在机器学习和深度学习的项目周期中,模型训练只是第一步。要确定一个模型是否真正具备业务价值和可部署性,**基准测试(Benchmarking)**是不可或缺的关键环节。基准测试不仅仅是对准确率(Accuracy)的数字记录,而是一套系统性的方法,旨在全面衡量模型在不同约束条件和实际场景下的表现。
一、测试背景:为何需要基准测试?
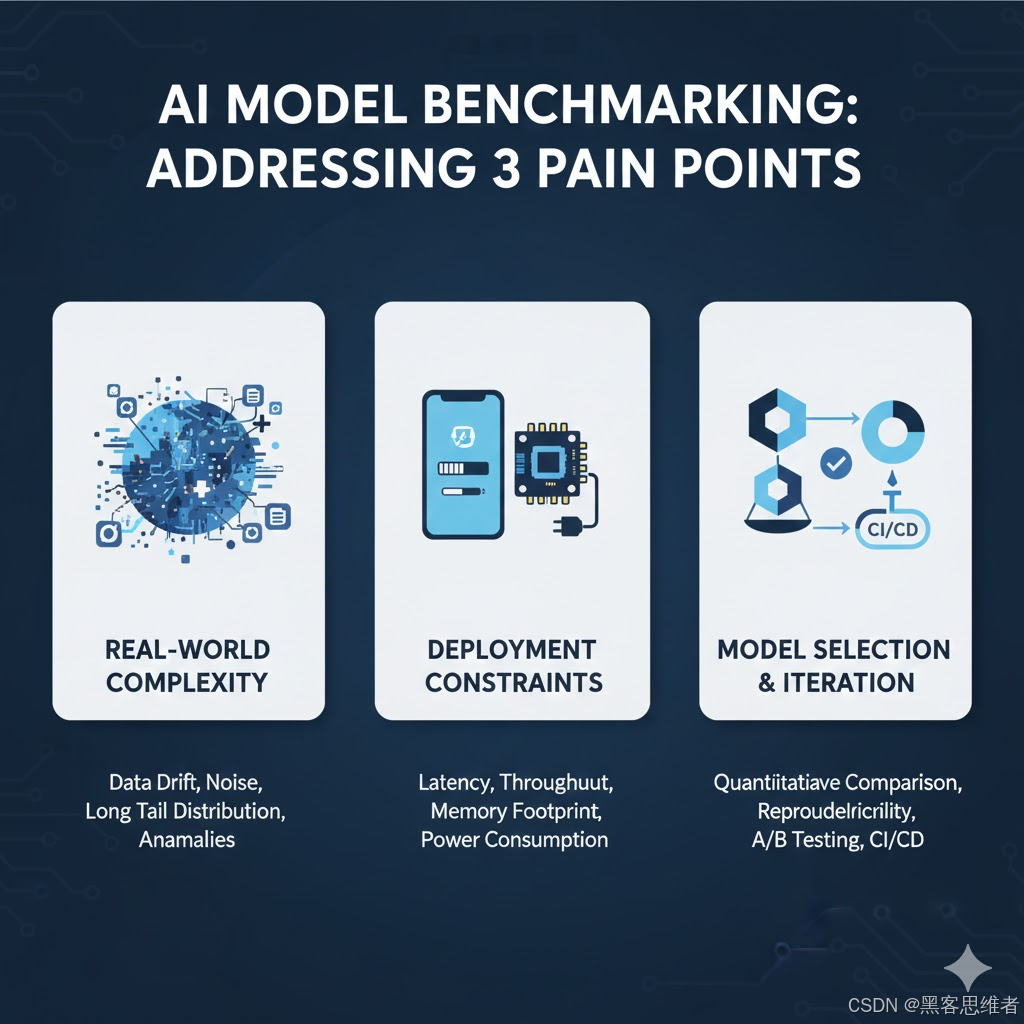
一个模型在训练集上表现优异,并不意味着它能直接投入生产。基准测试的必要性源于以下几个核心痛点:
1. 真实世界的复杂性
训练数据往往是理想化和均衡的。而在真实世界的部署环境中,数据分布可能漂移(Data Drift)、存在长尾效应、包含异常值或受到噪声干扰。基准测试能揭示模型在这些未见数据和非理想条件下的鲁棒性。
2. 部署环境的约束性
模型部署的环境可能是资源受限的边缘设备(如移动端或嵌入式系统),需要考虑延迟(Latency)、吞吐量(Throughput)和内存占用(Memory Footprint)等非功能性指标。高准确率的模型如果推理速度过慢,则没有实际应用价值。
3. 模型选择与迭代的依据
当团队有多个候选模型(如 ResNet-50 vs. EfficientNet-B0)或需要进行持续集成/持续部署(CI/CD)时,基准测试提供了一个客观、量化、可复现的比较标准,为模型选择和版本迭代提供科学依据。
二、测试目标:评估的两大维度
模型评估的基准测试目标可以清晰地划分为两大维度:功能性指标(Functional Metrics)和非功能性指标(Non-functional Metrics)。
1. 功能性指标(性能与精度)
这类指标关注模型学到了什么,以及它解决核心业务问题的能力。
- 准确度(Accuracy / F1-Score / AUC): 根据任务类型选择合适的精度指标,如分类任务侧重 F1-Score 或 AUC,回归任务侧重 RMSE 或 MAE。
- 泛化能力(Generalization): 确保模型在独立于训练集的**验证集(Validation Set)和测试集(Test Set)**上表现稳定。
- 鲁棒性(Robustness): 衡量模型对输入数据中的微小扰动、噪声或缺失值的抵抗能力。例如,通过注入高斯噪声或模拟传感器故障数据进行测试。
- 公平性(Fairness): 评估模型在不同用户群体(如性别、年龄、种族)子集上的精度差异,确保决策不带有系统性偏见。
2. 非功能性指标(效率与资源)
这类指标关注模型的运行效率和资源消耗,直接决定了模型的部署成本和用户体验。
- 推理延迟(Latency): 模型处理单个输入样本所需的时间。通常需要区分平均延迟 和P95/P99 延迟(确保最慢的请求也能在可接受的范围内完成)。
- 吞吐量(Throughput): 模型在单位时间内可以处理的样本数量,通常以 QPS(Queries Per Second)衡量。
