写在文章开头
夜莺是笔者近期了解到的一款比较强大的日志监控告警工具,按照官网的说法它可对接多种既有的主流数据源包括但不限于:
- ClickHouse
- elasticsearch
- Loki

然后我们只需按照夜莺配置模板即可完成监控指标、日志监控告警功能,而本文笔者所着重要介绍的,是这款系统中最强大的日志告警,笔者将通过一个es日志的示例逐步演示并结合源码分析的方式全方位带读者了解夜莺监控的使用和工作机制。
我是 SharkChili ,Java 开发者,Java Guide 开源项目维护者。欢迎关注我的公众号:写代码的SharkChili ,也欢迎您了解我的开源项目 mini-redis:github.com/shark-ctrl/...。
为方便与读者交流,现已创建读者群。关注下方公众号获取我的联系方式,添加时备注加群即可加入。
详解Nightingale安装与配置
前置准备
主流的日志采集都是通过skywalking采集日志到elasticsearch,如下架构图所示:

而本文的案例则是通过elasticsearch采集系统程序运行日志,并按照Nightingale协定的规则配置定时采集任务,一旦感知到elasticsearch日志中存在错误日志则发出告警:

为了更好的演示夜莺如何根据采集日志并发出告警,笔者这里也简单介绍一下本文数据源elasticsearch的的配置。本文elasticsearch选用版本为7.12.0,在该版本的es上笔者刷入如下索引,可以看到这款索引很好的模拟了日常采集日志的常见数据:
- 微服务名称
- 日志消息
- 日志时间
- 日志级别
vbnet
-- 创建索引
curl -X PUT "localhost:9200/java_app_logs" -H 'Content-Type: application/json' -d'
{
"mappings": {
"properties": {
"service_name": {
"type": "keyword"
},
"log_message": {
"type": "text"
},
"timestamp": {
"type": "date"
}
}
}
}
'
-- 添加日志级别
curl -X PUT "localhost:9200/java_app_logs/_mapping" -H 'Content-Type: application/json' -d'
{
"properties": {
"log_level": {
"type": "keyword"
}
}
}
'完成必要的索引创建后,我们就可以按需刷入如下请求建立文档模拟用户登录成功和失败的消息:
vbnet
-- 添加日志
curl -X POST "localhost:9200/java_app_logs/_doc" -H 'Content-Type: application/json' -d'
{
"service_name": "user-service",
"log_message": "用户登录成功,用户ID: 12345",
"log_level": "INFO",
"timestamp": "'$(date -u +"%Y-%m-%dT%H:%M:%S.%3NZ")'"
