引言:从语义搜索到关系推理的演进
设定问题:传统 RAG 的关键局限性
传统的检索增强生成(Retrieval-Augmented Generation, RAG)系统,通常被称为"基线 RAG"(Baseline RAG),在利用外部知识库增强大型语言模型(LLM)方面取得了革命性进展。这些系统主要依赖于向量数据库中的"相似性搜索"来获取与用户查询语义相关的文本"块"(chunks)¹。然而,这种方法存在根本性的局限:
- 关系盲目性 (Relational Blindness): 基线 RAG 擅长发现语义上相似的独立信息片段,但它本质上无法理解和利用这些信息片段之间隐含和显式的关系²。
- 无法"连接点" (Connecting the Dots): 当回答一个问题需要综合来自多个独立文档或分离片段的信息时,基线 RAG 往往会失败³。它无法在这些"点"之间进行推理。
- 上下文冗余与"迷失在中间" (Lost in the Middle): RAG 经常检索到大量重叠或冗余的信息,导致上下文窗口过长。这不仅效率低下,还会引发"迷失在中间"问题,即 LLM 会忽略或遗忘位于提示词中间部分的关键信息²。
- 全局性问题的失败: 对于"这个数据集中有哪些主要议题?"或"不同团队之间的关系如何?"这类全局或整体性问题,基线 RAG 束手无策。这本质上是一个查询聚焦型摘要 (Query-Focused Summarization, QFS) 任务,而非简单的信息检索⁵。
引入 GraphRAG:结构化推理解决方案
为了克服这些局限性,业界提出了 GraphRAG------一种基于图的检索增强生成范式⁶。
- 核心定义: GraphRAG 是一种利用图结构数据(特别是知识图谱, Knowledge Graphs)来显式地建模、存储、检索和推理关系型知识的 RAG 增强方法⁸。
- 核心承诺: 通过从扁平化的"块检索"转向结构化的"图遍历",GraphRAG 旨在显著减少 LLM 的"幻觉"⁴,提供卓越的可解释性(Explainability)⁸,并实现复杂的多跳推理 (Multi-hop Reasoning) ¹⁰ 和数据整体性理解⁵。
第一部分:GraphRAG 范式 - 通用架构与核心概念
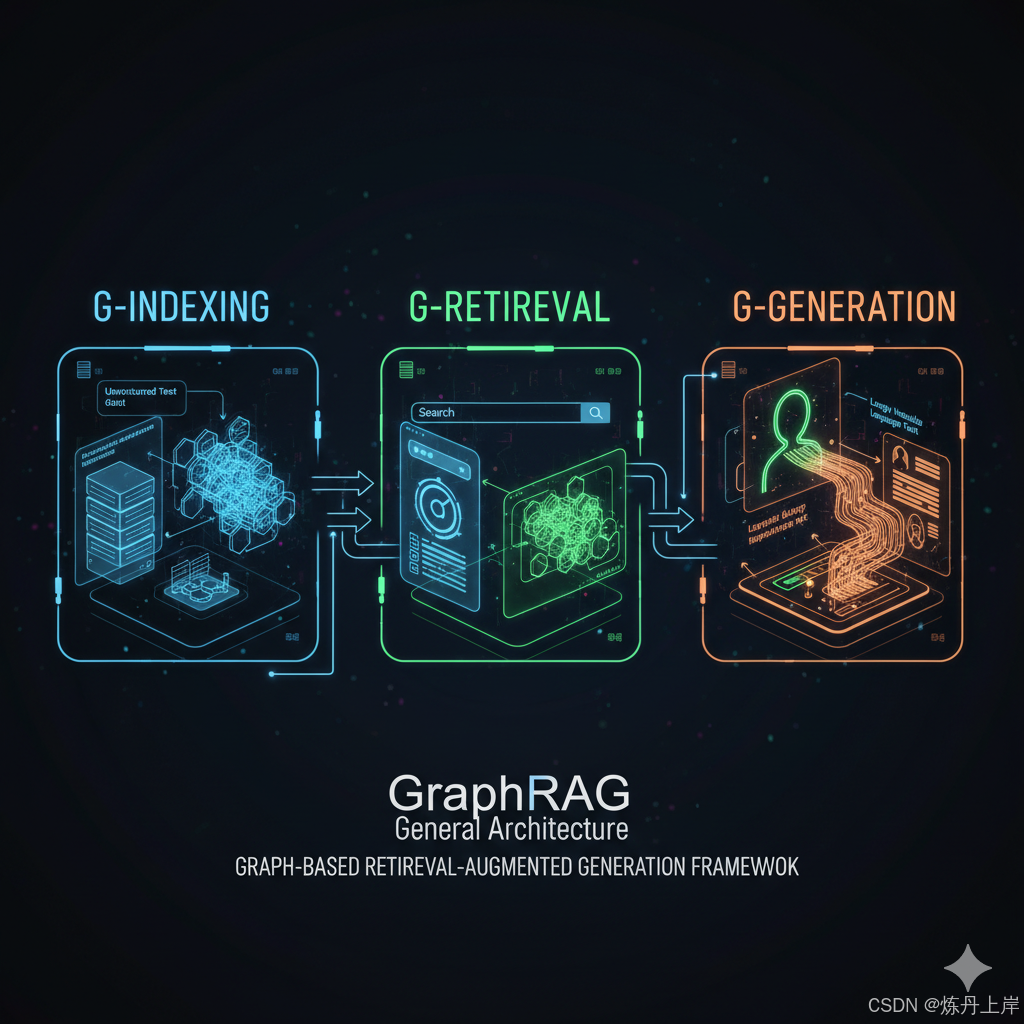
尽管不同的实现(如微软、蚂蚁集团或学术界)在细节上有所不同,但它们大都遵循一个通用的三阶段架构²。
通用三阶段架构
- G-Indexing (图索引构建) : 这是一个离线阶段。原始的非结构化数据(如文本文档)被处理,用于构建或识别一个图数据库(表示为 GGG)²。这是知识被提取和结构化的"重型"步骤。
- G-Retrieval (图引导检索) : 这是一个在线(查询时)阶段。系统根据用户的查询,从图数据库 GGG 中提取相关的图元素(如节点、路径、社区或子图)²。
- G-Generation (图增强生成): 在最后阶段,检索到的图数据(通常被"线性化"为自然语言文本)与原始查询和提示工程(Prompt)相结合,被送入 LLM 进行综合,以生成最终的、富含上下文的答案²。
图数据源:构建 vs. 购买 (Build vs. Buy)
GraphRAG 系统所依赖的图数据库 GGG 可以来自两个主要来源²:
- 开放知识图谱 (Open KGs) : 用于处理通用性任务,系统可以接入预先存在的公共图谱。
- 百科全书式知识图谱: 如 Wikidata, Freebase, DBpedia, YAGO。
- 常识知识图谱: 如 ConceptNet, ATOMIC。
- 领域知识图谱: 如 CMeKG (生物医学), Wiki-Movies (电影)²。
