大家好,我是 方圆 。本篇文章主要介绍 MCP Server Easy Code Reader,它可以帮助你在使用 Cursor/VSCode/IDEA 编写代码时,根据调用链路将多个项目或 Jar 包中相关的代码读取到上下文中,供 Code Agent 帮我们分析逻辑和编写代码,而无需再手动将源码复制到对话框中发送给 AI,提高 Code Agent 准确度和编码效率。MCP 已发布 Github 和 MCP.so,欢迎大家前往下载使用:
在介绍如何接入 Easy Code Reader 之前,我们先来看看它到底能做什么:
Easy Code Reader 最佳实践
Easy Code Reader 特别适合与 Claude、ChatGPT 等大模型配合使用,接下来以 Copilot Code Agent 结合 Claude4.5 模型为例,介绍一些最佳实践:
1. 跨项目调用,根据调用链路分析源码
在比较复杂的项目中一般会拆分多个微服务,某些功能的实现可能会跨多个项目调用,如果靠人梳理相关逻辑会比较耗时,所以可以将涉及的代码 clone 到本地后使用 Easy Code Reader MCP 并结合 Code Agent 进行分析。接下来我们以 Nacos 项目为例,假设我们想了解 Nacos 的服务注册功能是如何实现的,可以按照以下步骤操作:
首先,比如我们创建了一个 Nacos Client 客户端,在这段逻辑中执行服务注册:
java
public class Main {
private static final Logger logger = LoggerFactory.getLogger(Main.class);
public static void main(String[] args) throws NacosException, InterruptedException {
logger.info("开始初始化 Nacos 客户端...");
Properties properties = new Properties();
properties.put(PropertyKeyConst.SERVER_ADDR, "127.0.0.1:8848");
properties.put(PropertyKeyConst.NAMESPACE, "7430d8fe-99ce-4b20-866e-ed021a0652c9");
NamingService namingService = NacosFactory.createNamingService(properties);
System.out.println("=== 注册服务实例 ===");
try {
// 注册一个服务实例
namingService.registerInstance("test-service0", "127.0.0.1", 8080);
// 添加事件监听器
namingService.subscribe("test-service", event -> {
System.out.println("服务实例变化: " + event);
});
} catch (Exception e) {
System.out.println("服务注册失败(预期,因为服务器可能未启动): " + e.getMessage());
}
TimeUnit.HOURS.sleep(3);
}
}因为我们创建 Nacos Client 执行服务注册时是由 Nacos 提供的 SDK 直接调用 NamingService#registerInstance 方法实现的,我们并不清楚底层是如何实现的,如果我们想要了解实现细节,那么可以将 Nacos 的源码 Clone 下来,并使用 Easy Code Reader 读取相关源码,下面是一个示例 Prompt:
text
你是一位 Java 专家,请你帮我分析 #file:Main.java 中 namingService.registerInstance 方法的逻辑,这段逻辑的实现在本地项目的 nacos 中,所以你需要在 nacos 读取一系列相关的源码才能了解它的核心逻辑,读取 nacos 项目的代码你可以借助 easy-code-reader MCP,其中包含你可以获取项目信息、项目中所有的文件信息和某个文件的工具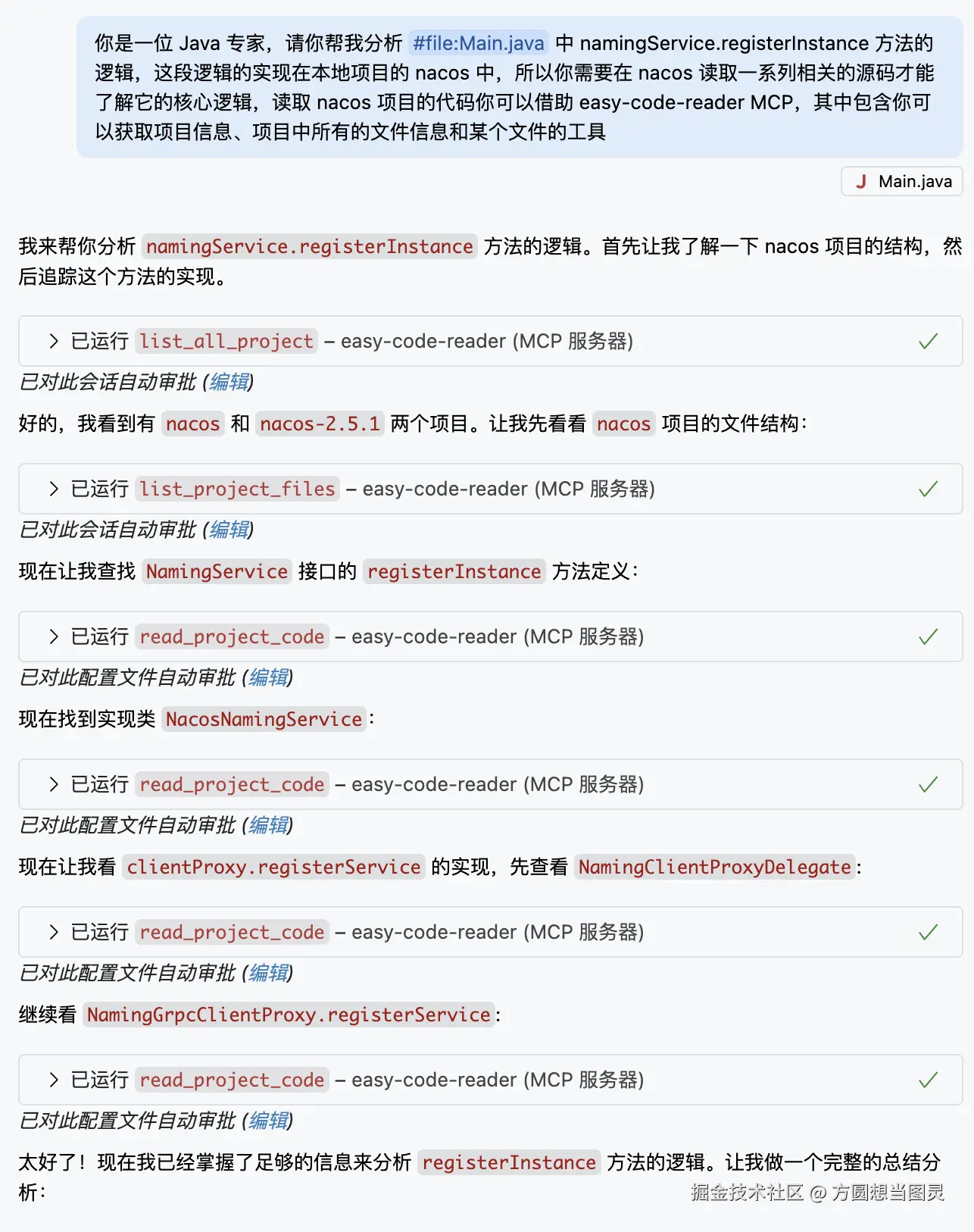