}
'
-- 登录失败的日志
curl -X POST "localhost:9200/java_app_logs/_doc" -H 'Content-Type: application/json' -d'
{
"service_name": "user-service",
"log_message": "用户登录失败,用户名: testuser,原因: 密码错误",
"log_level": "ERROR",
"timestamp": "'$(date -u +"%Y-%m-%dT%H:%M:%S.%3NZ")'"
}
'自此,我们就有了一份可进行采集监控的es数据源,就可以开始通过夜莺进行日志监控告警配置了。
二进制安装
因为笔者采用Linux服务器部署且采用二进制的方式安装,所以我们需要到github下载最新版本,对应的下载地址为:github.com/ccfos/night...
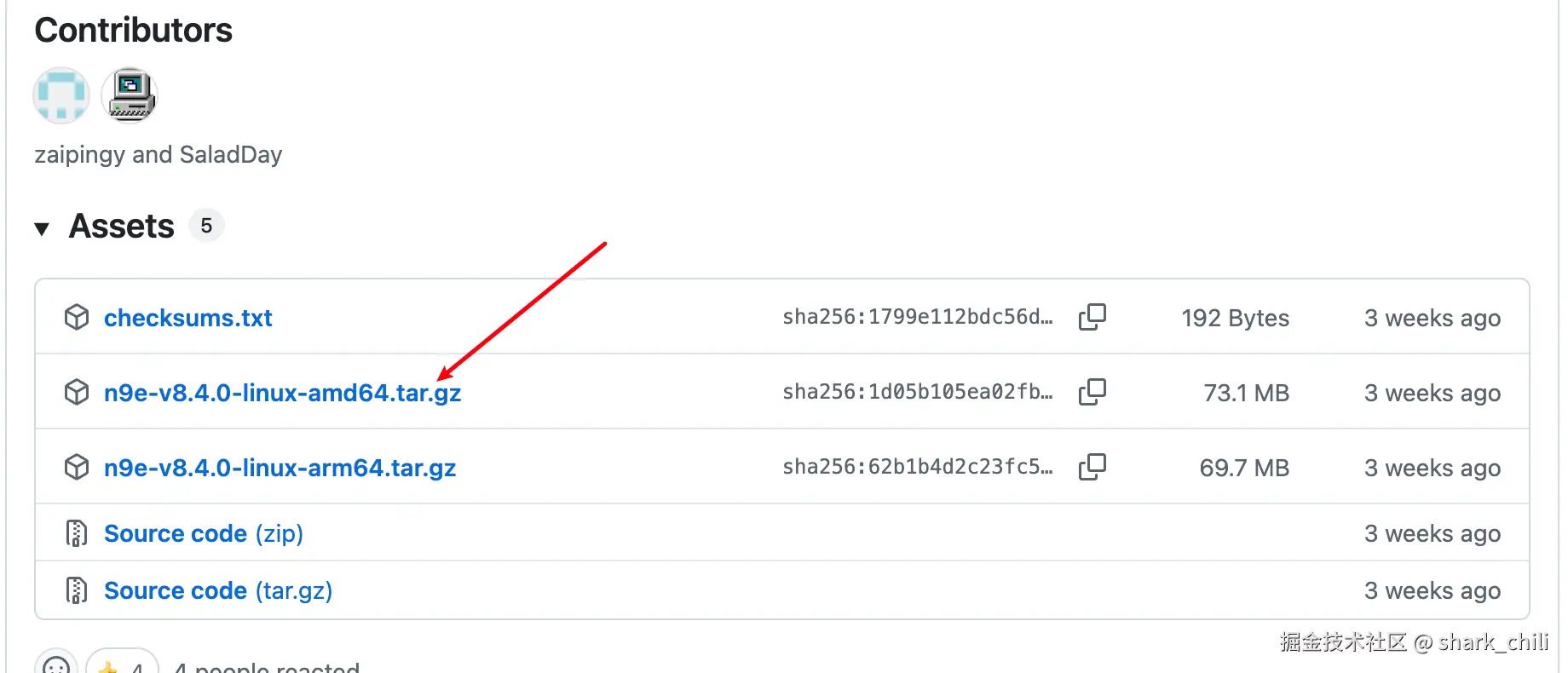
将下载好的压缩包进行解压:
tar zxvf n9e-v8.4.0-linux-amd64.tar.gz然后我们直接进入bin目录键入如下指令就可以将夜莺启动了:
bash
./n9e随后我们通过17000端口即可访问Nightingale登录界面,默认情况下Nightingale的账户和密码分别是:
账户:root
密码:root.2020
明确可以正常启动,读者可以使用如下指令以后台的方式启动:
bash
cd /opt/n9e && nohup ./n9e &> n9e.log &数据源配置
登录管理界面之后,就可以将es数据源引入进行监控告警管理了,通过集成中心定位到数据源,点击进入数据源配置界面:
随后点击新增并选择ElasticSearch数据源:

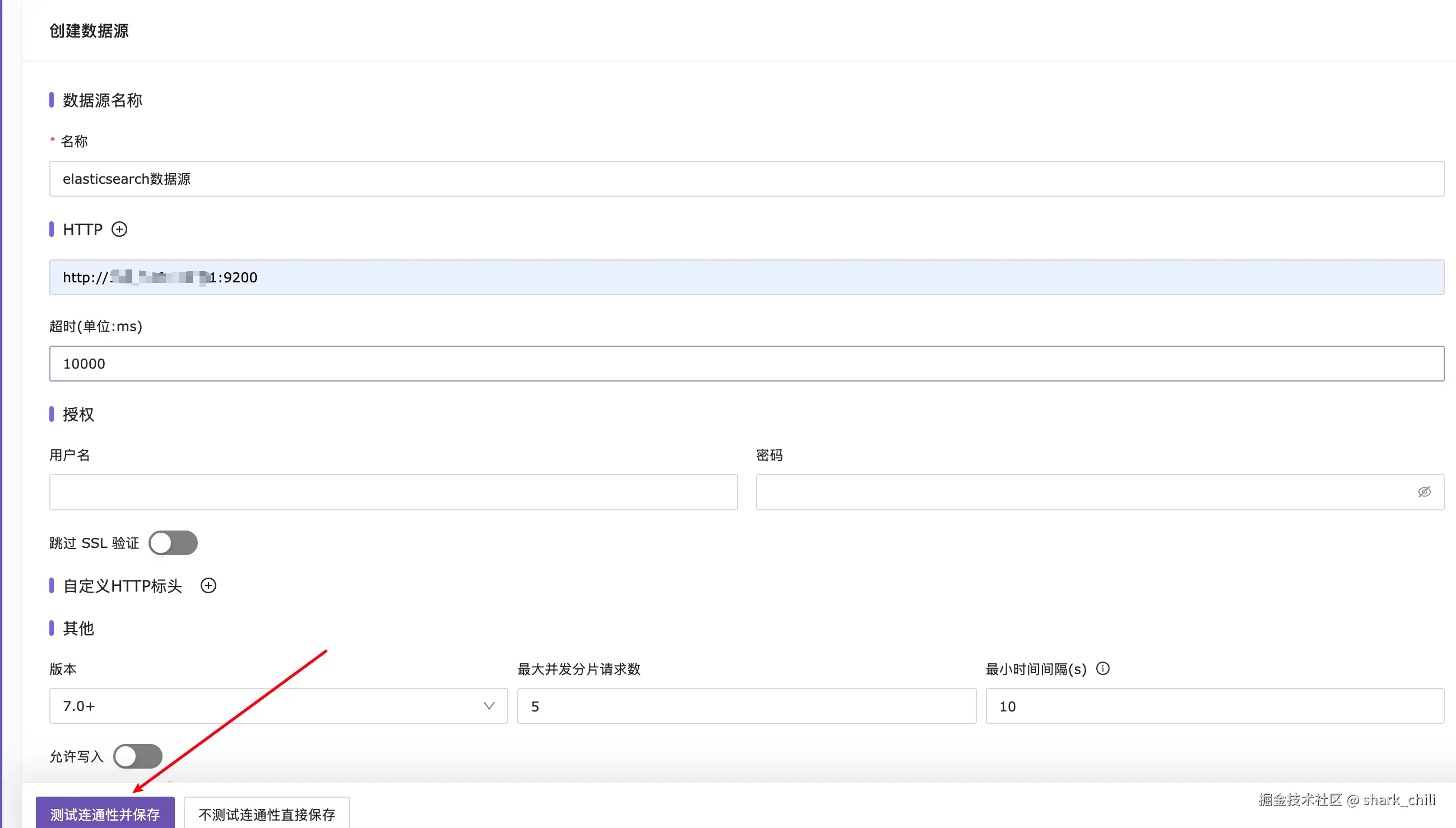
根据提示依次配置:
- 数据源名称
- 访问地址
- 版本信息
明确无误后,点击测试连通性并保存:
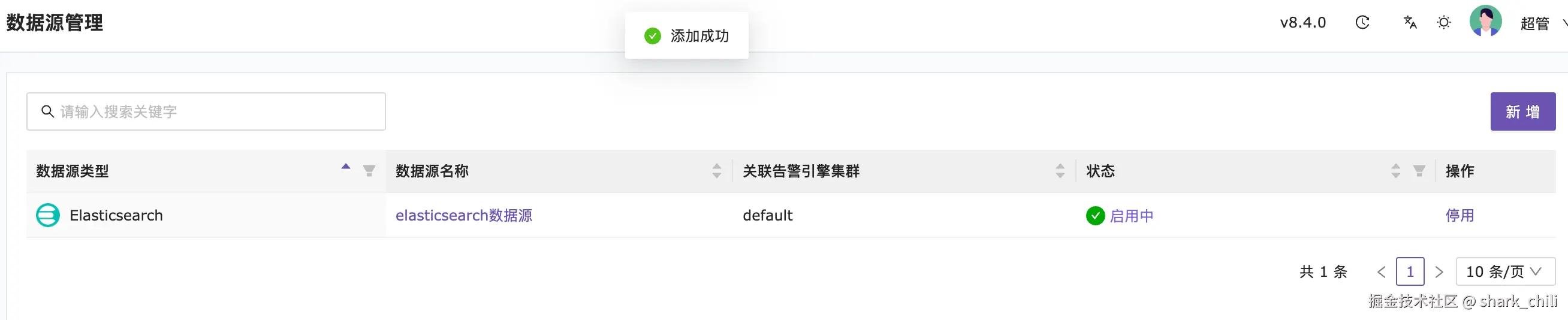
如下图所示,这样就说明数据源添加成功了,自此我们的Nightingale就可以针对日志数据源进行监控告警规则配置了:
日志查询
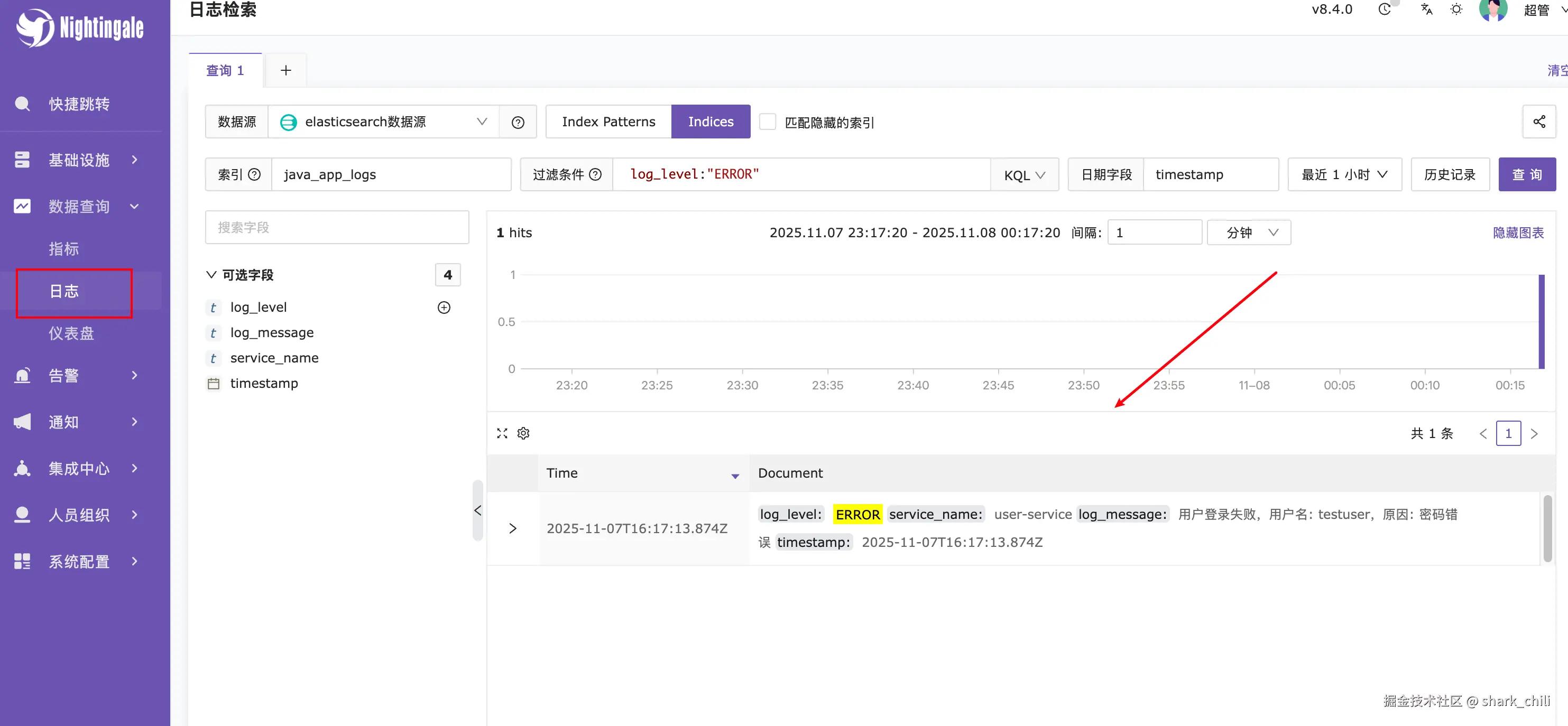
为了明确我们es写入的日志能够被准确的查询到,我们可以先通过Nightingale的日志页面针对针对该数据源进行日志查询,以笔者为例,对应的配置为:
- 数据源选择
elasticsearch数据源 - 选择索引模式即
indices - 索引使用
java_app_logs - 日志过滤条件为日志级别为错误级别的即
log_level:"ERROR"
对应的配置和输出结果如下,由此可确定笔者的配置没有任何问题:
告警规则配置与调测
重头戏来了,明确错误日志查询无误后,我们就可以按照我们上述的调测针对error级别的日志配置相应告警规则了,按照我们需求的说法,即一旦查询到错误级别的日志超过1条则直接发出告警,我们可以到告警面板选择规则管理配置监控告警,以笔者为例首先指明规则为错误日志监控告警:

针对规则配置,相应配置为:
- 选择数据源类型为