- 自建知识图谱 (Self-Constructed KGs): 这是大多数企业级(如微软和蚂蚁集团)和领域特定应用的核心。图谱是动态地从私有或专有文档语料库(如公司内部文档、法律档案、研究论文)中构建的²。
核心洞察:GraphRAG 的"流派"
深入分析不同的 GraphRAG 实现后,我们必须认识到一个关键点:"GraphRAG" 并非一个单一、标准化的技术,而是一个涵盖了至少两种截然不同哲学思想的范式。
- 流派 A:图作为事实数据库 (Graph as Fact Database)
- 焦点: 事实、精度、路径。
- 目标: 从文本中提取精确的、原子化的事实(三元组),并严格地在这些事实之间进行路径遍历和推理。
- 代表: 蚂蚁集团的架构¹¹。
- 流派 B:图作为洞察结构 (Graph as Insight Structure)
- 焦点: 主题、摘要、社区。
- 目标: 利用图的宏观结构(特别是社区)来理解数据的整体主题和高级关系。
- 代表: 微软的 GraphRAG 架构⁵。
实践者必须根据其具体用例(是需要精确的事实查询,还是需要宏观的主题洞察?)来选择合适的架构。本教程将分别深入探讨这两种流派。
第二部分:架构流派 A - 图作为事实数据库(三元组提取与子图遍历)
此流派将知识图谱(KG)视为一个结构化的、可验证的"真理"存储库。其核心目标是通过检索明确的事实及其间的路径来回答问题。
阶段 1:G-Indexing (三元组提取)
此流派的索引构建核心是**三元组提取 (Triplet Extraction)**¹¹。
- 什么是三元组? 知识图谱的基本原子单元是 (主语, 谓语, 宾语) (Subject, Predicate, Object) 的命题¹³。例如:(The Beatles, performed, 'Hello, Goodbye')。
- LLM 的角色: LLM 在解析自然语言句子并将其转换为结构化三元组方面表现出色,尤其是通过"少样本提示"(Few-shot Prompting) 的引导¹¹。
案例研究:蚂蚁集团技术栈 (DB-GPT + OpenSPG + TuGraph)
这个技术栈是流派 A 的完美示例¹¹。
- DB-GPT:作为一个 AI 原生数据应用开发框架,负责协调 LLM 的交互¹⁷。
- OpenSPG:作为知识图谱引擎,定义图的"模式"(Schema),例如其语义增强的可编程图(SPG)框架¹⁷。
- TuGraph:作为一个高性能的图数据库,它真正存储和管理这些三元组(节点和边)¹¹。
阶段 2:G-Retrieval (子图检索)
当用户提问时,系统有两种主要方式来检索这个事实数据库:
方法 1 (基础):关键词提取 + 图遍历
- LLM 从用户查询中提取关键词(通常是实体)¹¹。
- 系统在 TuGraph 中定位这些实体节点。
- 使用经典的图遍历算法(如广度优先搜索 (BFS) 或深度优先搜索 (DFS)),从这些节点"向外探索" N 跳(N-hops),以获取一个局部子图 (Local Subgraph)¹¹。
方法 2 (高级):Text-to-Cypher / Text-to-GQL
-
概念 : 这是一种更精确但更复杂的方法。系统不再使用启发式的关键词遍历,而是利用 LLM 将用户的自然语言查询直接翻译成一种形式化的图查询语言,如用于 Neo4j 的 Cypher 或新的标准 GQL¹¹。
-
示例 : 用户提问"哪些演员出演了汤姆·汉克斯导演的电影?"可能会被 LLM 翻译为 Cypher 查询:
cypherMATCH (p:Person {name: "Tom Hanks"})-->(m:Movie)<--(a:Person) RETURN a.name
