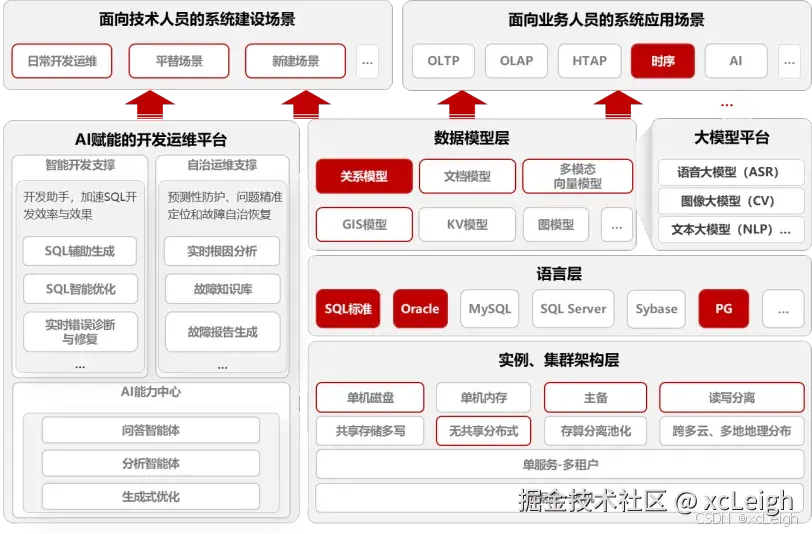
数字经济时代,数据类型繁杂、迁移困难、运维复杂等问题让企业备受困扰。金仓数据库深耕四十余年,推出 "五个一体化" 融合架构,用一套系统破解多场景数据管理难题。该架构实现多语法兼容,Oracle、MySQL 等主流数据库语法无缝适配,迁移零成本;支持关系、JSON、GIS、向量等多模数据统一存储查询,打破数据孤岛;覆盖交易、分析、AI 推理等全场景,无需拆分系统;集中与分布式架构灵活切换,适配不同业务规模;开发运维工具一体化,大幅降本增效。目前,该架构已在能源、金融、交通等多行业落地,凭借查询快、成本低、稳定性强的优势,成为企业数字化转型的可靠支撑,助力数据价值充分释放。

现在数字经济发展得越来越快,数据早就成了企业最核心的战略资产。互联网、物联网、AI这些技术用得越来越深,数据一下子变得又多又杂,还得实时处理,传统数据库那套"只能适配一种模式、架构零散、运维麻烦"的问题,现在看越来越突出。咱们国产数据库里的领头羊金仓,抓住"融合"这个关键点,搞出了"五个一体化"架构,一套系统就能搞定各种场景的数据管理问题,给企业数字化转型托底。
 10多个实际能用的代码案例,还有5个行业里真正落地的场景,像多语法兼容、多模数据处理、分布式部署这些核心需求都覆盖到了,技术同学看了就能快速上手用起来。
10多个实际能用的代码案例,还有5个行业里真正落地的场景,像多语法兼容、多模数据处理、分布式部署这些核心需求都覆盖到了,技术同学看了就能快速上手用起来。
一、数据库绕不开的三个难题
数字化转型越往深走,数据库就不只是存数据那么简单了。现在企业管数据,基本上都要面对三个头疼事:
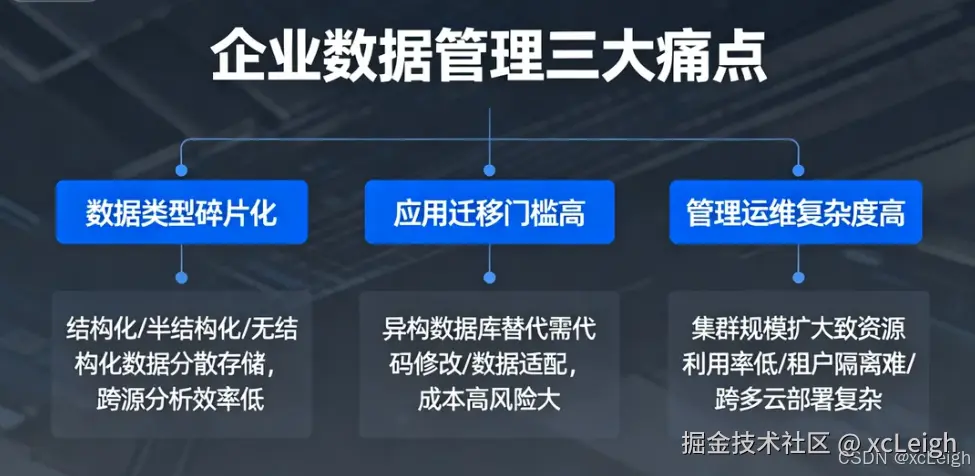
- 数据类型太散:以前的结构化数据就不说了,现在还有JSON文档这种半结构化的、日志这种无结构的,加上GIS地理数据、时序监控数据、向量特征数据,乱七八糟的都存在不同数据库里,想跨着查点东西特别费劲。
- 迁移起来太麻烦:企业搞数字化,经常要换不同类型的数据库。传统的迁移方式得改一堆代码、适配数据,又费钱又容易出问题,跟"住着人的房子里重装地暖"一样折腾。
- 管理运维太复杂:业务越做越大,数据库集群也跟着扩,分散的架构导致资源浪费、不同用户的数据难隔离、跨多个云部署也麻烦,运维成本一直降不下来。
面对这些问题,数据库行业肯定要"合"起来,这是躲不开的趋势。金仓做数据库四十多年了,技术积累够深,推出的"五个一体化"融合架构,就是要解决"一款数据库搞定所有事"这个核心需求。
二、五个一体化:金仓融合数据库的核心架构(带实际代码)
金仓数据库KES产品用的是松耦合、能扩展的五化技术平台架构,从五个方面深度融合,不管什么场景的数据管理都能覆盖到。下面结合实际代码和具体场景,跟大家说清楚每个架构怎么用。
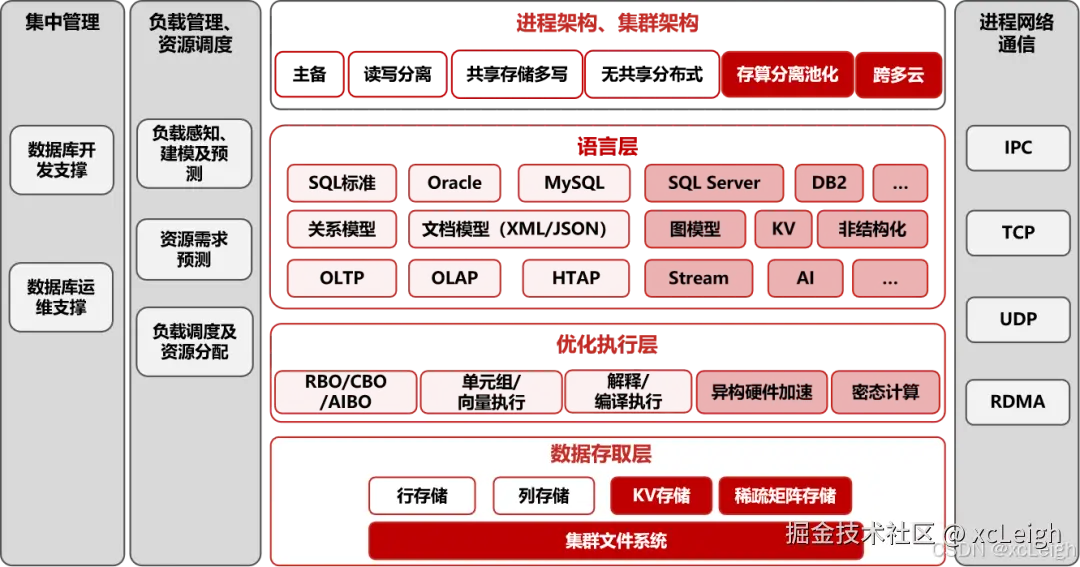
1. 多语法一起兼容:不用额外花钱就能换数据库
迁移数据库最麻烦的就是语法不兼容,不同数据库的SQL语法、存储过程、函数都不一样。金仓数据库特意做了多语法一体化兼容,Oracle、MySQL、SQL Server这些主流的语法都支持,应用代码不用改就能直接迁过来。
实际用例1:Oracle存储过程直接就能跑
有个金融机构,想把Oracle数据库里"更新用户账户余额"的存储过程迁到金仓,结果一行代码没改就跑通了:
plsql
-- Oracle风格存储过程(金仓直接兼容运行)
CREATE OR REPLACE PROCEDURE update_user_balance(
p_user_id IN NUMBER,
p_amount IN NUMBER,
p_result OUT VARCHAR2
) AS
v_current_balance NUMBER;
BEGIN
-- 查询当前余额(兼容Oracle ROWNUM语法)
SELECT balance INTO v_current_balance
FROM user_account
WHERE user_id = p_user_id AND ROWNUM = 1;
-- 更新余额(兼容Oracle MERGE语法)
