前言
本章学习Kafka的事务消息原理:
1)普通事务消息;
2)精确一次语义的事务消息;
注:本章基于Kafka2.6,无KRaft。
一、引入
1-1、使用案例
配置transactional.id事务id,同一时刻全局唯一。
Producer创建后需要执行一次initTransactions完成初始化工作。
java
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, IntegerSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put("transaction.timeout.ms", 60000);
// flink transactionalIdPrefix + "-" + subtaskId + "-" + checkpoint-id
props.put("transactional.id", "kafkaSink-0-5");
props.put("enable.idempotence", true);
try (KafkaProducer<Integer, String> producer = new KafkaProducer<>(props)) {
// 初始化FindCoordinatorRequest&InitProducerIdRequest
producer.initTransactions();
// 执行5个事务
for (int i = 0; i < 5; i++) {
sendTx(producer);
}
}
}Producer发送消息:
1)beginTransaction:纯内存状态变更,没有远程调用;
2)send:发送n条消息,可能涉及多个分区;
3)commitTransaction/abortTransaction:提交或回滚事务;
java
private static void sendTx(KafkaProducer<Integer, String> producer) {
// 执行一次事务
try {
// State=READY->IN_TRANSACTION
producer.beginTransaction();
for (int i = 0; i < 3; i++) {
// 如果发送到新分区,将新分区加入事务 AddPartitionsToTxnRequest
// i%2---指定发送分区0或1
ProducerRecord<Integer, String> record =
new ProducerRecord<>(TOPIC, i % 2, i, "hello");
Thread.sleep(1000L);
}
// 累积器满足条件,sender线程可能已经发送ProduceRequest...
// 提交事务EndTxnRequest
producer.commitTransaction();
} catch (ProducerFencedException | InterruptException | TimeoutException e) {
throw new RuntimeException(e);
} catch (KafkaException e) {
// 回滚事务EndTxnRequest
producer.abortTransaction();
}
}1-2、流程概览
initTransactions初始化:

1)生产者→配置中的任意Broker:Metadata,获取所有broker节点信息用于建立连接;
2)生产者→最小负载Broker:FindCoordinator,获取事务协调者(和消费组协调者类似,一个transactional.id对应集群里的某个broker);
3)生产者→协调者:InitProducerId,使用transactionId注册事务生产者,获取producerId和producerEpoch;
事务:

1)生产者→最小负载Broker:Metadata,如果发送消息遇到没有元数据的topic,需要先获取topic元数据,得到分区信息,知道分区对应leaderBroker才能发送消息;
2)生产者→协调者:AddPartitionsToTxn * M,M=本轮事务中涉及的topic分区数量,如果发送消息遇到本轮事务中的新分区,需要将分区加入到事务中,后面协调者才能在提交或回滚时调用对应leaderBroker;
3)生产者→Broker1:Produce * X,X=消息批次数量;
4)生产者→Broker2:Produce * Y,Y=消息批次数量;
5)生产者→协调者:EndTxn * 1,告知事务提交或回滚;
6)协调者→Broker1:WriteTxnMarkers * 1,标记本轮事务提交或回滚;
7)协调者→Broker2:WriteTxnMarkers * 1;
1-3、配置说明
在客户端侧有几个关联配置,相关逻辑见ProducerConfig#postProcessParsedConfig:
1)transactional.id :事务id,必须配置,同一时刻全局唯一,如果协调者发现冲突,则会返回ProducerFencedException异常,代表有另一个相同的事务生产者正在运行;
2)enable.idempotence :是否开启幂等,当配置transactional.id后,默认且强制为true;
3)acks :ack策略,当配置transactional.id后,默认且强制为-1,需要ISR都写入成功才响应客户端;
客户端其他配置:
1)transaction.timeout.ms:默认60s,超时事务协调者会自动回滚事务;
1-4、事务生产者概览
KafkaProducer#configureTransactionState:事务生产者在KafkaProducer中会构建一个TransactionManager用于管理事务。
如果未开启事务,仅开启幂等,也会构造TransactionManager。
java
private TransactionManager configureTransactionState(ProducerConfig config,
LogContext logContext) {
TransactionManager transactionManager = null;
if (config.idempotenceEnabled()) {
// 只要开启幂等,就有TransactionManager
transactionManager = new TransactionManager(
logContext,
transactionalId,
transactionTimeoutMs,
retryBackoffMs,
apiVersions,
autoDowngradeTxnCommit);
if (transactionManager.isTransactional())
log.info("Instantiated a transactional producer.");
else
log.info("Instantiated an idempotent producer.");
}
return transactionManager;
}
// TransactionManager#isTransactional
public boolean isTransactional() {
return transactionalId != null;
}TransactionManager包含以下关键属性:
java
public class TransactionManager {
// 事务id(transactional.id)
private final String transactionalId;
// 事务超时时间
private final int transactionTimeoutMs;
// 管理分区当前发送序号
private final TopicPartitionBookkeeper topicPartitionBookkeeper;
// 分区 - 提交offset(暂时忽略,精确一次)
private final Map<TopicPartition, CommittedOffset> pendingTxnOffsetCommits;
// 待发送的事务相关请求
private final PriorityQueue<TxnRequestHandler> pendingRequests;
// 事务中 Producer发送消息新包含的分区 待发送AddPartition
private final Set<TopicPartition> newPartitionsInTransaction;
// 发送AddPartition还未收到响应的分区
private final Set<TopicPartition> pendingPartitionsInTransaction;
// 完成AddPartition加入事务的分区
private final Set<TopicPartition> partitionsInTransaction;
private TransactionalRequestResult pendingResult;
// 事务协调者Broker节点
private Node transactionCoordinator;
// 消费组协调者Broker节点(暂时忽略,精确一次)
private Node consumerGroupCoordinator;
// 状态
private volatile State currentState = State.UNINITIALIZED;
// 上次异常
private volatile RuntimeException lastError = null;
// producerId和producerEpoch
private volatile ProducerIdAndEpoch producerIdAndEpoch;
// 是否开始事务
private volatile boolean transactionStarted = false;
// 是否需要升级producerEpoch
private volatile boolean epochBumpRequired = false;
private static class TopicPartitionBookkeeper {
private final Map<TopicPartition, TopicPartitionEntry>
topicPartitions = new HashMap<>();
}
private static class TopicPartitionEntry {
// 下一个分配的序号
private int nextSequence;
// 已发送消息的最后一个序号
private int lastAckedSequence;
// 已发送批次,还未收到响应
private SortedSet<ProducerBatch> inflightBatchesBySequence;
// 已发送消息的最后一个offset
private long lastAckedOffset;
}
}回顾Kafka生产者有两类线程:1)用户线程,调用KafkaProducer的api;2)Sender线程,与broker通讯。用户线程将消息放入消息累积器行成消息批次,Sender线程从累积器中获取消息批次发送给多个Broker。
Sender#runOnce:Sender线程无限循环逻辑。
java
void runOnce() {
if (transactionManager != null) {
// 事务生产者特殊处理....
if (maybeSendAndPollTransactionalRequest()) {
// 如果有事务相关请求发送,本轮不会发送ProduceRequest
return;
}
}
// 非事务生产者,只需要发送ProduceRequest....
long currentTimeMs = time.milliseconds();
// 从累积器拉取消息
long pollTimeout = sendProducerData(currentTimeMs);
// 执行IO读写
client.poll(pollTimeout, currentTimeMs);
}Sender#maybeSendAndPollTransactionalRequest:这里需要明确几点:
1)事务相关请求 (如InitProducerId、AddPartitionsToTxn、EndTxn)会按序优先于ProduceRequest发送;
2)即使配置了linger.ms(默认0)等条件,只要事务提交,一定触发消息累积器的拉取条件;
3)发送事务请求前,需要事务协调者节点可达;
java
private boolean maybeSendAndPollTransactionalRequest() {
// 如果仍有事务请求在处理中,则返回true,等待响应
if (transactionManager.hasInFlightRequest()) {
client.poll(retryBackoffMs, time.milliseconds());
return true;
}
// 事务回滚,响应所有消息批次异常
if (transactionManager.hasAbortableError()
|| transactionManager.isAborting()) {
if (accumulator.hasIncomplete()) {
RuntimeException exception = transactionManager.lastError();
accumulator.abortUndrainedBatches(exception);
}
}
// 一旦事务提交,强制触发累积器满足拉取条件
if (transactionManager.isCompleting() && !accumulator.flushInProgress()) {
// 标记累积器满足读取条件,sender线程会拉取消息批次投递到broker
accumulator.beginFlush();
}
// pendingRequests中拉取事务请求
TransactionManager.TxnRequestHandler nextRequestHandler = transactionManager.nextRequest(accumulator.hasIncomplete());
// 如果没有事务请求需要发送,可以发送ProduceRequest
if (nextRequestHandler == null)
return false;
AbstractRequest.Builder<?> requestBuilder = nextRequestHandler.requestBuilder();
Node targetNode = null;
try {
// 1. 找事务协调者FindCoordinatorRequest --- 类似找消费组协调者
targetNode = awaitNodeReady(nextRequestHandler.coordinatorType());
if (targetNode == null) {
maybeFindCoordinatorAndRetry(nextRequestHandler);
return true;
}
if (nextRequestHandler.isRetry())
time.sleep(nextRequestHandler.retryBackoffMs());
long currentTimeMs = time.milliseconds();
// 2. 发送下一个事务请求
ClientRequest clientRequest = client.newClientRequest(
targetNode.idString(), requestBuilder, currentTimeMs, true, requestTimeoutMs, nextRequestHandler);
client.send(clientRequest, currentTimeMs);
// 记录当前正在处理的请求id
transactionManager.setInFlightCorrelationId(clientRequest.correlationId());
// 执行IO操作
client.poll(retryBackoffMs, time.milliseconds());
return true;
} catch (IOException e) {
maybeFindCoordinatorAndRetry(nextRequestHandler);
return true;
}
}二、初始化
2-1、发现事务协调者
每个事务id(transactional.id)对应一个事务协调者,处理事务相关请求。
Producer可以向任意Broker发起FindCoordinatorRequest,请求中key=事务id,keyType=1。
java
public class FindCoordinatorRequestData implements ApiMessage {
private String key;
// 0-消费组协调者 1-事务协调者
private byte keyType;
}
public enum CoordinatorType {
GROUP((byte) 0), TRANSACTION((byte) 1);
}KafkaApis#handleFindCoordinatorRequest:Broker分配事务协调者的逻辑与消费组协调者完全一致。topic=__transaction_state默认有50个分区,计算分区=hash(事务id)%50,该分区对应leaderBroker即为当前事务id对应的协调者Broker。
scala
def handleFindCoordinatorRequest(request: RequestChannel.Request): Unit = {
val findCoordinatorRequest = request.body[FindCoordinatorRequest]
val (partition, topicMetadata) = CoordinatorType.forId(findCoordinatorRequest.data.keyType) match {
case CoordinatorType.GROUP =>
// 消费组协调者,topic=__consumer_offsets
val partition = groupCoordinator.partitionFor(findCoordinatorRequest.data.key)
val metadata = getOrCreateInternalTopic(GROUP_METADATA_TOPIC_NAME, request.context.listenerName)
(partition, metadata)
case CoordinatorType.TRANSACTION =>
// partition = hash(transactional.id)%50
val partition = txnCoordinator.partitionFor(findCoordinatorRequest.data.key)
// 获取topic=__transaction_state元数据,如果没有则自动创建
val metadata = getOrCreateInternalTopic(TRANSACTION_STATE_TOPIC_NAME, request.context.listenerName)
(partition, metadata)
}
// 根据partitionId找到分区leader的端点
val coordinatorEndpoint = topicMetadata.partitions.asScala
.find(_.partitionIndex == partition)
.filter(_.leaderId != MetadataResponse.NO_LEADER_ID)
.flatMap(metadata => metadataCache.getAliveBroker(metadata.leaderId))
.flatMap(_.getNode(request.context.listenerName))
.filterNot(_.isEmpty)
}2-2、获取producerId
2-2-1、Producer
KafkaProducer#initTransactions:用户线程block等待事务初始化完成。
java
// 事务管理器
private final TransactionManager transactionManager;
// IO线程
private final Sender sender;
// max.block.ms=60000 send最多block时长,默认60s
private final long maxBlockTimeMs;
public void initTransactions() {
TransactionalRequestResult result =
transactionManager.initializeTransactions();
sender.wakeup();
result.await(maxBlockTimeMs, TimeUnit.MILLISECONDS);
}TransactionManager#initializeTransactions:producer发送InitProducerIdRequest,获取ProducerIdAndEpoch。
java
public synchronized TransactionalRequestResult initializeTransactions() {
return initializeTransactions(ProducerIdAndEpoch.NONE);
}
synchronized TransactionalRequestResult initializeTransactions(ProducerIdAndEpoch producerIdAndEpoch) {
return handleCachedTransactionRequestResult(() -> {
// ...