如图所示,它会不断地根据源码调用链路,读取相关源码并进行分析,最终我们就能了解服务注册的实现细节,会使用到 MCP Easy Code Reader 提供的多个工具 list_all_project、list_project_files 和 read_project_code, 具体调用细节图示如下:

最终得到分析结果,节省很多时间:

2. 阅读 jar 包源码,根据源码完成代码编写
在使用第三方或其他外部依赖时,Copilot 或其他 Code Agent 并不能直接读取 jar 包中的源码,往往需要我们将源码内容手动复制到提示词中才能完成,费时费力。在 Easy Code Reader 中提供了 read_jar_source 工具来读取 jar 包中的源码,帮我们完成开发实现。我们还是以如下代码为例,现在我想实现多个服务实例的注册,但是我又不了解 NamingService 的实现,便可以借助 read_jar_source 来完成:
java
public class Main {
private static final Logger logger = LoggerFactory.getLogger(Main.class);
public static void main(String[] args) throws NacosException, InterruptedException {
logger.info("开始初始化 Nacos 客户端...");
Properties properties = new Properties();
properties.put(PropertyKeyConst.SERVER_ADDR, "127.0.0.1:8848");
properties.put(PropertyKeyConst.NAMESPACE, "7430d8fe-99ce-4b20-866e-ed021a0652c9");
NamingService namingService = NacosFactory.createNamingService(properties);
System.out.println("=== 注册服务实例 ===");
try {
// 注册一个服务实例
namingService.registerInstance("test-service0", "127.0.0.1", 8080);
// 添加事件监听器
namingService.subscribe("test-service", event -> {
System.out.println("服务实例变化: " + event);
});
// 注册多个服务实例
} catch (Exception e) {
System.out.println("服务注册失败(预期,因为服务器可能未启动): " + e.getMessage());
}
TimeUnit.HOURS.sleep(3);
}
}
text
你是一位 Java 技术专家,精通 Nacos 框架,请你帮我在 #file:Main.java 中完成注册多个服务实例的逻辑,在编写代码前,你需要先使用 easy-code-reader 的 read_jar_source 工具读取 com.alibaba.nacos.api.naming.NamingService 的源码信息来了解注册多个服务实例的方法处理过程如下所示:
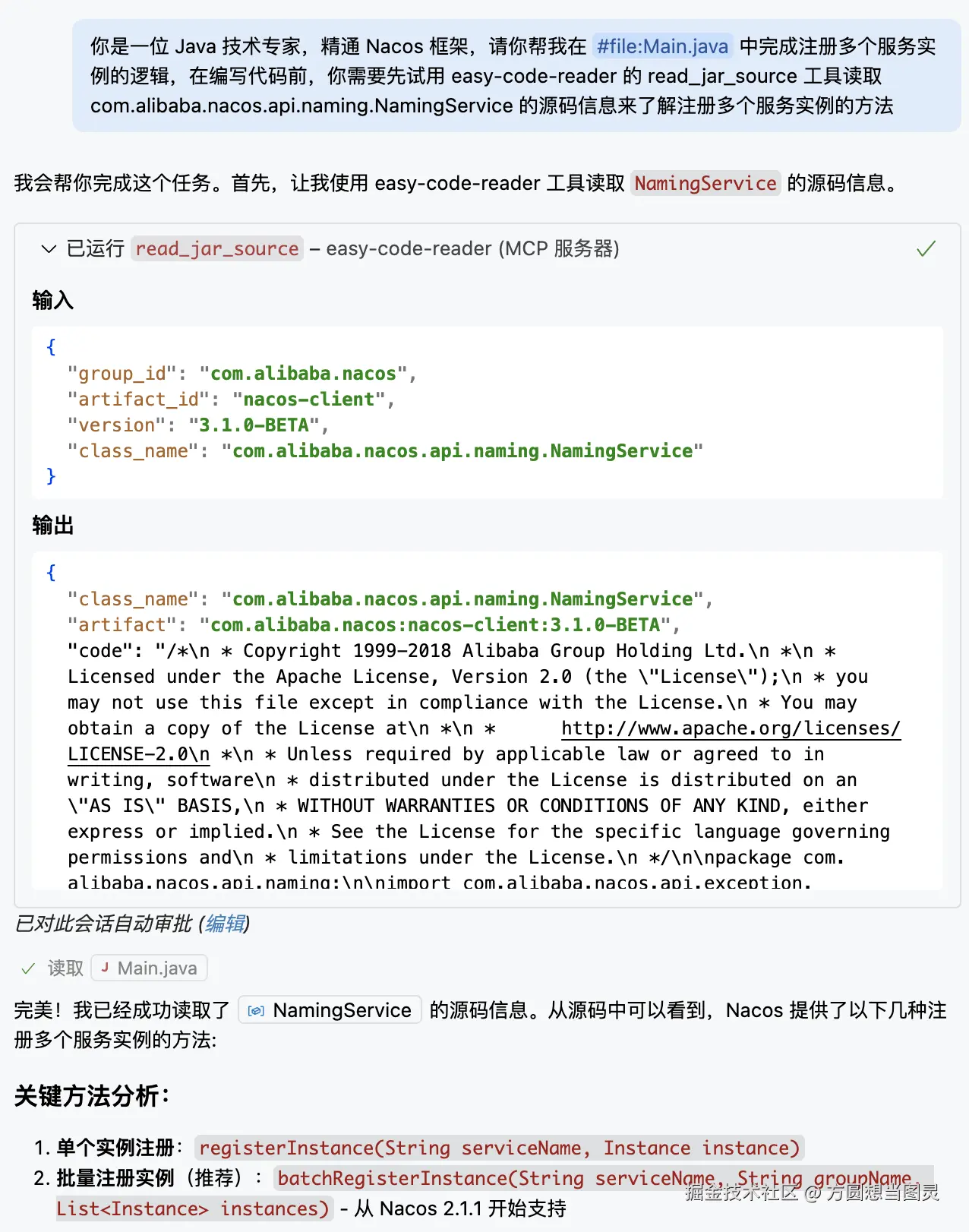
这样我们便能够快速地了解 NamingService 的实现细节,从而完成代码编写工作,节省了大量时间。
3. 跨项目阅读源码,根据源码完成本项目实现
在大型项目中,某些功能的实现可能会跨多个模块或微服务,如果部分逻辑已经实现并且后续其他应用的逻辑需要依赖这部分逻辑时,可以借助 Easy Code Reader 读取相关模块的源码,帮助我们更好地理解和实现当前项目的功能,示例 Prompt 如下:
text
你是一位 Java 技术专家,现在我要实现 XXX 的业务逻辑,这部分逻辑的实现需要调用本地项目 A 中 XXX 的接口及其实现,请你借助 MCP easy-code-reader 来帮我读取 A 项目中的源码,并帮我实现 XXX 的业务逻辑当然除了这三种应用场景以外,还可以使用 Easy Code Reader 完成以下事项:
- 异常问题快速溯源 :如果有异常信息是外部 jar 包依赖中抛出来的,可以使用
read_jar_source工具根据异常堆栈日志快速定位异常点 - 依赖升级影响评估(旧/新版本差异核对) :同样是使用
read_jar_source工具来完成新旧版本的实现差异,评估升级影响 - 业务代码逻辑评审 :如果业务逻辑开发实现在多个项目中,可以借助读取本地项目代码的工具
list_all_project、list_project_files和read_project_code,来分析新增的逻辑是否满足业务要求 - 新人快速上手多个微服务:借助读取本地项目代码的工具,可以根据接口调用链路快速理清微服务项目代码之间的关系,提高上手速度
既然它有这么多的应用场景,那么我们该如何接入 Easy Code Reader 呢?下面我们来介绍一下接入步骤:
快速接入(方法一):使用 uvx(推荐 - 开箱即用)
它的环境要求如下:
- uv - Python 包和项目管理工具
- Python 3.10 或更高版本
- Java Development Kit (JDK) - 用于运行反编译器,要求至少 Java 8
如果您还没有安装 uv,可以通过以下方式快速安装:
bash
# macOS/Linux
curl -LsSf https://astral.sh/uv/install.sh | sh
# Windows
powershell -c "irm https://astral.sh/uv/install.ps1 | iex"
# 或使用 pip
pip install uv或者参考 uv 官网 进行安装,并配置 uv 的安装路径添加到系统 PATH 中,以便可以直接使用 uvx 命令。uv 是一个极快的 Python 包和项目管理工具。使用 uvx 可以无需预先安装,直接运行,参考以下 MCP 客户端配置:
--maven-repo: 指定 Maven 仓库路径,将/custom/path/to/maven/repository内容替换为本地 Maven 仓库路径即可,不配置默认使用 MAVEN_HOME 目录或~/.m2/repository--project-dir: 指定本地项目目录路径,将/path/to/projects替换为实际保存所有项目的路径
json
{
"mcpServers": {
"easy-code-reader": {
"command": "uvx",
"args": [
"easy-code-reader",
"--maven-repo",
"/custom/path/to/maven/repository",
"--project-dir",
"/path/to/projects"
],
"env": {}
}
}
}将以上内容配置好后,AI 助手即可通过 MCP 协议调用 Easy Code Reader 提供的工具,完成多项目、多依赖的 Java 源代码读取工作。
快速接入(方法二):使用 uv 安装到本地(不推荐)
如果使用 快速接入(方法一) 安装运行失败,那么可以采用直接安装到本地的方法,运行如下命令:
bash
uv tool install easy-code-reader安装成功后,执行以下命令获取安装目录:
bash
which easy-code-reader比如,输出结果是:/Users/fangyuan/.local/bin/easy-code-reader,那么需要按照如下方式配置 MCP 客户端:
json
{
"mcpServers": {
"easy-code-reader": {
"command": "/Users/fangyuan/.local/bin/easy-code-reader",
"args": [
"--maven-repo",
"/custom/path/to/maven/repository",
"--project-dir",
"/path/to/projects"
],
"env": {}
}
}
}一般这样操作都能完成安装,后续如果有版本更新,可以通过以下命令进行升级:
bash
uv tool install --upgrade easy-code-reader常见问题
Q1: spawn uvx ENOENT spawn uvx ENOENT
