Cache(高速缓冲存储器)是计算机体系中位于CPU 与主内存(RAM)之间的一种高速小容量存储部件,核心目的是解决 CPU 运算速度与主内存读写速度不匹配的 "速度鸿沟",从而提升整个系统的运行效率。其基本原理围绕 "局部性原理" 展开,并通过高效的映射、替换与写策略实现数据的快速存取。
一、核心前提:局部性原理
Cache 存在的物理基础是程序与数据访问的局部性------CPU 在一段时间内,对内存的访问往往集中在一个较小的 "热点区域",而非随机分散在整个内存空间。这种局部性分为两类:
- 时间局部性:如果一个数据 / 指令被 CPU 访问过,那么它在短期内很可能被再次访问(例如循环代码、频繁使用的变量)。
- 空间局部性:如果一个数据 / 指令被访问,那么它相邻地址的数据 / 指令也很可能被访问(例如数组、连续的代码段)。
Cache 正是利用这一特性,将 CPU 近期可能访问的 "热点数据 / 指令" 从速度较慢的主内存复制到速度极快的 Cache 中。当 CPU 再次访问时,优先从 Cache 读取,避免直接访问主内存,从而节省时间。
二、核心概念:Cache 的 "分层" 与 "命中 / 缺失"
1. Cache 的分层结构
为进一步优化速度与成本的平衡,现代 CPU 通常采用多级 Cache 架构(从 CPU 核心向外,速度递减、容量递增),常见结构为:
- L1 Cache(一级缓存):紧挨着 CPU 核心,容量最小(通常每核心 32KB-128KB),速度最快(延迟仅 1-3 个 CPU 时钟周期),分为 "指令 Cache(L1I)" 和 "数据 Cache(L1D)",分别存储 CPU 待执行的指令和待处理的数据。
- L2 Cache(二级缓存):容量中等(通常每核心 256KB-2MB),速度次之(延迟 5-10 个时钟周期),通常为单个 CPU 核心独享,存储 L1 Cache 无法容纳的 "次热点" 数据 / 指令。
- L3 Cache(三级缓存):容量最大(通常 8MB-128MB),速度相对较慢(延迟 20-40 个时钟周期),多为多个 CPU 核心共享,服务于整个 CPU 的 "全局热点" 数据。
对比参考:主内存(RAM)的延迟通常为 100-200 个时钟周期,速度远低于Cache。