// InitProducerIdRequest入队
InitProducerIdRequestData requestData = new InitProducerIdRequestData()
// 事务id
.setTransactionalId(transactionalId)
// 事务超时时间
.setTransactionTimeoutMs(transactionTimeoutMs)
// 当前pid和epoch(初始都是-1)
.setProducerId(producerIdAndEpoch.producerId)
.setProducerEpoch(producerIdAndEpoch.epoch);
InitProducerIdHandler handler = new InitProducerIdHandler(new InitProducerIdRequest.Builder(requestData),
isEpochBump);
enqueueRequest(handler);
return handler.result;
}, State.INITIALIZING);
}
public class ProducerIdAndEpoch {
public final long producerId;
public final short epoch;
}2-2-2、协调者
事务协调者Broker侧用TransactionStateManager管理事务状态。
scala
class TransactionStateManager {
// __transaction_state协调者分区 - entry
val transactionMetadataCache: mutable.Map[Int, TxnMetadataCacheEntry];
}
class TxnMetadataCacheEntry(
// __transaction_state协调者分区leader epoch
coordinatorEpoch: Int,
// 事务id - 事务元数据
metadataPerTransactionalId: Pool[String, TransactionMetadata]) {
}
// 事务元数据
class TransactionMetadata(
// 事务id
val transactionalId: String,
// producerId
var producerId: Long,
var lastProducerId: Long,
// producerEpoch
var producerEpoch: Short,
var lastProducerEpoch: Short,
// 事务超时时间 --- 客户端传入
var txnTimeoutMs: Int,
// 当前事务状态
var state: TransactionState,
// 处于事务中的消息所在topic分区
val topicPartitions: mutable.Set[TopicPartition],
// 事务开始时间
@volatile var txnStartTimestamp: Long = -1,
// 上次更新时间
@volatile var txnLastUpdateTimestamp: Long)
)
// 事务元数据变更,属性几乎同TransactionMetadata
class TxnTransitMetadata(producerId: Long,
lastProducerId: Long,
producerEpoch: Short,
lastProducerEpoch: Short,
txnTimeoutMs: Int,
txnState: TransactionState,
topicPartitions: immutable.Set[TopicPartition],
txnStartTimestamp: Long,
txnLastUpdateTimestamp: Long)TransactionCoordinator#handleInitProducerId:
1)如果只是幂等生产者,生成producerId直接返回;
2)客户端设置的事务超时时间不能大于服务端限制transaction.max.timeout.ms(默认15分钟);
3)查询事务id是否已经存在TransactionMetadata事务元数据,否则生成一个producerId创建元数据;
4)组装元数据变更TxnTransitMetadata,比如producerEpoch++,事务超时时间更新;
5)将TxnTransitMetadata 写入事务id对应的协调者分区,把TransactionMetadata更新到内存;
producerId生成方式:每个broker从ZK的latest_producer_id_block节点获取步长1000的号段。如latest_producer_id_block={"version":1,"broker":111,"block_start":"11000","block_end":"11999"},下次获取就是12000-12999。
scala
def handleInitProducerId(transactionalId: String,
transactionTimeoutMs: Int,
expectedProducerIdAndEpoch: Option[ProducerIdAndEpoch],
responseCallback: InitProducerIdCallback): Unit = {
if (transactionalId == null) {
// 1. 如果是幂等生产者,则直接返回一个producerId
val producerId = producerIdManager.generateProducerId()
responseCallback(InitProducerIdResult(producerId, producerEpoch = 0, Errors.NONE))
} else if (!txnManager.validateTransactionTimeoutMs(transactionTimeoutMs)) {
// 2. 事务超时时间不能大于服务端限制transaction.max.timeout.ms=15分钟
responseCallback(initTransactionError(Errors.INVALID_TRANSACTION_TIMEOUT))
} else {
val coordinatorEpochAndMetadata = txnManager.getTransactionState(transactionalId).flatMap {
case None =>
// 3. 如果transactionalId不存在,生成producerId,创建元数据
val producerId = producerIdManager.generateProducerId()
val createdMetadata = new TransactionMetadata(
transactionalId = transactionalId,
producerId = producerId,
lastProducerId = RecordBatch.NO_PRODUCER_ID,
producerEpoch = RecordBatch.NO_PRODUCER_EPOCH,
lastProducerEpoch = RecordBatch.NO_PRODUCER_EPOCH,
txnTimeoutMs = transactionTimeoutMs,
state = Empty,
topicPartitions = collection.mutable.Set.empty[TopicPartition],
txnLastUpdateTimestamp = time.milliseconds())
txnManager.putTransactionStateIfNotExists(createdMetadata)
// 否则直接用原来的元数据
case Some(epochAndTxnMetadata) => Right(epochAndTxnMetadata)
}
val result: ApiResult[(Int, TxnTransitMetadata)] = coordinatorEpochAndMetadata.flatMap {
existingEpochAndMetadata =>
val coordinatorEpoch = existingEpochAndMetadata.coordinatorEpoch
val txnMetadata = existingEpochAndMetadata.transactionMetadata
txnMetadata.inLock { // 注意锁
// 4. 组装元数据变更TxnTransitMetadata,如epoch++,事务超时时间变更
prepareInitProducerIdTransit(transactionalId, transactionTimeoutMs, coordinatorEpoch, txnMetadata,
expectedProducerIdAndEpoch)
}
}
result match {
case Left(error) =>
responseCallback(initTransactionError(error))
case Right((coordinatorEpoch, newMetadata)) =>
if (newMetadata.txnState == PrepareEpochFence) {
// ... 事务id冲突
} else {
def sendPidResponseCallback(error: Errors): Unit = {
if (error == Errors.NONE) {
responseCallback(initTransactionMetadata(newMetadata))
} else {
responseCallback(initTransactionError(error))
}
}
// 5. 写入__transaction_state协调者分区
// key=transactionalId, value=TxnTransitMetadata(元数据变更),更新内存元数据
txnManager.appendTransactionToLog(transactionalId, coordinatorEpoch, newMetadata, sendPidResponseCallback)
}
}
}
}TransactionCoordinator#prepareInitProducerIdTransit:在锁保护下,校验元数据是否允许初始化,返回元数据变更TxnTransitMetadata。
scala
private def prepareInitProducerIdTransit(transactionalId: String,
transactionTimeoutMs: Int,
coordinatorEpoch: Int,
txnMetadata: TransactionMetadata,
expectedProducerIdAndEpoch: Option[ProducerIdAndEpoch]):
ApiResult[(Int, TxnTransitMetadata)] = {
if (txnMetadata.pendingTransitionInProgress) {
// 正在执行状态变更,返回重试
Left(Errors.CONCURRENT_TRANSACTIONS)
}
else if (!expectedProducerIdAndEpoch.forall(isValidProducerId)) {
Left(Errors.INVALID_PRODUCER_EPOCH)
} else {
txnMetadata.state match {
case PrepareAbort | PrepareCommit =>
// 正在回滚/提交,返回重试
Left(Errors.CONCURRENT_TRANSACTIONS)
case CompleteAbort | CompleteCommit | Empty =>
// 正常情况,进入这里
val transitMetadataResult =
if (txnMetadata.isProducerEpochExhausted &&
expectedProducerIdAndEpoch.forall(_.epoch == txnMetadata.producerEpoch)) {
// epoch已经到达Short.MaxValue - 1,生成新producerId
val newProducerId = producerIdManager.generateProducerId()
Right(txnMetadata.prepareProducerIdRotation(newProducerId, transactionTimeoutMs, time.milliseconds(),
expectedProducerIdAndEpoch.isDefined))
} else {
// 更新事务超时时间,epoch+1
txnMetadata.prepareIncrementProducerEpoch(transactionTimeoutMs, expectedProducerIdAndEpoch.map(_.epoch),
time.milliseconds())
}
transitMetadataResult match {
case Right(transitMetadata) => Right((coordinatorEpoch, transitMetadata))
case Left(err) => Left(err)
}
case Ongoing =>
// 事务中,准备进入PrepareEpochFence
Right(coordinatorEpoch, txnMetadata.prepareFenceProducerEpoch())
}
}
}TransactionStateManager#appendTransactionToLog:将元数据变更TxnTransitMetadata写入topic=__transaction_state下的协调者分区,最终应用到内存TransactionMetadata。
scala
def appendTransactionToLog(transactionalId: String,
coordinatorEpoch: Int,
newMetadata: TxnTransitMetadata,
responseCallback: Errors => Unit,
retryOnError: Errors => Boolean = _ => false): Unit = {
val keyBytes = TransactionLog.keyToBytes(transactionalId)
val valueBytes = TransactionLog.valueToBytes(newMetadata)
val timestamp = time.milliseconds()
val records = MemoryRecords.withRecords(TransactionLog.EnforcedCompressionType, new SimpleRecord(timestamp, keyBytes, valueBytes))
val topicPartition = new TopicPartition(Topic.TRANSACTION_STATE_TOPIC_NAME, partitionFor(transactionalId))
val recordsPerPartition = Map(topicPartition -> records)
def updateCacheCallback(responseStatus: collection.Map[TopicPartition, PartitionResponse]): Unit = {
if (responseError == Errors.NONE) {
getTransactionState(transactionalId) match {
case Left(err) =>
responseError = err
case Right(Some(epochAndMetadata)) =>
val metadata = epochAndMetadata.transactionMetadata
metadata.inLock {
if (epochAndMetadata.coordinatorEpoch != coordinatorEpoch) {
responseError = Errors.NOT_COORDINATOR
} else {
// 2. 应用元数据变更TxnTransitMetadata到内存TransactionMetadata元数据
metadata.completeTransitionTo(newMetadata)
}
}
case Right(None) =>
responseError = Errors.NOT_COORDINATOR
}
}
responseCallback(responseError)
}
inReadLock(stateLock) {
getTransactionState(transactionalId) match {
case Right(Some(epochAndMetadata)) =>
// 1. 写消息
replicaManager.appendRecords(
// 超时时间=事务超时时间
newMetadata.txnTimeoutMs.toLong,
// acks固定-1
TransactionLog.EnforcedRequiredAcks,
internalTopicsAllowed = true,
origin = AppendOrigin.Coordinator,
recordsPerPartition,
updateCacheCallback)
}
}
}后续所有的事务状态变化的流程大致都是:查询事务元数据TransactionMetadata→校验元数据→组装元数据变更TxnTransitMetadata→写消息到__transaction_state下的协调者分区→新元数据更新到内存。
可以想的到,只要写消息成功,后续所有事务状态都能通过回放消息恢复,更新状态到内存。这和消费组协调者的工作机制一样,只要__transaction_state的选出分区leader,回放消息,就可以把所有事务id的元数据TransactionMetadata更新到内存。
三、发消息
3-1、分区加入事务
考虑事务中存在不同分区的消息 ,而分区Leader是不同的Broker ,生产者需要将事务中的分区上报给事务协调者,后续协调者提交或回滚事务需要通过分区找到相关Broker。
3-1-1、Producer
KafkaProducer#doSend:Producer线程,将消息写入累积器后,将事务中新增的分区加入newPartitionsInTransaction。
java
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
//【1】max.block.ms=60*1000,最多等待60s,要拿到metadata,包括集群broker信息,topic-partition信息
clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), nowMs, maxBlockTimeMs);
// 【2】key/value序列化
// ...
