参考:https://abdullin.com/ilya/how-to-build-best-rag/
1、比赛题目
任务是根据公司年度报告创建一个问答系统。简而言之,比赛当天的流程如下:
- 你会收到100份随机选择的公司的年度报告,需要在2.5小时内解析这些报告并建立一个数据库。这些报告是PDF格式的,每份报告最多可达1000页。
- 然后,系统会生成 100 个随机问题(基于预定义的模板),你的系统必须尽快回答这些问题。
所有问题都必须有明确的答案,例如:
- 是/否;
- 公司名称(或在某些情况下多个公司名称);
- 领导职位名称、已推出的产品;
- 数值指标:收入、门店数量等。
每个答案都必须包含指向包含答案证据的页面的引用,以确保系统确实得出答案,而不是凭空想象。
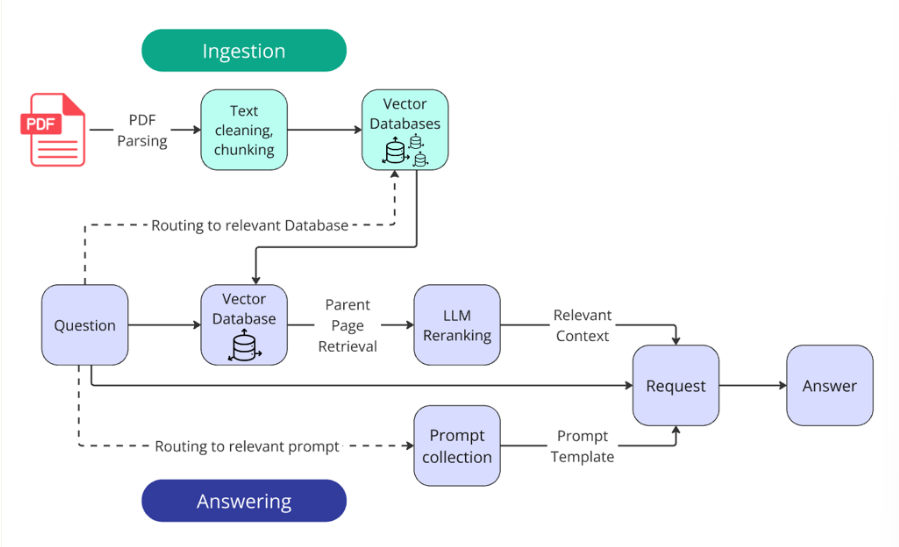
2、系统架构
系统生成的问题和答案:
{
"answers": [
{
"question_text": "For Ziff Davis, Inc., what was the value of Cloud storage capacity (TB) at the end of the period listed in annual report? If data is not available, return 'N/A'.",
"kind": "number",
"value": "N/A",
"references": [],
"reasoning_process": "1. The question is asking for the 'Cloud storage capacity (TB)' for Ziff Davis, Inc. at the end of the reporting period. This metric typically would refer to the total amount of cloud storage provided or used by the company measured in terabytes (TB). 2. I started by examining the provided annual report excerpts to identify any line items or discussions related to 'Cloud storage capacity' or any reference to cloud storage metrics. 3. I carefully reviewed financial statements, segment information, capital expenditure and notes sections from pages 59, 60, 92, 116, 115, 112, 111, 107, and 105 to look for any mention regarding cloud storage or related assets measured in TB. 4. Despite an exhaustive review of all these sections, I did not find any reference or data that correlates with or explicitly states the company's cloud storage capacity. 5. Since the question specifically asks for the value of cloud storage capacity (TB) and the context does not contain this information, I must conclude that the data is not available, leading to the appropriate response being 'N/A'."
