根据官网安装CUDN
执行命令nvcc -V 和 nvidia-smi 后出现下面图中表示安装OK
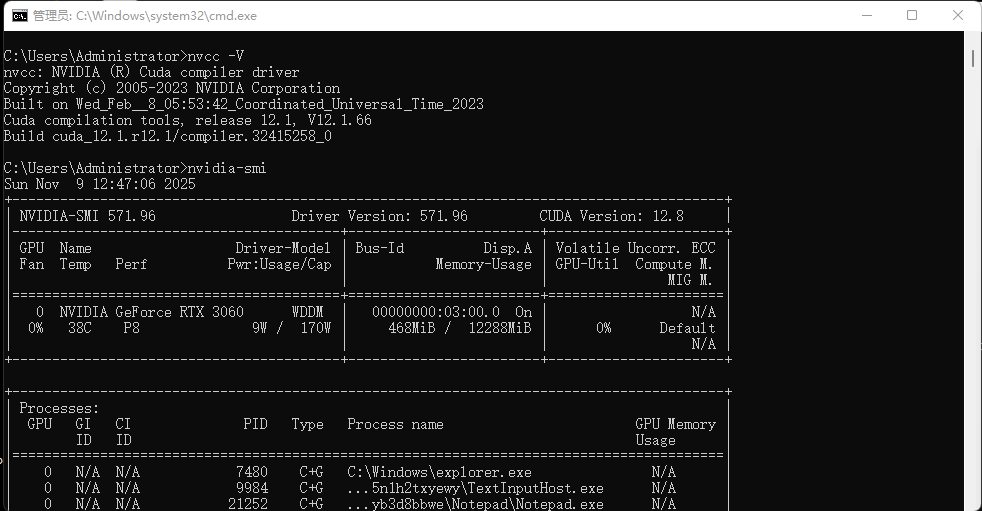
我到这里都ok,但是还是报未检测到CUDA环境,
可以进入Python环境执行命令
python
import torch
print(torch.__version__)
print(torch.version.cuda)
print(torch.cuda.is_available())理想输出应为:
2.3.0(PyTorch-cpu版本)12.1(编译时使用的CUDA版本)True(GPU可用)
发现PyTorch是cpu版本 要使用GPU需要PyTorch-GPU版
若已经下载了cpu版,可以执行卸载后再安装GPU版
卸载指令
python
#卸载 CPU 版 PyTorch(根据安装方式选择命令)
#若通过 pip 安装:执行卸载主包
pip uninstall torch
#再执行 卸载相关依赖
pip uninstall torchvision torchtext torchaudio
#若通过 conda 安装:执行
conda uninstall torch
#卸载主包后,再执行 卸载相关依赖。
conda uninstall torchvision torchtext torchaudio执行命令下载,若下载慢设置为国内镜像地址
python
#pip方式下载安装
pip install torch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia
#conda下载安装
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia安装完成后,成功开启GPU!