// 【3】计算partition,如果ProducerRecord没显示指定分区,DefaultPartitioner
int partition = partition(record, serializedKey, serializedValue, cluster);
// 【4】校验消息大小不能超过max.request.size = 1024 * 1024 = 1MB
int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound(...);
// 这里校验必须先执行producer.beginTransaction(),翻转内存状态为IN_TRANSACTION
if (transactionManager != null && transactionManager.isTransactional()) {
transactionManager.failIfNotReadyForSend();
}
// 【5】将消息加入累积器
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs, true, nowMs);
if (transactionManager != null && transactionManager.isTransactional())
// focus 分区加入事务
transactionManager.maybeAddPartitionToTransaction(tp);
// 【6】唤醒io线程发送消息
if (result.batchIsFull || result.newBatchCreated) {
this.sender.wakeup();
}
return result.future;
}
// TransactionManager#maybeAddPartitionToTransaction
public synchronized void maybeAddPartitionToTransaction(TopicPartition topicPartition) {
// 已经加入分区,忽略
if (isPartitionAdded(topicPartition)
|| isPartitionPendingAdd(topicPartition))
return;
// 加入分区,待发送AddPartitionsToTxnRequest
topicPartitionBookkeeper.addPartition(topicPartition);
newPartitionsInTransaction.add(topicPartition);
}RecordAccumulator#shouldStopDrainBatchesForPartition:Sender线程,从累积器拉取消息批次,发现分区还未加入事务,则不会拉取并发送出去。
java
private boolean shouldStopDrainBatchesForPartition(ProducerBatch first, TopicPartition tp) {
if (transactionManager != null) {
// 分区还未加入事务(完成AddPartitionsToTxnRequest)不能发送出去
if (!transactionManager.isSendToPartitionAllowed(tp))
return true;
// ... 其他判断
}
}
// TransactionManager#isSendToPartitionAllowed
synchronized boolean isSendToPartitionAllowed(TopicPartition tp) {
if (hasFatalError())
return false;
// 幂等生产者 || 分区还未进入事务
return !isTransactional() || partitionsInTransaction.contains(tp);
}TransactionManager#nextRequest:Sender线程,发现Producer发送消息导致有新分区加入事务,则发送AddPartitionsToTxnRequest,其中包含本次加入事务的n个分区。
java
synchronized TxnRequestHandler nextRequest(boolean hasIncompleteBatches) {
// producer线程发送的消息中,有新的分区加入事务,AddPartitionsToTxnRequest
if (!newPartitionsInTransaction.isEmpty())
enqueueRequest(addPartitionsToTransactionHandler());
// ...
}
private TxnRequestHandler addPartitionsToTransactionHandler() {
// newPartitionsInTransaction -> pendingPartitionsInTransaction
pendingPartitionsInTransaction.addAll(newPartitionsInTransaction);
newPartitionsInTransaction.clear();
AddPartitionsToTxnRequest.Builder builder =
new AddPartitionsToTxnRequest.Builder(transactionalId,
producerIdAndEpoch.producerId,
producerIdAndEpoch.epoch,
new ArrayList<>(pendingPartitionsInTransaction));
return new AddPartitionsToTxnHandler(builder);
}AddPartitionsToTxnHandler:收到AddPartitionsToTxnResponse,部分异常可以reenqueue重试,部分异常直接fatal失败,正常情况下分区会正常进入事务,加入partitionsInTransaction集合。
java
private class AddPartitionsToTxnHandler extends TxnRequestHandler {
public void handleResponse(AbstractResponse response) {
AddPartitionsToTxnResponse addPartitionsToTxnResponse = (AddPartitionsToTxnResponse) response;
// 分区 - 是否成功加入事务
Map<TopicPartition, Errors> errors = addPartitionsToTxnResponse.errors();
boolean hasPartitionErrors = false;
Set<String> unauthorizedTopics = new HashSet<>();
retryBackoffMs = TransactionManager.this.retryBackoffMs;
for (Map.Entry<TopicPartition, Errors> topicPartitionErrorEntry : errors.entrySet()) {
TopicPartition topicPartition = topicPartitionErrorEntry.getKey();
Errors error = topicPartitionErrorEntry.getValue();
if (error == Errors.NONE) {
continue;
} else if (error == Errors.COORDINATOR_NOT_AVAILABLE
|| error == Errors.NOT_COORDINATOR) {
lookupCoordinator(FindCoordinatorRequest.CoordinatorType.TRANSACTION, transactionalId);
reenqueue();
return;
} else if (error == Errors.CONCURRENT_TRANSACTIONS) {
maybeOverrideRetryBackoffMs();
reenqueue();
return;
} else if (error == Errors.INVALID_PRODUCER_EPOCH) {
fatalError(error.exception());
return;
}
// ...
}
Set<TopicPartition> partitions = errors.keySet();
pendingPartitionsInTransaction.removeAll(partitions);
// ...
else {
// 分区成功进入事务
partitionsInTransaction.addAll(partitions);
transactionStarted = true;
result.done();
}
}
}3-1-2、协调者
TransactionCoordinator#handleAddPartitionsToTransaction:
1)组装TxnTransitMetadata事务元数据变更,将请求中的分区加入;
2)写入__transaction_state对应协调者分区,并应用TxnTransitMetadata元数据变更到内存TransactionMetadata元数据;
scala
def handleAddPartitionsToTransaction(transactionalId: String,
producerId: Long,
producerEpoch: Short,
partitions: collection.Set[TopicPartition],
responseCallback: AddPartitionsCallback): Unit = {
if (transactionalId == null || transactionalId.isEmpty) {
responseCallback(Errors.INVALID_REQUEST)
} else {
val result: ApiResult[(Int, TxnTransitMetadata)] = txnManager.getTransactionState(transactionalId).flatMap {
case None => Left(Errors.INVALID_PRODUCER_ID_MAPPING)
case Some(epochAndMetadata) =>
val coordinatorEpoch = epochAndMetadata.coordinatorEpoch
val txnMetadata = epochAndMetadata.transactionMetadata
txnMetadata.inLock {
// 校验...
else {
// 组装新的TxnTransitMetadata,producer加分区,状态Ongoing
Right(coordinatorEpoch, txnMetadata.prepareAddPartitions(partitions.toSet, time.milliseconds()))
}
}
}
result match {
case Left(err) =>
responseCallback(err)
case Right((coordinatorEpoch, newMetadata)) =>
// 把新的TxnTransitMetadata写入__transaction_state,最终更新到transactionMetadataCache
txnManager.appendTransactionToLog(transactionalId, coordinatorEpoch, newMetadata, responseCallback)
}
}
}
// TransactionMetadata#prepareAddPartitions
def prepareAddPartitions(addedTopicPartitions: immutable.Set[TopicPartition], updateTimestamp: Long): TxnTransitMetadata = {
val newTxnStartTimestamp = state match {
case Empty | CompleteAbort | CompleteCommit => updateTimestamp
case _ => txnStartTimestamp
}
prepareTransitionTo(Ongoing, producerId, producerEpoch, lastProducerEpoch, txnTimeoutMs,
(topicPartitions ++ addedTopicPartitions).toSet, newTxnStartTimestamp, updateTimestamp)
}3-2、发送消息
3-2-1、Producer
RecordAccumulator#drainBatchesForOneNode:Sender线程从累积器拉取消息发送,需要为批次设置事务相关属性。
java
private List<ProducerBatch> drainBatchesForOneNode(Cluster cluster, Node node, int maxSize, long now) {
int size = 0;
// 遍历broker下的所有partition
List<PartitionInfo> parts = cluster.partitionsForNode(node.id());
// 需要发送的批次
List<ProducerBatch> ready = new ArrayList<>();
int start = drainIndex = drainIndex % parts.size();
do {
PartitionInfo part = parts.get(drainIndex);
TopicPartition tp = new TopicPartition(part.topic(), part.partition());
this.drainIndex = (this.drainIndex + 1) % parts.size();
if (isMuted(tp))
continue;
Deque<ProducerBatch> deque = getDeque(tp);
if (deque == null)
continue;
synchronized (deque) {
ProducerBatch first = deque.peekFirst();
if (first == null)
continue;
// 事务,部分场景下,不能发送消息,比如分区还未加入事务
if (shouldStopDrainBatchesForPartition(first, tp))
break;
boolean isTransactional = transactionManager != null && transactionManager.isTransactional();
ProducerIdAndEpoch producerIdAndEpoch =
transactionManager != null ? transactionManager.producerIdAndEpoch() : null;
ProducerBatch batch = deque.pollFirst();
if (producerIdAndEpoch != null && !batch.hasSequence()) {
// 设置 producerId+epoch+批次起始序号
// 批次起始序号=每个producerEpoch从0开始的offset
batch.setProducerState(producerIdAndEpoch, transactionManager.sequenceNumber(batch.topicPartition), isTransactional);
transactionManager.incrementSequenceNumber(batch.topicPartition, batch.recordCount);
transactionManager.addInFlightBatch(batch);
}
// 关闭批次,写入批次header
batch.close();
size += batch.records().sizeInBytes();
ready.add(batch);
batch.drained(now);
}
} while (start != drainIndex);
return ready;
}ProducerBatch#setProducerState:对于每个消息批次,加入事务相关属性
1)producerId和producerEpoch;
2)baseSequence:当前事务id在这个分区下的消息序号,从0开始增加;
3)isTransactional:true
java
public void setProducerState(ProducerIdAndEpoch producerIdAndEpoch, int baseSequence, boolean isTransactional) {
recordsBuilder.setProducerState(producerIdAndEpoch.producerId, producerIdAndEpoch.epoch, baseSequence, isTransactional);
}
// MemoryRecordsBuilder#setProducerState
public void setProducerState(long producerId, short producerEpoch, int baseSequence, boolean isTransactional) {
this.producerId = producerId;
this.producerEpoch = producerEpoch;
this.baseSequence = baseSequence;
this.isTransactional = isTransactional;
}TransactionManager:获取并增加分区消息序号。
java
// 获取当前分区的发送序号
synchronized Integer sequenceNumber(TopicPartition topicPartition) {
return topicPartitionBookkeeper.getPartition(topicPartition).nextSequence;
}
// 增加序号 = 当前序号 + 本批次消息数量
synchronized void incrementSequenceNumber(TopicPartition topicPartition, int increment) {
Integer currentSequence = sequenceNumber(topicPartition);
currentSequence = DefaultRecordBatch.incrementSequence(currentSequence, increment);
topicPartitionBookkeeper.getPartition(topicPartition).nextSequence = currentSequence;
}
// 管理每个分区的消息序号
private static class TopicPartitionBookkeeper {
private final Map<TopicPartition, TopicPartitionEntry> topicPartitions;
}
private static class TopicPartitionEntry {
private int nextSequence;
}最终ProduceRequest也会包含事务ID。
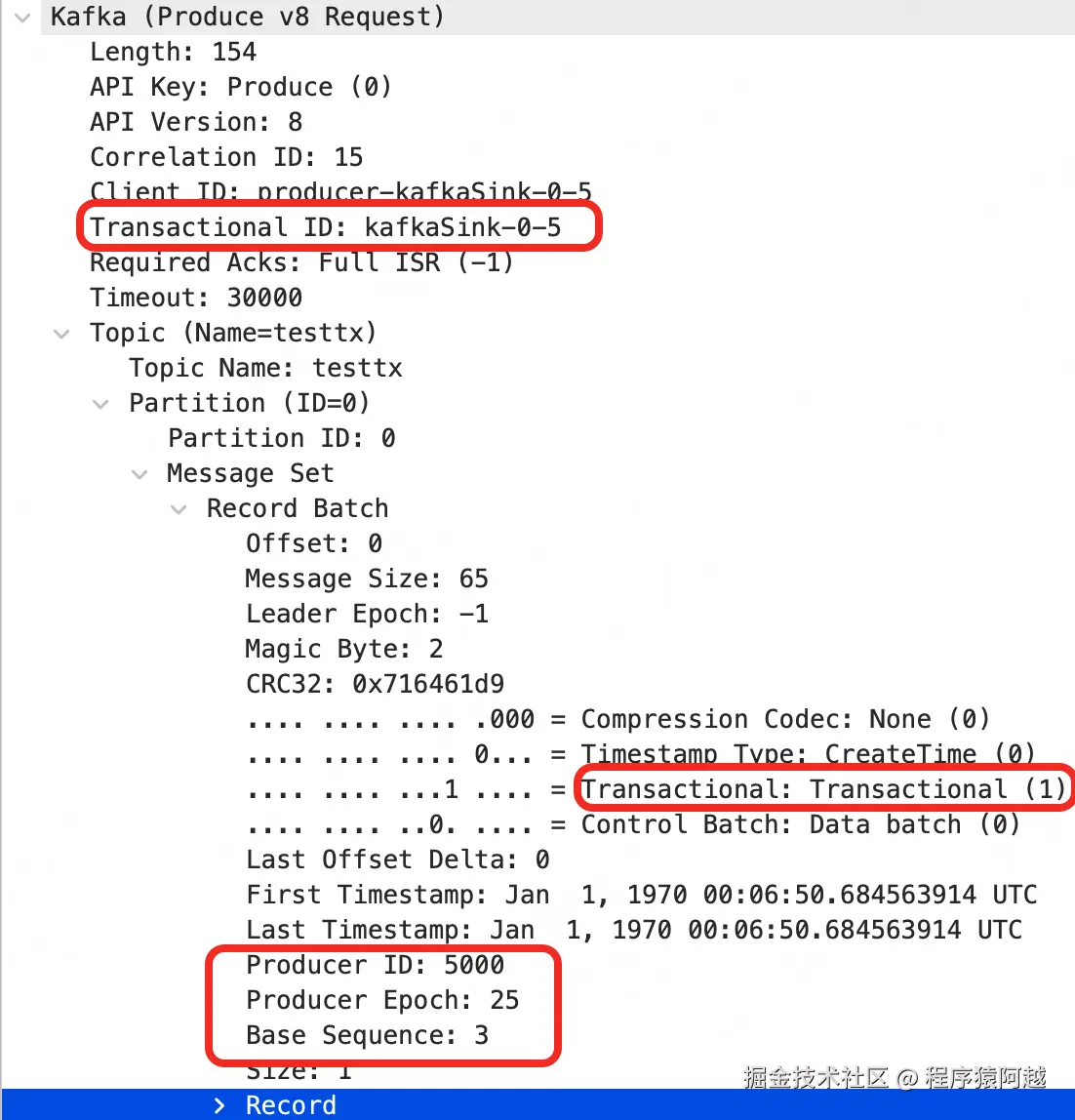
3-2-2、Broker
Log#append:在写用户消息流程中穿插事务处理。
1)analyzeAndValidateProducerState:maybeDuplicate幂等拦截+updatedProducers准备生产者事务状态更新;
2)segment.append:写数据;
3)producerStateManager.update:更新生产者事务状态;
4)maybeIncrementFirstUnstableOffset:更新LSO(lastStableOffset),RC隔离级别消费者在LSO之后的数据不可见;
当前是写事务中的用户消息 ,部分逻辑不会经过。当提交/回滚事务,这里会写入控制消息。
scala
private def append(records: MemoryRecords,
origin: AppendOrigin,
interBrokerProtocolVersion: ApiVersion,
assignOffsets: Boolean,
leaderEpoch: Int,
ignoreRecordSize: Boolean): LogAppendInfo = {
maybeHandleIOException(s"Error while appending records to $topicPartition in dir ${dir.getParent}") {
// 1. 校验并组装LogAppendInfo
val appendInfo = analyzeAndValidateRecords(records, origin, ignoreRecordSize)
lock synchronized { // log级别锁,同一个分区不能并发写
// 校验并继续填充LogAppendInfo
// ...
