














完整可直接运行的代码:
python
# lora_qwen_train.py
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, Trainer
from peft import LoraConfig, get_peft_model
model_name = "Qwen/Qwen2.5-7B-Instruct"
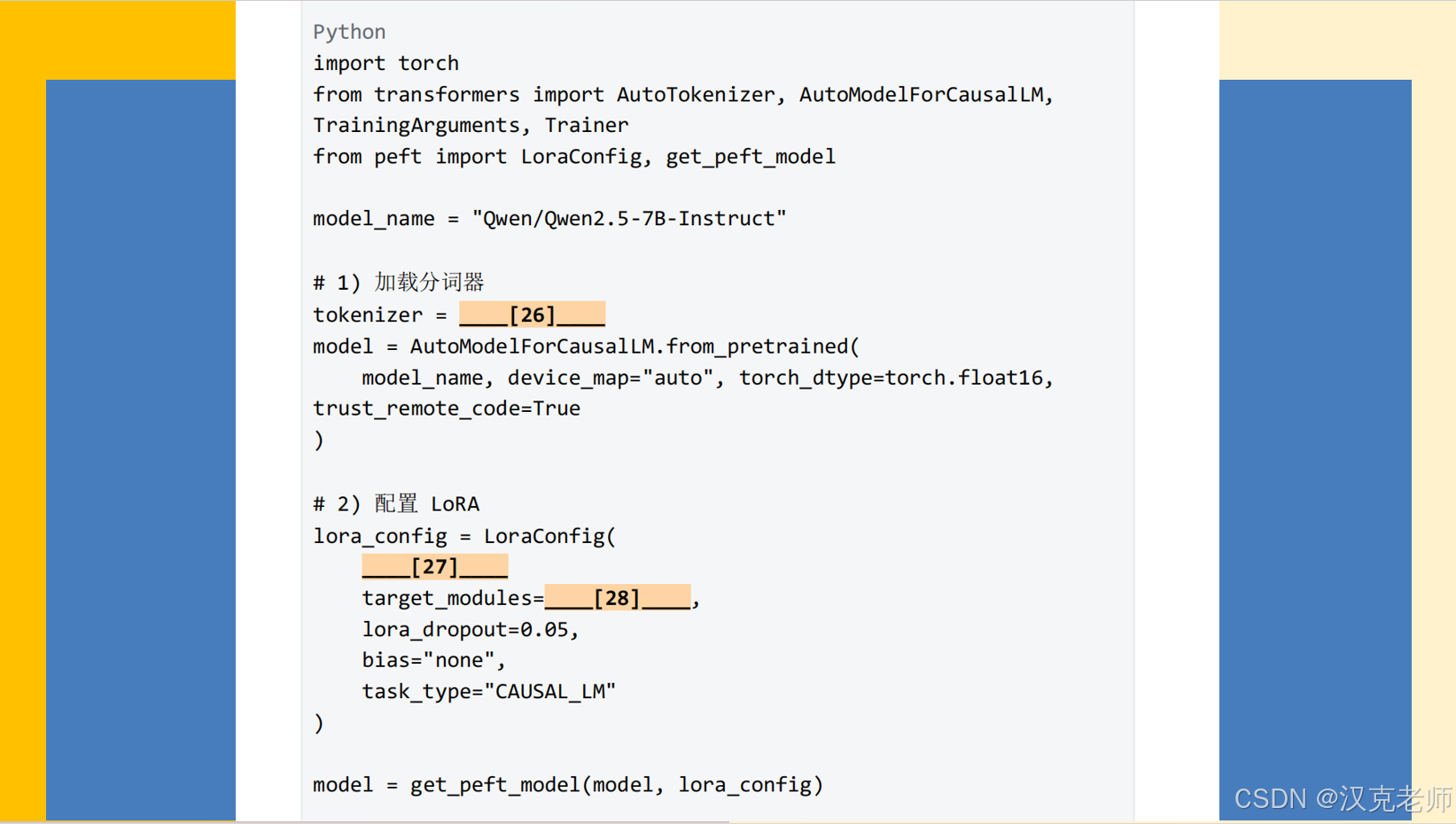
# 1) 加载分词器(允许 remote code,因为 Qwen 可能有自定义 tokenizer)
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
# 2) 加载模型(使用半精度并自动分配设备)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto", # auto device placement(若只用单卡也可以)
torch_dtype=torch.float16, # 以 fp16 加载以节省显存
trust_remote_code=True
)
# 【可选但强烈建议】在注入 LoRA 之前检查模型中可用的模块名,确保 target_modules 名称正确
# 下面会打印出包含 q,k,v,o 的模块名,便于确认实际命名
print("------ 模型中可能的 attention 投影层(部分) ------")
for name, module in model.named_modules():
