本文是《大数据环境搭建从零开始》系列教程的第十七篇,将手把手教你如何上传、安装和配置 JDK 17,为后续 Hadoop、Spark 等大数据组件搭建坚实的 Java 运行环境。
一、JDK 17:大数据环境的基石
1.1 为什么选择 JDK 17?
在大数据生态系统中,Java 运行环境是必不可少的基础组件。选择 JDK 17 的主要原因:
-
长期支持:JDK 17 是长期支持版本,稳定性有保障
-
性能优化:相比旧版本,在内存管理和垃圾回收方面有显著改进
-
新特性支持:为现代大数据框架提供更好的兼容性
-
安全更新:持续获得安全补丁,保障生产环境安全
1.2 环境准备
在开始安装前,请确保已完成:
-
✅ 系统更新和源配置
-
✅ lrzsz 工具包安装
-
✅ 目录结构规划
二、JDK 安装包上传详解
2.1 创建软件目录结构
良好的目录结构是规范运维的基础:
切换到软件目录
bash
cd /opt/software/
目录规划说明:
-
/opt/software/:存放原始安装包 -
/opt/module/:存放解压后的软件 -
这种分离管理便于版本控制和清理
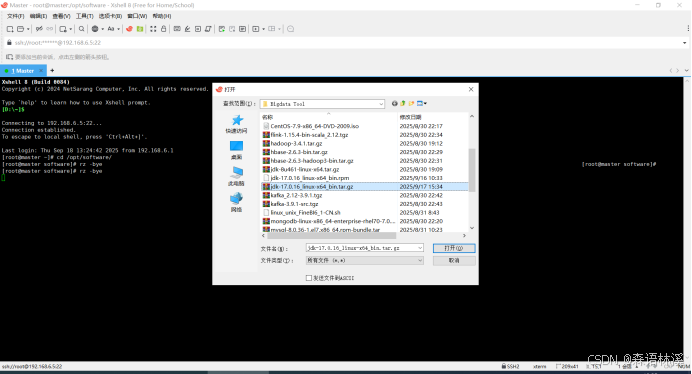
2.2 使用 rz 命令上传安装包
使用 Xshell 的 ZMODEM 协议进行文件上传:
使用 rz 命令上传文件
bash
rz -bye命令参数说明:
-
-b:以二进制方式传输 -
-y:覆盖已存在的文件 -
-e:对所有控制字符进行转义
上传过程如下图所示:
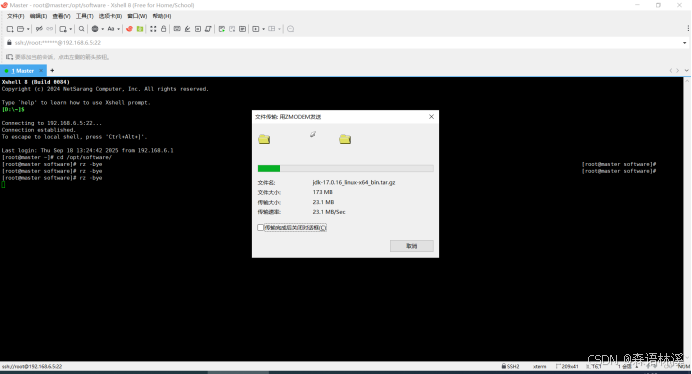
2.3 上传进度与验证
上传过程中请耐心等待,传输时间取决于文件大小和网络速度:
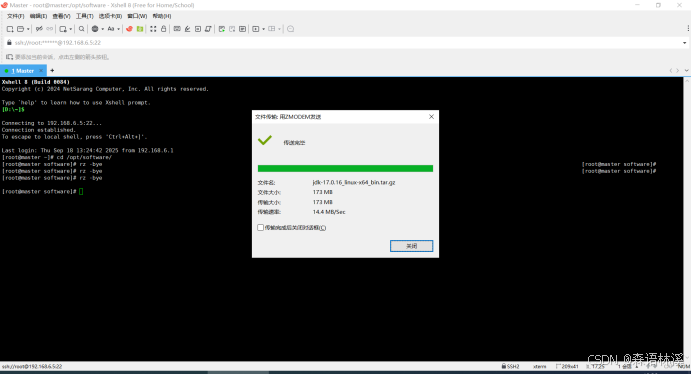
上传完成后,验证文件是否存在:
查看上传的文件
bash
ls -l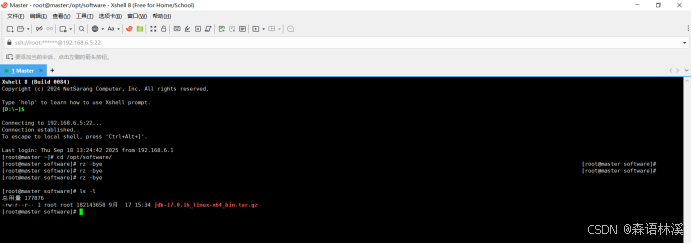
三、JDK 17 解压与安装
3.1 解压安装包到目标目录
将 JDK 解压到模块目录:
解压 JDK 到 module 目录
bash
tar -xvf jdk-17.0.16_linux-x64_bin.tar.gz -C /opt/module/解压过程显示:
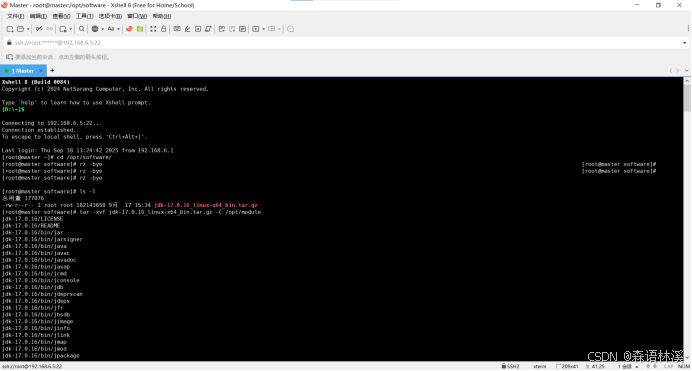
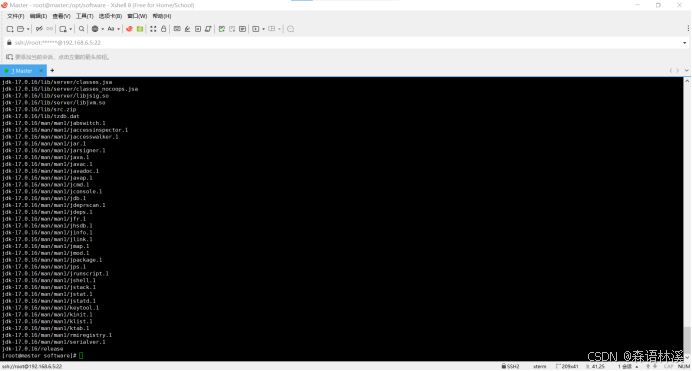