// 2. 处理segment滚动
val segment = maybeRoll(validRecords.sizeInBytes, appendInfo)
val logOffsetMetadata = LogOffsetMetadata(
messageOffset = appendInfo.firstOrLastOffsetOfFirstBatch,
segmentBaseOffset = segment.baseOffset,
relativePositionInSegment = segment.size)
// 【事务】幂等/事务处理(用户消息、控制消息)
// case1 producer写入事务中的消息返回 updatedProducers = (producerId,ProducerAppendInfo生产者待更新状态)
// case2 事务协调者写入控制批次 completedTxns(List[CompletedTxn]) = 当前写入控制批次(提交/回滚)
// case3 maybeDuplicate(BatchMetadata) = 重复ProducerRequest幂等批次
val (updatedProducers, completedTxns, maybeDuplicate) = analyzeAndValidateProducerState(
logOffsetMetadata, validRecords, origin)
// 幂等命中直接返回(用户消息)
maybeDuplicate.foreach { duplicate =>
appendInfo.firstOffset = Some(duplicate.firstOffset)
appendInfo.lastOffset = duplicate.lastOffset
appendInfo.logAppendTime = duplicate.timestamp
appendInfo.logStartOffset = logStartOffset
return appendInfo
}
// 3. 写segment(用户消息、控制消息)
segment.append(largestOffset = appendInfo.lastOffset,
largestTimestamp = appendInfo.maxTimestamp,
shallowOffsetOfMaxTimestamp = appendInfo.offsetOfMaxTimestamp,
records = validRecords)
// 4. 更新LEO,下次append的批次的offset从这里开始
updateLogEndOffset(appendInfo.lastOffset + 1)
// 【事务】处理生产者状态(用户消息、控制消息)
// 1. ongoingTxns.put(batch.first, List[TxnMetadata])
// 2. 记录producerId最近n个BatchMetadata用于幂等校验
for (producerAppendInfo <- updatedProducers.values) {
producerStateManager.update(producerAppendInfo)
}
// 【事务】处理完成的事务(控制消息)
for (completedTxn <- completedTxns) {
// 计算分区新LSO
val lastStableOffset = producerStateManager.lastStableOffset(completedTxn)
// 如果Abort,插入事务索引
segment.updateTxnIndex(completedTxn, lastStableOffset)
// ongoingTxns-批次->unreplicatedTxns
producerStateManager.completeTxn(completedTxn)
}
producerStateManager.updateMapEndOffset(appendInfo.lastOffset + 1)
// 【事务】更新unstable offset(用户消息、控制消息)
maybeIncrementFirstUnstableOffset()
// 5. 刷盘逻辑,flush.messages=Long.MAX_VALUE,配置成1则每次append都fsync
if (unflushedMessages >= config.flushInterval)
flush()
// 返回LogAppendInfo
appendInfo
}
}
}ProducerStateManager维护了一个分区Log下的生产者状态和事务状态。
scala
class Log(val topicPartition: TopicPartition,
val producerStateManager: ProducerStateManager) {}
class ProducerStateManager(val topicPartition: TopicPartition) {
// producerId -> producer状态
private val producers = mutable.Map.empty[Long, ProducerStateEntry]
private var lastMapOffset = 0L
private var lastSnapOffset = 0L
// 还未提交的事务:消息批次起始offset -> 事务元数据
private val ongoingTxns = new util.TreeMap[Long, TxnMetadata]
// 已经提交/回滚的事务,但是还未复制到slave:消息批次起始offset -> 事务元数据
private val unreplicatedTxns = new util.TreeMap[Long, TxnMetadata]
}ProducerStateEntry 维护了一个分区下一个生产者的状态,包含最近5个批次的元数据BatchMetadata。
BatchMetadata批次元数据,包含批次的offset和seq序号(起始和结束)等,每次写入消息成功后会更新。
scala
private[log] class ProducerStateEntry(val producerId: Long,
// 最近5个批次的元数据
val batchMetadata: mutable.Queue[BatchMetadata],
// 当前producer的epoch
var producerEpoch: Short,
// 协调者分区leaderEpoch
var coordinatorEpoch: Int,
var lastTimestamp: Long,
// 当前处于事务中的第一个offset
var currentTxnFirstOffset: Option[Long]) {}
private[log] case class BatchMetadata(
lastSeq: Int, lastOffset: Long, offsetDelta: Int, timestamp: Long) {
def firstSeq: Int = DefaultRecordBatch.decrementSequence(lastSeq, offsetDelta)
def firstOffset: Long = lastOffset - offsetDelta
}幂等校验
每个分区每个producerId缓存了5个消息批次元数据。写消息前根据消息批次序号,查询是否有重复的消息实现幂等。如果发现重复消息,像正常写入成功一样,直接响应客户端成功。
analyzeAndValidateProducerState→ProducerStateEntry#findDuplicateBatch:
scala
val batchMetadata: mutable.Queue[BatchMetadata]
// 写消息前,从元数据队列中,根据序号查询相同的批次
def findDuplicateBatch(batch: RecordBatch): Option[BatchMetadata] = {
if (batch.producerEpoch != producerEpoch)
None
else
batchWithSequenceRange(batch.baseSequence, batch.lastSequence)
}
def batchWithSequenceRange(firstSeq: Int, lastSeq: Int): Option[BatchMetadata] = {
val duplicate = batchMetadata.filter { metadata =>
firstSeq == metadata.firstSeq && lastSeq == metadata.lastSeq
}
duplicate.headOption
}
// 写消息后,将批次元数据入队,只保留5个
private def addBatchMetadata(batch: BatchMetadata): Unit = {
if (batchMetadata.size == 5)
batchMetadata.dequeue()
batchMetadata.enqueue(batch)
}这种幂等校验方式的前提是,每个分区每个生产者严格按照消息批次设置的序号发送。
一方面,客户端重试时,需要将消息批次按照顺序重新进入发送队列。
ProducerAppendInfo#checkSequence:另一方面,broker写消息前,需要校验序号连续。
scala
private def checkSequence(producerEpoch: Short, appendFirstSeq: Int, offset: Long): Unit = {
if (producerEpoch != updatedEntry.producerEpoch) {
// producerEpoch发生变化,所有序号会被清空
if (appendFirstSeq != 0) {
if (updatedEntry.producerEpoch != RecordBatch.NO_PRODUCER_EPOCH) {
throw new OutOfOrderSequenceException()
}
}
} else {
// 当前迭代的批次,是本次ProduceRequest批次中非首个,取已经迭代的批次最后一个
val currentLastSeq = if (!updatedEntry.isEmpty)
updatedEntry.lastSeq
// 当前迭代的批次,是本次ProduceRequest批次中第一个,取broker内存里的最后一个序号
else if (producerEpoch == currentEntry.producerEpoch)
currentEntry.lastSeq
else
RecordBatch.NO_SEQUENCE
if (!(currentEntry.producerEpoch == RecordBatch.NO_PRODUCER_EPOCH || inSequence(currentLastSeq, appendFirstSeq))) {
throw new OutOfOrderSequenceException()
}
}
}
// lastSeq=已经校验通过的最后一个序号;nextSeq=待校验的起始序号
private def inSequence(lastSeq: Int, nextSeq: Int): Boolean = {
nextSeq == lastSeq + 1L || (nextSeq == 0 && lastSeq == Int.MaxValue)
}消息不可见
事务消息的另一个关键点就是可见性。
Log#lastStableOffset:为了让消息在事务提交前不可见,每个分区维护了一个LSO(last stable offset)。
如果分区没有事务,则LSO=高水位;反之LSO=当前事务中的最小offset=firstUnstableOffset。
scala
// 事务中最小offset
private var firstUnstableOffsetMetadata: Option[LogOffsetMetadata] = None
// LSO
def lastStableOffset: Long = {
firstUnstableOffsetMetadata match {
case Some(offsetMetadata) if offsetMetadata.messageOffset < highWatermark => offsetMetadata.messageOffset
case _ => highWatermark
}
}broker侧重置消费进度 和拉取消息,都会根据隔离级别,限制消费者可见offset。
scala
// ListOffsetRequest消费组没有消费进度,重置消费进度,broker根据隔离级别返回
def fetchOffsetForTimestamp(timestamp: Long,
isolationLevel: Option[IsolationLevel],
currentLeaderEpoch: Optional[Integer],
fetchOnlyFromLeader: Boolean): Option[TimestampAndOffset] = inReadLock(leaderIsrUpdateLock) {
// 最大可拉取的offset
val lastFetchableOffset = isolationLevel match {
// 事务消息相关,消费者设置READ_COMMITTED隔离级别,只能消费LSO
case Some(IsolationLevel.READ_COMMITTED) => localLog.lastStableOffset
// 普通消费者,能消费HW之前的数据,HW高水位=min(ISR副本的写入进度LEO)
case Some(IsolationLevel.READ_UNCOMMITTED) => localLog.highWatermark
}
// ...