MERGE INTO user_account a
USING (SELECT p_user_id AS user_id, v_current_balance + p_amount AS new_balance FROM DUAL) b
ON (a.user_id = b.user_id)
WHEN MATCHED THEN UPDATE SET a.balance = b.new_balance;
p_result := 'SUCCESS';
EXCEPTION
WHEN NO_DATA_FOUND THEN
p_result := 'USER_NOT_FOUND';
WHEN OTHERS THEN
p_result := 'ERROR: ' || SQLERRM;
END;
/
-- 调用存储过程(兼容Oracle EXEC语法)
DECLARE
v_res VARCHAR2(100);
BEGIN
EXEC update_user_balance(1001, 500, v_res);
DBMS_OUTPUT.PUT_LINE(v_res); -- 输出:SUCCESS
END;
/实际用例2:MySQL客户端直接连金仓
一家互联网公司一直用MySQL客户端,想连金仓数据库,结果连接代码和SQL语句都没改,直接就连上了:
python
# MySQL风格Python连接代码(直接连接金仓)
import pymysql
# 连接金仓数据库(使用MySQL协议与端口)
conn = pymysql.connect(
host='192.168.1.100',
port=3306, # 金仓兼容MySQL端口
user='test',
password='Test@123',
db='ecommerce',
charset='utf8mb4'
)
# 执行MySQL风格SQL(兼容LIMIT、GROUP_CONCAT)
with conn.cursor() as cursor:
sql = """
SELECT order_id, GROUP_CONCAT(product_name) AS product_list
FROM orders
WHERE create_time > '2025-01-01'
GROUP BY order_id
LIMIT 10;
"""
cursor.execute(sql)
result = cursor.fetchall()
for row in result:
print(f"订单ID: {row[0]}, 商品列表: {row[1]}")
conn.close()2. 多模数据一起存:不用跨库就能查各种数据
金仓数据库能把关系、文档、图、时序、GIS、向量这些不同类型的数据放在一起存,还能混合查询,不用再搞复杂的跨库集成,就能把不同类型的数据关联起来分析。
实际用例3:关系数据和JSON文档一起查
某电商平台想查"用户基本信息+最近3条订单详情",订单详情是用JSON格式存的,直接用一条SQL就查出来了:
sql
-- 1. 创建含JSON字段的表(金仓原生支持JSONB类型)
CREATE TABLE users (
user_id INT PRIMARY KEY,
username VARCHAR(50) NOT NULL,
user_info JSONB, -- 存储用户地址、电话等半结构化数据
register_time TIMESTAMP
);
CREATE TABLE orders (
order_id INT PRIMARY KEY,
user_id INT REFERENCES users(user_id),
order_detail JSONB, -- 存储订单商品、金额等详情
create_time TIMESTAMP
);
-- 2. 插入多模数据
INSERT INTO users VALUES (
1001,
'zhangsan',
'{"phone": "13800138000", "address": "北京市海淀区中关村"}',
'2025-01-10'
);
INSERT INTO orders VALUES (
20001,
1001,