- 内存占用(Memory Footprint): 模型运行时占用的显存或系统内存大小,包括权重参数和运行时激活的内存。
- 功耗(Power Consumption): 尤其对于边缘设备,需要测量模型在推理时消耗的电能。
三、测试方法:建立系统化的基准体系
建立高效的模型基准测试体系,需要遵循系统化的步骤和特定的技术工具。
1. 数据集划分与处理
- 标准三段法: 严格划分训练集、验证集和测试集。测试集必须是**一次性(Hold-out)**数据集,只用于最终评估,防止评估偏差。
- 特定挑战集: 针对业务痛点,创建专门用于测试鲁棒性、边缘情况或长尾数据的对抗性数据集(Adversarial Datasets)。例如,如果模型容易被遮挡图像欺骗,就创建一个专门包含遮挡图像的子集。
2. 标准化测试环境
为了保证测试结果的可复现性,必须严格固定测试环境。
- 硬件锁定: 明确指定 CPU 型号、GPU 型号和版本(如 NVIDIA V100, Tensor Core 开启状态)。
- 软件锁定: 记录操作系统、CUDA/cuDNN 版本、Python 版本以及模型框架(TensorFlow/PyTorch)的具体版本号。
- 批处理大小(Batch Size): 在吞吐量测试中,固定 Batch Size,并测试不同大小的 Batch Size 对延迟的影响。
3. 性能测试工具与流程
需要使用专业工具来获取精确的延迟和吞吐量数据。
- 框架内置工具: 利用 PyTorch Profiler 或 TensorFlow Profiler 详细分析模型各个算子(Operator)的运行时间,找出性能瓶颈。
- 推理引擎工具: 使用 ONNX Runtime、TensorRT 或 OpenVINO 等推理优化引擎自带的性能测试工具,模拟生产环境下的实际推理流程。
- 并发负载测试: 使用 Apache JMeter 或 Locust 等工具,模拟多用户并发请求(高负载),测试模型在压力下的稳定性和 P95/P99 延迟。
4. 结果可视化与报告
所有测试数据都必须被清晰地记录和可视化。
- 指标面板: 使用 TensorBoard、MLflow 或定制的 Dashboard 集中展示所有功能性(如 F1-Score)和非功能性指标(如 Latency)。
- 效率-精度权衡曲线: 通常需要绘制一张图表,横轴为延迟(Latency),纵轴为精度(Accuracy)。这条曲线能直观展示不同模型版本或优化策略的效率-精度权衡(Efficiency-Accuracy Trade-off),是决策者选择部署模型的关键依据。
总结
模型评估的基准测试是一项严谨的工程实践,它将模型从理论性能推向实际应用价值。通过系统性地评估功能性指标和非功能性指标,并在标准化、可复现的环境下进行,团队才能确保最终部署的模型不仅"聪明",而且"跑得快、耗得少、用得稳",真正满足复杂的业务需求。