2. 命中与缺失
Cache 的核心性能指标围绕 "是否成功从 Cache 获取数据" 展开:
- Cache 命中(Hit):CPU 请求的数据 / 指令已存在于 Cache 中,直接从 Cache 读取,速度极快。
- Cache 缺失(Miss):CPU 请求的数据 / 指令不在 Cache 中,必须从主内存读取。此时需先将主内存中的 "热点块" 加载到 Cache 中(可能需要替换 Cache 中已有的旧数据),再供 CPU 访问,会产生明显的延迟(称为 "缺失代价")。
Cache 的性能用命中率(Hit Rate) 衡量:命中率 = 命中次数 / 总访问次数。现代 CPU 的 L1 Cache 命中率通常可达 90% 以上,L2/L3 Cache 命中率也在 80%-95% 之间,大幅降低了对主内存的依赖。
三 、cache 和 主存的映射方式
cache 与主存的核心映射方式有三种,核心结论是:直接映射、全相联映射、组相联映射,分别平衡命中率、硬件复杂度和访问速度。
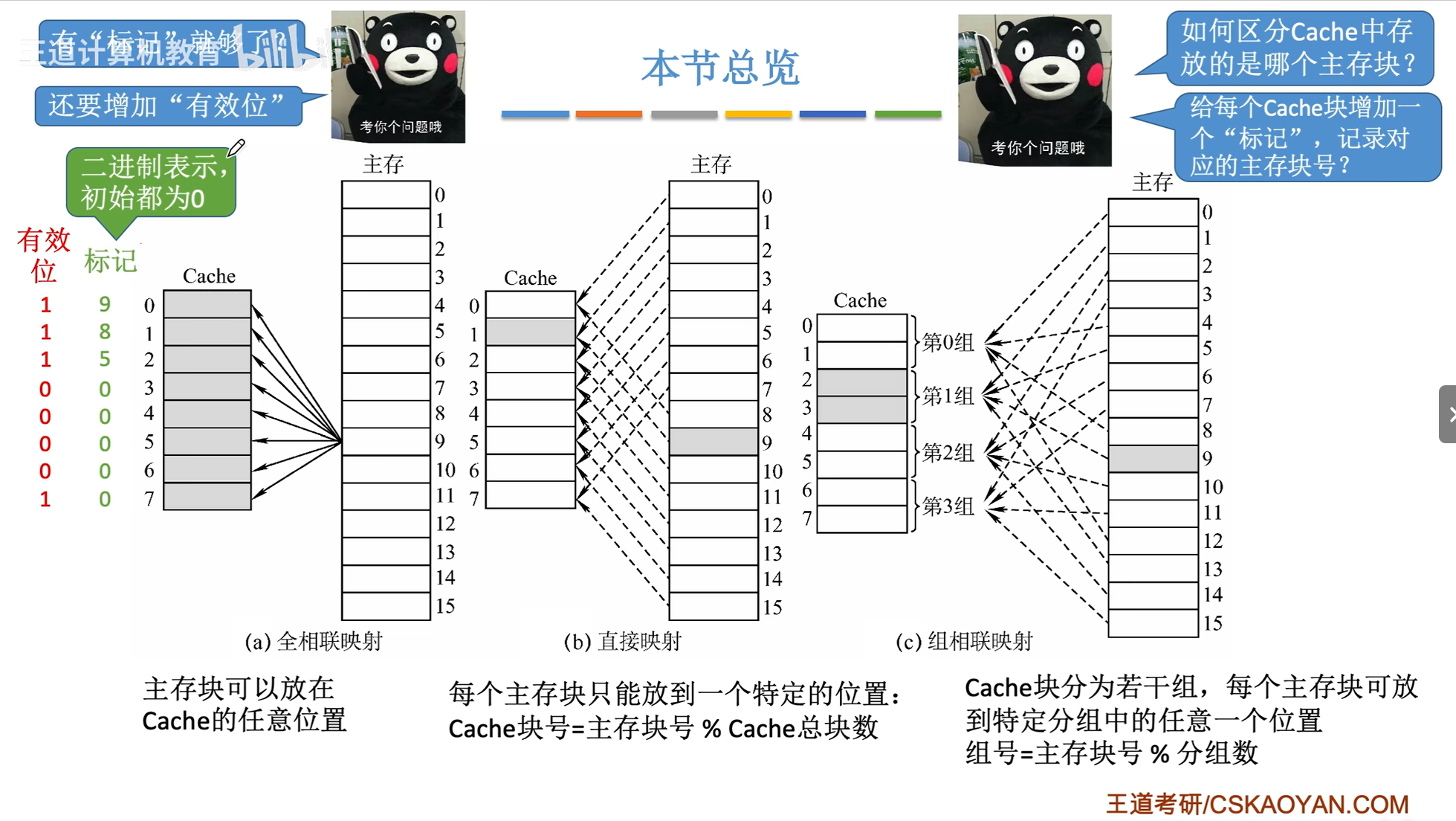
1. 直接映射
- 主存块按固定规则映射到唯一 cache 块,比如主存块号 mod cache 总块数。
- 优点是硬件实现简单、访问速度快,无需复杂比较逻辑。
- 缺点是冲突概率高,多个主存块可能争抢同一 cache 块,命中率较低。
2. 全相联映射
- 主存块可映射到 cache 中任意一块,无固定限制。
- 优点是冲突概率极低,命中率最高,能充分利用 cache 空间。
- 缺点是硬件复杂,需用关联存储器和全比较逻辑,访问速度较慢、成本较高。
3. 组相联映射
- 先将 cache 分组,主存块先映射到指定组(按规则,如主存块号 mod 组数),再可映射到组内任意块。
- 优点是兼顾前两种方式,冲突概率低于直接映射,硬件复杂度低于全相联映射。
- 缺点是性能依赖组大小,组内块数越多(越接近全相联),硬件复杂度越高。
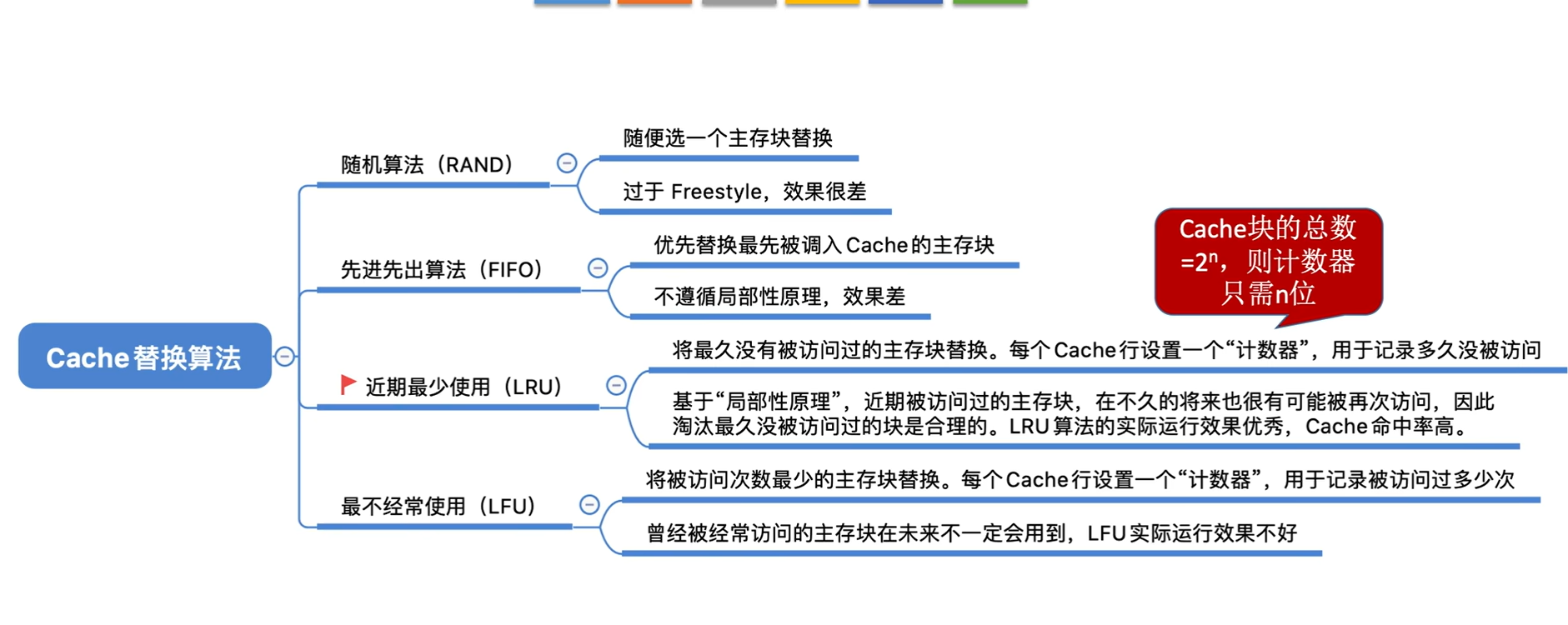
四、cache 替换算法
cache 替换算法的核心是 "当 cache 满时,选择哪个块淘汰以腾出空间",核心结论是:常用经典算法有四种,分别是随机算法、先进先出算法、最近最少使用算法、最不经常使用算法,核心权衡点是命中率、实现复杂度和开销。