elasticsearch数据源 - 选择精确匹配指定数据源为我们的
elasticsearch数据源 - 查询统计项指明索引为
java_app_logs且过滤条件为过滤出错误类型日志log_level:"ERROR" - 时间间隔设置为
30min以内的数据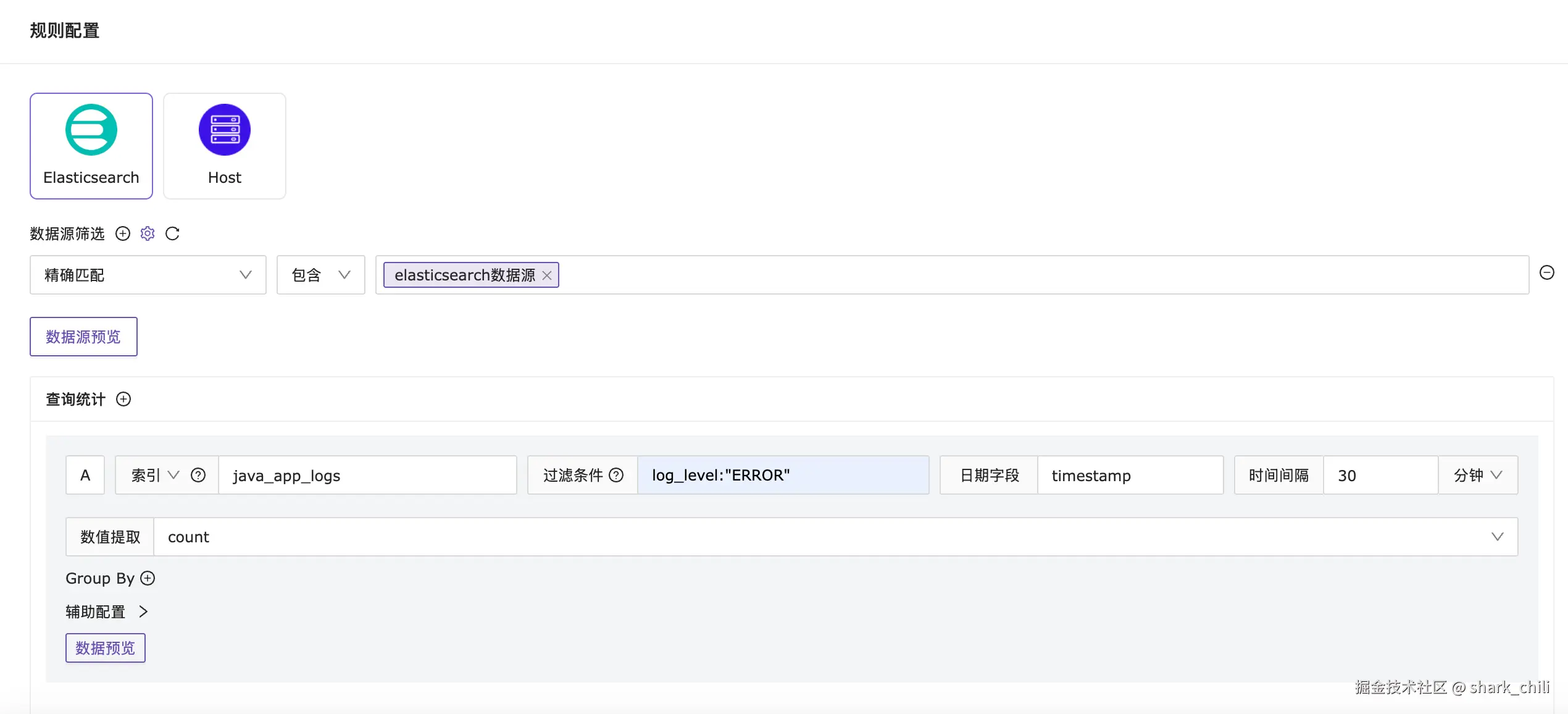
明确这个时间后,我们可以在es上刷几条错误日志看看规则配置是否可以正确执行:
vbnet
curl -X POST "localhost:9200/java_app_logs/_doc" -H 'Content-Type: application/json' -d'
{
"service_name": "user-service",
"log_message": "用户登录失败,用户名: testuser,原因: 密码错误",
"log_level": "ERROR",
"timestamp": "'$(date -u +"%Y-%m-%dT%H:%M:%S.%3NZ")'"
}
'可以看到通过表达式我们拿到了30条数据,说明这个规则配置没有问题: 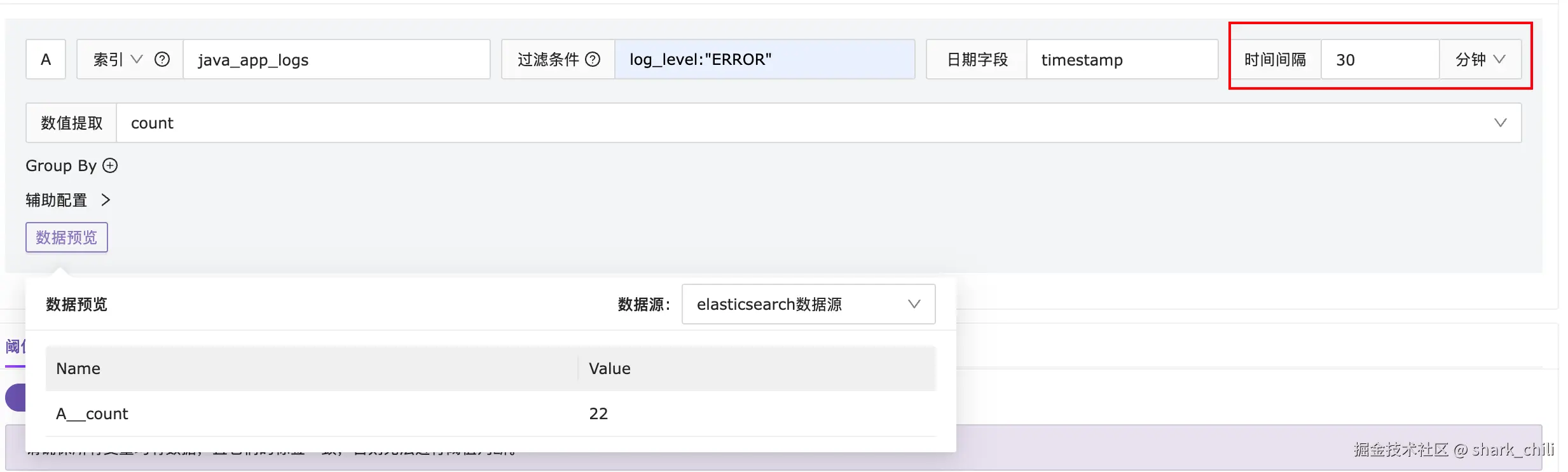
针对阈值判断,笔者指定规则为上述规则大于1也就是错误日志大于0条则触发告警,对应这个监控频率为1min一次,持续时长设置为0即代表只要出现一次直接告警。
这里我们也补充说明一下持续时长的概念,按照官网的说法持续时长即代表该规则为真时且持续配置的时间后才触发告警,例如我们1min执行一次,持续时长配置为120s即代表定时任务两次采集都收到错误级别日志大于1才触发告警。
当然笔者这里也是出于简单,直接配置为0:
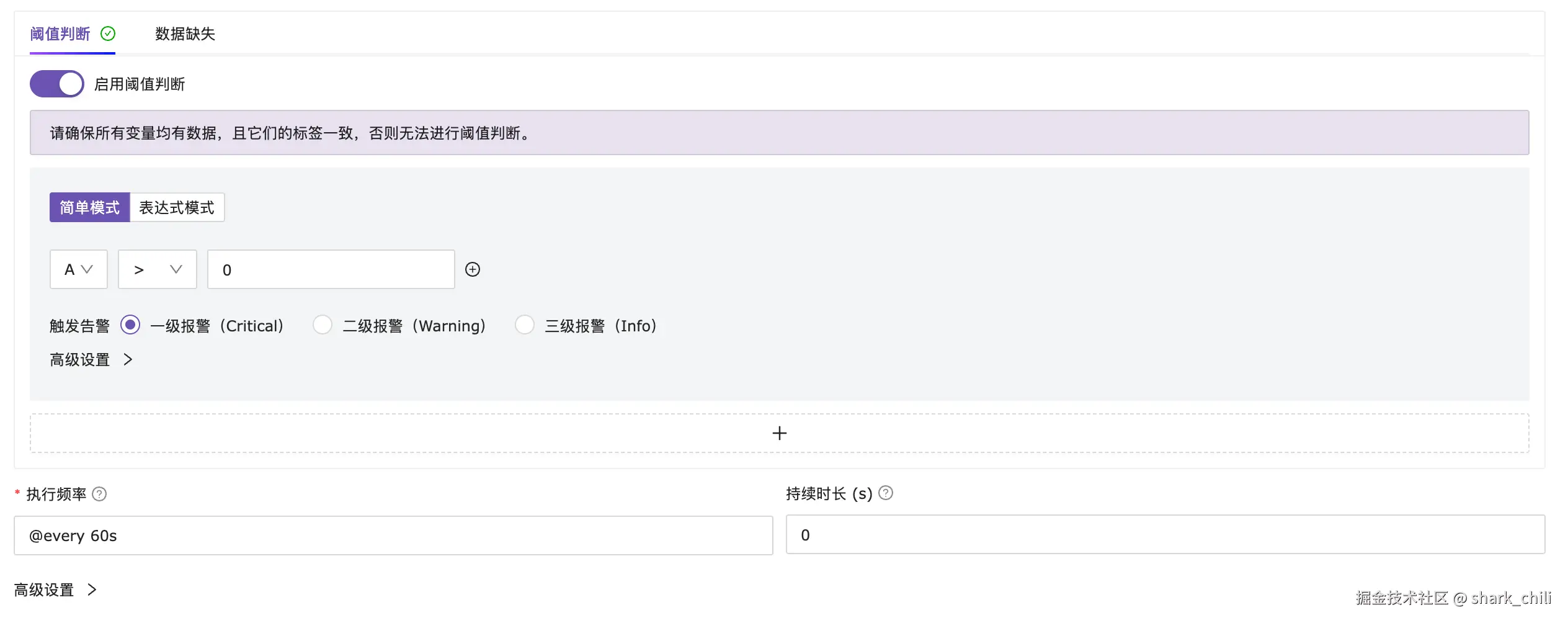
其他配置全部默认保存即可。
告警验收
此时,一旦触发告警我们就可以在告警事件上看到事件,因为夜莺默认情况下都会将事件存储在缓存中,基于这种设计理念我们可以将实时告警在夜莺平台上对接各种方式通知用户:
- 企业微信
- 阿里云短信
- 邮件

基于源码详解夜莺工作机制
日志告警预览查询原理
通过上述的实践,我们基本了解了夜莺的基本使用方式,为了更好的帮助读者理解夜莺这个开源告警的工作原理,笔者也将Nightingale的源码克隆到本地针对几个比较核心的部分进入深入的拆解分析。
首先我们先来说说数据预览这一块,因为Nightingale的数值提取针对支持对es日志进行count、max、min等多种日志数据收敛提取方式,然后通过数据源预览即可得到查询结果:
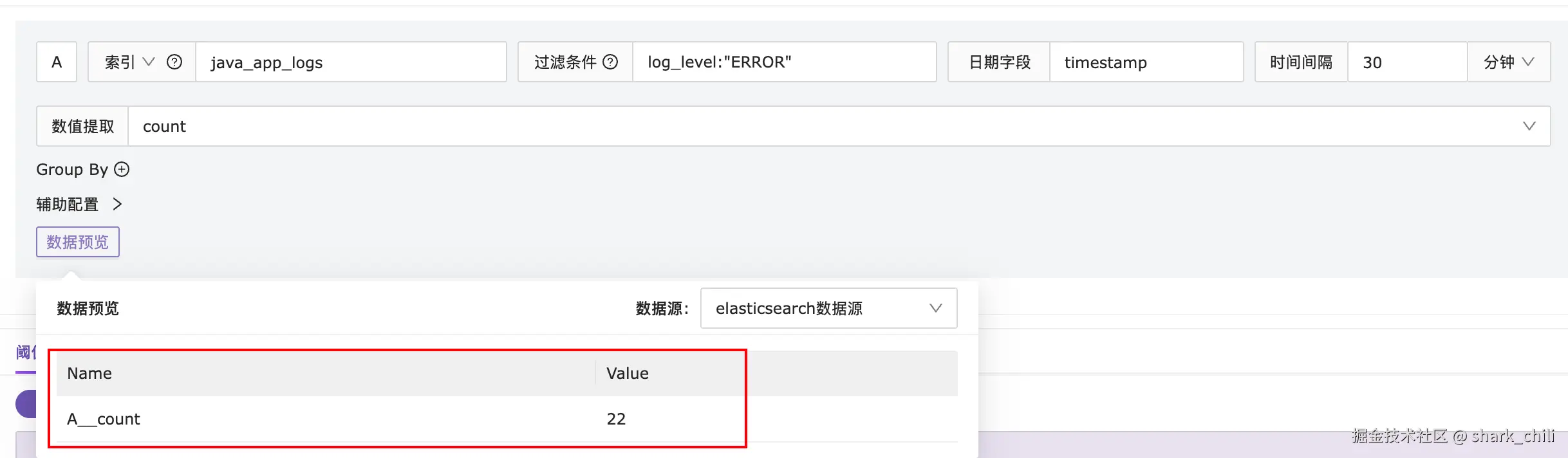
通过浏览器控台,笔者定位到对应的请求映射为http://127.0.0.1:17000/api/n9e/ds-query,同时我们也可以看到请求参数,如下所示,这里笔者也针对说明一下如下几个参数的含义:
cate:指明数据源类型为elasticsearchdatasource_id:规则配置使用的数据源为id为1,也就是我们首次配置的elasticsearch数据源query:这个json块比较重要,它说明我们配置的规则名为A,索引类型index_type为索引类型而非索引匹配模式,然后index指明为java_app_logs,然后就是kql配置规则和提取方式为countdate_field:指明采集的时间字段用索引中的timestamp
