目录
一.先讲一下普通请求、XHR请求
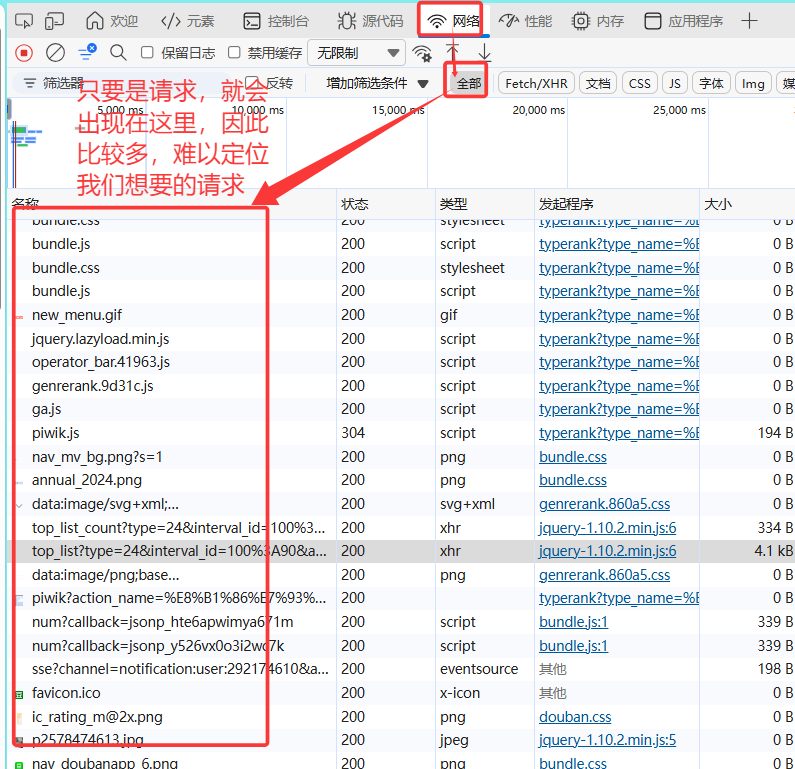
1.普通请求
右击网页->检查->网络->全部
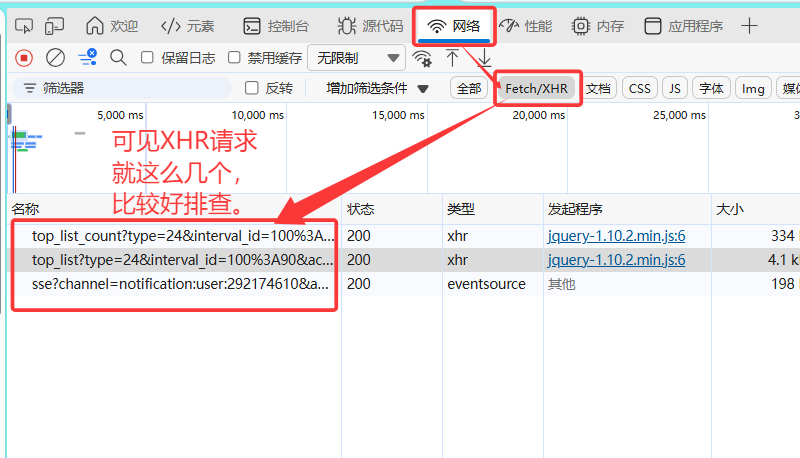
2.XHR请求
XHR就是**用来抓取网页中动态加载内容(如评论、更新)**的请求。也就是用来抓取网页后续的动态数据。
举例:我们页面一打开,会展示出一些静态资源。当我们点击"喜剧片"时,网页就会发送XHR请求,获取后端响应的喜剧片数据,然后将这些动态数据再渲染到页面上。此时这种请求,就叫XHR请求。
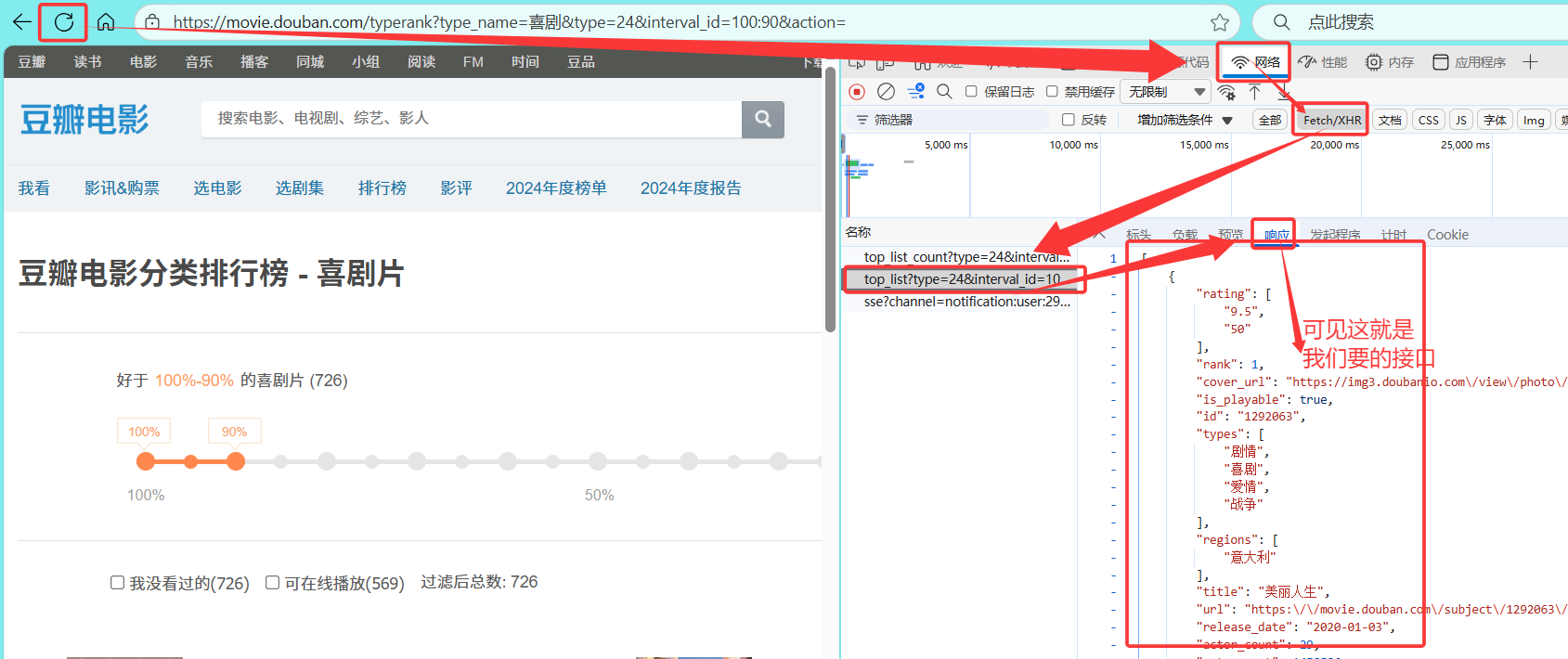
二.找响应豆瓣喜剧电影排行数据的接口
根据我们上面讲的,此时这个接口是后续提供喜剧电影排行的接口,属于后续渲染动态数据的接口,因此就可以去XHR请求里面找,应该十分好找。
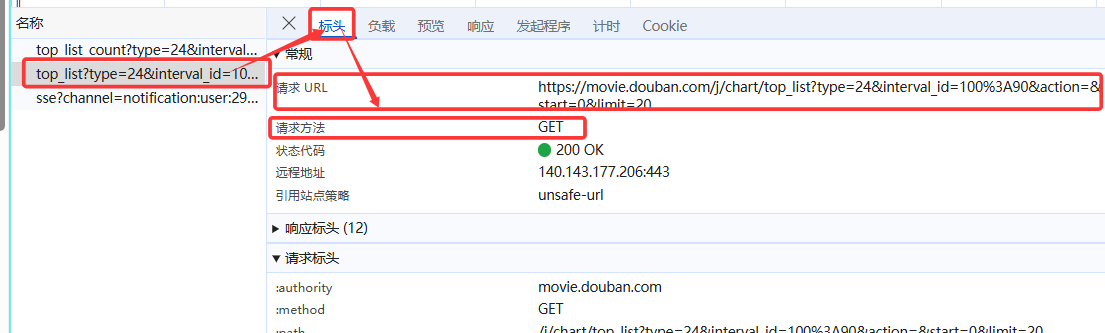
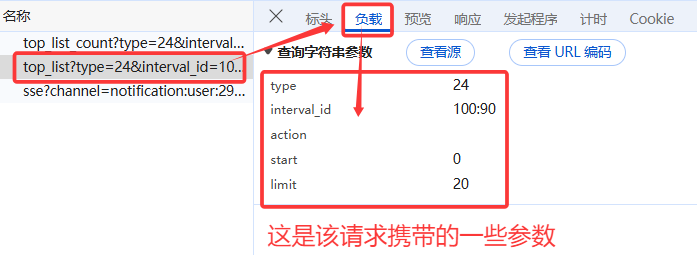
