【论文阅读】Igniting VLMs toward the Embodied Space
- [1 发表时间与团队](#1 发表时间与团队)
- [2 问题背景与核心思路](#2 问题背景与核心思路)
- [3 具体设计](#3 具体设计)
-
- [3.0 架构设计(统一跨层思维链)](#3.0 架构设计(统一跨层思维链))
-
- [核心机制(Path-Drop 训练策略)](#核心机制(Path-Drop 训练策略))
- [3.1 模型设计 (Architecture)](#3.1 模型设计 (Architecture))
- [3.2 训练设计(Training recipe)](#3.2 训练设计(Training recipe))
- [3.3 数据设计 (Data)](#3.3 数据设计 (Data))
- [4 实验表现](#4 实验表现)
- [5 结论](#5 结论)
1 发表时间与团队
-
时间:该研究成果于 2024 年底至 2025 年初发布(对应 Qwen2.5-VL 后的最新具身智能浪潮)。
-
团队:自变量。
2 问题背景与核心思路
问题背景
- Tokenization Gulf(词元化鸿沟):传统 VLM 擅长处理离散的文本符号,而机器人需要连续的物理信号。
- 松耦合困境:如 π 0 \pi_0 π0 等现有模型,将动作分支作为 VLM 的"插件",导致机器人"懂了指令但做不准动作",即指令遵循能力(Instruction Following)不足。
核心思路
"手脑一体"的紧耦合:通过 Uni-CoT(统一跨层思维链) 和特定的 MoE 架构,将逻辑推理与物理执行强行统一在同一个数学框架内,覆盖从"语义到感知运动"的全任务谱系。
3 具体设计
3.0 架构设计(统一跨层思维链)
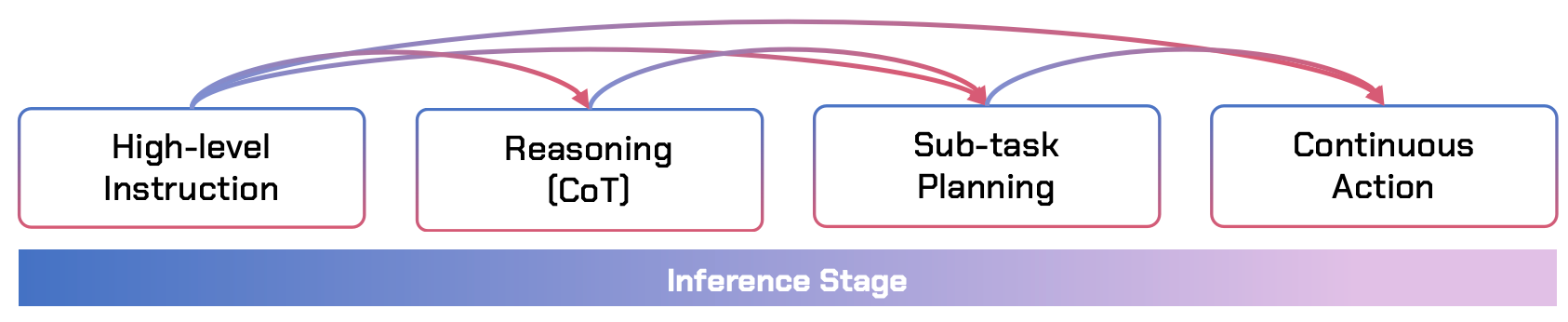
Uni-CoT 的核心在于它覆盖了语义-感知运动全谱系。可以把它想象成一个逐级降维的过程:
- 最高层:指令 (Instruction)
- 输入:"帮我把桌子上的垃圾清理掉。"
- 属性:极其抽象,完全没有物理细节。
- 中间层:逻辑推理 (Textual CoT)
- 生成:"桌上有个空罐子,我需要先移动到它上方,然后抓取并扔进右侧纸篓。"
- 属性:将大任务拆解为逻辑子目标。
- 桥接层:子任务规划 (Subtask Plan)
- 生成:具体的空间航点或离散动作(例如 FAST Tokens)。