},
{
"question_text": "Did Liberty Broadband Corporation announce a share buyback plan in the annual report? If there is no mention, return False.",
"kind": "boolean",
"value": true,
"references": [
{
"pdf_sha1": "446545ae548543d8744f8d885ff75face3424ba4",
"page_index": 88
},
{
"pdf_sha1": "446545ae548543d8744f8d885ff75face3424ba4",
"page_index": 89
},
{
"pdf_sha1": "446545ae548543d8744f8d885ff75face3424ba4",
"page_index": 149
}
],
"reasoning_process": "Step 1: I identified that the question asks whether Liberty Broadband Corporation announced a share buyback plan in its annual report. Step 2: I clarified that a share buyback plan is equivalent to a share repurchase program, where the company commits to buying back its common stock. Step 3: I reviewed the context provided from various pages and found a clear mention on page 89 under the heading 'Purchases of Equity Securities by the Issuer', where the report states that the company had funds available for share repurchases and details specific authorization events for repurchasing Liberty Broadband common stock. Step 4: This information is further supported by additional details in pages 90 and 150 that discuss repurchase activity and the approved share buyback program. Step 5: Based on this evidence, it is clear that the annual report did announce a share buyback plan, reaffirming that the repurchase strategy was an integral part of the financial discussion in the report."
},
.........3、RAG快速指南
RAG(检索增强生成)是一种通过将大型语言模型 (LLM) 与任意规模的知识库集成来扩展其功能的方法。
基本 RAG 系统的开发路径包括以下几个阶段:
- 解析:通过收集文档、将其转换为文本格式并清除无关噪声来准备知识库数据。
- 摄取:创建和填充知识库。
- 检索:构建一个工具,根据用户查询查找并返回相关数据,通常在向量数据库中采用语义搜索。
- 回答:用检索到的数据丰富用户的提示,将其发送到 LLM,并返回最终答案。
3.1解析
要开始填充任何数据库,首先必须将 PDF 文档转换为纯文本。PDF 解析是一项极其复杂的任务,充满了无数微妙的难点:
- 保留表格结构;
- 保留关键格式元素(例如,标题和项目符号列表);
- 识别多列文本;
- 处理图表、图像、公式、页眉/页脚等等。
Rice遇到了一些有趣的 PDF 解析问题(但没有时间解决):
- 大型表格有时会旋转 90 度,导致解析器生成乱码和无法阅读的文本。
- 由图像层和文本层共同构成的图表。
- 有些文档存在字体编码问题:从视觉上看,文本似乎没问题,但尝试复制或解析它会导致出现一组毫无意义的字符。
选择解析器
目前没有任何解析器能够处理所有细微差别,并在不丢失任何重要信息的情况下,将PDF内容完整地以文本形式返回。
RAG挑战赛中表现最佳的解析器是相对知名的Docling,该赛事的组织者之一----IBM----正是它的开发者
解析器定制
