前言
本文档旨在提供一个全面、细致的Hadoop部署教程,覆盖从基础环境准备到Hadoop伪分布式集群成功运行的每一个环节。内容严格遵循新手友好的原则,对每一步操作、每一条命令以及可能遇到的问题进行深入剖析,确保初学者能够顺利完成部署。整个过程将在VMware Workstation Pro虚拟机环境中,使用CentOS 7.9操作系统进行。
第一章:基础环境搭建------虚拟机与操作系统的准备
部署任何复杂的系统,一个稳定可靠的基础环境是成功的基石。本章将详细介绍如何准备用于Hadoop集群的虚拟机环境,包括VMware的配置和CentOS 7操作系统的安装。
1.1 系统镜像下载
首先,需要获取CentOS 7.9的ISO镜像文件,这是我们将要安装在虚拟机中的操作系统。可以通过访问CentOS的官方归档库来下载。
访问链接:CentOs 7.9 归档库
在该页面中,找到并点击名为CentOS-7-x86_64-DVD-2009.iso的文件进行下载。这个DVD版本包含了完整的软件包,便于后续安装。
1.2 创建新的VMware虚拟机
下载完ISO镜像后,打开VMware Workstation Pro,开始创建新的虚拟机。
-
在VMware主界面,点击"创建新的虚拟机"按钮,启动新建虚拟机向导。
-
向导类型选择"典型"即可,点击"下一步"。
-
在虚拟机硬件兼容性选择界面,保持默认的
Workstation 16.2.x或更高版本。这确保了较好的硬件支持和性能。点击"下一步"。
-
在"安装来源"步骤,选择"安装程序光盘映像文件(iso)",然后点击"浏览",定位到刚刚下载的
CentOS-7-x86_64-DVD-2009.iso文件。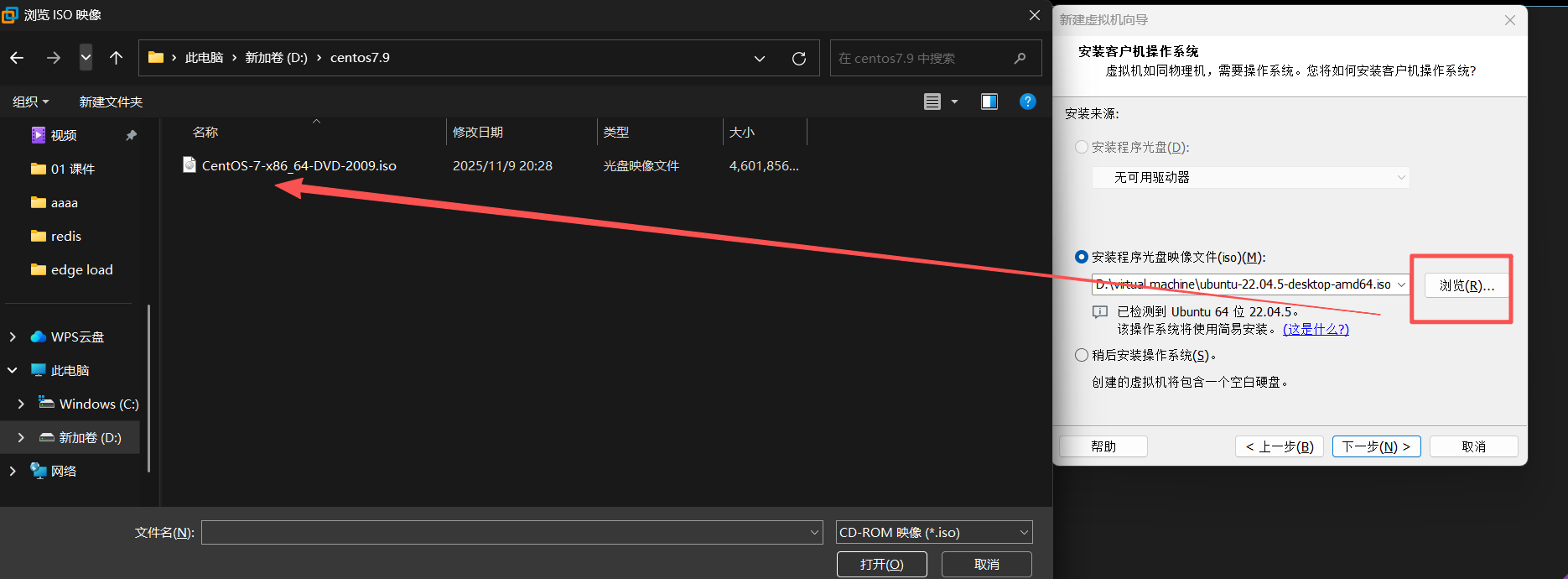
-
选择镜像文件后,VMware会识别出操作系统类型。点击"下一步"。
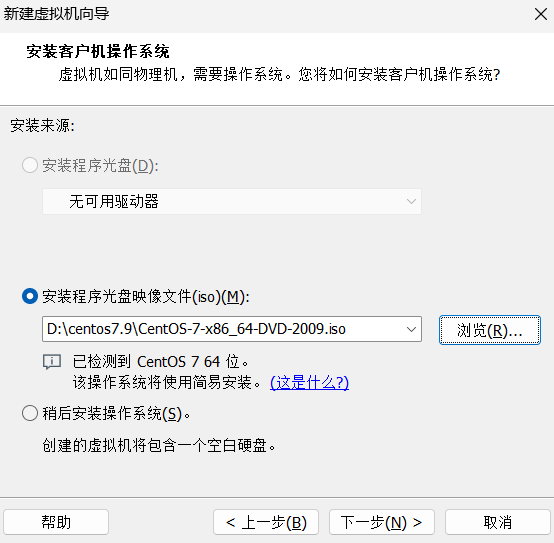
-
进入"简易安装信息"界面。这里可以预设一个用户账户和密码,VMware会在安装过程中自动创建。为了方便管理,可以设置一个容易记忆的用户名和密码。