1. 随机算法(Random)
- 随机选择一个 cache 块淘汰,无需记录块的使用信息。
- 优点是实现最简单、开销最低,无需额外硬件或软件支持。
- 缺点是命中率最低,可能淘汰刚使用或即将使用的块,性能不稳定。
2. 先进先出算法(FIFO)
- 按块进入 cache 的先后顺序淘汰,先进入的块优先被淘汰。
- 优点是实现简单,只需用队列记录块的进入顺序,开销较低。
- 缺点是未考虑块的实际使用频率,可能淘汰频繁使用的 "老块",命中率中等。
3. 最近最少使用算法(LRU)
- 淘汰最近一段时间内使用次数最少的 cache 块,基于 "近期未用则远期少用" 的假设。
- 优点是命中率高,贴合程序局部性原理,性能最优。
- 缺点是实现复杂,需记录块的使用时序(如用栈、计数器),硬件开销较大。
4. 最不经常使用算法(LFU)
- 淘汰统计周期内使用次数最少的 cache 块,基于 "使用频率低则未来少用" 的假设。
- 优点是考虑了块的使用频率,命中率高于随机和 FIFO 算法。
- 缺点是需统计使用次数,可能淘汰 "曾经高频但近期不用" 的块,且统计开销高于 FIFO。
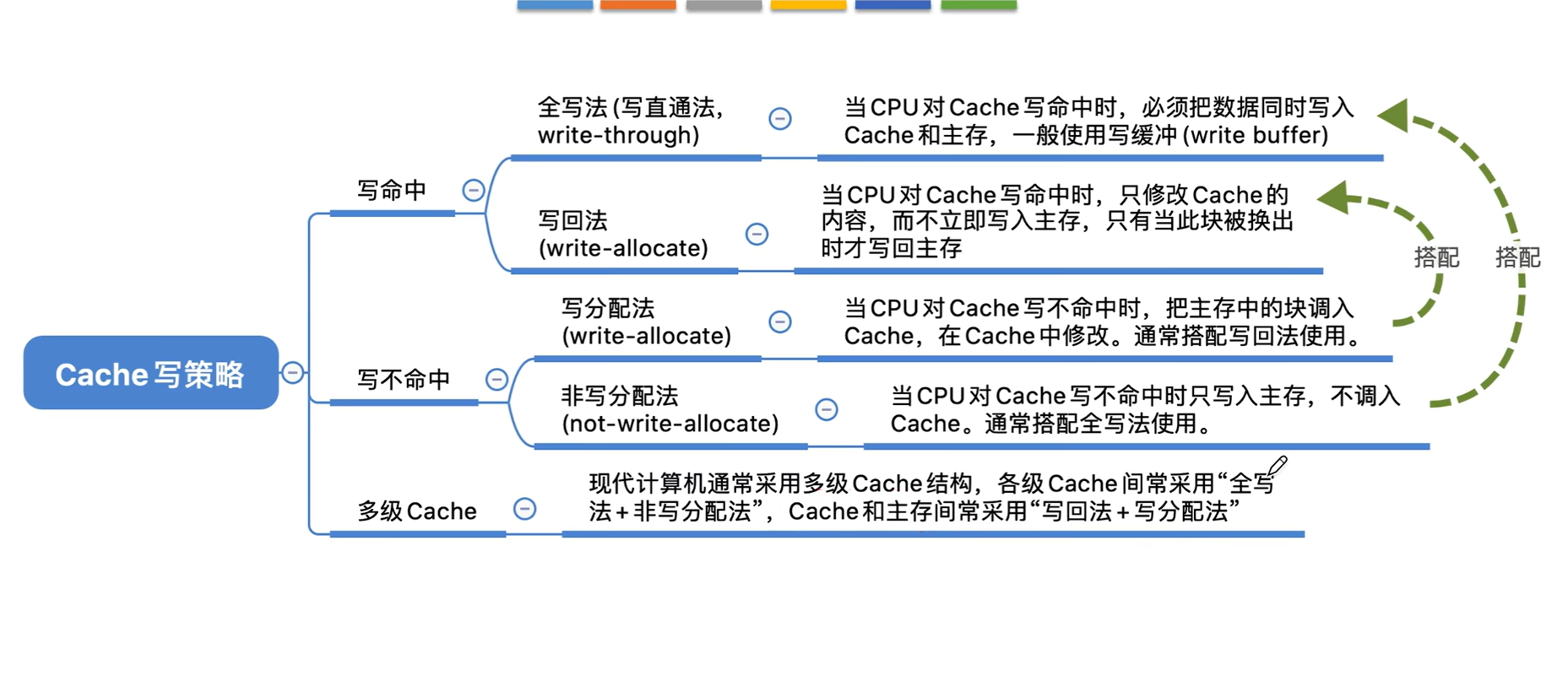
五、cache 写策略
Cache 写策略的核心目标是 解决 "Cache 块更新后,如何同步主存数据" ,核心分为两大方向:写直达(Write-Through) 和 写回(Write-Back),再配合 "写分配(Write-Allocate)" 或 "非写分配(No-Write-Allocate)" 规则,构成完整的写操作逻辑。
一、核心写策略:写直达 vs 写回
这是决定 "数据同步时机" 的核心策略,直接影响性能、总线开销和硬件复杂度。
1. 写直达(Write-Through,WT)
- 核心逻辑 :每次写入 Cache 时,同时将数据写入主存(Cache 和主存始终保持数据一致)。
- 关键规则:若写入的地址已在 Cache 中(写命中):更新 Cache + 同步更新主存;若不在 Cache 中(写缺失):直接写入主存(通常配合 "非写分配",不把主存块调入 Cache)。
