0. 前言
在上一篇的文章《源码运行RagFlow并实现AI搜索(文搜文档、文搜图、视频理解)与自定义智能体(一)》中,我们已经了解了如何源码运行RAGFlow,并也通过内置的DeepDoc和接入MinerU的方式对PDF文档进行了解析与搜索。本文中将接着前文,一起感受下RAGFlow的多模态搜索功能。
1. 图/视频理解
当我们运行好RAGFlow,并配置对应的视觉模型后,我们便可以对视频/图片进行解析了。
我这里配置的VLM模型为阿里的qwen3-vl-plus。
之后我们选择在对应的数据集中,上传对应的图片和视频,点击解析就可以看一下效果了。
1.1 图片解析
在数据集中对图片点击解析,其对应的Parse为picture。之后待解析完毕后,查看解析结果:
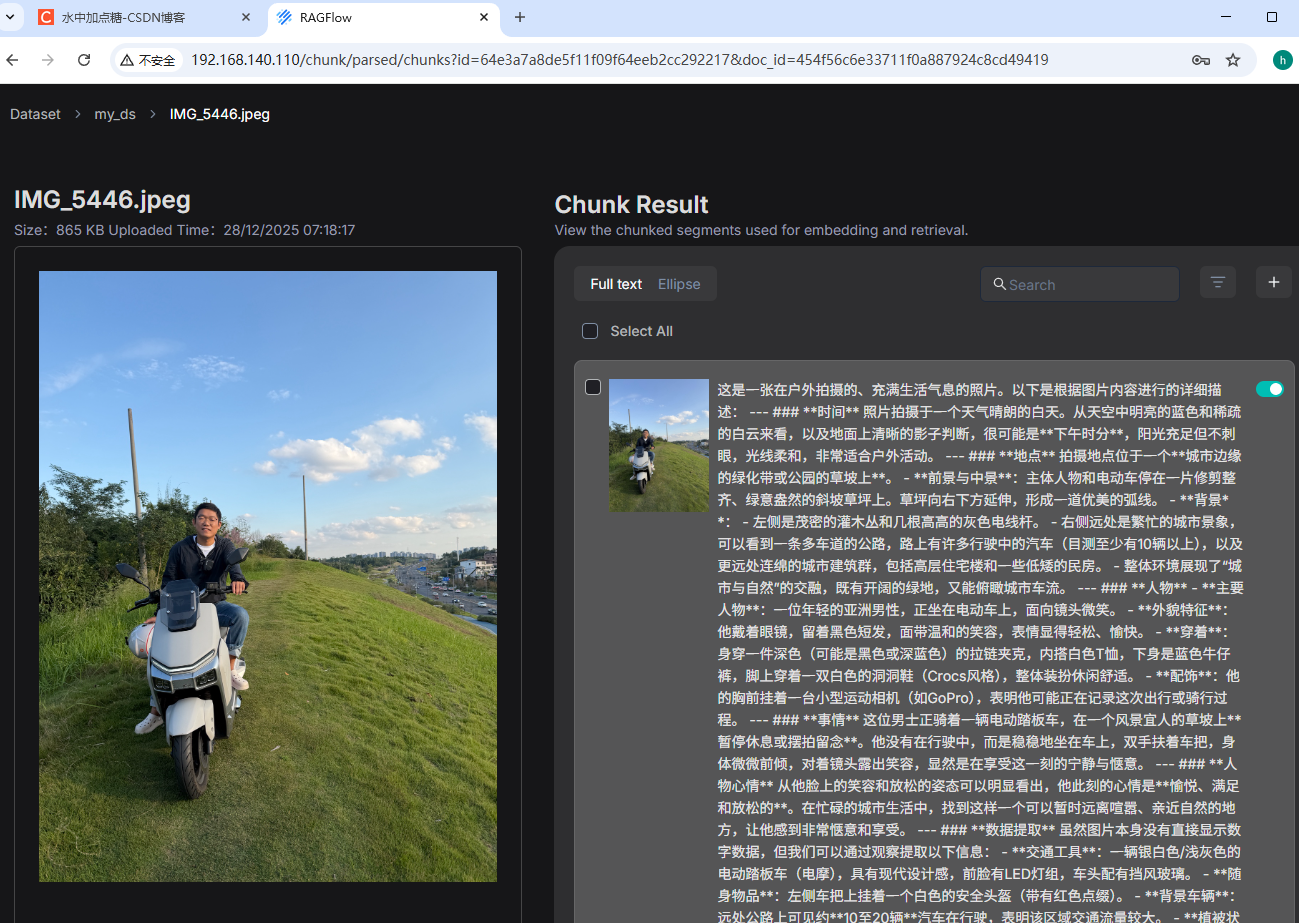
会将此图片的整体内容都描述在右边,并存为了一个Chunk。
1.2 视频解析
以视频链接:《跨市通勤近100公里,骑车下班的一天》
为例,使用yt-dlp工具将此视频下载到本地,之后再上传到RAGFlow( .\yt-dlp.exe -f "30064+30280" https://www.bilibili.com/video/BV1g2q1BuEP1),解析后的效果如下:
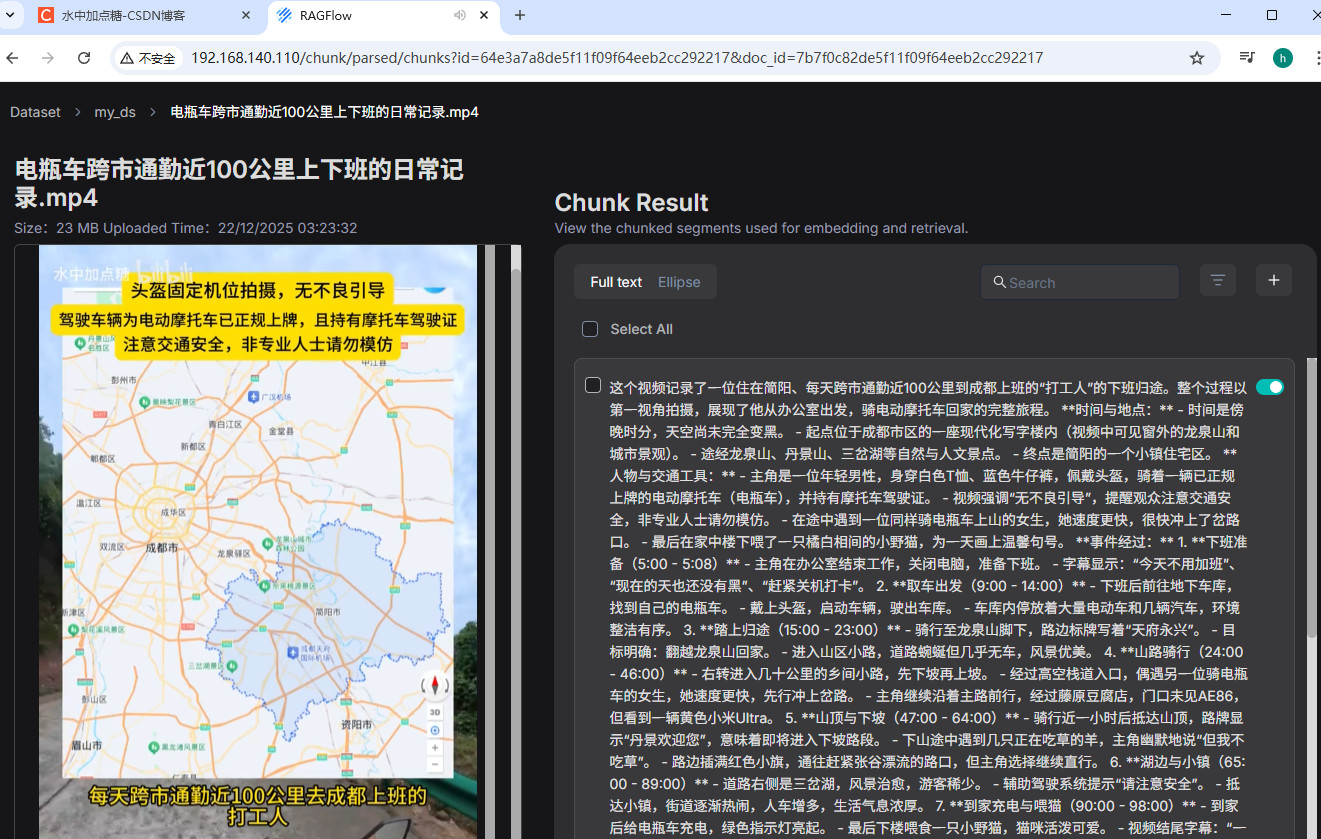
解析成功,与图片解析类似的,RAGFlow也将视频中的内容保存了一个Chunk。
此处图片和视频 的识别时的提示词 可见源码:rag/llm/cv_model.py
2. 文搜图/视频