uv 命令未找到,确保已正确安装 uv 并将其路径添加到系统 PATH 中,参考 快速接入(方法一),并尝试重启 IDE 后再启动 MCP Server。
以上内容就是 MCP Easy Code Reader 的介绍和接入方法,接下来的内容主要介绍一下它的实现原理,感兴趣的朋友可以继续往下看。
Easy Code Reader 实现原理
其实编写一个 MCP Server 并不复杂,大家可以参考这篇 Github 上的文章 Model Context Protocol(MCP) 编程极速入门。Easy Code Reader 通过 Python 语言实现,它提供了 4 个主要工具来协同完成源码读取工作:
list_all_project: 列出所有本地项目 ,这个工具能将配置的项目目录--project-dir下所有的文件夹都读取出来,每个文件夹代表一个项目,这样 Code Agent 便能根据项目名称来选择需要读取的项目list_project_files: 列出指定项目中的所有文件名,这个工具能将指定项目下的所有源码文件名都读取出来,Code Agent 便能根据调用链路选择需要读取的文件read_project_code: 读取指定项目中的某个文件源码,通过以上两个工具,Code Agent 能够定位到需要读取的文件,然后使用这个工具将源码内容读取出来,供 Code Agent 进行分析read_jar_source: 读取指定 jar 包中的某个类源码,如果调用链路中有外部 jar 包依赖的话,Code Agent 便可以使用这个工具将 jar 包中的源码读取出来,供分析和编写代码
这四个工具协同工作,便能实现跨项目、多依赖的源码读取工作,帮助 Code Agent 更好地理解代码逻辑,从而提高代码编写效率和准确度,以下是 MCP Tool 实现的技术细节:
list_all_project
列举项目目录下所有的项目文件夹名称。
用途:
- 查看所有可用的项目
- 当输入不完整的项目名时,帮助推理出最接近的项目名
- 验证项目是否存在
- 支持项目名称模糊匹配,快速查找特定项目
参数:
project_dir(可选): 项目目录路径,如未提供则使用启动时配置的路径project_name_pattern(可选): 项目名称模糊匹配模式(不区分大小写),用于过滤项目列表- 支持左右模糊匹配,例如
nacos将匹配包含nacos、Nacos、NACOS的项目名 - ⚠️ 使用建议:如果匹配模式过于严格可能导致遗漏目标项目
- 💡 最佳实践:若未找到预期结果,建议不传此参数重新查询完整列表
- 支持左右模糊匹配,例如
智能提示机制:
- 当使用
project_name_pattern但未匹配到项目时,返回结果会包含提示信息 - 建议 AI 助手在未找到预期项目时,不传
project_name_pattern参数重新查询 - 有效减少因过度过滤导致的查询失败
示例 1 - 列出所有项目:
json
{}示例 2 - 使用项目名称模糊匹配:
json
{
"project_name_pattern": "spring"
}返回格式:
json
{
"project_dir": "/path/to/projects",
"project_name_pattern": "spring",
"total_projects": 2,
"projects": [
"spring-boot",
"spring-cloud-demo"
],
"hint": "已使用项目名称模式 'spring' 进行过滤。如果未找到预期的项目,可能是模式匹配过于严格。建议:不传入 project_name_pattern 参数重新调用 list_all_project 工具查看完整项目列表。",
"total_all_projects": 5
}提示信息说明:
- 当使用
project_name_pattern但未匹配到任何项目时,hint字段会提示模式可能过于严格,并显示总项目数total_all_projects - 当使用
project_name_pattern且有匹配结果时,hint字段会提醒如果结果不符合预期可以不传参数重新查询,同时显示总项目数 - 这个智能提示机制帮助 AI 助手更好地调整查询策略,避免因过度过滤错过目标项目
list_project_files