尽管 Docling 取得了卓越的成果,但它仍然缺少一些关键功能。这些功能虽然部分存在,但分散在不同的配置中,无法整合在一起。
因此Rice重写了库中的几个方法,解析后得到了包含所有必要元数据的JSON数据,利用这个JSON数据构建一个Markdown文档,其中格式已修正,并且几乎完美地将 PDF 中的表格结构转换为 Markdown 和 HTML 格式,这在后面的应用中发挥了重要作用。
这个库速度很快,但仍然不足以在个人笔记本上满足要求,Rice利用了GPU加速并行解析,解析全部100个文档大约用了40分钟。
国内可以在AutoDL平台上租用显卡:
文本清理和表格准备
目前,我们已经将报告解析为 JSON 格式。填充数据库之前还必须清除文本中的噪声并对表格进行预处理
有时,PDF 文件中的部分文本会被错误解析,包含特定的语法错误,从而降低可读性和意义。Rice使用一组包含十几个正则表达式的程序解决了这个问题。

通过正则表达式模式也检测到了使用上述凯撒密码的文档。Rice尝试解码这些文档,但即使修复后,其中仍然包含许多伪影。因此,Rice直接对解析不良 的文本进行了OCR识别。
表序列化
在大型表格中,指标名称(水平标题)通常距离垂直标题太远,削弱了语义一致性。
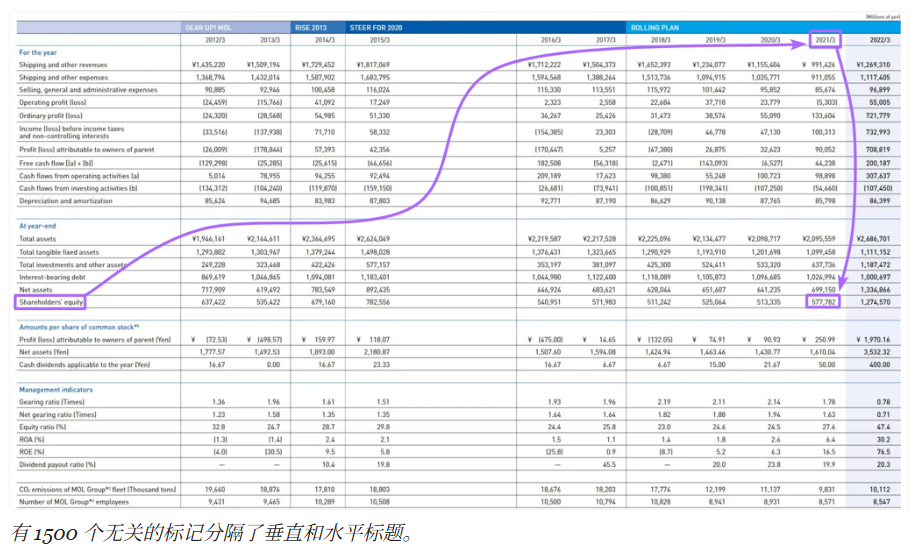
这会显著降低数据块在向量搜索中的相关性(更不用说表格无法完全放入一个数据块的情况了)。此外,LLM 难以将指标名称与大型表格中的表头进行匹配,可能返回错误的值。
表序列化 成了解决方案。参考论文:https://arxiv.org/pdf/2402.17944
序列化的本质是将一个大表转换成一组小的、上下文无关的字符串。
最初,Rice以 Markdown 格式将表格输入到语言模型中,但后来切换到了 HTML 格式(事实证明,HTML 格式的优势就在这里!)。语言模型对 HTML 格式的理解更加透彻,而且 HTML 格式允许描述包含合并单元格、子标题和其他复杂结构的表格
要回答"公司 2021 年的股东权益是多少?"这样的问题,只需向 LLM 提供一句话,而不是一个包含大量"噪音"的大型结构。在序列化过程中,整个表被转换成一组这样的独立数据块:

尽管序列化具有巨大的潜力,但最终的获胜方案并没有使用它。Rice将在文章末尾解释原因。
3.2 摄入
报告已从PDF格式转换为简洁的Markdown文本格式。现在让我们基于这些报告创建数据库。
分块
根据比赛规则,我们必须明确指出包含相关信息的页面。企业系统也采用相同的方法:参考文献可以验证模型的答案并非凭空捏造。
Rice将每页上的文本分成 300 个词元(大约 15 句话)的块。
为了对文本进行切片,Rice使用了带有自定义MD字典的递归分割器。为了避免丢失两个文本块之间的信息,添加了少量的文本重叠(50个词元)。
如果担心重叠无法完全消除因切片不当而带来的风险,可以搜索"语义分割器"。如果计划仅将找到的块插入上下文中,这一点尤为重要。
每个数据块的元数据中都存储着自身的 ID 和父页面编号。
向量化
创建100 个向量数据库,其中 1 个数据库 = 1 个文档。为了创建、存储和搜索矢量数据库,Rice使用了FAISS。
关于矢量数据库格式的一些介绍
数据库是使用该方法创建的 IndexFlatIP 。



扁平索引的优势在于所有向量都"原样"存储,不进行压缩或量化。搜索采用暴力搜索,因此精度更高。缺点是这种搜索方式对计算和内存的需求显著更高。
IP(内积)用于通过余弦相似度计算相关性得分。除了 IP 之外,还有 L2 算法------它通过欧氏距离计算相关性得分。IP 通常能给出更好的相关性评分。
为了将块和查询嵌入到向量表示中,Rice使用了text-embedding-3-large
3.3 检索
以下是Rice在比赛期间探索的一些方法:
混合搜索:vDB + BM25
混合搜索结合了基于语义向量的搜索和传统的基于关键词的文本搜索(BestMatch25)。理论上,它不仅考虑文本的含义,还考虑关键词的精确匹配,从而提高了检索准确率。通常,两种方法的搜索结果会被合并,并根据综合得分重新排序。
交叉编码器重排序
交叉编码器介于嵌入模型(双向编码器)和逻辑线性模型(LLM)之间。与通过向量表示比较文本(这种方法本身会丢失一些信息)不同,交叉编码器直接评估两个文本之间的语义相似性,从而给出更准确的分数。
LLM重新排名
很简单:将文本和问题发送给LLM,然后询问:"这段文本对回答这个问题有帮助吗?有多大帮助?请从0到1评价其相关性。"
与交叉编码器重排序类似,Rice在通过向量搜索进行初始过滤后应用此方法。
Rice制定了一份详细的提示,其中描述了一般准则和明确的相关性标准,以 0.1 为增量:
- 0 = 完全无关:该代码块与查询没有任何联系或关系。
- 0.1 = 几乎不相关:与查询只有非常轻微或模糊的联系。
- 0.2 = 略微相关:包含极其微小或间接的联系。
