前段时间,OpenAI 为展示开源诚意,公开了 GPT-oss 的全部模型参数 。结果没想到,这件事反倒像一次"体检报告公开"。一些开发者顺着权重数据深挖,反向分析出了模型训练阶段"吃进去"的各种素材,结论只能说------ OpenAI 中文训练数据,可能比我们想象得还要草台一些。

这件事最早来自今年 9 月 fi-le 的一篇研究《GPT-oss 泄露了哪些 OpenAI 的训练数据》,文章作者用一套开源的分析办法,对 GPT-oss 的权重做了完整扫描:
🔍 第一招:看哪些词"最重"
模型里面每个 token 都有自己的向量权重。哪些词越"重"(L2 Norm 越大),说明模型越容易被它们激活,也意味着训练集中它们出现得越频繁。

结果: 中文里出现了大量离谱词汇,权重比正常词还高。
比如日常词汇 "因此""描述""设置""代码"可以理解,但当分析范围扩展到"非 ASCII 标记"(非英语类 token)后,榜单里开始出现大量"不宜展示"的东西。
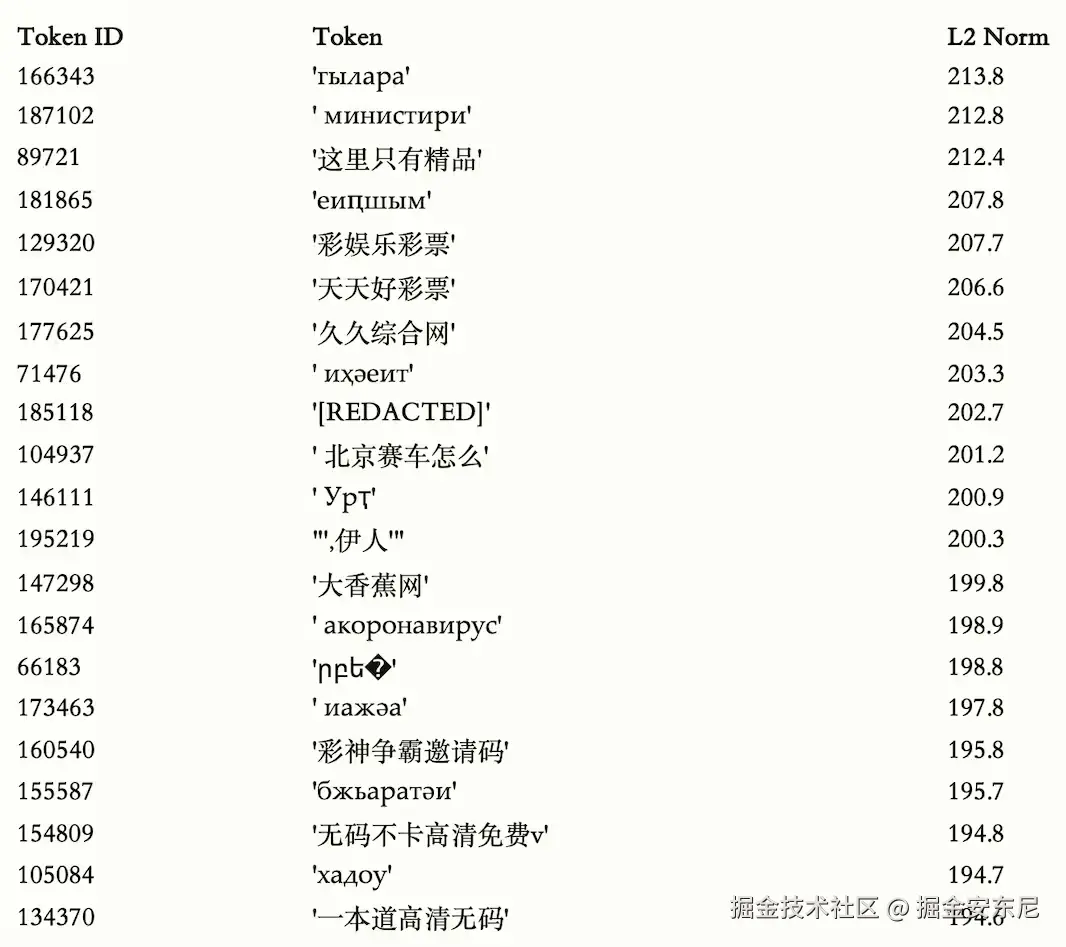
------ 这些并不是大家会正常去讨论的词,却在模型内部占据了"高权重位置"。
这意味着什么?
即便你输入"你好,帮我写个程序",模型依旧要把这些乱七八糟的 token 全部加载参与推理。
是的,它"常驻内存"。
🔍 第二招:直接问模型"你认识这个词吗?"
把一些敏感、广告、网络黑话投给模型,让它解释含义。模型一旦表现出非常"懂",说明这些词可能在训练中多次出现过。