精妙的类比¹⁹:
- Cypher 模板 (Templates):像单一块的玩具(僵硬但安全)。
- 动态 Cypher 生成 (Dynamic Generation):像玩乐高积木(更灵活,仍相对安全)。
- Text-to-Cypher:像绘画(完全的自由,但也极易失败)。
权衡: 此方法异常精确,但其可靠性完全取决于 LLM 生成正确 Cypher 查询的能力¹⁹。
阶段 3:G-Generation (生成)
最后,检索到的子图或 Cypher 查询结果被"线性化"回文本格式,作为高度相关和事实准确的上下文,与原始查询一起提交给 LLM 以生成最终答案¹¹。
第三部分:架构流派 B - 图作为洞察结构(社区检测与层级摘要)
此流派对个体事实的兴趣较小,而更关注知识的宏观结构和浮现的主题。这是微软 GraphRAG 实施方案的核心⁵。
核心哲学:解决 QFS
- 核心解决的问题: **查询聚焦型摘要 (Query-Focused Summarization, QFS)**⁵。即回答"这份报告的核心主题是什么?"或"A 项目和 B 项目是如何相互关联的?"。
- 核心解决方案 : 利用图的固有模块性 (Inherent Modularity) 和社区检测 (Community Detection) 算法,将庞杂的数据自动划分成"主题密集"的集群⁵。
阶段 1:G-Indexing (微软的索引工作流)
这是一个复杂的、由多个工作流(Workflows)组成的数据管道,通常由像 DataShaper 这样的库来编排和执行⁵。
关键工作流步骤⁵:
- 输入与分块 (Input & Chunking): 读入输入数据(如.txt,.csv 文件),并将其分割成 TextUnits(文本单元)⁵。
- 图提取 (Graph Extraction - LLM 密集型) :
- 这是标准 (Standard) 模式下的核心。LLM 会扫描每一个 TextUnit。
- 提取关键信息:实体 (Entities) (如人、地点、组织)、关系 (Relationships) (实体间的联系)和 主张 (Claims)(文本中的关键断言或事实)¹²。
- 图构建 (Graph Building): 将提取的实体、关系和主张组装成一个内存中的图结构⁵。
- 社区检测 (Community Detection - 算法核心) :
- 在构建的实体图上运行聚类算法,最著名的是 Leiden 或 Louvain 算法⁵。
- 什么是 Louvain 算法? 这是一种高效的层级聚类算法。其目标是最大化图的"模块性"(Modularity)²⁴。模块性是一个度量标准,用于衡量一个社区内部的连接密度与社区之间的连接密度的对比²⁵。
- 结果: 图被自动分割成多个"社区"或"主题集群"。同一社区内的节点(例如,所有"蓝色"节点)彼此间的联系远比它们与"红色"社区节点的联系更紧密¹²。
- 层级摘要 (Hierarchical Summarization - LLM 密集型) :
- 一旦社区被识别,系统会再次调用 LLM,要求它为每一个社区生成一个自然语言的摘要报告⁵。
- 这实质上创建了整个数据集的一个"语义索引"。你得到了 Level 0 摘要(最高层的主题),Level 1 摘要(子主题)等等²⁷。
- 嵌入 (Embedding): 最后,系统为文本块、实体和社区摘要创建向量嵌入,以便在检索阶段进行混合搜索²²。
关键洞察:成本 vs. 质量 (Standard vs. FastGraphRAG)
上述流程,特别是第 2 步和第 5 步,在每个文档块上都使用了昂贵的 LLM 调用,这导致了巨大的成本和缓慢的索引速度²⁸。
