实现AI和BI整合的初步思路和探索
这些年AI火的一塌糊涂,很多行业和传统技术领域都在积极的跟其产生交集。
BI是一个20年前开始火起来的技术,跌跌荡荡这些年,如今虽然不是网红菜,但绝对是企业的必点菜。
AI的出现让很多东西跟人们越来越近,那么AI配合BI有没有搞头呢?

关于这个话题,这些年我也不断的在尝试探索AI跟BI到底能碰撞出什么样的火花。我看到近些年在网上能找到的示例,主要是以下几种应用场景:
- Deepseek in word or excel一类,甚至在Power BI里也有,主要就是通过脚本去调用deepseek的http的接口,B站好多视频,我个人认为这个智能算纯技术探索,实在想不出有什么应用场景。
- 自然语言问答,通过自然语言的方式直接获取答案,第一次看到是在早期版本的Power BI,现在仍保持着这个功能。
- 文件直接生成图表。这个B站的教程很多,算是一个技术领域的介绍吧,但还很难上桌,因为用过Power BI或者Tableau的都会知道,客户对表格的要求是多么变态。
- 基于自然语言的统计,主要是TEXT2SQL这类,通过大预言模型对数据结构的理解,根据用户的问题生成查询,然后通过MCP之类的技术,返回结果。
这里我会演示最后一种方案。我们选择Dify + SQL Server的方式。
其实第三种方案,在B站你能看到基于Dify的很多演示,但受限于工具的功能,只能找到MySQL的。理论上来说,通过MCP也可以,但是我搜索了下支持SQLServer的MCP工具,都失败了。