}
// FetchRequest真实拉取消息
def read(startOffset: Long,
maxLength: Int,
isolation: FetchIsolation,
minOneMessage: Boolean): FetchDataInfo = {
// 根据隔离级别,决定最大可读offset
val maxOffsetMetadata = isolation match {
// slave同步,可以取LEO当前写入进度
case FetchLogEnd => endOffsetMetadata
// READ_UNCOMMITTED级别(默认),取HW高水位
case FetchHighWatermark => fetchHighWatermarkMetadata
// RC级别,取LSO
case FetchTxnCommitted => fetchLastStableOffsetMetadata
}
}综上,LSO取决于当前事务中的最小offset。现在关注broker接收用户事务消息。
生产者开启事务并没有远程调用,所以事务开始的标记取决于broker收到第一个事务消息批次。
ProducerStateManager#update:当消息写入完毕,如果生产者在这个分区首次发送消息批次,在ongoingTxns中记录事务开始的消息offset。
ongoingTxns记录了这个分区下n个生产者正在执行的事务的起始offset。
scala
// producerId -> producer状态
private val producers = mutable.Map.empty[Long, ProducerStateEntry]
// 还未提交的事务:消息批次起始offset -> 事务元数据
private val ongoingTxns = new util.TreeMap[Long, TxnMetadata]
def update(appendInfo: ProducerAppendInfo): Unit = {
// 更新producer状态
val updatedEntry = appendInfo.toEntry
producers.get(appendInfo.producerId) match {
case Some(currentEntry) =>
currentEntry.update(updatedEntry)
case None =>
producers.put(appendInfo.producerId, updatedEntry)
}
// 如果producer在这个分区刚发送第一条批次消息,代表刚开始一个事务,加入ongoingTxns
appendInfo.startedTransactions.foreach { txn =>
ongoingTxns.put(txn.firstOffset.messageOffset, txn)
}
}Log#maybeIncrementFirstUnstableOffset :当新事务开启 或高水位增加 ,该方法会被调用,用于更新firstUnstableOffset。
scala
private var firstUnstableOffsetMetadata: Option[LogOffsetMetadata] = None
private def maybeIncrementFirstUnstableOffset(): Unit = lock synchronized {
// 计算firstUnstableOffset
val updatedFirstStableOffset = producerStateManager.firstUnstableOffset
//...
if (updatedFirstStableOffset != this.firstUnstableOffsetMetadata) {
this.firstUnstableOffsetMetadata = updatedFirstStableOffset
}
}ProducerStateManager#firstUnstableOffset:LSO计算逻辑如下,注意虽然每个生产者实例会按照顺序开始和结束事务,事务offset是有序的;但是多个生产者在这个分区里的事务offset是无序的,所以需要取min(事务中offset,提交或回滚中offset)。
这里是处理用户消息,还没涉及到unreplicatedTxns,unreplicatedTxns需要在用户提交或回滚事务后加入。
scala
// 还未提交的事务:消息批次起始offset -> 事务元数据
private val ongoingTxns = new util.TreeMap[Long, TxnMetadata]
// 已经提交/回滚的事务,但是还未复制到slave:消息批次起始offset -> 事务元数据
private val unreplicatedTxns = new util.TreeMap[Long, TxnMetadata]
def firstUnstableOffset: Option[LogOffsetMetadata] = {
// 处于正在提交或回滚的最小offset
val unreplicatedFirstOffset = Option(unreplicatedTxns.firstEntry).map(_.getValue.firstOffset)
// 事务中的最小offset
val undecidedFirstOffset = Option(ongoingTxns.firstEntry).map(_.getValue.firstOffset)
// case2 没有正在提交或回滚的事务,取正在事务中的最小offset
if (unreplicatedFirstOffset.isEmpty)
undecidedFirstOffset
// case3 没有事务中,取正在提交或回滚的事务的最小offset
else if (undecidedFirstOffset.isEmpty)
unreplicatedFirstOffset
// case1 如果两者都存在,则取min(事务中,提交或回滚中)
else if (undecidedFirstOffset.get.messageOffset < unreplicatedFirstOffset.get.messageOffset)
undecidedFirstOffset
else
unreplicatedFirstOffset
}四、结束事务
4-1、producer
KafkaProducer提交和回滚都会阻塞等待协调者响应。
java
// max.block.ms=60000 最多block时长,默认60s
private final long maxBlockTimeMs;
public void commitTransaction() throws ProducerFencedException {
TransactionalRequestResult result = transactionManager.beginCommit();
sender.wakeup();
result.await(maxBlockTimeMs, TimeUnit.MILLISECONDS);
}
public void abortTransaction() throws ProducerFencedException {
TransactionalRequestResult result = transactionManager.beginAbort();
sender.wakeup();
result.await(maxBlockTimeMs, TimeUnit.MILLISECONDS);
}TransactionManager#beginCompletingTransaction:无论提交回滚,都是发送EndTxnRequest,区别是committed标志为true或false。
java
private TransactionalRequestResult beginCompletingTransaction(TransactionResult transactionResult) {
// 入队EndTxnRequest
EndTxnRequest.Builder builder = new EndTxnRequest.Builder(
new EndTxnRequestData()
.setTransactionalId(transactionalId)
.setProducerId(producerIdAndEpoch.producerId)
.setProducerEpoch(producerIdAndEpoch.epoch)
.setCommitted(transactionResult.id));
EndTxnHandler handler = new EndTxnHandler(builder);
enqueueRequest(handler);
}
public enum TransactionResult {
ABORT(false), COMMIT(true);
public final boolean id;
}EndTxnHandler#handleResponse:处理结束事务响应,部分异常可以重新入队自动重试;部分异常fatalError直接抛给用户;
java
public void handleResponse(AbstractResponse response) {
EndTxnResponse endTxnResponse = (EndTxnResponse) response;
Errors error = endTxnResponse.error();
if (error == Errors.NONE) {
completeTransaction();
result.done();
} else if (error == Errors.COORDINATOR_NOT_AVAILABLE || error == Errors.NOT_COORDINATOR) {
lookupCoordinator(FindCoordinatorRequest.CoordinatorType.TRANSACTION, transactionalId);
reenqueue();
} else if (error == Errors.COORDINATOR_LOAD_IN_PROGRESS || error == Errors.CONCURRENT_TRANSACTIONS) {
reenqueue();
} else if (error == Errors.INVALID_PRODUCER_EPOCH) {
fatalError(error.exception());
}
// ...
}TransactionManager#completeTransaction:正常结束事务,清空所有状态,清空事务中的分区。
java
private void completeTransaction() {
transitionTo(State.READY);
lastError = null;
epochBumpRequired = false;
transactionStarted = false;
newPartitionsInTransaction.clear();
pendingPartitionsInTransaction.clear();
partitionsInTransaction.clear();
}4-2、协调者
协调者还是一样,查询事务元数据TransactionMetadata→校验元数据→组装元数据变更TxnTransitMetadata→写消息到_transactionstate下的协调者分区→新元数据更新到内存。
TransactionCoordinator#endTransaction:
1)正常情况,事务处于Ongoing状态(事务中),元数据只变更状态为PrepareCommit/PrepareAbort,即预提交/回滚;
2)如果事务已经提交,即CompleteCommit,可能是客户端侧超时重试,重复发来提交请求,直接返回成功;
3)如果事务提交中,即PrepareCommit,可能是客户端侧超时重试,返回CONCURRENT_TRANSACTIONS,客户端框架层面会自行requeue,重试EndTxnRequest;
scala
val preAppendResult: ApiResult[(Int, TxnTransitMetadata)] =
// 1. 查询事务元数据TransactionMetadata
txnManager.getTransactionState(transactionalId).flatMap {
case Some(epochAndTxnMetadata) =>
val txnMetadata = epochAndTxnMetadata.transactionMetadata
val coordinatorEpoch = epochAndTxnMetadata.coordinatorEpoch
txnMetadata.inLock {
//... 2. 校验元数据 producerId producerEpoch等
txnMetadata.state match {
case Ongoing =>
// 正常提交/回滚,走这里
val nextState = if (txnMarkerResult == TransactionResult.COMMIT)
PrepareCommit
else
PrepareAbort
// 3. 组装元数据变更TxnTransitMetadata
Right(coordinatorEpoch, txnMetadata.prepareAbortOrCommit(nextState, time.milliseconds()))
case CompleteCommit =>
// 如果已经提交,返回成功
if (txnMarkerResult == TransactionResult.COMMIT)
Left(Errors.NONE)
case PrepareCommit =>
// 如果提交中,返回CONCURRENT_TRANSACTIONS,客户端自动重试
if (txnMarkerResult == TransactionResult.COMMIT)
Left(Errors.CONCURRENT_TRANSACTIONS)
//...
}
}
}
}TransactionCoordinator#endTransaction:
4)预提交状态写消息成功后,新元数据更新到内存;
5)准备最终状态变更,状态=CompleteCommit/CompleteAbort,事务中的分区=空;
6)这里就直接响应客户端提交成功了,实际上还并没真实提交,后续状态推进由协调者完成,如果协调者宕机,新的协调者(这个transactionalId对应协调者分区leader)也可以发现有事务处于预提交状态,从7开始恢复;
7)协调者执行最终提交;
scala
preAppendResult match {
case Left(err) =>
responseCallback(err)
case Right((coordinatorEpoch, newMetadata)) =>
def sendTxnMarkersCallback(error: Errors): Unit = {
if (error == Errors.NONE) {
// 5. 写PrepareCommit日志成功,再次准备下一次状态变更,校验元数据
val preSendResult: ApiResult[(TransactionMetadata, TxnTransitMetadata)] = txnManager.getTransactionState(transactionalId).flatMap {
//...
}
preSendResult match {
case Left(err) =>
responseCallback(err)
case Right((txnMetadata, newPreSendMetadata)) =>
// 6. 响应客户端成功
responseCallback(Errors.NONE)
// 7. 发送 marker 给 事务中的broker
// coordinatorEpoch = 协调者分区leaderEpoch,txnMarkerResult=提交/回滚
// txnMetadata 状态=PrepareCommit/PrepareAbort
// newPreSendMetadata 状态=CompleteCommit/CompleteAbort,分区=Empty
txnMarkerChannelManager.addTxnMarkersToSend(coordinatorEpoch, txnMarkerResult, txnMetadata, newPreSendMetadata)
}
} else {
responseCallback(error)
}
}
// 4. 写TxnTransitMetadata到__transaction_state,状态变更为newMetadata(PrepareCommit/PrepareAbort)
txnManager.appendTransactionToLog(transactionalId, coordinatorEpoch, newMetadata, sendTxnMarkersCallback)
}TransactionMarkerChannelManager#addTxnMarkersToSend:
1)异步向事务涉及的broker(事务中注册的分区对应的leaderBroker)发送WriteTxnMarkersRequest;
2)如果所有broker响应成功,将事务元数据最终状态=CompleteCommit/CompleteAbort,分区=Empty,写入__transaction_state;(如果这里失败,这里有重试,忽略)
scala
def addTxnMarkersToSend(coordinatorEpoch: Int,
txnResult: TransactionResult,
txnMetadata: TransactionMetadata,
newMetadata: TxnTransitMetadata): Unit = {
val transactionalId = txnMetadata.transactionalId
val pendingCompleteTxn = PendingCompleteTxn(
transactionalId,
coordinatorEpoch,
txnMetadata,
newMetadata)
// 待提交事务
transactionsWithPendingMarkers.put(transactionalId, pendingCompleteTxn)
// 事务包含多个分区,按照leaderBroker分组,异步发送WriteTxnMarkersRequest
addTxnMarkersToBrokerQueue(transactionalId, txnMetadata.producerId,
txnMetadata.producerEpoch, txnResult, coordinatorEpoch, txnMetadata.topicPartitions.toSet)
// 如果事务提交成功,newMetadata写入__transaction_state
maybeWriteTxnCompletion(transactionalId)
}TransactionMarkerChannelManager自身是一个线程,可以与broker通讯,发送WriteTxnMarkersRequest。
scala
class TransactionMarkerChannelManager(config: KafkaConfig,
metadataCache: MetadataCache,
networkClient: NetworkClient,
txnStateManager: TransactionStateManager,
time: Time)
extends InterBrokerSendThread("TxnMarkerSenderThread-" + config.brokerId, networkClient, time)
with Logging with KafkaMetricsGroup {
// brokerId -> 待发送WriteTxnMarkersRequest
private val markersQueuePerBroker: concurrent.Map[Int, TxnMarkerQueue]
= new ConcurrentHashMap[Int, TxnMarkerQueue]().asScala
}
class TxnMarkerQueue(@volatile var destination: Node) {
// 分区 -> 待发送WriteTxnMarkersRequest(无界队列)
private val markersPerTxnTopicPartition
= new ConcurrentHashMap[Int, BlockingQueue[TxnIdAndMarkerEntry]]().asScala
}WriteTxnMarkersRequest:
java
public class WriteTxnMarkersRequest extends AbstractRequest {
public final WriteTxnMarkersRequestData data;
public class WriteTxnMarkersRequestData implements ApiMessage {
// n个producer的结束事务可以批量发送
private List<WritableTxnMarker> markers;
}
static public class WritableTxnMarker implements Message {
private long producerId;
private short producerEpoch;
// true-提交 false-回滚
private boolean transactionResult;
// 事务里的n个topic分区
private List<WritableTxnMarkerTopic> topics;
private int coordinatorEpoch;
}
static public class WritableTxnMarkerTopic implements Message {
private String name;
private List<Integer> partitionIndexes;
}
}4-3、broker
各个broker中的事务相关分区,由于事务消息的写入,导致存在LSO,限制了RC隔离级别消费者消费。
当各broker处理完成协调者的WriteTxnMarkersRequest,LSO可能会增加,从而消费者可以消费到提交后的消息。
注意到WriteTxnMarkersRequest中没有offset相关概念,因为事务消息有顺序,只需要通过producerId就能从broker找到挂起的offset(broker管理了producer状态),从而改变LSO。
kafka.server.KafkaApis#handleWriteTxnMarkersRequest:对所有事务内的分区,写入事务提交/回滚标记EndTransactionMarker 消息,称为控制批次controlBatch。
scala
// 写入控制批次
val controlRecords = partitionsWithCompatibleMessageFormat.map { partition =>
val controlRecordType = marker.transactionResult match {
case TransactionResult.COMMIT => ControlRecordType.COMMIT
case TransactionResult.ABORT => ControlRecordType.ABORT
}
val endTxnMarker = new EndTransactionMarker(controlRecordType, marker.coordinatorEpoch)
// 分区 -> 控制批次(key=提交/回滚,value=controllerEpoch-协调者分区的leaderEpoch)
// 批次头包含producerId等
partition -> MemoryRecords.withEndTransactionMarker(producerId, marker.producerEpoch, endTxnMarker)
}.toMap
replicaManager.appendRecords(
timeout = config.requestTimeoutMs.toLong,
// acks=-1
requiredAcks = -1,
internalTopicsAllowed = true,
origin = AppendOrigin.Coordinator,
entriesPerPartition = controlRecords,
responseCallback = maybeSendResponseCallback(producerId, marker.transactionResult))Log#append:写消息过程中处理控制批次逻辑。
scala
private def append(records: MemoryRecords,
origin: AppendOrigin,
interBrokerProtocolVersion: ApiVersion,
assignOffsets: Boolean,
leaderEpoch: Int,
ignoreRecordSize: Boolean): LogAppendInfo = {
maybeHandleIOException(s"Error while appending records to $topicPartition in dir ${dir.getParent}") {
// 1. 校验并组装LogAppendInfo
val appendInfo = analyzeAndValidateRecords(records, origin, ignoreRecordSize)
lock synchronized { // log级别锁,同一个分区不能并发写
// 校验并继续填充LogAppendInfo
// ...
