It's amazing what you can learn if you're not afraid to try.
0. 前言
pi0 和 pi0.5 作为轰动具身智能领域的VLA引世人瞩目,2025.11.17 Physical Intelligence (π)发布了pi*0.6,一经发出,就在社区中引起了广泛关注,VLA+RL 的研究方向也越来越火热,故来拜读一下。
注意 π 0.6 ∗ π_{0.6}^* π0.6∗和pi0.6不能等价。
 论文页
论文页
项目页
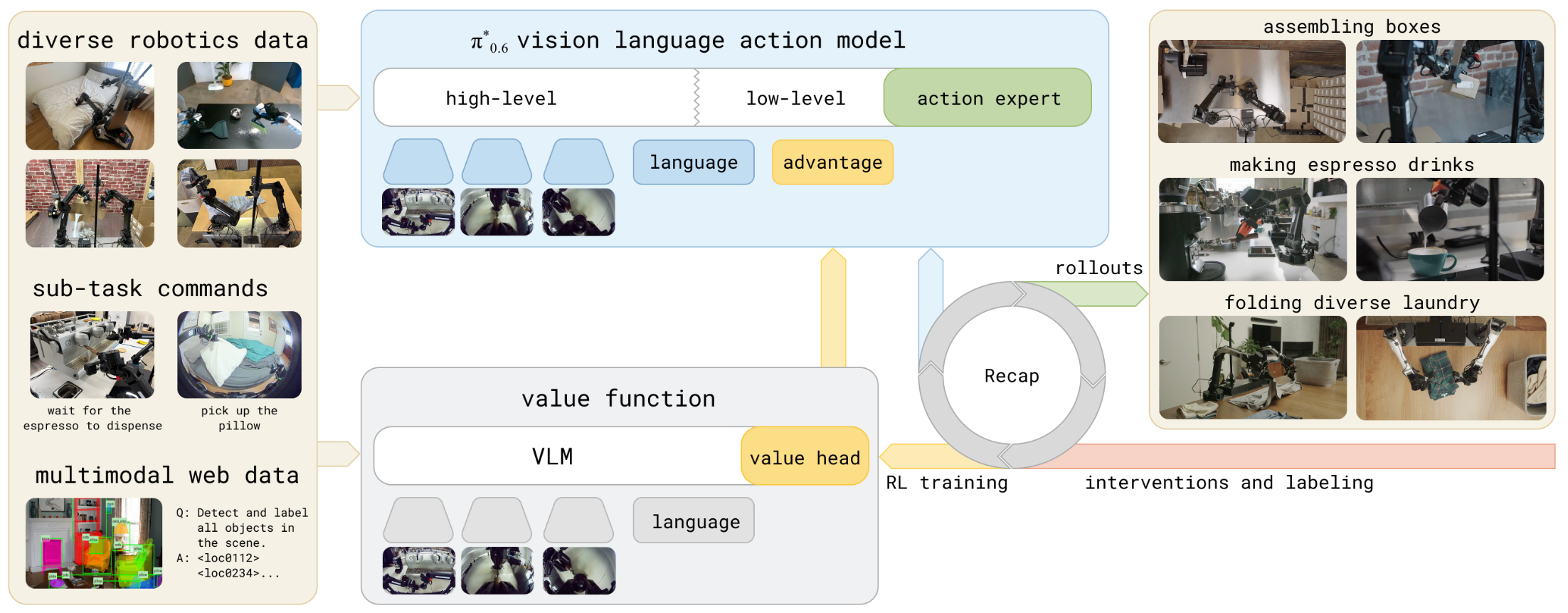
上图一,RECAP(RL with Experience and Corrections via Advantage-conditioned Policies) 使得可以通过奖励反馈与干预 来训练 VLA(vision-language-action)模型。本系统以一个已预训练并包含 advantage conditioning 的 VLA 为起点,这使模型能够从真实世界经验中高效学习。
advantage conditioning:指在策略或行为生成时,将"advantage"信息作为条件输入或控制信号,用以引导模型偏好更高优先级的动作。
针对每个任务,作者部署模型并收集两类数据:自主 rollout(模型自行执行时的轨迹 )和在线的人为修正 (人类在执行过程中给出的即时校正)。随后用这些在线数据对价值函数进行微调 ,从而改进它对动作如何影响任务表现的估计。
对 VLA 基于这些更新后的 advantage 进行微调 并以其为条件化输入,反过来能改进策略(policy)的行为。
过程闭环:在线数据 → 更新 value(得到更准的 advantage)→ 用 advantage 条件化并微调 VLA → 策略表现提升 → 产生更好/更安全的在线数据,如此迭代。
1. 简要介绍和相关工作
1.1 提出问题
熟能生巧:虽然人类在学新技能上极具灵活性,但要达到精通不可避免地需要通过反复尝试 来学习。借助通用机器人基础模型(例如 vision-language-action,简称 VLA),我们可以通过提示(prompts)灵活地为通用机器人指定任务。但和人一样,这些模型也需要练习某项技能才能达到精通。
这意味着不仅要 利用示范数据,还要 利用自主收集的数据------这些数据使策略能纠正在部署中实际犯下的错误、把速度与鲁棒性提升到超过人工遥控(teleoperation)的水平,并适应新的部署条件。
autonomously collected experiential data(自主收集数据):模型自主执行时产生的数据,可用于发现真实部署中出现的问题与分布漂移。
通过自主练习学习的基础------即用强化学习(RL)形式化的方法------几十年来已为人所知,但要把这些原理在通用且可扩展的机器人学习系统中落地仍面临重大挑战:为大模型设计 可扩展且稳定的 RL 方法、处理来自不同策略的异构数据 ,以及在现实世界中基于奖励 反馈开展 RL 训练(现实中的奖励信号可能是模糊或随机的)。
1.2 解决问题
在本文中,提出 RECAP------一种使 VLA 模型在训练流程各阶段 (从预训练到基于自主执行数据的训练)都能纳入奖励反馈的方法。RECAP 旨在通过一种通用的配方来解决这些问题,该配方结合了示范、自动实验和专家干预。
RECAP 从通用 VLA 的训练流程入手,利用来自多种机器人平台的多样数据先用离线 RL 对 VLA 进行预训练 ,然后再对部署过程中收集的数据进行额外训练 。在这些部署期间,机器人会基于每次试验的结果 接收(稀疏的)奖励反馈 ,并可能获得额外的专家干预以纠正错误。
训练流程遵循离线 RL 的范式:训练 一个价值函数来评估实现任务成功的进展 ,然后用该价值函数 来估计数据集中每个动作的 advantage。
通过将策略以基于该 advantage 的改进指标(improvement indicator)为条件化输入 ,我们能够得到改进后的策略。conditioning the policy(条件化策略):把一个关于"是否改进"或"改进程度"的信号作为额外输入(condition)提供给策略网络,使其能在生成动作时考虑该信号。图 1 给出了 RECAP 的高层概览。
可以用 RECAP 来训练用于复杂任务的策略,例如折叠各种衣物、组装纸箱或制作意式咖啡饮品。在图 2 中展示了这些任务的部分示例。
 该方法先在多任务、多机器人且多样化的数据集上,用离线 RL 对 π 0.6 ∗ π_{0.6}^* π0.6∗ 模型进行预训练 。 π 0.6 ∗ π_{0.6}^* π0.6∗是针对 RL 而对 π0.6 模型的改造 ;而 π0.6 相较于 π0.5 有所改进 ,引入了更大的 backbone(主干网络)和更丰富的 conditioning(条件化方式)。
该方法先在多任务、多机器人且多样化的数据集上,用离线 RL 对 π 0.6 ∗ π_{0.6}^* π0.6∗ 模型进行预训练 。 π 0.6 ∗ π_{0.6}^* π0.6∗是针对 RL 而对 π0.6 模型的改造 ;而 π0.6 相较于 π0.5 有所改进 ,引入了更大的 backbone(主干网络)和更丰富的 conditioning(条件化方式)。
π 0.6 ∗ π_{0.6}^* π0.6∗增加了对二值化01 advantage (binarized advantage)进行条件化的能力,这使得可以把价值函数纳入以改进策略。
在预训练之后 , π 0.6 ∗ π_{0.6}^* π0.6∗ 会先用示范数据 对模型在下游任务上进行微调,然后执行一次或多次的机器人在线数据采集 (on-robot data collection),并用这些数据通过 RL 改进模型。
流程是"预训练 → 用示范数据微调 → on-robot 收集数据 → RL 微调(可迭代)"
在自动实验上用 RECAP 训练 π 0.6 ∗ π_{0.6}^* π0.6∗ 在一些最困难的任务上 能将吞吐量提高超过一倍,并可将失败率降低 2 倍或更多。这使得 π 0.6 ∗ π_{0.6}^* π0.6∗ 达到了实用级别的鲁棒性:作者让它连续运行 13 小时 制作意式咖啡、在一个新家中连续两小时不间断 地折叠新类型衣物,并在工厂里组装用于实际包装的纸箱。
尽管 RECAP 基于此前研究中已探讨的若干算法组件,但这些组件的特定组合是新的,而结果首次表明:一种带有人类奖励反馈与干预的通用强化学习配方,结合部署中收集的经验 ,能显著提升 VLA 模型的鲁棒性与吞吐量。
1.3 相关工作
用模仿学习训练的策略 已知会遭遇误差累积 (compounding errors)问题,并且其性能至多只能和示范数据同等 (即不会超越示范质量)。本文目标是通过超越仅从离线示范的模仿学习,提高 vision-language-action(VLA)策略的可靠性与速度。先前的工作曾使用在线干预来改进机器人操控策略。
采用了这类干预的一种形式,称为 human-gated DAgger。与这些工作不同,作者的方法同时利用专家干预和完全自主的经验,从而得到一个整合多种数据源的基于 RL 的框架。
关于用 RL 自主改进机器人操控策略已有大量工作,包括使用基于 diffusion 的策略、在多任务设置中的方法,以及利用预训练多任务策略的研究。与这些工作不同,作者研究如何将现实世界的 RL 扩展到大型 VLA 策略 ,应用于长时域、精细化的操控任务。
近来许多工作研究了如何通过 RL 改进基础 VLA 模型。有些工作直接将 Proximal Policy Optimization(PPO)及其变体应用于 VLA 微调,但这些方法在高效、可扩展地推广到现实世界 RL 时存在困难。
另一类研究在预训练 VLA 之上探索 RL 微调:包括训练 residual policy、微调动作头网络、选择或精炼 VLA 提议的动作,或在 diffusion-based VLA 的噪声空间中优化策略。其中一些工作还探索了将学到的行为蒸馏回 VLA,从而进行端到端的迭代改进。这些先前工作通常使用离散动作或简单的高斯连续动作分布。
一个关键区别 是作者使用(迭代的)离线 RL 对整个 VLA 进行端到端训练 ,采用了富表达力的 flow-matching VLA 模型。这是通过一种简单且可扩展 的 advantage-conditioned 策略提取方法实现的,该方法消除了在大型 VLA 模型上使用策略梯度类目标的大部分复杂性。其实就是通过把 advantage 作为条件输入 来提取或构造改进后的策略,绕开了直接对大模型做策略梯度更新(后者在大模型上计算与稳定性上更困难)。
在比较实验中,表明该方法显著优于更传统的基于策略梯度的提取方案。在方法论上与 RECAP 更接近的是,一些先前工作已将价值函数与 VLA 的端到端 RL 在真实机器人上结合起来。例如,Huang 等人将经校准的 Q-learning 应用于抓取任务的离线示范数据集,但没有进行在线改进阶段。Zhang 等人使用直接偏好优化(DPO)从人类偏好中优化搬取放置技能,过程中使用来自 VLA 的在线 rollouts。最后,Zhai 等人和 Ghasemipour 等人分别用 PPO 和 REINFORCE,结合"完成所需时间(time-to-completion)"的价值函数来训练 VLA,处理的任务包括移动碗、展开垫子和在桌面上推动物体等。
