🧱 1. awk 简介
awk 是一种强大的文本处理语言,主要用于模式匹配、文本分析、格式化输出等场景。
它能够逐行扫描输入文件,对满足特定模式的文本执行相应的操作。
本文所介绍的 awk 如无特殊说,均指 GNU awk (gawk) 实现。
⚙️ 2. awk 用法
💡 2.1 基础用法
对于一些简单任务,可以直接在命令行中编写 awk 脚本并执行:
bash
awk [命令行参数] -- [脚本语句] [目标文件]📜 2.1 脚本用法
当处理逻辑较复杂的任务时,可以将 awk 程序写入脚本文件中,再通过 -f 参数执行
bash
awk [命令行参数] -f [脚本文件] -- [目标文件]🧩 3. 命令行参数
GUN awk 提供了丰富的命令行参数,用于控制程序的执行方式,输入输出行为,调试选项等。
🚀 3.1 启动参数
功能:该类参数用于指定 awk 脚本语句的来源或 awk 启动时的初始环境
-f program-file: 从脚本文件中读取 awk 脚本语句,效果:
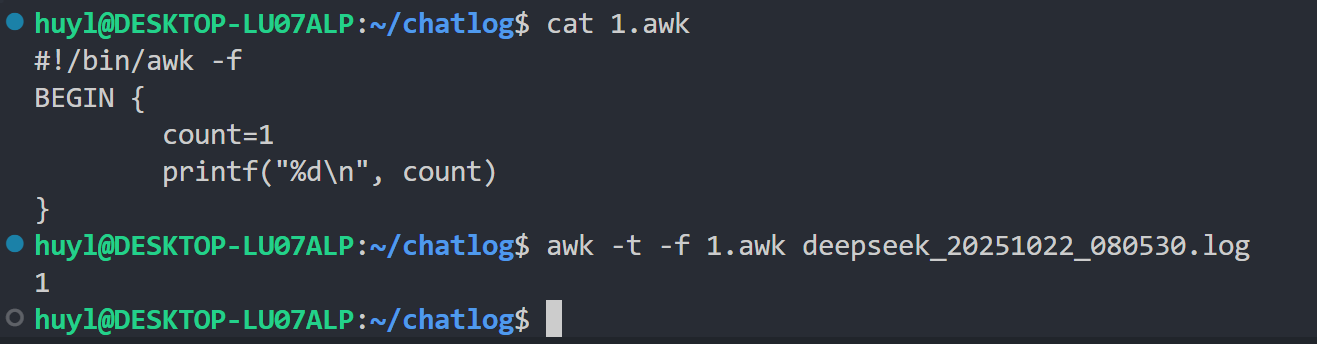
解释:这里 1.awk 是脚本文件,在命令行中通过 -f 参数调用脚本文件对 deepseek_20251022_080530,log 文件进行处理。这里是 awk 用法的脚本用法,在 -f 前面可以跟其他的命令行参数(如 -t)。
-e program-text: 直接在命令行指定 awk 脚本语句并执行,效果:
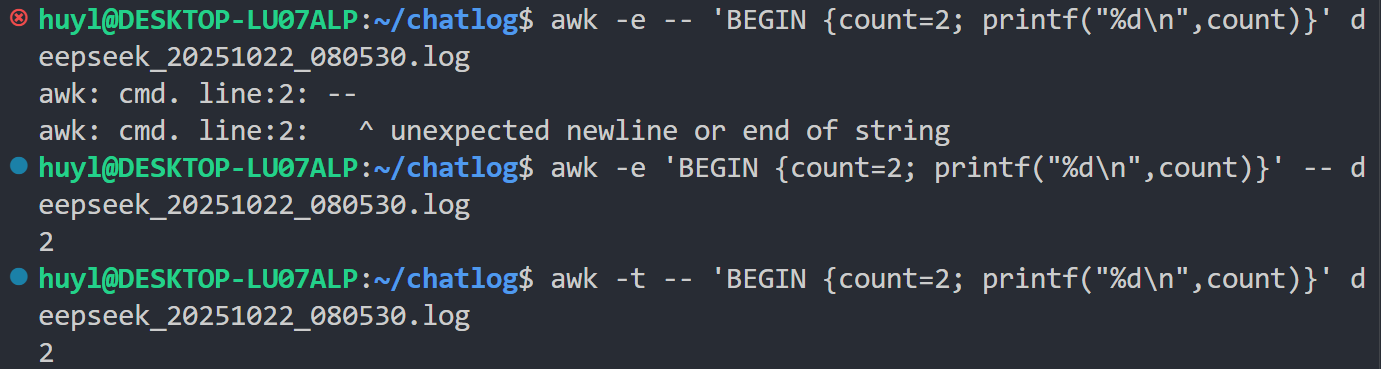
解释:这里单引号中间的内容即为 awk 脚本语句,在命令行中通过 -e 参数指定并执行。需要注意,这里虽然是 awk 用法的基础用法,但是一旦加了 -e 参数,脚本语句就必须放在 -- 前面,否则 awk 就会报错。所以一般都是不加 -e 参数直接将脚本语句放在 -- 后面的,效果和加了 -e 参数一样。
-v var=val:设置变量初始值,效果:

解释:这里通过 -v 参数在执行脚本语句前先给 count 变量赋值。 -v 参数赋值的变量在 awk 脚本语句中可以直接调用。
⚠️ 注意:通过 -v 参数赋值的变量默认为全局变量,如果在脚本中再次对参数赋值则会覆盖 -v 参数赋值的结果。
-i include-file或--include include-file: 加载 awk 库文件,效果:
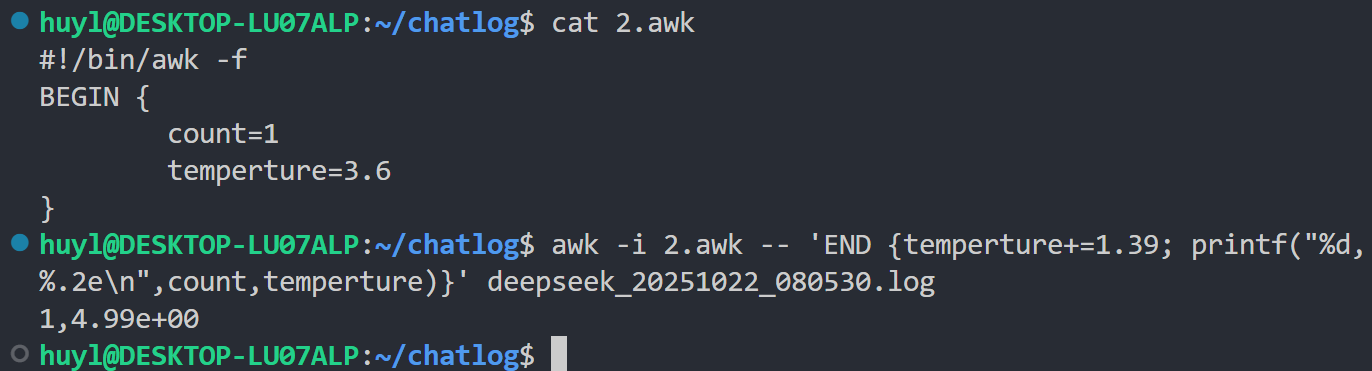
解释:awk 库文件一般里面都是放自定义变量或自定义函数的,这里 2.awk 是库文件,通过 -i 参数加载了 2.awk 中的变量,这样后面的脚本语句就可以直接使用了。
-l lib或--load lib: 加载C语言编写的动态共享库,允许 awk 脚本运行时调用 C 语言编写的函数,效果:
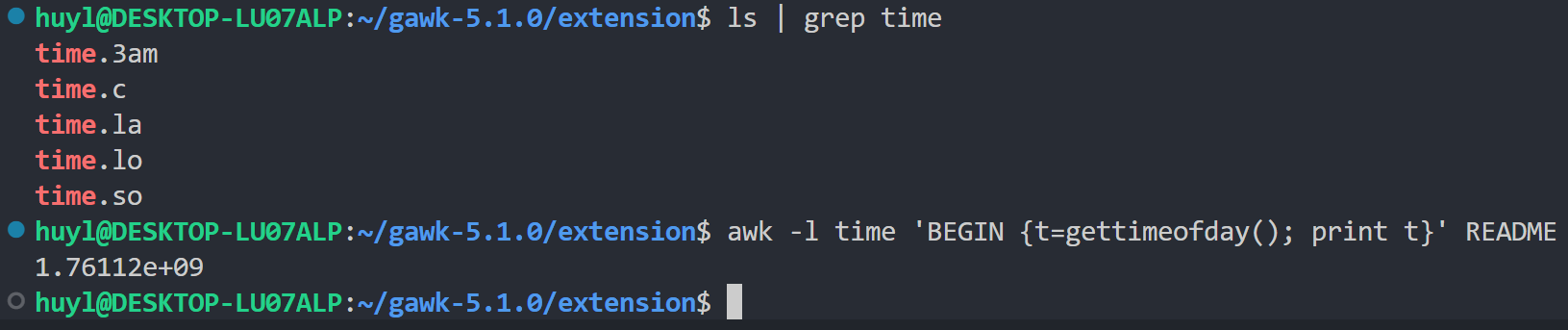
解释:我这里编译了GNU官方提供的 time.c 得到了动态共享库 time.so,然后通过 -l 参数让 awk 加载了 time.so ,在 awk 脚本语句中直接调用了 time.c 里面的 gettimeofday() 函数,利用这个函数打印了当前系统的时间戳。
⚠️ 注意:该功能是 awk 扩展功能,虽然很强大,但是要用他很麻烦。需要使用前在系统中做很多配置,具体过程见 7.1 使用 awk -l 参数加载C语言动态库的扩展功能。
📥 3.2 输入解析参数
功能:控制输入数据的解析与格式
-F fs: 设置字段分隔符,效果:
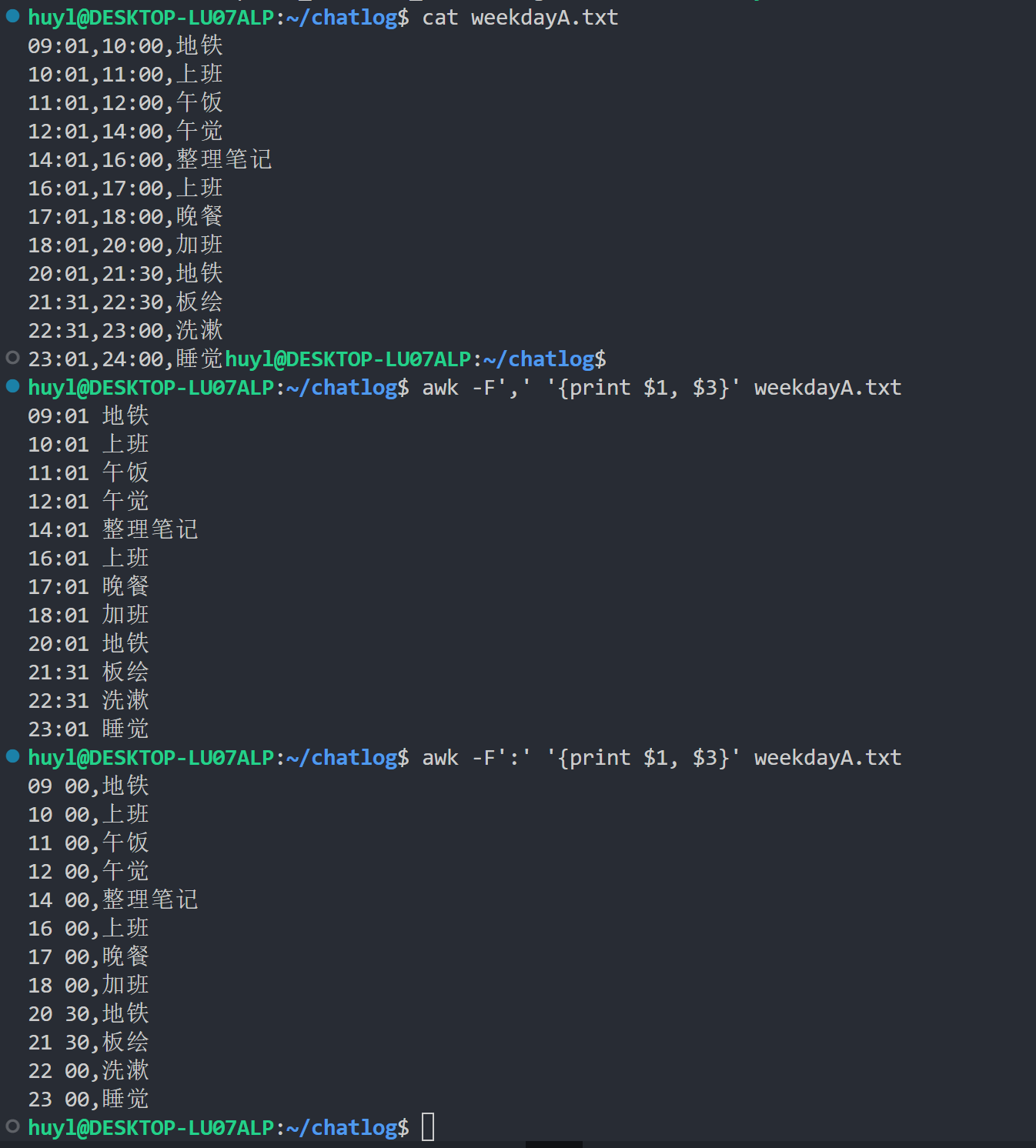
解释:如果不设置 -F 参数的话字段分隔符默认为空格,这里我分别设置了字段分隔符为逗号和冒号,并提取分割出来的第一个字段和第三个字段,可以看到同一份文件分割后的结果是不一样的。
-b或--characters-as-bytes: 将所有输入数据视为单字节,效果:
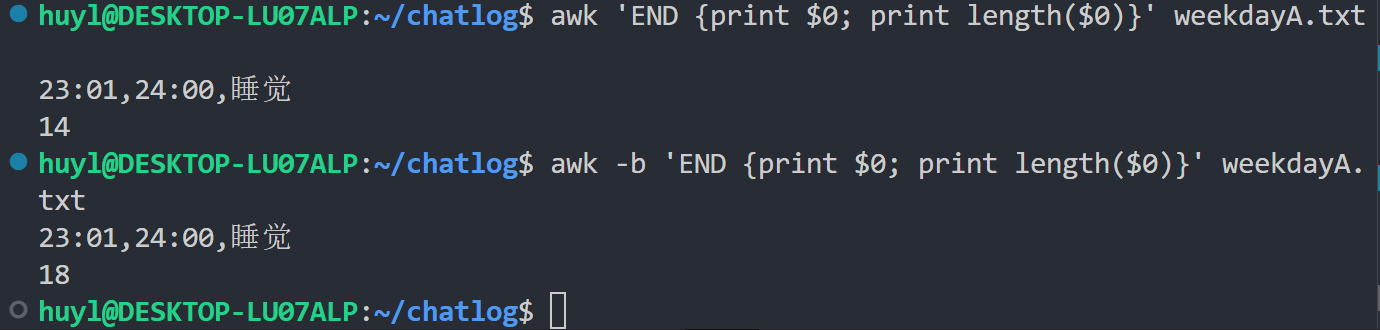
解释:这里我用 awk 打印了文件最后一行的内容并输出了文件最后一行的字节数。第一条命令没有加 -b 参数,awk默认使用 UTF-8 字符集来解析文件内容,一个中文算是1个字符,最后统计的是字符数所以结果是14;第二条命令加了 -b 参数,awk 使用把文件当成单字节文件来解析,一个中文占2个字节,最后统计的是字节数所以结果是18。这个参数应该是专门为了统计二进制文件,或网络数据包的字节数设计的。
-n或--non-decimal-data: 识别输入数据中的八进制和十六进制值,效果:
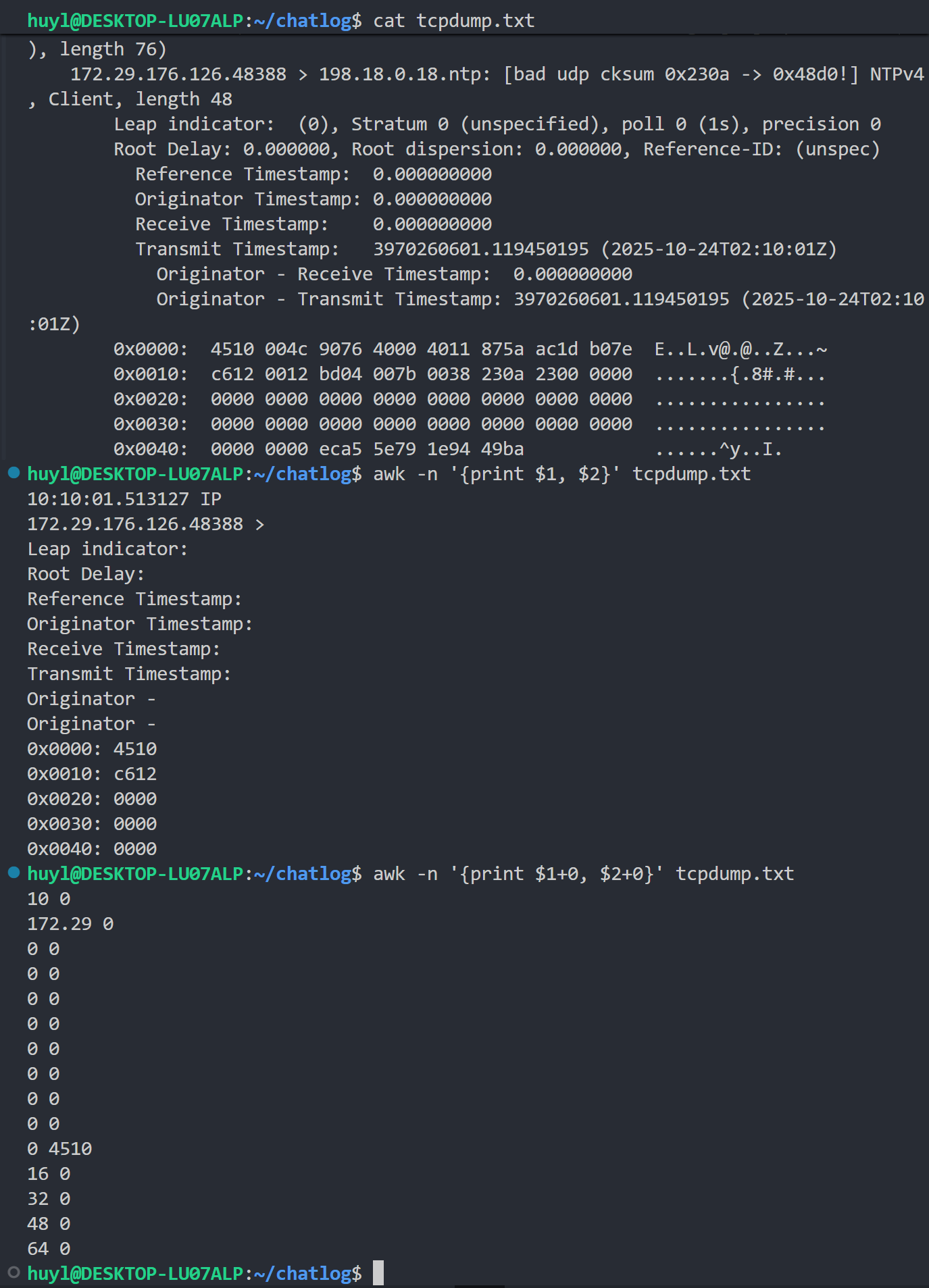
解释:这个参数很鸡肋,实战中基本没什么用,没兴趣的可以直接跳过。他设计的初衷应该是用来处理网络数据包或设备驱动的十六进制数据的,可以把十六进制数据直接进行数字计算,并把结果用十进制数据显示出来。但是从上面的效果可以看出,局限性很多。首先如果不进行任何运算十六进制数据是不会转化成十进制数据的。然后前面没有跟 0x 的十六进制数据也是不会被识别的。还不如直接写正则表达式匹配后用 awk 里面的函数进行计算和转化。
-r或--re-interval: 在正则表达式中使用区间表达式,效果:
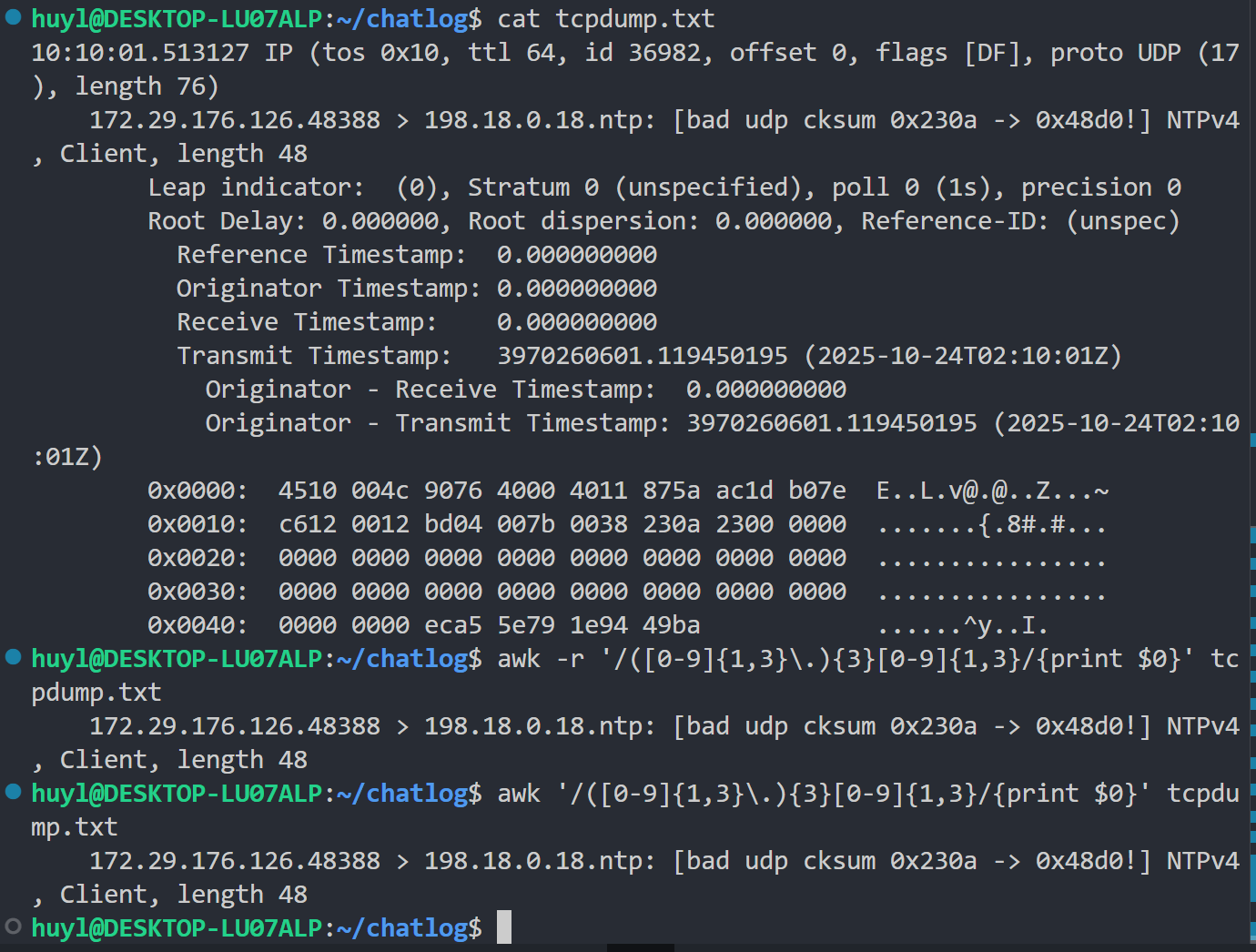
解释:这个参数比上一个还要鸡肋,建议不论敢不敢兴趣都直接跳过。但我为了这篇博客的完整性,所以还是得解释一下。正则表达式中的区间表达式即是 {n,m} 这种形式,用来表示匹配到的目标出现次数在 n 到 m 之间的情况。比如上面效果图中我就利用了带区间表达式的正则表达式 (0-9{1,3}.){3}0-9{1,3} 匹配了 IP 地址的格式,将包含 IP 地址的那一行打印出来。但是,现在的 awk ,默认是 gawk ,默认是支持这种区间表达式的,就是无论你开不开 -r 都能识别 {n,m} (见效果图)。只有在传统的旧版本 awk 下才会出现不支持区间表达式的情况,在这种情况下 -r 参数才有用,加上 -r 他就能识别 {n,m} 。
📤 3.3 输出控制参数
功能:控制 awk 程序的内部处理与性能
-O或--optimize: 启用程序优化,效果:
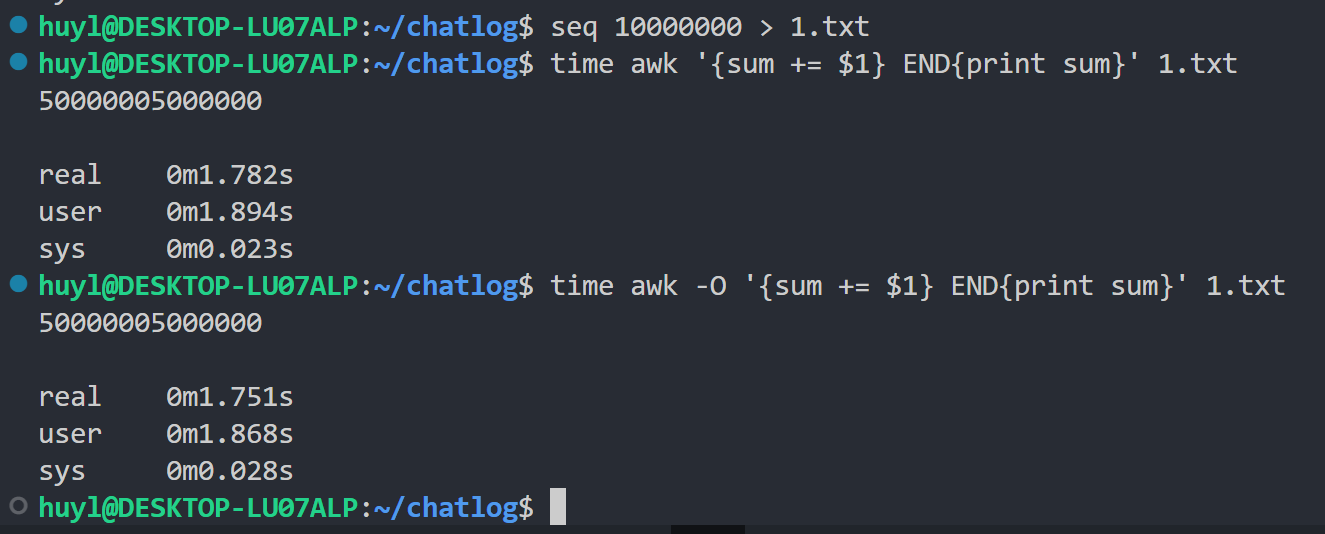
解释:这个参数基本不会用到,建议直接跳过。这个参数是优化脚本的参数,据说对于一些异常复杂的脚本,开启这个参数会减少 awk 处理的时间(awk 会进行常量优化,字节码优化,循环优化)。 awk 默认是开启这个参数的,所以加不加 -O 效果都一样。
-s或--no-optimize: 禁用优化,效果:
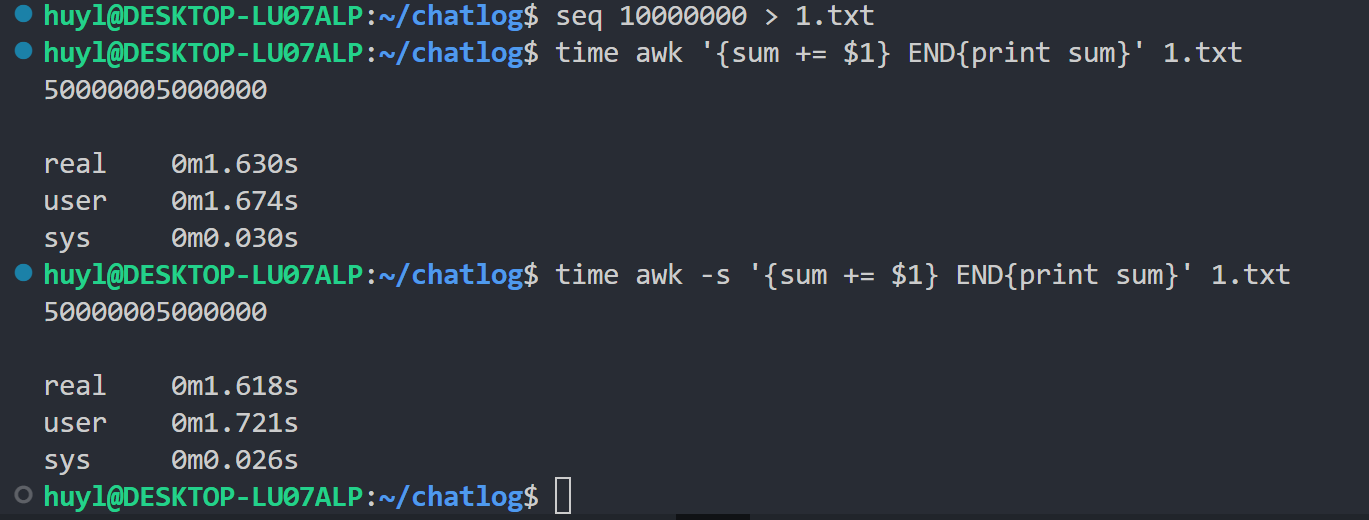
解释:这个参数是用于禁用 awk 程序优化的。如果你担心 awk 默认开启的程序优化会改变你代码逻辑,你可以加上这个参数。至于性能,我个人感觉优不优化没有很大差别。
-o[file]: 格式化输出程序源码,效果:
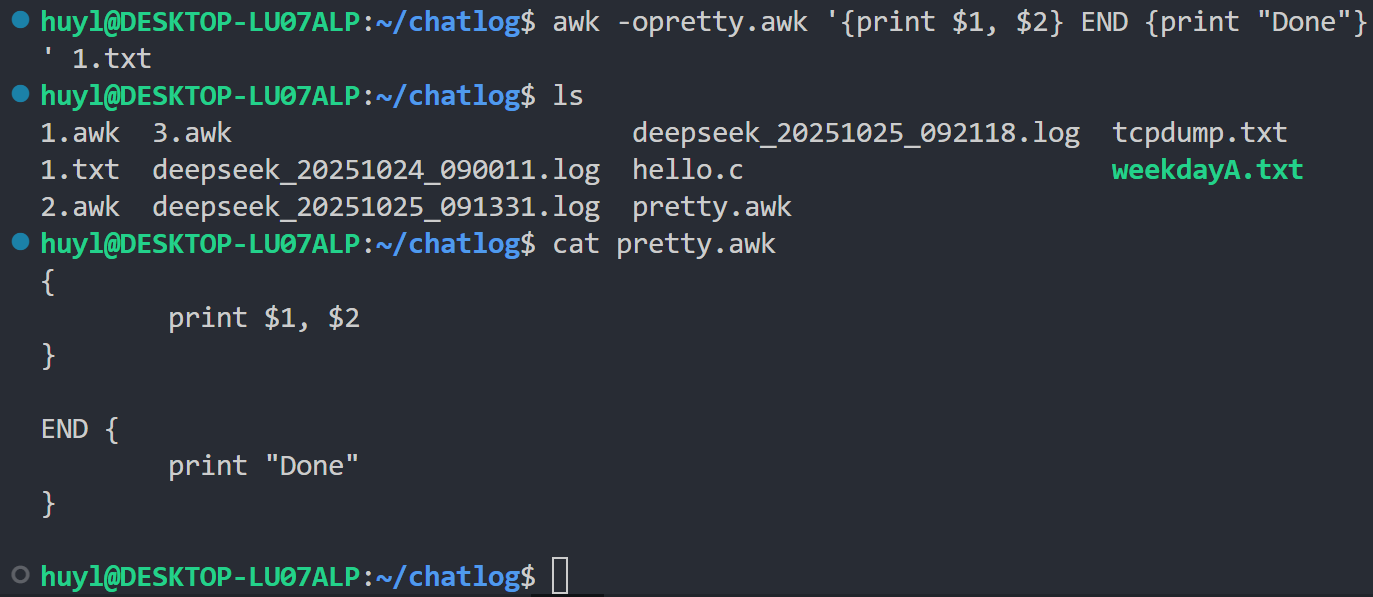
解释:没什么卵用的参数,建议直接跳过。如图所示就是用来把命令行的脚本输出到脚本文件中,并进行优雅的格式化。但是这个参数有个坑,那就是-o后面不能跟空格需要直接跟文件名。跟了空格就不会生成文件。
-M或--bignum: 使用任意精度算术,效果:
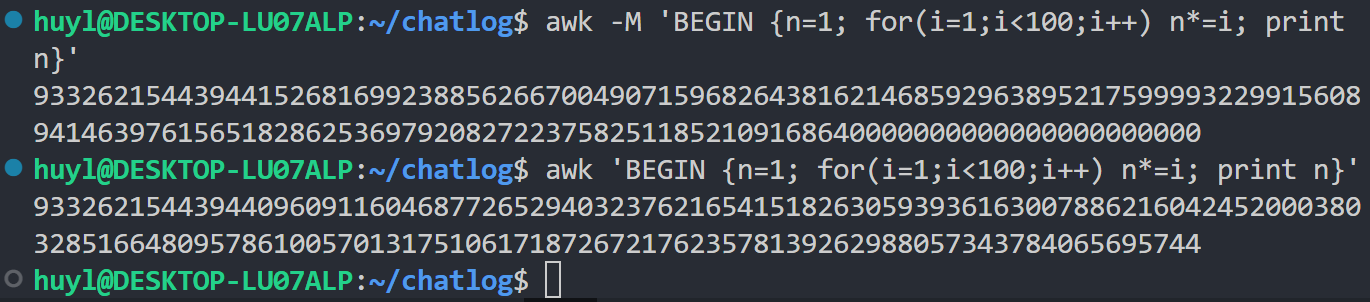
解释:这个参数适用于高精度数学计算的。awk 默认使用的是双精度浮点运算,加了 -M 参数后会使用更高精度的数学计算。图中加了 -M 以后的 100!是正确的结果,不加 -M 的结果存在误差
🧭 3.4 调试和诊断参数
功能:程序调试,性能分析与兼容性检查
-d[file]: 输出全局变量到文件,效果:
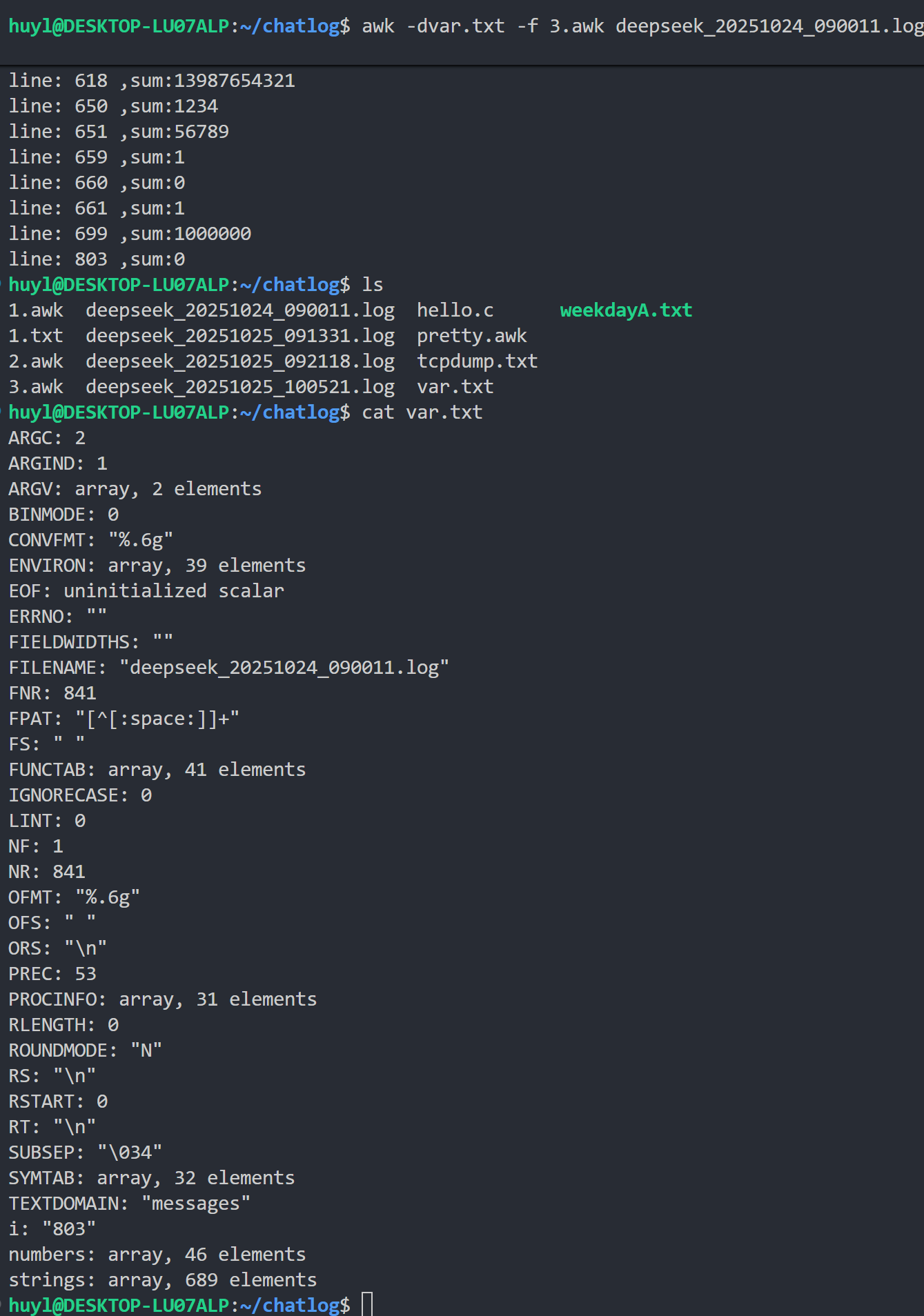
解释:这里利用 -dfile 参数将 awk 脚本运行结束时所有的全局变量输出到 var.txt 文件中。这个参数在调试 awk 脚本的时候很有用。
-D[file]: 启用调试模式,效果:

解释:这里用 -D 参数让 awk 在调试模式下运行。这个调试模式和 gdb 基本上玩法一样,需要先用
b 函数名设置断点,然后用run启动程序停在断点,然后再用n或s单步调试,用p打印信息。GNU还提供了一种非交互式的调试方法 -Dfile 。官方的解释就是在 -D 后面更脚本调试文件的名称,awk 就会按照脚本调试文件进行调试并打印信息。这个脚本调试文件应该也和 gdb 的脚本文件差不多。这里就不细说了。
-p[file]: 输出性能分析信息,效果:
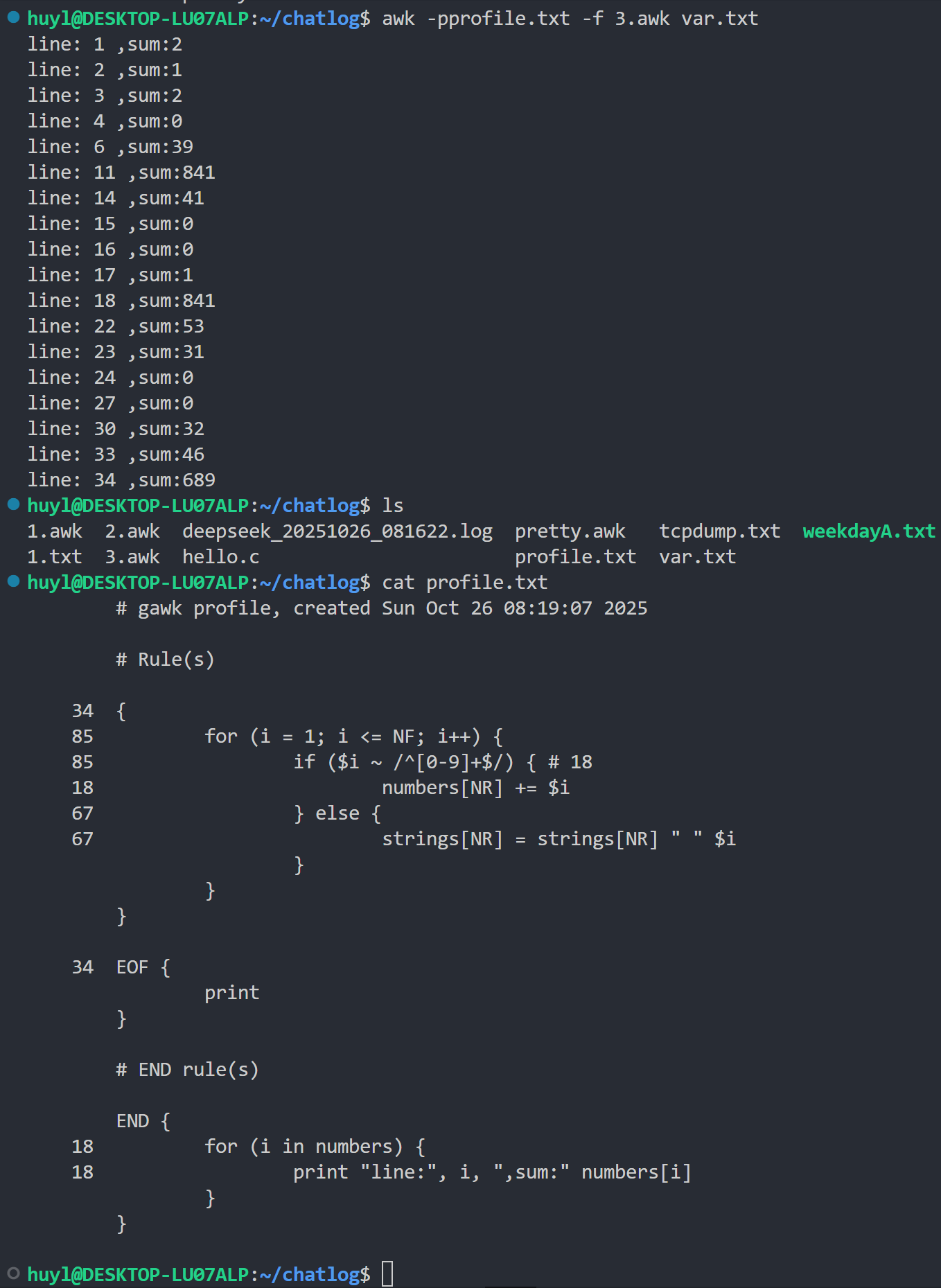
解释:这个参数是用来分析每个函数每个代码段执行了多少次的。这里我用 -p 参数将分析结果输出到 profile.txt 中(-p 和 profile.txt 中间没有空格)。从 profile.txt 这个文件中可以看到除了单独成行的括号以外每一行前面都有一个数字,这个数字就是这行代码执行的次数。利用 -p 参数可以帮助你找到 awk 脚本中需要性能优化的参数
-t: 对不能向传统 Unix awk 移植的构造发出警告,效果:
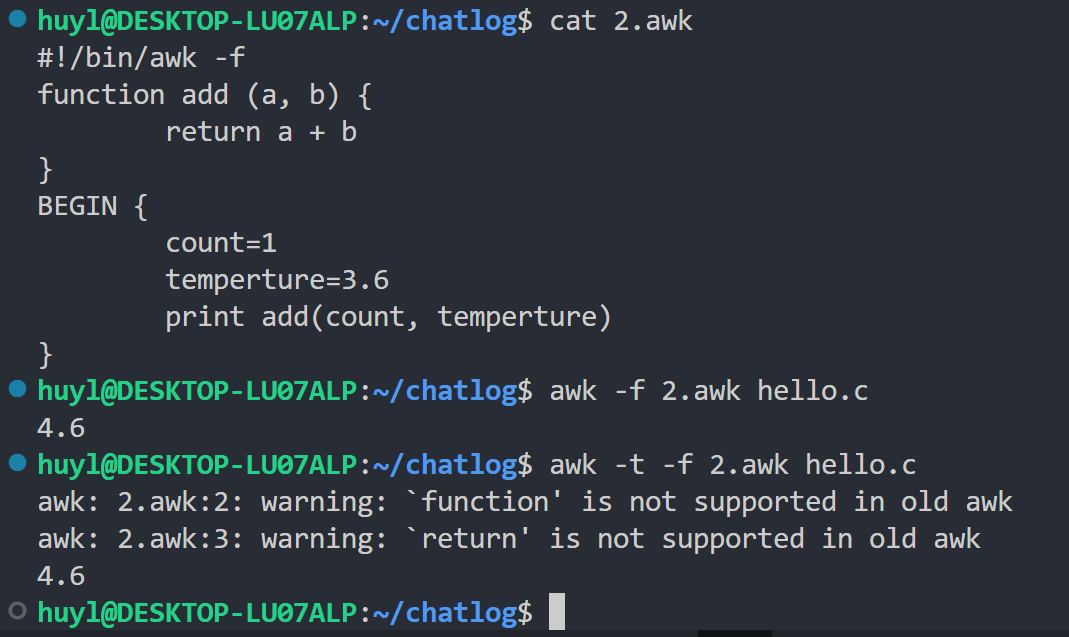
解释:这个参数是在旧 awk 脚本迁移到新的 gawk 环境的过程中检查兼容性的。这里可以看出加了 -t 参数以后 awk 会显示旧 awk 脚本不支持的语法。
-L [value]或--lint[=value]: 检查可疑或不可移植的构造,效果:
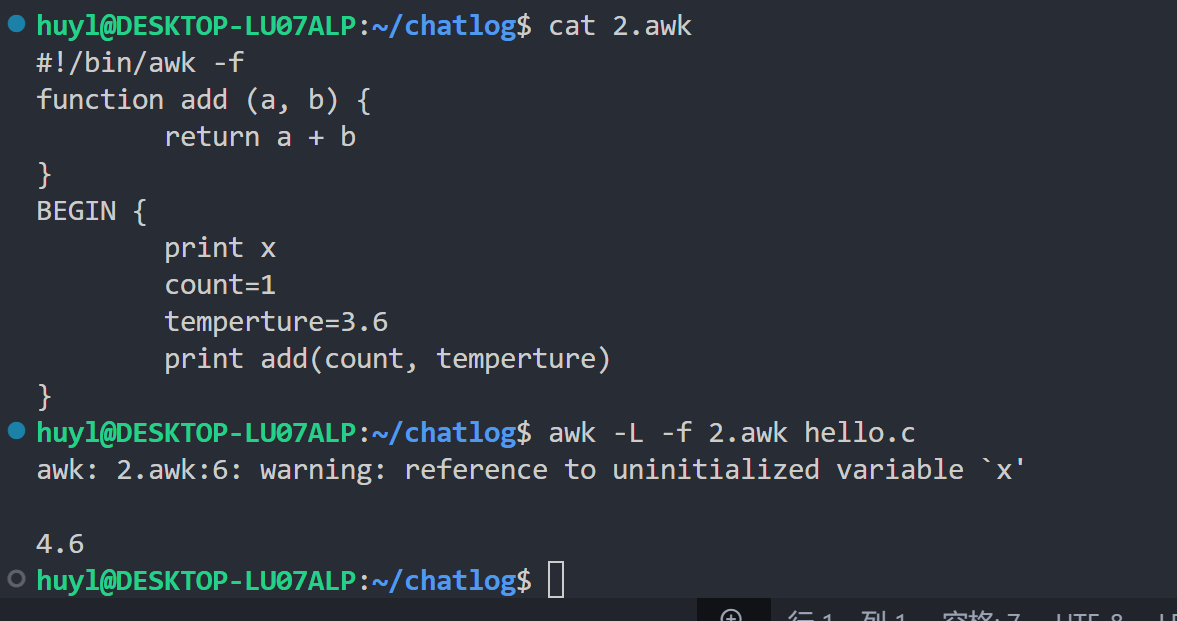
解释:这个参数相当于 awk 自带的语法检查器,可以检查不标准的语法。我这里在 2.awk 中加了一行打印未初始化变量 x 的代码,然后在执行 awk 脚本的时候添加 -L 这个参数,就可以看见 awk 给出的警告,说使用了未初始化变量 x 。但因为未初始化变量并非不可打印(打印了一个空行),所以代码依然能运行。
-S或--sandbox: 在沙箱模式下运行,效果:
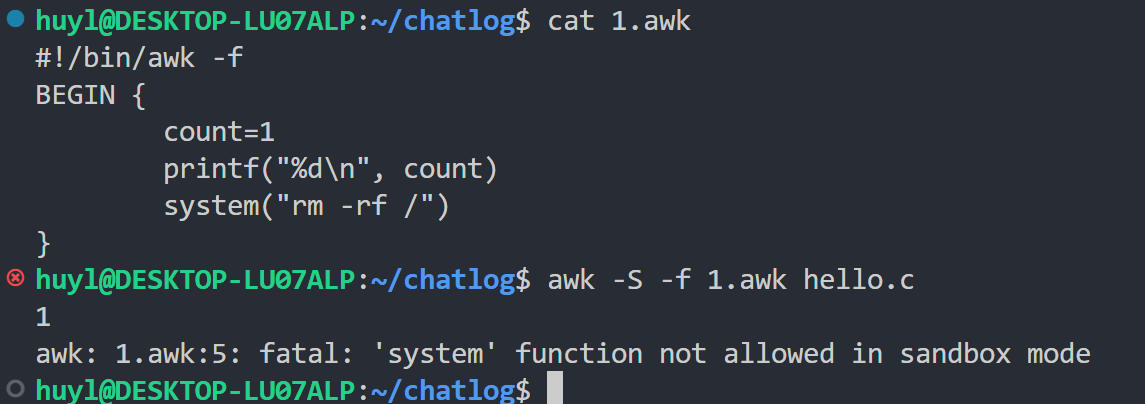
解释:由于 awk 可以在脚本中调用系统接口进行文件系统操作、进程操作、网络操作,所以来历不明的 awk 脚本可能直接对系统造成破坏(代码藏毒)。这里我用一个简单的删根跑路脚本 1.awk 为例演示了 -S 的效果。从结果可以看到前面打印部分的代码依然能正常执行,但是到跑路这行就跑不起来了。
🔄 3.5 兼容性与标准模式参数
功能:控制与旧版 awk 或 POSIX 标准的兼容性
-c或--traditional: 传统模式(兼容原版 awk),效果:

解释: 这里我用同一段代码,用传统模式和默认模式运行出来的结果不一样。默认模式是支持 GNU 扩展的也就是支持 PROCINFO 这个内置变量的,但传统模式不支持,所以默认模式能打印 pid 但传统模式无法打印 pid
-P: POSIX 兼容模式,效果:

解释:这里我用同一段代码,用 POSIX 模式和默认模式运行出来的结果不一样。虽说 POSIX 不支持 PROCINFO 但是可以看到 POSIX 也能打印 PID。POSIX 模式和传统模式还是有点区别的。具体哪些功能 POSIX 模式支持,哪些功能传统模式支持,我是一点也不感兴趣,也不想再深入讨论(反正正常情况也用不到)。估计哪些搞旧系统移植的人会有兴趣把。
-N: 使用本地化数字格式,效果无法展示
解释:建议直接跳过,这个参数是专门给德国人和法国人准备的。他们那里小数点用逗号表示。开启 -N 参数以后 awk 会检测系统当前的 LC=NUMBERIC 是否为德国或法国的数字格式,如果是就会将代码中数据之间的逗号当成小数点来理解。由于这个环境变量需要德国或法国的本地化数字格式,我这没有所以无法展示。
ℹ️ 3.6 信息和帮助参数
功能:提供版本和帮助信息
--version: 显示版本信息,效果:
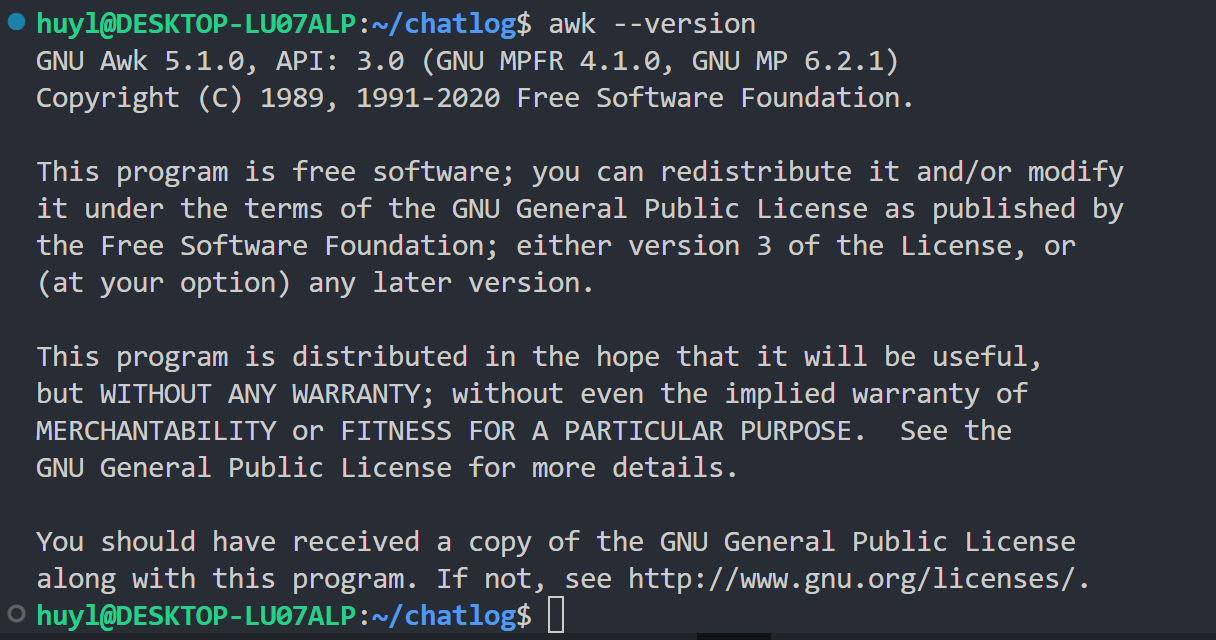
解释:我这里显示的是 Gawk 5.1.0 版本
-C: 显示版权信息,效果:
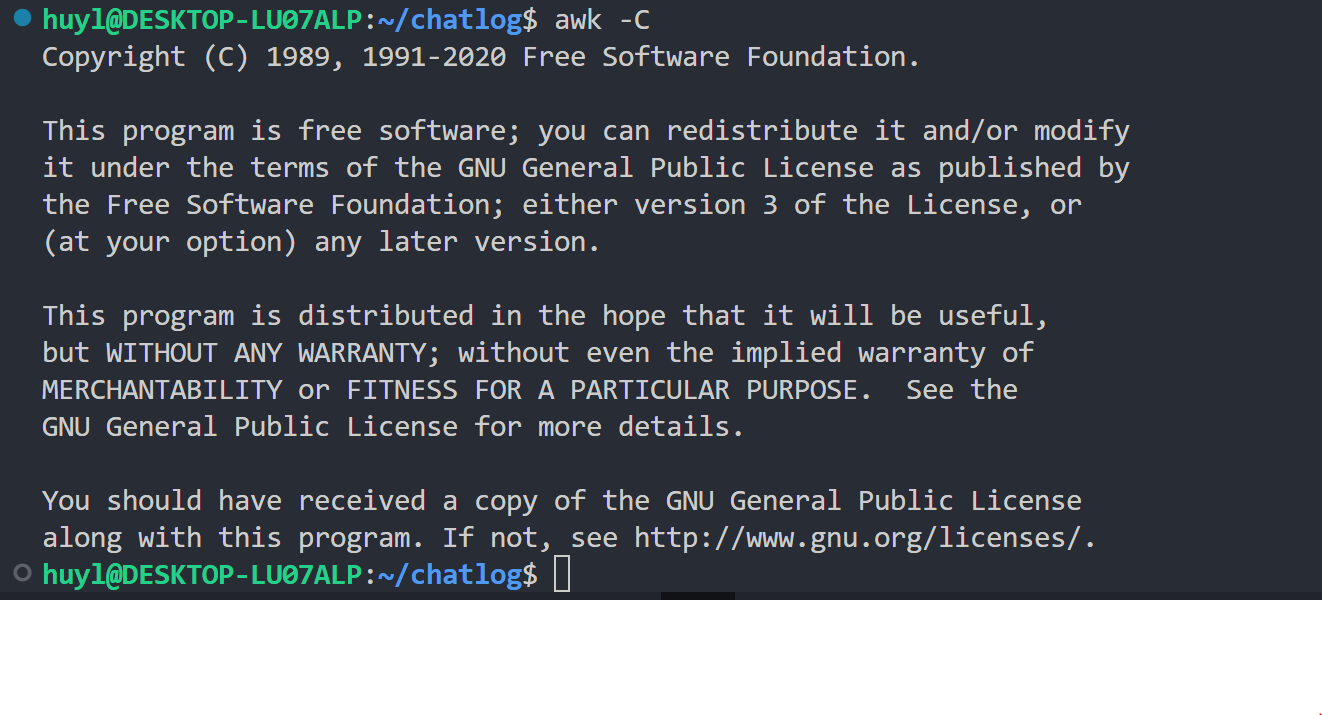
解释:这里会显示 awk 的版权信息
--help: 显示帮助信息,效果:
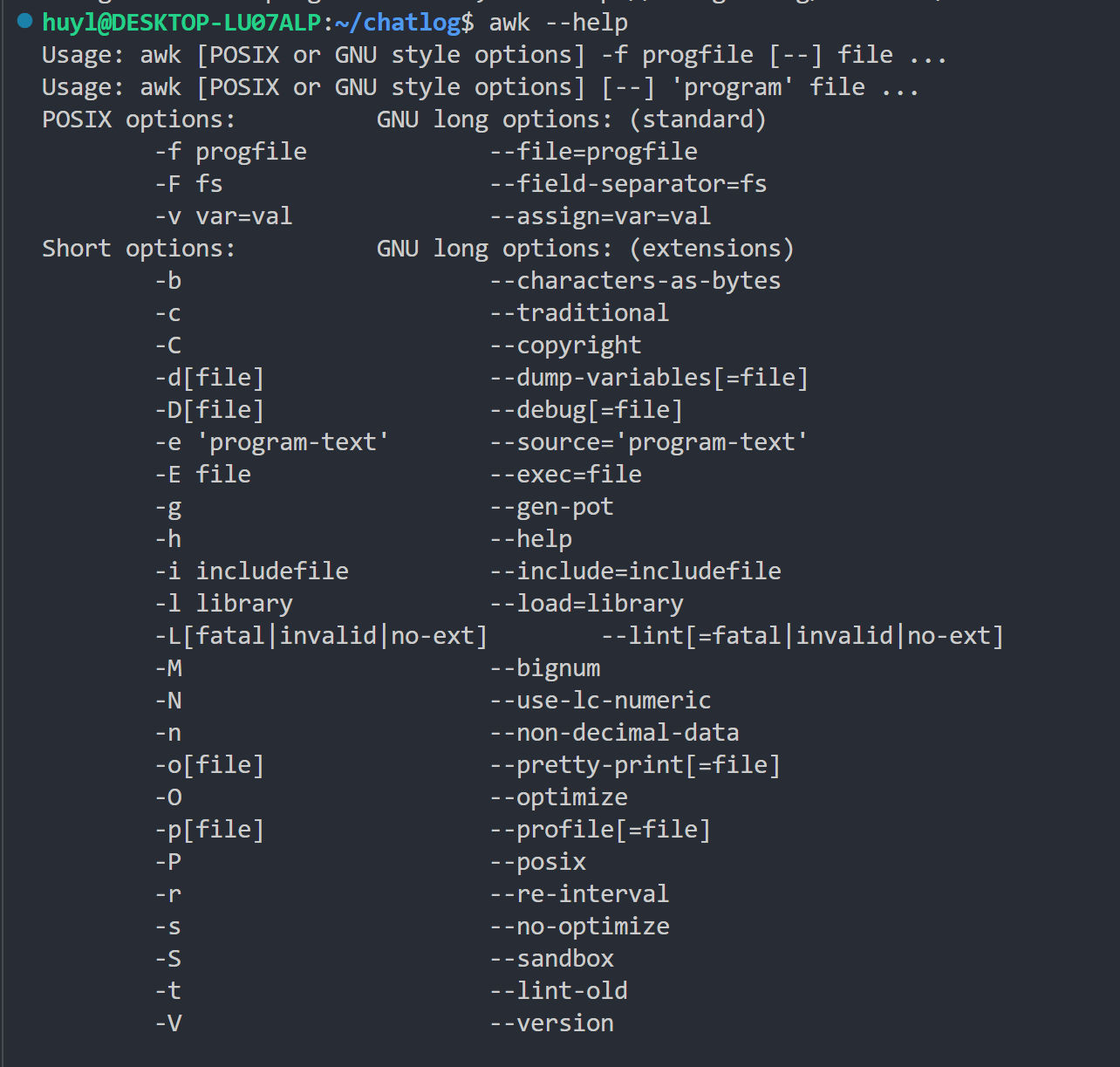
解释:这里会显示 awk 的简单帮助信息
🧾 4. awk 语法
awk 的脚本语句具备了编程语言的核心特性:支持变量定义、函数封装、逻辑分支控制,他甚至还提供了数组和命名空间等高级特性。这使得 awk 在处理复杂文本任务时展现出强大的灵活性。
⚠️ 注意:awk 的脚本语句如果是直接写在命令行中需要用 ' ' 包裹起来防止 shell 提前解析,如果是写在脚本文件中则不需要。
🔍 4.1 变量、字段和记录
在 awk 中可以定义和使用变量,变量分为两类:内置变量 和自定义变量。
- 自定义变量 :与 Shell 脚本类似,可以直接通过赋值语句创建,比如 。自定义变量的初始值默认为空字符串或 0,类型会根据使用场景自动在字符串与数值之间转换。变量名必须以字母或下划线开头,可包含字母、数字和下划线,但不建议与内置变量重名。效果:

解释:这里我定义了自定义变量 count 和 name 并把他们打印出来。
-
内置变量 :由 awk 预定义,用于描述输入内容、输出行为或程序运行状态。记录 和 字段 就是其中较为重要的两个内置变量。由于内置变量较多,所以内置变量相关的内容会放到第5节详细介绍。
-
记录(Record) :awk 是按行处理输入文本的,所以默认以换行符分隔的一行文本称为一条 记录,对应内置变量 $0。效果:

解释:这里我将所有匹配到 include 字符串的记录全打印出来。
- 字段(Field) :记录内部通过字段分隔符划分为若干部分,称为 字段 ,在对应的内置变量中分别用 1、2、$3... 表示。效果:

解释:这里我将所有匹配到 main 字符串的记录的第二个字段,以及对应的行号打印出来,可以看到 main 函数在第17行。脚本种的 NR 也是重要的内置变量之一,表示当前匹配到的行所在的行号。
🎯 4.2 匹配和操作
awk 中有种特殊的语法结构
awk
pattern { action }这个语法结构的操作逻辑是先匹配满足 pattern 条件的行,然后对每个匹配到行执行 action 中的代码。
匹配模式的类型有以下 4 种:
- 正则匹配 :
/pattern/ { action } - 字段匹配 :
$1 ~ /pattern/ { action } - 范围匹配 :
pattern1, pattern2 { action } - 特殊模式 :
BEGIN、END
效果:
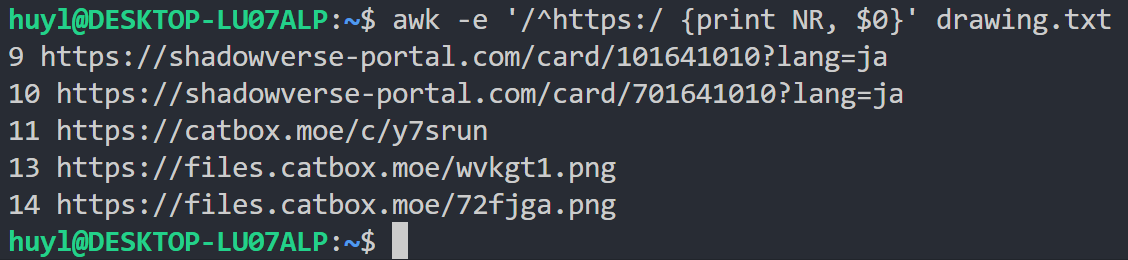
解释:这里我用的是正则匹配,从 drawing.txt 种匹配以 https:开头的记录,并打印记录以及行号。
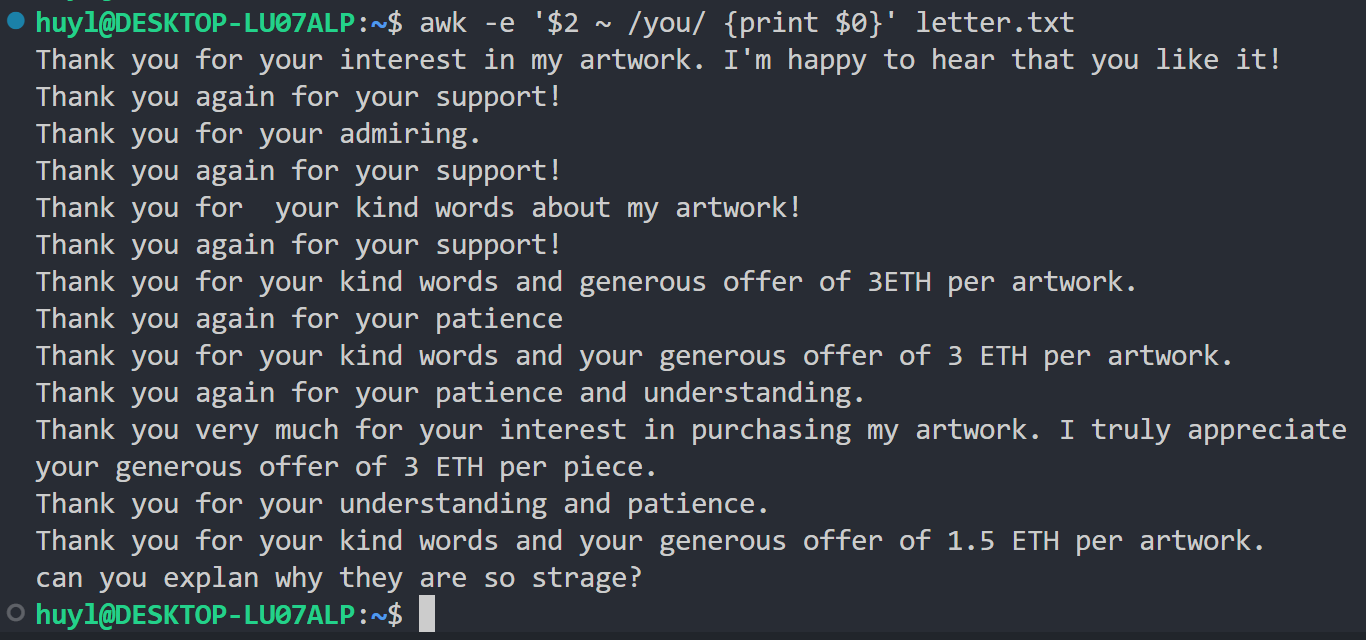
解释:这里我用的是字段匹配,从 letter.txt 种匹配第二个字段等于 you 的行,并打印记录。
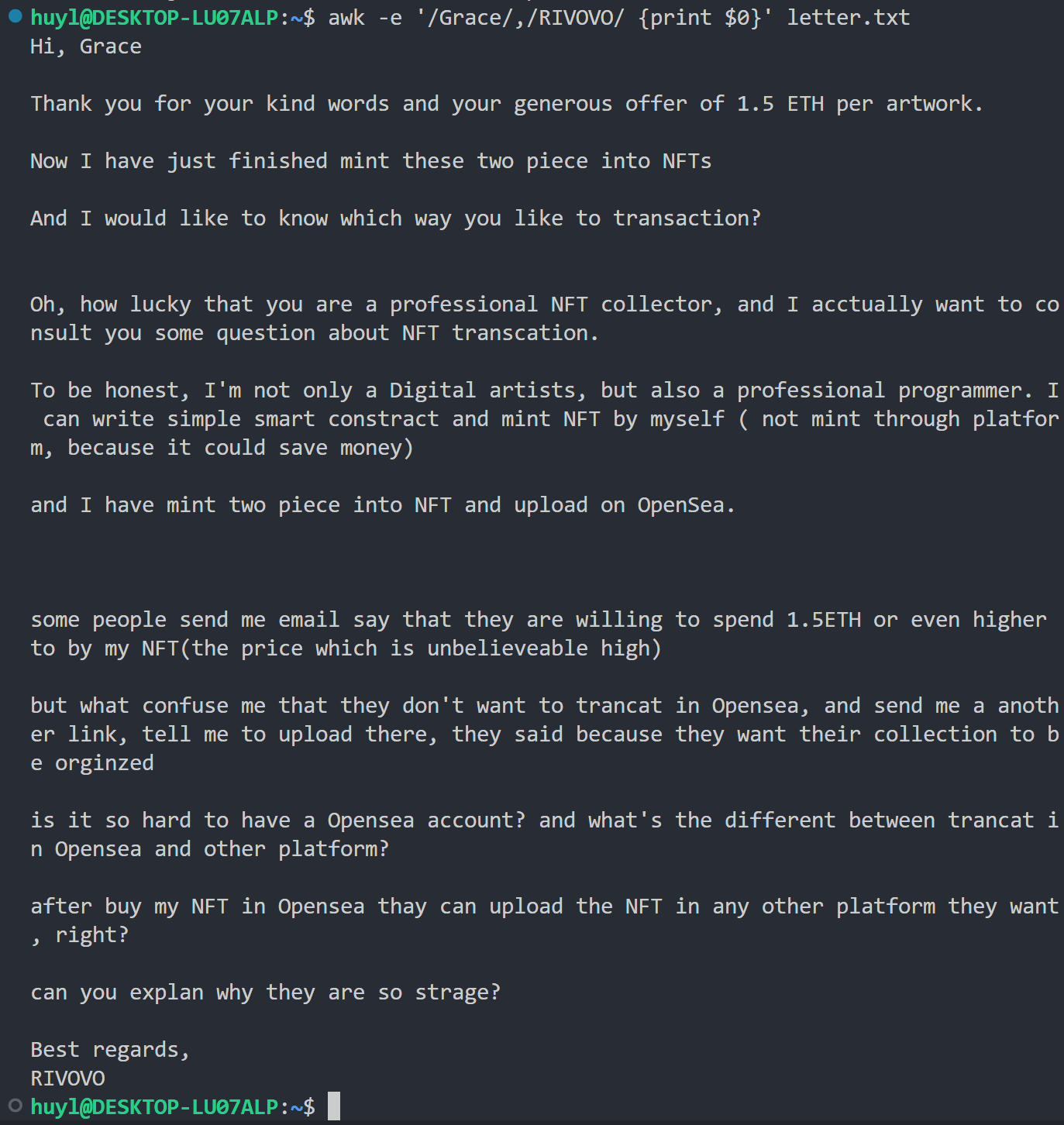
解释:这里我用了范围匹配,匹配了从 Grace 到 RIVOVO 之间的所有记录,并将其打印了出来

解释:这里我用了特殊匹配,BEGIN 表示在所有程序执行之前,后面跟的 action 会在awk 匹配文件之前执行,这里我将 awk 的内置变量 FS ,即字段分隔符在所有程序执行之前改成了 . 。然后再打印 FS 变量。如果是 END 表示在所有程序执行之后
🔁 4.3 逻辑控制
awk 和别的语言一样,支持条件判断、循环、流程控制的逻辑控制语句
- 条件判断 :awk 中的条件判断语句用
if-else if-else来表示,效果:

解释:这里我用 if 条件控制语句筛选出 test.c 中以 int 开头的行并将其打印出来。
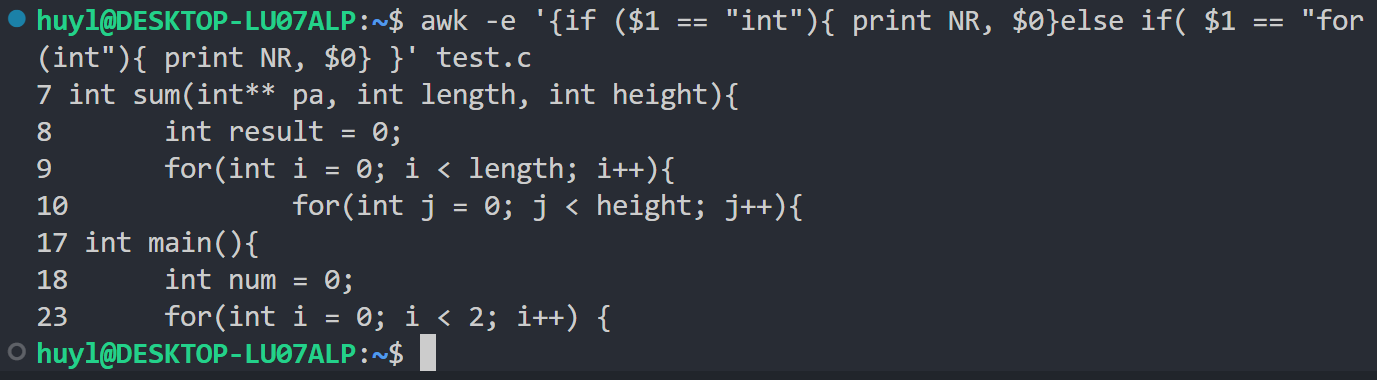
解释:这里我用 if-else if 条件控制语句筛选出 test.c 文件中以 int 或者 for(int 开头的行并将其和对应行号打印出来
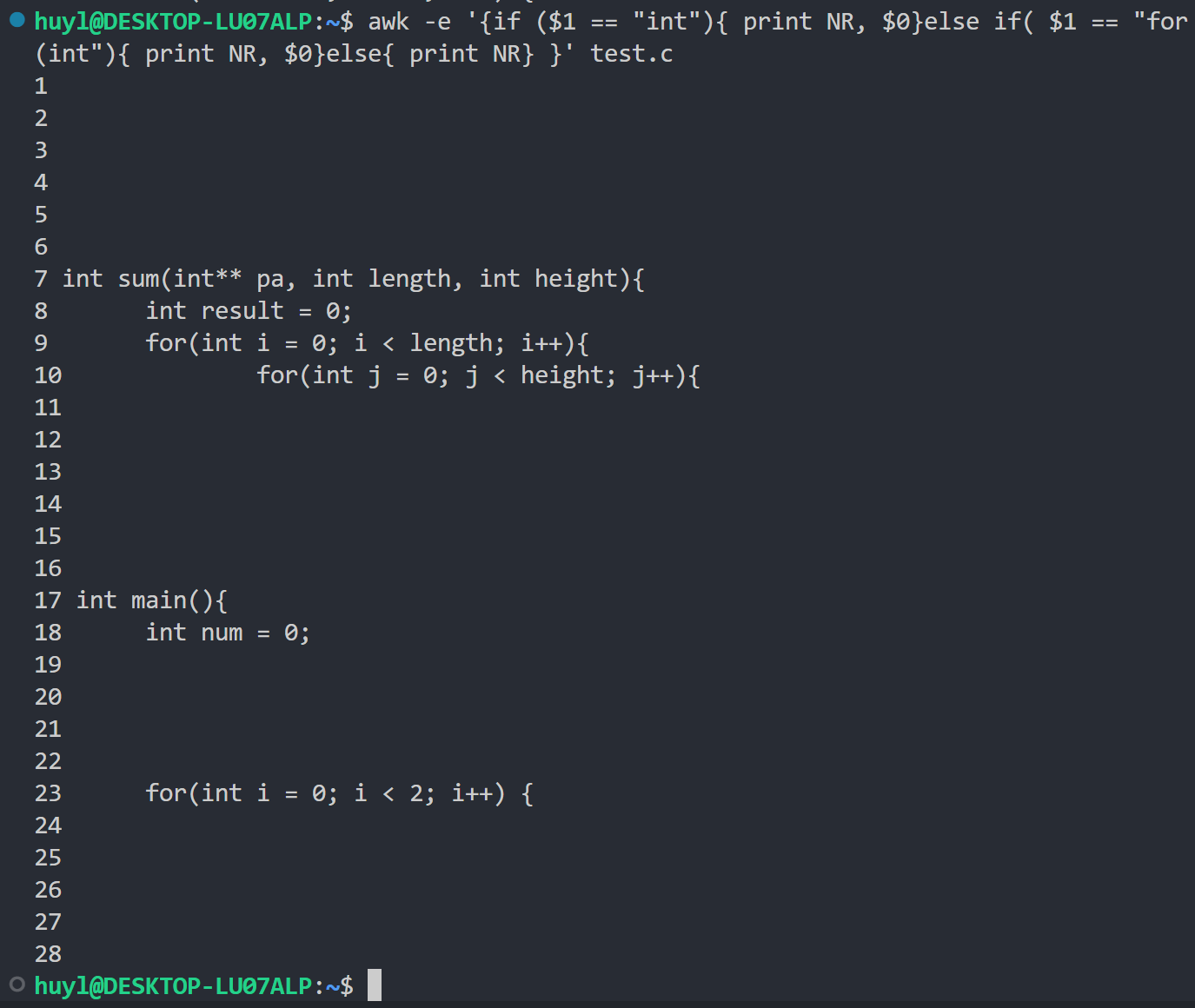
解释:这里我用 if-else if-else 语句筛选出 test.c 文件中所有以 int 或 for(int 开头的行并将其对应的行号和内容打印出来。没有 int 或 for(int 开头的行只打印行号。
- 循环 :awk 中的循环语句用
while、for、do-while来表示,效果:
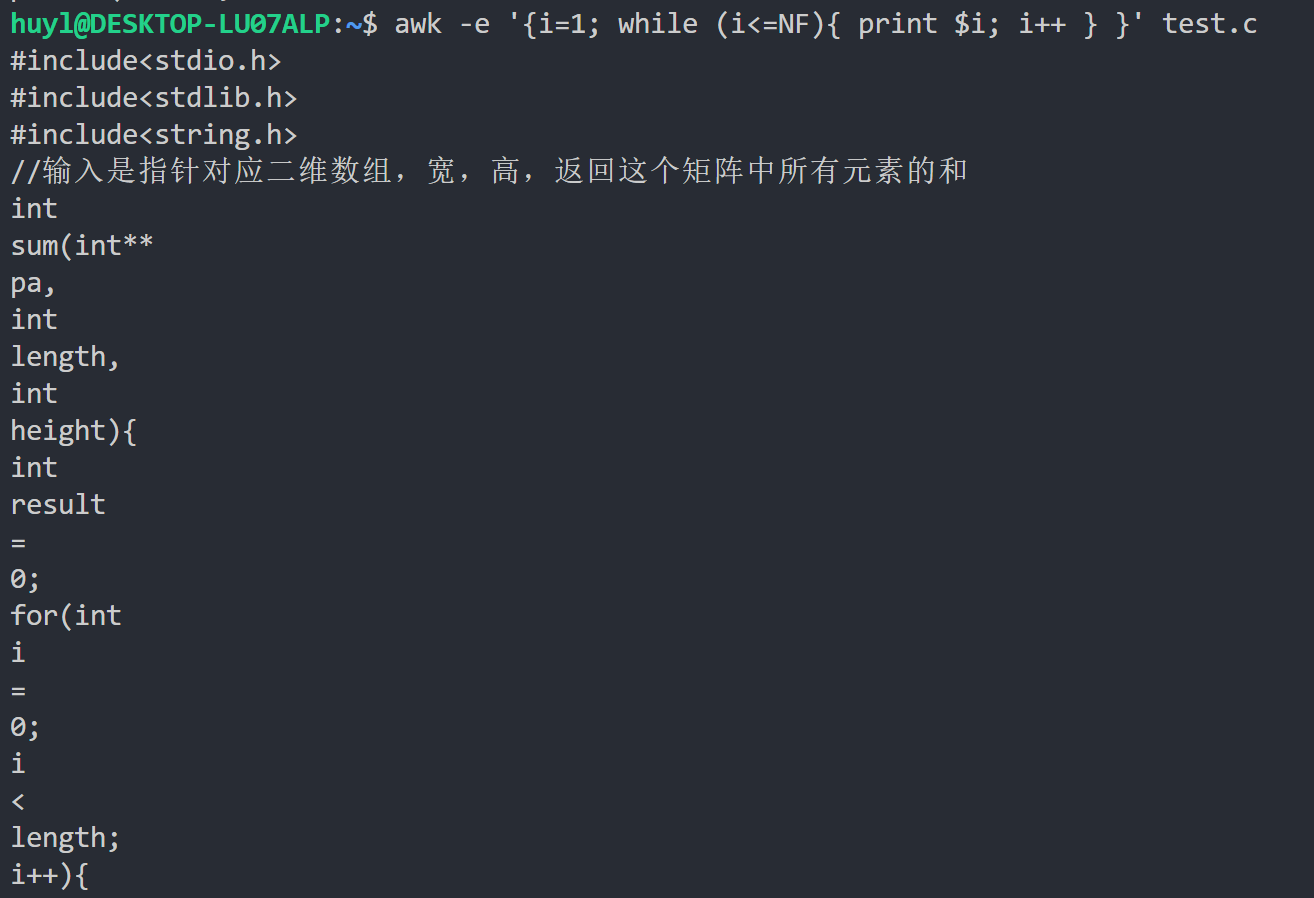
解释:这里我用 while 循环语句将 test.c 文件中每一行的每个字段依次打印出来
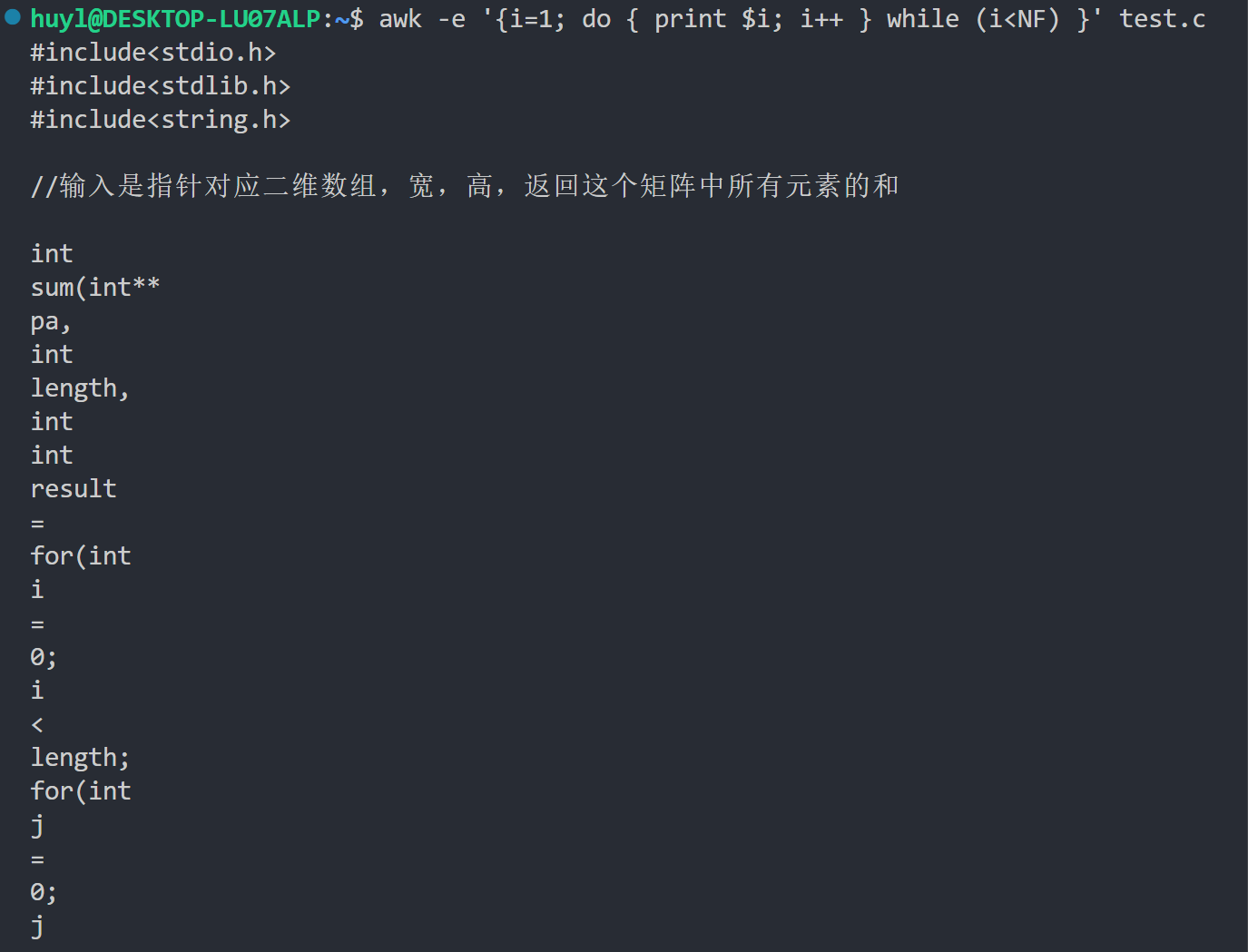
解释:这里我用 do while 语句将 test.c 文件中每一行的每个字段依次打印出来,但是和上面哪个不同,由于在判断 i 和 NF 的大小之前会先打印依次,所以导致了 NF 位0的空行直接被打印出来了。
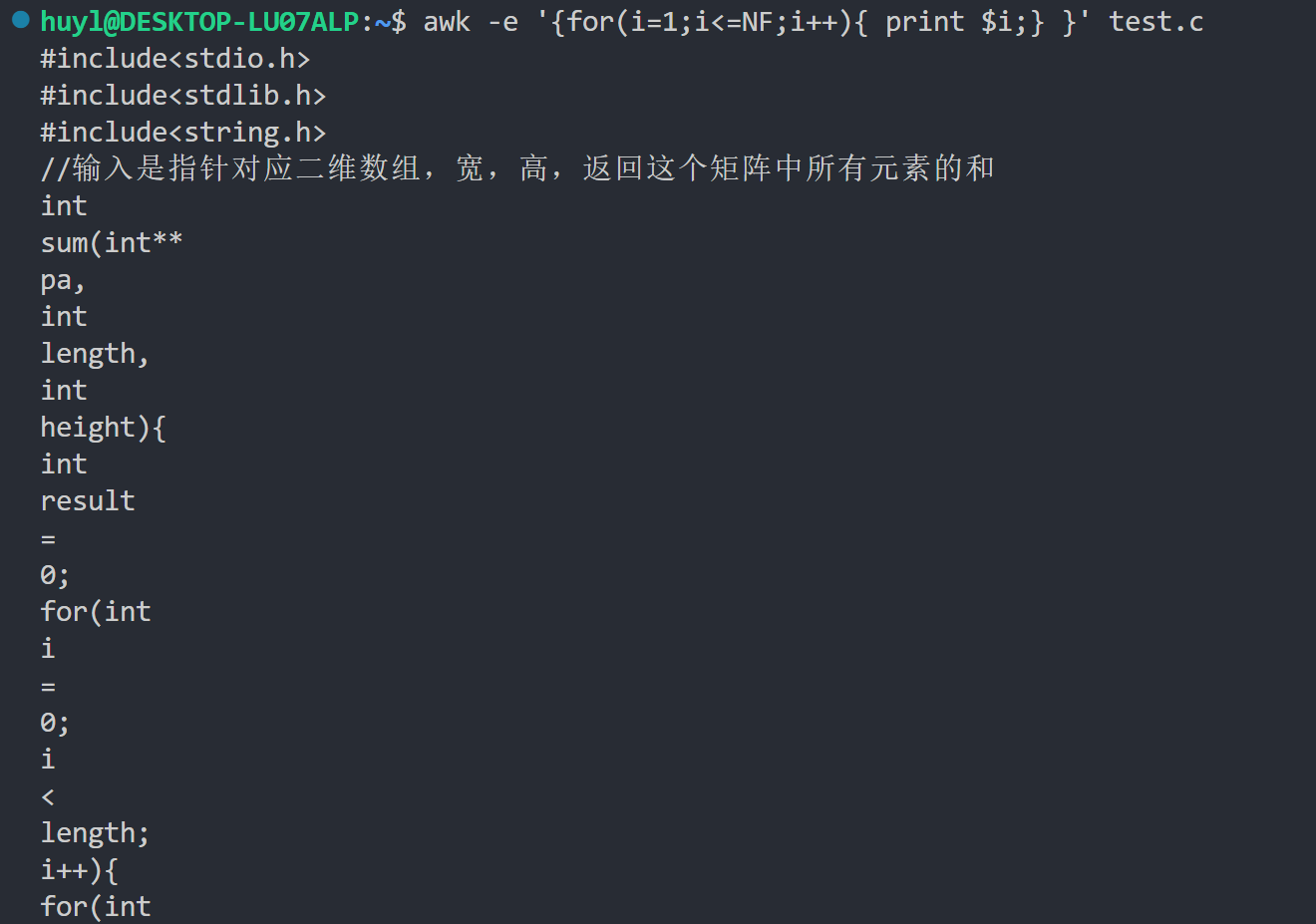
解释:这里我用 for 语句将 test.c 文件中每一行的每个字段依次打印出来
- 流程控制 :awk 还可以用
break、continue来控制循环流程,用next、exit来控制处理记录的流程,效果:
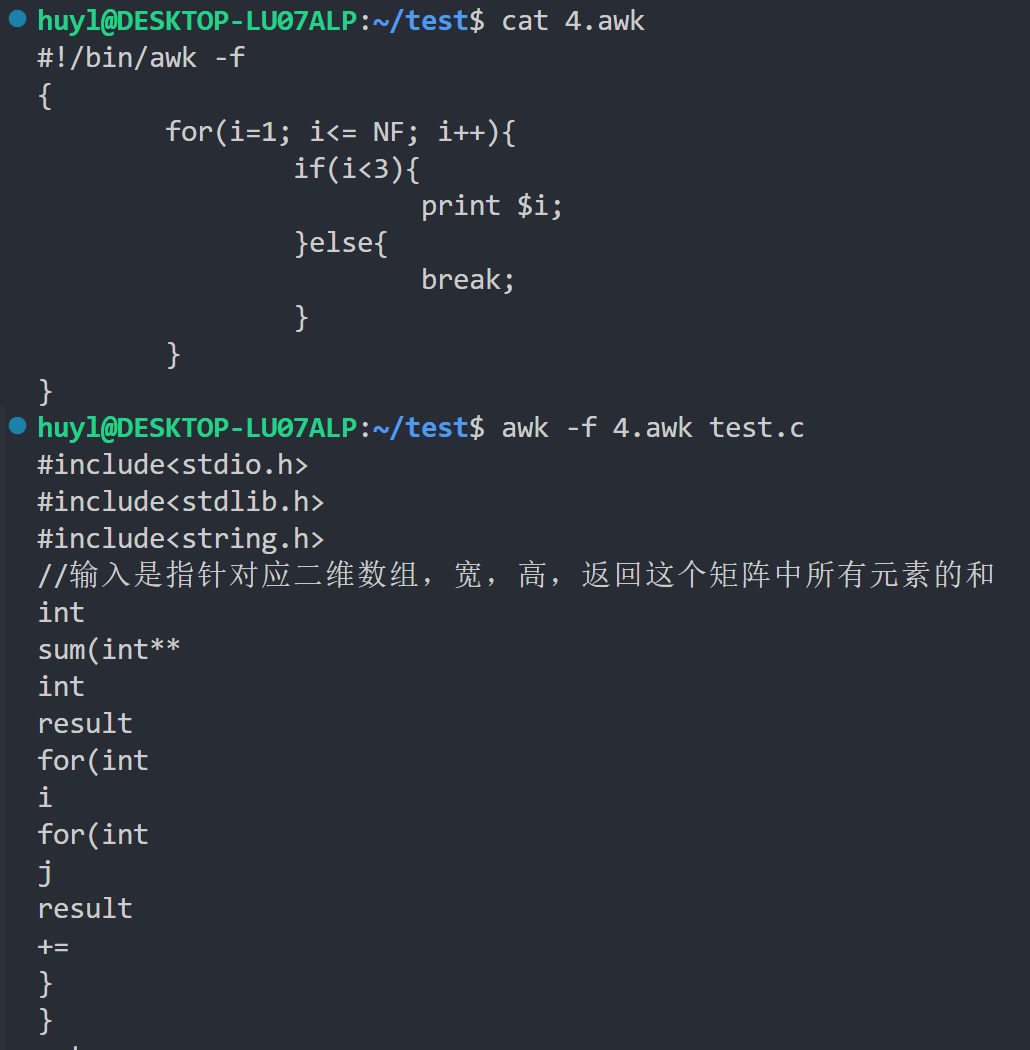
解释:这里我用了 for 语句 + if 语句 + break语句,将每行前两个字段打印出来
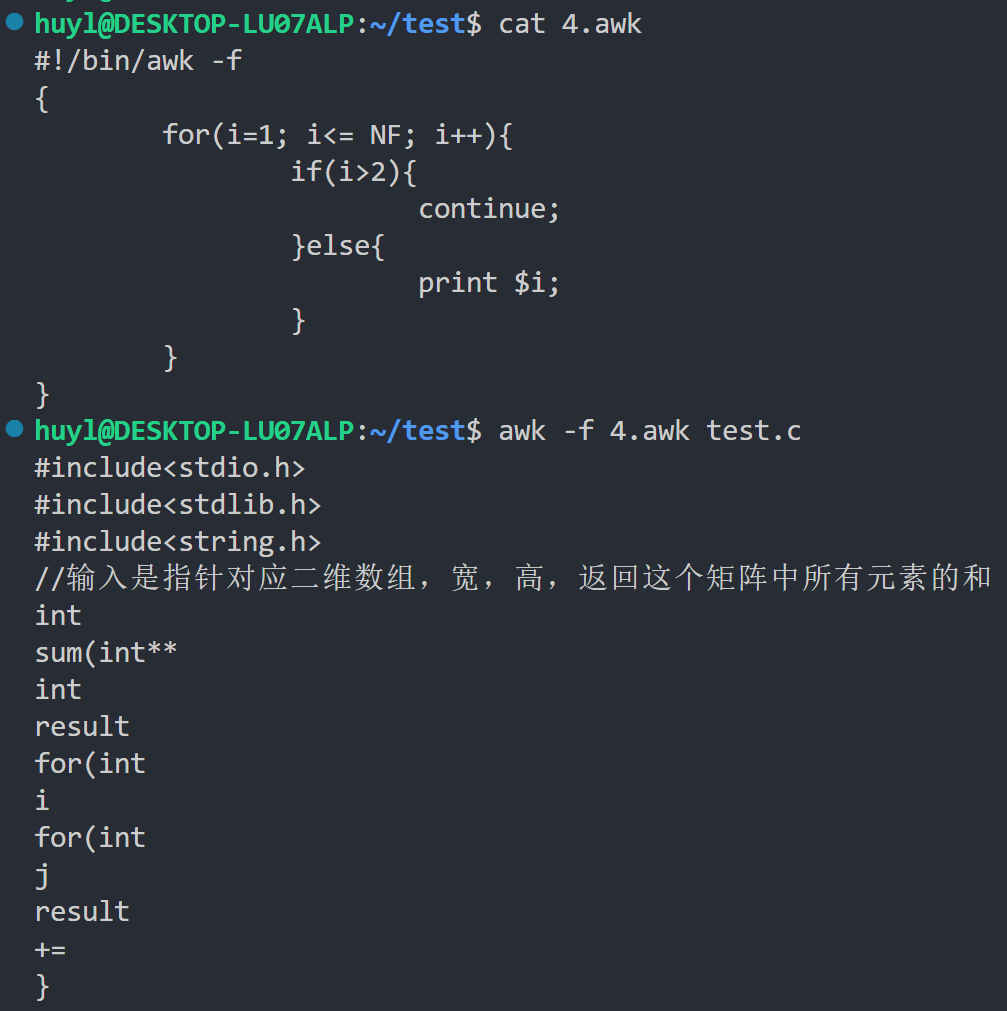
解释:这里我用了 for 语句 + if 语句 + continue语句,将每行前两个字段打印出来(这里我用相同效果的例子绝对不是因为复制粘贴省事)
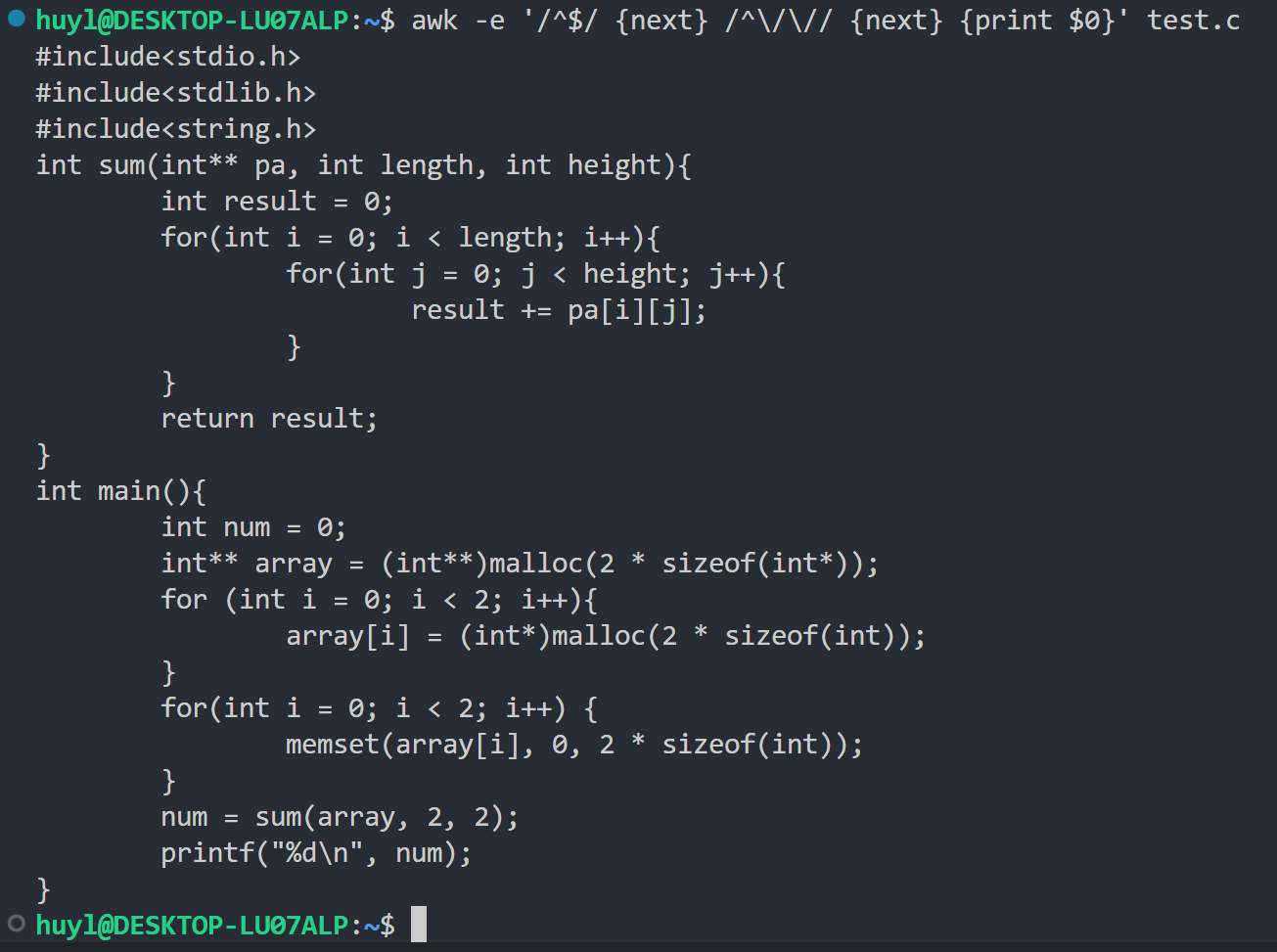
解释:这里我用了正则匹配 + next 语句,跳过了空行和注释行打印其余的内容
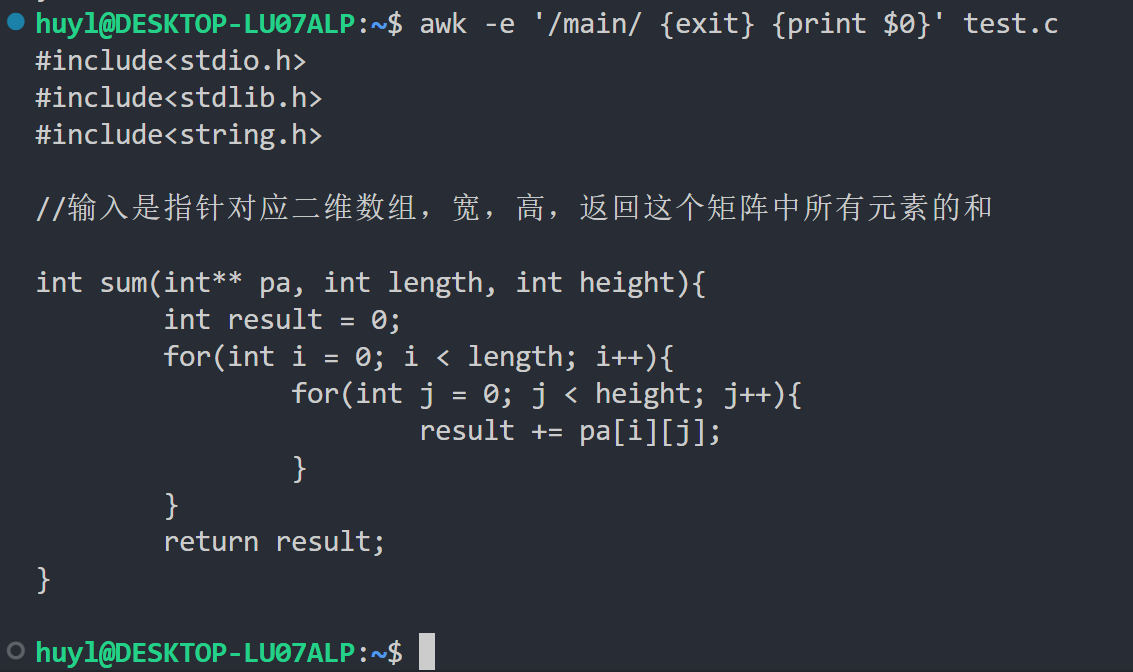
解释:这里我用了正则匹配 + exit 语句,让 awk 程序在匹配到 main 这个字符串的时候退出,所以只打印了从开头到 main 函数之间的内容
🗂️ 4.4 数组
- 关联型数组:awk 中提供了数组的数据结构。但是他这个数组是关联型数组,也就是说数组的元素实际上是个键值对。数组的下标为元素的键,数组元素的值为元素的键值。键和键值可以是数字也可以是字符串。效果:
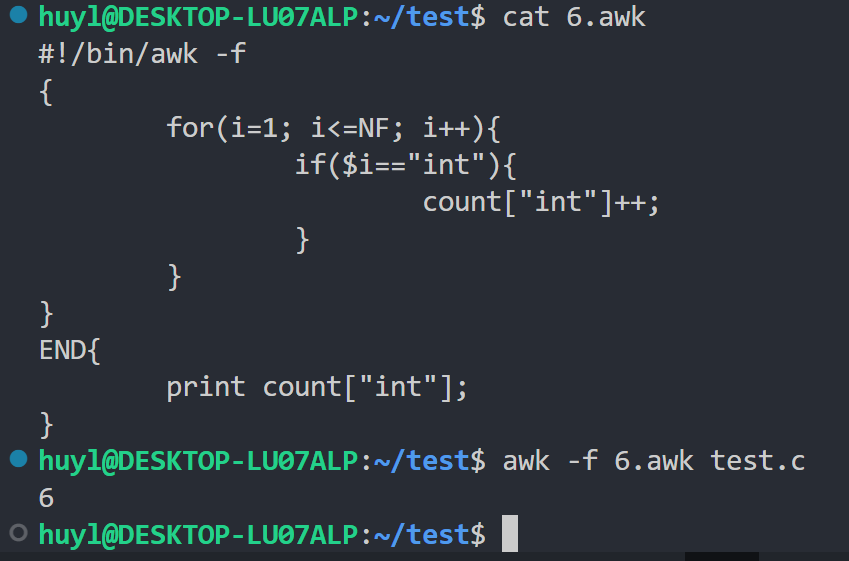
解释:这里我用一个数组来统计 test.c 中 int 字符串出现的次数,结果是6次。
- 元素自动创建:用 awk 访问数组中不存在的元素时会自动创建,效果:
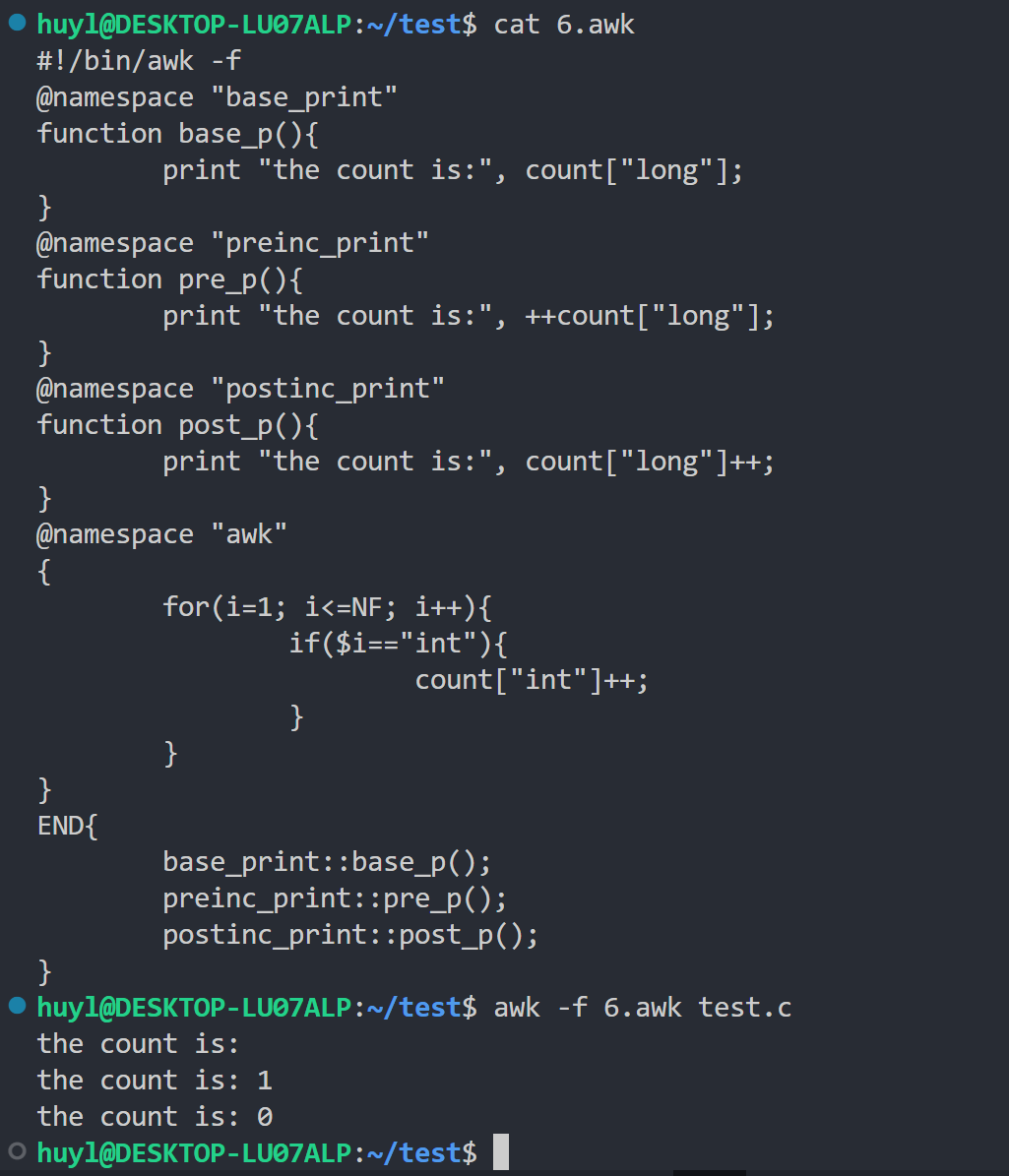
解释:这里我用命名空间分割了3个 print 函数,分别在 END 代码块中调用了这3个不同的 print 函数访问了不存在元素 long 。第一次访问没有加任何计算打印了空,第二次访问做了前加加,打印了1。第三次访问做了后加加,打印了0。可见如果访问不存在元素的时候 awk 会自动初始化为空字符串,如果访问的时候周围有运算符号则会自动初始化为0。(命名空间的语法后面会讲,这里先接过来用一下,实在看不懂也可以先跳到后面命名空间的小节,看完后再回来理解这一段)
- 数组无序遍历 :可以用
for (key in array)的形式遍历 awk 数组,但是数组的便利顺序不确定。如需排序需额外处理,效果:
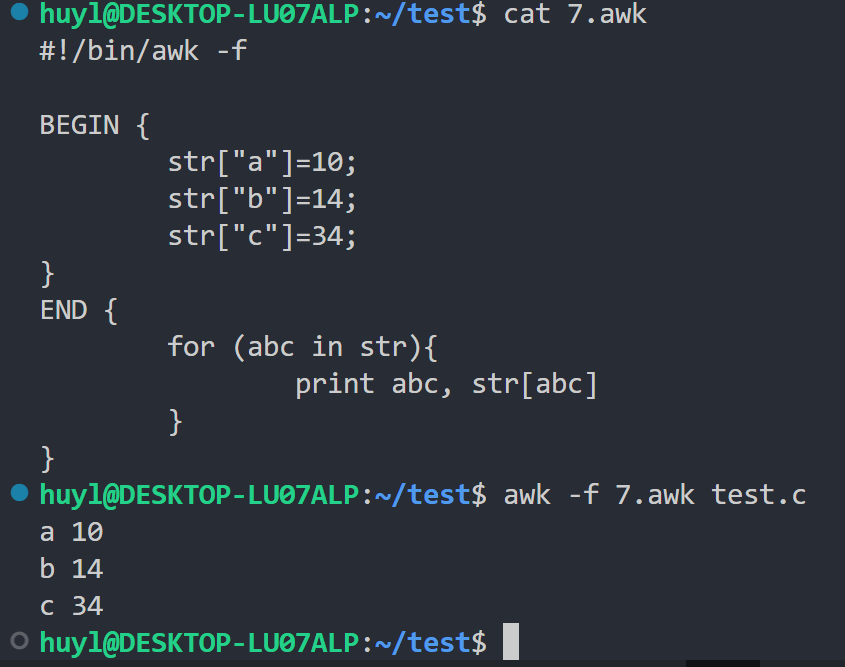
解释:这里我定义了 str 数组并遍历了这个数组打印了数组中每个元素的键和键值。
🧮 4.5 函数与命名空间
- 自定义函数:awk 中用户可以定义和使用自定义函数,效果:
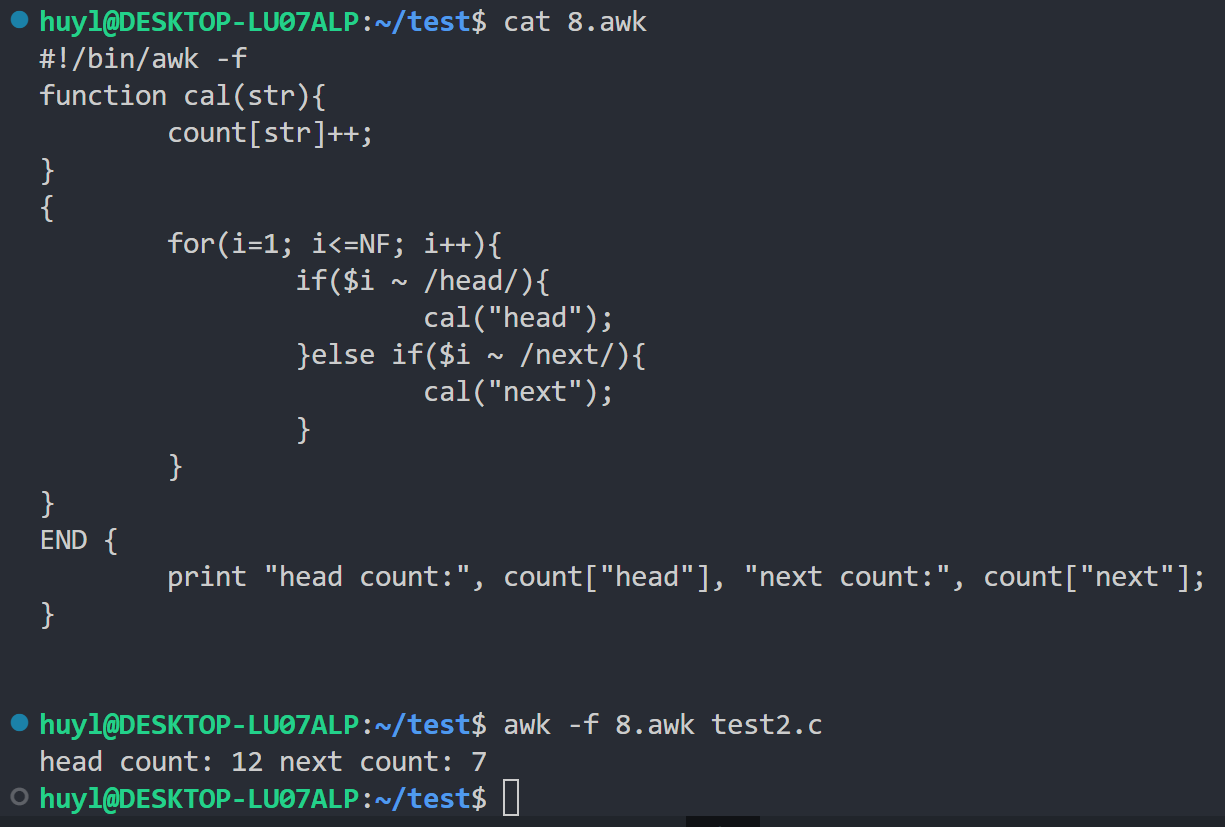
解释:这里我开头定义了一个 cal 自定义函数用来创建数组统计各个字段出现的次数。然后在主代码块中匹配 head 和 next 字段,匹配到了就调用 cal 函数进行字段数统计,最后在 END 代码块中打印统计信息。需要注意的是这里的匹配方式是
$i ~ /head/而不是$i == "head"。前者只要在一行任何位置出现 head 字符串都算匹配成功,而后者匹配的是完整的 head 字符串,必须 head 前后都是空格才能匹配成功。如果 head 前面或后面有其他字符,比如list->head或者head;都会匹配失败。
-
内置函数:awk 提供了丰富的内置函数,这些函数由 awk 定义好,用户只需要调用就行了。由于内置函数较多,所以与内置函数相关的内容会放到第6节详细介绍。
-
命名空间:awk 中的变量默认都是全局变量,不好控制容易冲突,所以 awk 提供了命令空间用于组织代码和控制变量。效果:
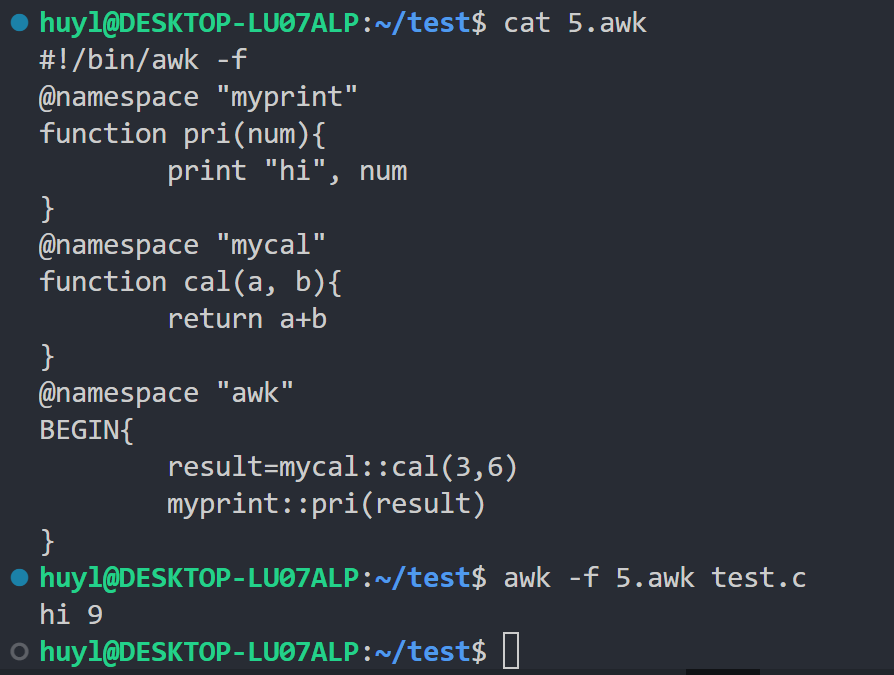
解释:这里我在脚本中先定义了 myprint 命名空间的 pri 函数打印 hi 和入参 num,然后定义了 mycal 命名空间的 cal 函数对入参进行相加并将结果作为返回值返回,最后我切换回 awk 默认的命名空间在 BEGIN 代码块中调用了这两个函数,先利用 cal 函数将3和6相加,再将结果传给 pri 函数打印。
⚠️ 注意:awk 的命名空间只能写在 .awk 后缀的脚本文件中并通过 awk 的脚本用法使用,直接写在命令行中通过 awk 的基础用法使用会出现syntax error。也就是说基础用法的 awk 无法识别命名空间这种语法(我试了很多遍了不行)。
⚠️ 注意:@namesapce "awk"为 awk 的默认命名空间,即如果你什么 namespace 都不写,所有定义的函数和变量都正在 "awk" 这个命名空间下。所哟i如果你定义了别的命名空间,别忘了最后切换回 "awk" 这个主命名空间后再调用。
🧰 4.6 数学计算与表达式
- 算数运算符:awk 支持基本的算数运算符,包括加减乘除和取模,效果:

解释:这里我分别计算了 a 和 b 相加、相减、相乘、相除、取模的结果。
- 比较运算符:awk 支持比较运算符,不仅可以比较数字还可以比较字符串,效果:
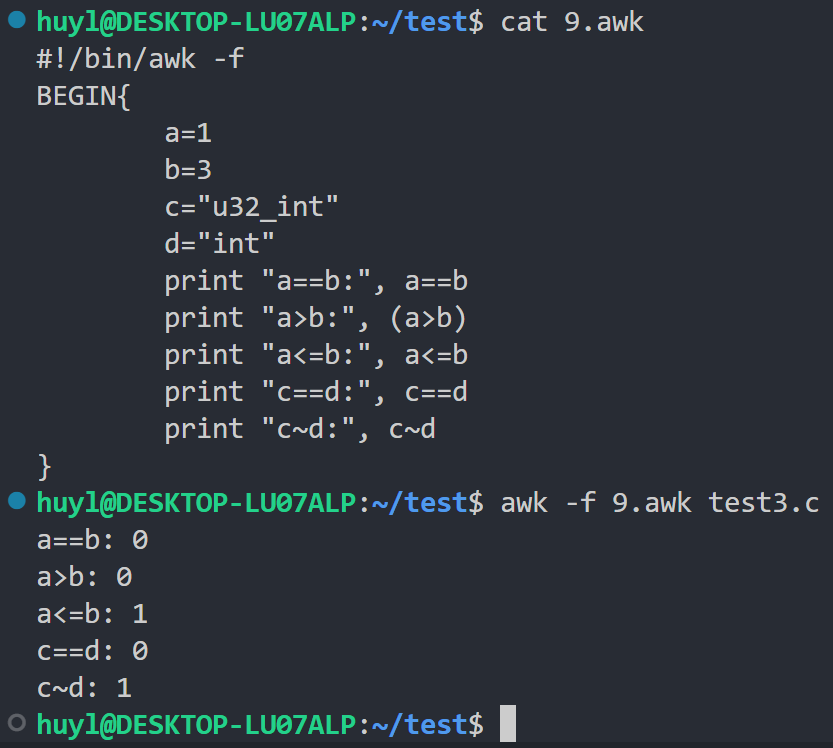
解释:这里我分别比较了数字变量 a 和 b 是否相等、a 是否大于 b 、a 是否小于等于 b 。然后我又比较了字符变量 c 和 d 是否相等,c 是否匹配正则表达式 d 。可以看出 awk 的比较运算返回的结果是 0 和 1 。
⚠️ 注意:在这5个比较运算中,我唯独把 a>b 用括号括起来。知道为什么吗?因为如果不括起来你会发现a>b: 0这行死活打印不出来,然后当前文件夹下还会出现一个名字为 3 的文本文件,打开一看发现里面只有一行 a>b: 1 。相信聪明的你应该已经猜到发生了什么了。没错,awk 的 print 函数有个特殊用法 print ...... > file.txt。这个用法会创建一个file.txt文件,然后把......中的内容写道 file.txt 中。当 awk 不确定你这个 > 是大于号还是重定向符号时,会默认把 > 当成重定向符号。所以不加括号相当于把 "a>b:", a 写入了 b 。这里 a 是 1, b 是 3 ,所以就出现了内容为 a>b: 1 名字为 3 的神奇的文件。
- 逻辑运算符: awk 还支持逻辑运算符,通常配合比较运算符使用,效果:
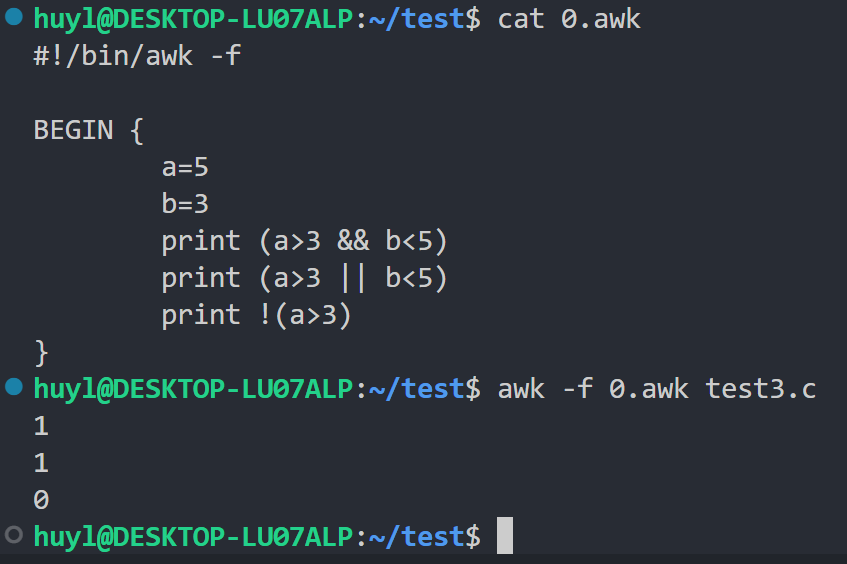
解释:这里我分别用了 && 、 || 、 ! 来处理比较运算 a>3 和 b<5 的结果,第一个 print 两个都是1所以与运算的结果是1,第二个 print 两个都是1所以或运算的结果是1,第三个 a>3 的结果是1所以非运算的结果是0
📊 5. awk 内置变量
awk 的作者们设计了一套自动更新的上下文环境变量,这些变量在 awk 每次读入新行时都会被自动更新,程序员可以直接使用。这些变量的存在大大简化了 awk 的使用。这些变量就是 awk 的内置变量。
🧵 5.1 参数信息变量
这些内置变量与调用 AWK 脚本时传递的命令行参数相关。
ARGC: 表示命令行参数的数量。类似于 C 语言中的argc。效果:

解释:这里我在命令行输入了6个参数,但是最后打印 ARGC 的结果是4,这是因为 awk 默认把 -e 和 '{BEGIN {print ARGC}' 当成了选项参数 ,而不是输入参数。所以 awk 认为输入参数只有4个,即 awk、test.c、test2.c、test3.c。
ARGV: 表示命令行参数的数组。类似于 C 语言中的argv。效果:

解释:这里我写了一个循环,利用上面讲到的 ARGC 来遍历 ARGV 数组中的每个元素,可以看到 awk 确实认为命令行参数只有 awk、test.c、test2.c、test3.c。
ARGIND: 当前正在处理的文件在ARGV中的索引。效果:
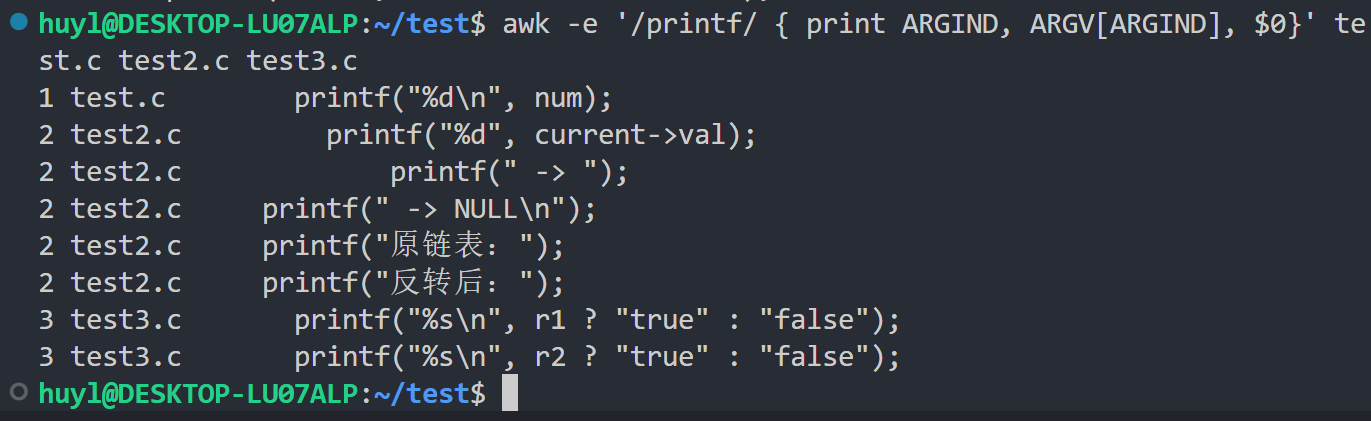
解释:这里我将每一次匹配到 printf 函数是正在处理的文件在 ARGV 中的索引,正在处理的文件名,以及正在处理的行打印出来。可以清楚的看到 test.c、test2.c、test3.c 分别打印了什么。
✂️ 5.2 分隔变量
这些变量控制 AWK 如何将输入行分割成字段(列)和记录(行)。
FS: 字段分隔符。默认是空格(包括空格和制表符)。你可以将它设置为任何字符串或正则表达式,AWK 会根据它来分割每一行的字段。效果:
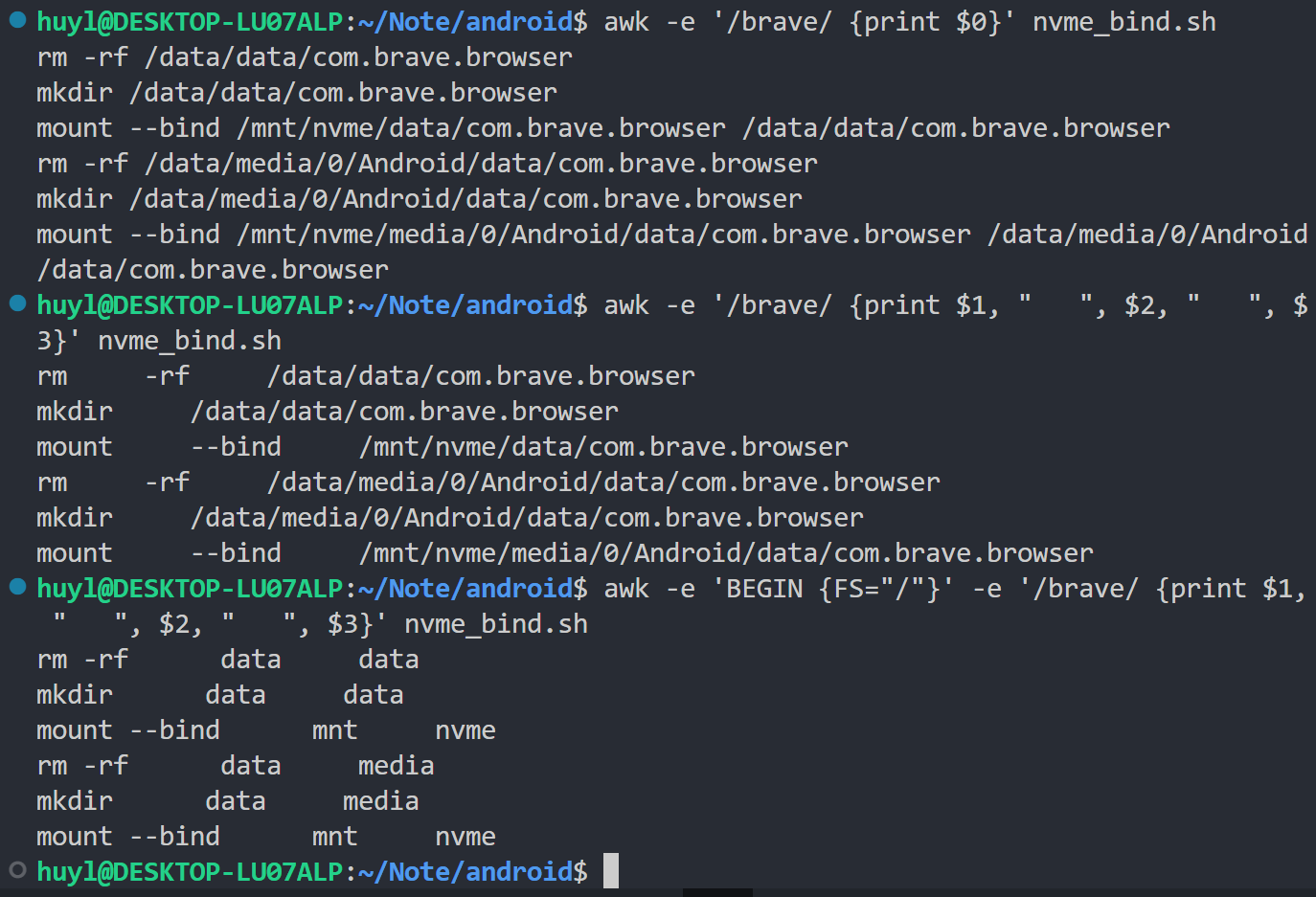
解释:这里第一条命令我打印了所有匹配到 brave 字符串的记录(行),第二条命令我打印了匹配到 brave 字符串的记录中的第一二三个字段。这里我没有设置 FS 变量,awk 默认 FS=" ",所以看到三个字符都是以空格为分隔符分割开的。第三条命令我在打印第一二三个字段之前设置了 FS="/" ,所以 awk 将 / 作为分隔符分割记录,从结果可以看出三个字符都是以 / 为分隔符分割开的。
- RS : 记录分隔符。默认是换行符
\n。你可以修改它来处理非标准格式的文件。AWK 会根据它来分割每份文件中的记录。效果:
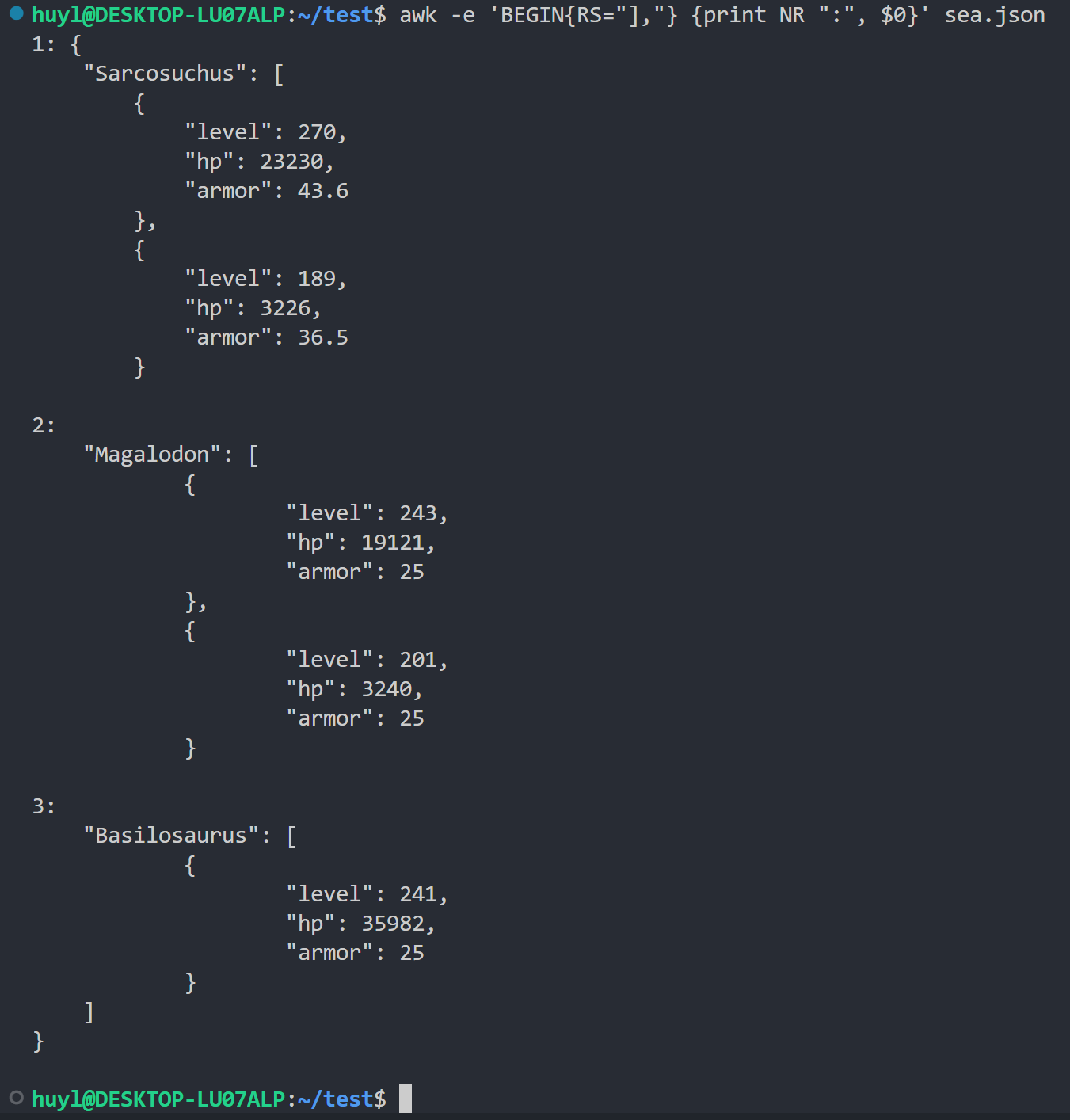
解释:这里我用
],作为分隔符来分割记录,并把分割后的记录打印出来。可以看到1,2,3条记录分别对应着JSON串中的相应元素。
- FIELDWIDTHS : 一组以空格分隔的数字,指定每个字段的固定宽度。当设置此变量后,AWK 将启用固定宽度的字段分割模式,忽略
FS。效果:
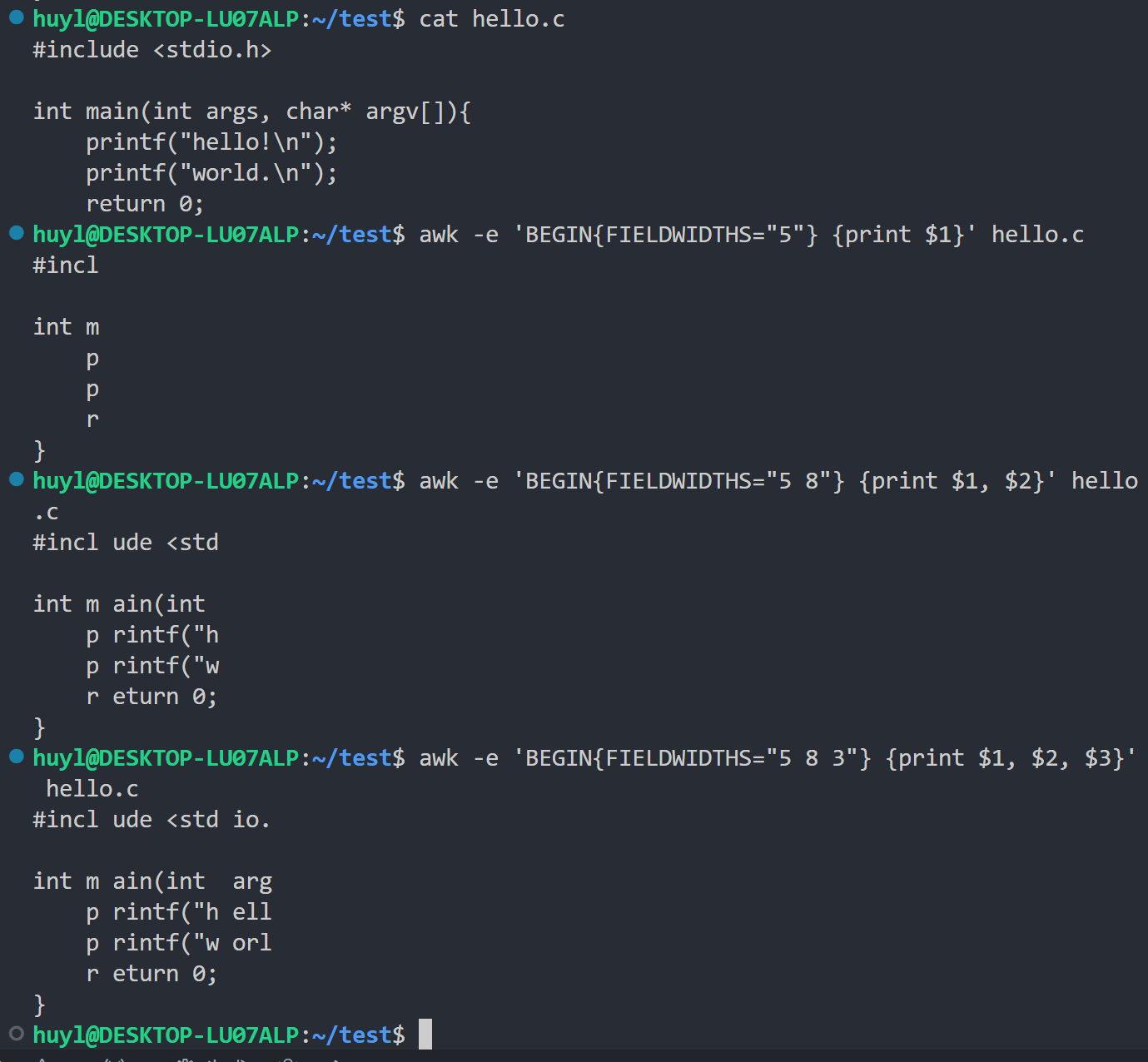
解释:这里的 FIELDWIDTHS要严格遵守
FIELDWIDTHS="1 2 3"形式的语法,如果少了双引号或是空格改成了逗号都会直接报错。双引号之间的数字表示第n格字段包含几个字节。比如我第一条命令 FIELDWIDTHS="5" 就表示第一个字段包含5个字节,从后面 print $1 可以看出打印出来的第一个字段确实只有5个(int m包括空格一共5个字节),说明 awk 按照字节数而不是分隔符把记录分割成字段。第二条命令 FILEDWIDTHS="5 8"表示第一个字段包含5个字节,第二个字段包含8个字节;第三条命令 FIEDWIDTHS="5 8 3" 表示第一个字段包含5个字节,第二个字段包含8个字节,第三个字段包含3个字节。
- FPAT: 这个内置变量是一个正则表达式,用于描述一个字段的内容,而不是字段的分隔符。当你需要匹配一个模式来定义字段,而不是用分隔符来分割时,可以考虑使用这个内置变量。效果:
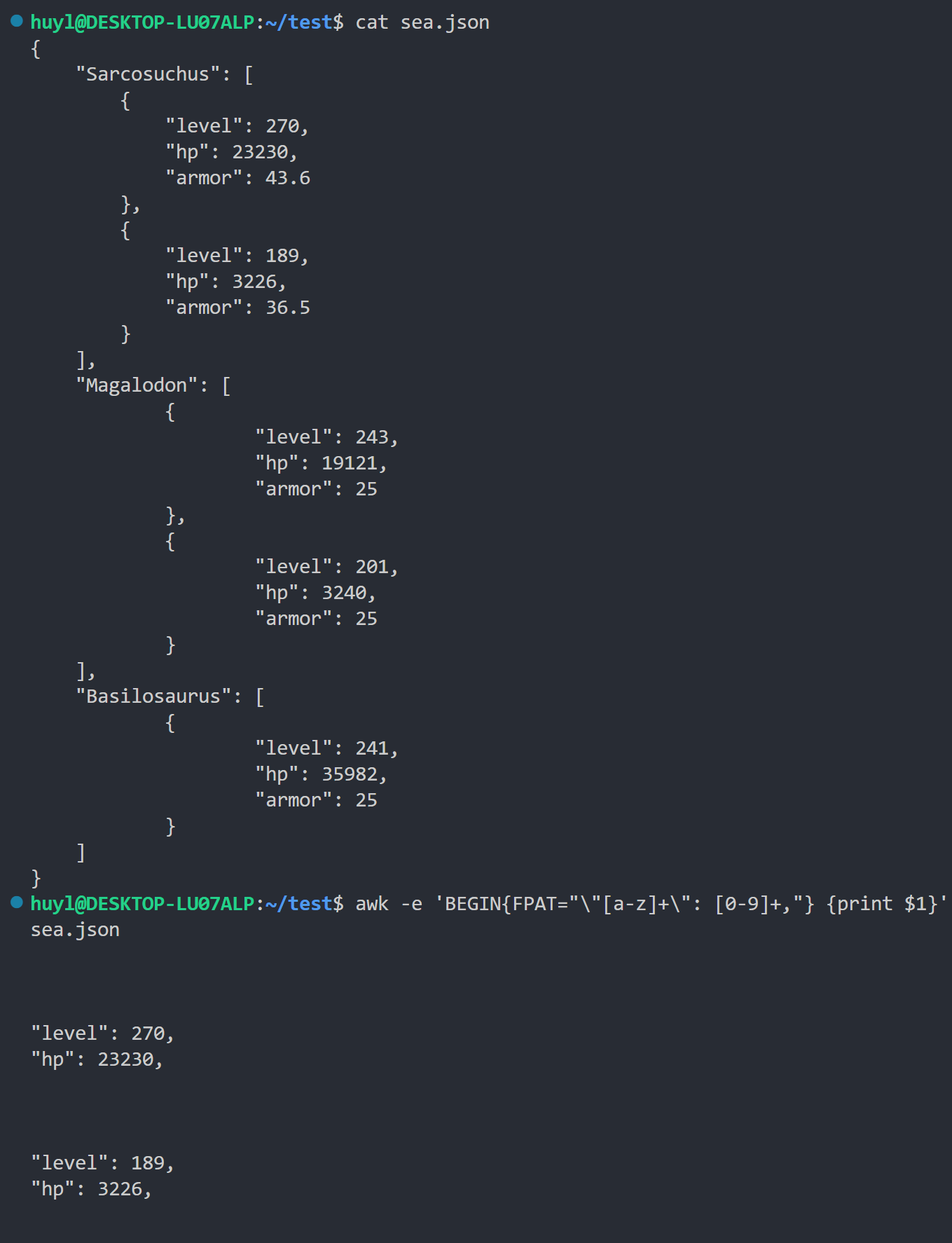
解释:这里我构造了一个键值对的正则表达式把他塞给FPAT来匹配键值对,awk 会把匹配到的内容放到第一个字段中,如果没有匹配到第一个字段就是空。从打印出结果可以看到第1-3行没匹配到所以是空,第4-5行匹配到了所以打印了键值对。
- OFS : 输出字段分隔符。当使用
print语句打印多个以逗号分隔的字段时,AWK 会用OFS(默认是空格)来连接它们。效果:
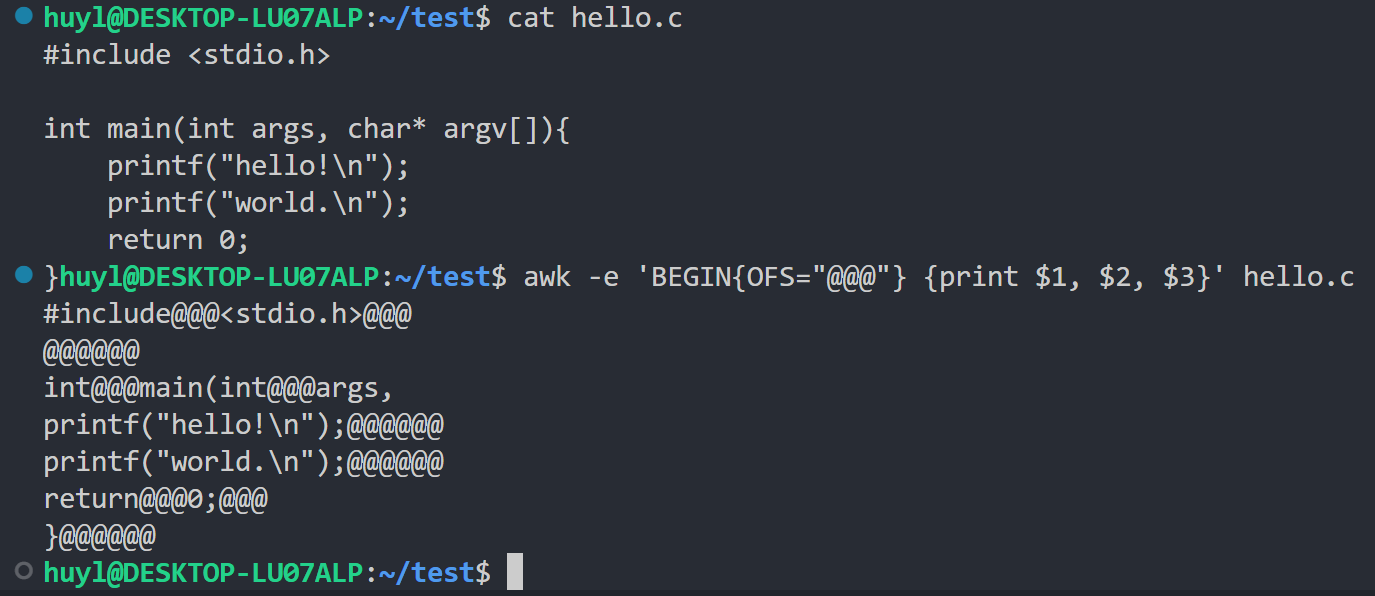
解释:这里我在程序开始的时候把 OFS 改成了@@@,可以看到原来应该用空格分割的字段在打印的时候变成用@@@分割了。空行由于第一第二第三个字段都是空,所以三个空之间塞两个@@@就是@@@@@@;只有一个字段的由于第二第三个字段都是空,所以第一第二字段之间塞@@@,第二第三字段之间塞@@@加起来就是@@@@@@
- ORS : 输出记录分隔符。控制
print语句结束时输出的字符,默认是换行符\n。效果:
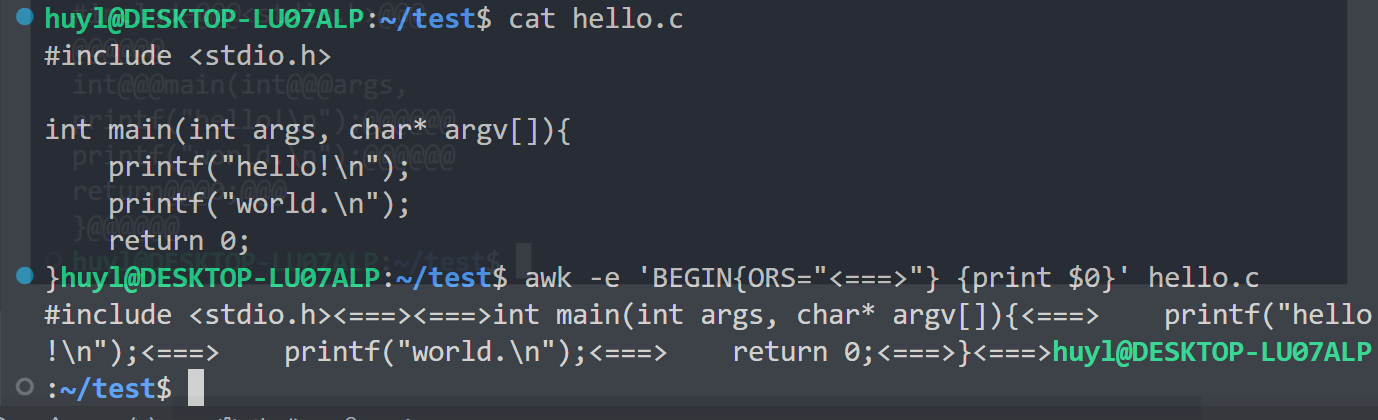
解释:这里我在程序开始前先把 ORS设置成了
<===>,所以在程序跑起来后本来应该用换行符分割的记录全部用<===>进行分割了
- SUBSEP : 数组下标分隔符。当使用多维数组(实际上是数组的数组)时,AWK 会自动用
SUBSEP(默认是\034,一个不可打印字符)来连接各个维度的下标。效果:
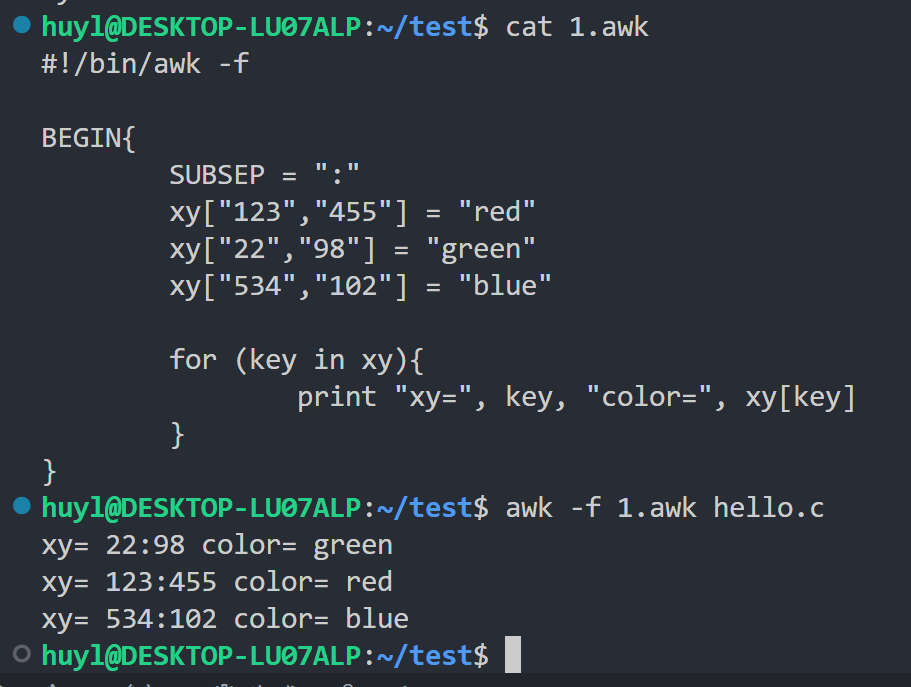
解释:这里我在程序开始前把 SUBSEP 设置成了
:,所以程序开始后打印的多维数组的键就是用:链接了。如果不设置默认使用,链接
📏 5.3 输入输出文件控制变量
这些变量控制数据的读写方式及其格式化。
- FILENAME : 当前正在处理的输入文件的名称。效果:

解释:这里我在程序运行结束的时候打印了当前处理的文件名,hello.c。需要注意的是如果你把 print FILENAME 写在 BEGIN 代码块中由于程序还没运行文件还没处理所以他只会打印一个空行。
- RT : 这个变量可以用来记录终止符。这个内置变量只有在
RS被设置为正则表达式时才会生效,RT包含了实际匹配到RS的文本。效果:
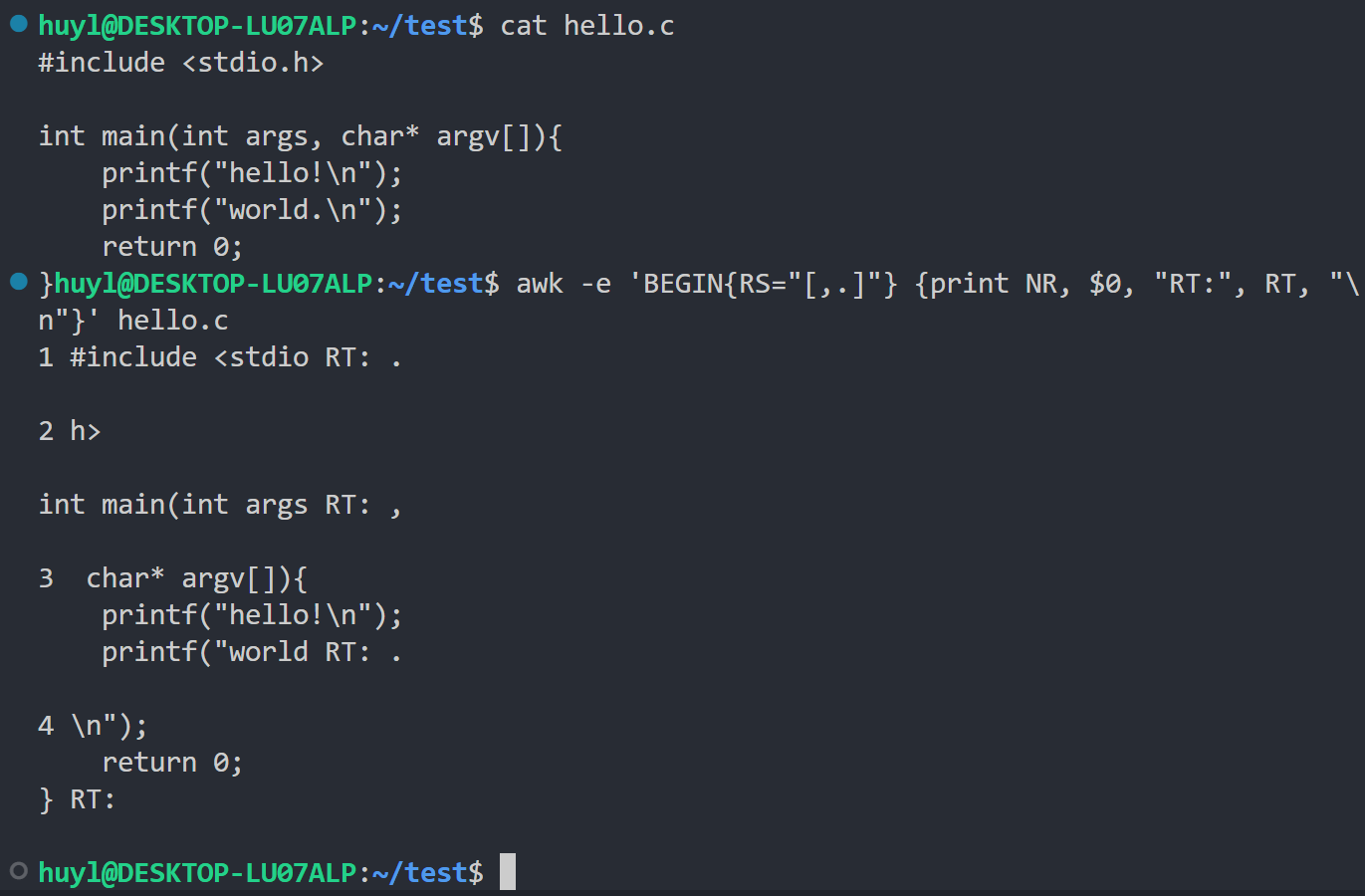
解释:这里我在程序执行前把 RS改成了逗号和句号,并且在程序运行时依次打印了记录号,记录值,RT值。本来以换行符来分割记录,现在用逗号和句号来分割记录了。所以在程序运行后打印出来的 RT 值也都是逗号和句号。
- BINMODE: 控制在非 POSIX 系统上(如 Windows)对输入/输出文件的二进制模式处理。设置为 1(输入)、2(输出)或 3(输入和输出),以防止 AWK 修改二进制文件中的换行符。效果:
解释:用 awk 处理二进制文件的时候设置的参数,一般是用来处理网络包、图片视频音频的。在处理来自 windows 系统的二进制文件时加上这个参数能防止换行符不被错误的解析。至于怎么处理的二进制文件,这东西我没法和你解释,因为我只是一只脚本小子。
- ERRNO : 一个字符串,描述了当
getline重定向或close()函数调用失败时的系统错误。如果发生了 I/O 错误,ERRNO会被设置为相应的错误信息字符串。效果:
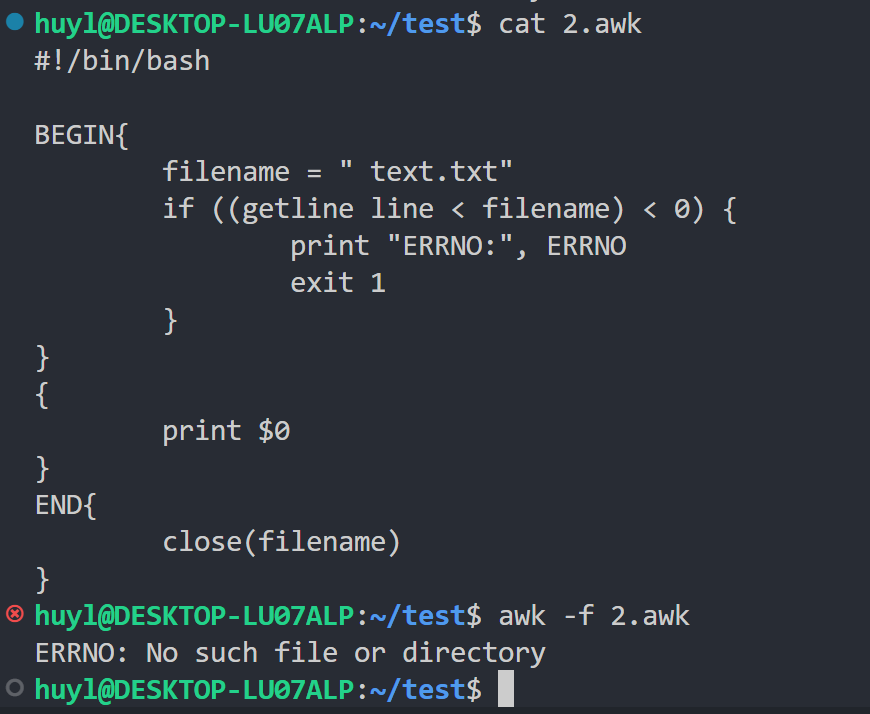
解释:这里我起了个不存在的文件名,并在 awk 中打开它,构造了一个找不到文件的错误,然后再利用 ERRNO 把错误信息打印出来,输出的
No such file or directory即是 ERRNO 的值。
📏 5.4 记录与字段统计变量
这些变量提供了关于当前正在处理的记录(行)的信息。
- FNR : 当前输入文件中的记录号(行号)。对于每个新文件,
FNR都会从1重新开始计数。效果:
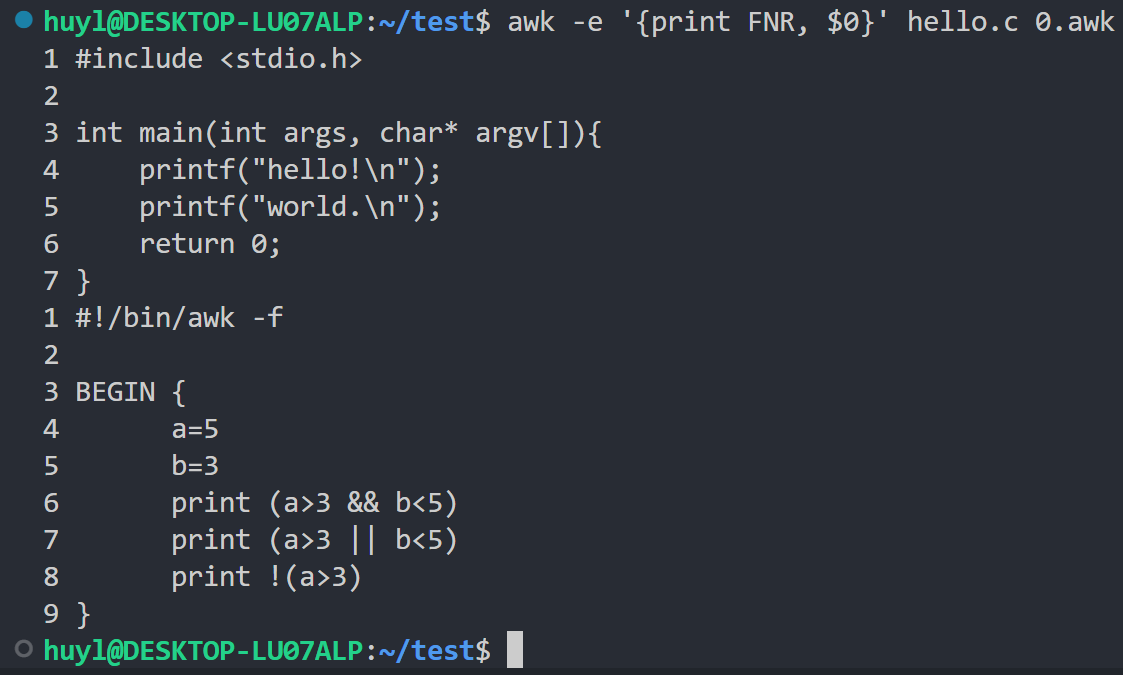
解释:这里我在awk中输入了两个文件,并打印了 FNR 和对应的记录。可以看到每个新文件的开始 FNR 都会从新变成1。
- NR : 总的记录号(行号)。从 AWK 开始执行起,处理的所有记录的总数。
NR不会因为处理新文件而重置。效果:
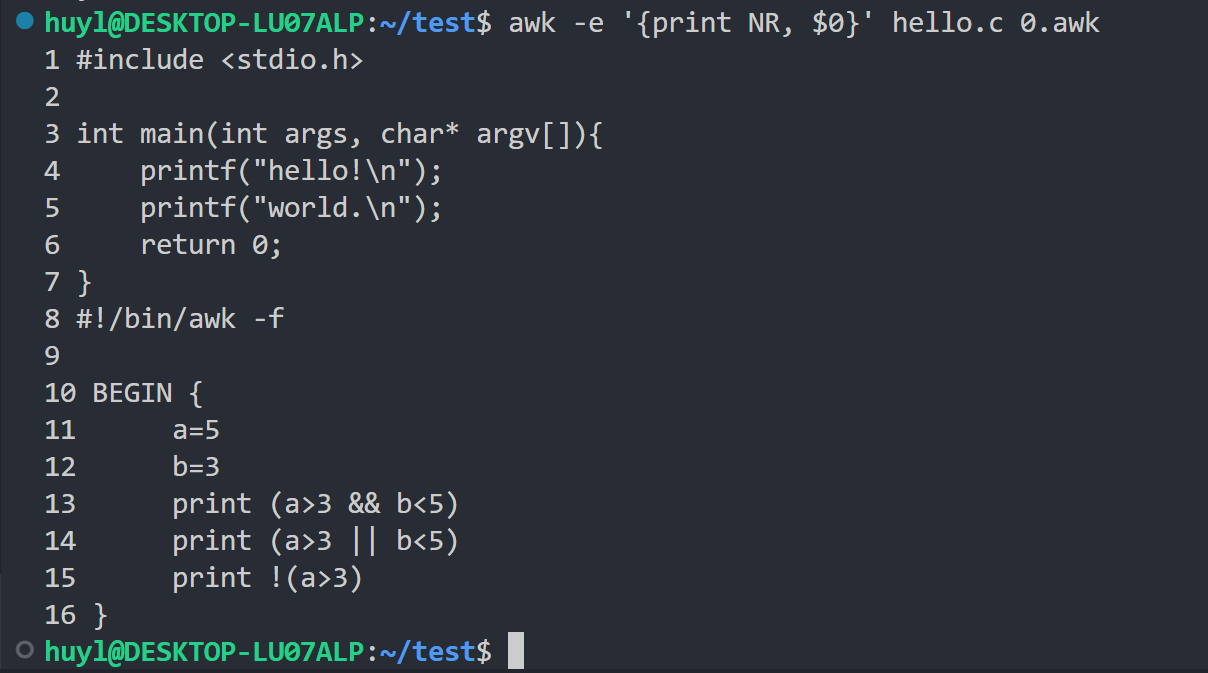
解释:这里我在awk中输入了两个文件,并打印了 NR 和对应的记录。可以看到 NR 即时处理多份文件也不会因为遇到新文件而变成1。
- NF : 当前记录中的字段数量。效果:
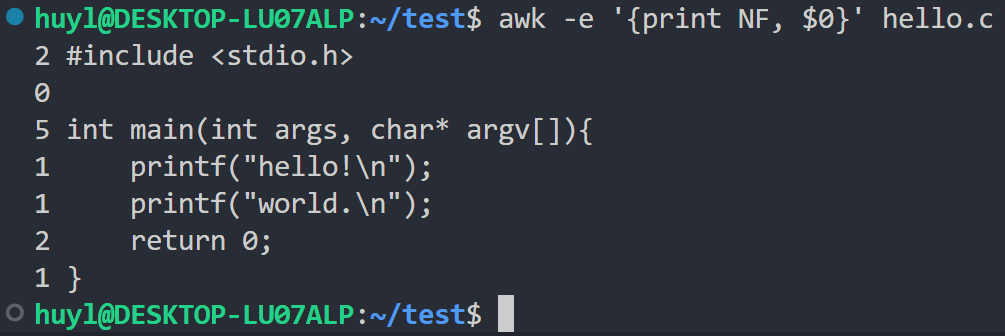
解释:这里我在 awk 中打印了每条记录对应的字段数,可以看到第一条记录用空格分割有2个字段,第二条0个第三条5个第四条1个第五条1个第六条2个第七条1个。
- RSTART : 由
match()函数匹配的字符串的起始位置。如果未匹配,则为 0。效果:
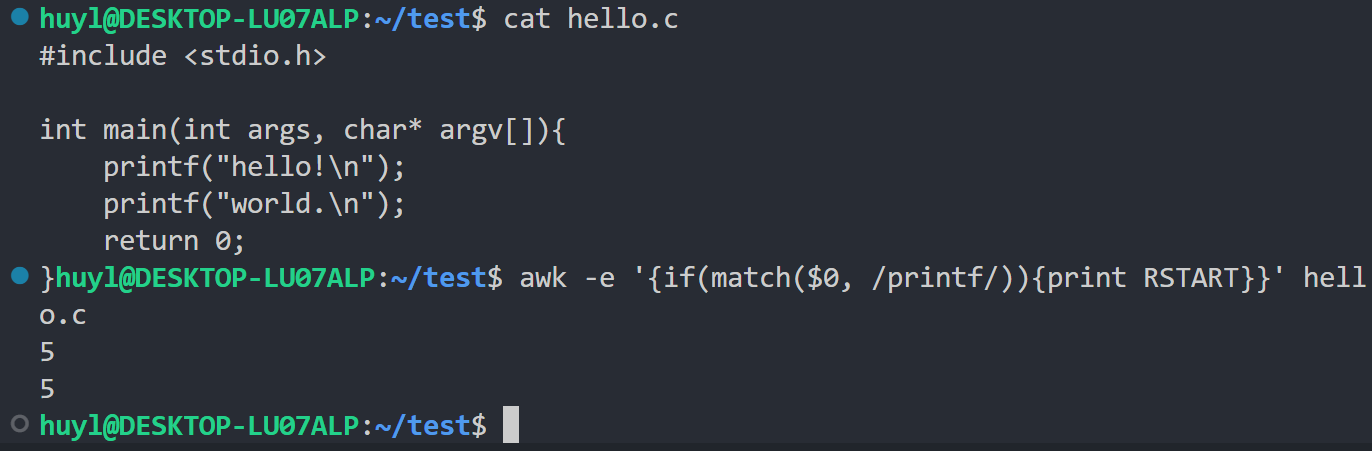
解释:这里我用match函数匹配了 printf 这个字段,并将匹配到的字符串的起始位置用 RSTART 打印出来,可以看到打印的结果都是5说明这两次匹配到的其实位置都是第五个字符串的位置(printf前面有四个空格的缩进所以是5)
- RLENGTH : 由
match()函数匹配的字符串的长度。如果未匹配,则为 -1。效果:
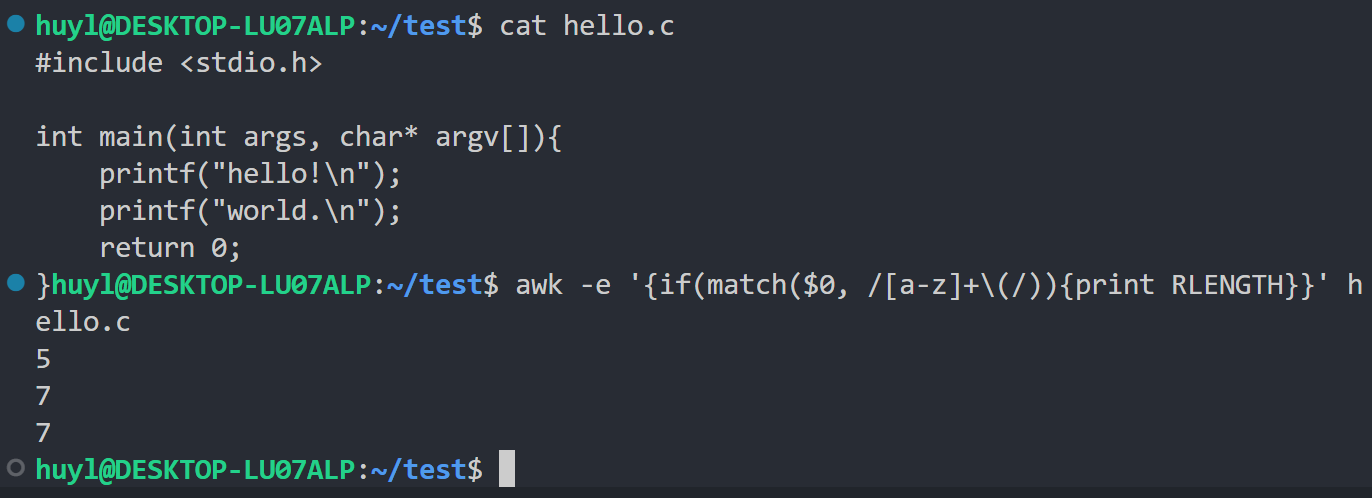
解释:这里我用match和正则表达式匹配了(和前面的字符,并将匹配到字符的长度打印出来,结果分别是5,7,7,对应的应该是 main(,printf(,printf(
🧭 5.5 环境与运行时信息变量
这些变量提供了关于 AWK 内部结构的信息。
- FUNCTAB: 一个数组,其索引是当前 AWK 程序中定义的所有函数的名称。效果:
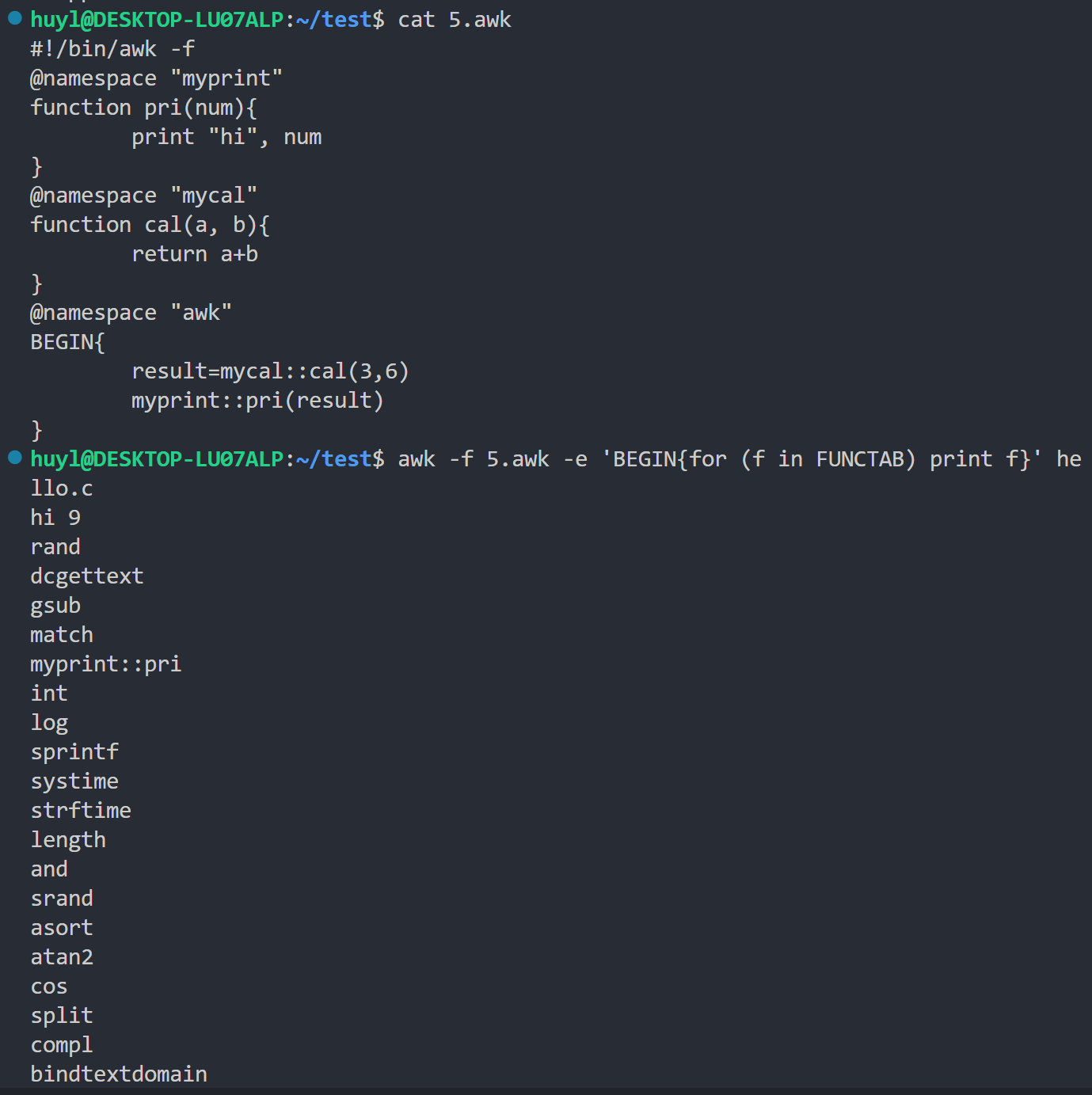
解释:这里我利用FUNCTAB将5.awk脚本中定义的所有函数打印出来,可以看出5.awk脚本中定义的函数除了我自己写的myprint::pri还有很多awk内置的函数,比如cos,log之类的。
⚠️ 注意:FUNCTAB这个内置变量不能直接打印因为它实际上是一个数组,不是单纯的变量,要用循环遍历的方式打印
- SYMTAB : 一个数组,其索引是当前 AWK 程序中的所有变量名。可以通过
SYMTAB["varname"]来间接访问或修改变量的值,这在元编程中很有用。效果:
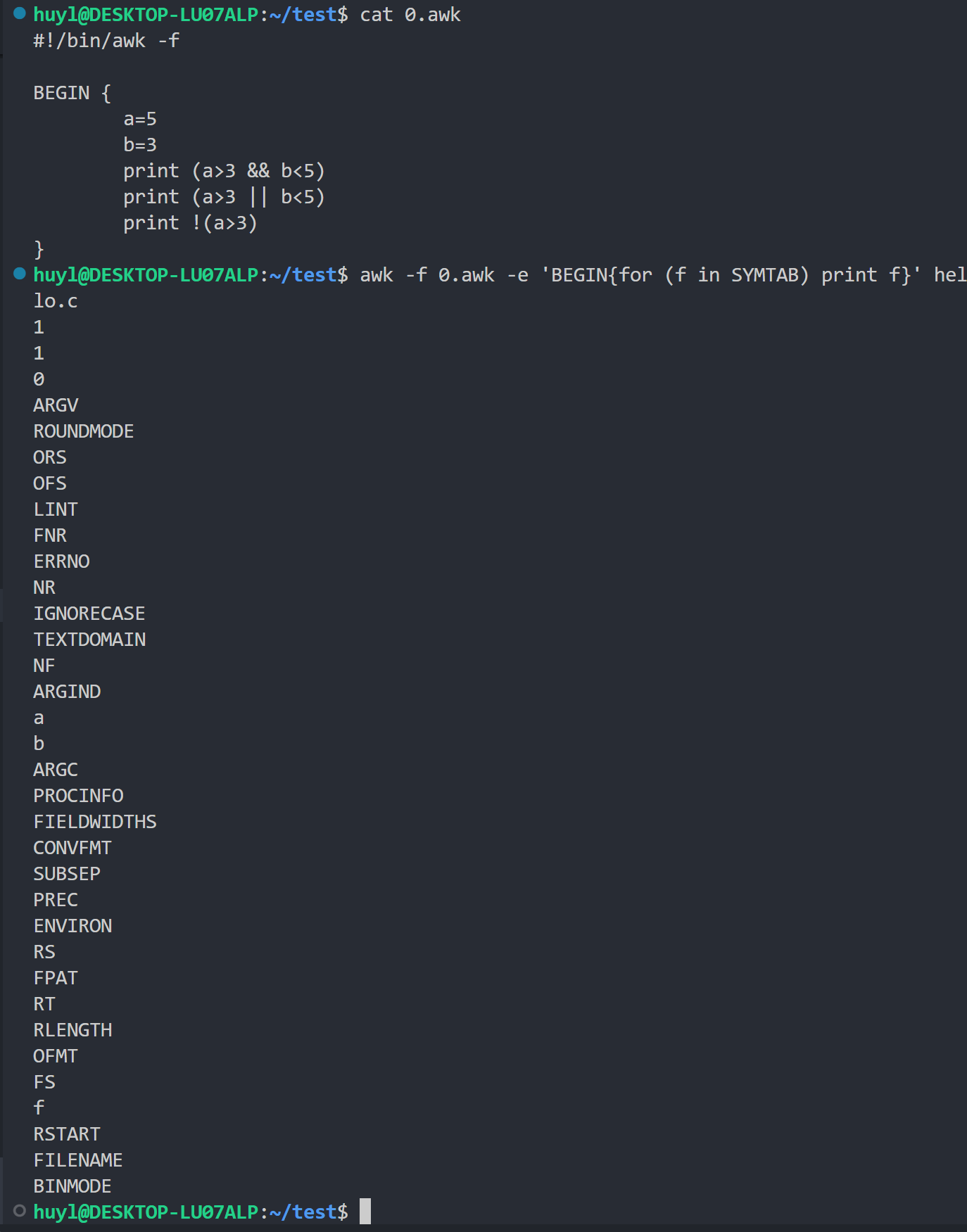
解释:这里我利用SYMTAB将0.awk脚本中定义的所有函数打印出来,可以看到除了我自己定义的a,b,f变量还有很多 awk 脚本的内置变量。其中开头的110是print函数右边的哪个逻辑表达式的结果,awk也把他们当成布尔型变量打印出来了,1表示true,0表示false
- PROCINFO : 一个数组,提供了关于正在运行的 AWK 进程和其环境的信息。包含诸如
pid(进程ID)、gid(组ID)、uid(用户ID)、version(GAWK版本)等元素。效果:
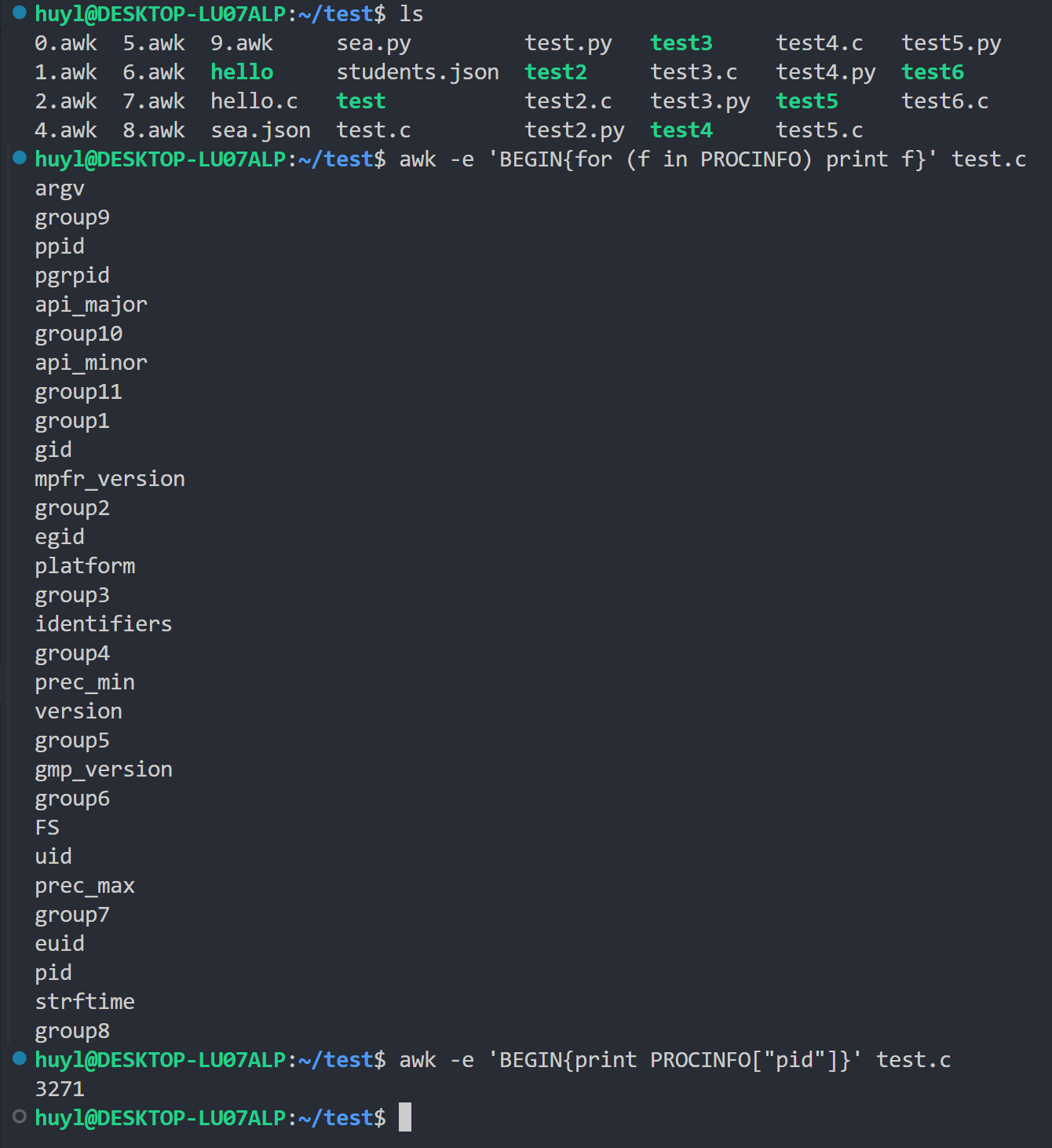
解释: 这里我先遍历打印了 PROCINFO 数组内的所有内容,然后再将其中的 pid 的值打印出来,没错, PROCINFO 是个关联型数组,也就是键值对。
⚠️ 注意:要想打印 pid 之类的值必须加上双引号,否则打印的是空字符串。
- ENVIRON : 一个数组,包含了当前 shell 的环境变量。索引是环境变量的名字(如
"HOME"),对应的值是变量的值。效果:
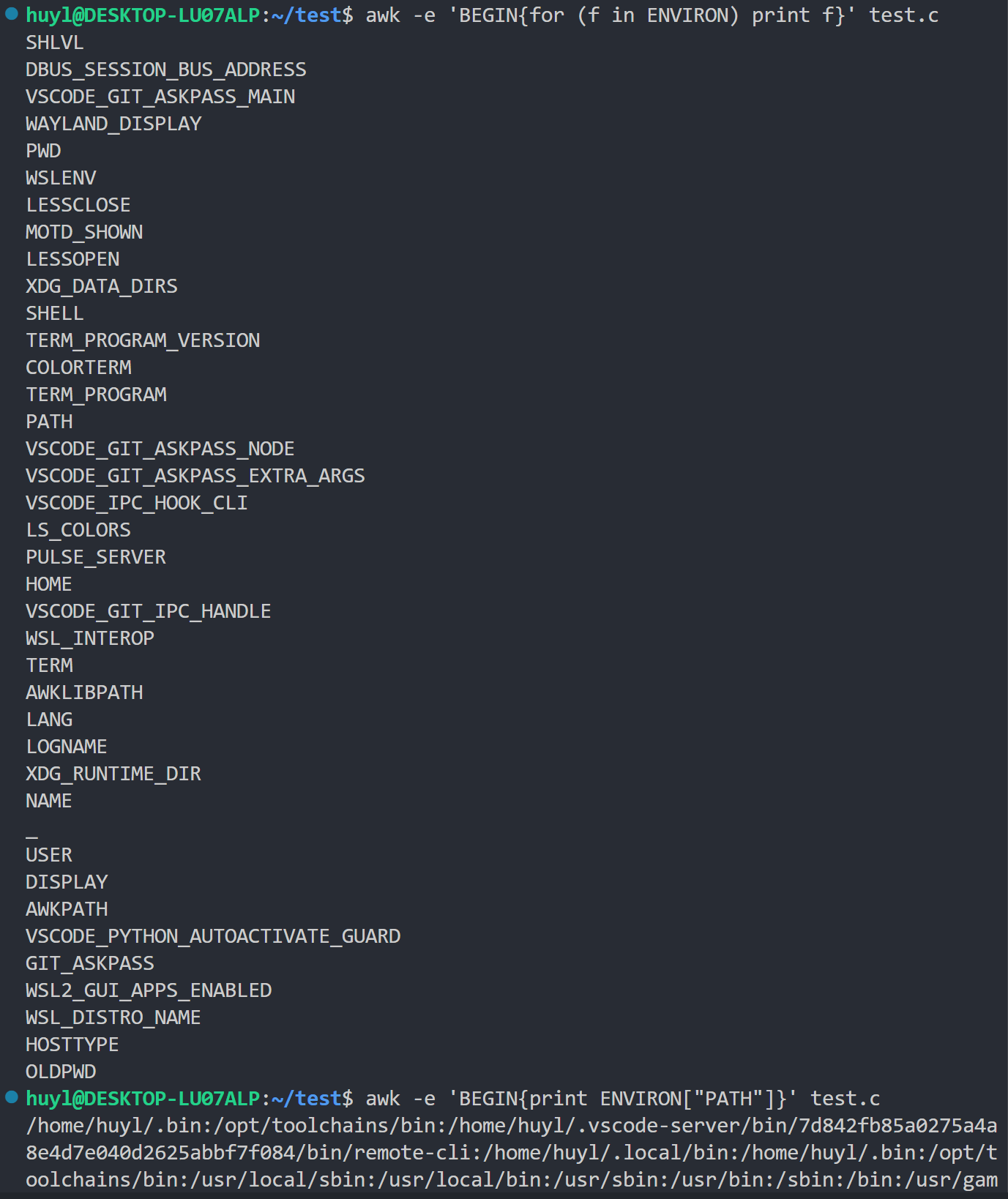
解释:这里我先是遍历了 ENVIRON 这个数组,然后再打印了这个数组中的 PATH 键值对的值。
⚠️ 注意:awk 的 ENVIRON 内置变量只能用于查看环境变量并不能修改,因为他是从父进程(shell)中继承来的一个只读的环境变量副本。
🔢 5.6 数字运算与精度控制变量
这些变量控制数字到字符串的转换和算术运算的精度。
- CONVFMT : 控制数字转换为字符串的格式。默认是
"%.6g"。当数字在需要字符串的上下文中(如拼接)被使用时,会按此格式转换。效果:
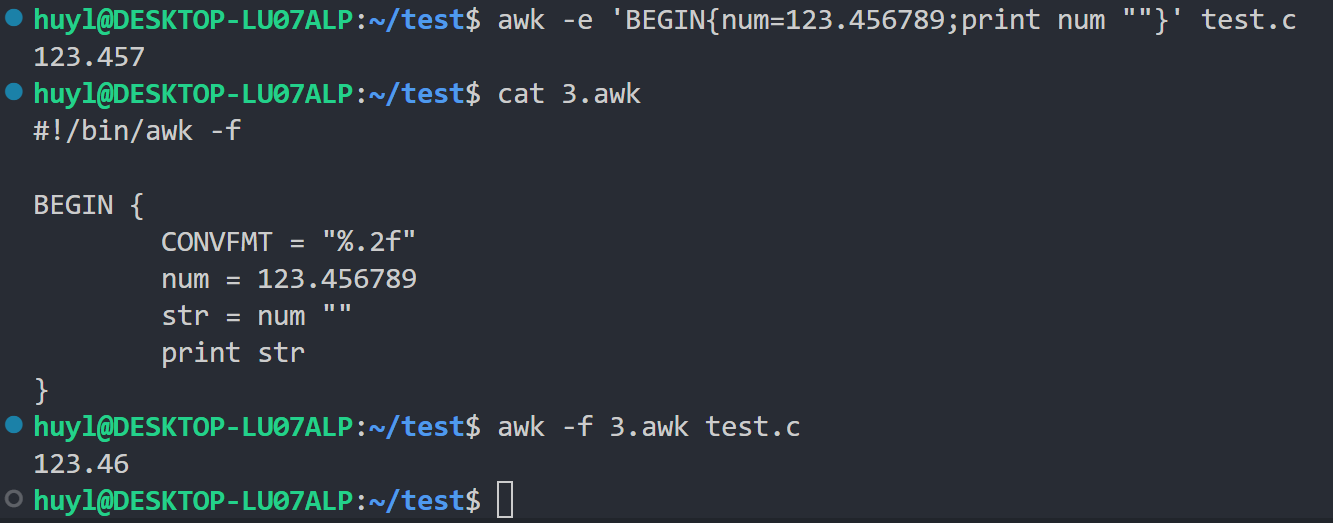
解释:这里我在没有设置CONFVMT的时候默认保留的是6位有效数字,print num "" 是强制将num转化为字符串并打印的语句。后面我设置了CONFVMT保留小数点后两位,打印出来的结果小数点后只有两位。至于第一次结果为什么是123.457而不是123.456那是因为awk四舍五入把123.4567变成123.457了
- OFMT : 控制
print语句输出数字时的格式。默认也是"%.6g"。当print一个纯数字时,会按此格式输出。效果:

解释:这里我先不做任何设置,将num以数字的形式打印得到的结果是默认的保留6个有效数字的123.457。后面我将OFMT设置成保留9位有效数字,打印出来的结果解释123.456789。
- PREC : 任意精度算术的精度位数。当使用
-M选项(GNU Awk)启用任意精度算术时,此变量设置了有效数字的最大位数。效果:

解释:建议直接跳过,永远都不要用这个内置参数。 这里我先把PREC设置成16位十进制精度,OFMT设置成20个有效数字,出来得结果是 1523.4375;然后我把PREC设置成20位十进制精度,出来结果就多了5个有效数字变成1523.447265625。但是正确结果应该是1523.44704。这里我也不懂为什么会出现这种情况,没法解释了。
- ROUNDMODE : 控制任意精度算术的舍入模式。可以是
"N"(四舍五入到最接近的值)、"U"(向上舍入)等。效果:
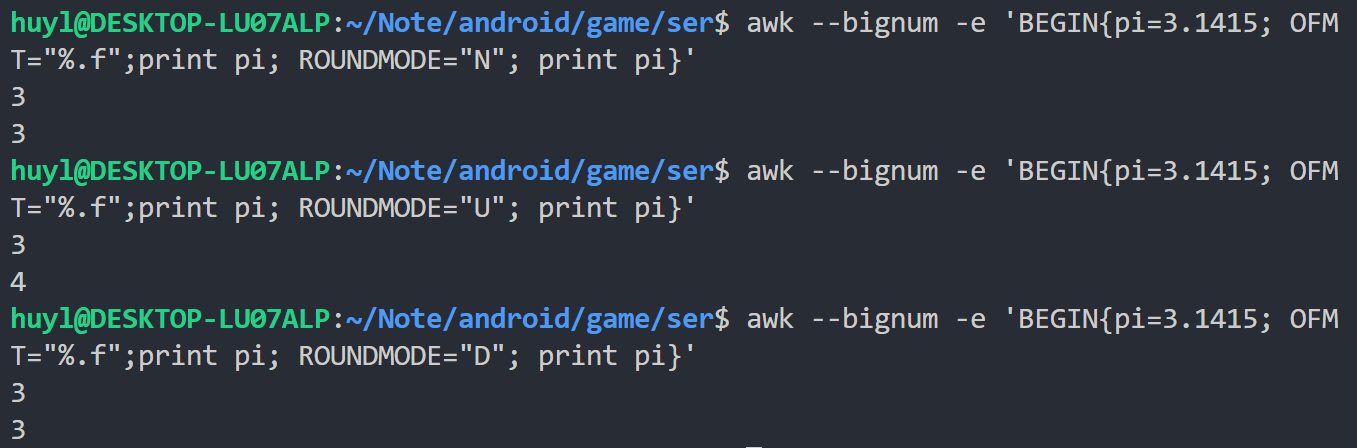
解释:建议直接跳过。 这个内置参数是用来控制浮点运算时的舍入行为的,一共有5种模式"N"、"U"、"D"、"Z"、"A"分别对应银行家舍入、向正无穷舍入、向负无穷舍入、朝0截断方向舍入、远离0舍入。这里我尝试了"N"、"U"、"D"三种舍入方式,可以看到 3.1415 只有在向正无穷舍入的时候会变成4其余两种舍入方式都是3
⚠️ 注意:要想 ROUNDMODE 内置参数生效,命令行参数种必须有 --bignum 来开启 awk 的高精度计算功能,否则无论 ROUNDMODE 如何设置结果都会受到默认的 "N" 银行家舍入行为影响。
🥫 5.7 其他特殊用途变量
- IGNORECASE: 控制所有正则表达式匹配和字符串操作是否忽略大小写。默认是 0(关闭)。如果设置为非零值,则进行不区分大小写的匹配。效果:

解释:这里我用IGNORECASE打开了忽略大小写的设置,并在 awk 脚本代码块种匹配了 newnode 。从结果可以看到 newNode 被匹配到了。
- LINT : 在 AWK 程序中动态控制
--lint检查。设置为"fatal"会使 lint 警告变成致命错误。提供对代码质量的运行时控制。效果:
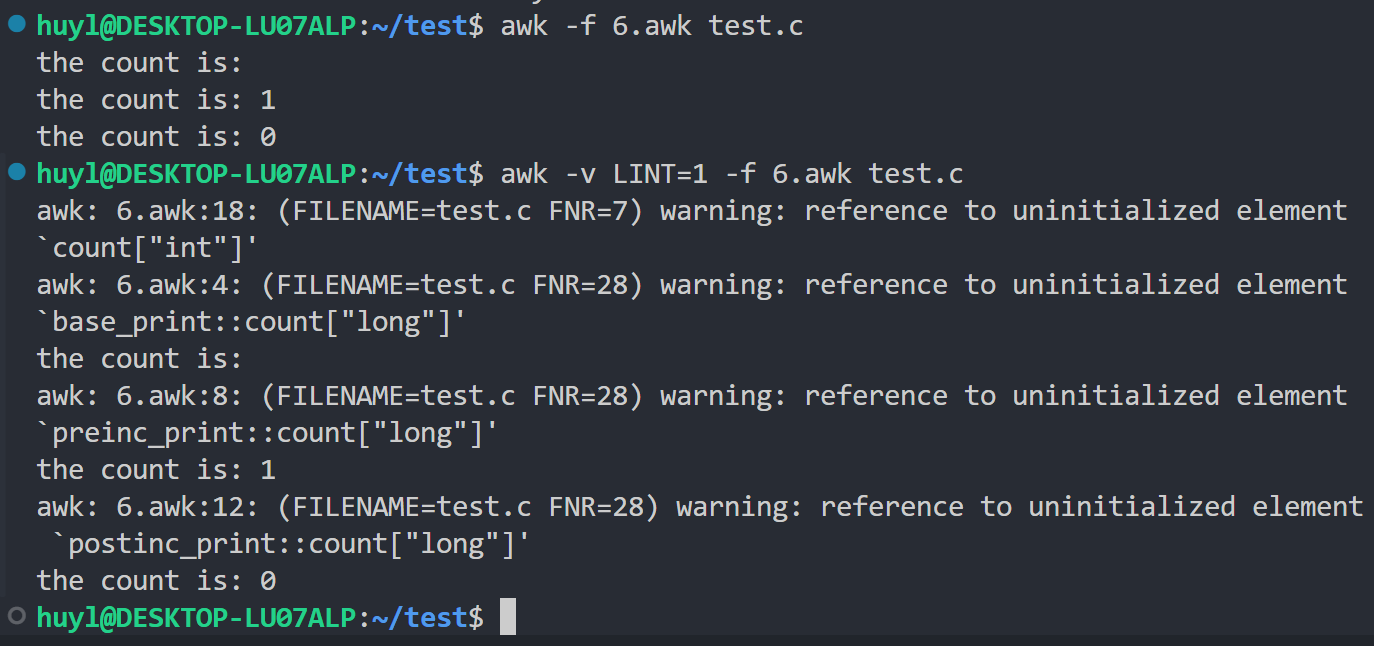
解释:这里我分别将开了LINT和没开LINT的结果进行对比,可以看到开了 LINT 后会对旧awk版本不兼容的语法做出 warning 警告
⭐️ 6. awk 内置函数
➕ 6.1 数学计算函数
这些函数用于执行各种数学运算。
sin(x):返回 x 的正弦值(x 为弧度),效果:

解释:我在awk脚本中调用sin()函数并打印了1的正弦值
cos(x):返回 x 的余弦值(x 为弧度),效果:

解释:我在awk脚本中调用了cos() 函数并打印了1的余弦值
atan2(y, x):返回 y/x 的反正切值(弧度),在 -π 到 π 之间,效果:

解释:我在awk 脚本中调用了atan2()函数并打印了(1,1)的正切值
exp(x):返回 e 的 x 次幂,效果:

解释:我在awk脚本中调用了exp()函数并打印了e 的一次方的值
log(x):返回 x 的自然对数(以 e 为底),效果:

解释:我在awk脚本中调用了log()函数并打印了以e为底1的对数的值
sqrt(x):返回 x 的平方根,效果:

解释:我在awk脚本中调用了sqrt()函数并打印了9的平方根的值
int(x):返回 x 的整数部分(向零取整),效果:

解释:我在awk脚本中调用了sqrt()函数并打印了10.33取整的值
rand():返回一个在 [0, 1) 范围内的随机浮点数,效果:

解释:我在awk脚本中调用了rand()函数并打印了返回的随机值。
srand([x]):设置随机数生成器的种子。如果省略 x,则使用当前时间,效果:

解释:这里我在awk脚本中先设置了随机数生成器种子,在生成了随机数,最后打印了返回的随机数值
🖨️ 6.2 字符串函数
这些函数用于操作和处理字符串。
asort(source, dest)对数组source的值进行排序,将排序后的值重新索引(从1开始连续编号)存入dest数组。如果省略dest,则直接修改原数组。返回数组的元素个数。效果:
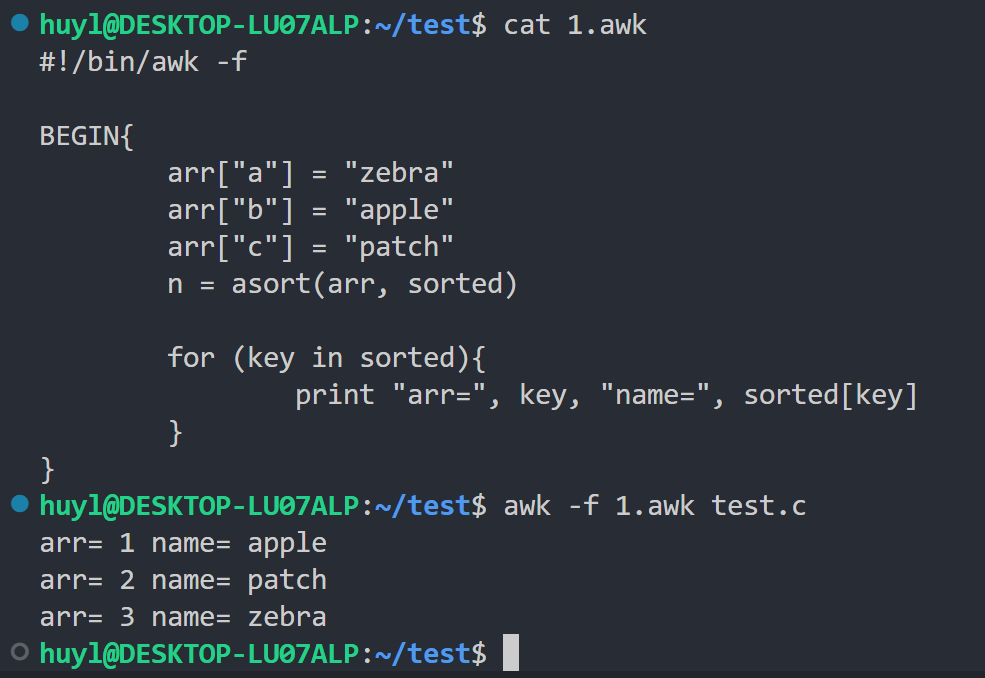
解释:这里我用asort()函数对arr数组进行排序,将排序的结果存入sorted数组中,并将sourted数组中的内容打印出来,可以看到排序后的数组索引变成了1、2、3,并且数组中的内容也发生了变化
asorti(source, dest):对数组source的**下标(索引)**进行排序,将排序后的下标存入dest数组。如果省略dest,则直接修改原数组(会丢失原来的值!)。返回数组的元素个数。效果:
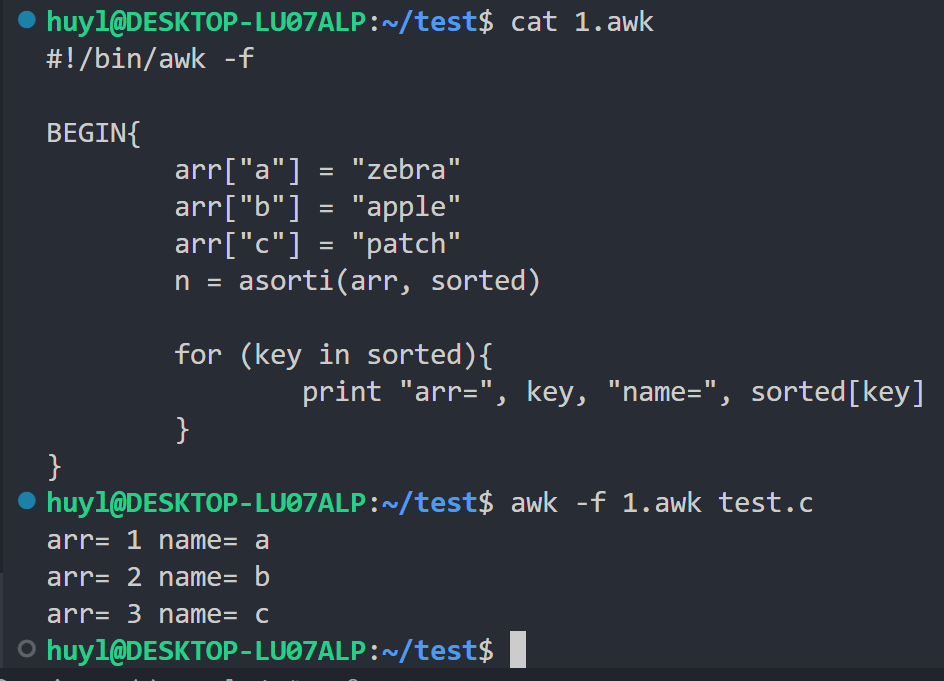
解释:这里我用asorti()函数对arr数组的下标进行排序,将排序的结果存入sorted数组中,并将sourted数组中的内容打印出来,可以看到排序后的数组索引变成了1、2、3,并且数组中的内容变成了原数组的下标。
length(string):返回字符串的长度。如果省略参数,返回$0的长度,效果:

解释:这里我用length函数获取了str字符串的长度并将其打印出来
substr(string, start, length):返回从 start 位置开始的子串,可指定长度,效果:

解释:这里我用substr函数截取了str字符串的第3个到第4个子串,并将其打印了出来,siondf的第3-4个子串是on 所以打印的是on
index(string, substring):返回子串在字符串中第一次出现的位置,未找到返回 0,效果:

解释:这里我用index在str字符串中查找"on"子串,并打印出第一次出现的位置,3
match(string, regexp):在字符串中搜索正则表达式的匹配,返回匹配位置,未找到返回 0,效果:

解释:这里我用match匹配str字符串中满足
.[a-z]+$正则表达式的字段,并打印匹配到的位置,6
split(string, array, fieldsep):将字符串分割到数组中,返回字段数,效果:
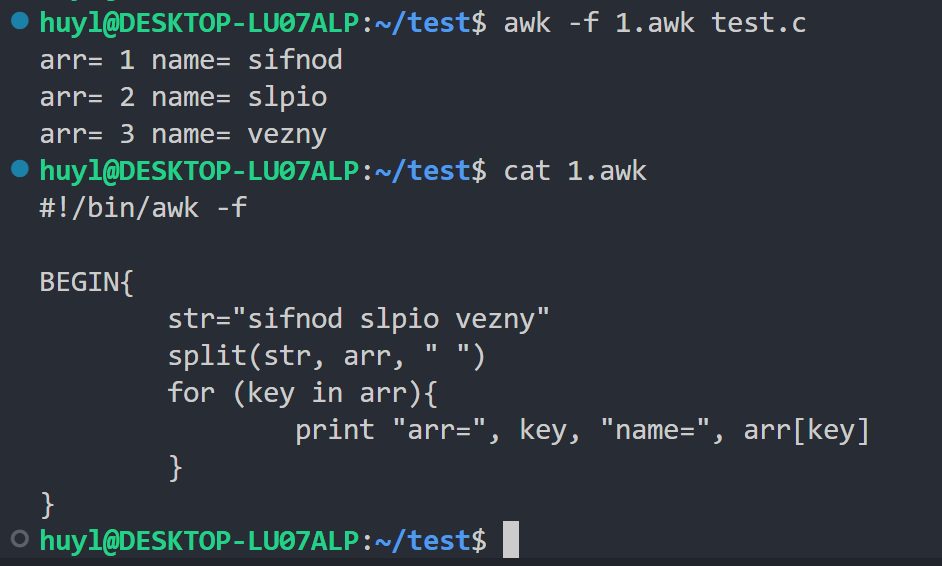
解释:这里我用split函数以" "为分隔符将字符串 str 分割成子串并塞入数组 arr 中,最后将 arr 中的内容遍历打印出来。
sub(regexp, replacement, target):在 target(默认为$0)中替换第一个匹配 regexp 的子串,效果:

解释:这里我用正则表达式/@a-z./匹配@qq.字段并利用sub函数将匹配到的字段替换成@163.字段,最后将替换后的字符串变量打印出来。
gsub(regexp, replacement, target):在 target(默认为$0)中替换所有匹配 regexp 的子串,效果:

解释:这里我用gsub函数将str字符串的所有英文部分全部替换成和谐符号,最后将替换后的字符串变量打印出来。str字符串中一共有两处匹配,所以替换了两处内容。gsub和sub最大的不同就是可以多处替换。
gensub(regexp, replacement, how, target):更强大的替换函数,返回新字符串而不修改原字符串,效果:
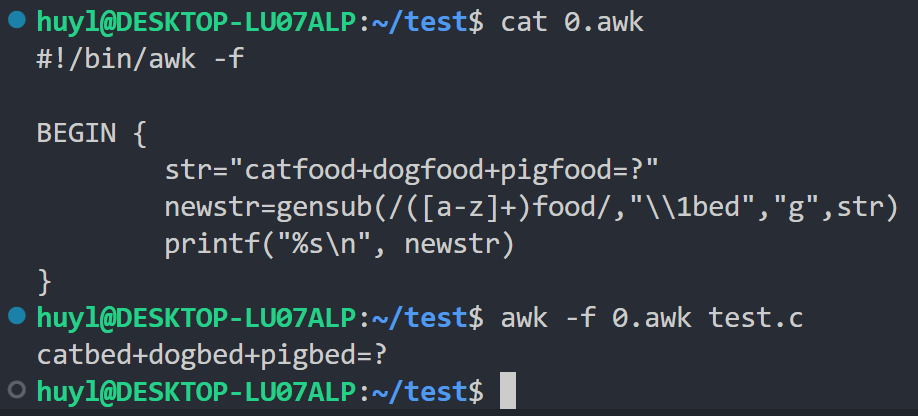
解释:这里我用gensub在脚本中将所有的宠物粮换成了宠物床。gensub的第一个参数即是宠物粮的正则表达式,第二个参数即时要替换的宠物床的正则表达式,其中的\1表示前一个匹配正则表达式中第一个用括号括起来的部分,即cat或dog或pig,把他们原封不动的保留下来,而后面的food替换成bed。第三个参数"g"表示全局替换,这里也可以改成数字,比如1就只会替换catfood,2就只会替换dogfood,3就只会替换pigfood。这里的第四个参数就是被替换的字符串str
tolower(string):将字符串转换为小写,效果:

解释:这里我用tolower将字符串str转换成了小写的newstr并打印了出来
toupper(string):将字符串转换为大写,效果:

解释:这里我用tolower将字符串str转换成了小写的newstr并打印了出来
sprintf(format, expression1, ...):返回格式化的字符串(类似于 C 语言的 sprintf),效果:

解释:这里我用sprintf函数来格式化字符串并将结果给到str,最后将str打印出来。可以看到打印出来的str中的数字符合 %.2f的保留两位小数的格式。
⏲️ 6.3 时间函数
这些函数用于处理日期和时间。
systime():返回当前时间的 Unix 时间戳(从 1970-01-01 开始的秒数),效果:

解释:这里我通过systime函数获取当前系统的时间戳并打印出来
mktime(datespec):将格式为 "YYYY MM DD HH MM SS DST" 的日期字符串转换为时间戳,效果:

解释:这里我用mktime函数构造了一个时间戳并将其打印了出来
strftime([format [, timestamp]]):将时间戳格式化为日期时间字符串,效果:

解释:这里我用strftime函数获取当前系统的时间戳并按照格式将时间戳转化成可读的时间和日期,最后将其打印出来
🎛️ 6.4 位操作函数
这些函数用于对整数进行位级操作。
and(v1, v2):返回 v1 和 v2 的按位与结果,效果:

解释:这里我将整数 5(110)和整数3(011)进行位与操作,得到结果1(001)并将其打印出来
or(v1, v2):返回 v1 和 v2 的按位或结果,效果:

解释:这里我将整数 5(110)和整数3(011)进行位或操作,得到结果7(111)并将其打印出来
xor(v1, v2):返回 v1 和 v2 的按位异或结果,效果:

解释:这里我将整数 5(110)和整数3(011)进行位异或操作,得到结果6(110)并将其打印出来
lshift(value, count):将 value 左移 count 位,效果:

解释:这里我利用lshift将1进行左移10位得到结果1024(刚好是2的10次方)并将其打印出来
rshift(value, count):将 value 右移 count 位,效果:

解释:这里我利用lshift将16进行右移2位得到结果4并将其打印出来
compl(value):返回 value 的按位取反(补码),效果:

解释:这里我打印了利用compl函数打印了当前系统中0的补码9007199254740991。awk内部整数的有效精度是53位所以就是0x1FFFFFFFFFFFFF,转换成十进制也就i是9007199254740991。
🔋 6.5 类型判断函数
这些函数用于判断值的类型。
isarray(x):如果 x 是数组返回 1,否则返回 0,效果:

解释:这里我先构造了一个数组arr然后将arr数组传给isarray函数判断,并将判断的结果打印出来,是1
typeof(x):返回表示 x 类型的字符串,返回值可以有"array", "number", "string", "strnum", "regexp", "unassigned", "undefined",效果:

解释:这里我先构造了一个数组arr然后将arr数组传给typeof函数判断,并将判断的结果打印出来,结果显示是array类型的变量,也就是数组类型的变量
⚠️ 7. 注意事项
☣️ 7.1 使用 awk -l 参数加载C语言动态库的扩展功能
awk 要使用 -l 参数加载C语言动态库的扩展功能,需要在系统上进行以下配置:
-
查看系统中 awk 版本
bashawk --version -
根据 awk 版本拉取 awk 源码包(我这里是5.1.0版本)
bashwget https://ftp.gnu.org/gnu/gawk/gawk-5.1.0.tar.xz -
解压源码包并进入源码目录
bashtar -xvf gawk-5.1.0.tar.gz cd gawk-5.1.0.tar.gz -
配置并编译
bash./configure make -
进入 extension 插件目录,这里有很多 .c 文件都是 GNU 官方提供的动态共享库示例文件
-
打开其中一个 .c 文件拉到最后看他向 awk 注册了哪些接口函数
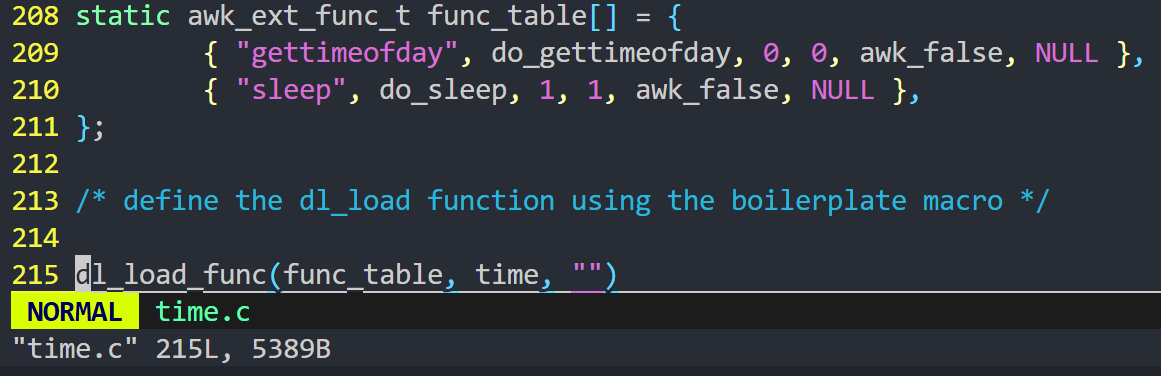
-
记下这些接口函数的名字(比如 gettimeofday),然后把上层目录的 gettext.h 文件复制到 extension 目录中
bashcp ./../gettext.h . -
将这个示例文件编译成动态库
bashgcc -fPIC -shared -o time.so time.c -
使用 -l 参数在 awk 脚本中使用动态库函数(gettimeofday)
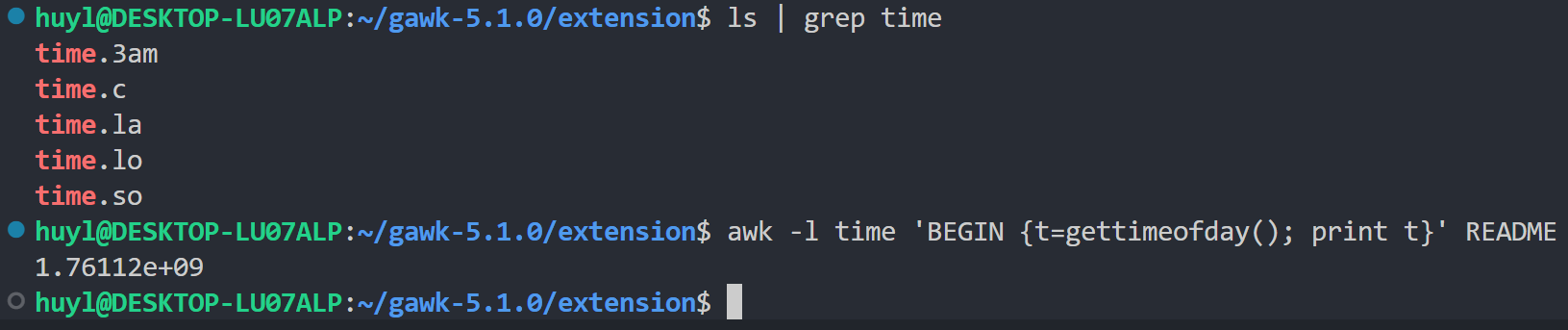
💡 提示:我这里演示为了简洁易懂直接把示例文件编译成了可被 awk 调用的动态库。理论上所有C语言程序都能编译成可被 awk 调用的动态库,但是需要满足以下条件:
- 包含 gawkapi.h 头文件
- 按照 awk_ext_func_t 结构体的格式定义各种接口函数
- 将这些函数组成的函数表通过回调函数 dl_load_func 注册到 awk 中
- 将 .c 文件拷贝到 gawk-5.1.0/extensions 目录下编译(如果缺什么头文件可以一起考进来)
具体细节可以看官方提供的示例文件的源码,源码很简单一眼就能看懂。