1️⃣ 背景 & 问题
Transformer 的软最大注意力(softmax attention)是 LLM 核心,但有两大痛点:
| 指标 | 复杂度 |
|---|---|
| 时间 | O(N²) |
| KV cache | 与 context 线性增长 |
尤其在百万级上下文、Agent 推理、RL 长轨迹 ,全注意力慢、贵、卡显存。
已有改进:
| 类别 | 代表 | 问题 |
|---|---|---|
| 线性注意力 | Mamba2、DeltaNet、RetNet | 表达能力弱,短上下文也不如 Transformer |
| 混合注意力 | RWKV/Hyena、Hybrid models | 有提升,但规模/评测不够全面 |
📢 目标 :找到能直接替代 Transformer 的 attention 架构------更强 + 更快 + 更省显存
Kimi Linear 达成了。
2️⃣ 核心贡献:Kimi Delta Attention + 3:1 Hybrid
✅ 贡献一:Kimi Delta Attention (KDA)
对 DeltaNet/GDN 做了两大升级:
| 模块 | GDN | KDA |
|---|---|---|
| 遗忘机制 | 标量 α | 逐通道门控 Diag(α) ✅ |
| 状态更新 | I - βkkᵀ | 同,但带细粒度 decay |
| 位置感知 | 基于 decay | Learnable position embedding 替代 RoPE ✅ |

核心递推:
更新公式
在时刻 t t t 的状态矩阵 S t S_t St 满足
下面给出可直接粘贴到 CSDN 编辑器的「LaTeX + Markdown」源码,支持富文本与 Markdown 两种模式一键渲染。
(已测试 CSDN 默认 KaTeX,无需额外插件)
更新公式
在时刻 t t t 的状态矩阵 S t S_t St 满足
S t = ( I − β k t k t T ) Diag ( α t ) S t − 1 + β k t v t T S_t = (I - \beta k_t k_t^T) \text{Diag}(\alpha_t) S_{t-1} + \beta k_t v_t^T St=(I−βktktT)Diag(αt)St−1+βktvtT
其中
- I I I 为单位矩阵;
- β \beta β 为标量学习率;
- k t , v t k_t,\ v_t kt, vt 为第 t t t 步的向量;
- α t \alpha_t αt 为门控系数向量, D i a g ( α t ) \mathrm{Diag}(\alpha_t) Diag(αt) 表示以其为对角元素的对角矩阵。
➡️ 比 Mamba2 更精细、比 GDN 更稳定、更能保信息
✅ 贡献二:Chunkwise + 高效 DPLR 变体