所以这里我会换一个思路,既然Dify现成工具以及MCP都很难找到对SQLServer的支持,那么就拿出Python大法,大体的思路就是通过Python来访问SQLServer,然后再通过Python暴露一个http的接口,供Dify去调用。
你会问为什么偏要SQLServer,因为这里想主要介绍通过Dify现成工具以及MCP之外的另外一种万能的方式,其次,再怎么说我也是曾经连续连年的SQLServer MVP,所以对SQLServer还是很有感情的。
再就一点,在SQLServer下有一个不错的资源即使官方示例的数据仓库,Adventure works,里面有现成的数据可以供我们演示用。
这套数据仓库的结构如下,以下是我在Power BI里的建模,可以清晰的看到表间关系:
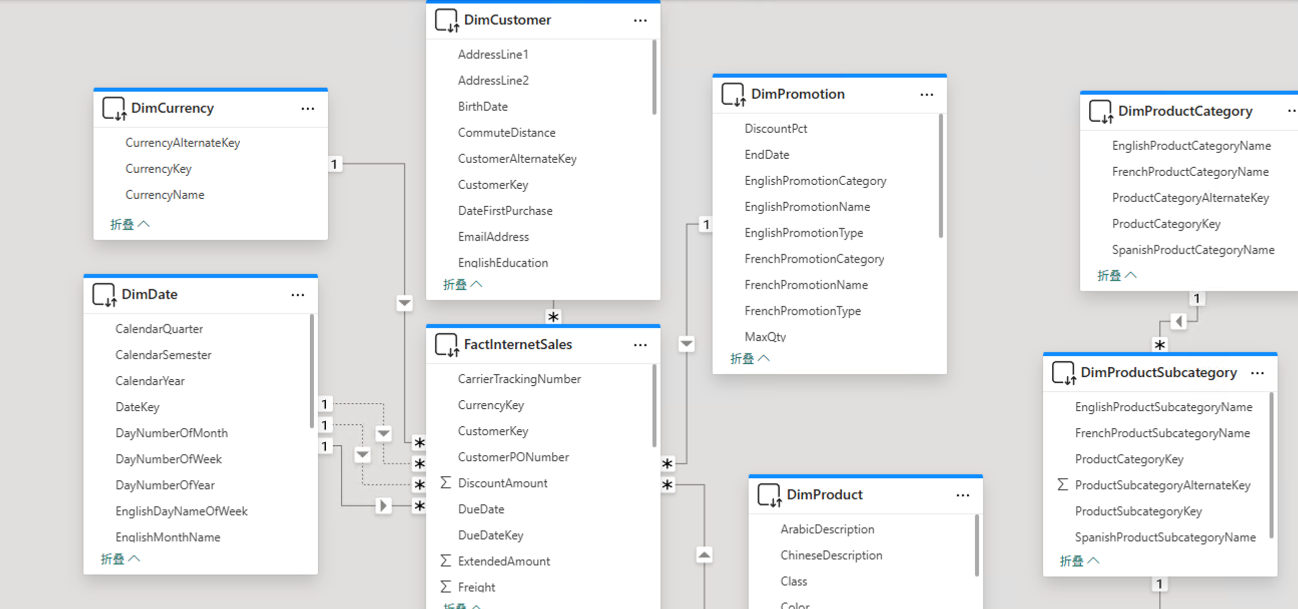
当初我在设计数据仓库比较迷茫时,都会来参考一下相应的问题,在这套数据仓库里是如何设计的。
为了方便演示,这里我只选择两张表,一个是FactInternetSales,一个是DimProduct。我们首先需要做的是将两个表的建脚本导出来,后续放在大模型里让大模型知道相应的数据结构。大模型会根据字段的名字来理解相应字段的含义。有些时候通过字段名可能看不出其含义,解决的方法就是通过对字段的注释,来辅助大模型理解数据的含义。
接下来在Dify中,创建一个ChatFlow。
这里我们主要用到以下几个关键模块:
- LLM,通过大模型根据用户的问题生成查询语句,最后再通过大模型汇总信息。
- 代码执行,由于我们用的是思考模型,所以Dify中我们读取到的反馈是包含大模型思考信息的。通过Python代码,可以很容易的过滤掉这部分信息,确保只有纯查询语句被传递到下一步。