'{"products": [{"name": "笔记本电脑", "price": 5999}, {"name": "鼠标", "price": 99}], "total": 6098}',
'2025-02-01'
);
-- 3. 混合查询(关系字段+JSON属性过滤+聚合)
SELECT
u.user_id,
u.username,
u.user_info->>'$.phone' AS phone, -- 提取JSON属性
COUNT(o.order_id) AS order_count,
ARRAY_AGG(o.order_detail->>'$.total') AS order_totals -- 聚合JSON属性
FROM users u
LEFT JOIN orders o ON u.user_id = o.user_id
WHERE o.create_time BETWEEN '2025-01-01' AND '2025-03-01'
GROUP BY u.user_id, u.username, u.user_info->>'$.phone';实际用例4:时序数据和GIS空间数据一起查
某智慧交通平台要查"2025-10-01 08:00-09:00之间,在上海虹桥机场5公里内行驶的出租车轨迹",用金仓的时序+GIS融合功能直接就实现了:
sql
-- 1. 创建时序+GIS混合表(金仓原生支持TIMESTAMPTZ、GEOGRAPHY类型)
CREATE TABLE taxi_trajectory (
taxi_id VARCHAR(20) NOT NULL,
track_time TIMESTAMPTZ NOT NULL, -- 时序时间字段
location GEOGRAPHY(POINT) NOT NULL, -- GIS地理坐标(经纬度)
speed NUMERIC(5,1),
PRIMARY KEY (taxi_id, track_time) -- 时间+业务维度分区键
) PARTITION BY RANGE (track_time); -- 按时间分区
-- 2. 创建分区(按天分区)
CREATE TABLE taxi_trajectory_20251001 PARTITION OF taxi_trajectory
FOR VALUES FROM ('2025-10-01') TO ('2025-10-02');
-- 3. 插入轨迹数据(经纬度:虹桥机场约121.33°E, 31.19°N)
INSERT INTO taxi_trajectory VALUES (
'SH-T-12345',
'2025-10-01 08:15:30+08',
ST_SetSRID(ST_MakePoint(121.33, 31.19), 4326), -- 构建GIS点
45.5
);
-- 4. 时空混合查询(时间范围+空间距离过滤)
SELECT
taxi_id,
track_time,
ST_AsText(location) AS location, -- 转换为可读经纬度
speed,
ST_Distance(
location,
ST_SetSRID(ST_MakePoint(121.33, 31.19), 4326) -- 虹桥机场坐标
) / 1000 AS distance_km -- 计算距离(单位:公里)
FROM taxi_trajectory
WHERE
track_time BETWEEN '2025-10-01 08:00:00+08' AND '2025-10-01 09:00:00+08'
AND ST_Distance(
location,
ST_SetSRID(ST_MakePoint(121.33, 31.19), 4326)
) <= 5000; -- 筛选5公里内数据实际用例5:向量数据和文本语义一起查
有个做AI的公司想实现"文本语义搜索",把文本转成向量存起来,通过向量相似度找相似文本,用金仓的向量存储功能很快就实现了:
sql
-- 1. 创建向量表(金仓支持VECTOR类型,适配AI场景)
CREATE TABLE text_vectors (
id INT PRIMARY KEY,
content TEXT NOT NULL, -- 原始文本