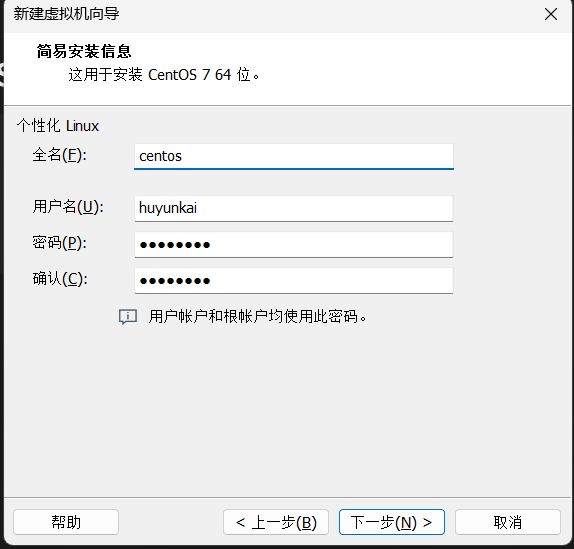
-
为虚拟机命名并选择存储位置。强烈建议将虚拟机文件存储在非系统盘(如D盘),以避免占用C盘空间,影响宿主机性能。
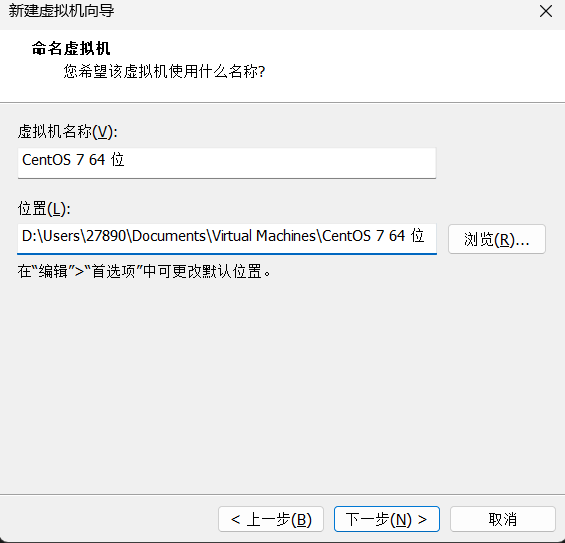
1.3 配置虚拟机硬件资源
硬件资源的分配直接影响虚拟机的运行效率,特别是对于Hadoop这样需要消耗较多计算和内存资源的系统。
-
处理器配置:根据宿主机性能,为虚拟机分配处理器核心。这里分配了4个处理器核心,这对于单节点的Hadoop学习环境是比较充足的配置。点击"下一步"。
-
内存配置:为虚拟机分配内存。这里设置为8GB。Hadoop的各个组件,尤其是NameNode和ResourceManager,对内存有一定要求,8GB可以保证伪分布式模式的流畅运行。
-
网络类型:选择"使用网络地址转换(NAT)"。NAT模式可以让虚拟机通过宿主机共享网络访问外部互联网,同时在宿主机内部形成一个独立的局域网,配置简单,是初学者的首选。
-
I/O控制器类型:保持默认的"LSI Logic (推荐)"。
-
磁盘类型:保持默认的"SCSI (推荐)"。
-
创建新虚拟磁盘:选择"创建新虚拟磁盘",因为这是一台全新的虚拟机。
-
磁盘容量:指定磁盘大小为30GB,并选择"将虚拟磁盘拆分成多个文件"。30GB对于安装操作系统、JDK、Hadoop以及存储少量测试数据是足够的。拆分文件有助于在不同文件系统的磁盘间移动虚拟机。
-
磁盘文件位置:保持默认即可,点击"下一步"。
-
完成创建:最后,向导会展示所有配置的摘要。如果需要调整,可以点击"自定义硬件"。确认无误后,点击"完成"。
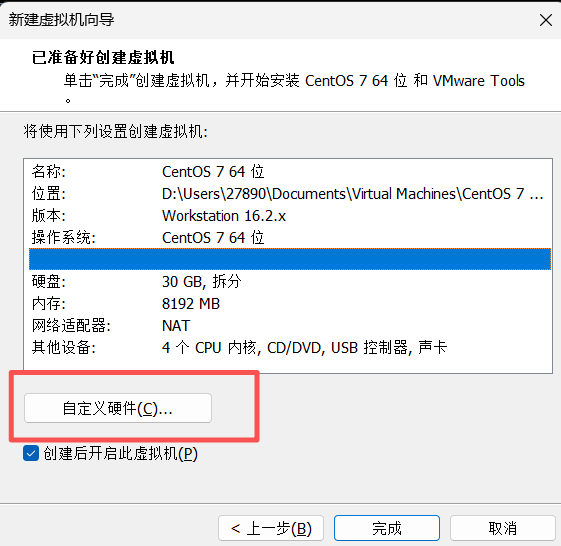
1.4 启动虚拟机并安装CentOS 7
创建完成后,在VMware主界面选中新创建的虚拟机,点击"开启此虚拟机"。
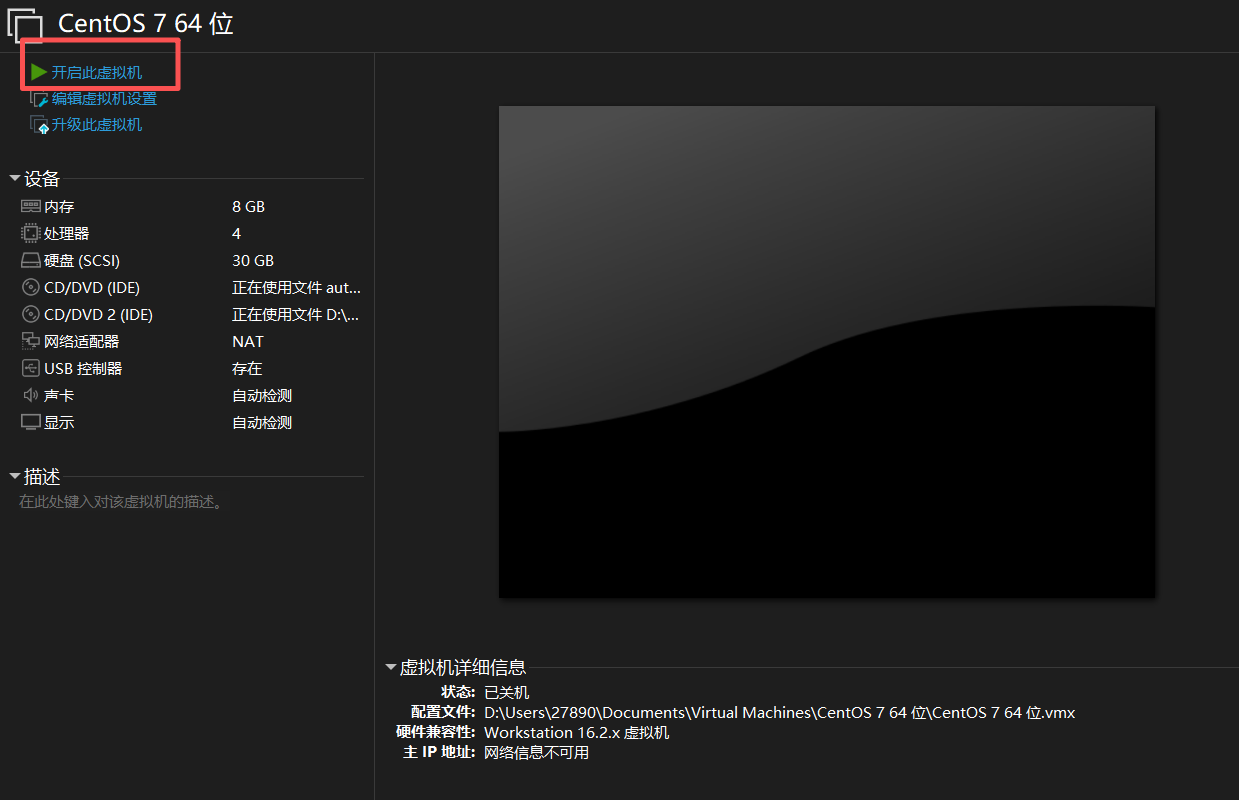