在我们把图片和视频转换为了文本(Chunk)后,我们就可以对它进行搜索了。
2.1 关键字搜索(文本匹配)
选择RAGFlow中的Search,在其中创建一个search app ,并选择对应的数据集。
还是在上面的已有数据集的基础上,我们输入:电动车 ,进行搜索,结果如下:
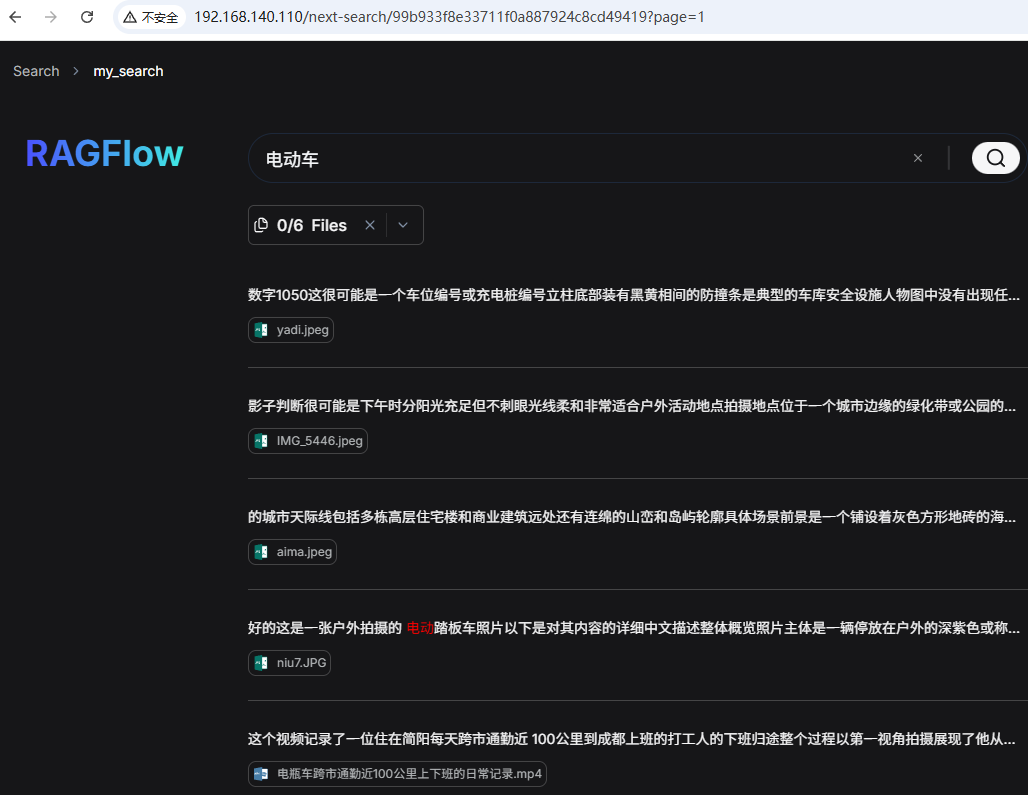
结果返回的文档有图片 也有视频。
查看调用的http接口时的完整curl命令为:
curl 'http://192.168.140.110/v1/chunk/retrieval_test' \
-H 'Accept: application/json' \
-H 'Accept-Language: zh-CN,zh;q=0.9' \
-H 'Authorization: ImU2ZDkzYzE2ZTNkNTExZjA4Y2UzMWE2ZWI3ZTRmNWMzIg.aVEC3A.4F60mVL5yHnMhe299t3hpSJfOco' \
-H 'Cache-Control: no-cache' \
-H 'Connection: keep-alive' \
-H 'Content-Type: application/json;charset=UTF-8' \
-b 'session=.eJwdyzsSgCAMBcC7pLYgBsLnMozAY7RFqRzvrmO5xd6U54mRj0aJIntWE02DFOZuwladrlqtBXOIgRbKfeDcKV1j4tPfoC1aWQOkub9VCG-K4mG7q0LPC9pVHPY.aVEC3A.1H0DCtXxI0BW6eh-mks8SN8bU2A' \
-H 'Origin: http://192.168.140.110' \
-H 'Pragma: no-cache' \
-H 'Referer: http://192.168.140.110/next-search/99b933f8e33711f0a887924c8cd49419?page=1' \
-H 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36' \
--data-raw '{"kb_id":["64e3a7a8de5f11f09f64eeb2cc292217"],"highlight":true,"question":"电动车","page":1,"size":50,"search_id":"99b933f8e33711f0a887924c8cd49419","tenant_id":null}' \
--insecure这其中的关键参数有:
- kb_id,知识库id
- question,被搜索的关键字
- search_id,search_app对应的id
2.2 关键字搜索源码分析
查看此接口调用的主要源码,位于chunk_app.py 下的retrieval_test接口:
python
@manager.route('/retrieval_test', methods=['POST']) # noqa: F821
@login_required
@validate_request("kb_id", "question")
async def retrieval_test():
