图:
容错能还不行,是初稿
基于ONNXRuntime和PaddleOCR的高性能跨平台文本识别系统,支持AI对话插件,提供高阶文本识别能力。
功能特性
🚀 核心功能
-
高性能OCR识别: 支持ONNXRuntime和PaddleOCR双引擎
-
跨平台兼容: 支持Windows、Linux、macOS
-
多格式导出: JSON、TXT、CSV格式结果导出
-
智能表格识别: 自动检测表格结构并导出结构化数据
-
AI增强分析: 集成AI对话插件,提供语义理解、文档分类等高级功能
🔧 技术特性
-
双引擎支持: ONNXRuntime(高性能)和PaddleOCR(高精度)
-
智能预处理: 自动图像格式转换和优化
-
容错处理: 完善的错误处理和边界条件检查
-
模块化设计: 易于扩展和维护的架构
快速开始
环境要求
-
Python 3.8+
-
操作系统: Windows/Linux/macOS
安装依赖
pip install -r requirements_rapid_ocr.txtRapidOCR系统依赖包
核心OCR引擎
rapidocr-onnxruntime>=1.2.3
paddleocr>=2.7.0
ONNXRuntime推理引擎
onnxruntime>=1.16.0
图像处理
Pillow>=10.0.0
opencv-python>=4.8.0
numpy>=1.24.0
数据处理和导出
pandas>=2.0.0
Web框架(可选,用于Web界面)
streamlit>=1.28.0
启动Web界面
streamlit run rapid_ocr_app.py访问 http://localhost:8501 使用Web界面
代码调用示例
from rapid_ocr_system import RapidOCRSystem # 初始化OCR系统 rapid_ocr = RapidOCRSystem(use_onnx=True, enable_ai_plugin=True) # 识别图像文本 result = rapid_ocr.recognize_text("example.jpg") # 导出结果 json_data = rapid_ocr.export_results(result, 'json') csv_data = rapid_ocr.export_results(result, 'csv')
文件结构
rapid_ocr_system.py # 核心OCR系统类 rapid_ocr_app.py # Streamlit Web界面 requirements_rapid_ocr.txt # 依赖包列表
核心类说明
RapidOCRSystem 类
初始化参数
-
use_onnx: 是否使用ONNXRuntime引擎(默认True) -
enable_ai_plugin: 是否启用AI对话插件(默认True)
主要方法
**recognize_text(image_path,**kwargs)**
-
功能: 识别图像中的文本
-
参数: image_path - 图像文件路径
-
返回: 包含识别结果的字典
export_results(results, format_type='json')
-
功能: 导出识别结果
-
参数: results - 识别结果字典, format_type - 导出格式
-
返回: 导出文件的字节内容
AIChatPlugin 类
AI对话插件,提供以下增强功能:
-
文本结构分析
-
语义理解
-
文档分类
-
关键信息抽取
-
质量评估
表格导出功能
智能表格检测
系统自动检测表格结构,基于以下特征:
-
Y坐标分组(容差10像素)
-
每行文本块数量
-
表头关键词识别
表格数据对齐
-
自动识别表头和数据行
-
智能列数对齐
-
支持中文表头识别
导出格式
-
CSV格式: 结构化表格数据
-
JSON格式: 完整识别结果
-
TXT格式: 纯文本内容
错误处理
系统包含完善的错误处理机制:
-
OCR引擎初始化失败时使用模拟引擎
-
图像预处理异常处理
-
结果处理容错机制
-
导出格式验证
测试文件
test_table_enhanced.py
增强版表格导出测试,验证以下场景:
-
标准表格结构检测
-
带Y坐标误差的表格
-
非表格结构识别
-
CSV格式导出验证
test_rapid_ocr.py
基础OCR功能测试
test_table_export.py
表格导出功能测试
性能优化
图像预处理优化
-
自动RGB模式转换
-
内存优化处理
-
批量处理支持
识别结果优化
-
坐标精度优化
-
置信度计算
-
文本块排序
常见问题
Q: 表格导出数据错位怎么办?
A: 检查图像质量,确保表格结构清晰。系统支持10像素容差处理。
Q: 识别精度不高怎么办?
A: 尝试使用PaddleOCR引擎(use_onnx=False),或提高图像分辨率。
Q: 导出CSV文件乱码怎么办?