if any(k in name for k in ["q_proj", "k_proj", "v_proj", "o_proj", "q", "k", "v", "o", "query", "key", "value"]):
print(name)
print("------ 结束 ------")
# 3) 配置 LoRA:在 q_proj 与 v_proj 上注入,r=8, lora_alpha=16
lora_config = LoraConfig(
r=8,
lora_alpha=16,
target_modules=["q_proj", "v_proj"], # <-- 你要求的 target_modules
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
# 把模型包装为 PEFT 模型(会在指定模块处注入低秩适配器)
model = get_peft_model(model, lora_config)
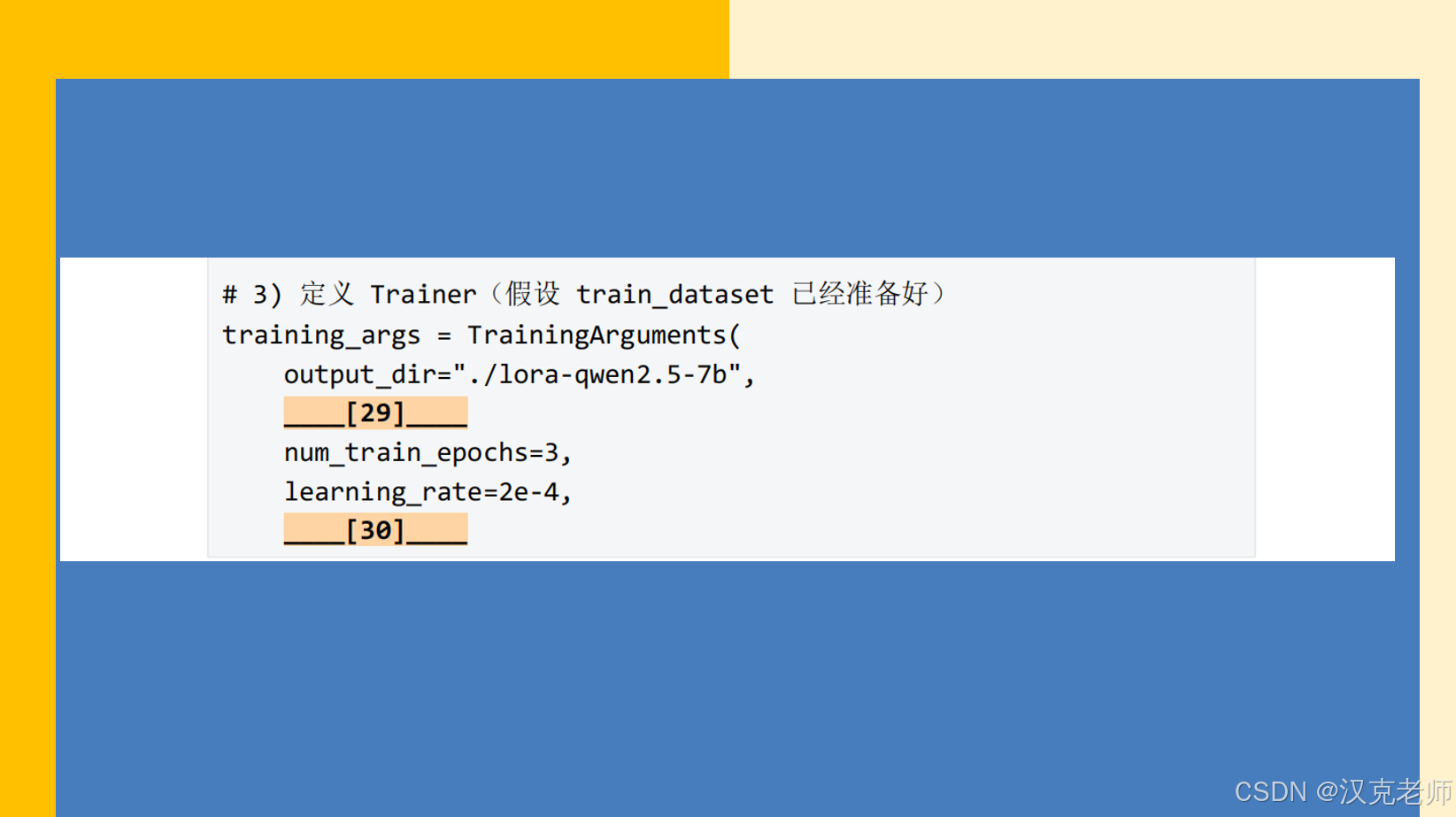
# 4) TrainingArguments(单卡 16GB 情况下稳妥设置)
training_args = TrainingArguments(
output_dir="./lora-qwen2.5-7b",
per_device_train_batch_size=1, # 单卡每 step 1 个样本,降低 OOM 风险
gradient_accumulation_steps=8, # 累积 8 步 -> 有效全局 batch = 8