虚拟机会从之前加载的ISO镜像文件启动,并自动开始CentOS 7的安装过程。这个过程是自动化的,因为它使用了VMware的简易安装功能。
安装过程会持续一段时间,包括分区、软件包安装和基本配置。
安装完成后,系统会自动重启并进入登录界面。点击之前设置的用户名,输入密码即可登录到CentOS 7的桌面环境。
至此,基础的虚拟机和操作系统环境已经准备就绪。
第二章:系统基础配置
在安装Hadoop之前,需要对新安装的CentOS 7系统进行一些基础配置,以确保后续操作的顺利进行。
2.1 网络连通性测试
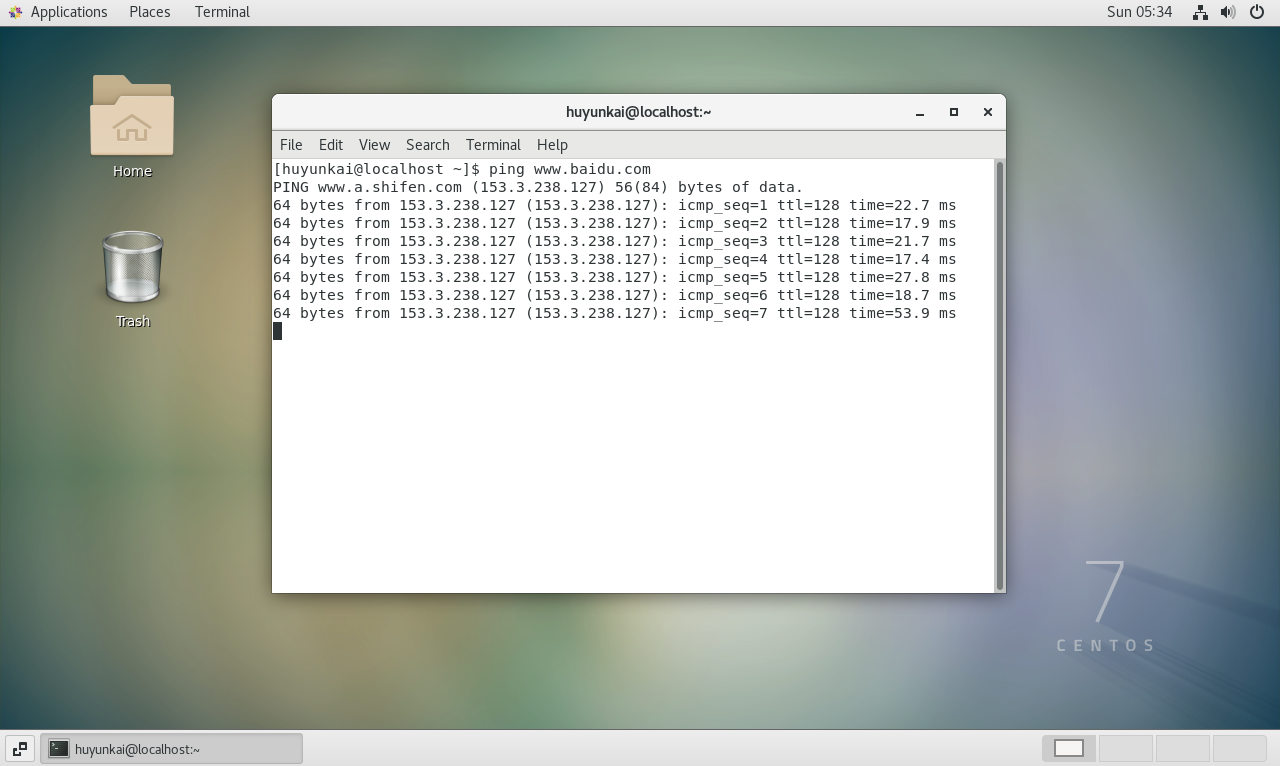
首先,打开终端,测试网络是否正常。ping是一个检查网络连通性的基本命令。
bash
ping www.baidu.com如果能看到来自目标地址的连续响应,说明虚拟机已经可以正常访问互联网。
2.2 关闭防火墙
在学习和开发环境中,为了避免Hadoop各组件之间的端口通信被阻止,通常会选择关闭防火墙。在生产环境中,则需要配置精确的防火墙规则。
执行以下命令来停止并永久禁用firewalld服务:
bash
# 停止当前运行的防火墙服务
sudo systemctl stop firewalld
# 禁止防火墙服务开机自启
sudo systemctl disable firewalldsudo命令用于以管理员权限执行操作。执行时,系统会提示输入当前用户的密码。

2.3 配置SSH免密登录
Hadoop集群的管理脚本(如start-dfs.sh)需要通过SSH来启动和停止各个节点上的服务进程。即使是在伪分布式模式下(所有进程运行在同一台机器上),Hadoop也需要能够免密SSH登录到localhost。
-
生成密钥对 :使用
ssh-keygen命令生成RSA类型的密钥对(一个公钥id_rsa.pub,一个私钥id_rsa)。bash# -t rsa 指定密钥类型为RSA # -P '' 指定私钥的密码为空,实现免密 # -f ~/.ssh/id_rsa 指定密钥文件的存放位置 ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa在执行过程中,连续按回车键接受所有默认设置。