// 2. 处理segment滚动...
val segment = maybeRoll(validRecords.sizeInBytes, appendInfo)
val logOffsetMetadata = LogOffsetMetadata(
messageOffset = appendInfo.firstOrLastOffsetOfFirstBatch,
segmentBaseOffset = segment.baseOffset,
relativePositionInSegment = segment.size)
// 【事务】幂等/事务处理(用户消息、控制消息)
// case2 事务协调者写入控制批次 completedTxns(List[CompletedTxn]) = 当前写入控制批次(提交/回滚)
val (updatedProducers, completedTxns, maybeDuplicate) = analyzeAndValidateProducerState(
logOffsetMetadata, validRecords, origin)
// 幂等命中直接返回(用户消息)....
// 3. 写segment(用户消息、控制消息)
segment.append(largestOffset = appendInfo.lastOffset,
largestTimestamp = appendInfo.maxTimestamp,
shallowOffsetOfMaxTimestamp = appendInfo.offsetOfMaxTimestamp,
records = validRecords)
// 4. 更新LEO,下次append的批次的offset从这里开始
updateLogEndOffset(appendInfo.lastOffset + 1)
// 【事务】处理生产者状态(用户消息、控制消息)...
// 【事务】处理完成的事务(控制消息)
for (completedTxn <- completedTxns) {
// 计算分区新LSO
val lastStableOffset = producerStateManager.lastStableOffset(completedTxn)
// 如果Abort,插入事务索引
segment.updateTxnIndex(completedTxn, lastStableOffset)
// ongoingTxns-批次->unreplicatedTxns
producerStateManager.completeTxn(completedTxn)
}
producerStateManager.updateMapEndOffset(appendInfo.lastOffset + 1)
// 【事务】更新unstable offset(用户消息、控制消息)
maybeIncrementFirstUnstableOffset()
// 5. 刷盘逻辑,flush.messages=Long.MAX_VALUE,配置成1则每次append都fsync
if (unflushedMessages >= config.flushInterval)
flush()
// 返回LogAppendInfo
appendInfo
}
}
}ProducerAppendInfo#append:写控制批次前,校验并构造CompletedTxn和需要更新的ProducerStateEntry。
scala
def append(batch: RecordBatch, firstOffsetMetadataOpt: Option[LogOffsetMetadata]): Option[CompletedTxn] = {
if (batch.isControlBatch) {
// 控制批次
val recordIterator = batch.iterator
if (recordIterator.hasNext) {
val record = recordIterator.next()
val endTxnMarker = EndTransactionMarker.deserialize(record)
// 构造CompletedTxn和需要更新的ProducerStateEntry
val completedTxn = appendEndTxnMarker(endTxnMarker, batch.producerEpoch, batch.baseOffset, record.timestamp)
Some(completedTxn)
} else {
None
}
} else {
// 正常事务中的消息
val firstOffsetMetadata = firstOffsetMetadataOpt.getOrElse(LogOffsetMetadata(batch.baseOffset))
appendDataBatch(batch.producerEpoch, batch.baseSequence, batch.lastSequence, batch.maxTimestamp,
firstOffsetMetadata, batch.lastOffset, batch.isTransactional)
None
}
}
// ProducerAppendInfo#appendEndTxnMarker
def appendEndTxnMarker(endTxnMarker: EndTransactionMarker,
producerEpoch: Short,
offset: Long,
timestamp: Long): CompletedTxn = {
checkProducerEpoch(producerEpoch, offset)
// 如果发现controllerEpoch变更,异常
checkCoordinatorEpoch(endTxnMarker, offset)
// 当前挂起的offset
val firstOffset = updatedEntry.currentTxnFirstOffset
// ...
updatedEntry.maybeUpdateProducerEpoch(producerEpoch)
// 设置producer没有挂起的offset
updatedEntry.currentTxnFirstOffset = None
updatedEntry.coordinatorEpoch = endTxnMarker.coordinatorEpoch
updatedEntry.lastTimestamp = timestamp
CompletedTxn(producerId, firstOffset, offset, endTxnMarker.controlType == ControlRecordType.ABORT)
}Log#append:leader写完控制批次消息后,会插入事务索引,并将这批控制消息对应的事务标记为unreplicatedTxns,因为还没复制给follower。
scala
// 【事务】处理完成的事务(当前写入控制批次)
for (completedTxn <- completedTxns) {
// 计算分区新LSO
val lastStableOffset = producerStateManager.lastStableOffset(completedTxn)
// 如果Abort,插入事务索引
segment.updateTxnIndex(completedTxn, lastStableOffset)
// ongoingTxns-批次->unreplicatedTxns
producerStateManager.completeTxn(completedTxn)
}事务索引结构为AbortedTxn,最终落盘后体现为.txnindex文件,和其他索引一样,每segment一个。
scala
private[log] class AbortedTxn(val buffer: ByteBuffer) {
import AbortedTxn._
def this(producerId: Long,
firstOffset: Long,
lastOffset: Long,
lastStableOffset: Long) = {
this(ByteBuffer.allocate(AbortedTxn.TotalSize))
// 数据协议版本0
buffer.putShort(CurrentVersion)
buffer.putLong(producerId)
// 本事务消息的第一个offset
buffer.putLong(firstOffset)
// 本事务消息的最后一个offset(控制批次的offset)
buffer.putLong(lastOffset)
// 完成事务后的LSO
buffer.putLong(lastStableOffset)
buffer.flip()
}
}ProducerStateManager#completeTxn:事务起始offset,从ongoingTxns移动到unreplicatedTxns。
scala
// 还未提交的事务:消息批次起始offset -> 事务元数据
private val ongoingTxns = new util.TreeMap[Long, TxnMetadata]
// 已经提交/回滚的事务,但是还未复制到follower:消息批次起始offset -> 事务元数据
private val unreplicatedTxns = new util.TreeMap[Long, TxnMetadata]
def completeTxn(completedTxn: CompletedTxn): Unit = {
val txnMetadata = ongoingTxns.remove(completedTxn.firstOffset)
txnMetadata.lastOffset = Some(completedTxn.lastOffset)
unreplicatedTxns.put(completedTxn.firstOffset, txnMetadata)
}Log#updateHighWatermarkMetadata:follower从leader复制消息,导致HW高水位提升后,移除unreplicatedTxns中的事务,最终提升LSO(LastStableOffset),消息对RC隔离级别消费者可见。
LSO的计算逻辑在前面写消息部分提到了,要用ongoingTxns和unreplicatedTxns共同决定。
scala
private def updateHighWatermarkMetadata(newHighWatermark: LogOffsetMetadata): Unit = {
lock synchronized {
highWatermarkMetadata = newHighWatermark
// unreplicatedTxns移除HW之前的事务
producerStateManager.onHighWatermarkUpdated(newHighWatermark.messageOffset)
// 计算LSO
maybeIncrementFirstUnstableOffset()
}
}
// ProducerStateManager
def onHighWatermarkUpdated(highWatermark: Long): Unit = {
removeUnreplicatedTransactions(highWatermark)
}
private def removeUnreplicatedTransactions(offset: Long): Unit = {
val iterator = unreplicatedTxns.entrySet.iterator
while (iterator.hasNext) {
val txnEntry = iterator.next()
val lastOffset = txnEntry.getValue.lastOffset
if (lastOffset.exists(_ < offset))
iterator.remove()
}
}4-4、consumer
consumer如果设置RC隔离级别,broker可以通过LSO控制在事务提交后才能消费到消息。
但是如果事务回滚,如何让消息不可见?
FetchResponse.PartitionData:实际上,消费者会从Broker拉取到回滚的消息,但同时也会拉到回滚的事务信息AbortedTransaction。
java
public static final class PartitionData<T extends BaseRecords> {
public final Errors error;
public final long highWatermark;
public final long lastStableOffset;
public final long logStartOffset;
public final Optional<Integer> preferredReadReplica;
// 这批消息相关的回滚事务
public final List<AbortedTransaction> abortedTransactions;
// MemoryRecords 包含多个消息批次
public final T records;
}Log#addAbortedTransactions:broker在拉取完消息后,如果隔离级别是RC,会拉取这批消息相关的中断事务信息,从事务索引中获取。
scala
// 收集AbortedTransaction
private def addAbortedTransactions(
// 消费进度
startOffset: Long,
// 当前正在读取的segment 起始offset->segment
segmentEntry: JEntry[JLong, LogSegment],
// 拉到的消息
fetchInfo: FetchDataInfo): FetchDataInfo = {
val fetchSize = fetchInfo.records.sizeInBytes
// 起始offset --- 拉到的消息的第一个offset
val startOffsetPosition = OffsetPosition(fetchInfo.fetchOffsetMetadata.messageOffset,
fetchInfo.fetchOffsetMetadata.relativePositionInSegment)
// 根据拉取大小 得到结束位点
val upperBoundOffset = segmentEntry.getValue.fetchUpperBoundOffset(startOffsetPosition, fetchSize).getOrElse {
val nextSegmentEntry = segments.higherEntry(segmentEntry.getKey)
if (nextSegmentEntry != null)
nextSegmentEntry.getValue.baseOffset
else
logEndOffset
}
// 收集中断事务
val abortedTransactions = ListBuffer.empty[AbortedTransaction]
def accumulator(abortedTxns: List[AbortedTxn]): Unit = abortedTransactions ++= abortedTxns.map(_.asAbortedTransaction)
collectAbortedTransactions(startOffset, upperBoundOffset, segmentEntry, accumulator)
FetchDataInfo(fetchOffsetMetadata = fetchInfo.fetchOffsetMetadata,
records = fetchInfo.records,
firstEntryIncomplete = fetchInfo.firstEntryIncomplete,
abortedTransactions = Some(abortedTransactions.toList))
}
private def collectAbortedTransactions(startOffset: Long,
upperBoundOffset: Long,
startingSegmentEntry: JEntry[JLong, LogSegment],
accumulator: List[AbortedTxn] => Unit): Unit = {
var segmentEntry = startingSegmentEntry
while (segmentEntry != null) {
val searchResult = segmentEntry.getValue.collectAbortedTxns(startOffset, upperBoundOffset)
accumulator(searchResult.abortedTransactions)
if (searchResult.isComplete)
return
segmentEntry = segments.higherEntry(segmentEntry.getKey)
}
}
// LogSegment#collectAbortedTxns 从事务索引获取中断事务
def collectAbortedTxns(fetchOffset: Long, upperBoundOffset: Long): TxnIndexSearchResult =
txnIndex.collectAbortedTxns(fetchOffset, upperBoundOffset)Fetcher.CompletedFetch#nextFetchedRecord:consumer处理消息,自行跳过回滚的事务消息和控制批次。
java
// 回滚事务信息
private final PriorityQueue<FetchResponse.AbortedTransaction> abortedTransactions;
// 遍历到处于回滚的producerId
private final Set<Long> abortedProducerIds;
// 正在迭代的n个消息批次
private final Iterator<? extends RecordBatch> batches;
private Record nextFetchedRecord() {
while (true) {
// ....