为了解决这个问题,微软引入了 FastGraphRAG------一种混合方法,它用传统的、更快的 NLP 技术替代了昂贵的 LLM 任务³⁰。
表 1:微软 GraphRAG 索引方法的对比 (Standard vs. Fast)
| 任务 | Standard GraphRAG (标准版) | FastGraphRAG (快速版) | 质量与成本洞察 |
|---|---|---|---|
| 实体提取 | LLM 被提示提取"命名实体"并生成详细描述。 | 使用 NLP 库 (NLTK, spaCy) 提取"名词短语"。无描述。 | 质量: 标准版具有高保真度的实体。快速版"噪音"更大。 |
| 关系提取 | LLM 被提示描述每对实体之间的关系。 | 关系被定义为实体对在同一 TextUnit 中的共现 (co-occurrence)。无描述。 | 质量: 标准版捕获语义。快速版仅捕获"邻近性"。 |
| 实体摘要 | LLM 将一个实体的所有实例描述合并为单个摘要。 | 不需要 (N/A)。 | 成本: 标准版增加了更多的 LLM 调用。 |
| 社区报告生成 | LLM 摘要丰富的实体/关系描述。 | LLM 摘要与实体相关的原始 TextUnit 内容。 | 关键洞察³⁰: 对于 QFS/全局搜索,FastGraphRAG 以低得多的成本提供了高质量的摘要结果。 |
| 最佳用例 | 高保真图探索,深度实体理解。 | 摘要性问题(全局搜索),快速、廉价的索引。 |
阶段 2 & 3:G-Retrieval & Generation (双模检索)
微软的这种复杂索引结构使其能够支持两种截然不同的查询模式,以应对不同类型的问题³。
模式 1:局部搜索 (Local Search) - 针对具体问题
- 适用场景: "告诉我关于'项目 X'的信息"或"Alice 和 Bob 之间有什么关系?"³。
- 技术流程³¹ :
- 嵌入用户查询。
- 执行向量搜索,找到最相关的实体(注意:是实体,不是文本块)作为入口点。
- 从这些实体节点开始,在图上执行**"扇出"(fan-out) 遍历**,收集其邻居、关系和所属社区。
- 将这个以实体为中心的局部上下文(图信息)提供给 LLM 进行回答。
模式 2:全局搜索 (Global Search) - 针对整体性问题
- 适用场景: "数据中的主要议题是什么?"或"关于我们产品的整体情绪是怎样的?"³。
- 技术流程 (即 "From Local to Global" / Map-Reduce 方法)⁵ :
- "Map" (映射) 阶段: 系统检索所有的 N 级社区摘要(例如,50 个主题摘要)。然后,它将用户的原始问题与每一个社区摘要(共 50 次)并行地输入 LLM,生成 50 个"从该社区视角出发的"局部答案⁵。
- "Reduce" (规约) 阶段: 收集所有 50 个局部答案。然后,将这 50 个答案作为上下文,进行一次最终的 LLM 调用,要求 LLM 将它们**综合(规约)**成一个连贯的、全局性的答案⁵。
评价: 这是对 QFS 任务的一个极其精妙的算法解决方案。它通过"分而治之"的策略,利用 LLM 同时作为并行的分析器(Map)和最终的综合器(Reduce),成功地"理解"了整个数据集。
第四部分:前沿与高级 GraphRAG 架构
GraphRAG 的概念仍在快速演进,学术界和前沿实验室正在探索更强大的架构。
流派 1:多模态 GraphRAG (Multimodal GraphRAG)
图不必局限于文本。节点可以是文本、图像、视频片段或结构化数据³⁴。
- G-Indexing (索引) :
- 使用 TF-IDF 或 BERT 对文本进行向量化;使用视觉模型(如 CNNs, ViT)提取图像特征³⁴。