-
授权公钥 :将生成的公钥内容追加到
authorized_keys文件中。这个文件记录了所有被允许通过密钥免密登录到本机的公钥。bashcat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys -
设置权限 :
authorized_keys文件对权限有严格要求,必须确保只有文件所有者有读写权限,否则SSH服务会拒绝使用它。bashchmod 0600 ~/.ssh/authorized_keys -
测试免密登录:尝试SSH登录到本机。
bashssh localhost第一次连接时,系统会询问是否信任该主机的指纹,输入
yes并回车。如果之后没有提示输入密码就直接成功登录,说明免密配置成功。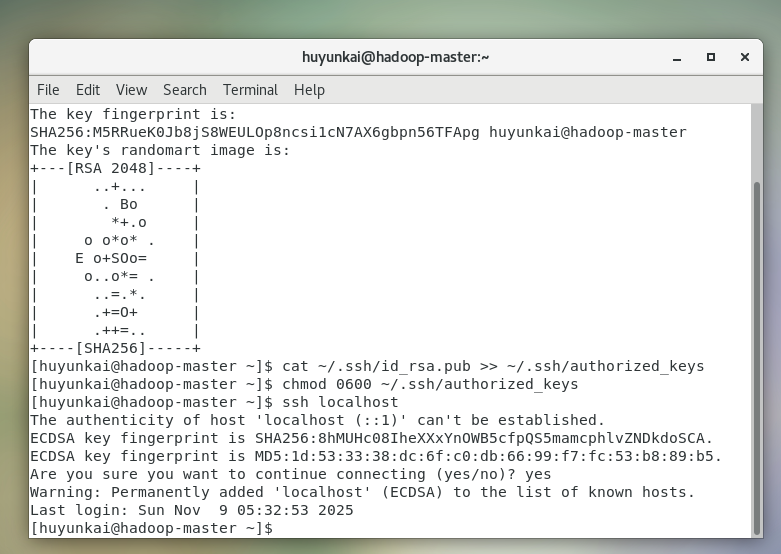
测试成功后,输入
exit命令退回到原来的会话。
第三章:核心依赖安装与问题排查------JDK
Hadoop是基于Java开发的,因此必须安装Java Development Kit (JDK)。这里选择稳定且广泛兼容的OpenJDK 8。
3.1 首次尝试安装JDK与权限问题
使用yum包管理器来安装JDK。
bash
# -y 选项表示对所有提示自动回答yes
sudo yum install -y java-1.8.0-openjdk-devel执行后,遇到了权限问题,提示当前用户不在sudoers文件中。这意味着该用户没有被授权使用sudo命令。

3.2 解决sudo权限问题
要解决此问题,需要编辑/etc/sudoers文件,为当前用户授予sudo权限。直接编辑此文件风险很高,推荐使用visudo命令,它会在保存时检查文件语法,防止配置错误导致系统无法使用sudo。
-
切换到
root用户,因为只有root用户有权限修改sudoers文件。bashsu - root输入