# ......
# 获取出请求参数。question为搜索的关键字;kb_id为知识库id列表;
question = req["question"]
kb_ids = req["kb_id"]
# ......
top = int(req.get("top_k", 1024))
tenant_ids = []
if req.get("search_id", ""):
# 根据search_id获取出对应的search_config配置
search_config = SearchService.get_detail(req.get("search_id", "")).get("search_config", {})
# ......
try:
# ......
e, kb = KnowledgebaseService.get_by_id(kb_ids[0])
# ......
# 获取出被检索知识库对应的向量模型
embd_mdl = LLMBundle(kb.tenant_id, LLMType.EMBEDDING.value, llm_name=kb.embd_id)
# ......
# 调用retrieval进行检索,ranks为检索结果
ranks = settings.retriever.retrieval(question, embd_mdl, tenant_ids, kb_ids, page, size,
float(req.get("similarity_threshold", 0.0)),
float(req.get("vector_similarity_weight", 0.3)),
top,
doc_ids, rerank_mdl=rerank_mdl,
highlight=req.get("highlight", False),
rank_feature=labels
)
# ......
return get_json_result(data=ranks)
except Exception as e:
if str(e).find("not_found") > 0:
return get_json_result(data=False, message='No chunk found! Check the chunk status please!',
code=RetCode.DATA_ERROR)
return server_error_response(e)上面的代码简化之后看着还是很简单,但它其实只是冰山一角。
它最终会执行到search.py 中的retrieval 方法。从它的包名rag.nlp.search来看就知道它不简单。其主要代码为:
python
def retrieval(self, question, embd_mdl, tenant_ids, kb_ids, page, page_size, similarity_threshold=0.2,
vector_similarity_weight=0.3, top=1024, doc_ids=None, aggs=True,
rerank_mdl=None, highlight=False,
rank_feature: dict | None = {PAGERANK_FLD: 10}):
ranks = {"total": 0, "chunks": [], "doc_aggs": {}}
# ......
# Ensure RERANK_LIMIT is multiple of page_size
RERANK_LIMIT = math.ceil(64/page_size) * page_size if page_size>1 else 1
req = {"kb_ids": kb_ids, "doc_ids": doc_ids, "page": math.ceil(page_size*page/RERANK_LIMIT), "size": RERANK_LIMIT,
"question": question, "vector": True, "topk": top,
"similarity": similarity_threshold,
"available_int": 1}
# ......
sres = self.search(req, [index_name(tid) for tid in tenant_ids],
kb_ids, embd_mdl, highlight, rank_feature=rank_feature)
if rerank_mdl and sres.total > 0:
# 启用rerank模型时的调用
sim, tsim, vsim = self.rerank_by_model(rerank_mdl,
sres, question, 1 - vector_similarity_weight,
vector_similarity_weight,
rank_feature=rank_feature)
else:
lower_case_doc_engine = os.getenv('DOC_ENGINE', 'elasticsearch')
if lower_case_doc_engine in ["elasticsearch","opensearch"]:
# ElasticSearch doesn't normalize each way score before fusion.
sim, tsim, vsim = self.rerank(
sres, question, 1 - vector_similarity_weight, vector_similarity_weight,
rank_feature=rank_feature)
else:
# ......
# ......
return ranks从上可知,它主要调用了以下两个重要方法:
- search,搜索;拿着问题question,使用配置的向量模型embd_mdl,去知识库集合kb_ids中检索
- rerank,重排序;对search到的结果sres,带着问题question和向量相似度权重vector_similarity_weight对sres进行重排序
先看search方法,主要代码为:
python
def search(self, req, idx_names: str | list[str],
kb_ids: list[str],
emb_mdl=None,
highlight: bool | list | None = None,
rank_feature: dict | None = None
):
if highlight is None:
highlight = False
# 生成过滤语句
filters = self.get_filters(req)
orderBy = OrderByExpr()
# ......
kwds = set([])
qst = req.get("question", "")
q_vec = []
if not qst:
# ......
else:
highlightFields = ["content_ltks", "title_tks"]
if not highlight:
highlightFields = []
elif isinstance(highlight, list):
highlightFields = highlight
# 分词处理,以'电动车'为例,matchText='((电动车 OR "电动" OR ("电动"~2)^0.5)^1.0)';keyword=['电动车', '电动车', '电动']
matchText, keywords = self.qryr.question(qst, min_match=0.3)
if emb_mdl is None:
# ......
else:
# 对输入的question进行向量化处理,返回的是match语句(question对应的向量,以及相似度语句)
matchDense = self.get_vector(qst, emb_mdl, topk, req.get("similarity", 0.1))
# question对应的向量
q_vec = matchDense.embedding_data
src.append(f"q_{len(q_vec)}_vec")
fusionExpr = FusionExpr("weighted_sum", topk, {"weights": "0.05,0.95"})
matchExprs = [matchText, matchDense, fusionExpr]
# 默认的dataStore为elasticSearch(es_conn.py),调用dataStore对应的search进行搜索
res = self.dataStore.search(src, highlightFields, filters, matchExprs, orderBy, offset, limit,
idx_names, kb_ids, rank_feature=rank_feature)
total = self.dataStore.get_total(res)
logging.debug("Dealer.search TOTAL: {}".format(total))
# If result is empty, try again with lower min_match
if total == 0:
# 首次搜索未命中,去掉matchExprs再次搜索
# ......
for k in keywords:
# ......关键字处理,用于后面的高亮处理
logging.debug(f"TOTAL: {total}")
# 检索结果中包含的知识库id列表
ids = self.dataStore.get_chunk_ids(res)
keywords = list(kwds)
# 高亮文本
highlight = self.dataStore.get_highlight(res, keywords, "content_with_weight")
aggs = self.dataStore.get_aggregation(res, "docnm_kwd")
# 返回结果
return self.SearchResult(
total=total,
ids=ids,
query_vector=q_vec,
aggregation=aggs,
highlight=highlight,
field=self.dataStore.get_fields(res, src + ["_score"]),
keywords=keywords
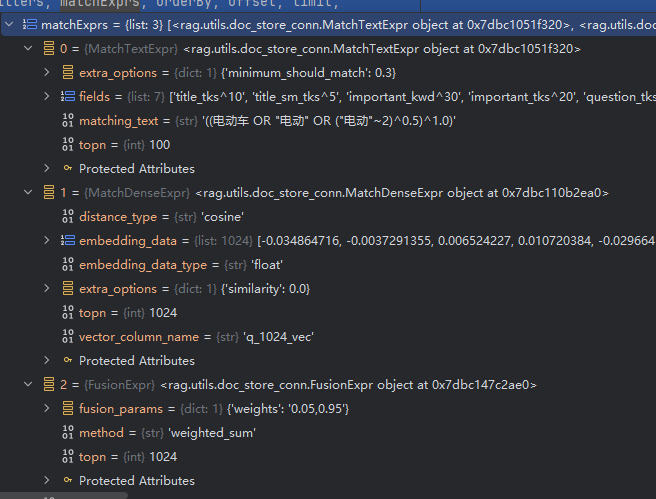
)tips:在代码阅读过程中可使用debug方式 运行程序,以加强理解。如'电动车'运行过程中的matchExprs 语句的值为:
再看下rerank方法的主要代码:
python
def rerank(self, sres, query, tkweight=0.3,
vtweight=0.7, cfield="content_ltks",
rank_feature: dict | None = None
):
# 这里的qryr是FulltextQueryer,将query分词得到keywords。'电动车'的keywords=['电动车', '电动车', '电动']
_, keywords = self.qryr.question(query)
# 获取到向量维度
vector_size = len(sres.query_vector)