其他参数则是轮询间隔和基于这个间隔生成的起止时间:
python
{
"cate": "elasticsearch",
"datasource_id": 1,
"query": [
{
"ref": "A",
"index_type": "index",
"index": "java_app_logs",
"filter": "log_level:"ERROR"",
"value": {
"func": "count"
},
"date_field": "timestamp",
"interval": 1800,
"start": 1762532762,
"end": 1762534562
}
]
}返回结果如下,通过整体结构我们可以看出,对应A规则的在1762531200即2025年11月8日 00:00:00查出count为22:
python
{
"dat": [
{
"ref": "A",
"metric": {
"__name__": "A__count"
},
"values": [
[
1762531200,
22
]
],
"query": "map[date_field:timestamp end:1.762534562e+09 filter:log_level:"ERROR" index:java_app_logs index_type:index interval:1800 ref:A start:1.762532762e+09 value:map[func:count]]"
}
],
"err": ""
}明确这个接口出参和入参之后,我们就可以针对该接口进行深入分析了,本质上Nightingale数值提取查询就是通过上述请求参数生成es的restful请求参数,并通过返回结果中的聚合通提取到规则对应的count、max、min等信息然后返回给用户:
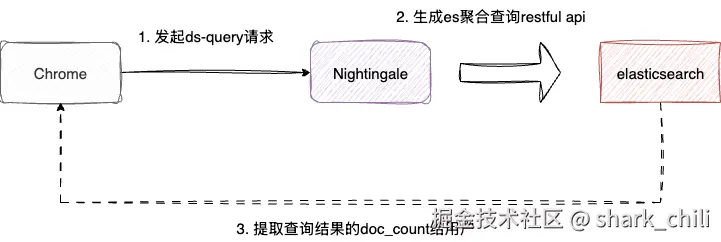
对应的我们可以在router.go文件中看到这个请求的入口,可以看到该请求映射本质上都是通过QueryData这个函数处理的:
arduino
//告警规则配置请求入口
pages.POST("/ds-query", rt.QueryData)步入QueryData,即可看到如下几个步骤:
- 将请求参数绑定到变量f这个
QueryParam结构体上,本质上就是将上述的入参进行一个一一对应的封装 - 通过QueryDataConcurrently发起es查询请求
- 将查询结果返回
go
func (rt *Router) QueryData(c *gin.Context) {
var f models.QueryParam
//解析绑定参数
ginx.BindJSON(c, &f)
//发起es restful请求然后返回结果resp
resp, err := QueryDataConcurrently(rt.Center.AnonymousAccess.PromQuerier, c, f)
//......