解压参数说明:
-
-x:解压文件 -
-v:显示详细过程 -
-f:指定文件名 -
-C:指定解压目标目录
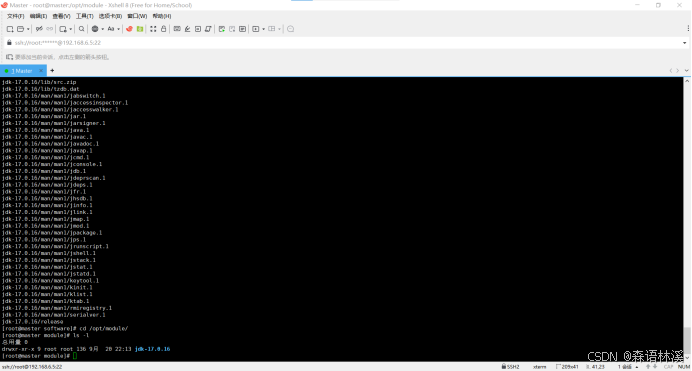
3.2 验证解压结果
检查解压后的目录结构:
切换到模块目录
bash
cd /opt/module/查看解压结果
bash
ls -l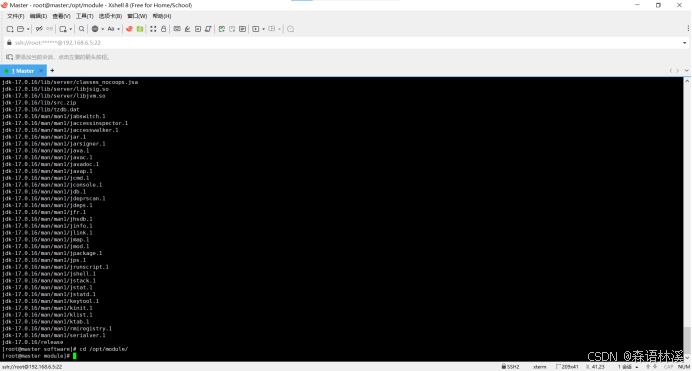
四、环境变量配置深度解析
4.1 编辑系统配置文件
使用 vim 编辑全局环境变量文件:
bash
vim /etc/profile
4.2 配置 JDK 环境变量
按 i 键进入编辑模式,在文件末尾添加以下配置:
bash
# JDK 17 Configuration
export JAVA_HOME=/opt/module/jdk-17.0.16
export JRE_HOME=$JAVA_HOME
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin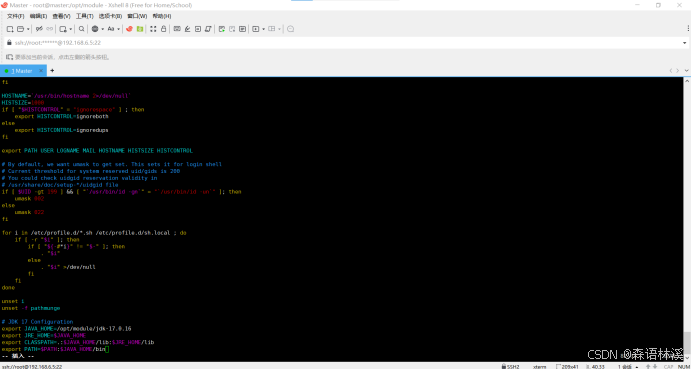
环境变量详解:
| 变量名 | 作用 | 配置值 |
|---|---|---|
JAVA_HOME |
JDK 安装路径 | /opt/module/jdk-17.0.16 |
JRE_HOME |
JRE 路径 | 与 JAVA_HOME 相同 |
CLASSPATH |
类加载路径 | 当前目录和 JDK 库路径 |
PATH |
命令搜索路径 | 添加 JDK bin 目录 |
4.3 保存并退出编辑器
按 ESC 键后输入 :wq 保存文件:
五、环境变量生效与验证
5.1 重新加载配置文件
使环境变量立即生效:
bash
source /etc/profile
5.2 全面验证安装结果
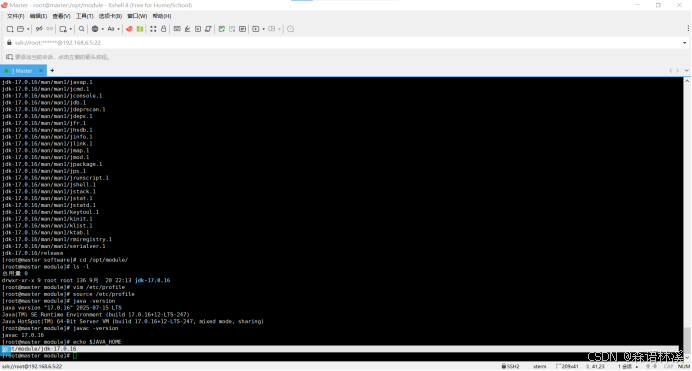
执行以下命令验证 JDK 安装是否成功:
5.2.1 验证 Java 运行时版本
bash
java -version预期输出:
java version "17.0.16" 2024-07-16 LTS
Java(TM) SE Runtime Environment (build 17.0.16+11-LTS-258)
Java HotSpot(TM) 64-Bit Server VM (build 17.0.16+11-LTS-258, mixed mode, sharing)