- 属性:将逻辑转化为具体的物理意图。
- 底层:连续动作 (Continuous Actions)
- 输出:由 Flow-matching 生成的毫米级坐标和夹爪开度。
- 属性:纯物理信号,直接控制电机。
核心机制(Path-Drop 训练策略)
这是 Uni-CoT 能够"落地"的关键。如果模型每次做动作前都要写一段话,机器人会反应迟钝。
- 训练时:研究团队会随机"丢弃"中间的推理步骤(CoT)或子任务规划。
- 路径 A:指令 → \rightarrow → 推理 → \rightarrow → 规划 → \rightarrow → 动作(用于复杂、陌生任务)。
- 路径 B:指令 → \rightarrow → 动作(用于简单、熟练任务)。
- 结果:这种策略强制模型在底层表征上实现**"跨层对齐"**。即使不输出文字推理,模型的特征向量里也已经隐含了逻辑信息。
端到端可微(Differentiable):以当机械臂没抓准时,梯度会直接回流,告诉模型:"你刚才对'杯子'这个词的空间定位(Grounding)有偏差"。
3.1 模型设计 (Architecture)
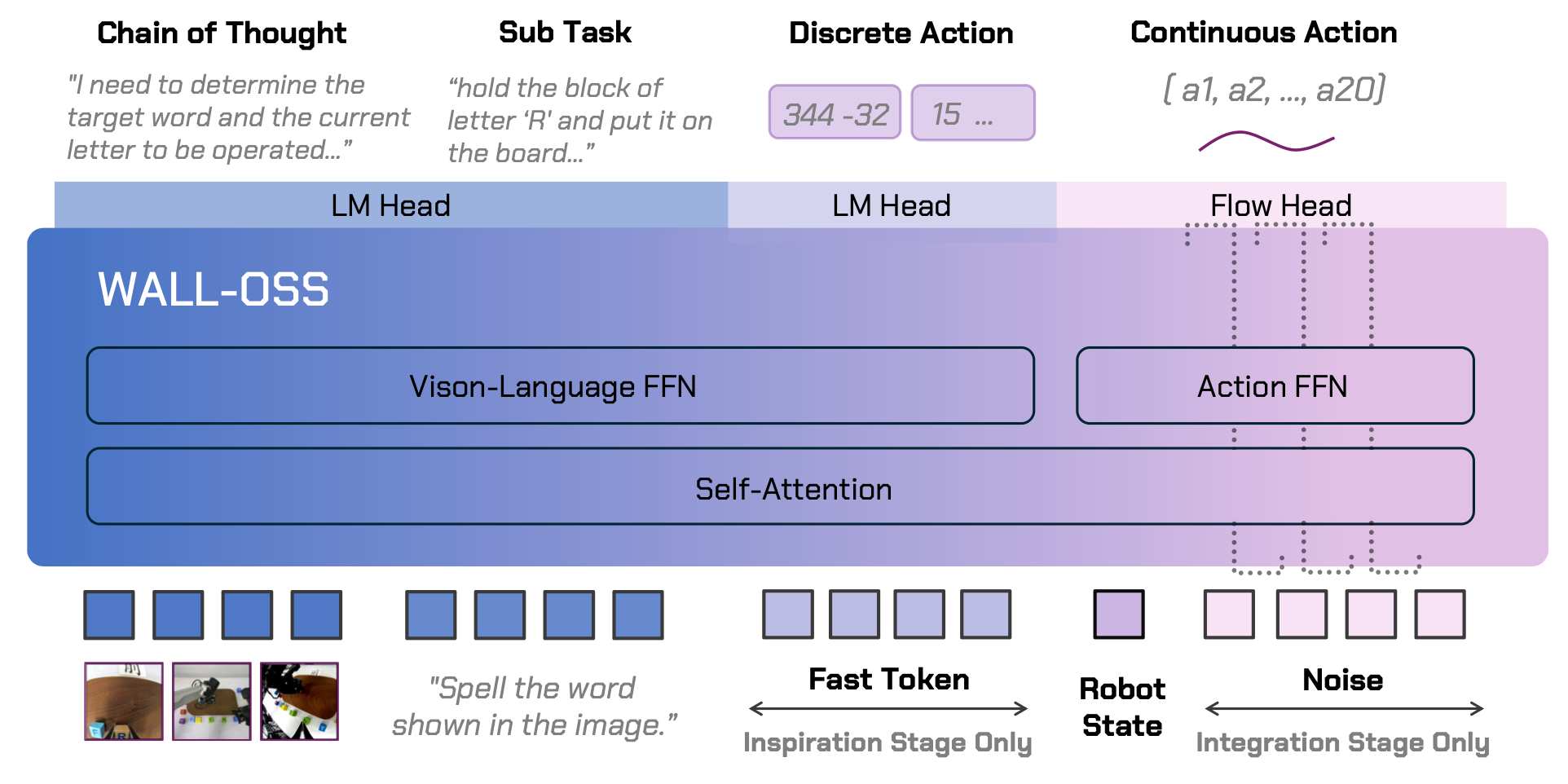
- Backbone(底座):选用 Qwen2.5-VL-3B,利用其原生动态分辨率和强大的空间 Grounding 能力。
- MoE 静态路由:Vision-Language FFN:负责感知和语义理解。Action FFN:负责动作特征生成。两者共享 Attention(自注意力机制),确保动作实时受视觉和指令指引。
- 生成算法:采用 Flow Matching(流匹配) 代替传统的 Diffusion,生成更平滑、更直接的动作轨迹。
3.2 训练设计(Training recipe)

三阶段训练策略:
- base模型预训练
- Inspiration Stage(启发阶段):引入 FAST Tokenization(cf. π 0 \pi_0 π0-FAST),让模型学会"动作单词"的离散 Choice。
- Integration Stage(整合阶段):冻结/解冻 VLM,通过流匹配学习高精度的连续控制,实现"肌肉记忆"。
-
Phase 1: 锁死大脑,激活小脑(Frozen VLM Training)
在这一阶段,团队采取了极其谨慎的策略:冻结(Freeze) 整个视觉语言模型(VLM)的主体参数。