if (isolationLevel == IsolationLevel.READ_COMMITTED && currentBatch.hasProducerId()) {
// 1. 将中断producerId加入abortedProducerIds
consumeAbortedTransactionsUpTo(currentBatch.lastOffset());
long producerId = currentBatch.producerId();
if (containsAbortMarker(currentBatch)) {
// 3. 如果是【控制批次且回滚】,abortedProducerIds中移除该producerId,后续该producerId消息可见
abortedProducerIds.remove(producerId);
} else if (isBatchAborted(currentBatch)) {
// 2. 如果是【用户消息且被当前批次的producerId在abortedProducerIds中】,代表被回滚,跳过这批消息
nextFetchOffset = currentBatch.nextOffset();
continue;
}
}
if (!currentBatch.isControlBatch()) {
return record;
} else {
// 跳过控制批次
nextFetchOffset = record.offset() + 1;
}
}
}
private void consumeAbortedTransactionsUpTo(long offset) {
if (abortedTransactions == null)
return;
while (!abortedTransactions.isEmpty() && abortedTransactions.peek().firstOffset <= offset) {
FetchResponse.AbortedTransaction abortedTransaction = abortedTransactions.poll();
abortedProducerIds.add(abortedTransaction.producerId);
}
}
// 是否是回滚控制批次
private boolean containsAbortMarker(RecordBatch batch) {
if (!batch.isControlBatch())
return false;
Iterator<Record> batchIterator = batch.iterator();
if (!batchIterator.hasNext())
return false;
Record firstRecord = batchIterator.next();
return ControlRecordType.ABORT == ControlRecordType.parse(firstRecord.key());
}
// 这个事务消息的批次被回滚了
private boolean isBatchAborted(RecordBatch batch) {
return batch.isTransactional()
&& abortedProducerIds.contains(batch.producerId());
}4-5、事务超时
TransactionCoordinator#startup:事务协调者每10s扫描一次是否有事务超时。
scala
def startup(enableTransactionalIdExpiration: Boolean = true): Unit = {
// 10s检测一次超时事务
scheduler.schedule("transaction-abort",
() => abortTimedOutTransactions(onEndTransactionComplete),
txnConfig.abortTimedOutTransactionsIntervalMs,
txnConfig.abortTimedOutTransactionsIntervalMs
)
}TransactionCoordinator#abortTimedOutTransactions:事务协调者,扫描所有超时事务,自动执行回滚,回滚完成后producerEpoch+1。
scala
private[transaction] def abortTimedOutTransactions(onComplete: TransactionalIdAndProducerIdEpoch => EndTxnCallback): Unit = {
// 1. 扫描所有超时事务
txnManager.timedOutTransactions().foreach { txnIdAndPidEpoch =>
txnManager.getTransactionState(txnIdAndPidEpoch.transactionalId).foreach {
case None =>
case Some(epochAndTxnMetadata) =>
val txnMetadata = epochAndTxnMetadata.transactionMetadata
val transitMetadataOpt = txnMetadata.inLock {
if (txnMetadata.producerId != txnIdAndPidEpoch.producerId) {
None
} else if (txnMetadata.pendingTransitionInProgress) {
// 2-1. 如果事务元数据正在变更,暂时不回滚
None
} else {
// 2-2. 否则,需要回滚,回滚完成后producerEpoch+1
Some(txnMetadata.prepareFenceProducerEpoch())
}
}
// 3. 回滚事务
transitMetadataOpt.foreach { txnTransitMetadata =>
endTransaction(txnMetadata.transactionalId,
txnTransitMetadata.producerId,
txnTransitMetadata.producerEpoch,
TransactionResult.ABORT,
isFromClient = false,
onComplete(txnIdAndPidEpoch))
}
}
}
}TransactionStateManager#timedOutTransactions:协调者扫描超时事务
1)生产者初始化,上报事务超时时间transaction.timeout.ms默认60s;
2)生产者首次将分区加入事务,状态翻转Onging代表事务开始,记录事务开始时间;
3)即超时时间=分区首次加入事务+60s;
scala
private[transaction] val transactionMetadataCache: mutable.Map[Int, TxnMetadataCacheEntry] = mutable.Map()
def timedOutTransactions(): Iterable[TransactionalIdAndProducerIdEpoch] = {
val now = time.milliseconds()
inReadLock(stateLock) {
transactionMetadataCache.flatMap { case (_, entry) =>
entry.metadataPerTransactionalId.filter { case (_, txnMetadata) =>
if (txnMetadata.pendingTransitionInProgress) {
false
} else {
txnMetadata.state match {
// 事务中第一次收到AddPartition
// 状态 => Ongoing, 记录txnStartTimestamp事务开始时间
case Ongoing =>
txnMetadata.txnStartTimestamp + txnMetadata.txnTimeoutMs < now
case _ => false
}
}
}.map { case (txnId, txnMetadata) =>
TransactionalIdAndProducerIdEpoch(txnId, txnMetadata.producerId, txnMetadata.producerEpoch)
}
}
}当生产者在超时后发起任何请求,比如发送消息给broker、结束事务给协调者,因为producerEpoch已经改变,都会响应ProducerFencedException,此时生产者会进入FATAL_ERROR状态,唯一处理方式是关闭后重新启动。
五、精确一次
Kafka经常会提到精确一次ExcatlyOnce,常见使用场景是结合Flink的CheckPoint实现端到端精确一次,具体案例参考官方ExactlyOnceMessageProcessor。
scala
/**
* A demo class for how to write a customized EOS app. It takes a consume-process-produce loop.
* Important configurations and APIs are commented.
*/
public class ExactlyOnceMessageProcessor extends Thread {
}精确一次指的是consume-process-produce 循环:从来源topic消费消息,经过数据处理,写入目标topic。因为消费进度实际上会作为消息,由消费组协调者 存储在 __consumeoffset中,所以可以一起加入事务(producer#sendOffsetsToTransaction)。
注:每次poll到消息会改变consumer内存中的消费进度,所以如果回滚事务,需要重新通过seek api回滚消费进度。
java
public void run() {
// 1. 事务生产者 初始化事务
producer.initTransactions();
final AtomicLong messageRemaining = new AtomicLong(Long.MAX_VALUE);
// 2. 消费者订阅
consumer.subscribe(Collections.singleton(inputTopic));
int messageProcessed = 0;
while (messageRemaining.get() > 0) {
try {
// 3. 消费者拉消息
ConsumerRecords<Integer, String> records = consumer.poll(Duration.ofMillis(200));
if (records.count() > 0) {
// 4. 开启事务
producer.beginTransaction();
for (ConsumerRecord<Integer, String> record : records) {
// 5. 数据处理
ProducerRecord<Integer, String> customizedRecord = transform(record);
// 6. 写事务消息
producer.send(customizedRecord);
}
// 7. 在事务里发送当前分区消费进度
Map<TopicPartition, OffsetAndMetadata> offsets = consumerOffsets();
producer.sendOffsetsToTransaction(offsets, consumer.groupMetadata());
// 8. 提交事务
producer.commitTransaction();
messageProcessed += records.count();
}
} catch (ProducerFencedException e) {
throw new KafkaException(String.format("The transactional.id %s has been claimed by another process", transactionalId));
} catch (FencedInstanceIdException e) {
throw new KafkaException(String.format("The group.instance.id %s has been claimed by another process", groupInstanceId));
} catch (KafkaException e) {
// 9. 发生异常,回滚事务
producer.abortTransaction();
// 10. 重新从coordinator获取消费进度,回滚消费进度
resetToLastCommittedPositions(consumer);
}
messageRemaining.set(messagesRemaining(consumer));
}
}5-1、AddOffsetsToTxnRequest
TransactionManager#sendOffsetsToTransaction:sendOffsetsToTransaction实际上是发送AddOffsetsToTxnRequest给事务协调者,包含消费组id。
java
public synchronized TransactionalRequestResult sendOffsetsToTransaction(final Map<TopicPartition, OffsetAndMetadata> offsets,
final ConsumerGroupMetadata groupMetadata) {
AddOffsetsToTxnRequest.Builder builder = new AddOffsetsToTxnRequest.Builder(
new AddOffsetsToTxnRequestData()
.setTransactionalId(transactionalId)
.setProducerId(producerIdAndEpoch.producerId)
.setProducerEpoch(producerIdAndEpoch.epoch)
.setGroupId(groupMetadata.groupId())
);
AddOffsetsToTxnHandler handler = new AddOffsetsToTxnHandler(builder, offsets, groupMetadata);
enqueueRequest(handler);
return handler.result;
}KafkaApis#handleAddOffsetsToTxnRequest:事务协调者 的处理方式,同AddPartitionsToTxnRequest 普通事务消息的分区加入事务一样,只是这个分区是消费组id对应的消费组协调者分区(partition=hash(groupId)%50)。
scala
def handleAddOffsetsToTxnRequest(request: RequestChannel.Request): Unit = {
val addOffsetsToTxnRequest = request.body[AddOffsetsToTxnRequest]
val transactionalId = addOffsetsToTxnRequest.data.transactionalId
val groupId = addOffsetsToTxnRequest.data.groupId
// 获取消费组对应__consumer_offsets消费组协调者分区
val offsetTopicPartition = new TopicPartition(GROUP_METADATA_TOPIC_NAME, groupCoordinator.partitionFor(groupId))
// ... 其他校验
txnCoordinator.handleAddPartitionsToTransaction(transactionalId,
addOffsetsToTxnRequest.data.producerId,
addOffsetsToTxnRequest.data.producerEpoch,
Set(offsetTopicPartition),
sendResponseCallback)
}5-2、TxnOffsetCommitRequest
AddOffsetsToTxnHandler:producer收到AddOffsetsToTxnResponse 成功,代表事务协调者分区已经成功加入事务,发送TxnOffsetCommitRequest 事务offset提交请求给消费组协调者,其中的特点是,提交offset包含了producerId和epoch。
java
private class AddOffsetsToTxnHandler extends TxnRequestHandler {
private final AddOffsetsToTxnRequest.Builder builder;
private final Map<TopicPartition, OffsetAndMetadata> offsets;
private final ConsumerGroupMetadata groupMetadata;
@Override
public void handleResponse(AbstractResponse response) {
AddOffsetsToTxnResponse addOffsetsToTxnResponse = (AddOffsetsToTxnResponse) response;
Errors error = Errors.forCode(addOffsetsToTxnResponse.data.errorCode());
if (error == Errors.NONE) {
pendingRequests.add(txnOffsetCommitHandler(result, offsets, groupMetadata));
transactionStarted = true;
}
}
}
private TxnOffsetCommitHandler txnOffsetCommitHandler(TransactionalRequestResult result,
Map<TopicPartition, OffsetAndMetadata> offsets,
ConsumerGroupMetadata groupMetadata) {
for (Map.Entry<TopicPartition, OffsetAndMetadata> entry : offsets.entrySet()) {
OffsetAndMetadata offsetAndMetadata = entry.getValue();
CommittedOffset committedOffset = new CommittedOffset(offsetAndMetadata.offset(),
offsetAndMetadata.metadata(), offsetAndMetadata.leaderEpoch());
pendingTxnOffsetCommits.put(entry.getKey(), committedOffset);
}
final TxnOffsetCommitRequest.Builder builder =
new TxnOffsetCommitRequest.Builder(transactionalId,
groupMetadata.groupId(),
producerIdAndEpoch.producerId,
producerIdAndEpoch.epoch,
pendingTxnOffsetCommits,
groupMetadata.memberId(),
groupMetadata.generationId(),
groupMetadata.groupInstanceId(),
autoDowngradeTxnCommit
);
return new TxnOffsetCommitHandler(result, builder);
}GroupMetadataManager#storeOffsets:消费组协调者处理事务offset提交
1)消费进度消息中会包含producerId/epoch/是否事务提交,后续回放可以恢复内存状态;
2)内存记录:producerId→事务中groupId;producerId -> (待提交消费分区,消费进度offset);
3)写消费进度到_consumeroffsets;
scala
def storeOffsets(group: GroupMetadata,
consumerId: String,
offsetMetadata: immutable.Map[TopicPartition, OffsetAndMetadata],
responseCallback: immutable.Map[TopicPartition, Errors] => Unit,
producerId: Long = RecordBatch.NO_PRODUCER_ID,
producerEpoch: Short = RecordBatch.NO_PRODUCER_EPOCH): Unit = {
// 有producerId的offset提交,认为是事务offset提交
val isTxnOffsetCommit = producerId != RecordBatch.NO_PRODUCER_ID
getMagic(partitionFor(group.groupId)) match {
case Some(magicValue) =>
// ...