vector_column = f"q_{vector_size}_vec"
# 向量维度初始化,默认全为0
zero_vector = [0.0] * vector_size
ins_embd = []
# 获取出每个chunk的向量值
for chunk_id in sres.ids:
vector = sres.field[chunk_id].get(vector_column, zero_vector)
if isinstance(vector, str):
vector = [get_float(v) for v in vector.split("\t")]
ins_embd.append(vector)
if not ins_embd:
return [], [], []
# list格式处理
for i in sres.ids:
if isinstance(sres.field[i].get("important_kwd", []), str):
sres.field[i]["important_kwd"] = [sres.field[i]["important_kwd"]]
# 构造ins_tw,用于文本相似度的token
ins_tw = []
for i in sres.ids:
# 正文token去重
content_ltks = list(OrderedDict.fromkeys(sres.field[i][cfield].split()))
# 标题token
title_tks = [t for t in sres.field[i].get("title_tks", "").split() if t]
# 问题字段token
question_tks = [t for t in sres.field[i].get("question_tks", "").split() if t]
# 关键词token
important_kwd = sres.field[i].get("important_kwd", [])
# 字段加权拼token
tks = content_ltks + title_tks * 2 + important_kwd * 5 + question_tks * 6
ins_tw.append(tks)
## For rank feature(tag_fea) scores.
rank_fea = self._rank_feature_scores(rank_feature, sres)
# 使用hybrid_similarity混合相似器计算相似度
sim, tksim, vtsim = self.qryr.hybrid_similarity(sres.query_vector,
ins_embd,
keywords,
ins_tw, tkweight, vtweight)
# 混合相似度+tag相似度;tksim为文本关键字相似度;vtsim为向量相似量
return sim + rank_fea, tksim, vtsim
def hybrid_similarity(self, avec, bvecs, atks, btkss, tkweight=0.3, vtweight=0.7):
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
# 计算query_vector与chunk的余弦相似度;avec=query的向量,bvecs=chunk的向量列表
sims = cosine_similarity([avec], bvecs)
# 计算文本相似度;atks=query关键词,btkss=每个文档的加权拼接token列表
tksim = self.token_similarity(atks, btkss)
if np.sum(sims[0]) == 0:
return np.array(tksim), tksim, sims[0]
# 根据tkweight=相似度权重,vtweight=向量相似度权重,计算最终的混合权重值
return np.array(sims[0]) * vtweight + np.array(tksim) * tkweight, tksim, sims[0]这其中的难点在于token_similarity 方法的实现,这里不再展开,有兴趣都可搜索以下关键字后再阅读源码:TF-IDF 、BM25 、SPLADE 、SBERT。
2.3 相似度搜索(向量)
在RagFlow的搜索应用 中有以下设置界面:
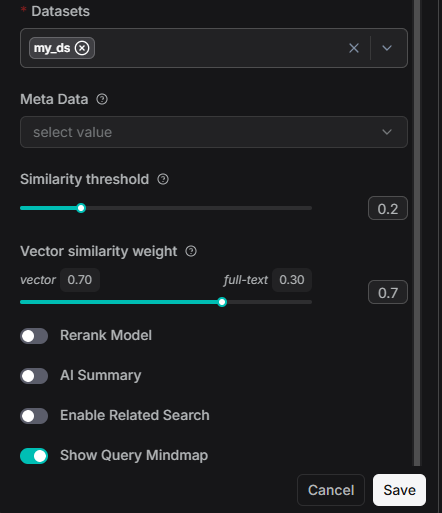
- similarity_threshold,相似度阈值
RAGFlow employs either a combination of weighted keyword similarity and weighted vector cosine similarity, or a combination of weighted keyword similarity and weighted reranking score during retrieval. This parameter sets the threshold for similarities between the user query and chunks. Any chunk with a similarity score below this threshold will be excluded from the results. By default, the threshold is set to 0.2. This means that only chunks with hybrid similarity score of 20 or higher will be retrieved.