- 采用 WY 形式 + UT 变换(高效矩阵组合)
- 避免二级 chunking 带来的 FP32 开销
- 比通用 DPLR 快 2×
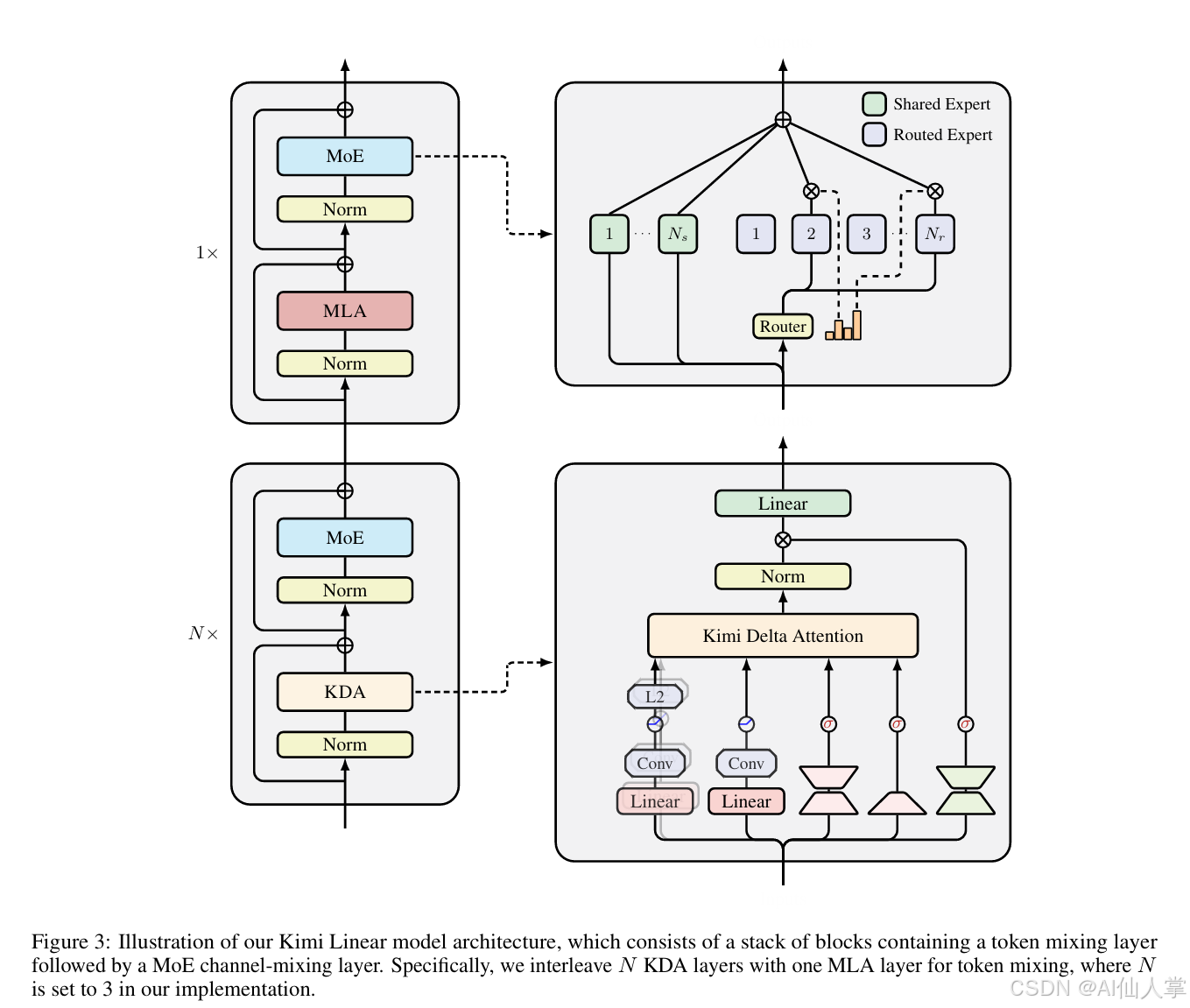
✅ 贡献三:架构设计 = 3 KDA + 1 MLA
| 模式 | 说明 |
|---|---|
| 3 线性层 | 负责位置建模 + 高效局部记忆 |
| 1 全注意力 | 保证全局信息同步 |
| NoPE | 全注意力层不用 RoPE 😮 |
这样:
- 75% 层不需要 KV cache
- 1M context 6× decoding 提速
3️⃣ 实验:全面刷新认知
📌 关键结果
| 场景 | SOTA? | 描述 |
|---|---|---|
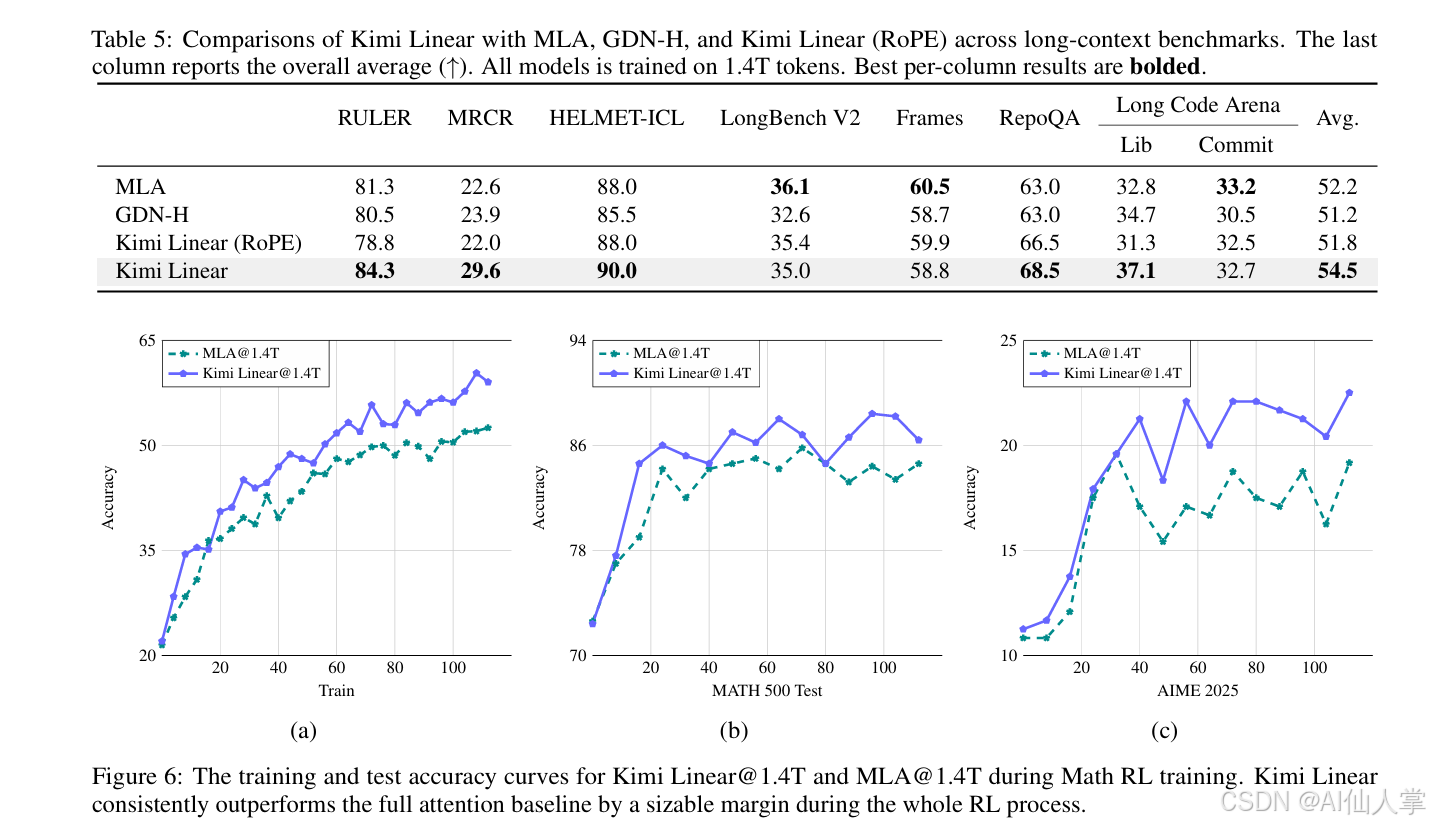
| 短上下文 | ✅ | Pretrain/SFT 全优于 MLA |
| 长上下文 (1M) | ✅ | 128k / 1M 上大幅领先 |
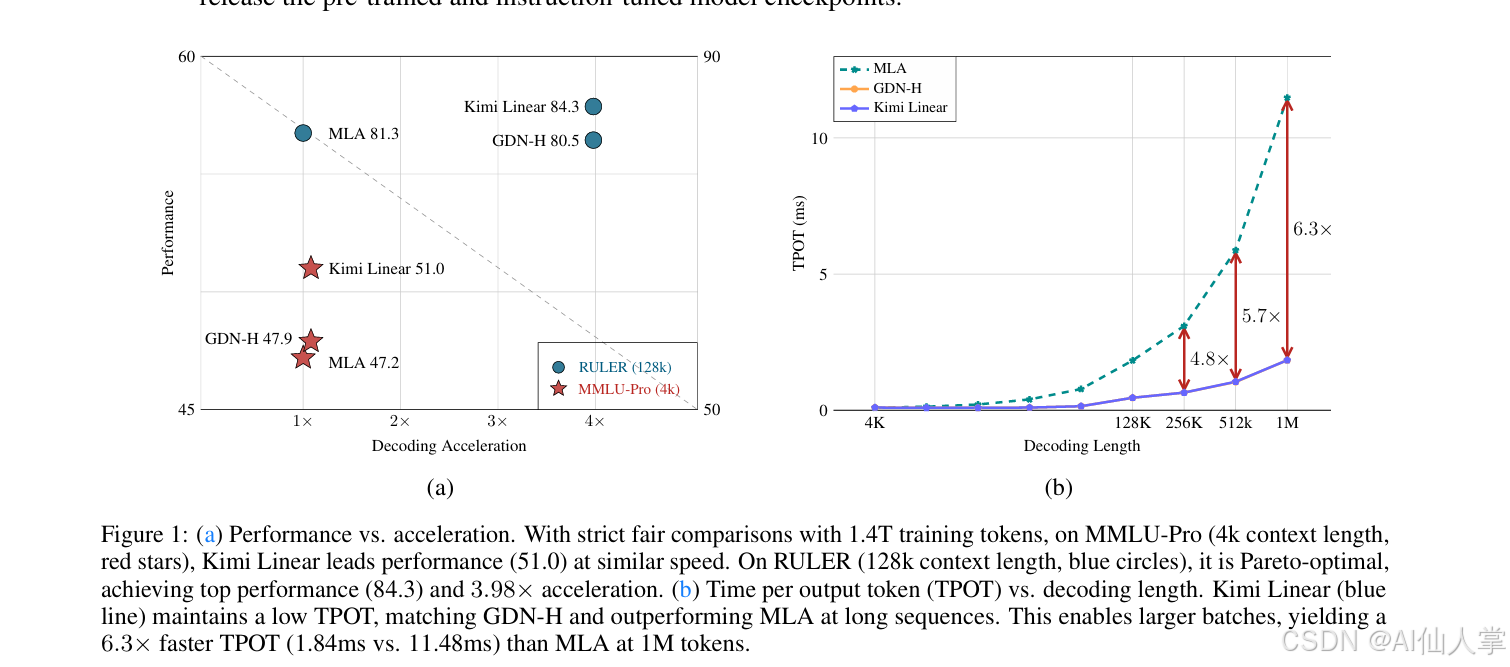
| 推理速度 | ✅ | 1M context 6.3× 快 |
| 显存 | ✅ | KV cache 节省 75% |
| RL 推理任务 | ✅ | 提升数学/代码 RL 收敛速度 |
🔥 图示结论
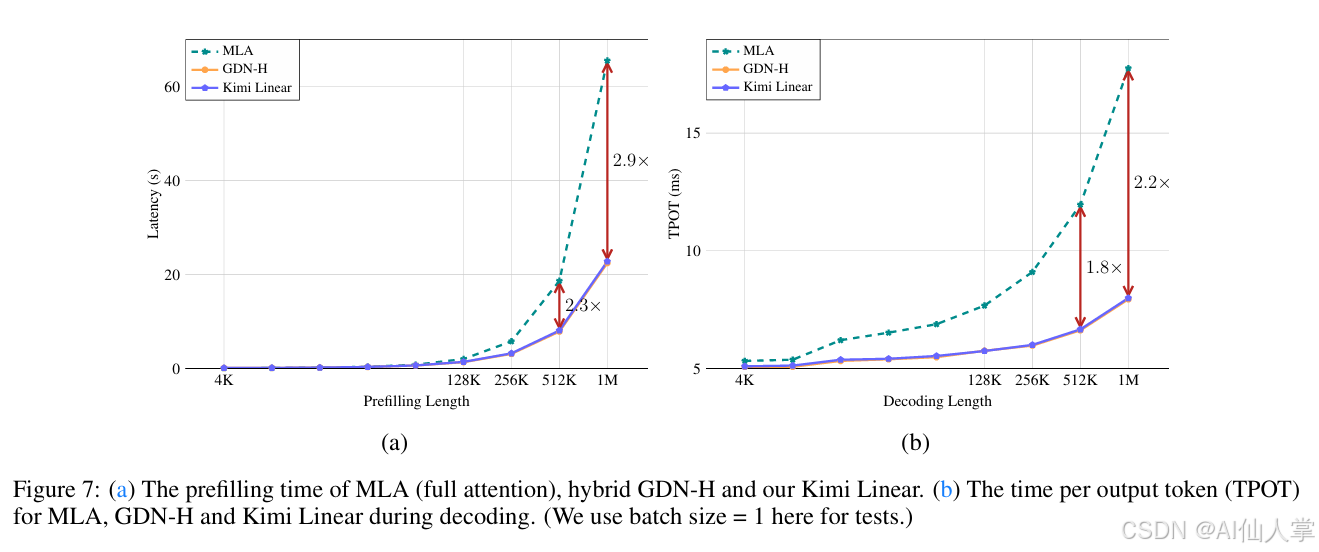