列出 Java 项目中的源代码文件和配置文件路径。
用途:
- 了解项目结构和文件组织
- 查找特定的类或配置文件
- 分析类之间的关系和依赖
- 当项目文件过多时,聚焦特定模块
- 支持文件名模糊匹配,快速定位目标文件
支持两种模式:
- 全项目模式 (不指定
sub_path):列出整个项目的所有文件 - 聚焦模式 (指定
sub_path):只列出指定子目录下的文件
参数:
project_name(必需): 项目名称,例如nacossub_path(可选): 指定项目内的子目录路径,例如core或address/src/main/javafile_name_pattern(可选): 文件名模糊匹配模式(不区分大小写),用于进一步过滤文件列表- 支持左右模糊匹配,例如
Service将匹配包含service、Service、SERVICE的文件名 - ⚠️ 使用建议:如果匹配模式过于严格可能导致遗漏目标文件
- 💡 最佳实践:若未找到预期结果,建议不传此参数重新查询完整列表
- 支持左右模糊匹配,例如
project_dir(可选): 项目所在的父目录路径,如未提供则使用启动时配置的路径
自动过滤内容:
- ✅ 包含:Java 源代码 (.java)、配置文件 (.xml, .properties, .yaml, .json 等)、构建脚本、文档
- ❌ 排除:测试目录 (
src/test)、编译产物 (target,build)、IDE 配置、版本控制文件
智能提示机制:
- 当使用
file_name_pattern但未匹配到文件时,返回结果会包含提示信息 - 建议 AI 助手在未找到预期文件时,不传
file_name_pattern参数重新查询 - 有效减少因过度过滤导致的查询失败
示例 1 - 列出整个项目:
json
{
"project_name": "nacos"
}示例 2 - 只列出 core 模块:
json
{
"project_name": "nacos",
"sub_path": "core"
}示例 3 - 使用文件名模糊匹配:
json
{
"project_name": "nacos",
"file_name_pattern": "Service"
}返回格式:
json
{
"project_name": "nacos",
"project_dir": "/path/to/projects/nacos",
"search_scope": "core",
"file_name_pattern": "Service",
"total_files": 15,
"files": [
"core/src/main/java/com/alibaba/nacos/core/service/NacosService.java",
"api/src/main/java/com/alibaba/nacos/api/naming/NamingService.java",
"..."
],
"hint": "已使用文件名模式 'Service' 进行过滤。如果未找到预期的文件,可能是模式匹配过于严格。建议:不传入 file_name_pattern 参数重新调用 list_project_files 工具查看完整文件列表。"
}提示信息说明:
- 当使用
file_name_pattern但未匹配到任何文件时,hint字段会提示模式可能过于严格 - 当使用
file_name_pattern且有匹配结果时,hint字段会提醒如果结果不符合预期可以不传参数重新查询 - 这个智能提示机制帮助 AI 助手更好地调整查询策略,避免因过度过滤错过目标文件
read_project_code
从本地项目目录中读取指定文件的源代码或配置文件内容。
用途:
- 读取具体类或文件的完整源代码
- 查看配置文件内容(pom.xml、application.yml、application.properties 等)
- 读取项目文档(README.md、SQL 脚本等)
- 支持多模块 Maven/Gradle 项目
- 自动搜索常见的源代码和配置文件路径
参数:
project_name(必需): 项目名称,例如my-projectfile_path(必需): 文件标识符:可以是完全限定的 Java 类名或文件相对路径- Java 类名格式:
com.example.MyClass(自动查找对应的 .java 文件) - 相对路径格式:
src/main/java/com/example/MyClass.java - 模块相对路径:
core/src/main/java/com/example/MyClass.java - 配置文件路径:
src/main/resources/application.yml、pom.xml - 文档文件:
README.md、docs/setup.md
- Java 类名格式:
project_dir(可选): 项目目录路径,如未提供则使用启动时配置的路径
支持的文件类型:
- Java 源代码 (.java)
- 配置文件 (.xml, .properties, .yaml, .yml, .json, .conf, .config)
- 构建脚本 (.gradle, .gradle.kts, pom.xml)
- 文档文件 (.md, .txt)
- SQL 脚本 (.sql)
- Shell 脚本 (.sh, .bat)
自动搜索路径:
- 对于 Java 类名:
src/main/java/{class_path}.java、src/{class_path}.java、{class_path}.java - 对于配置文件:项目根目录、
src/main/resources/、src/、config/及子模块 - 支持多模块项目中的子模块路径
推荐工作流程:
- 使用
list_all_project确认项目存在 - 使用
list_project_files(建议带file_name_pattern参数)查看文件列表 - 使用本工具读取具体文件内容
示例 1 - 使用类名读取 Java 源代码:
json
{
"project_name": "my-spring-app",
"file_path": "com.example.service.UserService"
}示例 2 - 使用相对路径读取 Java 文件:
json
{
"project_name": "nacos",
"file_path": "address/src/main/java/com/alibaba/nacos/address/component/AddressServerGeneratorManager.java"
}示例 3 - 读取配置文件:
json
{
"project_name": "my-spring-app",
"file_path": "src/main/resources/application.yml"
}示例 4 - 读取项目根目录的文件:
json
{
"project_name": "my-spring-app",
"file_path": "pom.xml"
}返回格式:
json
{
"project_name": "my-spring-app",
"class_name": "com.example.service.UserService",
"file_path": "/path/to/projects/my-spring-app/src/main/java/com/example/service/UserService.java",
"code": "package com.example.service;\n\nimport ...\n\npublic class UserService {\n // ...\n}"
}read_jar_source
从 Maven 依赖中读取 Java 类的源代码(优先从 sources jar,否则反编译)。
参数:
group_id(必需): Maven group ID,例如org.springframeworkartifact_id(必需): Maven artifact ID,例如spring-coreversion(必需): Maven version,例如5.3.21class_name(必需): 完全限定的类名,例如org.springframework.core.SpringVersionprefer_sources(可选,默认true): 优先使用 sources jar 而不是反编译
工作原理:
- 首先尝试从
-sources.jar中提取源代码(如果prefer_sources=true) - 如果 sources jar 不存在或提取失败,自动回退到反编译主 JAR 文件