- 操作细节:Qwen2.5-VL 的所有 Transformer 层参数都不动。只训练新加入的 Flow Head(流匹配预测头) 和 Action FFN(动作专家网络)。
- 核心逻辑:
- 防止知识污染:机器人动作数据(如机械臂的坐标序列)与互联网文本数据分布完全不同。如果一开始就全量训练,会导致模型出现"灾难性遗忘",变得不再会说话或理解逻辑。
- 特征对齐:强制要求动作专家学会如何从已经成型的视觉/语言特征中,提取出对控制有用的信息。
- 训练目标:模型开始接触 Flow Matching。它学习如何在给定的视觉背景下,将随机噪声逐渐"推"向真实的动作轨迹。
-
Phase 2: 全身合练,手脑合一(Unfrozen Joint Optimization):当 Action FFN 已经初步学会如何根据视觉信号生成动作后,模型进入了全参数微调阶段。
- 操作细节:解除冻结(Unfreeze):允许 VLM 主体、Action FFN 和视觉编码器同步更新梯度。
- 核心逻辑:
- 深度融合:在 Phase 1 中,大脑和小脑是"各过各的"。在 Phase 2,通过联合优化,VLM 内部的注意力权重会发生微调,使其更敏锐地捕捉那些对动作至关重要的视觉细节(比如夹爪边缘的微小位移)。
- Uni-CoT 的闭环:此时,文本推理(CoT)产生的中间表征直接参与到动作生成的梯度计算中。如果动作做错了,模型会反思是不是中间的推理逻辑或空间 Grounding 出了问题。
- 训练目标:通过端到端的微分(Differentiable),实现**指令遵循(Instruction Following)**的极致对齐。确保"把杯子拿远一点"这种抽象的程度词,能精确反映在电机的位移量上。
-
3.3 数据设计 (Data)
- 具身 VQA 增强:针对空间定位、坐标预测、任务进度建模设计了大量的自动生成问答数据,用于填补预训练模型与物理世界的分布差距。
4 实验表现
- 基准对比:在 Open X-Embodiment 等数据集上,将 π 0 \pi_0 π0 设为主要竞争对手。
- 关键指标:
- 指令遵循:得益于 Uni-CoT,在复杂长程任务中表现卓越。
- 空间精度:通过 VQA 强化,其物体定位和抓取成功率大幅领先。
- 推理效率:Path-drop 机制使得简单任务可以"秒发"动作,而复杂任务则会"深思熟虑"。
5 结论
WALL-OSS 证明了统一思维链是具身智能进化的关键。它不仅让 VLM 获得了空间感,更通过一种端到端可微的架构,解决了长期以来"感知"与"控制"脱节的问题。