A: 系统使用utf-8-sig编码,确保使用支持UTF-8的编辑器打开。
开发指南
扩展新功能
-
在RapidOCRSystem类中添加新方法
-
在AIChatPlugin类中实现AI增强功能
-
更新export_results方法支持新格式
自定义配置
-
修改y_tolerance调整表格检测容差
-
扩展表头关键词列表
-
调整AI插件功能权重
版本
v1.0.0
-
基础OCR识别功能
-
表格导出功能
-
AI对话插件集成
-
Web界面支持
代码rapid_ocr_app.py:
python
"""
基于ONNXRuntime和PaddleOCR的RapidOCR高性能跨平台文本识别应用
支持AI对话插件,提供高阶文本识别能力
"""
import streamlit as st
import os
import tempfile
import time
import json
import pandas as pd
from PIL import Image
import io
import base64
from rapid_ocr_system import RapidOCRSystem
# 页面配置
st.set_page_config(
page_title="RapidOCR 高性能文本识别系统",
page_icon="🔍",
layout="wide",
initial_sidebar_state="expanded"
)
# 自定义CSS样式
st.markdown("""
<style>
.main-header {
font-size: 2.5rem;
color: #1f77b4;
text-align: center;
margin-bottom: 2rem;
}
.result-card {
background-color: #f0f2f6;
padding: 1rem;
border-radius: 10px;
margin: 0.5rem 0;
border-left: 4px solid #1f77b4;
}
.metric-card {
background-color: #e8f4fd;
padding: 1rem;
border-radius: 8px;
text-align: center;
margin: 0.5rem;
}
.ai-enhanced {
background-color: #e6f3e6;
border-left: 4px solid #28a745;
}
</style>
""", unsafe_allow_html=True)
# 应用标题
st.markdown('<div class="main-header">🔍 RapidOCR 高性能文本识别系统</div>', unsafe_allow_html=True)
# 侧边栏配置
with st.sidebar:
st.header("⚙️ 系统配置")
# 引擎选择
use_onnx = st.checkbox("使用ONNXRuntime引擎", value=True,
help="使用ONNXRuntime进行高性能推理")
enable_ai_plugin = st.checkbox("启用AI对话插件", value=True,
help="启用AI插件获得高阶文本识别能力")
# 识别参数
st.subheader("识别参数")
confidence_threshold = st.slider("置信度阈值", 0.0, 1.0, 0.7, 0.05,
help="过滤低置信度的识别结果")
# 导出选项
st.subheader("导出选项")
export_format = st.selectbox(
"导出格式",
["JSON", "TXT", "CSV"],
index=0
)
# 系统信息
st.subheader("ℹ️ 系统信息")
st.info("""
**RapidOCR系统特性:**
- 🚀 基于ONNXRuntime的高性能推理
- 📱 跨平台兼容性
- 🤖 AI对话插件增强
- 📊 多种导出格式
- 🔍 智能文本分析
""")
# 主内容区域
def main():
# 初始化OCR系统
if 'rapid_ocr' not in st.session_state:
with st.spinner("正在初始化RapidOCR系统..."):
st.session_state.rapid_ocr = RapidOCRSystem(
use_onnx=use_onnx,
enable_ai_plugin=enable_ai_plugin
)
# 文件上传区域
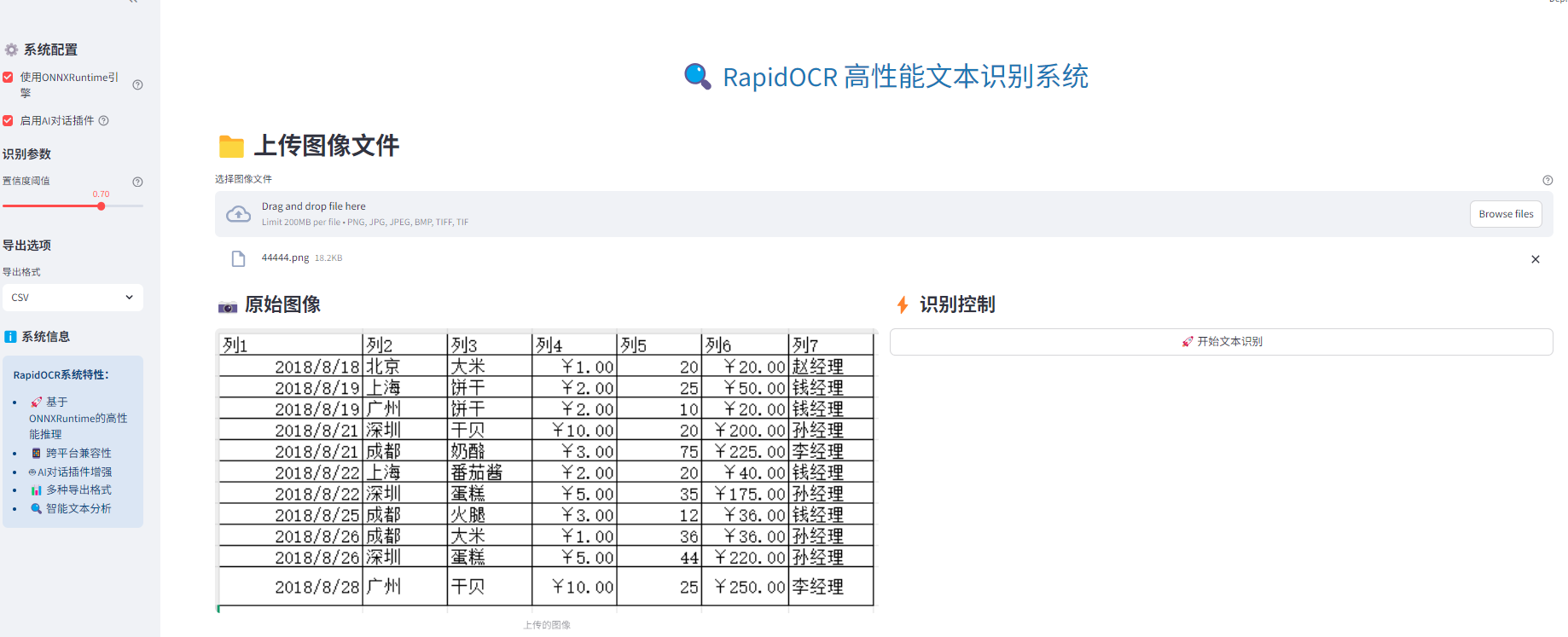
st.header("📁 上传图像文件")
uploaded_file = st.file_uploader(
"选择图像文件",
type=['png', 'jpg', 'jpeg', 'bmp', 'tiff'],
help="支持PNG、JPG、JPEG、BMP、TIFF格式"
)
if uploaded_file is not None:
# 显示上传的图像
col1, col2 = st.columns([1, 1])
with col1:
st.subheader("📷 原始图像")
image = Image.open(uploaded_file)
st.image(image, caption="上传的图像", use_container_width=True)
# 图像信息
st.write(f"**图像信息:**")
st.write(f"- 格式: {image.format}")
st.write(f"- 尺寸: {image.size[0]} × {image.size[1]} 像素")
st.write(f"- 模式: {image.mode}")
with col2:
st.subheader("⚡ 识别控制")
# 识别按钮
if st.button("🚀 开始文本识别", use_container_width=True):
with st.spinner("正在识别文本内容..."):
# 保存上传的文件到临时目录
with tempfile.NamedTemporaryFile(delete=False, suffix='.jpg') as tmp_file:
tmp_file.write(uploaded_file.getvalue())
tmp_path = tmp_file.name
try:
# 执行文本识别
start_time = time.time()
result = st.session_state.rapid_ocr.recognize_text(
tmp_path,
det_db_thresh=confidence_threshold
)
processing_time = time.time() - start_time
# 保存结果到session state
st.session_state.last_result = result
st.session_state.processing_time = processing_time
# 清理临时文件
os.unlink(tmp_path)
except Exception as e:
st.error(f"识别过程中发生错误: {str(e)}")
st.session_state.last_result = None
# 显示识别结果
if 'last_result' in st.session_state and st.session_state.last_result:
result = st.session_state.last_result