与这些先前工作相比,作者描述了一个带有多重优点的迭代式离线 RL 框架用于 VLA。
- 首先,作者的方法支持高容量的 diffusion 与 flow-based VLA ,不同于 先前研究中使用的离散动作模型。
- 其次,通过 advantage conditioning 的策略提取避免了对 on-policy PPO 或 REINFORCE 的需求,该方法可以利用所有先前的(off-policy 或离线)数据。
- 最后,作者的评估包含复杂、灵巧且时间跨度较长的任务;在这些任务上作者的方法能在处理可变形物体、液体与多阶段任务时将吞吐量提升约 2 倍。
先前的工作探索了以奖励、价值与 advantage 为条件来条件化策略的想法,其中也包括使用 classifier-free guidance 的方法。作者将该思路扩展用于预训练与微调大规模通用 VLA 策略,整合多种数据来源(包括示范、干预与自主 roll-outs)以学习真实机器人操控任务。近来的研究也探讨了如何有效训练多任务、语言条件化的奖励函数与价值函数。
基于这些工作,作者还训练了一个语言条件化的分布式(distributional)价值函数 ,从而能够为 作者的 advantage-conditioned VLA 训练框架估计状态---动作优势(state-action advantages)。
2. 先验知识
2.1 强化学习
考虑标准的 RL 设置:智能体由策略 π ( a t ∣ o t ) π(a_t∣o_t) π(at∣ot) 给出,在观测 o t ∈ O o_t∈O ot∈O 下选择动作 a t a_t at。我们把轨迹定义为 τ = ( o 0 , a 0 , ... , o T ) ∈ O × A × ⋯ × O τ=(o_0,a_0,...,o_T)∈O×A×⋯×O τ=(o0,a0,...,oT)∈O×A×⋯×O。由策略 π ( a t ∣ o t ) π(a_t∣o_t) π(at∣ot) 与随机动力学 p ( o t + 1 ∣ o t , a t ) p(o_t+1∣o_t,a_t) p(ot+1∣ot,at) 导出轨迹分布
ρ π ( τ ) ρ_π(τ) ρπ(τ):
ρ π ( τ ) = p ( o 0 ) ∏ t = 0 T − 1 π ( a t ∣ o t ) p ( o t + 1 ∣ o t , a t ) . \rho_{\pi}(\tau) = p(o_0)\prod_{t=0}^{T-1}\pi(a_t|o_t)\,p(o_{t+1}\mid o_t,a_t). ρπ(τ)=p(o0)t=0∏T−1π(at∣ot)p(ot+1∣ot,at).
奖励函数为 r ( o t , a t ) r(o_t,a_t) r(ot,at)为简写记作 r t r_t rt,其中 r T r_T rT 是终止(terminal)奖励。可以定义(折扣)累计回报或 return 为 R ( τ ) = ∑ t = 0 T r t R(τ)=∑_{t=0}^{T}r_t R(τ)=∑t=0Trt(文中未使用折扣因子,不过可以容易地加入)。
RL 的目标是最大化累计回报,学习使下述目标 J(π) 最大化的策略:
J ( π ) = E τ ∼ ρ π R ( τ ) = E τ ∼ ρ π ∑ t = 0 T r t . J(\pi)=\mathbb{E}{\tau\sim\rho\pi}\bigR(\\tau)\\big=\mathbb{E}{\tau\sim\rho\pi}\Big\\sum_{t=0}\^T r_t\\Big. J(π)=Eτ∼ρπR(τ)=Eτ∼ρπt=0∑Trt.
策略 π 的价值函数定义为:
V π ( o t ) = E τ t + 1 : T ∑ t ′ = t T r t ′ , V^{\pi}(o_t)=\mathbb{E}{\tau{t+1:T}}\Big\\sum_{t'=t}\^T r_{t'}\\Big, Vπ(ot)=Eτt+1:Tt′=t∑Trt′,即从当前观测 o t o_t ot 开始到终止的预期累计回报。
动作的 advantage 可按 n 步估计定义为:
A π ( o t , a t ) = E ρ π ( τ ) ∑ t ′ = t t + N − 1 r t ′ + V π ( o t + N ) − V π ( o t ) . A^{\pi}(o_t,a_t)=\mathbb{E}{\rho{\pi}(\tau)}\Big\\sum_{t'=t}\^{t+N-1} r_{t'} + V\^{\\pi}(o_{t+N})\\Big-V^{\pi}(o_t). Aπ(ot,at)=Eρπ(τ)t′=t∑t+N−1rt′+Vπ(ot+N)−Vπ(ot).
2.2 正则化强化学习
通常不直接最大化 J(π),而是在 RL 中引入正则化,优化在获得高奖励的同时保持与某个参考策略 π r e f π_{ref} πref 的接近。例如,当我们在同一数据上做大量梯度更新时,这点很重要;此时 π r e f π_{ref} πref 通常对应于收集训练数据的行为策略(behavior policy)。
可形式化为下述目标:
J ( π , π ref ) = E τ ∼ ρ π θ ∑ t = 0 γ t r t − β E o ∼ ρ π θ D ( π ( ⋅ ∣ o ) ∥ π ref ( ⋅ ∣ o ) ) , J(\pi,\pi_{\text{ref}})=\mathbb{E}{\tau\sim\rho{\pi_\theta}}\Big\\sum_{t=0}\\gamma\^t r_t\\Big-\beta\;\mathbb{E}{o\sim\rho{\pi_\theta}}\bigD\\big(\\pi(\\cdot\|o)\\Vert\\pi_{\\text{ref}}(\\cdot\|o)\\big)\\big, J(π,πref)=Eτ∼ρπθt=0∑γtrt−βEo∼ρπθD(π(⋅∣o)∥πref(⋅∣o)),其中 D 表示某种散度度量。
当 D 为 KL 散度时,有一条常用结论:最优解满足:
π ^ ( a ∣ o ) ∝ π ref ( a ∣ o ) exp ( A π ref ( o , a ) β ) , \hat{\pi}(a\mid o) \propto \pi_{\text{ref}}(a\mid o)\,\exp\!\big(\tfrac{A^{\pi_{\text{ref}}}(o,a)}{\beta}\big), π^(a∣o)∝πref(a∣o)exp(βAπref(o,a)),这是最大化 J ( π , π r e f ) J(π,π_{ref}) J(π,πref) 的解(β 可视为拉格朗日乘子)。
advantage-conditioned 策略提取方法基于一个相关但不太广为人知的结果:若定义
π ^ ( a ∣ o ) ∝ π ref ( a ∣ o ) p ( I ∣ A π ref ( o , a ) ) β , \hat{\pi}(a\mid o)\propto \pi_{\text{ref}}(a\mid o)\;p\big(I\mid A^{\pi_{\text{ref}}}(o,a)\big)^{\beta}, π^(a∣o)∝πref(a∣o)p(I∣Aπref(o,a))β,其中
p ( I ∣ A π ref ( o , a ) ) = g ( A π ref ( o , a ) ) ∫ g ( A π ref ( o , a ′ ) ) d a ′ p\big(I\mid A^{\pi_{\text{ref}}}(o,a)\big)=\frac{g\big(A^{\pi_{\text{ref}}}(o,a)\big)}{\int g\big(A^{\pi_{\text{ref}}}(o,a')\big)\,da'} p(I∣Aπref(o,a))=∫g(Aπref(o,a′))da′g(Aπref(o,a))是以单调增函数 g 测度动作 a相对于 π r e f π_{ref} πref 是否能带来改进的概率,则 π ^ \hatπ π^ 在性能上保证不劣于 πref,即 J ( π ^ ) ≥ J ( π r e f ) J(\hatπ)≥J(π_{ref}) J(π^)≥J(πref)。
将在第 IV-B 节中利用该性质推导作者的策略提取方法。利用上述定义,可以通过解以下最小化问题将闭式定义的 π ^ \hatπ π^ 转为参数化策略:
min θ E s ∼ ρ π ref KL ( π \^ ∥ π θ ) . \min_{\theta}\;\mathbb{E}{s\sim\rho{\pi_{\text{ref}}}}\big\\operatorname{KL}\\big(\\hat{\\pi}\\,\\Vert\\,\\pi_{\\theta}\\big)\\big. θminEs∼ρπrefKL(π\^∥πθ).