查看该接口的相关信息:
可见此时能看到请求的url、请求方式为GET、携带的参数。
还有User-Agent,即发送者,可解决该网站的反爬机制。
综上,我们就找到了该接口的url、请求方式、入参。这是爬虫最基础的三大件。

三.编写代码,爬取数据
python
import requests
#url
url = "https://movie.douban.com/j/chart/top_list"
#入参
myParam = {
"type":"24",
"interval_id":"100:90",
"action":"",
"start":"0",
"limit":"20",
}
#设置请求头中的发送者(解决反爬问题)
myHeader = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36 Edg/142.0.0.0"
}
#发送请求,获取响应数据
resp = requests.get(url=url, headers=myHeader, params=myParam)
#输出响应数据
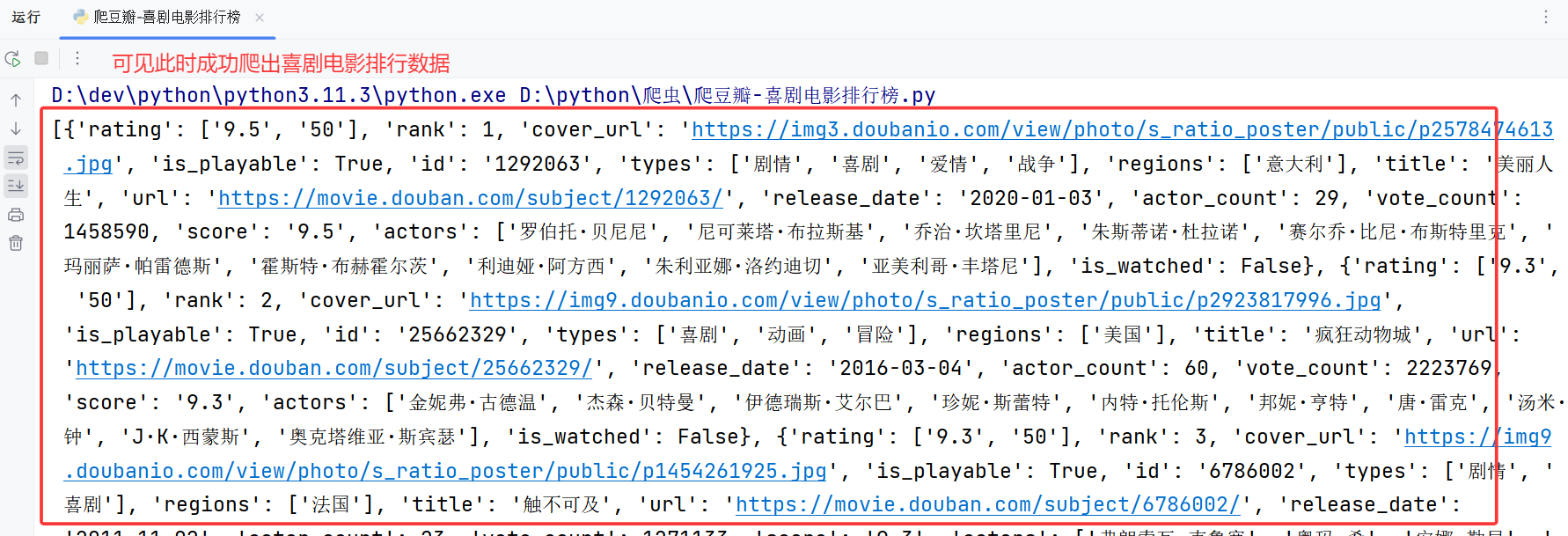
print(resp.json())查看运行效果
四.强调两点
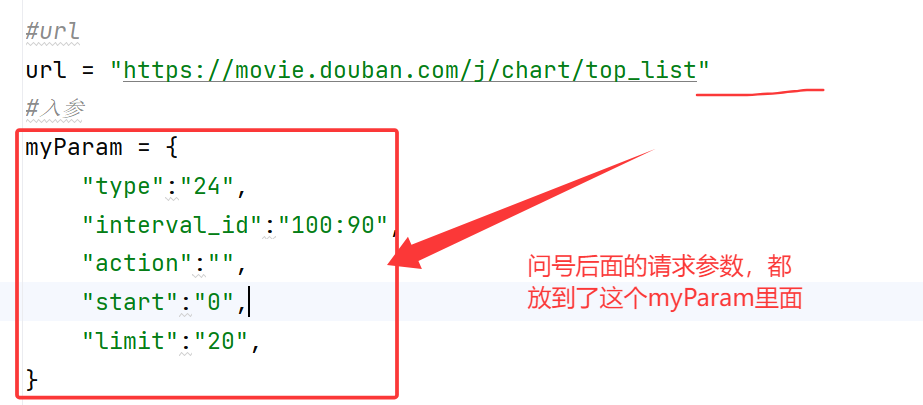
1.GET请求的两种携带参数的方式
- 放在地址栏(url)的问号后面
- 放入params里面
其实以上两种,最后都会被整合成地址栏的问号后面,只不过把入参放在params里面,看着更加清爽。
因此可见,我们写的代码中,只将url写到问号前,因为我们的入参都放在了params里面
2.爬到的数据能干什么?
我们已经将喜剧片排行榜的数据爬出来了,可以存到一个文档里。这样我们就有了这些数据,以后可以作为数据建模的数据源,供我们使用。
但是要注意一点,我们一定要爬那些公开的、非秘密的数据,而不要侵权、违反规则。爬虫只是帮助我们搜集数据的工具,而不应该成为伤害他人权益的利刃。
以上就是本篇文章的全部内容,喜欢的话可以留个免费的关注呦~~~