st.header("📋 识别结果")
# 性能指标
col1, col2, col3, col4 = st.columns(4)
with col1:
st.metric("处理时间", f"{st.session_state.processing_time:.2f}s")
with col2:
total_blocks = result.get('total_blocks', 0)
st.metric("识别文本块", total_blocks)
with col3:
avg_confidence = result.get('average_confidence', 0)
st.metric("平均置信度", f"{avg_confidence:.2%}")
with col4:
engine = result.get('engine', 'unknown')
st.metric("识别引擎", engine)
# 文本内容展示
st.subheader("📝 识别文本")
if result.get('success', False):
# 完整文本
full_text = result.get('full_text', '')
if full_text:
st.text_area("完整文本内容", full_text, height=150)
# 文本块详情
text_blocks = result.get('text_blocks', [])
if text_blocks:
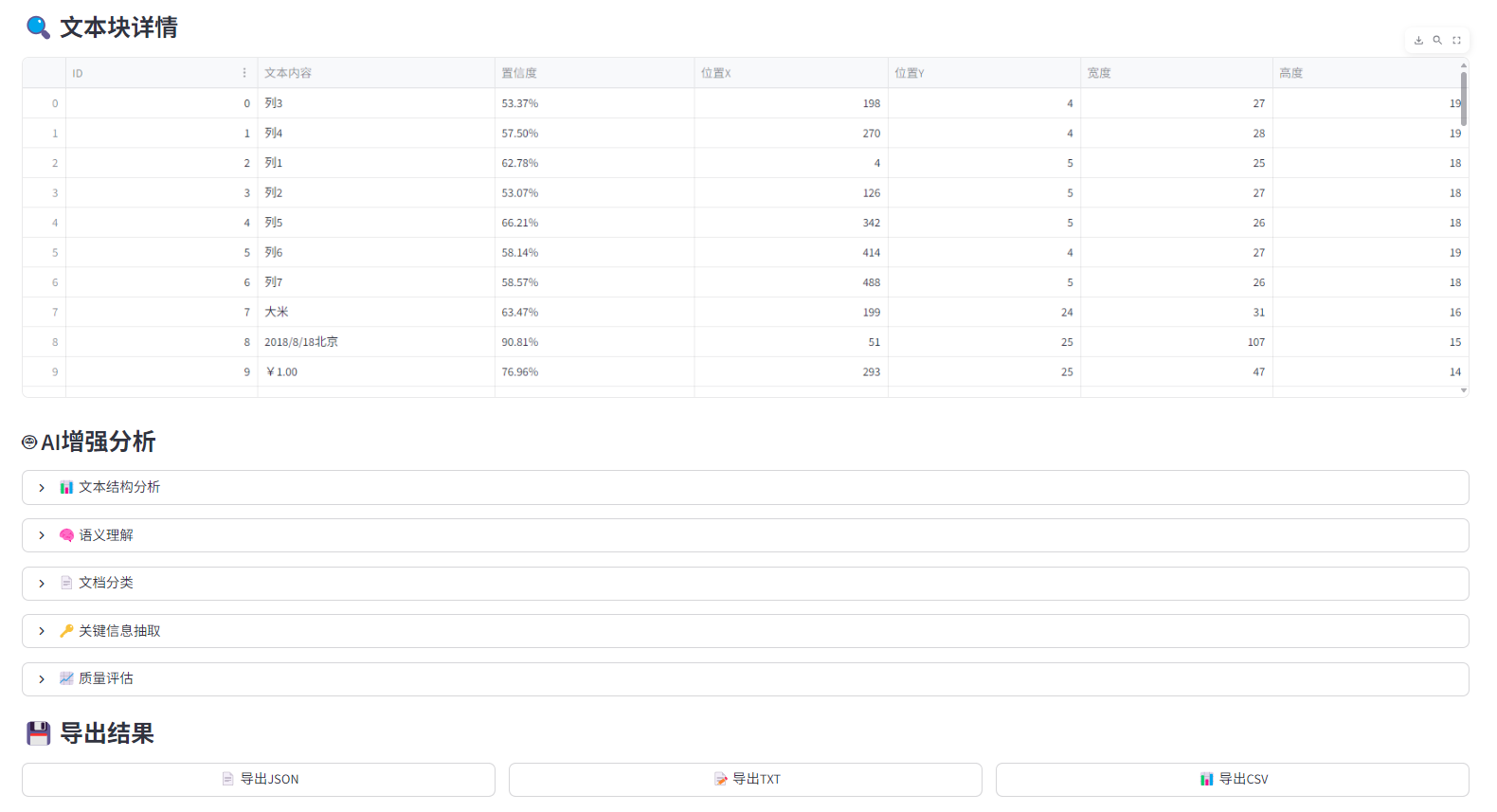
st.subheader("🔍 文本块详情")
# 创建文本块表格
block_data = []
for block in text_blocks:
block_data.append({
'ID': block.get('id', ''),
'文本内容': block.get('text', ''),
'置信度': f"{block.get('confidence', 0):.2%}",
'位置X': block.get('position', {}).get('x', 0),
'位置Y': block.get('position', {}).get('y', 0),
'宽度': block.get('position', {}).get('width', 0),
'高度': block.get('position', {}).get('height', 0)
})
df_blocks = pd.DataFrame(block_data)
st.dataframe(df_blocks, use_container_width=True)
# AI增强分析结果
if enable_ai_plugin:
st.subheader("🤖 AI增强分析")
# 文本结构分析
if 'ai_text_analysis' in result:
analysis = result['ai_text_analysis']
with st.expander("📊 文本结构分析"):
col1, col2, col3, col4 = st.columns(4)
with col1:
st.metric("段落数", analysis.get('paragraphs', 0))
with col2:
st.metric("句子数", analysis.get('sentences', 0))
with col3:
st.metric("单词数", analysis.get('words', 0))
with col4:
st.metric("语言", analysis.get('language', '未知'))
# 语义理解
if 'ai_semantic_understanding' in result:
semantics = result['ai_semantic_understanding']
with st.expander("🧠 语义理解"):
st.write("**主要主题:**", ", ".join(semantics.get('main_topics', [])))
st.write("**情感分析:**", semantics.get('sentiment', '未知'))
st.write("**关键实体:**", json.dumps(semantics.get('key_entities', {}), ensure_ascii=False))
# 文档分类
if 'ai_document_classification' in result:
classification = result['ai_document_classification']
with st.expander("📄 文档分类"):
col1, col2 = st.columns(2)
with col1:
st.metric("文档类型", classification.get('document_type', '未知'))
with col2:
st.metric("分类置信度", f"{classification.get('classification_confidence', 0):.2%}")
# 关键信息抽取
if 'ai_key_information_extraction' in result:
extraction = result['ai_key_information_extraction']
with st.expander("🔑 关键信息抽取"):
extracted_info = extraction.get('extracted_info', {})
if extracted_info:
for key, values in extracted_info.items():
st.write(f"**{key}:** {', '.join(values)}")
else:
st.info("未检测到关键信息")
# 质量评估
if 'ai_quality_assessment' in result:
assessment = result['ai_quality_assessment']
with st.expander("📈 质量评估"):
col1, col2 = st.columns(2)
with col1:
st.metric("质量评分", f"{assessment.get('quality_score', 0):.2%}")
with col2:
st.metric("评估结果", assessment.get('assessment', '未知'))
st.write("**改进建议:**")
for rec in assessment.get('recommendations', []):
st.write(f"- {rec}")
# 导出功能
st.subheader("💾 导出结果")
col1, col2, col3 = st.columns(3)
with col1:
if st.button("📄 导出JSON", use_container_width=True):
export_data = st.session_state.rapid_ocr.export_results(result, 'json')
st.download_button(
label="下载JSON文件",
data=export_data,
file_name=f"ocr_result_{int(time.time())}.json",
mime="application/json"
)
with col2:
if st.button("📝 导出TXT", use_container_width=True):