root用户的密码进行切换。
-
执行
visudo命令。bashvisudo -
在打开的编辑界面中,找到
root ALL=(ALL) ALL这一行,在它的下方添加一行,格式如下:bash# 将 "name" 替换为实际的用户名 name ALL=(ALL:ALL) ALL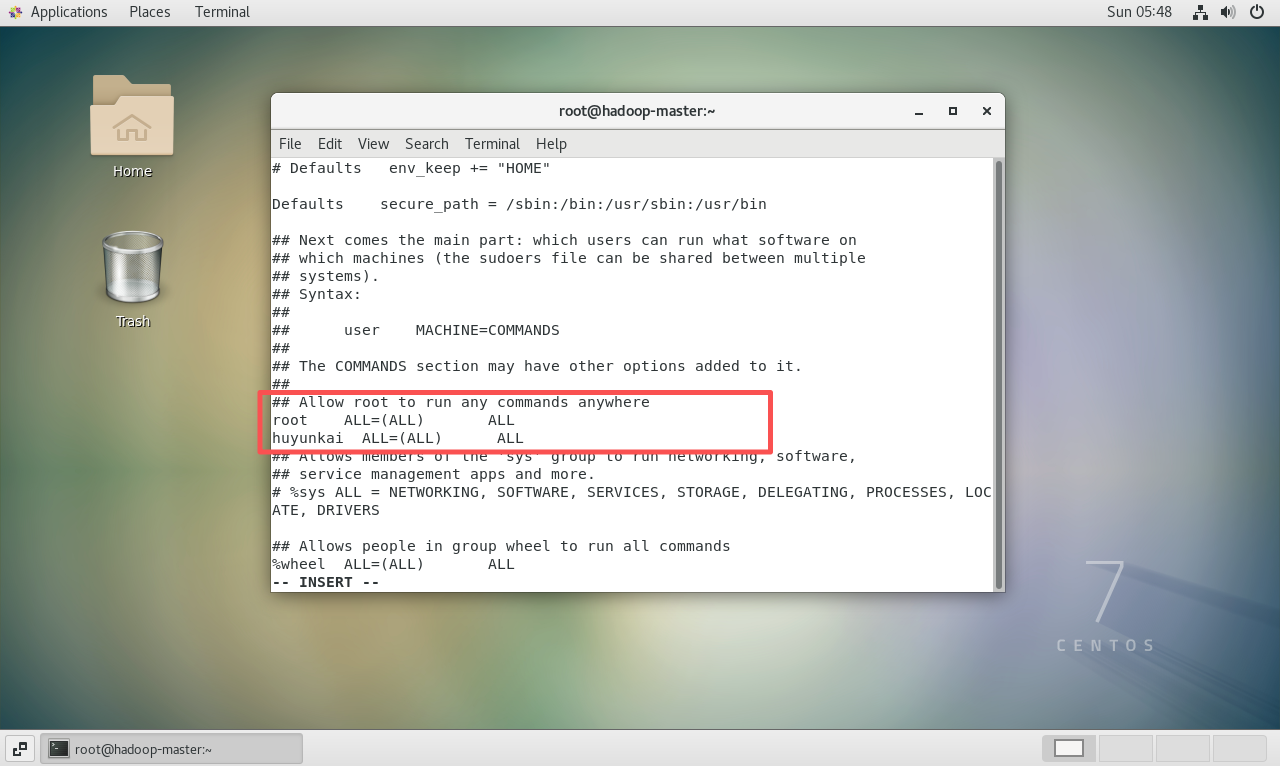
-
按下
Esc键退出插入模式,然后输入:wq并回车,保存并退出。之后可以执行exit退回到普通用户。
3.3 再次尝试安装与网络DNS问题
回到普通用户终端,重新执行JDK安装命令。
bash
sudo yum install -y java-1.8.0-openjdk-devel这次虽然sudo权限问题解决了,但出现了新的报错:"Could not resolve host: mirrors.cloud.aliyuncs.com"。这表明系统无法解析域名,是典型的DNS配置问题。
3.4 配置DNS服务器
为了让系统能够将域名转换为IP地址,需要配置一个可用的DNS服务器。在CentOS 7中,推荐使用nmtui(NetworkManager Text User Interface)这个文本图形化工具来管理网络配置,这样可以避免配置被系统重启覆盖。
-
在终端输入
sudo nmtui启动工具。bashsudo nmtui -
在
nmtui界面中,使用方向键选择"Edit a connection",然后按回车。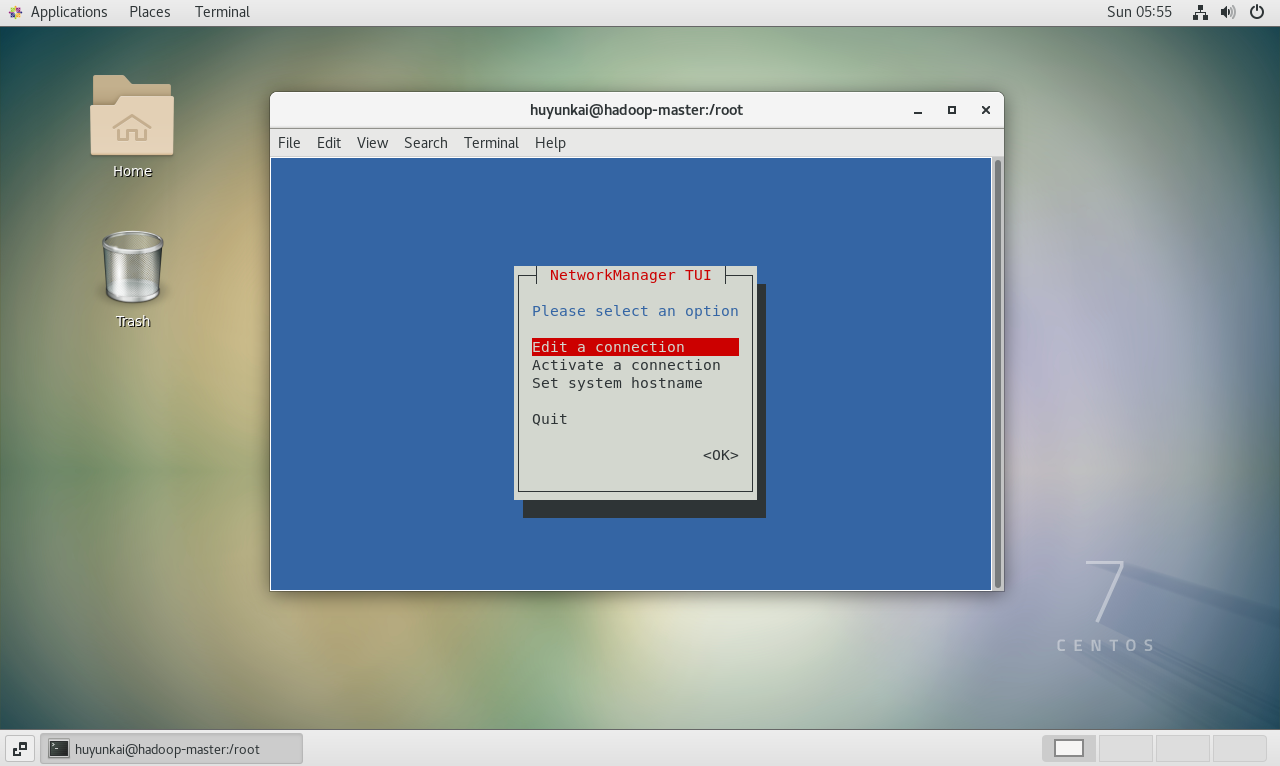
-
选择当前正在使用的网络连接(通常名为
ens33),然后移动到右侧的<Edit...>并按回车。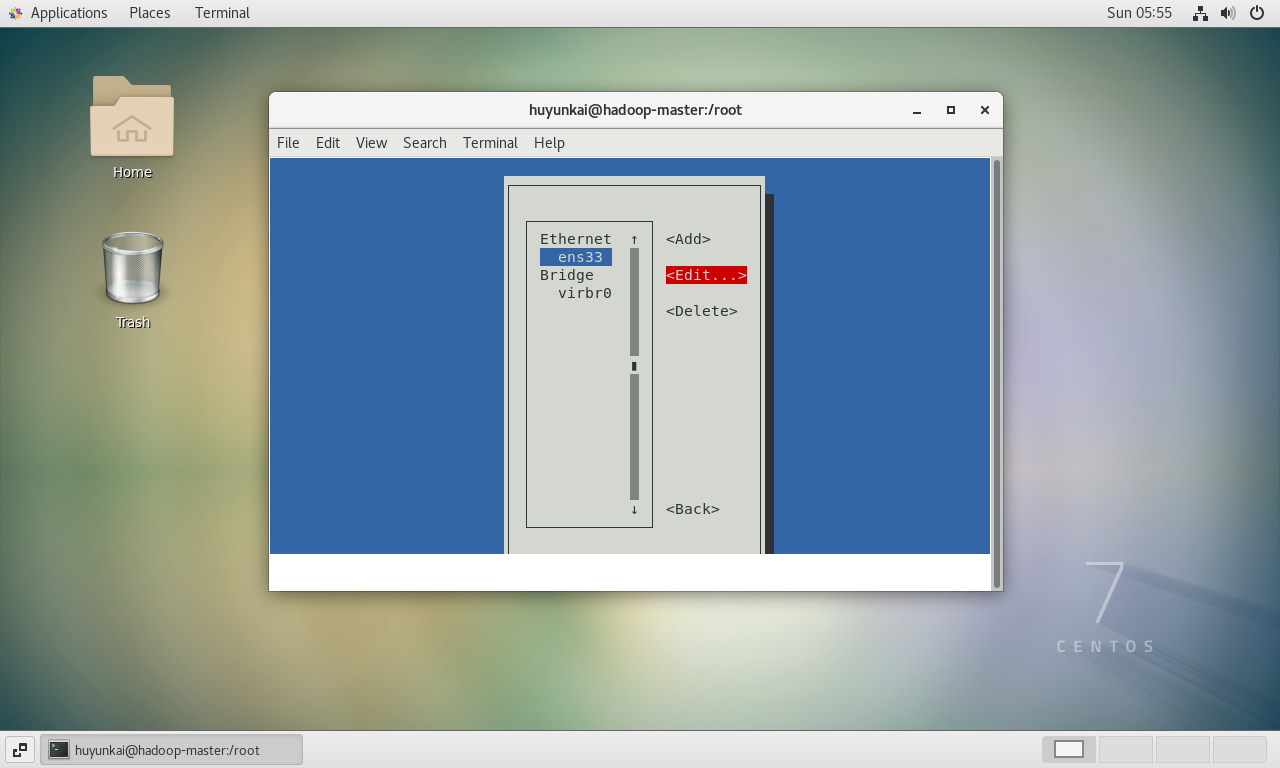
-
在编辑界面中,找到"IPv4 CONFIGURATION",将光标移动到右侧的