3. 通过基于 advantage 条件化策略的经验与实践进行RL(RECAP)
- 数据采集。在任务上运行 VLA,给每个 episode 标注任务结果 标签(用于决定奖励),并可选地提供人工干预,作为对早期迭代中错误的修正示例。
- 价值函数训练。使用迄今收集的全部数据来训练一个大型的多任务价值函数 ,记作 V π r e f V^{π_{ref}} Vπref,它能检测失败并评估完成任务的预期时间。
- 基于 advantage 的条件化训练。为用此价值函数改进 VLA 策略 ,在 VLA 的前缀中加入一个基于该价值函数导出的最优性指示器 (optimality indicator),即 advantage。这个"advantage-conditioned"配方为在次优数据上从价值函数提取更优策略提供了一种简单且有效的方式。
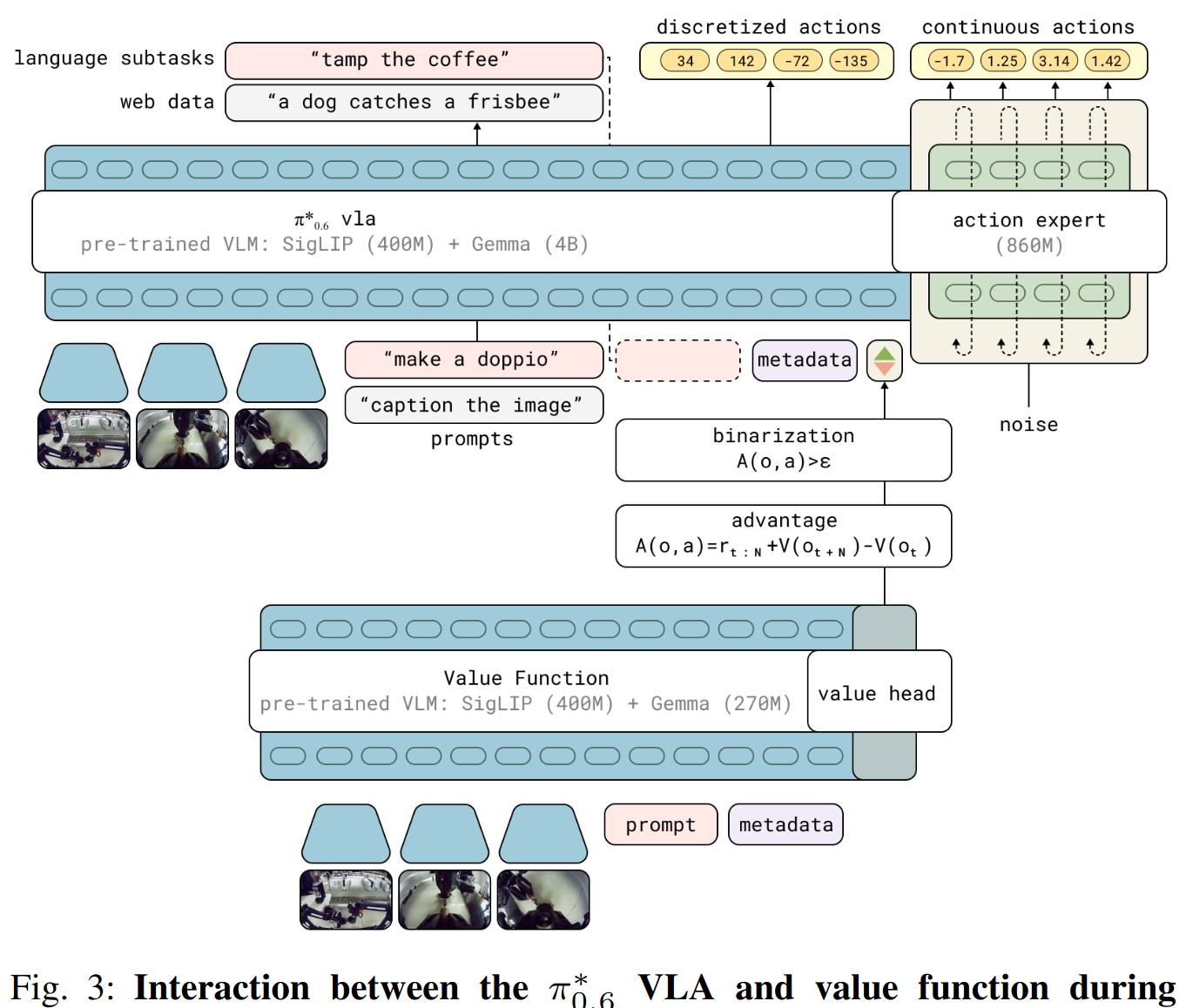
图 1 展示了训练流程的总体结构,图 3 则给出价值函数与策略架构的更详细细节 。作者的预训练阶段在整个预训练数据集 (包含来自众多任务和多种机器人、累计数万小时的示范)上执行上面第(2)和第(3)步。随后我们会执行第(1)(2)(3)步一次或多次,用自主收集的数据进一步改进 VLA。
下面将描述价值函数训练与策略训练步骤 ,并在第 4 节给出针对训练 π 0.6 ∗ π_{0.6}^* π0.6∗ 的具体实现。
3.1 分布式价值函数训练
为了训练一个在预训练或后训练阶段 均能作为可靠 critic 的价值函数 ,作者用一个多任务分布式价值函数 表示 V π r e f V^{π_{ref}} Vπref,记为 p ϕ ( V ∣ o t , ℓ ) ∈ Δ B p_ϕ(V∣o_t,ℓ)∈Δ_B pϕ(V∣ot,ℓ)∈ΔB,它把观测 o t o_t ot 与语言指令 ℓ 映射到 B个离散化价值 bin 上的分布。
在实现中,该价值函数采用与 VLA 策略相同的架构 ,但使用更小的 VLM backbone。
令 R t ( τ ) = ∑ t ′ = t T r t ′ R_t(τ)=∑{t′=t}^{T}r_t^′ Rt(τ)=∑t′=tTrt′ 表示轨迹 τ从时刻 t到结束的经验回报 ,通过先把经验回报 R t ( τ ) R_t(τ) Rt(τ) 离散化为 B=201 个 bins(记作 R t B R_t^B RtB,然后在当前数据集 D 上最小化交叉熵 H 来训练 p ϕ ( V ∣ o t , ℓ ) p_ϕ(V∣o_t,ℓ) pϕ(V∣ot,ℓ):
min ϕ E τ ∈ D ∑ o t ∈ τ H ( R t B ( τ ) , p ϕ ( V ∣ o t , ℓ ) ) . (1) \min{\phi}\;\mathbb{E}_{\tau\in D}\Bigg\\sum_{o_t\\in\\tau} H\\big(R\^B_t(\\tau),\\,p_{\\phi}(V\\mid o_t,\\ell)\\big)\\Bigg. \tag{1} ϕminEτ∈Dot∈τ∑H(RtB(τ),pϕ(V∣ot,ℓ)).(1)
训练目标是把模型预测的回报分布 和轨迹上观测到的离散化经验回报对齐(分类/分布拟合问题)。
这是针对由数据集 D(即行为策略 π r e f π_{ref} πref)表示的策略的一个 Monte Carlo 值函数估计。我们可以从学得的价值分布中提取连续价值函数 (进而计算 advantage),例如:
V π ref ( o t , ℓ ) = ∑ b = 0 B p ϕ ( V = b ∣ o t , ℓ ) v ( b ) , V^{\pi_{\text{ref}}}(o_t,\ell)=\sum_{b=0}^{B} p_{\phi}(V=b\mid o_t,\ell)\;v(b), Vπref(ot,ℓ)=b=0∑Bpϕ(V=b∣ot,ℓ)v(b),
其中 v(b)表示与 bin b 对应的实际数值(value)。
在预训练阶段 ,数据集 D 对应人类示范 ,价值函数捕捉我们条件化(任务与元数据)下的期望回报;在随后的迭代中,该价值函数会偏向示范回报与学得策略回报的加权组合。
虽然这种 on-policy 的估计器不如经典的 off-policy Q 函数估计器最优,但作者发现它简单且高度可靠,同时仍能在模仿学习基础上带来实质性改进。作者的方法可以在未来扩展以兼容 off-policy 估计器。
3.2 通过 advantage conditioning 进行策略提取
一旦得到价值函数 V π r e f V^{π_{ref}} Vπref,我们需要一种方法利用该价值函数训练出改进后的策略------这就是所谓的策略提取。
对我们场景而言,有效的策略提取方法需满足若干标准。
- 其一,能够有效利用多样的 off-policy 数据,包括初始示范、专家干预,以及来自最新和更早策略的自主试验数据(这与离线 RL 面临的挑战密切相关)。
- 其二,方法要可扩展并易于应用于大型 VLA 模型,包含用 flow matching 或 diffusion 生成动作的模型。
- 其三,需能有效利用"好"(近优)与"差"(次优)数据,尤其当我们希望通过自主经验改进策略时这一点至关重要。
在现有的策略提取方法中,策略梯度类方法(包括正则化策略梯度与重参数化梯度)是最常见的,但这些方法难以应用于 flow matching 模型------后者通常没有易计算的对数似然,使得在现代 VLA 架构上扩展变得困难。
另一种选择是加权回归方法(如 AWR),它们隐式地对行为策略做正则化,并使用简单的(重要性加权的)监督学习目标。然而,这类方法会丢弃或显著降权大量数据,实际上实现了一种过滤式模仿。
相反,作者采用 advantage conditioning 的变体:对所有数据做监督训练 ,同时将基于 advantage 的**"动作优劣指示"作为额外输入**。该思路与文献中将策略条件化于轨迹函数的多种方法密切相关。
作者的方法形式上与 CFGRL 最相关。基于第 2 节的推导,可用贝叶斯规则将"策略改进概率"写为
p ( I ∣ A π r e f ( o , a ) ) = π r e f ( a ∣ I , o ) / π r e f ( a ∣ o ) p(I∣A^{π_{ref}}(o,a))=π_{ref}(a∣I,o)/π_{ref}(a∣o) p(I∣Aπref(o,a))=πref(a∣I,o)/πref(a∣o)把语言条件也加入后,得到改进的正则化策略的闭式表达为:
π ^ ( a ∣ o , ℓ ) ∝ π ref ( a ∣ o , ℓ ) ( π ref ( a ∣ I , o , ℓ ) π ref ( a ∣ o , ℓ ) ) β . \hat{\pi}(a\mid o,\ell) \propto \pi_{\text{ref}}(a\mid o,\ell)\left(\frac{\pi_{\text{ref}}(a\mid I,o,\ell)}{\pi_{\text{ref}}(a\mid o,\ell)}\right)^{\beta}. π^(a∣o,ℓ)∝πref(a∣o,ℓ)(πref(a∣o,ℓ)πref(a∣I,o,ℓ))β.当 β=1 时,有 π ^ ( a ∣ o , ℓ ) = π r e f ( a ∣ I , o , ℓ ) \hatπ(a∣o,ℓ)=π_{ref}(a∣I,o,ℓ) π^(a∣o,ℓ)=πref(a∣I,o,ℓ)。因此,如果我们训练策略能够同时表达 π r e f ( a ∣ o , ℓ ) π_{ref}(a∣o,ℓ) πref(a∣o,ℓ) 与 π r e f ( a ∣ I , o , ℓ ) π_{ref}(a∣I,o,ℓ) πref(a∣I,o,ℓ),就可以在不显式建模 p(I∣A)的情况下表示 π ^ \hatπ π^。这一原理类似 classifier-free guidance:训练模型同时能在"有条件"和"无条件"下生成样本。
我们假设改进指示 I 服从一个阈值 delta 分布:
p ( I ∣ A π ref ( o , a , ℓ ) ) = δ ( A π ref ( o , a , ℓ ) > ϵ ℓ ) , p\big(I\mid A^{\pi_{\text{ref}}}(o,a,\ell)\big)=\delta\big(A^{\pi_{\text{ref}}}(o,a,\ell)>\epsilon_\ell\big), p(I∣Aπref(o,a,ℓ))=δ(Aπref(o,a,ℓ)>ϵℓ),
其中 ϵ ℓ ϵ_ℓ ϵℓ 为任务相关的改进阈值。该阈值允许我们控制最优性指示,减少在训练后为锐化改进条件分布而寻找衰减因子 β 的需要。对应的策略目标为最小化以下负对数似然:
min θ E D π ref − log π θ ( a t ∣ o t , ℓ ) − α log π θ ( a t ∣ I t , o t , ℓ ) , (3) \min_{\theta}\; \mathbb{E}{D{\pi_{\text{ref}}}}\Big- \\log \\pi_{\\theta}(a_t\\mid o_t,\\ell) \\;-\\; \\alpha \\log \\pi_{\\theta}(a_t\\mid I_t,o_t,\\ell) \\Big, \tag{3} θminEDπref−logπθ(at∣ot,ℓ)−αlogπθ(at∣It,ot,ℓ),(3)
I t = 1 A π ref ( o t , a t , ℓ ) > ϵ ℓ . I_t = \mathbf{1}{A^{\pi{\text{ref}}}(o_t,a_t,\ell) > \epsilon_\ell}. It=1Aπref(ot,at,ℓ)>ϵℓ.