vec VECTOR(768) NOT NULL -- 768维向量(如BERT模型输出)
);
-- 2. 创建向量索引(HNSW算法,优化相似度查询性能)
CREATE INDEX idx_text_vec ON text_vectors USING HNSW (vec vector_cosine_ops);
-- 3. 插入向量数据(模拟BERT生成的向量)
INSERT INTO text_vectors VALUES (
1,
'金仓数据库支持多模数据一体化存储',
'[0.123, 0.456, ..., 0.789]' -- 768维向量省略
);
INSERT INTO text_vectors VALUES (
2,
'国产数据库领军者推出融合架构',
'[0.234, 0.567, ..., 0.890]'
);
-- 4. 向量语义检索(查询与目标文本最相似的3条记录)
-- 目标文本:"金仓推出多模融合数据库架构"(模拟其向量)
SELECT
id,
content,
vector_cosine_distance(vec, '[0.189, 0.512, ..., 0.834]') AS similarity -- 计算余弦相似度
FROM text_vectors
ORDER BY similarity ASC -- 相似度越小越相似
LIMIT 3;3. 多场景一起处理:不管什么业务需求都能覆盖
金仓数据库能同时处理OLTP(交易)、OLAP(分析)、流处理、AI推理这些场景,不用把系统拆分开,就能实现实时决策。
实际用例6:实时交易和实时分析一起查
某零售企业想实时查"库存不足10件,且近7天销量前50的商品",用金仓的HTAP混合查询功能,一条SQL就搞定了:
sql
-- 1. 创建商品表(支持交易场景)
CREATE TABLE products (
product_id INT PRIMARY KEY,
product_name VARCHAR(100) NOT NULL,
stock INT NOT NULL, -- 实时库存(OLTP字段)
category VARCHAR(50)
);
-- 2. 创建销售流水表(时序数据,支持分析场景)
CREATE TABLE sales_flow (
flow_id BIGSERIAL PRIMARY KEY,
product_id INT REFERENCES products(product_id),
sale_time TIMESTAMP NOT NULL,
sale_num INT NOT NULL,
sale_amount NUMERIC(10,2)
);
-- 3. HTAP混合查询(实时库存过滤+近7天销量分析)
SELECT
p.product_id,
p.product_name,
p.stock,
SUM(s.sale_num) AS 7d_sale_num -- 近7天销量(OLAP分析)
FROM products p
LEFT JOIN sales_flow s
ON p.product_id = s.product_id
AND s.sale_time >= CURRENT_TIMESTAMP - INTERVAL '7 days'
WHERE p.stock < 10 -- 实时库存过滤(OLTP交易字段)
GROUP BY p.product_id, p.product_name, p.stock
ORDER BY 7d_sale_num DESC
LIMIT 50;4. 集中和分布一起用:不管业务大小都能适配
金仓数据库支持主备、读写分离、分布式这些部署模式,业务小的时候用集中式,业务大了就扩成分布式,特别灵活。下面给大家看个分布式部署的实际案例。
实际用例7:按区域分片的分布式分表
有个物流企业要存全国的物流订单数据,按"区域"分片部署分布式集群,数据自动分到不同节点,查询的时候也不用管分片,直接查就行:
sql
-- 1. 创建分布式分表规则(按region字段分片)
CREATE SHARDING TABLESPACE ts_shard1 WITH (LOCATION = 'shard1_host:5432');