<Show>并按回车,展开详细配置。找到"DNS servers"一项,在<Add...>处按回车,输入一个公共DNS服务器地址,例如114.114.114.114。可以添加多个作为备用,如8.8.8.8或223.5.5.5。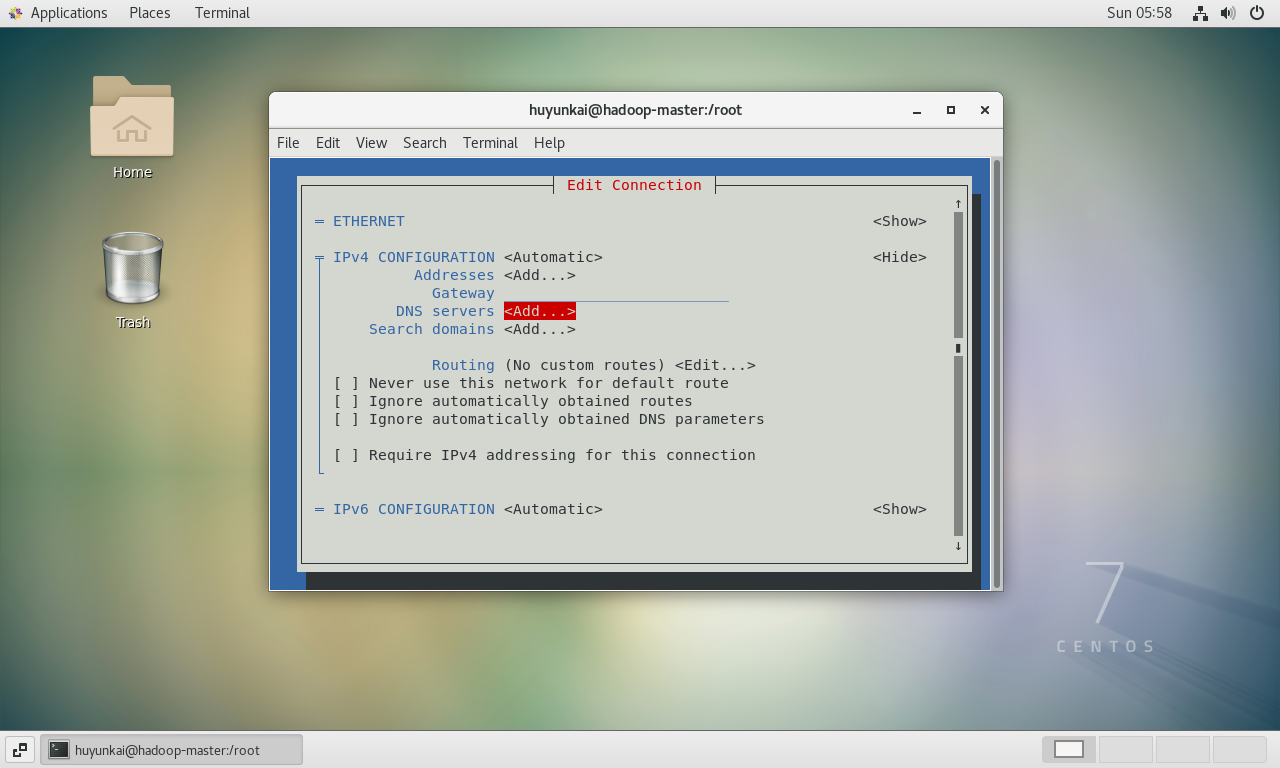
配置完成后的效果如下图所示。
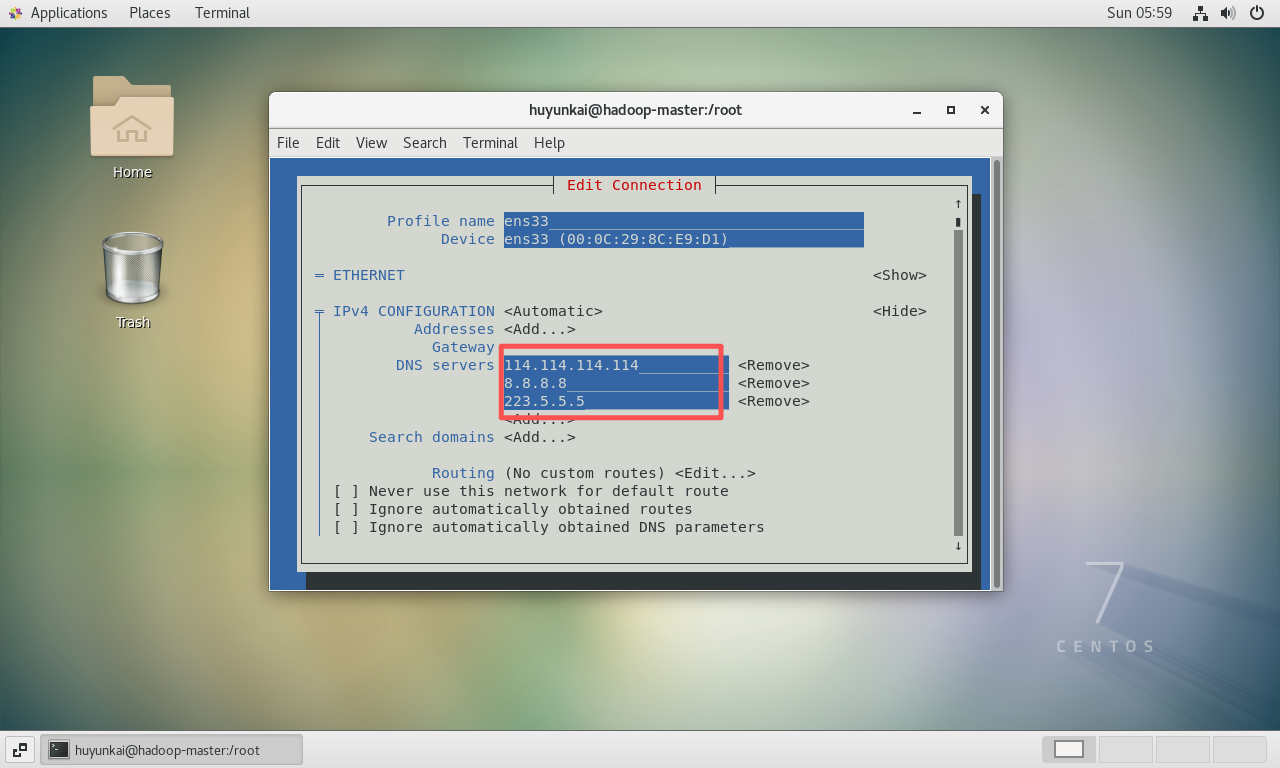
-
配置完成后,一直用方向键移动到底部,选择
<OK>并按回车保存。然后选择Quit退出nmtui。 -
重启网络服务:为了让新的DNS配置立即生效,需要重启NetworkManager服务。
bashsudo systemctl restart NetworkManager -
验证DNS配置 :查看
/etc/resolv.conf文件,确认其中包含了刚才配置的DNS服务器地址。bashcat /etc/resolv.conf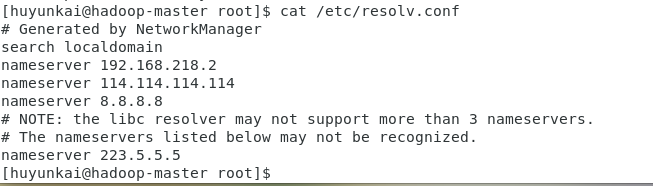
3.5 优化软件源并成功安装JDK
在解决网络问题的基础上,为了提高软件包的下载速度,可以将yum的默认源更换为国内的镜像源,例如阿里云或清华大学的镜像源。
-
备份默认源 :
bashsudo mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup -
下载新的源文件 (这里使用阿里云的源):
bashwget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo -
清理并生成新缓存 :
bashsudo yum clean all sudo yum makecache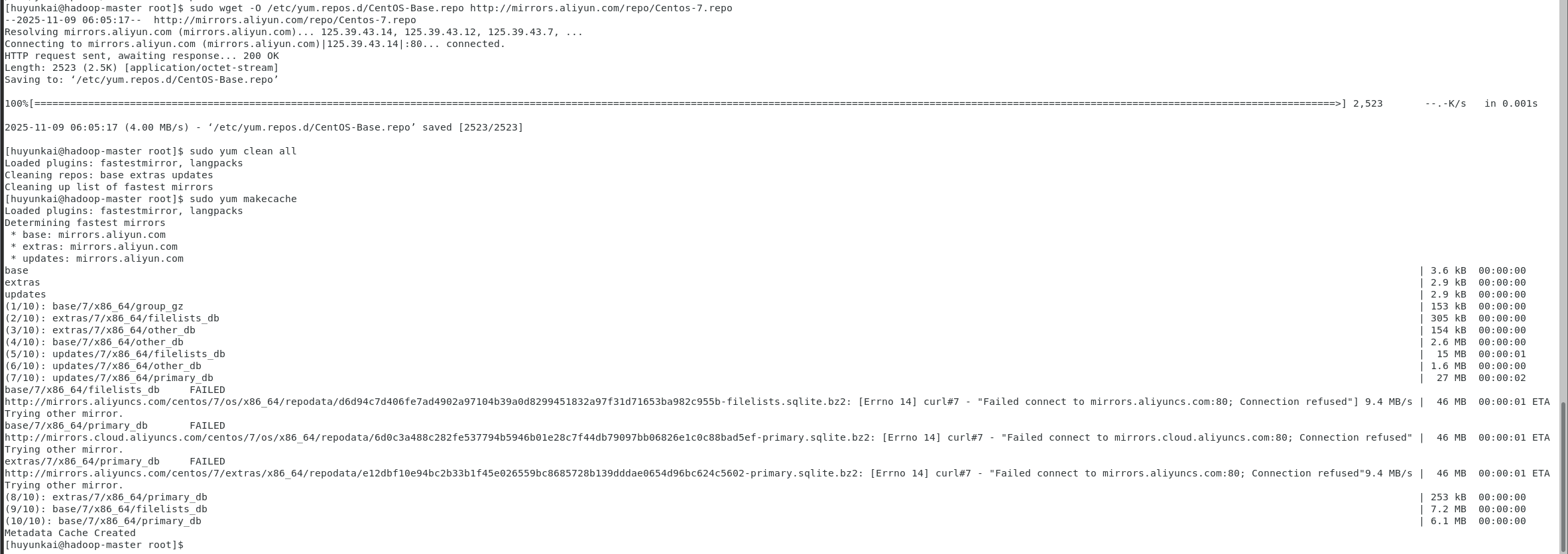
现在,所有准备工作都已完成。再次执行JDK安装命令:
bash
sudo yum install -y java-1.8.0-openjdk-devel这次,yum命令成功执行,完成了JDK的下载和安装。
最后,验证JDK是否安装成功:
bash
java -version如果命令输出了OpenJDK的版本信息,说明Java环境已正确安装。