先用学到的 value 计算 advantage,然后二值化(> ϵℓ 则 It=1),把这个二值指示作为额外条件输入。损失由两部分组成 :普通的负对数似然项 ------ 让模型拟合行为数据(baseline)。加权的条件化项 ------ 强化在"被判为改进"的样本上模型在带条件时的概率;超参数 α控制这部分的权重。
这相当于用监督学习训练策略,但同时教会模型在"优样本"条件下如何更有力地分配概率,从而实现从 value 到 policy 的可扩展提取。
设定 I t = 1 I_t=1 It=1 对专家修正动作强制为正(positive)是合理的假设,因为人工修正通常是优动作,这样能把人类提供的高价值片段放大。
优势值 A π r e f A^{π_{ref}} Aπref来自前面训练得到的价值函数,α 为权衡超参数。实际中,数据集 D π r e f D_{π_{ref}} Dπref 包含迄今为止的所有数据(示范与自主尝试等),因此参考策略 π r e f π_{ref} πref 是人类行为与先前部署策略的混合。为包含人工修正,我们在自主 rollout 中把人工修正提供的动作强制设为 I t I_t It=True(即正样本)。
若假设专家总会提供好的纠正动作,则该选择合理。正如第 4 节所述, VLA 在实际中同时产生离散与连续输出 ,其中连续分布用 flow matching 表示。因此,真实的训练目标会把离散输出的似然项与连续输出的 flow-matching 目标结合起来。
在实践中,先在整个预训练数据集上预训练一个模型 以表示 π θ ( a t ∣ I t , o t , ℓ ) π_θ(a_t∣I_t,o_t,ℓ) πθ(at∣It,ot,ℓ),然后对每个任务执行一次或多次带有 on-policy rollouts(以及可选的专家纠正干预)的迭代更新。
3.3 方法总揽
在算法 1 中给出了完整方法的概览

如本节开头所述,该方法可由三个子例程完整定义:通过自主 rollouts(可选地包含专家纠正干预)收集数据;根据公式(1)训练价值函数;根据公式(3)训练策略。
方法不同步骤之间唯一变化的是每个子例程所用的数据:预训练阶段使用所有先前的示范数据,而针对每个技能 ℓ(i)的专家/专化训练过程会使用额外的自主收集数据。
在实践中,特化模型(specialists)是从预训练模型微调得到的,而最终的通用模型(generalist)则是从头训练的。方法的更多细节载于附录 F。
4. 实现、模型与系统细节
作者用一个称为 π 0.6 ∗ π_{0.6}^* π0.6∗ 的 VLA 来实例化 RECAP。
π 0.6 ∗ π_{0.6}^* π0.6∗ 基于 π0.6 VLA,后者是 π0.5 VLA 的演进版本 5,在 model card 6 中有若干改进细节。 π 0.6 ∗ π_{0.6}^* π0.6∗ 额外加入了对二值化 advantage 指示器 I t I_t It 的条件化能力,使其适合与 RECAP 一起用于 RL 训练。模型架构见图 3。
作者沿用第 3 节的方法,在 VLA 旁边一并训练一个 value function;该 value function 同样由一个 VLM 初始化。用 RECAP 同步训练该 value function 与 VLA 后得到最终的模型,即 π 0.6 ∗ π_{0.6}^* π0.6∗。
本节首先详述模型设计 以及如何把 value function 的 advantage 值接入模型,然后描述 reward 函数与 value 函数,最后展开实现中训练与数据采集的具体流程。
4.1 π 0.6 π_{0.6} π0.6模型
π 0.6 π_{0.6} π0.6模型源自 π 0.5 π_{0.5} π0.5 模型;该模型能够通过 flow matching 灵活地表示分块(chunked)的动作分布,并产生用于高阶策略推理的中间文本(intermediate text)。
它采用 Knowledge Insulation(KI)训练流程:在连续动作与离散化的 tokens(包含通过 FAST 77 离散化的动作)上对整个模型做端到端训练,同时使用 stop-gradient(阻断梯度)机制,防止 flow-matching 的 action expert 影响模型的其余部分。预训练同时使用机器人数据与来自 Web 的视觉-语言共训练数据。
π 0.6 π_{0.6} π0.6 在若干方面优于 π 0.5 π_{0.5} π0.5:
- 预训练数据集扩充了来自多个机器人平台的额外数据;
- 基础 VLM 使用 Gemma3 4B 模型;
- action expert 的参数量增大到 860M。
模型可写作 π θ ( a t : t + H , ℓ ^ ∣ o t , ℓ ) π_θ(a_{t:t+H},\hatℓ∣o_t,ℓ) πθ(at:t+H,ℓ^∣ot,ℓ) 其中 o t = X t 1 , ... , X t n , q t o_t=X_t\^1,...,X_t\^n,q_t ot=Xt1,...,Xtn,qt包含相机图像 X 与机器人状态配置 q,而 ℓ = ℓ t + s ℓ=ℓ_t+s ℓ=ℓt+s 是语言输入,包含总体任务提示 ℓ t ℓ_t ℓt(例如 "make me an espresso")以及额外的语言元数据 s,后者进一步调制任务的执行方式。
模型生成动作块 a t : t + H a_{t:t+H} at:t+H,由关节角与夹爪命令组成,频率为 50 Hz;动作生成由一个独立的 "action expert" 完成------该子网络有专门的权重(860M 参数),用 flow matching 专门训练以生成动作,但它可以 attend(关注/读取)模型其余部分的激活。
模型还生成 tokenized 的离散输出 ℓ ^ \hatℓ ℓ^,其中包含下一个预测子任务的文本表示 (例如 "pick up the coffee cup"),用于高层决策。因为动作在 ℓ ^ \hatℓ ℓ^ 之后生成 ,动作生成实际上以该预测子任务为条件 ,从而获得高层指引。在推理时,子任务预测的频率低于动作生成频率。
在训练过程中,模型还会按 KI 流程用 FAST tokenizer 预测动作块的 tokenized 表示 a t : t + H ℓ a_{t:t+H}^ℓ at:t+Hℓ。把这些离散化动作 记作 a t : t + H ℓ a_{t:t+H}^ℓ at:t+Hℓ。action expert 不把这些 tokenized 作为输入,因此离散动作与连续动作是独立预测的 。最终的训练对数似然为 l o g π θ ( a t : t + H , a t : t + H ℓ , ℓ ^ ∣ o t , ℓ ) log π_θ(a_{t:t+H},a{t:t+H}^ℓ,\hatℓ∣o_t,ℓ) logπθ(at:t+H,at:t+Hℓ,ℓ^∣ot,ℓ)。
由于我们先预测 ℓ ^ \hatℓ ℓ^,因此可以按下式对对数似然进行分解:
log π θ ( a t : t + H , a t : t + H ℓ , ℓ ^ ∣ o t , ℓ ) = log π θ ( ℓ ^ ∣ o t , ℓ ) + log π θ ( a t : t + H ℓ ∣ o t , ℓ , ℓ ^ ) + log π θ ( a t : t + H ∣ o t , ℓ , ℓ ^ ) . \log \pi_{\theta}\big(a_{t:t+H}, a^{\ell}{t:t+H}, \hat{\ell}\mid o_t,\ell\big) = \log \pi{\theta}\big(\hat{\ell}\mid o_t,\ell\big) \;+\; \log \pi_{\theta}\big(a^{\ell}{t:t+H}\mid o_t,\ell,\hat{\ell}\big) \;+\; \log \pi{\theta}\big(a_{t:t+H}\mid o_t,\ell,\hat{\ell}\big). logπθ(at:t+H,at:t+Hℓ,ℓ^∣ot,ℓ)=logπθ(ℓ^∣ot,ℓ)+logπθ(at:t+Hℓ∣ot,ℓ,ℓ^)+logπθ(at:t+H∣ot,ℓ,ℓ^).