- HTTP请求,通过这个模块去调用Python编写的http接口,来跟SQLServer进行交互。
工作流大体结构如下:
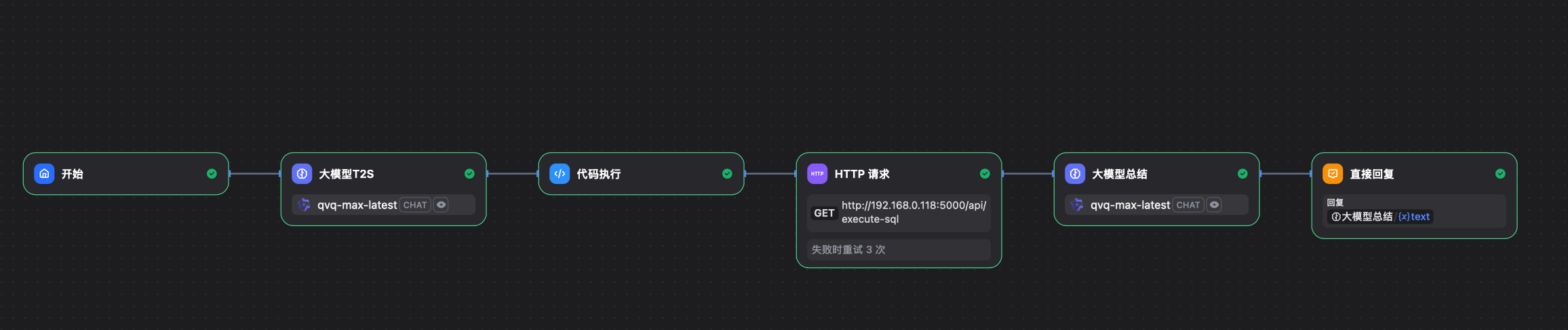
这里有几个需要关注的点:
在大模型Text2SQL模块中,在User提示词里除了要提供相应表的结构之外,还需要告诉大模型出了SQL语句不要返回其它信息。不然大模型会贴心的输出说明内容,后续还需要单独对其进行过滤。
以下是我用到的提示词,供参考。请留意为了考虑篇幅排版,这里我省略了建表脚本。
LLM提示词
你是一个数据库专家。
以下是相关表结构:
***FactInternetSales的建表脚本,为了篇幅这里我省略了。
***DimProduct的建表脚本,为了篇幅这里我省略了。
请将用户的请求转换成相应的SQL查询。
{{#sys.query#}}
直接生成SQL查询,只返回SQL查询,不要生成其它任何内容。由于我使用的大模型会附带think部分的信息,所以后面我加了一段python代码处理了一下:
Python
def main(arg1: str):
return {
"result": arg1.split("</think>")[1],
}接下来是构建Python跟SQLServer通信的部分,这里我用的是Flask,通过它可以很方便的将Python的一个方法,暴露成一个http接口。然后在这个Python方法中,理论上你就可以做任何事。
https://github.com/microsoftbi/SQLServer-Scripts/blob/master/iDWH.py