测试中,GPT-5 能明确识别某些中文敏感短语,甚至能拆分出汉字来源,虽然回复时比较克制,但能看出来------ 这些词至少在训练集中出现过。
这种方法在机器学习里叫 Membership Inference,俗称"顺着反应推语料"。
🔍 第三招:做排行榜,看类别
研究者把模型识别特别强的 token 做聚类,结果一分组,大致出现几种类型:
- 一些是正常中文词汇
- 一些是网络热门词
- 更多是:广告词、成人站点名、灰色领域词汇......
尤其是"非 ASCII 高权重 token"榜单,一看真会让人皱眉。
🔍 第四招:让模型玩网络梗 & 怪词
研究者故意丢进去一些无意义网络词、恶搞梗,看模型懂不懂。 结果表明: 有些词模型懂得离谱地多,说明训练数据里出现得不算少。
GPT-4o 曾出现同类迹象

事实上,这已经不是第一次有人质疑 OpenAI 模型的中文语料质量了。早些时候有人分析过 GPT-4o 的数据,也揭示出不少类似情况。
简单来说:
训练数据里混杂了大量不规范、不健康、不适宜出现在大规模通用模型里的东西。
🔬 更进一步:跨模型测试"敏感 token 识别度"
研究者把 GPT-oss、GPT-5、GPT-4o 和 Claude 拿来做对比测试。
方法是把权重最高的 50 个敏感中文 token 输入模型,让它们判断词义及语言类型。
结果非常有趣:
- 有些模型能非常准确识别
- 有些模型直接拒答
- 有些模型干脆说"不认识"
规律是:越容易识别的 token,越可能在训练语料出现得多;且在 GitHub 公共仓库里也更容易搜到对应黑名单记录。
换句话说:AI 的"知识盲区"和"知识污染",都藏在训练数据里。
为什么会这样?
理论上,模型训练会经过权重衰减,不常出现的词本该"弱化"。
但如果某些词在训练集中被反复出现(例如抓取 GitHub / 公网爬虫时混进来的广告、灰产词、垃圾站内容),权重就会被异常放大。
这类中文互联网垃圾内容的比重不算低,因此模型"吃进去多少",几乎决定了它内部记住多少。
而且------越是开源模型,这些痕迹越容易被暴露出来。
DeepSeek 做得不一样
作为对照,DeepSeek 在训练阶段做过明确的"脏数据清洗"策略:
- 过滤成人内容
- 清理广告文本
- 删除灰色信息
- 进行人工审核
- 多级过滤才进入训练集
这也解释了为什么很多人觉得 DeepSeek 的中文输出比海外模型更"干净"、更本土化一些。
🧾 最终结论
- GPT-oss 权重公开后,开发者用反向分析方法挖出了中文训练集中的大量异常 token。
- 高权重敏感词说明:训练数据里确实混入了不少广告词、垃圾内容、灰色站点信息。
- 这些污染可能来自 GitHub 的公开黑名单、爬虫抓取的中文垃圾内容等。
- 多模型对敏感 token 的识别能力差异明显,证明不同模型在数据清洗上采取了不同策略。
- 相比之下,DeepSeek 在中文语料清洗上更严格,也因此更"干净"。