4.2 从 π₀.₆ 到带 advantage 条件化的 π*₀.₆
为了把 advantage 信息纳入策略,作者把模型输入扩展 为包含一个额外的改进指示器 (作为额外的文本 输入):当
I t = T r u e I_t=True It=True 时输入 "Advantage: positive",否则输入 "Advantage: negative"。模型其余部分与第 4.1 节描述的 VLA 相同。
优势指示器出现在训练序列中 ℓ ^ \hatℓ ℓ^ 之后 但在(离散化与连续)动作之前,因此只影响动作的对数似然项。这保证高层子任务预测不受 indicator 直接改变,而动作部分会基于该 indicator 调整概率分配,从而实现条件化的策略提取。
连续动作部分的对数似然无法被精确计算,而是通过 flow matching 损失来训练。基于若干假设,flow matching 与 diffusion 有密切对应关系,而 diffusion 可被解释为对数似然的下界,因此我们可以把"离散动作的对数似然"与"连续动作的 flow-matching 损失"之和近似看作整体动作似然的一个下界:
log π θ ( a t : t + H , a t : t + H ℓ ∣ I t , o t , ℓ , ℓ ^ ) ≳ E η , ω log p θ ( a t : t + H ℓ ∣ I t , o t , ℓ , ℓ \^ ) − α η ∥ ω − a t : t + H − f θ ( a t : t + H η , ω , I t , o t , ℓ , ℓ \^ ) ∥ 2 \log \pi_{\theta}(a_{t:t+H}, a^{\ell}{t:t+H}\mid I_t,o_t,\ell,\hat{\ell}) \gtrsim \mathbb{E}{\eta,\omega}\Big \\log p_{\\theta}\\big(a\^{\\ell}_{t:t+H}\\mid I_t,o_t,\\ell,\\hat{\\ell}\\big)-\\alpha_{\\eta}\\big\\\|\\omega - a_{t:t+H} - f_{\\theta}(a\^{\\eta,\\omega}_{t:t+H},I_t,o_t,\\ell,\\hat{\\ell})\\big\\\|\^2 \\Big logπθ(at:t+H,at:t+Hℓ∣It,ot,ℓ,ℓ^)≳Eη,ωlogpθ(at:t+Hℓ∣It,ot,ℓ,ℓ\^)−αη ω−at:t+H−fθ(at:t+Hη,ω,It,ot,ℓ,ℓ\^) 2
其中 a t : t + H η , ω = η a t : t + H + ( 1 − η ) ω a_{t:t+H}^{η,ω}=ηa_{t:t+H}+(1−η)ω at:t+Hη,ω=ηat:t+H+(1−η)ω 是加噪后的动作, ω ∼ N ( 0 , I ) ω∼N(0,I) ω∼N(0,I) 为噪声,η∈0,1 是 flow-matching 的时间索引, f θ f_θ fθ 表示 diffusion/expert 在连续域的输出。 α η α_η αη 是损失加权项(可设为与噪声相关的权重)。损失的完整细节见附录 C。
在训练时,随机缺省(omit)指示 I t I_t It 而不是通过调节损失倍率 α 来实现两种能力:一方面可以直接以 I t = T r u e I_t=True It=True 采样策略(对应于方程 (2) 中设置 β=1),另一方面可以同时得到条件化与无条件(unconditional)模型,从而实现 classifier-free guidance(CFG),在推理阶段可以用放大因子 β>1 来"锐化"改进条件分布。具体细节见附录 E。
4.3 奖励定义与价值函数训练
因为我们的目标是提出一种通用且广泛适用的基于经验训练 VLA 的方法,所以采用了一种几乎可应用于任意任务的一般性稀疏奖励定义。
对每个 episode 获得一个表明该 episode 是否成功的标签。根据该 episode 级别的成功标签来导出奖励,使得价值函数对应于"直到成功所剩步数的(负值)"。把目标定为"尽快完成任务",因此用"剩余步数"的负数作为价值目标(步数越少 → 值越接近 0;失败则给很低的值),本质上把任务效率(time-to-completion)纳入 value 评估。
这等价于下面的奖励函数,其中 T 表示 episode 的最后一步, C f a i l C_{fail} Cfail 是一个较大的常数,用来确保失败的 episode 得到很低的值:
r t = { 0 if t = T and success , − C fail if t = T and failure , − 1 otherwise . (5) r_t = \begin{cases} 0 & \text{if } t = T \text{ and success},\\4pt- C_{\text{fail}} & \text{if } t = T \text{ and failure},\\4pt -1 & \text{otherwise}. \end{cases} \tag{5} rt=⎩ ⎨ ⎧0−Cfail−1if t=T and success,if t=T and failure,otherwise.(5)
用这个奖励函数 ,训练价值函数去预测成功 episode 中 "直到成功还剩的步数的负值",以及对失败 episode 预测一个很大的负数值。实际上我们会把预测值归一化到 (−1,0)区间。
因为训练任务多样,各任务的典型长度差别很大 ,基于每个任务的最大 episode 长度按任务进行值归一化。价值函数的输入与 π 0.6 ∗ π^*_{0.6} π0.6∗ VLA 使用相同的语言输入 ,架构设计也相同 ,但使用较小的 670M 参数的 VLM backbone(同样由 Gemma 3 初始化)(见图 3)
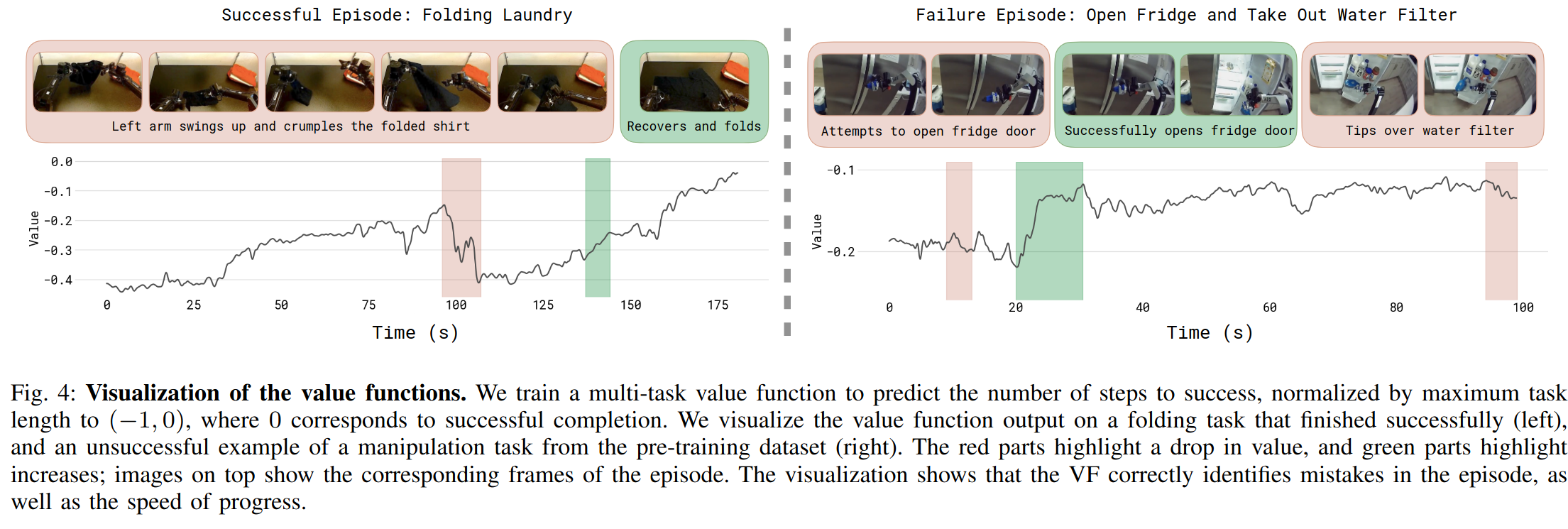
为防止过拟合,还在一个小规模的多模态 Web 数据混合上对价值函数进行共同训练 。图 4 展示了价值函数在一些成功与失败 episode 示例上的可视化,附录 B 的图 13 给出了更多可视化内容。
4.4 预训练、数据采集与基于经验的学习
在预训练阶段 使用的数据混合 大体沿用 π0.5 的配方:包括来自 Web 的视觉---语言数据、子任务 ℓ ^ \hatℓ ℓ^ 的预测,以及来自多种机器人、上面各种任务的低层动作预测数据。作者注意到,预训练后 π 0.6 ∗ π^*_{0.6} π0.6∗ 能执行的任务远不止第 5 节评估中列出的那些。