CREATE SHARDING TABLESPACE ts_shard2 WITH (LOCATION = 'shard2_host:5432');
-- 2. 创建分布式表(按region哈希分片)
CREATE TABLE logistics_orders (
order_id BIGINT PRIMARY KEY,
region VARCHAR(20) NOT NULL, -- 分片键:华北、华东、华南等
consignee VARCHAR(50) NOT NULL,
create_time TIMESTAMP NOT NULL
)
SHARDING BY HASH (region) -- 哈希分片策略
SHARDING TABLESPACES (ts_shard1, ts_shard2); -- 分片存储节点
-- 3. 插入数据(自动路由到对应分片)
INSERT INTO logistics_orders VALUES (
30001,
'华北',
'Li Si',
'2025-02-10 14:30:00'
); -- 自动路由到ts_shard1
INSERT INTO logistics_orders VALUES (
30002,
'华东',
'Wang Wu',
'2025-02-10 15:45:00'
); -- 自动路由到ts_shard2
-- 4. 分布式查询(透明跨分片查询)
SELECT region, COUNT(order_id) AS order_count
FROM logistics_orders
WHERE create_time >= '2025-02-01'
GROUP BY region;5. 开发和运维一起管:又省成本又提效率
金仓数据库有KStudio(开发工具)和KOPS(运维平台),开发和运维能打通,不用各自为政。下面给大家看个自动化运维的脚本案例。
实际用例8:自动备份数据库的脚本
有个企业想每天凌晨3点自动备份数据库,还得自动清理7天前的旧备份,用KOPS的脚本很快就实现了自动化:
shell
#!/bin/bash
# 金仓KOPS自动化备份脚本(兼容Linux环境)
# 配置参数
DB_NAME="production_db"
BACKUP_DIR="/data/kingbase/backup"
DATE=$(date +%Y%m%d_%H%M%S)
BACKUP_FILE="${BACKUP_DIR}/${DB_NAME}_${DATE}.dmp"
RETENTION_DAYS=7
# 1. 创建备份目录
mkdir -p ${BACKUP_DIR}
# 2. 执行全量备份(使用金仓原生备份工具)
ksql -U sysdba -d ${DB_NAME} -c "BACKUP DATABASE ${DB_NAME} TO '${BACKUP_FILE}' WITH COMPRESSION 6;"
# 3. 检查备份是否成功
if [ $? -eq 0 ]; then
echo "[$DATE] 备份成功:${BACKUP_FILE}" >> ${BACKUP_DIR}/backup_log.txt
else
echo "[$DATE] 备份失败" >> ${BACKUP_DIR}/backup_log.txt
exit 1
fi
# 4. 清理过期备份(保留7天内数据)
find ${BACKUP_DIR} -name "${DB_NAME}_*.dmp" -mtime +${RETENTION_DAYS} -delete
echo "[$DATE] 已清理${RETENTION_DAYS}天前的旧备份" >> ${BACKUP_DIR}/backup_log.txt实际用例9:AI辅助优化SQL
用KStudio开发的时候,遇到写得不好的SQL,不用自己费劲优化,AI能自动改成高效的版本:
sql
-- 原始低效SQL(未走索引,全表扫描)
SELECT * FROM orders
WHERE create_time BETWEEN '2025-01-01' AND '2025-01-31'
AND order_status = 'PAID';
-- KStudio AI优化后SQL(自动添加索引提示,优化过滤顺序)