第四章:Hadoop安装与伪分布式配置
Java环境就绪后,可以开始安装和配置Hadoop。本章将以Hadoop 3.3.6为例,配置一个伪分布式集群。
4.1 下载并解压Hadoop
-
下载Hadoop:从官方源下载Hadoop速度可能较慢,可以切换到国内镜像源(如阿里云)来加速下载。
bash# 官方源(可能较慢) # wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz # 使用阿里云镜像源 wget https://mirrors.aliyun.com/apache/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
-
解压Hadoop :将下载的压缩包解压到
/usr/local目录下。/usr/local是通常用于存放用户自行安装的软件的地方。bash# -z: 处理gzip压缩 # -x: 解压 # -v: 显示过程 # -f: 指定文件 # -C: 指定解压目录 sudo tar -zxvf hadoop-3.3.6.tar.gz -C /usr/local/
-
重命名目录 :为了方便后续配置和引用,将带有版本号的目录名
hadoop-3.3.6重命名为hadoop。bashcd /usr/local/ sudo mv hadoop-3.3.6/ hadoop
4.2 配置Hadoop环境变量
为了能在任何路径下直接使用hadoop、hdfs等命令,需要将Hadoop的bin和sbin目录添加到系统的PATH环境变量中。
-
编辑系统全局配置文件
/etc/profile。bashsudo vi /etc/profile -
在文件末尾添加以下内容:
bashexport HADOOP_HOME=/usr/local/hadoop export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin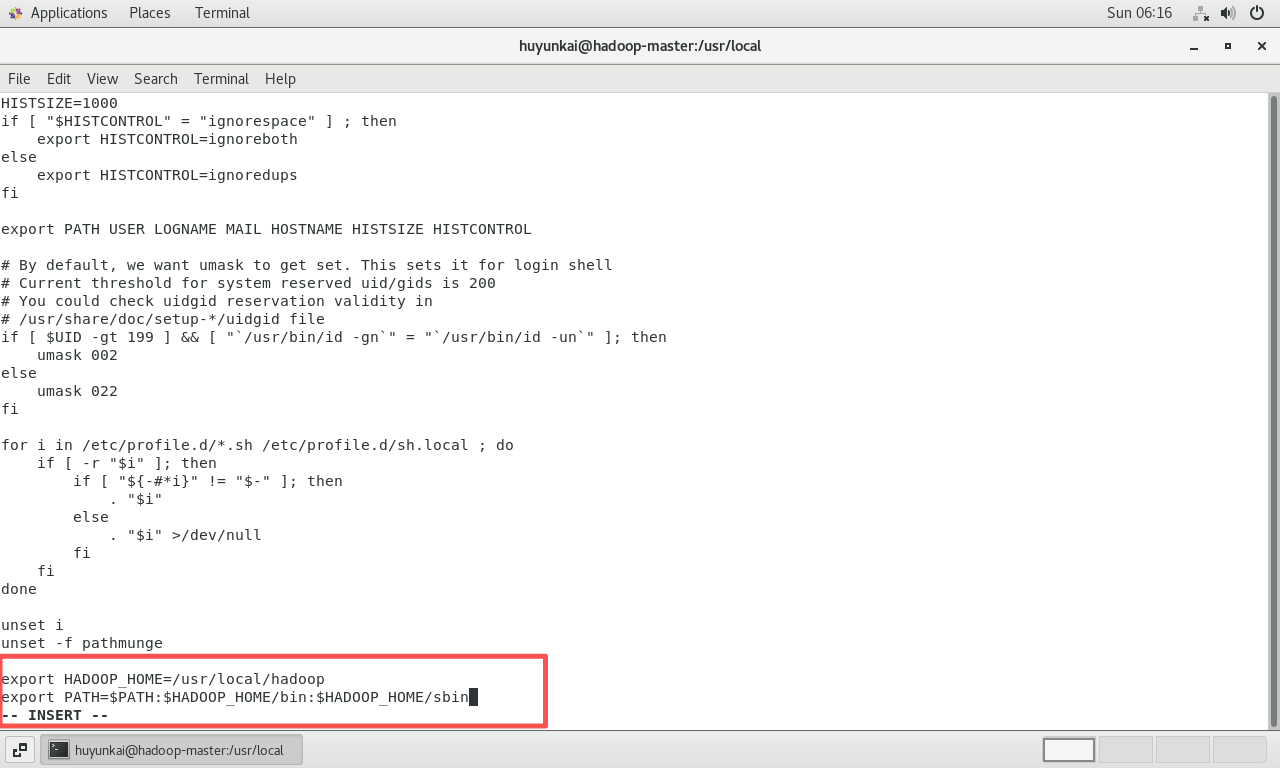