- 为 text_i 和 image_i 创建节点。
- 如果它们的特征向量之间的余弦相似度超过某个阈值(例如 >0.5> 0.5>0.5),则在文本节点和图像节点之间创建一条"相关"边³⁴。
- G-Retrieval (检索): 用户的查询(可以是文本或图像)被向量化后,可以在这个多模态图上执行近邻搜索,从而检索到跨模态的相关内容³⁴。
流派 2:GNN-RAG (使用图神经网络的 RAG)
流派 A 中的 BFS/DFS 遍历是一种启发式(或说"盲目")的搜索。GNN-RAG 提出了一种更智能的方法:学习如何检索。
架构³⁵:
- 检索 (GNN): 使用图神经网络 (GNN)(而不是 LLM)在密集的 KG 子图上进行推理,以识别最可能的答案候选节点。
- 路径发现 (Pathfinding): 使用图算法找到连接"查询实体"和 GNN 发现的"答案候选者"之间的最短路径。
- 语言化 (Verbalization): 将这些结构化的路径(即 (节点, 边, 节点))翻译回自然语言句子(例如,(奥巴马, 出生于, 夏威夷) 变为 "奥巴马出生于夏威夷")。
- 生成 (LLM): 将这些"语言化的推理路径"作为上下文提供给 LLM。
洞察: 这是对 GNN 和 LLM 优势的完美结合。GNN 负责其擅长的结构化和符号推理,LLM 负责其擅长的自然语言理解和生成³⁵。
流派 3:G-Retriever (NVIDIA 的最优子图检索)
这是 NVIDIA 提出的一种 SOTA (State-of-the-Art) 架构,旨在通过数学优化的方式找到"最佳"上下文子图³⁶。
- 核心算法: **获奖斯坦纳树 (Prize-Collecting Steiner Tree, PCST)**³⁶。
- 技术流程³⁶ :
- 处理用户查询,在图上找到语义相关的节点和边。
- 为这些相关的图元素分配"奖金"(Prizes)(一个数值)。
- 运行 PCST 算法。该算法的目标是找到一个子图(一棵"树"),使其在最大化所收集奖金总额的同时,最小化该子图的成本(例如,大小或边的跳数)。
- 结果: 得到一个信息密度最高、信噪比最佳的子图,并将其作为上下文输入 LLM。
评价: 这种方法用一个"最优解"取代了启发式的"遍历",从根本上提高了检索上下文的质量。
第五部分:比较分析 - GraphRAG 在 RAG 生态中的位置
一个系统架构师不仅要比较 GraphRAG 的不同流派,还必须将其与 RAG 生态中其他前沿技术进行比较,如 CRAG 和 Self-RAG³⁷。
GraphRAG vs. 纠正型 RAG (Corrective-RAG, CRAG)
- CRAG ³⁸ : CRAG 的核心在于运行时(Runtime)的验证和纠正。它引入了一个轻量级的"检索评估器"。
- 如果检索到的文档是相关的,则使用它。
- 如果是不相关的,则丢弃它。
- 如果是"模棱两可"或"不完整"的,它会触发一次新的网络搜索,以获取额外信息来纠正或补充上下文。
- 比较 : 它们是正交的(Orthogonal)。GraphRAG 致力于完善索引(离线结构化)。CRAG 致力于完善检索(在线验证)。它们完全可以结合使用:例如,使用 CRAG 来验证 GraphRAG 检索到的子图的相关性。
GraphRAG vs. 自我反思 RAG (Self-RAG)
- Self-RAG ³⁷ : Self-RAG 的核心在于智能体(Agentic)的自主决策。它通过训练 LLM 生成特殊的"反思令牌"(Reflection Tokens),使 LLM 自己具备了决策能力:
- 是否需要检索?
- 何时进行检索?
- 检索到的文档是否有用?
- 生成的内容是否符合事实?