SELECT /*+ INDEX(orders idx_orders_create_time_status) */ -- AI推荐索引
order_id, user_id, total_amount
FROM orders
WHERE order_status = 'PAID' -- 先过滤等值条件
AND create_time BETWEEN '2025-01-01' AND '2025-01-31'; -- 再过滤范围条件
-- AI同时生成索引创建语句
CREATE INDEX idx_orders_create_time_status
ON orders (order_status, create_time)
INCLUDE (order_id, user_id, total_amount); -- 覆盖索引,避免回表三、行业里怎么用:五个一体化的实际价值
金仓"五个一体化"架构已经在很多行业用起来了,下面给大家分享5个典型的落地场景,看看实际用着效果怎么样:
1. 能源行业:智能电网调度系统
- 实际需求:要实时处理全国26个省1000多个节点的电网时序监控数据,每秒都有10万多条数据进来,还得把GIS地理定位、设备台账这些关系数据放在一起分析。
- 用金仓的方案 :
- 多模存储:把电网负荷的时序数据、变电站位置的GIS数据、设备信息的关系数据放在一起存;
- 分布式架构:按省份分片部署,能扩展到16个计算节点;
- 实际效果:查数据延迟不到1.5秒,系统已经稳定跑了16年,存储成本省了60%。
2. 金融行业:基金TA系统
- 实际需求:想换掉Oracle数据库,每天要处理百万级的基金交易订单,还得实时算净值、分析历史交易数据。
- 用金仓的方案 :
- 多语法兼容:Oracle的存储过程不用改就能迁过来,TPCC性能能到220万tpmc;
- HTAP一体化:交易订单和净值分析在一个库里处理,数据延迟不到100ms;
- 实际效果:迁移时间少了一半,运维成本降了40%,现在已经支持130多家金融机构的核心业务。
3. 交通行业:出租车轨迹监控系统
- 实际需求:要存10万辆出租车的实时轨迹数据,每天得有10亿多条,还得支持"按时间和空间查+分析违规情况"。
- 用金仓的方案 :
- 时序+GIS融合:轨迹数据按时间分区,加上R-Tree空间索引,查5公里范围内的数据不到500ms;
- 分布式分片:按区域存数据,能扩展到32个存储节点;
- 实际效果:查询速度快了10倍,存储成本省了80%,每天能支撑200多万次轨迹查询。
4. 医疗行业:医院HIS系统
- 实际需求:要存患者的电子病历(文本)、检查报告(JSON)、影像数据(向量),多个科室要共享数据,还得保护患者隐私。
- 用金仓的方案 :
- 多模存储:把患者基本信息的关系数据、检查报告的JSON数据、影像特征的向量数据放在一起管;
- 高安全特性:数据加密、动态脱敏,能满足等保四级的要求;
- 实际效果:已经在301医院这些三甲医院用起来了,查数据效率快了8倍,隐私保护完全符合规定。
5. 政务行业:城市应急管理系统
- 实际需求:要把公安、交通、消防这些多个部门的数据整合起来,遇到突发事件能实时响应,还能分析历史数据。
- 用金仓的方案 :
- 开发运维一体化:用KStudio快速做报表,用KOPS自动监控系统状态;
- 跨多云部署:一个集群能跨政务云和私有云部署,数据同步不到30秒;
- 实际效果:突发事件响应时间缩到5分钟内,多部门数据整合效率提了60%。
四、最后说几句:融合才能让数据更有价值
数字化转型说白了就是要把数据的价值发挥出来,而数据库是管数据的核心,架构好不好,直接影响数据价值能不能快速兑现。金仓的"五个一体化"架构,从语法兼容、多模融合、场景覆盖、架构弹性、运维智能这五个方面整合,把传统数据库的各种限制都打破了。
对技术同学来说,这意味着不用学好几套数据库语法,不用写复杂的跨库代码,也不用操心架构扩展会不会不兼容------一套系统、一套代码,不管什么业务场景都能覆盖到。 
以后AI技术和数据库会结合得更紧密,金仓也会继续深化"五个一体化"的能力,研究智能分片、弹性伸缩、多模态融合这些新方向。作为国产数据库的标杆,金仓一直想着"让中国数据跑在中国引擎上",希望能帮更多企业管好数据、省成本提效率,给数字经济高质量发展添把力。