//将结果返回给用户
ginx.NewRender(c).Data(resp, nil)
}而QueryDataConcurrently内部逻辑也比较简单,因为我们的http请求入参中的query是个数组,所以该函数会拿到QueryParam中的query数组进行遍历,生成一个个协程发起请求并通过倒计时门栓阻塞等待,当所有请求结果写入切片后,直接将切片resp返回:
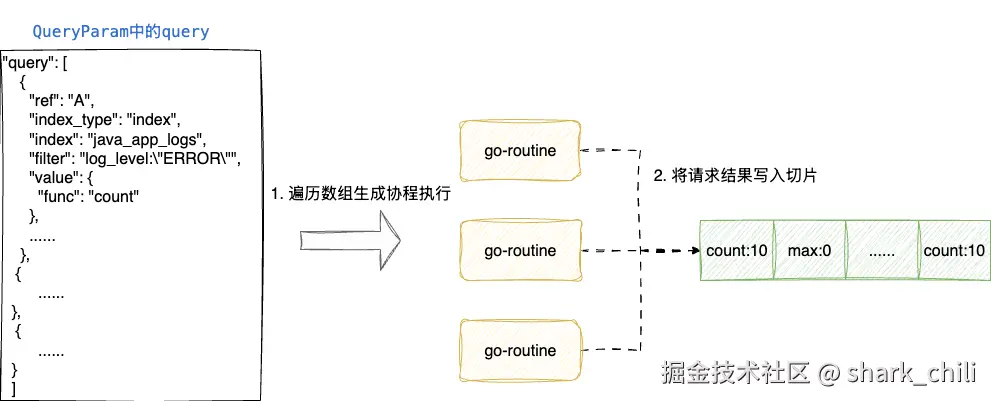
go
func QueryDataConcurrently(anonymousAccess bool, ctx *gin.Context, f models.QueryParam) ([]models.DataResp, error) {
//声明一个结果切片
var resp []models.DataResp
//......
for _, q := range f.Querys {
//......
//针对查询请求添加一个倒计时门栓
wg.Add(1)
//起个协程发起es查询
go func(query interface{}) {
defer wg.Done()
//执行查询,实际调用es的地方,将数组内部的query参数传入
datas, err := plug.QueryData(ctx.Request.Context(), query)
//......
//将结果写入resp这个切片中
resp = append(resp, datas...)
mu.Unlock()
}(q)
}
//等待所有协程查询结束
wg.Wait()
if len(errs) > 0 {
return nil, errs[0]
}
//......
//返回执行结果的切片
return resp, nil
}通过上述源码可以看到每一个协程都是通过plug.QueryData(ctx.Request.Context(), query)发起es请求的,实际上这段逻辑都是在eslike.go上完成的,对应的执行步骤为就是:
- 基于filter生成es的must表达式
- 基于timestamp和interval生成range查询
- 基于1、2构建一个bool查询
- 通过参数value指明的count聚合,构建出一个桶聚合,指明不同时间区间的符合要求的文档数
对应的参数解析映射如下:
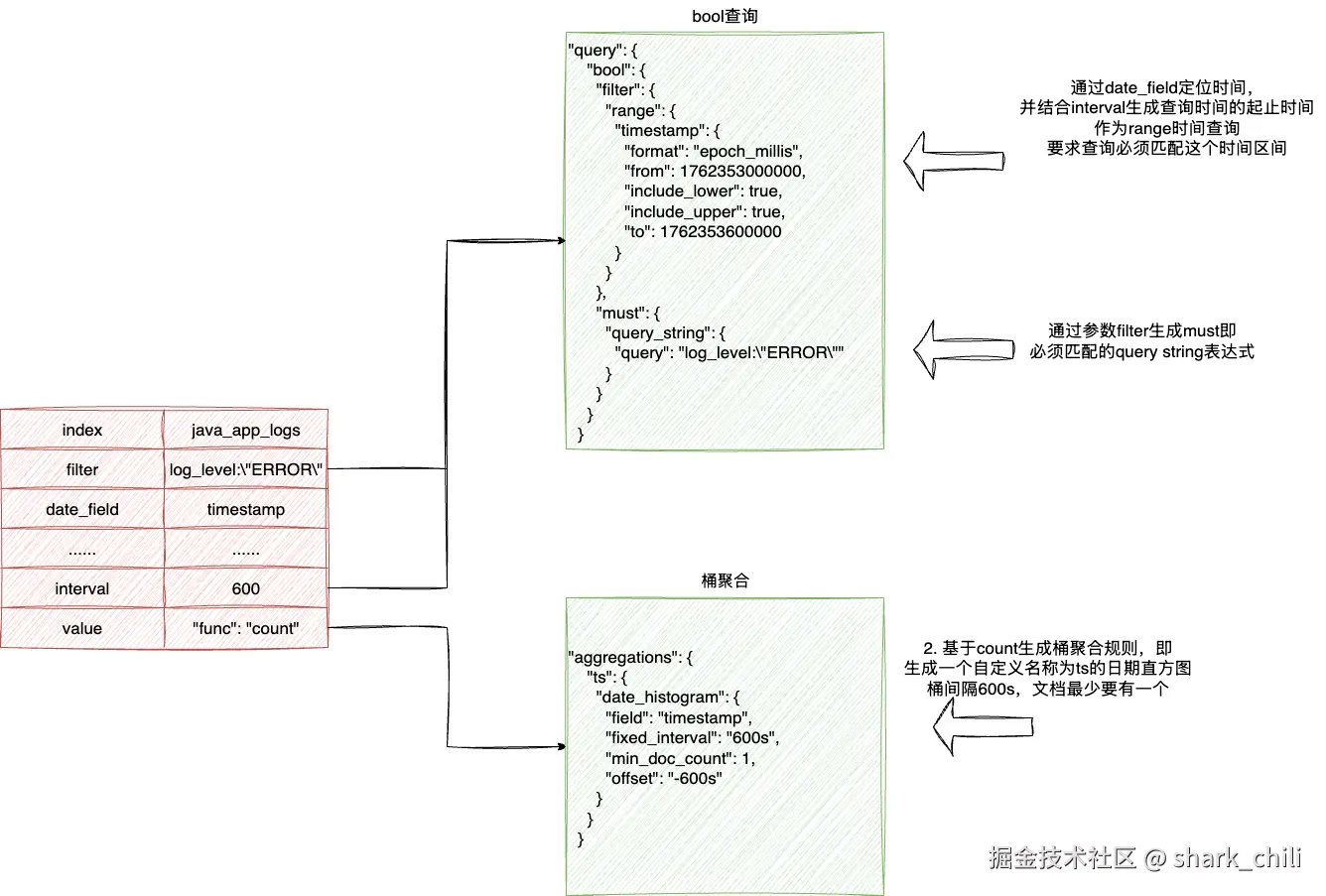 最后es会返回类似如下的一个结构体,Nightingale就会拿出这个doc_count作为结果封装返回:
最后es会返回类似如下的一个结构体,Nightingale就会拿出这个doc_count作为结果封装返回:
json
"aggregations" : {
"ts" : {
"buckets" : [
{
"key_as_string" : "2025-11-05T14:30:00.000Z",
"key" : 1762353000000,
"doc_count" : 10
}
]
}
}对应的逻辑参见如下eslike.go的QueryData,和上述说明一致,读者可结合注释阅读理解:
python
func QueryData(ctx context.Context, queryParam interface{}, cliTimeout int64, version string, search SearchFunc) ([]models.DataResp, error) {
//......
//生成range对象,结构体类似于
/**
range": {
"timestamp": {
"format": "epoch_millis",
"from": 1762353000000,
"include_lower": true,
"include_upper": true,
"to": 1762353600000
}
}
*/
q := elastic.NewRangeQuery(param.DateField)
//......
//生成时间范围并给出返回对应的时间单位
q.Gte(time.Unix(start, 0).UnixMilli())
q.Lte(time.Unix(end, 0).UnixMilli())
q.Format("epoch_millis")
//......