- ...
校正后的相关性得分采用加权平均值计算:
vector_weight = 0.3, llm_weight = 0.7
重排序Prompt:
class RerankingPrompt:
system_prompt_rerank_single_block = """
You are a RAG (Retrieval-Augmented Generation) retrievals ranker.
You will receive a query and retrieved text block related to that query. Your task is to evaluate and score the block based on its relevance to the query provided.
Instructions:
1. Reasoning:
Analyze the block by identifying key information and how it relates to the query. Consider whether the block provides direct answers, partial insights, or background context relevant to the query. Explain your reasoning in a few sentences, referencing specific elements of the block to justify your evaluation. Avoid assumptions---focus solely on the content provided.
2. Relevance Score (0 to 1, in increments of 0.1):
0 = Completely Irrelevant: The block has no connection or relation to the query.
0.1 = Virtually Irrelevant: Only a very slight or vague connection to the query.
0.2 = Very Slightly Relevant: Contains an extremely minimal or tangential connection.
0.3 = Slightly Relevant: Addresses a very small aspect of the query but lacks substantive detail.
0.4 = Somewhat Relevant: Contains partial information that is somewhat related but not comprehensive.
0.5 = Moderately Relevant: Addresses the query but with limited or partial relevance.
0.6 = Fairly Relevant: Provides relevant information, though lacking depth or specificity.
0.7 = Relevant: Clearly relates to the query, offering substantive but not fully comprehensive information.
0.8 = Very Relevant: Strongly relates to the query and provides significant information.
0.9 = Highly Relevant: Almost completely answers the query with detailed and specific information.
1 = Perfectly Relevant: Directly and comprehensively answers the query with all the necessary specific information.
3. Additional Guidance:
- Objectivity: Evaluate block based only on their content relative to the query.
- Clarity: Be clear and concise in your justifications.
- No assumptions: Do not infer information beyond what's explicitly stated in the block.