- 支持 SNAPSHOT 版本的智能处理
智能错误提示:
当 JAR 文件未找到时,工具会提供详细的排查建议:
- 提示可能的原因(依赖未安装、Maven 坐标错误)
- 建议使用
read_project_code工具读取项目的pom.xml文件 - 指导在
<dependencies>部分核对正确的 Maven 坐标 - 提示确认坐标后重新调用工具
- 说明可能需要执行 Maven 构建命令安装依赖
这个智能提示机制特别适合与 AI 助手配合使用,能有效减少因 Maven 坐标错误导致的重复尝试。
示例:
json
{
"group_id": "org.springframework",
"artifact_id": "spring-core",
"version": "5.3.21",
"class_name": "org.springframework.core.SpringVersion"
}返回格式:
json
{
"class_name": "org.springframework.core.SpringVersion",
"artifact": "org.springframework:spring-core:5.3.21",
"source_type": "sources.jar",
"code": "package org.springframework.core;\n\npublic class SpringVersion {\n // ...\n}"
}source_type 字段说明:
source_type 字段标识源码的来源,帮助 AI 助手了解代码的可靠性和新鲜度:
"sources.jar": 从 Maven 的 sources JAR 文件中提取(最可靠,与发布版本完全一致)"decompiled": 通过反编译器新反编译生成(可能存在反编译不完整的情况)"decompiled_cache": 从之前反编译的缓存中读取(避免重复反编译,提升性能)
💡 使用建议:
sources.jar来源的代码最准确,可直接作为分析依据decompiled来源的代码可能会有语法糖恢复、泛型擦除等反编译特征decompiled_cache与decompiled质量相同,只是从缓存读取以提升效率
反编译器选择与缓存机制
read_jar_source 工具支持多个反编译器,并根据 Java 版本自动选择最合适的:
| Java 版本 | 推荐反编译器 | 说明 |
|---|---|---|
| 8 - 20 | CFR | 自动使用 CFR 反编译器(兼容 Java 8+),已包含在包中:src/easy_code_reader/decompilers/cfr.jar |
| 21+ | Fernflower | 自动使用 Fernflower 反编译器(IntelliJ IDEA 使用的反编译器),已包含在包中:src/easy_code_reader/decompilers/fernflower.jar |
反编译后的文件会被缓存在 JAR 包所在目录的 easy-code-reader/ 子目录中,例如:
如果 JAR 包位置为:
bash
~/.m2/repository/org/springframework/spring-core/5.3.21/spring-core-5.3.21.jar反编译后的源文件将存储在:
bash
~/.m2/repository/org/springframework/spring-core/5.3.21/easy-code-reader/spring-core-5.3.21.jar缓存文件本身也是一个 JAR 格式的压缩包,包含所有反编译后的 .java 文件,这样可以避免重复反编译相同的 JAR 包,提高性能。但 针对 SNAPSHOT 版本需要特殊处理: 因为 Maven 针对快照版本会生成带时间戳的 JAR(如 artifact-1.0.0-20251030.085053-1.jar),Easy Code Reader 会自动查找最新的带时间戳版本进行反编译,并且以缓存以 artifact-1.0.0-20251030.085053-1.jar 名称存储,提供版本判断的依据,当检测到新版本时,会自动清理旧的 SNAPSHOT 缓存,生成新的缓存文件。