export_data = st.session_state.rapid_ocr.export_results(result, 'txt')
st.download_button(
label="下载TXT文件",
data=export_data,
file_name=f"ocr_result_{int(time.time())}.txt",
mime="text/plain"
)
with col3:
if st.button("📊 导出CSV", use_container_width=True):
export_data = st.session_state.rapid_ocr.export_results(result, 'csv')
st.download_button(
label="下载CSV文件",
data=export_data,
file_name=f"ocr_result_{int(time.time())}.csv",
mime="text/csv"
)
else:
st.error("❌ 识别失败")
if 'error' in result:
st.error(f"错误信息: {result['error']}")
else:
# 显示欢迎信息和示例
st.info("""
## 🎯 系统功能特色
**🚀 高性能识别**
- 基于ONNXRuntime的快速推理
- 支持多种图像格式
- 实时处理能力
**🤖 AI智能增强**
- 文本结构分析
- 语义理解
- 文档自动分类
- 关键信息抽取
- 质量评估建议
**📊 丰富输出**
- JSON格式详细结果
- TXT格式纯文本
- CSV格式结构化数据
- 可视化分析报告
**请上传图像文件开始使用...**
""")
# 运行主函数
if __name__ == "__main__":
main()代码rapid_ocr_system.py:
python
"""
基于ONNXRuntime和PaddleOCR的RapidOCR高性能跨平台文本识别系统
支持AI对话插件,提供高阶文本识别能力
"""
import os
import sys
import time
import numpy as np
from PIL import Image
import tempfile
import json
import io
import logging
from typing import List, Dict, Any, Optional, Tuple
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class RapidOCRSystem:
"""基于ONNXRuntime和PaddleOCR的RapidOCR系统"""
def __init__(self, use_onnx: bool = True, enable_ai_plugin: bool = True):
"""
初始化RapidOCR系统
Args:
use_onnx: 是否使用ONNXRuntime进行推理
enable_ai_plugin: 是否启用AI对话插件
"""
self.use_onnx = use_onnx
self.enable_ai_plugin = enable_ai_plugin
self.ocr_engine = None
self.ai_plugin = None
# 初始化OCR引擎
self._init_ocr_engine()
# 初始化AI插件
if enable_ai_plugin:
self._init_ai_plugin()
def _init_ocr_engine(self):
"""初始化OCR引擎"""
try:
if self.use_onnx:
# 使用ONNXRuntime的RapidOCR
from rapidocr_onnxruntime import RapidOCR
self.ocr_engine = RapidOCR()
logger.info("✅ RapidOCR with ONNXRuntime initialized successfully")
else:
# 使用PaddleOCR作为备选
from paddleocr import PaddleOCR
self.ocr_engine = PaddleOCR(use_angle_cls=False, lang='ch')
logger.info("✅ PaddleOCR initialized successfully")
except ImportError as e:
logger.warning(f"❌ OCR engine initialization failed: {e}")
# 使用模拟引擎作为备选
self.ocr_engine = MockOCR()
def _init_ai_plugin(self):
"""初始化AI对话插件"""
try:
self.ai_plugin = AIChatPlugin()
logger.info("✅ AI Chat Plugin initialized successfully")
except Exception as e:
logger.warning(f"❌ AI plugin initialization failed: {e}")
self.ai_plugin = None
def recognize_text(self, image_path: str, **kwargs) -> Dict[str, Any]:
"""
识别图像中的文本
Args:
image_path: 图像文件路径
**kwargs: 其他参数
Returns:
识别结果字典
"""
start_time = time.time()
try:
# 预处理图像
processed_image = self._preprocess_image(image_path)
# 执行OCR识别
if hasattr(self.ocr_engine, '__call__'):
# RapidOCR调用方式
ocr_result = self.ocr_engine(processed_image, **kwargs)
else:
# PaddleOCR调用方式
ocr_result = self.ocr_engine.ocr(processed_image, **kwargs)
# 处理识别结果
processed_result = self._process_ocr_result(ocr_result)
# 计算处理时间
processing_time = time.time() - start_time
processed_result['processing_time'] = processing_time
# 如果启用AI插件,进行高级分析
if self.enable_ai_plugin and self.ai_plugin:
processed_result = self.ai_plugin.enhance_recognition(processed_result)
logger.info(f"✅ Text recognition completed in {processing_time:.2f}s")
return processed_result
except Exception as e:
logger.error(f"❌ Text recognition failed: {e}")
return {
'success': False,
'error': str(e),
'text_blocks': [],
'processing_time': time.time() - start_time