"""父页面检索
回答问题所需的核心信息通常集中在一小部分中------这正是将文本分成更小的部分可以提高检索质量的原因。但该页上的其余文本可能仍然包含次要但仍然重要的细节。因此,在找到前 n 个最相关的代码块后,Rice只将它们用作指向完整页面的指针,然后将完整页面添加到上下文中。这正是Rice在每个代码块的元数据中记录页码的原因。
组装检索器
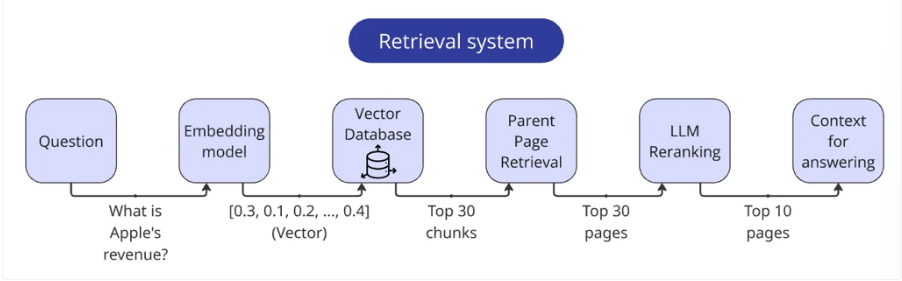
召回步骤:
- 将查询向量化。
- 根据查询向量找出前 30 个最相关的数据块。
- 通过数据块元数据提取页面(记得去重!)。
- 将页面通过LLM重新排序器进行处理。
- 调整页面相关性得分。
- 返回前 10 个页面,在每个页面前面加上页码,并将它们合并成一个字符串。
3.4 增强
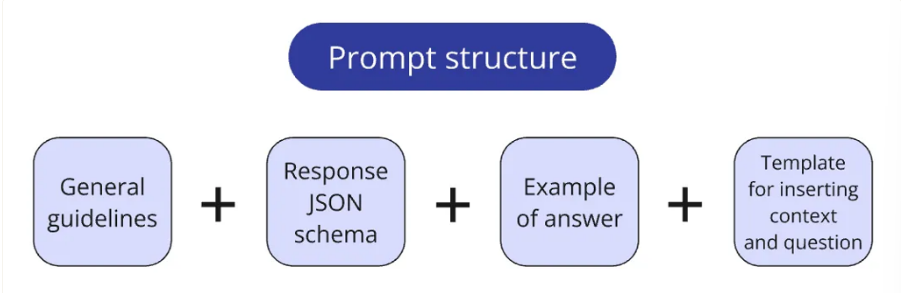
Rice将提示信息存储在一个专用 prompts.py 文件中,通常会将提示信息拆分成逻辑块:
- 核心系统指令;
- Pydantic schema 定义了 LLM 预期响应格式;
- 创建一次性/少量提示的示例问答对;
- 用于插入上下文和查询的模板。
一个小函数会根据需要将这些模块组合成最终的提示配置。这种方法可以灵活地测试不同的提示配置(例如,比较不同示例在一次性提示中的有效性)。
3.5 生成
将查询路由到数据库
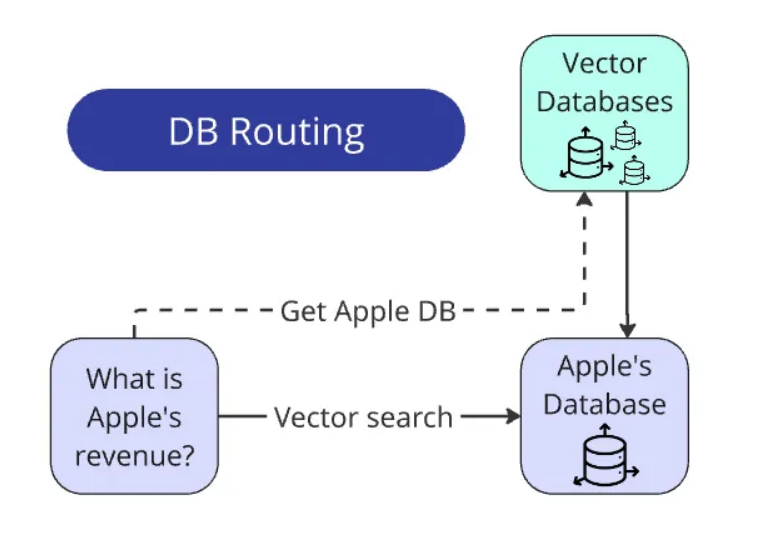
总结起来:
找到名称 → 与数据库匹配 → 仅在该数据库中搜索。搜索范围缩小了 100 倍。
将查询路由到提示符
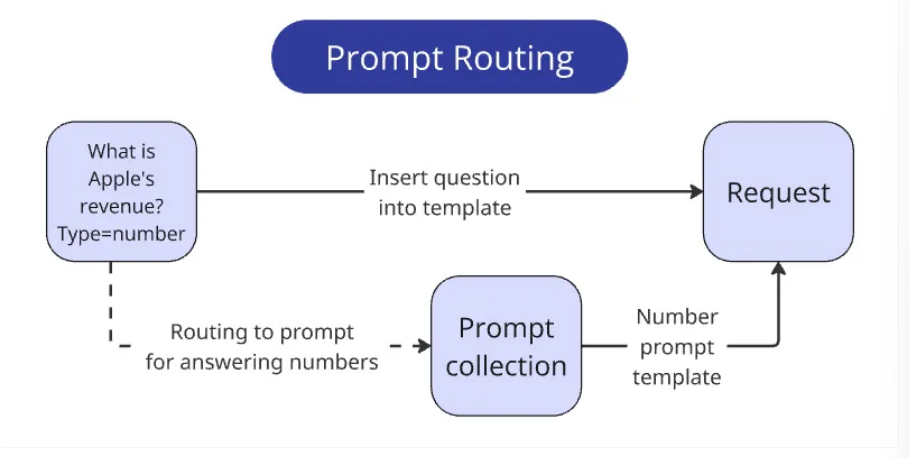
我们应该尽量减少每个查询的规则数量。一种方法是将单个查询拆分成一系列更简单的查询。不过,就我们而言,我们可以实现一个更简单的解决方案------由于明确提供了预期的响应类型,我们只需根据答案类型向提示提供相关的指令集即可。
路由复合查询
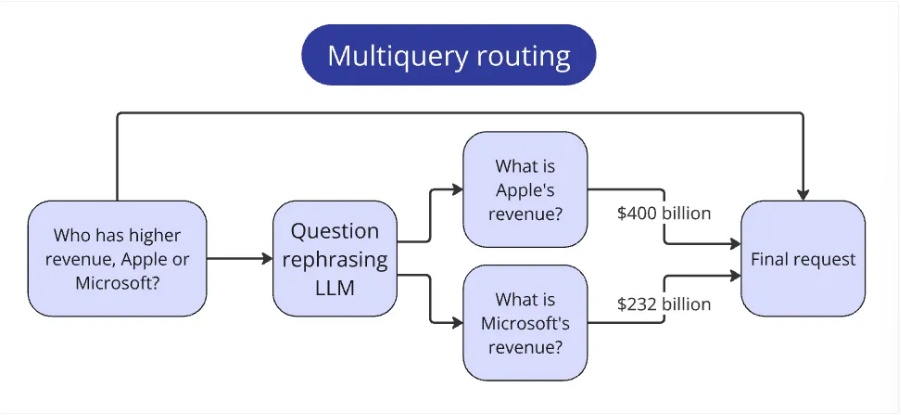
比赛中包含一些需要比较多家公司指标的问题。这类问题不符合其他简单查询的模式,因为它们需要额外的步骤才能回答。
在收集到每家公司的答案后,我们将它们放到上下文中,以回答最初的问题。