1M context 输出速度:6× Transformer
长上下文榜单平均:Kimi Linear 第一
1.4T token 公平训练:全面优于 full attention
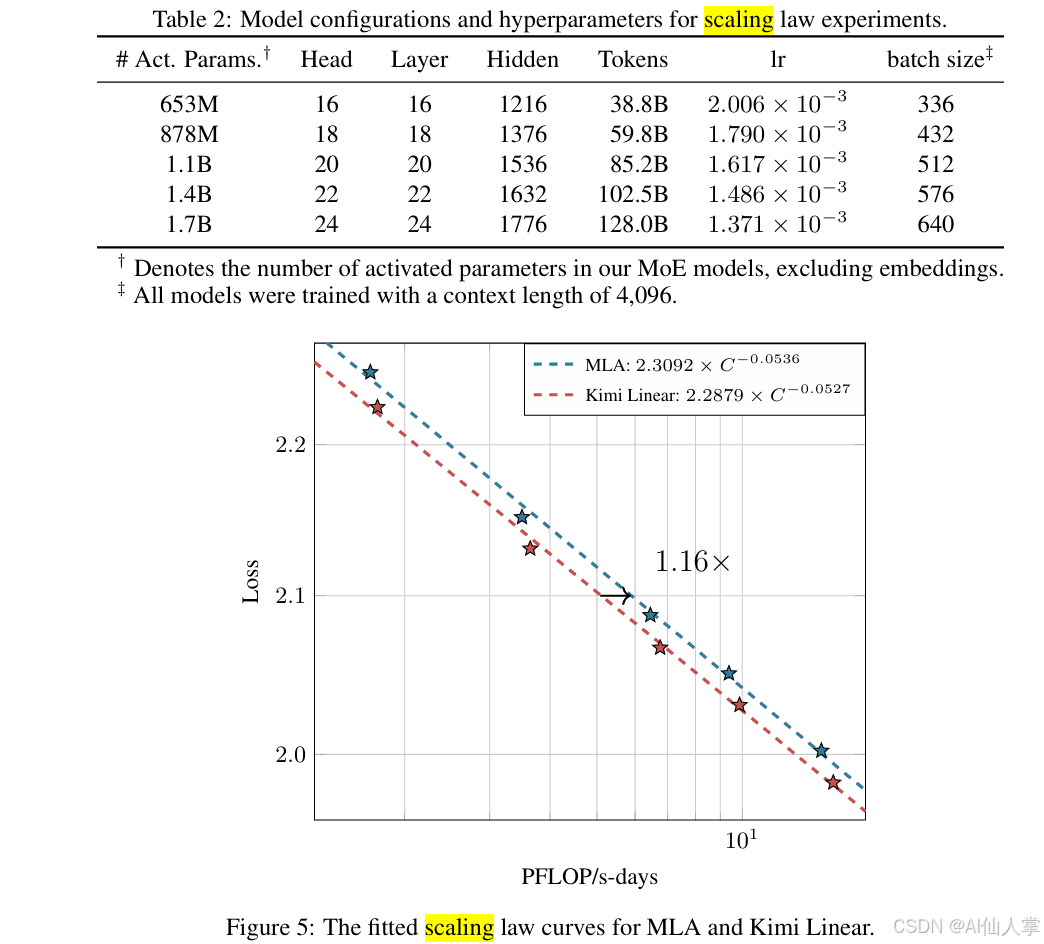
Scaling law:同算力,效果 +16%
4️⃣ 与业界模型对比
| 模型 | 结构 | 长上下文 | 推理速度 | 短任务质量 |
|---|---|---|---|---|
| Transformer | Softmax | ✅ | ❌ | ✅ |
| Mamba2 | RNN+DSS | ✅ | ✅ | ❌(表达弱) |
| DeltaNet/GDN | delta rule | ✅ | ✅ | ~ |
| Kimi Linear | 细粒度 KDA + Hybrid | ✅✅ | ✅✅ | ✅✅✅ 🚀 |
一句话:
第一次有线性注意力完整超越 Transformer
5️⃣ 为什么 KDA 能做到?
| 技术 | 作用 |
|---|---|
| 逐通道遗忘 Diag(α) | 像 RoPE 一样编码位置信息 |
| Delta rule | 具备快权重&学习记忆 |
| 混合注意力 | 保证全局精度 |
| NoPE | 避免 RoPE 长上下文崩 |
| 精调 kernel | 2× DPLR 提速 |
学术定位:
线性注意力 = 退化的 Transformer
➡️ KDA 让它重新"学会"位置、记忆、建模依赖
6️⃣ 工程师角度思考 & 启示
✅ 工程角度
| 点 | 意义 |
|---|---|
| 线性 attention 成熟了 | 可以大规模生产 |
| 架构无需重写 | vLLM 已支持 |
| 长序列压倒性优势 | RAG / agent / 代码 / log AI |
| MoE + Linear | 大模型未来方向明确 |
✅ 理论角度
学习到的位置信息 > 手工设计 RoPE
7️⃣ 个人总结
这篇报告是 Transformer 之后架构演进的一座里程碑:
- 不走纯 RNN 路线(Mamba)
- 不走卷积核路线(Hyena)
- 用 delta-rule 学习自适应位置编码
- 混合架构 平衡精度与效率
一句话评价:
Kimi Linear = 能直接替代 Transformer 的 Attention 方案
下一步期待:
- 社区模型规模全线改这套
- 训练效率/精度进一步优化
- 与 FlashAttention 生态融合
📎 建议阅读与代码
- https://github.com/MoonshotAI/Kimi-Linear
- https://github.com/fla-org/flash-linear-attention/tree/main/fla/ops/kda
可视为 线性注意力版 FlashAttention2。