//生成bool查询并基于fiter构建出must子句,传入q即将range查询存入filter子句中
/**
"query": {
"bool": {
"filter": {
"range": {
"timestamp": {
"format": "epoch_millis",
"from": 1762353000000,
"include_lower": true,
"include_upper": true,
"to": 1762353600000
}
}
},
"must": {
"query_string": {
"query": "log_level:"ERROR""
}
}
}
}
*/
queryString := GetQueryString(param.Filter, q)
var aggr elastic.Aggregation
switch param.MetricAggr.Func {
case "avg":
aggr = elastic.NewAvgAggregation().Field(field)
//......
aggr = elastic.NewSumAggregation().Field(field)
case "count":
aggr = elastic.NewValueCountAggregation().Field(field)
//......
default:
return nil, fmt.Errorf("func %s not support", param.MetricAggr.Func)
}
//生成聚合桶查询,每个桶至少要有一个文档,少了就不显示
tsAggr := elastic.NewDateHistogramAggregation().
Field(param.DateField).
MinDocCount(1)
//......
//构建查询参数
searchSource := elastic.NewSearchSource().
Query(queryString).
Aggregation("ts", tsAggr) //设置自定义聚合名称为ts
//......
//发起请求
result, err := search(ctx, indexArr, searchSource, param.Timeout, param.MaxShard)
//......
/** 提取ts中的bucket桶提取count和key也就是时间生成item返回
"aggregations" : {
"ts" : {
"buckets" : [
{
"key_as_string" : "2025-11-05T14:30:00.000Z",
"key" : 1762353000000,
"doc_count" : 10
}
]
}
}
*/
js, err := simplejson.NewJson(result.Aggregations["ts"])
//......
bucketsData, err := js.Get("buckets").Array()
return items, nil
}告警规则添加
了解了规则配置解析之后,我们再来了解后续步骤,即如何将规则持久化到Nightingale底层的数据库中,让告警监控的工作协程能够获取到这个规则进行定时查询和告警消息缓存。
对应的我们通过浏览器控台定位到接口映射为http://127.0.0.1:17000/api/n9e/busi-group/1/alert-rules,请求参数为一个比较大的JSON数组,为了更好的说明和解析,这里笔者也给出几个比较核心的部分以便于读者更准确的理解规则的存储过程。
先来看看参数的第一部分,可以看到这个规则通过cate即category指明数据源类型为elasticsearch,并通过datasource这个数组块指明等价匹配数据源-1也就是elasticsearch
json
"cate": "elasticsearch",
"datasource_queries": [{
"match_type": 0, //精确匹配
"op": "in", //包含关系
"values": [
1 //数据源1也就是我们配置的elasticsearch
]
}],然后就是规则配置,对应的rule_config的JSON参数如下,这里笔者抽出核心的两个部分,第一个部分也就是上面规则查询的参数,对应的明细笔者上文已经详细解释过了,这里就不多做赘述,这里我们着重说明一下trigger,其内部有个expressions结合3个参数语义和浏览器界面即知晓这个就是触发条件的配置,他告知Nightingale在查询count大于0的时候即可触发告警:
python
"rule_config": {
"queries": [{ //查询条件参数
"prom_ql": "",
"severity": 2,
"ref": "A",
"index_type": "index",
"value": {
"func": "count"
},
"unit": "none",
"index": "java_app_logs",
"date_field": "timestamp",
"filter": "log_level:"ERROR"",
"interval": 1800
}],
//.......
"triggers": [{
"mode": 0,
"expressions": [{ //当规则A查出来的值大于0时触发告警
"ref": "A",
"comparisonOperator": ">",
"value": 0,
"logicalOperator": "&&"
}],
"severity": 1, //一级告警
"recover_config": {
"judge_type": 0
},
"join_ref": "A",
"exp": "$A > 0"
}],
//.......
},最后一个部分也就是规则配置的调度算法,对应参数如下:
cron_pattern指明每15s执行一次prom_for_duration:持续时间为60s也就是4次调度都触发告警与之则告警enable_days_of_weeks:执行周期为一整周即周一到周日都有enable_stimes: 开始时间enable_etimes:结束时间
perl
"cron_pattern": "@every 15s",
"prom_for_duration": 60,
"enable_days_of_weeks": [
[
"0",
"1",
"2",
"3",
"4",
"5",
"6"
]
],
"enable_stimes": [
"00:00"
],
"enable_etimes": [
"00:00"
],明确参数后,我们通过接口映射定位到后端的执行函数,也就是alertRuleAddByFE方法,这里笔者也贴出接口对应的映射配置和实际执行函数,保存规则的逻辑比较简单,即:
- 解析参数并判空
- 调用
alertRuleAdd保存规则 - 返回执行结果
go
pages.POST("/busi-group/:id/alert-rules", rt.auth(), rt.user(), rt.perm("/alert-rules/add"), rt.bgrw(), rt.alertRuleAddByFE)
func (rt *Router) alertRuleAddByFE(c *gin.Context) {
username := c.MustGet("username").(string)
var lst []models.AlertRule
//解析参数列表存储到lst这个规则结构体中
ginx.BindJSON(c, &lst)
//如果参数为空直接返回异常
count := len(lst)
if count == 0 {
ginx.Bomb(http.StatusBadRequest, "input json is empty")
}
bgid := ginx.UrlParamInt64(c, "id") //获取对应group id
//调用alertRuleAdd保存规则
reterr := rt.alertRuleAdd(lst, username, bgid, c.GetHeader("X-Language"))
//将结果渲染返回
ginx.NewRender(c).Data(reterr, nil)
}宏观的了解整个流程之后,我们还是需要深入细节了解alertRuleAdd实现细节,其实这段逻辑和我们java开发日常的crud接口都差不多,本质上就是将参数绑定到go语言的dto上保存到数据库(默认为sqllite),对应的映射转换细节如下:
- EnableStime和EnableEtime作为任务起止时间直接平迁
- 执行周期转为空格分隔
- 核心的告警规则查询条件和调度时间配置json即rule config直接序列化为JSON写入
几个核心转换过程笔者也已图解的方式展示了一下,读者结合说明了解一下:
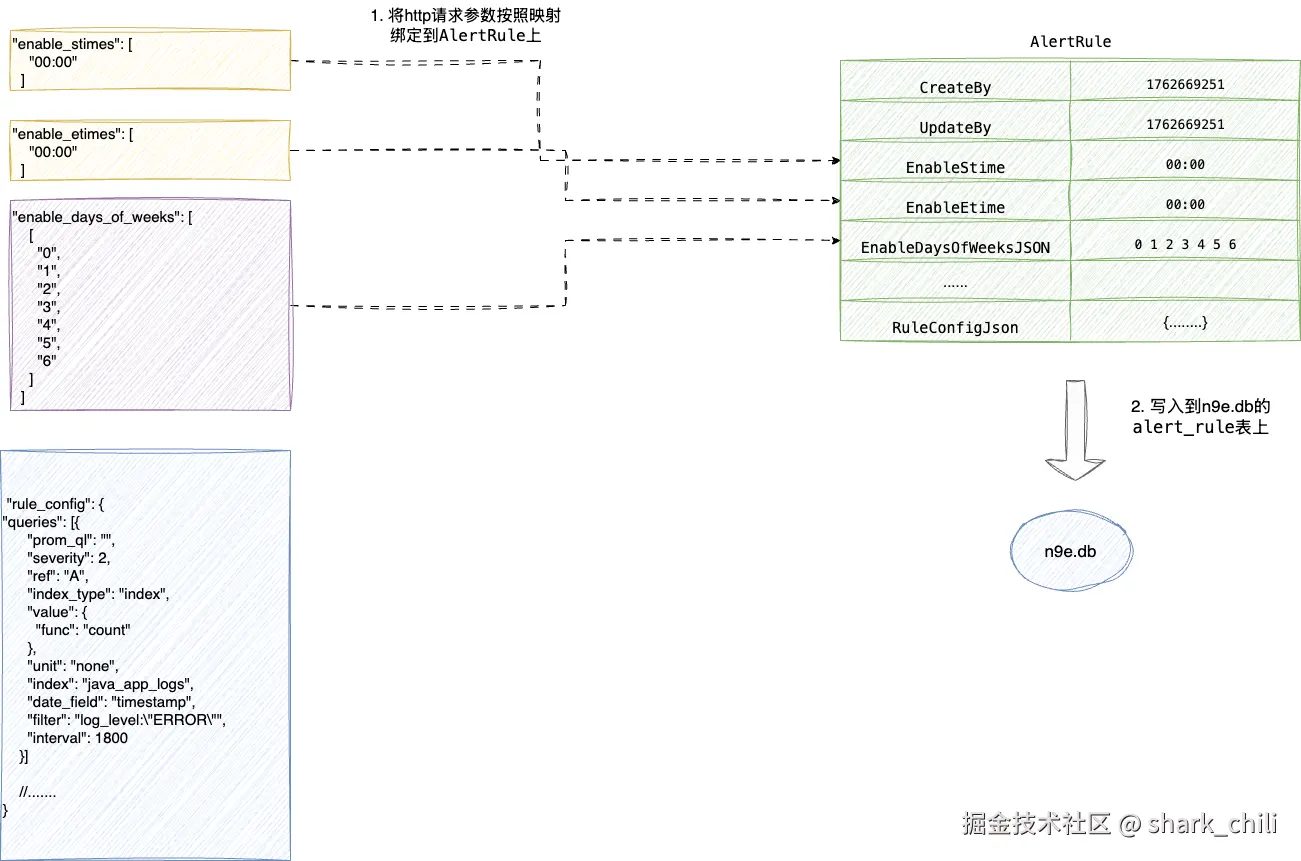
对应笔者也给出router_alert_rule.go中alertRuleAdd的实现,可以看到如下步骤:
- 这个函数内部设置了
alertRule对象的CreateBy和UpdateBy - 调用
FE2DB生执行前端参数转为上图所示的数据结构 - 然后
AlertRule调用Add写入db中,很明显这种设计让AlertRule具备持久化的能力,是一种具备充血模型的设计理念
go
func (rt *Router) alertRuleAdd(lst []models.AlertRule, username string, bgid int64, lang string) map[string]string {
count := len(lst) //获取对应的规则切片长度
// alert rule name -> error string
reterr := make(map[string]string)
for i := 0; i < count; i++ {
lst[i].Id = 0 //设置规则id和配置用户名信息
lst[i].GroupId = bgid
if username != "" {
lst[i].CreateBy = username //绑定创建人username也就是root
lst[i].UpdateBy = username //绑定修改人username也就是root
}
//价格lst转为封装db字段信息,例如起止时间 执行规则配置等信息,如果某条报错直接结束循环
if err := lst[i].FE2DB(); err != nil {
reterr[lst[i].Name] = i18n.Sprintf(lang, err.Error())
continue
}
//存入数据库,返回写入结果
if err := lst[i].Add(rt.Ctx); err != nil {
reterr[lst[i].Name] = i18n.Sprintf(lang, err.Error())
} else {
reterr[lst[i].Name] = ""
}
}
return reterr
}结合上述的整体说明笔者也给出FE2DB的函数实现细节,大体就是上图所示的映射转换,读者可结合注释回顾一下:
perl
func (ar *AlertRule) FE2DB() error {
//如果起止时间存在则将起止时间设置到调用的ar上,也就是我们配置的enable_stimes和enable_etimes
if len(ar.EnableStimesJSON) > 0 {
ar.EnableStime = strings.Join(ar.EnableStimesJSON, " ")
ar.EnableEtime = strings.Join(ar.EnableEtimesJSON, " ")
} else {
ar.EnableStime = ar.EnableStimeJSON
ar.EnableEtime = ar.EnableEtimeJSON
}
//按照空格设置启用的星期,按照空格进行拼接,对应参数为 "enable_days_of_weeks": [
// [
// "0",
// "1",
// "2",
// "3",
// "4",
// "5",
// "6"
// ]
// ],
if len(ar.EnableDaysOfWeeksJSON) > 0 {
for i := 0; i < len(ar.EnableDaysOfWeeksJSON); i++ {
if len(ar.EnableDaysOfWeeksJSON) == 1 {
ar.EnableDaysOfWeek = strings.Join(ar.EnableDaysOfWeeksJSON[i], " ")
} else {
if i == len(ar.EnableDaysOfWeeksJSON)-1 {
ar.EnableDaysOfWeek += strings.Join(ar.EnableDaysOfWeeksJSON[i], " ")
} else {
ar.EnableDaysOfWeek += strings.Join(ar.EnableDaysOfWeeksJSON[i], " ") + ";"
}
}
}
} else {
ar.EnableDaysOfWeek = strings.Join(ar.EnableDaysOfWeekJSON, " ")
}
//......
//将rule_config转为json串绑定到RuleConfig上
if ar.RuleConfigJson != nil {
b, err := json.Marshal(ar.RuleConfigJson)
if err != nil {
return fmt.Errorf("marshal rule_config err:%v", err)
}
//绑定rule规则 "rule_config": {
// "queries": [{
// "prom_ql": "",
// "severity": 2,
// "ref": "A",
// "index_type": "index",
// "value": {
// "func": "count"
// },
// "unit": "none",
// "index": "java_app_logs",
// "date_field": "timestamp",
// "filter": "log_level:"ERROR"",
// "interval": 1800
// }],
ar.RuleConfig = string(b)
ar.PromQl = ""
}
//......
return nil
}基于FE2DB生成数据映射对象后,就需要进行持久化,按照笔者的说法该模型会调用内置的Add将结构体持久化,对应的方法也位于alert_rule.go文件的Add:
go
func (ar *AlertRule) Add(ctx *ctx.Context) error {
//......
//设置创建时间和更新时间
now := time.Now().Unix()
ar.CreateAt = now
ar.UpdateAt = now
//写入数据库 写入到alert_rule表
return Insert(ctx, ar)
}最终我们也可以在alert_rule看到这份信息:

轮询监控告警工作过程
完成的查询的任务创建之后,就到了Nightingale中最重要的一环,即基于规则进行告警监控,这个过程本质就是上述两个步骤的综合配置结果,即通过规则配置和插入,结合用户调测配置的查询规则进行周期性轮询并,针对查到的数据进行阈值判断,一旦发现结果超出阈值,则将结果写入缓存队列中,后续各种告警手段都会基于这个缓存进行告警输出。
这里笔者也给出Nightingale告警的宏观流程:
- 基于之前写入数据库且缓存的rule对象生成job提交到调取器
scheduler中 scheduler定期执行这个jobjob向elasticsearch发起请求获取结果- 将触发阈值的结果封装成
DataResp写入缓存seriesStore中 - 遍历
seriesStore将其封装成事件写入一个协程安全的队列eventQueue中 - 后续
Nightingale就会基于这个队列缓存进行数据库持久化或者告警操作
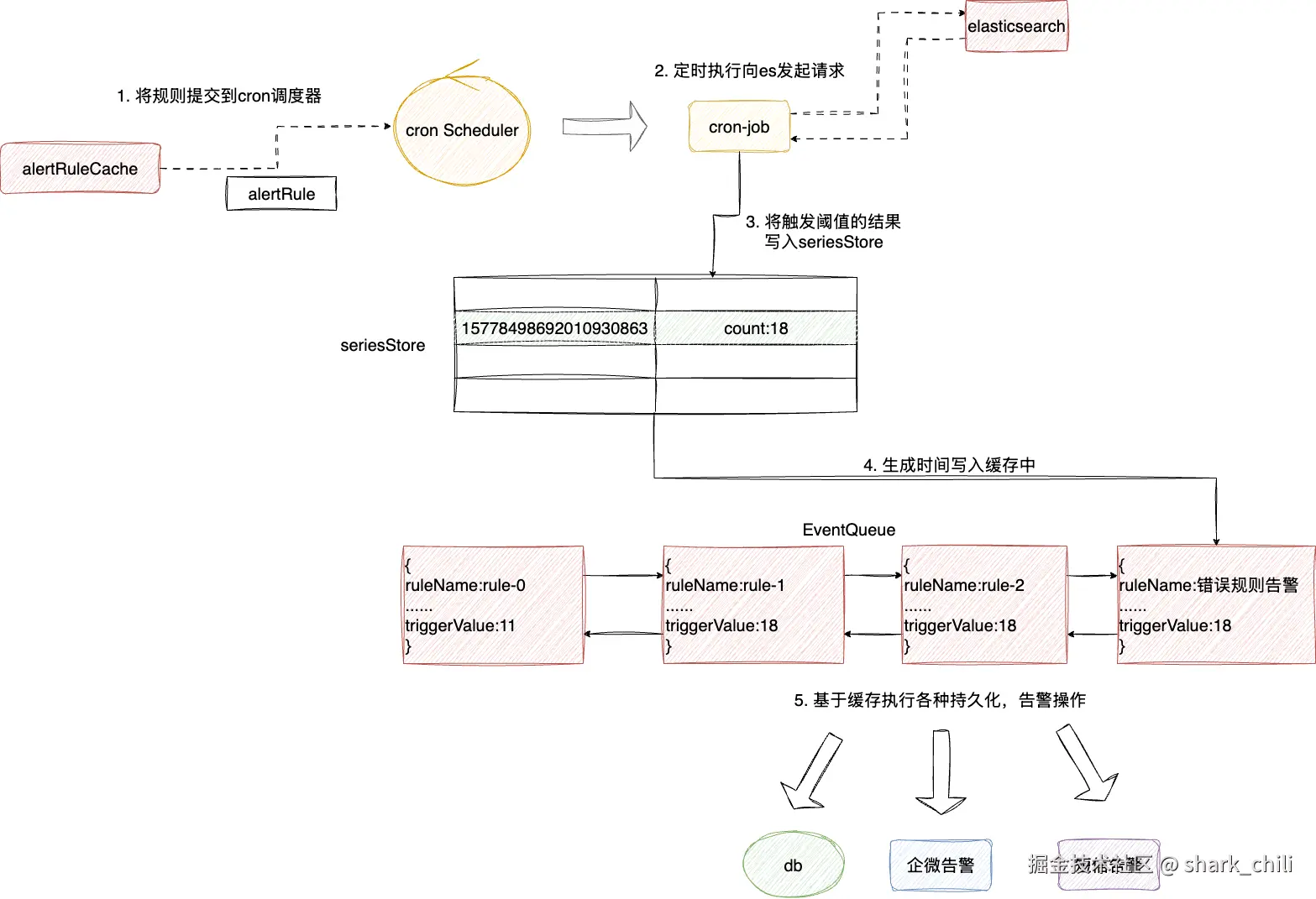
对应的我们先给出从缓存中获取rule并将其提交到调度器scheduler的代码,即位于alert_rule.go下的syncAlertRules函数,逻辑比较简单,从alertRuleCache拉取到规则后调用NewAlertRuleWorker提交到调度器即可:
go
func (s *Scheduler) syncAlertRules() {
//从缓存中拿到rule
ids := s.alertRuleCache.GetRuleIds()
//.....