思维链
CoT 通过让模型在给出最终答案之前进行"思考过程",显著提高了答案质量。LLM 不会立即给出答案,而是生成一系列中间推理步骤,最终得出解决方案。
Rice特意指示模型专注于评估问题和语境之间指标的兼容性。这显著减少了幻觉的出现。

结构化输出
结构化输出 (SO) 是一种强制模型以严格定义的格式响应的方法。它通常作为单独的参数传递给 API,例如 Pydantic 或 JSON 模式。
这样可以保证模型始终返回严格遵循所提供模式的有效 JSON。

CoT SO
上述方法最好结合起来使用。
Rice用于回答竞赛问题的主要模板只有四个字段:
- 逐步分析 ------初步推理(思路链本身)。
- reasoning_summary --- 前一个字段的简要摘要(以便更容易跟踪模型的逻辑)。
- relevant_pages --- 答案中引用的报告页码。
- final_answer --- 按照比赛要求格式撰写的简洁答案。
前三个字段在所有四个针对不同答案类型的提示中重复使用。第四个字段每次都不同,用于指定答案类型并描述模型需要考虑的特定细微差别。
结构化输出重解析器
并非所有 LLM 都支持结构化输出,而结构化输出能够保证完全符合模式。
如果模型没有专门的结构化输出功能,仍然可以在提示符中直接显示输出模式:
class AnswerSchemaFixPrompt:
system_prompt = """
You are a JSON formatter.
Your task is to format raw LLM response into a valid JSON object.
Your answer should always start with '{' and end with '}'
Your answer should contain only json string, without any preambles, comments, or triple backticks.
"""
user_prompt = """
Here is the system prompt that defines schema of the json object and provides an example of answer with valid schema:
\"\"\"
{system_prompt}
\"\"\"
---
Here is the LLM response that not following the schema and needs to be properly formatted:
\"\"\"
{response}
\"\"\"
"""一次性提示
这是另一种常见且相当显而易见的方法:在提示中添加示例答案对可以提高回答的质量和一致性。
这个例子同时具有多种用途:
- 展现了堪称典范的循序渐进的推理过程。
- 进一步阐明了在复杂情况下的正确行为(有助于重新校准模型的偏差)。
- 说明模型的答案应该遵循的 JSON 结构(对于缺乏原生 SO 支持的模型尤其有用)。
指令改进
分析问题
让我们来看这个例题。 Who is the CEO of ACME inc?
这就引出了一个问题:究竟哪些内容可以归入"CEO"这个范畴?
- 系统应该如何准确理解客户端的问题?
- 客户是想知道担任类似管理职务的人的姓名,还是只想知道该特定职位的名称?
- 稍微偏离字面解释是否可以接受?偏离到什么程度才算过头?

提示创建
指令示例:
答案类型 = 数字


答案类型 = 姓名

系统速度
Rice估算了每个问题的代币消耗量,并以 25 个问题为一批进行处理。系统仅用了 2 分钟就完成了全部 100 个问题。
系统质量
拥有验证集不仅有助于改进提示,而且对整个系统都有益处。
Rice将所有关键功能都设为可配置项,以便衡量它们在实际应用中的影响并微调超参数。以下是一些配置字段示例:

在测试配置时,表格序列化不仅没有提升系统性能,反而略微降低了其效率。显然,Docling 能够很好地解析 PDF 中的表格,检索器也能有效地找到它们,LLM 也无需额外辅助就能充分理解它们的结构。而向页面添加更多文本只会降低信噪比。
4. 结论
成功的关键因素包括高质量的解析、高效的检索、智能的路由,以及------尤其值得一提的是------LLM 重排序和精心设计的提示,这些因素使得即使使用精简模型也能取得优异的成绩。
这次比赛的主要收获很简单: RAG 的精髓在于细节。你对任务理解得越透彻,就能越精确地调整流程中的每个组件,即使是最简单的技术也能带来更大的收益。