在预训练期间,先在同一数据集上训练价值函数,目标是预测"直到成功所剩步数的负值"。随后估计每个任务的改进阈值 ϵ ℓ ϵ_ℓ ϵℓ,用于判定基于 advantage 的改进指示器 I t I_t It。将 ϵ ℓ ϵ_ℓ ϵℓ 设为该任务 ℓ ℓ ℓ 的价值函数预测值的 30% 分位点(30th percentile)。
然后在 VLA 训练时对价值函数进行 on-the-fly 推理 ,为每个样本估计 A π r e f ( o t , a t , ℓ ) A^{π_{ref}}(o_t,a_t,ℓ) Aπref(ot,at,ℓ),并据此以 ϵ ℓ ϵ_ℓ ϵℓ 计算 I t I_t It。该指示器按 4 篇(4.1)所述被作为输入添加到 π 0.6 ∗ π^*_{0.6} π0.6∗。
由于作者把价值函数的 VLM backbone 设为相对较小的 670M ,在 VLA 训练期间 对价值函数做 on-the-fly 推理带来的额外开销很小。
在预训练后 ,为目标任务启动策略改进循环。
首先用该任务的示范数据 D ℓ D_ℓ Dℓ 对 π 0.6 ∗ π^*_{0.6} π0.6∗ 做微调 。此阶段把指示器 I t I_t It 固定为 True (作者发现这样能带来略好的结果),因此该阶段相当于监督微调 (SFT)。这样得到初始策略 π ℓ 0 π_ℓ^0 πℓ0,然后用它来收集额外数据 并将其加入 D ℓ D_ℓ Dℓ。
部分 episode 是完全自主采集的 ,部分由专家遥操作监控并在必要时介入提供纠正。这些纠正能教会策略如何避免灾难性失败或如何从错误中恢复。
但需要注意,仅靠这些纠正通常无法解决所有问题:在自主执行中介入是破坏性的事件,且即便是专家也无法保证干预质量一致,也通常不能改进行为的细节方面(例如整体速度)。
人为修正更适合修复较大的错误(recoveries、避免卡死等),但不会自动提升速度、流畅性或是长期稳定性
因此,纠正更主要用于修复大错误与克服探索难题,本身并不能作为最优监督(这与理论上的假设不同)。
回想 3.2 节,对所有人工纠正强制 设 I t = T r u e I_t=True It=True,但除了这一点外,整条 episode(包括自主段与纠正段 )都会被可选地加入数据集 D ℓ D_ℓ Dℓ,无论该 episode 是否包含纠正。
数据收集后,用目前为止为该任务收集的所有数据 对价值函数进行微调 ,然后用更新后的指示器 I t I_t It 来微调策略,流程与预训练阶段相同。
价值函数与策略 均从预训练 checkpoint 开始微调 ,而不是从上一次迭代得到的策略/价值函数继续 微调。作者发现这种做法有助于避免多次迭代中的漂移 ,不过也可能 通过始终从上一次模型继续微调来取得不错的结果。
此过程可按需重复若干次 ,但实践中作者发现即使一次迭代通常也能带来显著改进。
5. 实验评估
在实验评估中,使用 RECAP 对 π0.6 模型进行训练,任务集合包括:制作意式咖啡、折叠各类衣物,以及组装纸箱。
每个任务包含多步操作,时长从 5 到 15 分钟不等 ,涉及复杂操控行为(受限的有力操作、倾倒液体、操纵布料与纸板等),且需要快速执行以实现高吞吐量。在图 5 中示意了实验所用的机器人平台。

5.1 评估任务
定量评估与比较使用三大任务类别及其具体变体:折叠衣物、咖啡制作与纸箱组装。
洗衣(T 恤与短裤)。这是 π0 论文中使用的标准折衣任务:从一个具有随机初始状态的篮子中取出 T 恤或短裤,整理摊平并折叠。成功判定为在 200 秒内将一件衣物正确折叠并堆放在桌子的右上角。
多样衣物折叠任务要求折叠更多种类的衣物 (共 11 种:毛巾、衬衫、毛衣、牛仔裤、T 恤、短裤、POLO 衫、裙子、长袖衬衫、袜子、内衣)。为降低方差,在实验中作者以难度较大的扣子衬衫作为性能评估对象 ,但策略在训练时覆盖全部物品 。成功定义为在 500 秒内把目标物品正确折叠并放到桌上堆里。
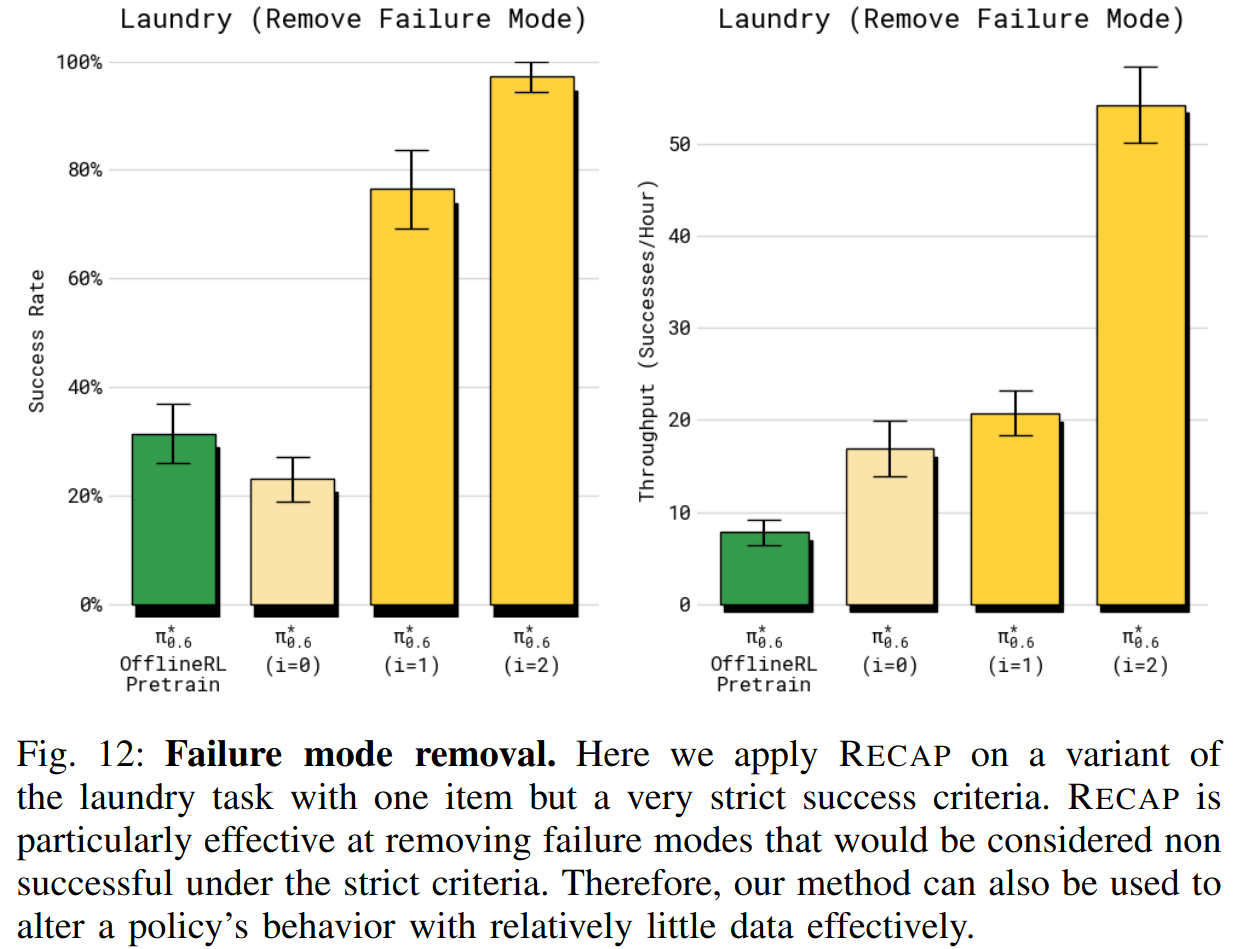
针对性失败消除任务:在一个更结构化的设置中,从固定摊平的初始条件折叠一件橙色 T 恤。成功标准更严格:在 200 秒内正确折叠且衣领始终面朝上。该任务用于评估 RECAP 是否能通过 RL 去除特定的不良行为(在此例中是将衣领朝下放置的习惯性错误)。
咖啡馆任务(双份浓缩):评估在商业咖啡机上制作咖啡的长时任务。尽管策略能做多种饮品并能用毛巾清洁机器,定量实验聚焦双份浓缩任务。流程包括取手柄、上磨豆机研磨、压粉、将手柄锁入咖啡机、放杯、萃取并上杯。成功判定为在 200 秒内完成所有步骤且不出现关键性失误(如掉落手柄或洒出咖啡)。
纸箱组装:在真实工厂部署场景中评估组装包装箱的问题。工作包括从平摊纸板开始折叠纸箱、贴标并将箱子放入指定的箱内。定量实验中我们关注任务的所有子步骤;成功定义为在 600 秒内把纸板从平摊状态变为组装并堆放好的纸箱。
5.2 对比与消融实验
将 RECAP 与若干基线方法进行比较:
- 预训练 π0.5:不使用 RL,也不采用 RECAP(即纯离线/监督基线)。
- 预训练 π0.6:无 advantage 指示 I t I_t It,以监督学习方式预训练。
- RL 预训练的 π 0.6 ∗ π^*_{0.6} π0.6∗ :在预训练阶段即同时用 RL 训练并包含价值函数,且如 4.4 节所述包含 advantage 指示 I t I_t It。
- 离线 RL + SFT:从预训练的 π 0.6 ∗ π^*_{0.6} π0.6∗ checkpoint 出发,用目标任务的示范数据做微调(SFT),在该阶段把 advantage 值对所有示范固定为 True。
- π 0.6 ∗ π^*_{0.6} π0.6∗ 最终模型):使用 RECAP 在目标任务上训练得到,包含自主 rollouts 与专家修正。默认评估时 β=1。在部分实验中也用到 classifier-free guidance(CFG)推理,对应于 β>1。
- AWR:从相同的预训练 π0.6 出发,用 advantage-weighted regression(AWR)微调,权重由本研究的价值函数所提取的 advantage 提供。
- PPO:作者实现了一个 DPPO/FPO 的变体,在单步 diffusion 目标上计算似然,并采用遵循 SPO 83 的替代 PPO 约束定义(具体见附录 D)。
5.3 量化结果
作者在评估中使用两个指标:throughput(吞吐量)和 success rate(成功率)。吞吐量衡量每小时成功完成的任务数 ,因此同时反映速度与成功率 ,是一个实用的复合指标 。成功率衡量成功 episode 的占比 ,由人工标注得出 。评估员会按照多个质量维度判断一次 episode 的表现 ,再将这些质量指标聚合为 一个成功/失败标签。
1)RECAP 对策略的改进有多少?