// 消费进度记录,额外包含producerId/epoch/isTxnOffsetCommit
val builder = MemoryRecords.builder(buffer, magicValue, compressionType, timestampType, 0L, time.milliseconds(),
producerId, producerEpoch, 0, isTxnOffsetCommit, RecordBatch.NO_PARTITION_LEADER_EPOCH)
records.foreach(builder.append)
val entries = Map(offsetTopicPartition -> builder.build())
if (isTxnOffsetCommit) {
// 如果是 事务消费offset提交
group.inLock {
// 内存记录producerId -> 事务中的groupId
addProducerGroup(producerId, group.groupId)
// 消费组元数据记录 producerId -> (待提交消费分区,消费进度offset)
group.prepareTxnOffsetCommit(producerId, offsetMetadata)
}
} else {
group.inLock {
group.prepareOffsetCommit(offsetMetadata)
}
}
// 写__consumer_offsets
appendForGroup(group, entries, putCacheCallback)
}
}5-3、OffsetFetchRequest
事务中的消息对RC消费者的影响是不可见;事务中待提交的offset对同组消费者的影响是offset不可见。
低版本中一个消费组只能有一个消费者消费一个分区,事务中的待提交offset其实不影响其他消费者。
但是事务offset的提交取决于事务生产者,有可能消费者已经rebalance了,这个待提交offset的分区已经分配给其他消费者,但是事务还未提交,所以消费者拉取分区消费进度时需要做好隔离。
GroupMetadataManager#getOffsets:协调者收到consumer查询消费进度的请求,如果分区有待提交的offset,则返回UNSTABLE_OFFSET_COMMIT,consumer侧会自动重试。
scala
def getOffsets(groupId: String,
requireStable: Boolean,
topicPartitionsOpt: Option[Seq[TopicPartition]]):
Map[TopicPartition, PartitionData] = {
// ...
topicPartitions.map { topicPartition =>
if (requireStable
&& group.hasPendingOffsetCommitsForTopicPartition(topicPartition)) {
// 如果分区有事务中的offset,返回UNSTABLE_OFFSET_COMMIT,消费者客户端会重试
topicPartition -> new PartitionData(OffsetFetchResponse.INVALID_OFFSET,
Optional.empty(), "", Errors.UNSTABLE_OFFSET_COMMIT)
} else {
// 正常获取消费进度...
val partitionData = group.offset(topicPartition)
}
}.toMap
}5-4、提交/回滚事务
sendOffsetsToTransaction本质上和addPartition是一样的,将消息分区加入事务。
事务offset处理的区别仅在于broker处理事务协调者的WriteTxnMarkersRequest。
KafkaApis#handleWriteTxnMarkersRequest:写入控制批次后,如果发现本轮事务中包含__consumer_offsets的分区,则处理消费位点提交。
scala
def handleWriteTxnMarkersRequest(request: RequestChannel.Request): Unit = {
def maybeSendResponseCallback(producerId: Long, result: TransactionResult)(responseStatus: Map[TopicPartition, PartitionResponse]): Unit = {
val successfulOffsetsPartitions = responseStatus.filter { case (topicPartition, partitionResponse) =>
// 事务中包含__consumer_offsets
topicPartition.topic == GROUP_METADATA_TOPIC_NAME && partitionResponse.error == Errors.NONE
}.keys
if (successfulOffsetsPartitions.nonEmpty) {
// 事务里包含消费位点提交 异步处理
groupCoordinator.scheduleHandleTxnCompletion(producerId, successfulOffsetsPartitions, result)
}
// 响应事务协调者
sendResponseExemptThrottle(request, new WriteTxnMarkersResponse(errors))
}
// 写入控制批次
replicaManager.appendRecords(
timeout = config.requestTimeoutMs.toLong,
// acks=-1
requiredAcks = -1,
internalTopicsAllowed = true,
origin = AppendOrigin.Coordinator,
entriesPerPartition = controlRecords,
responseCallback = maybeSendResponseCallback(producerId, marker.transactionResult))
}
}GroupMetadata#completePendingTxnOffsetCommit:如果提交,更新事务offset到实际offset;否则什么都不做。
scala
// 分区消费进度
private val offsets = new mutable.HashMap[TopicPartition, CommitRecordMetadataAndOffset]
// producerId -> (待提交消费分区,消费进度offset)
private val pendingTransactionalOffsetCommits = new mutable.HashMap[Long, mutable.Map[TopicPartition, CommitRecordMetadataAndOffset]]()
def completePendingTxnOffsetCommit(producerId: Long, isCommit: Boolean): Unit = {
// producerId -> (待提交消费分区,消费进度offset)
val pendingOffsetsOpt = pendingTransactionalOffsetCommits.remove(producerId)
if (isCommit) {
pendingOffsetsOpt.foreach { pendingOffsets =>
pendingOffsets.foreach { case (topicPartition, commitRecordMetadataAndOffset) =>
val currentOffsetOpt = offsets.get(topicPartition)
if (currentOffsetOpt.forall(_.olderThan(commitRecordMetadataAndOffset))) {
// 更新分区的消费进度为pending消费offset
offsets.put(topicPartition, commitRecordMetadataAndOffset)
}
}
}
}
}总结
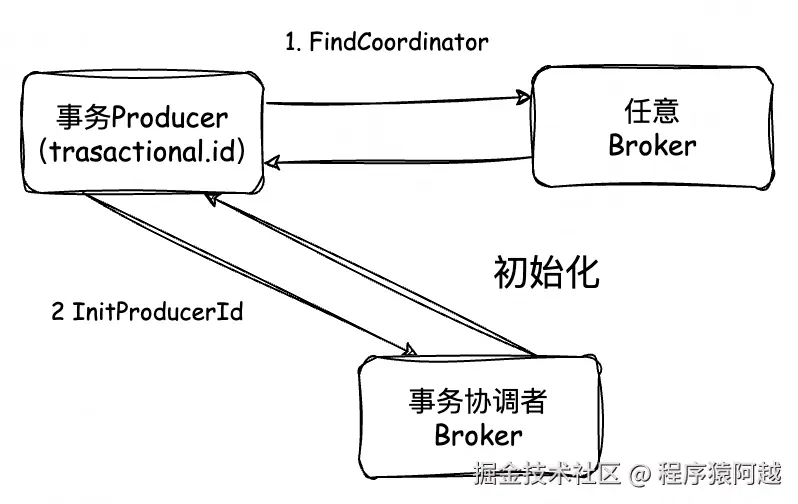
事务生产者初始化:
1)事务生产者,发送FindCoordinator给任意Broker;
2)任意Broker,topic=__transaction_state默认有50个分区,协调者=leader(hash(transactionalId)%50),响应事务生产者;
3)事务生产者,发送InitProducerId给事务协调者;
4)事务协调者,为每个transactionalId分配producerId和epoch给生产者,将元数据变更记录到__transaction_state;
5)事务生产者,记录producerId和epoch,后续所有请求都需要携带这个信息;
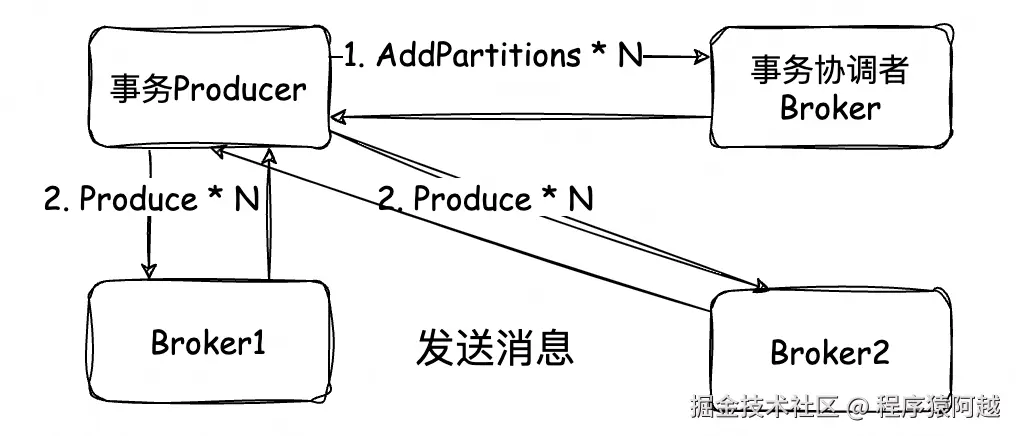
发送消息:
1)事务生产者:发送消息遇到事务中的新分区,先发送AddPartitions给事务协调者;
2)事务协调者:元数据记录事务中的分区(首次AddPartitions代表事务开始,记录事务开始时间),将元数据变更记录到__transaction_state;
3)事务生产者:发送消息给Broker,每个消息批次包含递增序号;
4)Broker:除了消息写入以外,每个topic分区维护producerId对应状态,包括:最近5个消息批次序号-用于幂等校验、producerId对应事务起始offset-用于计算LSO(LastStableOffset,如果RC级别消费者,只有LSO之前消息可见);
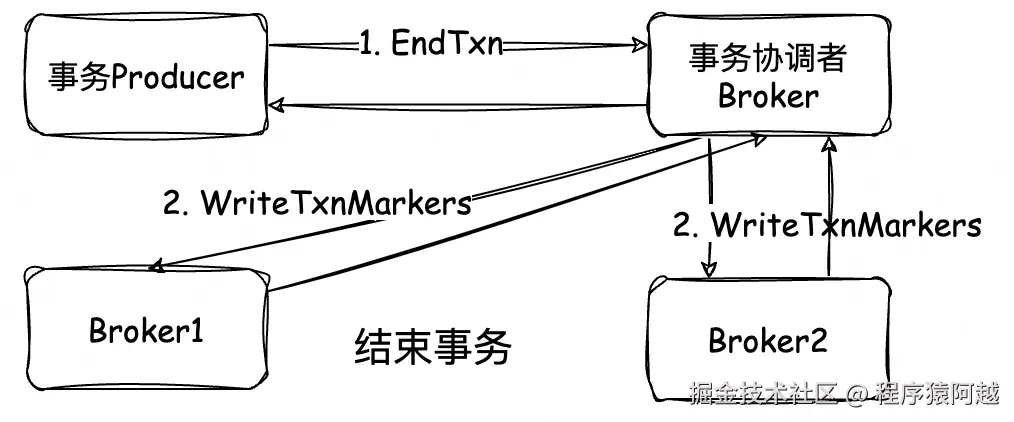
结束事务:
1)事务生产者:发送ExdTxn,提交和回滚通过一个标志位区分;
2)事务协调者:事务元数据变更状态,清空事务中分区,将元数据变更记录到__transaction_state,这一步完成后就会响应生产者成功;
3)事务协调者:异步发送WriteTxnMarkers给事务中所有分区涉及的broker;
4)Broker:在事务相关分区中写入控制批次(key=提交/回滚,value=controllerEpoch-协调者分区的leaderEpoch,批次头包含producerId),当控制批次写入leader成功且follower复制导致HW增加超过本轮事务的offset,LSO增加从而消息对RC消费者可见。如果回滚事务,需要将本轮回滚事务的起始和结束offset记录到事务索引.txnindex文件,后续消费者拉取消息会返回回滚事务信息,由消费者自行过滤不可见消息;
精确一次:
1)指的是consume-process-produce循环,从来源topic消费消息,经过数据处理,写入目标topic;
2)消费进度存储在__consumer_offset这个topic中,本质也是写消息,所以可以纳入一个事务中;
3)生产者,sendOffsetsToTransaction,先调用事务协调者 将__consumer_offset的消费组协调分区加入事务,再调用消费组协调者写入__consumer_offset消费进度(包含producerId,如果故障恢复,依然可以恢复状态,无论提交还是回滚,因为有控制批次)但是内存中挂起offset;
4)事务结束同正常事务消息,只不过消费组协调者broker发现事务中有__consumer_offset相关分区,则内存提交offset;