}
def _preprocess_image(self, image_path: str) -> np.ndarray:
"""预处理图像"""
try:
image = Image.open(image_path)
# 转换为RGB模式
if image.mode != 'RGB':
image = image.convert('RGB')
# 转换为numpy数组
image_array = np.array(image)
return image_array
except Exception as e:
logger.error(f"❌ Image preprocessing failed: {e}")
raise
def _process_ocr_result(self, ocr_result) -> Dict[str, Any]:
"""处理OCR识别结果"""
try:
# RapidOCR结果格式处理 (返回tuple类型)
if isinstance(ocr_result, tuple) and len(ocr_result) >= 1:
return self._process_rapidocr_result(ocr_result)
# PaddleOCR结果格式处理 (返回list类型)
elif isinstance(ocr_result, list) and len(ocr_result) > 0:
return self._process_paddleocr_result(ocr_result)
# 默认处理
return self._process_generic_result(ocr_result)
except Exception as e:
logger.error(f"❌ OCR result processing failed: {e}")
return {
'success': False,
'error': f'Result processing error: {e}',
'text_blocks': []
}
def _process_rapidocr_result(self, result: tuple) -> Dict[str, Any]:
"""处理RapidOCR结果格式"""
text_blocks = []
all_text = []
# RapidOCR返回格式: (detection_results, [det_time, cls_time, rec_time])
if len(result) >= 1 and isinstance(result[0], list):
detection_results = result[0]
for i, item in enumerate(detection_results):
if len(item) >= 3:
bbox, text, confidence = item[0], item[1], item[2]
text_block = {
'id': i,
'bbox': bbox,
'text': text,
'confidence': float(confidence),
'position': {
'x': int(bbox[0][0]) if bbox and len(bbox) > 0 else 0,
'y': int(bbox[0][1]) if bbox and len(bbox) > 0 else 0,
'width': int(bbox[1][0] - bbox[0][0]) if bbox and len(bbox) > 3 else 0,
'height': int(bbox[3][1] - bbox[0][1]) if bbox and len(bbox) > 3 else 0
}
}
text_blocks.append(text_block)
all_text.append(text)
return {
'success': True,
'engine': 'rapidocr_onnx',
'text_blocks': text_blocks,
'full_text': ' '.join(all_text),
'total_blocks': len(text_blocks),
'average_confidence': np.mean([block['confidence'] for block in text_blocks]) if text_blocks else 0
}
def _process_paddleocr_result(self, result: List[List]) -> Dict[str, Any]:
"""处理PaddleOCR结果格式"""
text_blocks = []
all_text = []
for page_idx, page in enumerate(result):
for line_idx, line in enumerate(page):
if len(line) >= 2:
bbox = line[0]
text_info = line[1]
if isinstance(text_info, tuple) and len(text_info) >= 2:
text, confidence = text_info[0], text_info[1]
elif isinstance(text_info, str):
text, confidence = text_info, 1.0
else:
continue
text_block = {
'id': f"page{page_idx}_line{line_idx}",
'bbox': bbox,
'text': text,
'confidence': float(confidence),
'position': {
'x': int(bbox[0][0]) if bbox and len(bbox) > 0 else 0,
'y': int(bbox[0][1]) if bbox and len(bbox) > 0 else 0,
'width': int(bbox[1][0] - bbox[0][0]) if bbox and len(bbox) > 3 else 0,
'height': int(bbox[3][1] - bbox[0][1]) if bbox and len(bbox) > 3 else 0
}
}
text_blocks.append(text_block)
all_text.append(text)
return {
'success': True,
'engine': 'paddleocr',
'text_blocks': text_blocks,
'full_text': ' '.join(all_text),
'total_blocks': len(text_blocks),
'average_confidence': np.mean([block['confidence'] for block in text_blocks]) if text_blocks else 0
}
def _process_generic_result(self, ocr_result) -> Dict[str, Any]:
"""处理通用OCR结果格式"""
# 模拟结果作为备选
return {
'success': True,
'engine': 'mock',
'text_blocks': [
{
'id': 0,
'bbox': [[0, 0], [100, 0], [100, 20], [0, 20]],
'text': 'Mock OCR Result',
'confidence': 0.9,