需要留意的事,在DB_CONFIG里,指定数据库名,用户名和密码。
数据库这里我们用的是:AdventureWorksDW2016,大家可以从微软的官方网站找到这个数据库的下载.用户名和密码根据自己的配置指定就可以。
代码的逻辑也很简单,实例化一个Flask对象后,直接run起来指定好IP和端口号就可以。
Python的方法里哪个需要暴露成接口,就在前面加一个@app.route的声明,指定好路由地址,METHOD(POST or GET)就可以。
最后一步,通过大模型对用户的提问以及查询到的结果进行一个简单的汇总,以下是我用到的提示词作为参考:
LLM提示词
根据用户的问题:{{#sys.query#}}
以及参考数据:
{{#HTTP请求/{x}body#}}
汇总输出。请留意不要直接copy这个代码到你的工作流当中,因为copy出的提示词只有变量id,而不同环境的id是不同的,所以对应http请求位置的内容需要手动在代码里添加。
最后调试一下工作流.
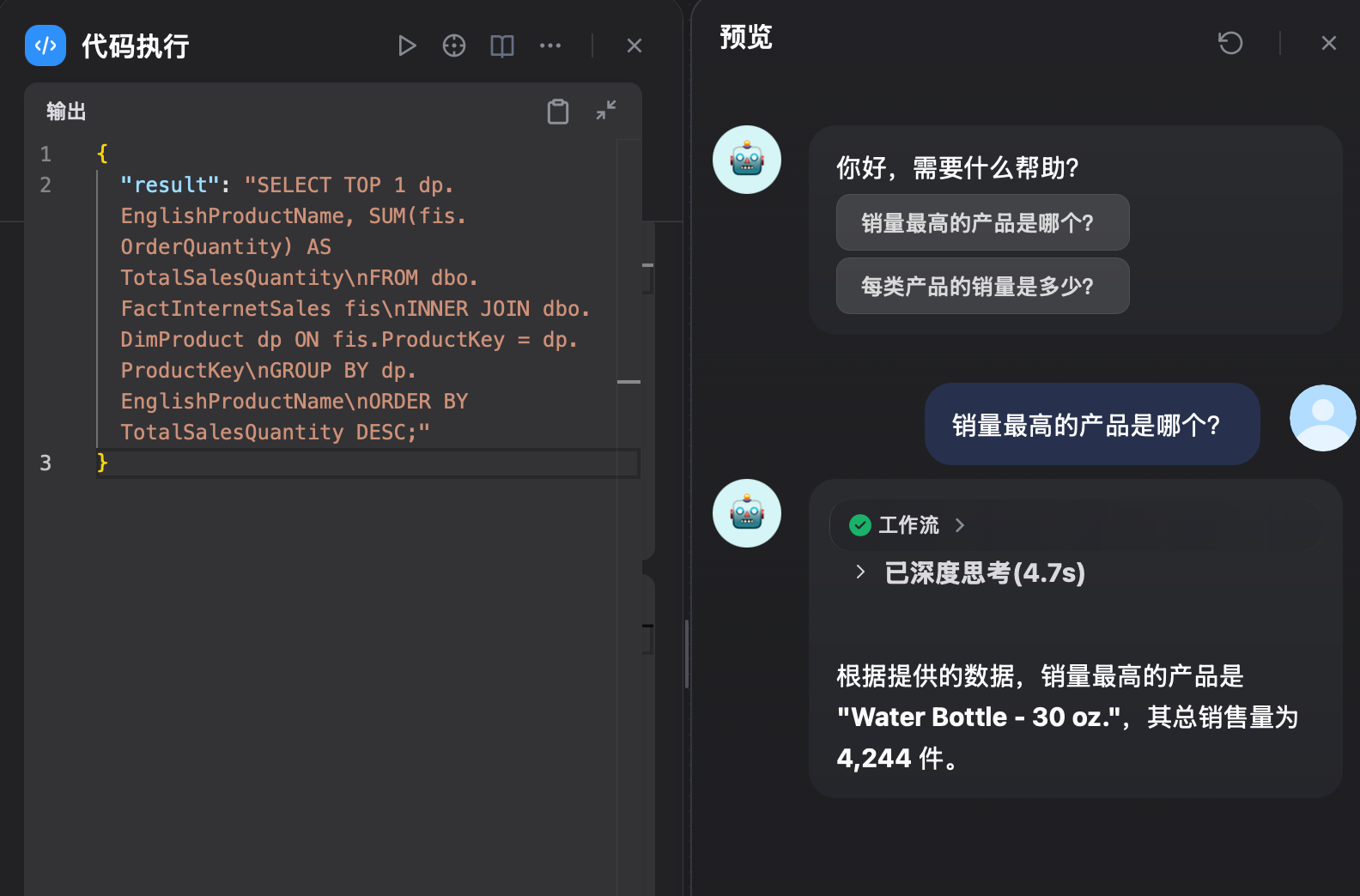
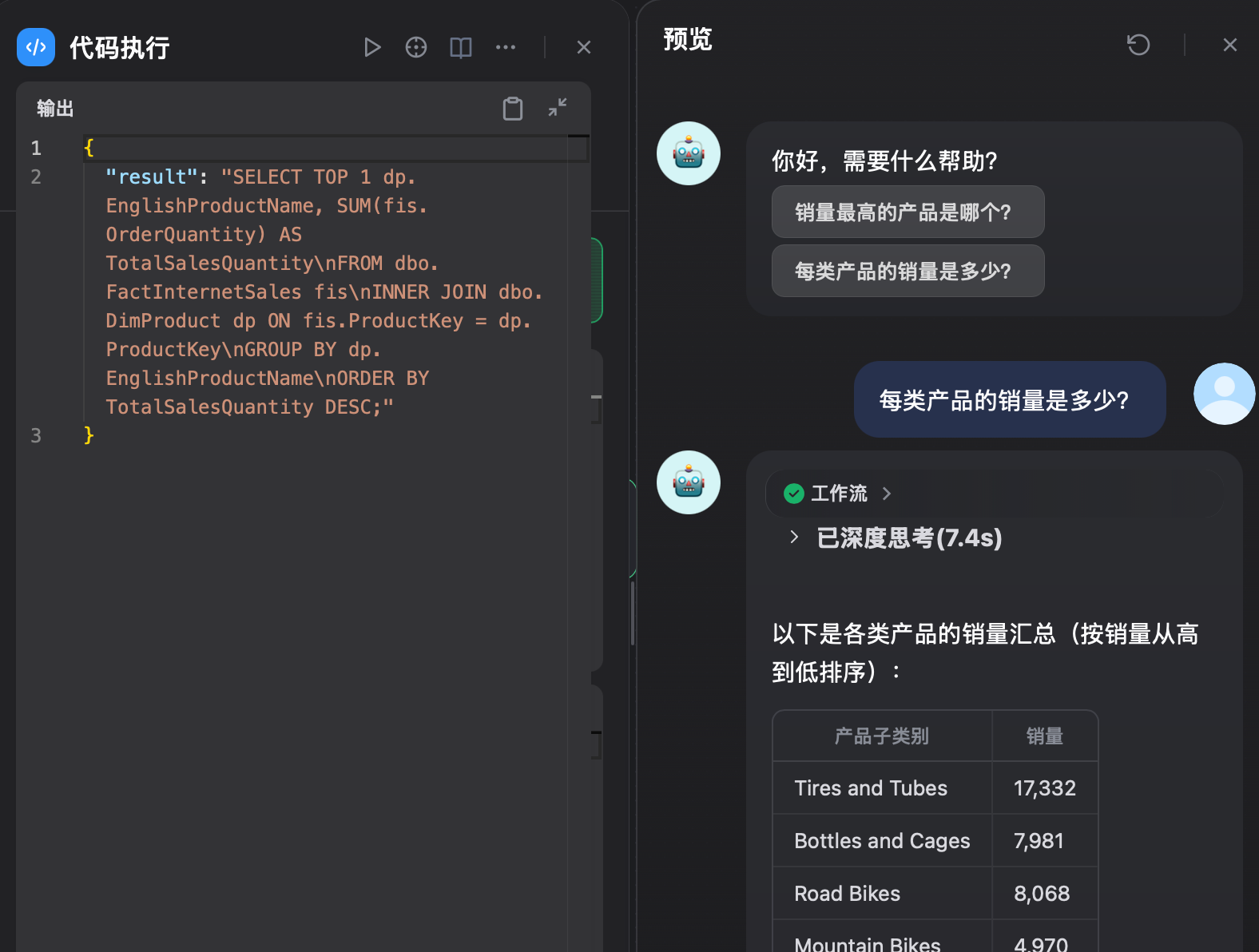
可以看到,这个场景我们虽然只介绍了两张表给大模型,所以基于这两张表的提问可以看到基本是靠谱的。
这里需要注意一个地方是,工作流可能会莫名其妙的出错,比如我曾遇到的一个问题是,大模型在生成查询语句的时候,虽然我指定了不要生成出了SQL之外的内容,但偶尔它还会加个东西比如sql=SELEC......这类。这个只能在报错的时候,具体的去看workflow的log,以及调试后台的python代码才能具体定位到是什么问题,然后再针对问题做相应的处理。