- 比较 : 这是**"结构" vs. "智能体"**的对决。
- GraphRAG 说:"把你的知识构建成一个完美的结构(索引),检索将变得简单而精确。" 它将智能前置到了数据中。
- Self-RAG 说:"让模型(智能体)足够聪明,它将能自主地导航不完美的知识。" 它将智能保留在了模型中。
表 2:高级 RAG 技术特性对比分析
| 技术 | 核心原则 | 关键机制 | 解决的关键问题 | 最佳用例 |
|---|---|---|---|---|
| 基线 RAG (Baseline RAG) | 语义搜索 | Top-K 向量检索 | 缺乏外部知识。 | 简单的事实问答 (Q&A)¹。 |
| GraphRAG | 关系推理 | 图构建(离线)+ 图遍历 / 社区摘要(在线) | 关系盲目性,无法进行 QFS(整体性问题)²。 | 知识发现,调查分析,复杂数据理解⁹。 |
| CRAG (Corrective-RAG) | 验证与纠正 | 检索评估器 + 外部(如网络)搜索 | 检索到的文档不相关、有噪声或过时³⁸。 | 准确性要求极高、数据可能过时的公共 RAG 系统。 |
| Self-RAG | 自我反思与自主 | 反思令牌 + 自适应决策 | 静态/盲目的检索,生成内容不接地气³⁷。 | 自主智能体,需要动态决定是否检索的任务。 |
第六部分:实践考量 - 应用、优势与局限
GraphRAG 的真实优势
- 减少幻觉,提升信任: 响应基于明确的、可验证的图路径,而不是模糊的向量相似性得分⁴。
- 卓越的可解释性 (Explainability): 你可以展示推理路径。"我们推荐这个,是因为 A 实体 -> 关联到 -> B 实体 -> 且属于 -> C 主题"⁸。
- 知识发现与全局洞察: 这是流派 B (微软) 的真正亮点。通过对社区进行摘要,GraphRAG 能够揭示隐藏的主题和联系,这是简单的"Top-K"搜索永远无法发现的²⁷。
关键挑战与局限性("致命缺陷")
尽管 GraphRAG 非常强大,但在生产环境中部署它必须面对严峻的挑战:
- 索引成本 (最大的问题): 无论是流派 A(LLM 提取三元组)还是流派 B(LLM 提取实体/关系/摘要),使用 LLM 处理每一篇文档的索引成本都极其高昂。²⁸ 和 ²⁸ 的分析指出,"一本 32,000 词的书花费 7 美元" 的索引成本,对于许多生产级应用来说是无法接受的²⁸。
- 索引速度: 这是一个缓慢的离线过程。除非图可以被高效地"动态更新",否则它不适用于需要实时索引的数据²⁸。
- 架构复杂性: 系统的复杂性远超基线 RAG。你不再只是管理一个向量存储,而是需要维护一个包括 ETL、知识图谱构建、图数据库和多阶段工作流的复杂技术栈²⁹。
真实世界的应用案例
- 企业知识管理: 用于导航和理解庞大的内部文档库⁹。
- 法律领域: 通过分析法律文件间的引用和关系来发现判例⁹。
- 制药/医疗: 连接研究论文、临床试验数据、患者病历和监管指南¹⁰。
- 商业智能 (BI) 与分析: 综合分析客户行为、区域销售数据和市场趋势,以生成深入的 BI 报告⁴¹。
- IT 运维 (IT Ops) 与事件管理: 通过映射服务依赖关系、事件日志和故障排除指南 (TSG),进行根本原因分析 (RCA)⁴²。
- 金融与欺诈检测: 通过对交易网络建模,发现需要多跳才能识别的异常模式或有组织的欺诈团伙¹⁰。
结论:迈向"连接式推理"的未来
GraphRAG 标志着一个根本性的转变:从基线 RAG 所擅长的信息检索 (Information Retrieval) 迈向知识综合 (Knowledge Synthesis)。
最终,未来最强大的 RAG 系统将不会是纯粹的向量、纯粹的图或纯粹的智能体。它们将是混合 (Hybrid) 架构⁴³:
它们将使用向量搜索进行快速的、语义相关的初步检索。
它们将利用图结构来提供事实基础(Grounding)、关系上下文和可解释性。
它们将依赖智能体逻辑(如 Self-RAG 或 CRAG)来智能地决定是使用向量搜索还是图遍历,以及如何验证和纠正输出。
GraphRAG 不是对 RAG 的替代,而是其演进过程中一个至关重要的"结构化推理层",它使我们能够向数据提出一类全新的、关于"连接"和"全局"的深刻问题。