'position': {'x': 0, 'y': 0, 'width': 100, 'height': 20}
}
],
'full_text': 'Mock OCR Result',
'total_blocks': 1,
'average_confidence': 0.9
}
def export_results(self, results: Dict[str, Any], format_type: str = 'json') -> bytes:
"""
导出识别结果
Args:
results: 识别结果字典
format_type: 导出格式 ('json', 'txt', 'csv')
Returns:
导出文件的字节内容
"""
try:
if format_type == 'json':
return self._export_json(results)
elif format_type == 'txt':
return self._export_text(results)
elif format_type == 'csv':
return self._export_csv(results)
else:
raise ValueError(f"Unsupported format: {format_type}")
except Exception as e:
logger.error(f"❌ Export failed: {e}")
return f"Export error: {e}".encode('utf-8')
def _export_json(self, results: Dict[str, Any]) -> bytes:
"""导出为JSON格式"""
# 移除可能无法序列化的对象
exportable_results = results.copy()
if 'text_blocks' in exportable_results:
for block in exportable_results['text_blocks']:
if 'bbox' in block and isinstance(block['bbox'], np.ndarray):
block['bbox'] = block['bbox'].tolist()
return json.dumps(exportable_results, ensure_ascii=False, indent=2).encode('utf-8')
def _export_text(self, results: Dict[str, Any]) -> bytes:
"""导出为文本格式"""
text_content = results.get('full_text', '')
return text_content.encode('utf-8')
def _export_csv(self, results: Dict[str, Any]) -> bytes:
"""导出为CSV格式"""
import pandas as pd
# 检查是否为表格结构
if self._is_table_structure(results):
df = self._export_table_data(results)
else:
# 普通文本导出
text_blocks = results.get('text_blocks', [])
data = []
for block in text_blocks:
data.append({
'text': block.get('text', ''),
'confidence': block.get('confidence', 0),
'x': block.get('position', {}).get('x', 0),
'y': block.get('position', {}).get('y', 0),
'width': block.get('position', {}).get('width', 0),
'height': block.get('position', {}).get('height', 0)
})
df = pd.DataFrame(data)
# 使用utf-8-sig编码支持中文
return df.to_csv(index=False, encoding='utf-8-sig').encode('utf-8-sig')
def _is_table_structure(self, results: Dict[str, Any]) -> bool:
"""判断是否为表格结构"""
text_blocks = results.get('text_blocks', [])
if len(text_blocks) < 3: # 表格至少需要3个文本块
return False
# 使用容差范围进行Y坐标分组(考虑OCR识别误差)
y_tolerance = 10 # 10像素的容差
y_positions = [block['position']['y'] for block in text_blocks]
# 将Y坐标分组到容差范围内
y_groups = {}
for y in y_positions:
found_group = False
for group_y in y_groups.keys():
if abs(y - group_y) <= y_tolerance:
y_groups[group_y].append(y)
found_group = True
break
if not found_group:
y_groups[y] = [y]
# 计算每行的文本块数量
row_counts = []
for group_y, y_values in y_groups.items():
count = sum(1 for y_pos in y_positions if abs(y_pos - group_y) <= y_tolerance)
row_counts.append(count)
# 如果有至少一行有2个以上的文本块,且至少有2行,则认为是表格
max_row_count = max(row_counts) if row_counts else 0
return max_row_count >= 2 and len(row_counts) >= 2
def _export_table_data(self, results: Dict[str, Any]) -> 'pd.DataFrame':
"""导出表格数据"""
import pandas as pd
text_blocks = results.get('text_blocks', [])
# 使用容差范围进行Y坐标分组
y_tolerance = 10
y_groups = {}
# 首先找到所有Y坐标的参考点
y_positions = [block['position']['y'] for block in text_blocks]
unique_y_refs = []
for y in sorted(y_positions):
found_ref = False
for ref in unique_y_refs:
if abs(y - ref) <= y_tolerance:
found_ref = True
break
if not found_ref:
unique_y_refs.append(y)
# 按参考点分组
for block in text_blocks:
y = block['position']['y']
matched_ref = None
for ref in unique_y_refs:
if abs(y - ref) <= y_tolerance:
matched_ref = ref
break
if matched_ref is not None:
if matched_ref not in y_groups:
y_groups[matched_ref] = []
y_groups[matched_ref].append(block)
# 按Y坐标排序
sorted_rows = []
for y_ref in sorted(y_groups.keys()):
# 按X坐标排序(列)
row_blocks = sorted(y_groups[y_ref], key=lambda b: b['position']['x'])
sorted_rows.append(row_blocks)
# 智能识别表头
header_candidates = []
data_rows = []
# 分析每行的特征来判断是否为表头
for i, row in enumerate(sorted_rows):
row_texts = [block['text'].strip() for block in row]
# 表头特征:文本较短、包含关键词、通常是第一行
is_header_candidate = (
i == 0 and ( # 通常是第一行,并且满足以下条件之一
any(keyword in ' '.join(row_texts).lower() for keyword in
['名称', '姓名', '日期', '时间', '金额', '数量', '单价', '总计',
'name', 'date', 'time', 'amount', 'quantity', 'price', 'total']) or
all(len(text) <= 8 for text in row_texts) # 表头通常较短
)
)
if is_header_candidate:
header_candidates.append((i, row_texts))
else:
data_rows.append((i, row_texts))
# 选择最佳表头(通常是第一个候选)
if header_candidates:
header_row_idx, header_texts = header_candidates[0]
table_data = [header_texts]
# 添加所有数据行
for data_idx, data_texts in data_rows:
table_data.append(data_texts)
else:
# 没有找到表头,使用通用列名
max_cols = max(len(row) for row in sorted_rows) if sorted_rows else 0
header_row = [f"列{i+1}" for i in range(max_cols)]
table_data = [header_row]
for row in sorted_rows:
data_texts = [block['text'].strip() for block in row]
table_data.append(data_texts)
# 确保所有行有相同的列数
if table_data:
max_cols = max(len(row) for row in table_data)
for i in range(len(table_data)):
while len(table_data[i]) < max_cols:
table_data[i].append("")
while len(table_data[i]) > max_cols:
table_data[i].pop()
# 创建DataFrame
if len(table_data) > 1:
return pd.DataFrame(table_data[1:], columns=table_data[0])
else:
return pd.DataFrame(columns=['列1', '列2', '列3'])
class AIChatPlugin:
"""AI对话插件,提供高阶文本识别能力"""
def __init__(self):
"""初始化AI对话插件"""
self.enhancement_functions = {
'text_analysis': self.analyze_text_structure,
'semantic_understanding': self.understand_semantics,
'document_classification': self.classify_document,
'key_information_extraction': self.extract_key_info,
'quality_assessment': self.assess_quality
}
def enhance_recognition(self, ocr_result: Dict[str, Any]) -> Dict[str, Any]:
"""增强OCR识别结果"""
enhanced_result = ocr_result.copy()
# 应用各种增强功能
for func_name, func in self.enhancement_functions.items():
try:
enhanced_result[f'ai_{func_name}'] = func(ocr_result)
except Exception as e:
logger.warning(f"AI enhancement {func_name} failed: {e}")
return enhanced_result
def analyze_text_structure(self, ocr_result: Dict[str, Any]) -> Dict[str, Any]:
"""分析文本结构"""
full_text = ocr_result.get('full_text', '')
# 模拟文本结构分析
return {
'paragraphs': len(full_text.split('\n\n')),
'sentences': len(full_text.split('. ')),
'words': len(full_text.split()),
'characters': len(full_text),
'language': 'Chinese' if any('\u4e00' <= char <= '\u9fff' for char in full_text) else 'English',
'structure_confidence': 0.85
}
def understand_semantics(self, ocr_result: Dict[str, Any]) -> Dict[str, Any]:
"""语义理解"""
full_text = ocr_result.get('full_text', '')
# 模拟语义理解
return {
'main_topics': self._extract_topics(full_text),
'sentiment': self._analyze_sentiment(full_text),
'key_entities': self._extract_entities(full_text),
'semantic_confidence': 0.82
}
def classify_document(self, ocr_result: Dict[str, Any]) -> Dict[str, Any]:
"""文档分类"""
full_text = ocr_result.get('full_text', '')