- vector_similarity_weight,向量相似权重
This sets the weight of keyword similarity in the combined similarity score, either used with vector cosine similarity or with reranking score. The total of the two weights must equal 1.0.
在有了上面的源码解读后,我们对以上两个关键字也会有新的理解。以下为我的理解:
- similarity_threshold是混合相似度的阈值,低于此值的搜索结果会被丢弃
- vector_similarity_weight决定了返回结果的排序,也就是文本相似度 与向量相似度对应值结果的排序顺位
接下来再让vector_similarity_weight 的值分别为0.1和0.9时,看一下搜索相同内容的效果。
所使用到的测试数据为《数据集成框架SeaTunnel-Transform体验------LLM和Embedding》中的测试数据,csv数据如下:
csv
id,name
0,香蕉
1,苹果
2,葡萄
3,凤梨
4,蓝莓
5,杜蕾斯
6,冈本
7,第六感
8,杰士邦
9,赤尾
10,梦龙
11,哈根达斯
12,八喜
13,巧乐兹
14,可爱多
15,海底捞
16,乡村基
17,肯德基
18,西贝
19,大米先生1. vector_similarity_weight=0.1时
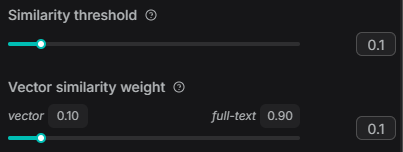
输入:'香蕉',返回了'香蕉':
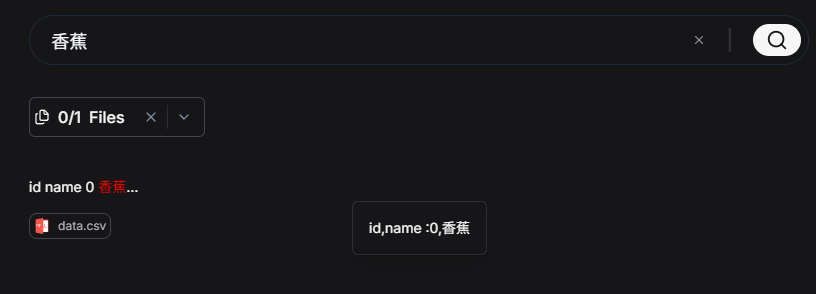
输入:'水果',无返回
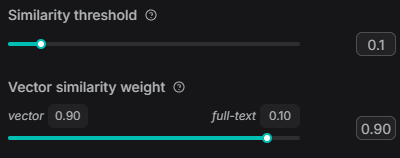
2. vector_similarity_weight=0.9时,输入:水果 :
理想情况,当输入'水果'时,根据相似度应该返回数据集中与水果相关的所有数据,但上面并没有返回。于是将向量相似度权重尝试加大,但依旧无数据返回:
查阅了RAGFlow中对于默认向量存储KNN搜索的实现代码,并结合es官方KNN搜索文档(https://www.elastic.co/docs/solutions/search/vector/knn),发现在当前的0.22.1版本中存在BUG导致的。
python
elif isinstance(m, MatchDenseExpr):
assert (bqry is not None)
similarity = 0.0
if "similarity" in m.extra_options:
similarity = m.extra_options["similarity"]
s = s.knn(m.vector_column_name,
m.topn,
m.topn * 2,
query_vector=list(m.embedding_data),
filter=bqry.to_dict(),
similarity=similarity,
)这行代码有点问题:similarity=similarity,这里的similarity不应为数字。以搜索'电动车'为例,其输出的es查询命令如下:
Bool(
boost = 0.050000000000000044,
filter = [
Terms(
kb_id = ['64e3a7a8de5f11f09f64eeb2cc292217']
),
Bool(
must_not = [
Range(
available_int = {
'lt': 1
}
)
]
)
],
must = [
QueryString(
boost = 1,
type = 'best_fields',
query = '((电动车 OR "电动" OR ("电动"~2)^0.5)^1.0)',
minimum_should_match = '30%',
fields = [
'title_tks^10',
'title_sm_tks^5',
'important_kwd^30',
'important_tks^20',
'question_tks^20',
'content_ltks^2',
'content_sm_ltks'
]
)
]
)在本文中,由于bug原因,向量相似度搜索功能的示例暂且跳过。
3. 图搜图/视频
在RAGFlow自带的搜索功能中,目前(0.22.1)只支持使用文本 进行搜索,通过文本作为关键字也能搜索出相关的文档、视频、图片等信息,但它的匹配过程依旧使用的是关键字的匹配,在多模态的场景中存在一定的局限性。
但在最近的几个月中,多模态大模型的发展速度是快的惊人 ,以智谱的GLM-4.6V多模态模型为例测试一下。
这里以我的上下班通勤视频(跨市通勤近100公里,骑车下班的一天.mp4)为例,测试以下问题:视频中出现了一辆小米汽车,它的颜色是什么?
