个字符完全是随机的
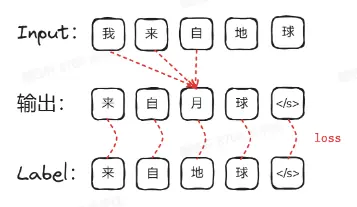
那么,它是如何学习的呢?在自注意力机制中,通过为 qk 增加掩码,softmax 后将负无穷对应到 0,隐藏掉 n 字符以后的内容。这样,输出的第 n+1 个字符只能关注到前 n 个字符,如同戴上了一副"只看过去"的眼镜。
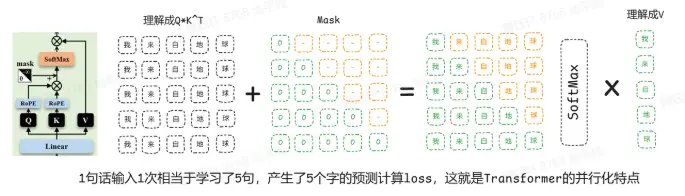
通过训练,大模型从一个随机混沌的状态,逐渐学会输入与下一个词符之间的潜在联系。
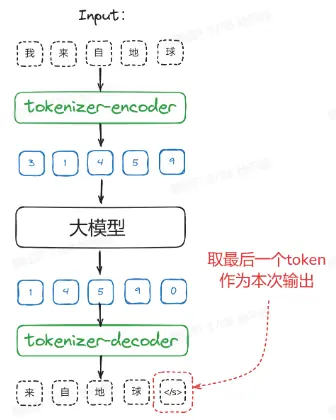
以上是为了便于理解而抽象出来的过程。
大模型的输入是由数字组成的张量,而非自然语言字符。自然语言通过 tokenizer(可以理解为一种词典)映射到词典的页码数字 ID,进行输入计算。得到的输出数字再利用词典进行解码,重新得到自然语言。
大模型的输出是一个 N*len(tokenizer)的多分类概率张量,在 Topk 中选出的有概率的 token,得到下一个词。
损失函数:交叉熵损失
学习率:与 batchsize 成倍数关系,batchsize 变大一倍,学习率也增大一倍