这个方案实际应用中应该还会有些问题需要考虑:
- 模型对输入长度的限制。如果需要更多的表参与进来,那么提示词会越来越长。
- 不同模型的反应可能会不同,可能需要对结果进行单独的处理。这里我用的是qvq-max-latest。
- 大模型对数据结构里表关系的理解。对于微软的这个示例库,是带着外键信息的,并且外键字段也都是能对应上的。如果没有这些信息,以及从字面上看不出关联,就需要在提示词里指明这些信息。
- 这类场景,考虑到大模型的输出限制以及token消耗,尽量只做统计类查询问题,不要生成raw data。
- 未避免SQL注入,尽量在提示词部分,或者在python接口部分,屏蔽DML类语句。(UPDATE,INSERT or DELETE...)
本文工作流的yml文件可以在这里获取:
https://files.cnblogs.com/files/aspnetx/AIBI01.yml.js?t=1762690256&download=true
博客园不能直接上传yml后缀的文件,所以我加了个.js后缀。
到这里我们的初步演示就结束了。当然具体通过大模型来跟数据库进行协作,还有很大的提升空间,这里我推荐B站的这个最新的教程,通过LangChain 1.0构建SQL Agent。
视频是介绍最新的LangChain 1.0的,讲通过SQL Agent的方式,让大模型自己去看有哪些表以及其结构都是什么,最后再生成对应的查询。看上去智能好多。