5.2.2 验证 Java 编译器版本
bash
javac -version预期输出 :javac 17.0.16
5.2.3 验证环境变量配置
bash
echo $JAVA_HOME预期输出 :/opt/module/jdk-17.0.16
完整验证结果:
六、配置原理与技术细节
6.1 环境变量作用域分析
| 配置文件 | 作用范围 | 生效方式 | 适用场景 |
|---|---|---|---|
/etc/profile |
所有用户 | 登录时自动加载 | 系统级配置 |
~/.bashrc |
当前用户 | 交互式shell加载 | 用户级配置 |
~/.bash_profile |
当前用户 | 登录时加载 | 用户环境初始化 |
6.2 JDK 目录结构解析
安装后的 JDK 目录包含以下重要子目录:
-
bin/:Java 工具命令(java、javac、jar 等) -
lib/:库文件和支持文件 -
include/:本地接口头文件 -
jmods/:模块化运行时镜像 -
legal/:法律声明文档
七、故障排查与常见问题
7.1 安装问题诊断
如果验证失败,可以按以下步骤排查:
检查文件权限
bash
ls -ld /opt/module/jdk-17.0.16检查环境变量加载
bash
echo $PATH | tr ':' '\n' | grep java手动执行 Java 命令
bash
/opt/module/jdk-17.0.16/bin/java -version7.2 常见错误解决方案
问题1:命令未找到
-bash: java: command not found
解决方案 :检查环境变量配置是否正确,重新执行 source /etc/profile
问题2:权限拒绝
-bash: /opt/module/jdk-17.0.16/bin/java: Permission denied
解决方案:为 JDK 目录添加执行权限
bash
chmod -R +x /opt/module/jdk-17.0.16/bin/八、JDK 17 新特性在大数据中的应用
8.1 密封类增强类型安全
java
// 定义密封接口,限制实现类
public sealed interface DataProcessor
permits HadoopProcessor, SparkProcessor, FlinkProcessor {
void process(DataFrame data);
}8.2 模式匹配简化代码