为回答这个问题,主要定量结果见图 7 和 8。跨所有任务,最终的 π 0.6 ∗ π^*{0.6} π0.6∗ 相较于基线(仅监督的)π0.6、仅 RL 预训练的 π 0.6 ∗ π^*{0.6} π0.6∗ 、以及"离线 RL + SFT" 的 π 0.6 ∗ π^*{0.6} π0.6∗ 都有显著提升。在把 on-robot 数据纳入训练后(即从 offline RL + SFT 到最终 π 0.6 ∗ π^*{0.6} π0.6∗ ),在多样衣物折叠和浓缩咖啡任务上的吞吐量增加超过 2 倍 ,失败率大约降低一半。对于较简单的洗衣任务(T 恤与短裤),SFT 后成功率已接近上限,但最终模型仍显著提高了吞吐量。
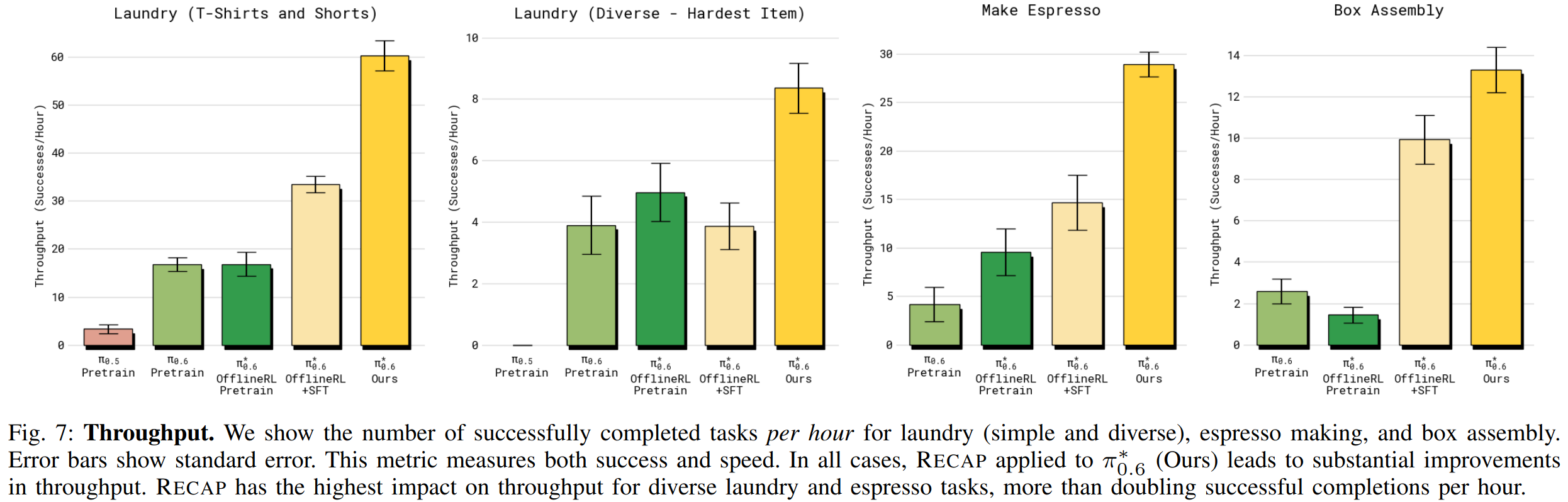 除了多样衣物任务外,最终 π 0.6 ∗ π^*{0.6} π0.6∗ 在所有任务上的成功率都超过 90% 。这使其在实际场景(例如办公室制作咖啡或工厂组装纸箱)中变得可用,如配套视频所示。
除了多样衣物任务外,最终 π 0.6 ∗ π^*{0.6} π0.6∗ 在所有任务上的成功率都超过 90% 。这使其在实际场景(例如办公室制作咖啡或工厂组装纸箱)中变得可用,如配套视频所示。
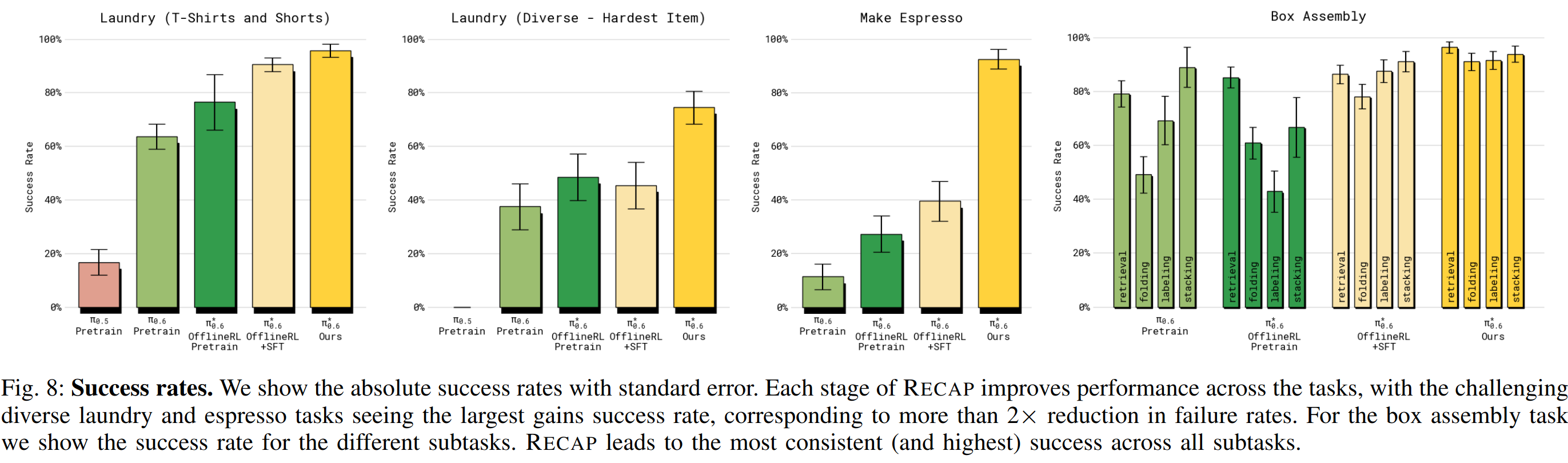 对于纸箱组装任务,图 8(右)给出四个子阶段 的成功率细分:拾取纸板、组装纸箱、贴标签、将箱子放入货箱。与其他模型相比, π 0.6 ∗ π^*{0.6} π0.6∗ 在每个子阶段都取得了更高的成功率 。多数失败是因为策略超时 。配套视频还展示了每个任务连续运行数小时的快进画面。
对于纸箱组装任务,图 8(右)给出四个子阶段 的成功率细分:拾取纸板、组装纸箱、贴标签、将箱子放入货箱。与其他模型相比, π 0.6 ∗ π^*{0.6} π0.6∗ 在每个子阶段都取得了更高的成功率 。多数失败是因为策略超时 。配套视频还展示了每个任务连续运行数小时的快进画面。
2)多次迭代下 RECAP 对 π 0.6 ∗ π^*_{0.6} π0.6∗的改进有多大?
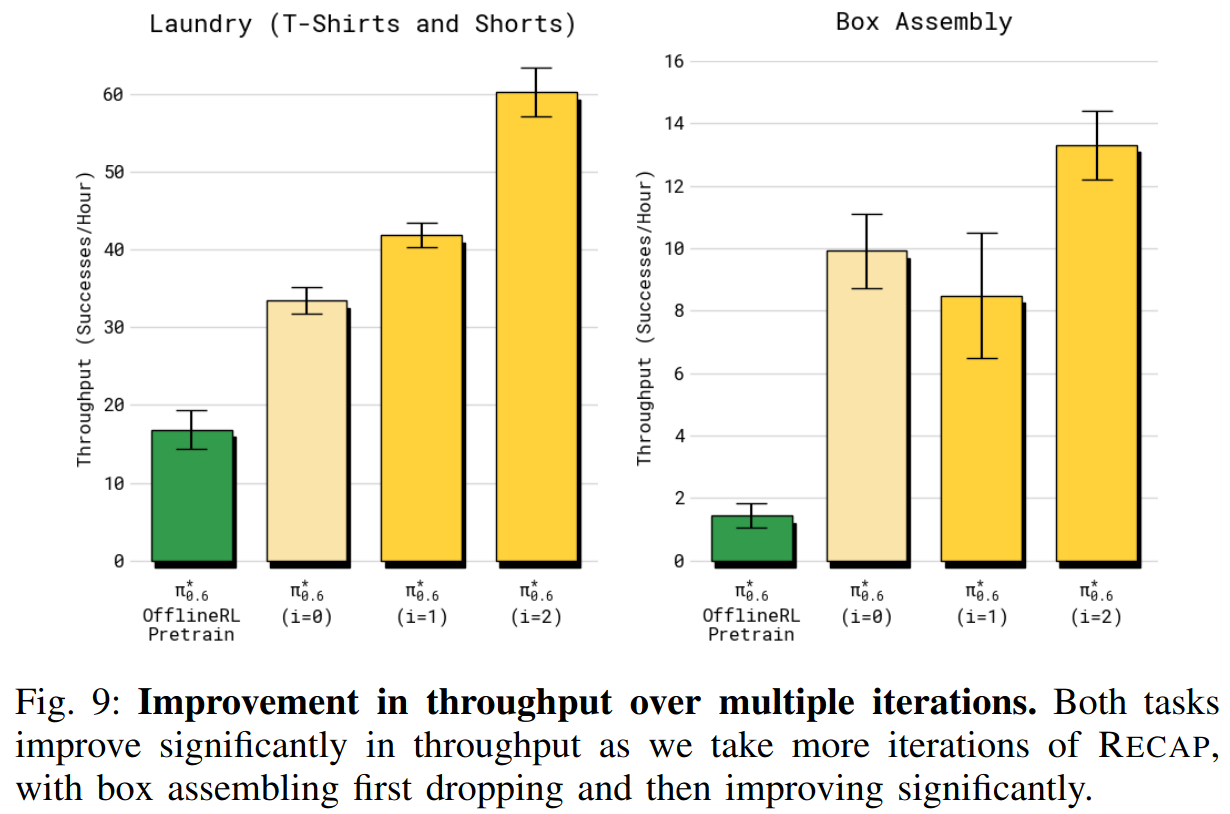
接着说明 RECAP 通过多次数据收集与训练迭代如何改进策略。我们考察 T 恤/短裤折叠任务与纸箱组装任务。
对 T 恤折叠,仅使用自主评估收集的数据(不含人工修正)做两次迭代的策略改进,以评估方法在纯 RL 情况下的效果。每次迭代在四台机器人上各收集 300 条轨迹 。纸箱组装在每次迭代中同时使用 600 条自主试验和 360 条带专家干预的试验。
在图 9 中绘制了随迭代的吞吐量 (i = 1, i = 2)。最终一轮(标为 Ours)对应上一节报告的最佳结果。作者 还与用于初始数据收集的策略 (即离线 RL 预训练的 π 0.6 ∗ π^*{0.6} π0.6∗ 加 SFT)进行了比较。对这两个任务, π 0.6 ∗ π^*{0.6} π0.6∗ 在两次迭代后均有所改进。洗衣任务表现为稳定提升,总体吞吐量提高约 50% 。对长时任务的纸箱组装,需要更多数据才能看到明显提高,但在第二次迭代后吞吐量提高了约 2 倍 。
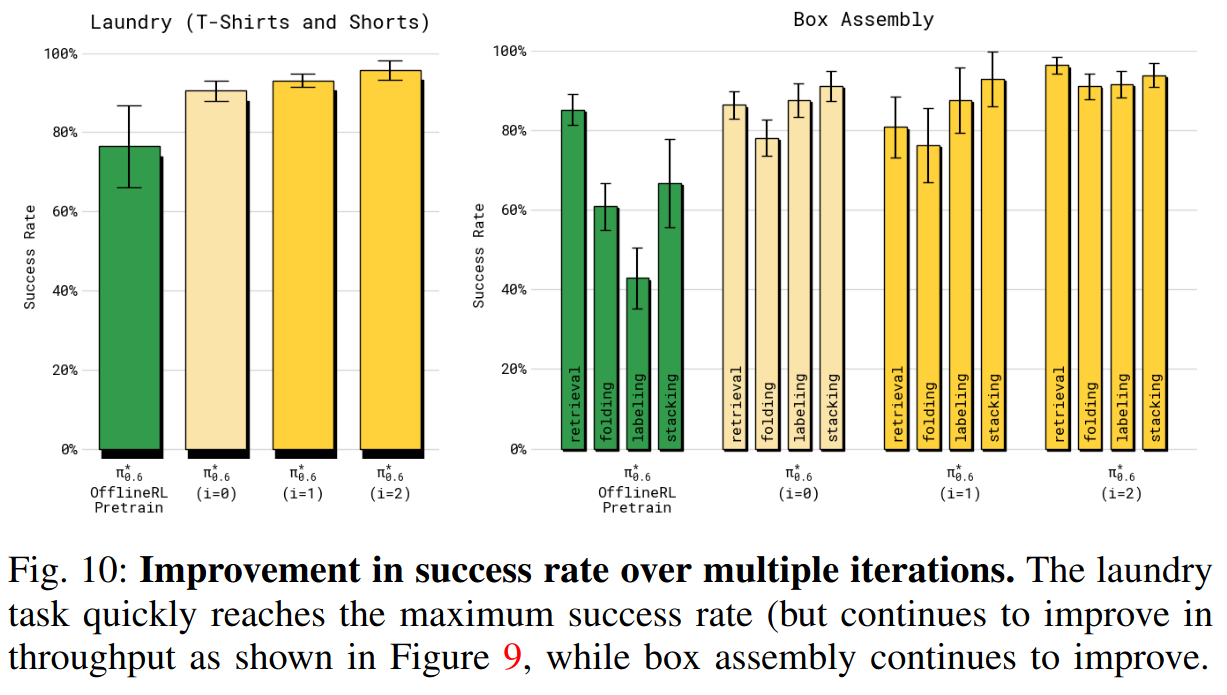
在图 10 中也展示了随迭代的成功率。对洗衣任务,第一轮就把成功率提升到 90% 以上,第二轮主要提升吞吐量 。对纸箱组装,两个迭代都带来了明显的成功率提升。虽然仍有失败(尤其是最后把箱子放到堆里时),最终策略在 600 秒的时限内,对折箱和贴标签两个子任务的成功率都约为 90%。
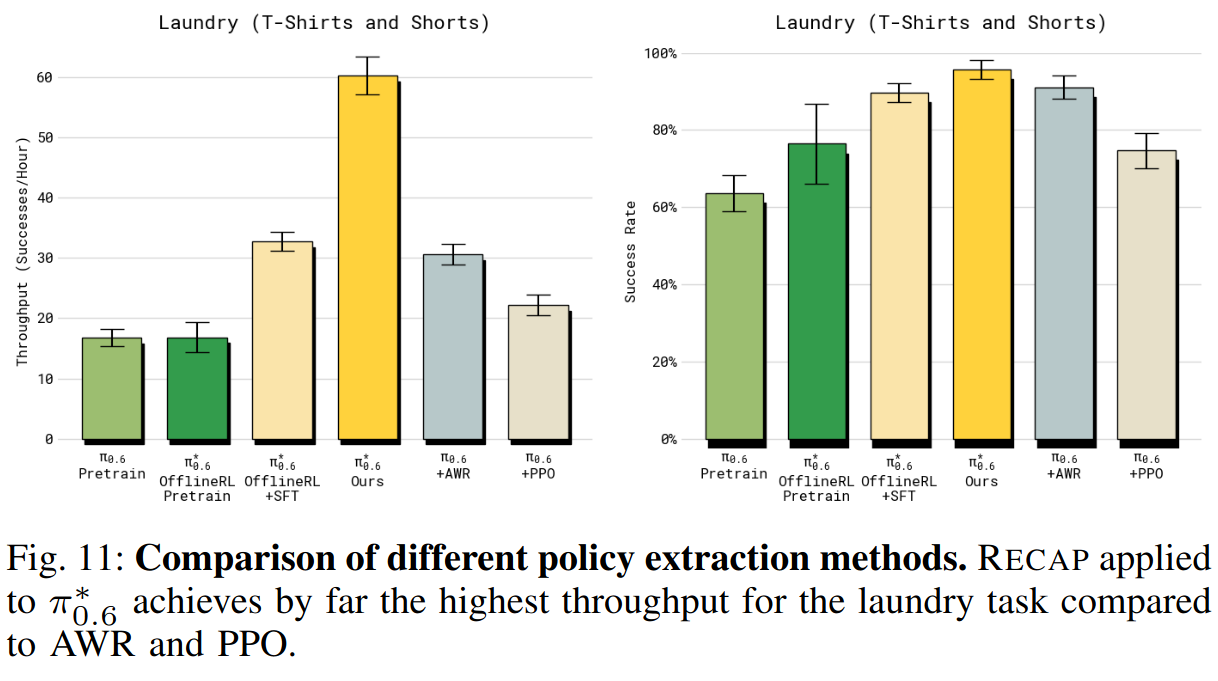
3)RECAP 中的 advantage-conditioned 策略提取与其他方法相比如何?