- 优点:① 数据一致性好(Cache 和主存始终同步,无需额外同步机制);② 硬件实现简单(无需记录 Cache 块是否 "脏",无额外判断逻辑);③ 崩溃 / 断电时数据不易丢失(主存已实时更新)。
- 缺点:① 总线开销大(每次写操作都要访问主存,主存速度慢,拖慢写性能);② 写延迟高(需等待主存写入完成,才能确认写操作结束)。
2. 写回(Write-Back,WB)
- 核心逻辑 :写入 Cache 时,仅更新 Cache 块,不立即同步主存;只有当该 Cache 块被替换时,才将 "修改过的脏块" 写回主存(未修改的 "干净块" 直接丢弃)。
- 关键规则:需为每个 Cache 块维护一个 "脏位(Dirty Bit)":标记该块是否被修改过;写命中:更新 Cache + 置位脏位(无需访问主存);写缺失:若替换的是脏块,先将脏块写回主存,再调入新块并更新(通常配合 "写分配")。
- 优点:① 总线开销小(仅替换脏块时访问主存,多次写同一 Cache 块只需一次主存操作);② 写延迟低(仅操作 Cache,无需等待主存);③ 适配程序 "写局部性"(频繁写同一数据时性能优势极大)。
- 缺点:① 硬件复杂度高(需维护脏位、设计脏块替换逻辑);② 数据一致性差(Cache 和主存可能不同步,需额外机制处理多处理器 / 多 Cache 场景);③ 崩溃 / 断电风险(未写回主存的脏块数据会丢失,需配合缓存保护机制)。
二、辅助规则:写分配 vs 非写分配
写策略需搭配 "是否将缺失的主存块调入 Cache" 的规则,仅在 "写缺失" 时生效:
| 规则 | 写分配(Write-Allocate) | 非写分配(No-Write-Allocate) |
|---|---|---|
| 核心逻辑 | 写缺失时,先将主存块调入 Cache,再写入 Cache | 写缺失时,直接写入主存,不将主存块调入 Cache |
| 搭配的核心写策略 | 通常与 "写回" 配合(写回 + 写分配是主流组合) | 通常与 "写直达" 配合(写直达 + 非写分配更合理) |
| 优势 | 利用写局部性(后续写同一数据可命中 Cache) | 减少 Cache 无效占用(避免调入仅写一次的数据) |