num_train_epochs=3,
learning_rate=2e-4,
fp16=True, # 启用半精度训练(节省显存)
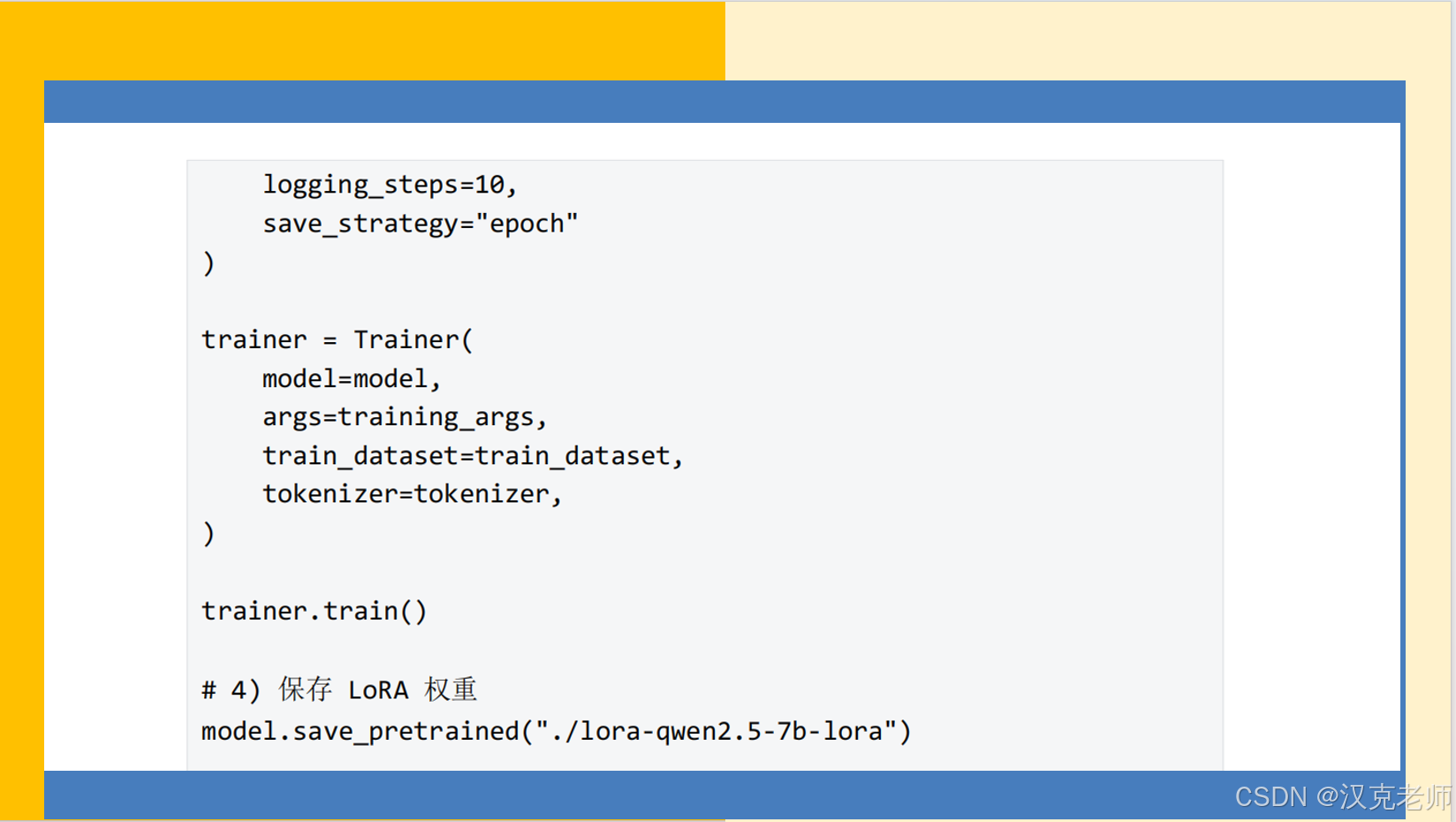
logging_steps=10,
save_strategy="epoch",
# 可根据需要加上以下两个参数以更节省显存或更稳定:
# gradient_checkpointing=True,
# dataloader_pin_memory=True,
)
# 这里假设 train_dataset 已经准备好并是一个继承自 torch.utils.data.Dataset 的对象
# 例如:train_dataset = MyDataset(tokenizer, ...)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset, # 请在运行前把 train_dataset 变量定义好
tokenizer=tokenizer,
)
# 5) 开始训练
trainer.train()
# 6) 只保存 LoRA adapter 权重(PEFT 会只保存 adapter 权重到该目录)
model.save_pretrained("./lora-qwen2.5-7b-lora")
print("LoRA 权重已保存到 ./lora-qwen2.5-7b-lora")注意:本代码依赖 transformers 与 peft,并假定运行环境有支持 fp16 的 GPU(单卡 16GB)。