把 3.2 节中的 advantage-conditioned 提取法与文献中的 AWR 与 PPO 进行比较,使用 T 恤/短裤任务做对照。为保证可控对比,作者为基线使用和最终模型相同的数据------这实际上给基线略微优势(因为这些数据是在运行 RECAP 时收集的)。结果见图 11。AWR 和 PPO 虽能取得合理结果,但都远落后于作者的方法,并且难以超越"离线 RL + SFT"的 π 0.6 ∗ π^*_{0.6} π0.6∗。对 PPO,在此 off-policy 场景中必须使用小的 trust-region 约束(η = 0.01)来稳定训练;虽然这样训练稳定,但性能不佳。AWR 能达到较合理的成功率,但会导致策略执行更慢、吞吐量更低。
4)RECAP 能否用相对较少的数据显著改变策略行为并去除某个失败模式?
在上面的整体评估之外,还针对特定失败模式检验 RECAP 是否能去掉某个错误。作者用一个严格成功判定的洗衣版本------要求把 T 恤折好且衣领居中并朝上------来测试。每次 episode 从一个对 baseline(offline RL + SFT)容易失败的对抗性初始条件开始(把衬衫放平但易导致错误折叠)。如图 12 所示,在该设置下应用 RECAP 两次迭代(每次收集 600 条轨迹)后,策略成功率达到 97%,且速度很快。因此我们得出结论:RECAP 可以在没有任何人工干预或额外示范的情况下,仅通过 RL 就有效去除特定失败模式 。
6. 讨论与未来工作
要训练出在现实任务上能达到人类那样的鲁棒性、速度与流畅性的策略,是机器人学习领域的重大挑战。在本文中,讨论了如何通过经验学习------结合 DAgger 式的人工指导与强化学习------来开始应对这一挑战。
作者提出了 RECAP,一种结合自主试验、奖励反馈与人工干预来训练 VLA 的方法,并展示了用 RECAP 训练得到的模型 π 0.6 ∗ π^*_{0.6} π0.6∗ 在若干现实任务(制作意式咖啡、折叠各类衣物、组装纸箱)上的结果。
RECAP 的核心是一种适合可扩展训练 VLA 策略的 RL 方法 :利用价值函数估计的 advantage conditioning 来做策略提取。
用于该 RL 方法的数据由自主 rollouts 与人工干预组合采集:用人工干预纠正关键错误,同时用自主数据微调行为细节。实验表明 RECAP 能同时提升 VLA 的成功率与吞吐量------在一些更难的任务上吞吐量超过翻倍,失败次数大约减少 2 倍。RECAP 还有若干改进方向。
首先,本系统并非完全自主 :它依赖人工标注与人工付出以获取奖励反馈、提供干预以及进行 episode 重置。已有不少工作探索了自动化这些环节的方法,VLA 提供了新的手段来实现更自动化的数据采集,例如用高层策略去推理并执行场景重置。
其次,在探索策略上相对朴素:探索主要依赖策略的随机性与人工干预来寻找新解。当初始的模仿学习策略已经能采取合理动作时,这种做法是可接受的;但仍有大量改进空间,可以采用更复杂的探索方法。
最后,RECAP 采用迭代"离线"更新 (即收集一批数据、重训练模型、再重复),而非在数据收集时实时更新策略与价值函数的完整在线 RL 循环 。作者出于便利而这样做 ,但把该方法扩展为一个并发的在线 RL 框架是一个有前景的未来工作方向。更广泛地说,用 RL 训练 VLA 或许是实现能满足真实世界应用需求的最直接路径。
在 VLA 上做 RL 面临诸多挑战:包括对高容量模型做大规模 RL 的难度、样本复杂度、自治能力以及延迟反馈等问题。尽管为小规模系统或"虚拟"领域(例如 LLM)设计的现有 RL 框架可以作为良好起点,但要使 RL 成为 VLA 训练中的实用工具仍需更多研究。希望本工作能成为朝这个方向迈出的有意义一步。