| 劣势 | 写缺失时额外增加 "调入 Cache" 的延迟和开销 | 无法利用写局部性(多次写同一数据需反复访问主存) |
三、四种常见写策略组合(工程落地主流方案)
| 组合方式 | 核心逻辑 | 适用场景 | 典型应用 |
|---|---|---|---|
| 写直达 + 非写分配 | 写命中:更新 Cache + 主存;写缺失:直接写主存 | 对一致性要求高、写局部性弱的场景 | 部分嵌入式设备、简单 IO 缓存 |
| 写回 + 写分配 | 写命中:更新 Cache + 置脏位;写缺失:调块入 Cache→更新→替换时写回主存 | 写局部性强、追求高性能的场景(主流选择) | PC、服务器、手机芯片、高端 SoC |
| 写直达 + 写分配 | 写命中:更新 Cache + 主存;写缺失:调块入 Cache→更新 + 主存 | 极少用(兼顾局部性但总线开销仍大) | 特殊工业控制芯片 |
| 写回 + 非写分配 | 写命中:更新 Cache + 置脏位;写缺失:直接写主存 | 极少用(浪费写回的总线优势) | 无主流应用 |
四、核心写策略(写直达 vs 写回)对比表
| 对比维度 | 写直达(Write-Through) | 写回(Write-Back) |
|---|---|---|
| 数据一致性 | 高(Cache 与主存实时同步) | 低(仅脏块替换时同步) |
| 总线开销 | 大(每次写都访问主存) | 小(仅脏块替换时访问主存) |
| 写延迟 | 高(需等待主存写入) | 低(仅操作 Cache) |
| 硬件复杂度 | 低(无需脏位、无复杂替换同步逻辑) | 高(需脏位、脏块写回逻辑) |
| 崩溃数据安全性 | 高(主存已实时更新) | 低(脏块可能丢失) |
| 适配局部性 | 弱(未利用写局部性) | 强(充分利用写局部性) |
| 主流程度 | 非主流(仅简单场景使用) | 主流(绝大多数高性能设备选择) |
总结
- 工程落地首选 写回 + 写分配:平衡性能、总线开销和局部性利用,是 PC、服务器、高端芯片的标准配置;
- 简单场景 / 强一致性需求选 写直达 + 非写分配:牺牲部分性能换低复杂度和高一致性;
- 写策略的核心 trade-off:性能(写回) vs 一致性 / 复杂度(写直达),需结合场景取舍。