java
// 使用模式匹配简化类型检查和转换
if (obj instanceof DataFrame df) {
return df.filter(row -> row.getInt("age") > 18);
}九、生产环境最佳实践
9.1 安全配置建议
限制 JDK 文件权限
bash
chmod -R 755 /opt/module/jdk-17.0.16
bash
chown -R root:root /opt/module/jdk-17.0.16配置 Java 安全策略
bash
cp /opt/module/jdk-17.0.16/conf/security/java.policy /etc/java-17-security/9.2 性能优化配置
在 /etc/profile 中添加性能参数
bash
export JAVA_OPTS="-Xms2g -Xmx4g -XX:+UseG1GC -XX:MaxGCPauseMillis=200"十、版本管理与升级策略
10.1 多版本共存方案
使用 alternatives 管理多版本
bash
alternatives --install /usr/bin/java java /opt/module/jdk-17.0.16/bin/java 3
bash
alternatives --config java10.2 备份与回滚计划
备份环境配置
bash
cp /etc/profile /etc/profile.backup.$(date +%Y%m%d)备份 JDK 目录
bash
tar czf jdk-17.0.16-backup.tar.gz /opt/module/jdk-17.0.16技术总结
通过本教程,我们完整掌握了:
-
使用 rz 命令上传安装包的技巧
-
JDK 解压和目录规划的规范操作
-
系统环境变量的正确配置方法
-
安装结果的全面验证流程
-
故障排查和性能优化策略
现在,你的系统已经具备了运行大数据组件的 Java 环境,为后续的 Hadoop、Hive、Spark 等组件的安装奠定了坚实基础。
下篇预告:接下来我们将开始安装和配置 Hadoop 集群,正式进入大数据世界的核心领域!
觉得这篇文章对你有帮助吗?
👍 点赞 + ⭐ 收藏 + 👁 关注,一键三连,鼓励我继续创作更多优质教程!
系列文章目录:
-
第十七篇:JDK 17 安装与配置完整指南(本文)
-
第十八篇:敬请期待...
有任何 JDK 安装问题,欢迎在评论区留言讨论!