回答截图为:
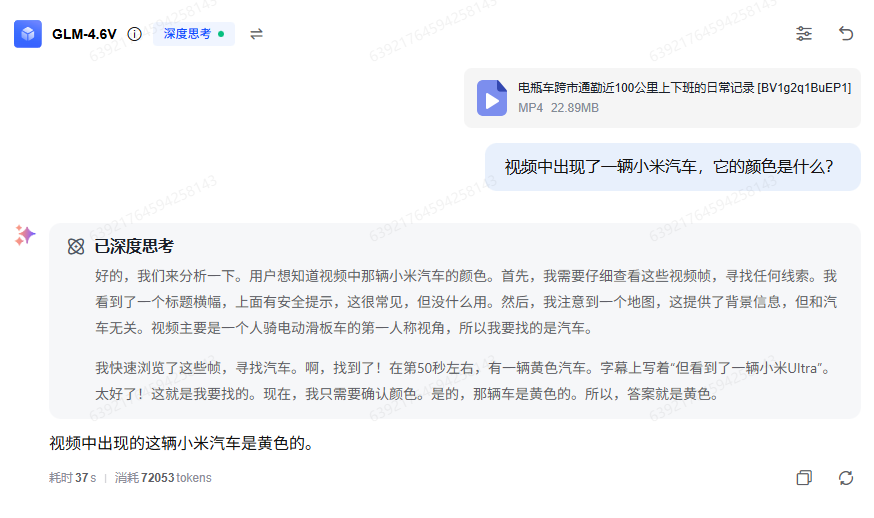
其中有以下关键信息:
- 小米汽车是黄色的
- 在第50秒左右
打开视频的第50秒看一下:

确实为一辆黄色的小米汽车。
再次询问:视频中经过了一座湖,它是什么湖,并且经过它时有一辆汽车,那辆汽车是什么颜色的?
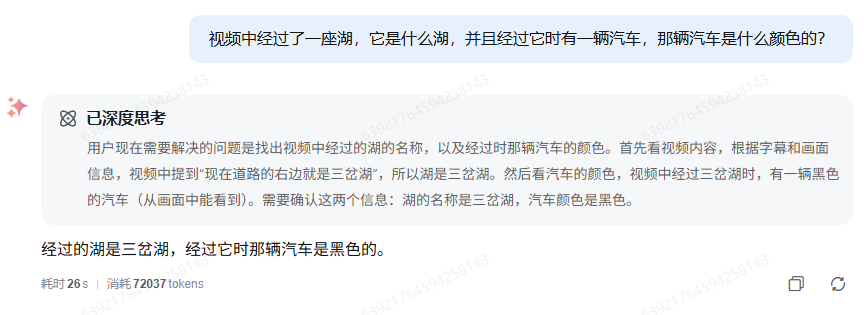
回答为:经过的湖是三岔湖,经过它时那辆汽车是黑色的。
再打开视频确认一下:

非常完美。
不过,上面的功能在RAGFlow的目前版本(0.23.1)中并不支持,如果需要实现图搜图/视频 等多模态的搜索,我们需要对源码进行改造,这部分可参考KnowFlow项目作者的这篇文章:《适配 RAGFlow......多模态视频解析》,其主要通过视频抽帧的方式实现。
实现时的相关搜索关键字:CLIP、视频抽帧、Whisper、ASR、多模态模型。
除此之外,我们也可以使用RAGFlow中的智能体编排实现多模态搜索的功能,具体实现步骤见我的后续文章。