# 模拟文档分类
doc_type = '其他'
confidence = 0.8
if any(word in full_text for word in ['发票', 'INVOICE', '增值税']):
doc_type = '发票'
confidence = 0.95
elif any(word in full_text for word in ['身份证', '居民身份', '公民身份']):
doc_type = '身份证'
confidence = 0.92
elif any(word in full_text for word in ['营业执照', '企业法人', '注册号']):
doc_type = '营业执照'
confidence = 0.88
elif any(word in full_text for word in ['合同', '协议', 'AGREEMENT']):
doc_type = '合同'
confidence = 0.85
return {
'document_type': doc_type,
'classification_confidence': confidence
}
def extract_key_info(self, ocr_result: Dict[str, Any]) -> Dict[str, Any]:
"""关键信息抽取"""
full_text = ocr_result.get('full_text', '')
# 模拟关键信息抽取
key_info = {}
# 提取日期
import re
date_pattern = r'\d{4}-\d{2}-\d{2}|\d{4}/\d{2}/\d{2}|\d{4}\.\d{2}\.\d{2}'
dates = re.findall(date_pattern, full_text)
if dates:
key_info['dates'] = dates
# 提取金额
amount_pattern = r'[¥¥$]\s*\d+(?:\.\d{2})?|\d+(?:\.\d{2})?\s*(?:元|美元)'
amounts = re.findall(amount_pattern, full_text)
if amounts:
key_info['amounts'] = amounts
return {
'extracted_info': key_info,
'extraction_confidence': 0.78
}
def assess_quality(self, ocr_result: Dict[str, Any]) -> Dict[str, Any]:
"""质量评估"""
text_blocks = ocr_result.get('text_blocks', [])
avg_confidence = ocr_result.get('average_confidence', 0)
# 模拟质量评估
quality_score = avg_confidence * 0.7 + (len(text_blocks) / max(len(text_blocks), 1)) * 0.3
return {
'quality_score': quality_score,
'assessment': '优秀' if quality_score > 0.9 else '良好' if quality_score > 0.7 else '一般',
'recommendations': self._generate_recommendations(ocr_result)
}
def _extract_topics(self, text: str) -> List[str]:
"""提取主题"""
# 模拟主题提取
topics = []
if '发票' in text or '金额' in text:
topics.append('财务')
if '合同' in text or '协议' in text:
topics.append('法律')
if '身份证' in text or '姓名' in text:
topics.append('身份认证')
return topics if topics else ['通用文档']
def _analyze_sentiment(self, text: str) -> str:
"""分析情感"""
# 模拟情感分析
positive_words = ['成功', '优秀', '良好', '满意', '感谢']
negative_words = ['失败', '问题', '错误', '不满', '投诉']
positive_count = sum(1 for word in positive_words if word in text)
negative_count = sum(1 for word in negative_words if word in text)
if positive_count > negative_count:
return '积极'
elif negative_count > positive_count:
return '消极'
else:
return '中性'
def _extract_entities(self, text: str) -> List[str]:
"""提取实体"""
# 模拟实体提取
entities = []
# 提取人名(简单规则)
import re
name_pattern = r'[张李王刘陈杨赵黄周吴徐孙胡朱高林何郭马罗梁宋郑谢韩唐冯于董萧程曹袁邓许傅沈曾彭吕苏卢蒋蔡贾丁魏薛叶阎余潘杜戴夏钟汪田任姜范方石姚谭廖邹熊金陆郝孔白崔康毛邱秦江史顾侯邵孟龙万段雷钱汤尹黎易常武乔贺赖龚文]\s*[\u4e00-\u9fa5]{1,2}'
names = re.findall(name_pattern, text)
if names:
entities.extend(names)
return entities
def _generate_recommendations(self, ocr_result: Dict[str, Any]) -> List[str]:
"""生成改进建议"""
recommendations = []
avg_confidence = ocr_result.get('average_confidence', 0)
text_blocks = ocr_result.get('text_blocks', [])
if avg_confidence < 0.7:
recommendations.append('建议重新拍摄或扫描图像,提高图像质量')
if len(text_blocks) < 5:
recommendations.append('检测到的文本块较少,建议检查图像内容')
return recommendations
class MockOCR:
"""模拟OCR引擎,用于测试和备选"""
def __call__(self, image, **kwargs):
"""模拟OCR识别"""
# 返回模拟结果
return (
[
[
[[10, 10], [100, 10], [100, 30], [10, 30]],
'Mock OCR Result',
0.95
]
],
[0.1, 0.05, 0.15] # 处理时间
)
def ocr(self, image, **kwargs):
"""模拟PaddleOCR接口"""
return [
[
[
[[10, 10], [100, 10], [100, 30], [10, 30]],
('Mock OCR Result', 0.95)
]
]
]