//基于id拿到rule具体信息
for _, id := range ids {
rule := s.alertRuleCache.Get(id)
//.....
ruleType := rule.GetRuleType()
if rule.IsPrometheusRule() || rule.IsInnerRule() {
//.....
for _, dsId := range datasourceIds {
//.....
//封装成cronjob添加
alertRule := NewAlertRuleWorker(rule, dsId, processor, s.promClients, s.ctx)
alertRuleWorkers[alertRule.Hash()] = alertRule
}
} else if rule.IsHostRule() {
//.....
} else {
//.....
}
}后续就会有一个协程定时调用eval.go的Eval方法,通过GetAnomalyPoint发起es查询,如果存在异常端点事件,则将其通过Processor.Handle封装成event缓存起来,等待Nightingale底层各种协程进行持久化、告警操作,对应笔者给出这几个步骤的核心代码断,读者可以结合注释了解一下:
go
func (arw *AlertRuleWorker) Eval() {
//......
//根据数据源类型获取异常点anomalyPoints
switch typ {
case models.PROMETHEUS:
//......
default:
//触发es查询,anomalyPoints就是异常的端点信息(如果存在的话)
anomalyPoints, recoverPoints, err = arw.GetAnomalyPoint(cachedRule, arw.Processor.DatasourceId())
}
//......
} else {
//......
}
//处理异端点数据anomalyPoints,将其封装成event缓存,等待后续告警 持久化等各种操作
arw.Processor.Handle(anomalyPoints, "inner", arw.Inhibit)
}对应的笔者也给出GetAnomalyPoint的实现细节,逻辑比较简单,整体就是触发es查询即QueryData(上文告警规则调测介绍过,其底层es查询的逻辑),然后将其写入seriesStore中,然后结合rule对象通过parser.CalcWithRid查看结果是否触发阈值,如果触发则存入异常端点的切片points中返回:
go
func (arw *AlertRuleWorker) GetAnomalyPoint(rule *models.AlertRule, dsId int64) ([]models.AnomalyPoint, []models.AnomalyPoint, error) {
//......
//触发es查询即可得到 异常端点的时间点和count
series, err := plug.QueryData(ctx, query)
//......
for i := 0; i < len(series); i++ {
//计算es结果的hash
serieHash := hash.GetHash(series[i].Metric, series[i].Ref)
//计算tag hash
tagHash := hash.GetTagHash(series[i].Metric)
//将本次count查询结果存储到序列桶中
seriesStore[serieHash] = series[i]
//......
//将series的hash写入到seriesTagIndex中
seriesTagIndex[tagHash] = append(seriesTagIndex[tagHash], serieHash)
}
//......
}
//......
if !ruleQuery.ExpTriggerDisable {
for _, trigger := range ruleQuery.Triggers {
//......
//从标签seriesTagIndex中获取series的hash值
for _, seriesHash := range seriesTagIndex {
//......
//通过表达式结合查询结果查看是否满足条件
isTriggered := parser.CalcWithRid(trigger.Exp, m, rule.Id)
//......
//将结果封装成point,并追加到切片中
point := models.AnomalyPoint{
Key: sample.MetricName(),
Labels: sample.Metric,
Timestamp: int64(ts),
Value: value,
Values: values,
Severity: trigger.Severity,
Triggered: isTriggered,
Query: fmt.Sprintf("query:%+v trigger:%+v", queries, trigger),
RecoverConfig: trigger.RecoverConfig,
ValuesUnit: valuesUnitMap,
}
//如果符合条件则将其追加到points中
if isTriggered {
points = append(points, point)
} else {
//......
}
}
}
}
//......
//返回point
return points, recoverPoints, nil
}最后就是事件告警了,逻辑比较简单,基于上一步的异常端点anomalyPoints遍历生成event写入缓存中:
go
func (p *Processor) Handle(anomalyPoints []models.AnomalyPoint, from string, inhibit bool) {
//......
// 遍历anomalyPoints,根据 event 的 tag 将 events 分组,处理告警抑制的情况
eventsMap := make(map[string][]*models.AlertCurEvent)
for _, anomalyPoint := range anomalyPoints {
//封装成事件
event := p.BuildEvent(anomalyPoint, from, now, ruleHash) //基于异常点生成告警事件
//......
}
//......
//将anomalyPoint哈希运算存入eventsMap
tagHash := TagHash(anomalyPoint)
//追加到对应tagHash(也就是我们的规则标签的hash)
eventsMap[tagHash] = append(eventsMap[tagHash], event)
}
//遍历告警事件的map并处理事件,其底层就是将其存入到一个协程安全的缓存队列中
for _, events := range eventsMap {
p.handleEvent(events)
}
//......
}小结
本文详细的介绍了Nightingale的日志告警规则配置和实现细节,基于这个契机,笔者也来谈谈读者常问的一个问题------如何较好的去掌握一门技术,作为一个计算机从业者,私以为学习一门技术的本质无非是想尽一切去了解它,让自己拥有白盒的视角去看待这些原本黑盒的技术。
以本次Nightingale这个告警框架为例,读者可以非常直观的看到笔者的学习过程,本质上就是:
- 结合一手官网的文档去学习和应用
- 通过这些应用找到请求入口
- 结合入口定位到源码入口并针对每个接口的实现细节进行阅读和具象化梳理
最终读者眼中的这些工具,在笔者眼里就变为一个http请求在go应用框架的协程中的各种数据流扭转和es交互请求和响应,后续无论是运用还是问题排查也都是以这种视角游刃有余的去使用和排查。
总结源码 结合接口推断保存查询 数据流向哪里来 推测告警或者动作的源头 从而了解源码原理
我是 SharkChili ,Java 开发者,Java Guide 开源项目维护者。欢迎关注我的公众号:写代码的SharkChili ,也欢迎您了解我的开源项目 mini-redis:github.com/shark-ctrl/...。
为方便与读者交流,现已创建读者群。关注下方公众号获取我的联系方式,添加时备注加群即可加入。
参考
夜莺监控官网:n9e.github.io/zh/docs/pro...
夜莺告警规则配置:flashcat.cloud/docs/conten...
夜莺日志告警:n9e.github.io/zh/docs/usa...
使用SkyWalking和Elasticsearch实现全链路监控 :help.aliyun.com/zh/es/use-c...
《Elasticsearch实战第二版》
一篇文章学会黑盒测试、白盒测试(含实操) :blog.csdn.net/u010924879/...
DDD领域驱动设计:贫血模型和充血模型 :zhuanlan.zhihu.com/p/464914100
JSON文件加注释的7种方法 :blog.csdn.net/Dream_fengy...
本文使用 markdown.com.cn 排版