-
保存退出后,执行
source命令使配置立即生效。bashsource /etc/profile
4.3 修改Hadoop核心配置文件
Hadoop的行为由一系列XML配置文件控制,这些文件位于$HADOOP_HOME/etc/hadoop目录中。
进入该目录:
bash
cd /usr/local/hadoop/etc/hadoop/
-
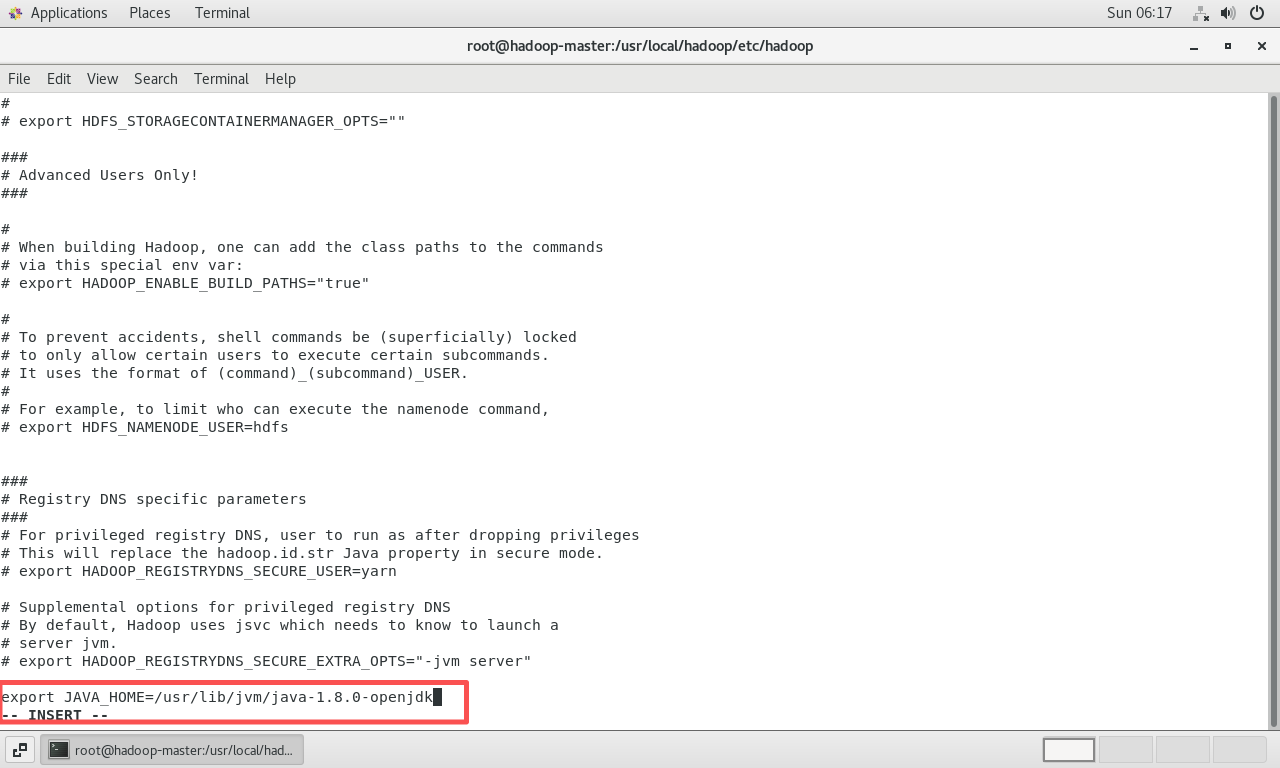
配置
hadoop-env.sh: 这个脚本用于设置Hadoop运行时的环境变量,最重要的是指定JAVA_HOME。bashsudo vi hadoop-env.sh在文件中添加(或修改)
JAVA_HOME的设置,指向之前安装的OpenJDK路径。bashexport JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk注意:这里的路径可能需要根据实际安装情况调整,后续排错环节会展示如何找到精确路径。
-
配置
core-site.xml: 这是Hadoop的核心配置文件,用于定义HDFS的地址和端口。bashsudo vi core-site.xml在
<configuration>标签内添加:xml<property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property>这指定了HDFS NameNode的RPC地址为
localhost的9000端口。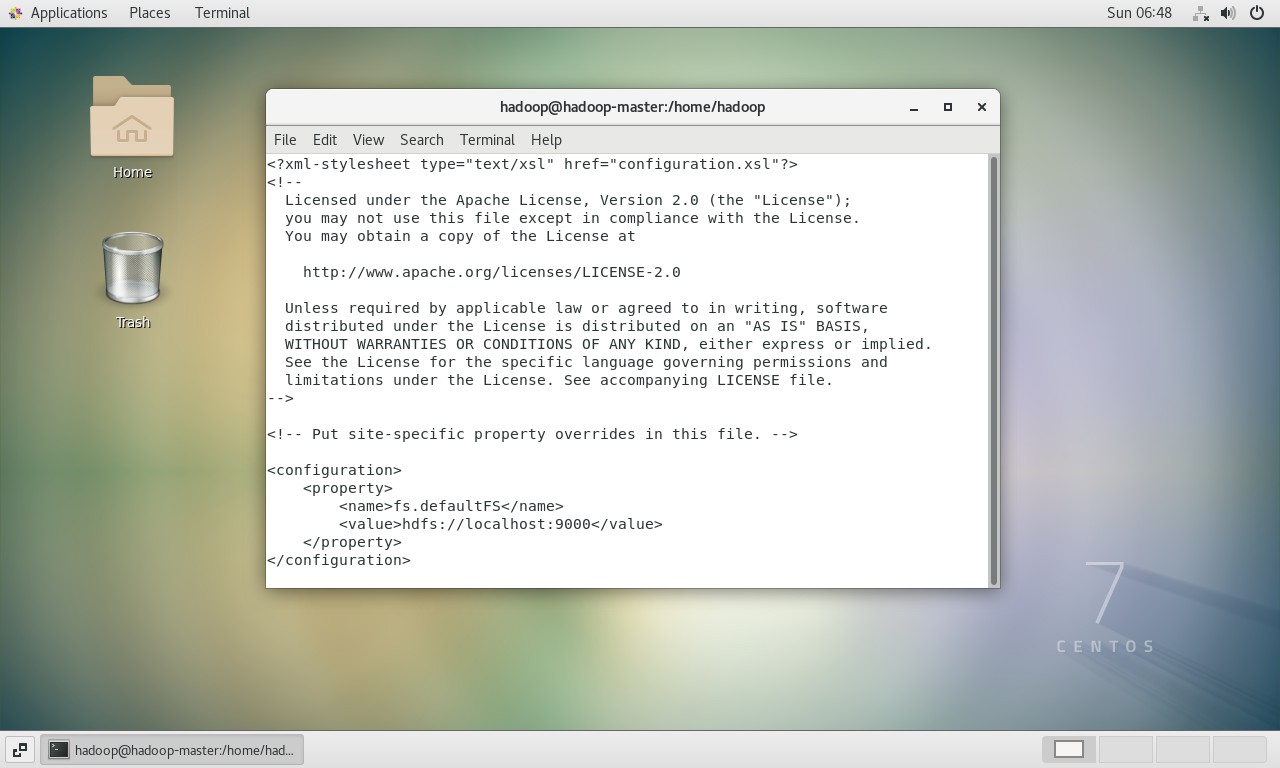
-
配置
hdfs-site.xml: 这个文件用于配置HDFS的具体参数。bashsudo vi hdfs-site.xml在
<configuration>标签内添加:xml<property> <name>dfs.replication</name> <value>1</value> </property>dfs.replication指定了HDFS中文件的副本数量。在伪分布式(单机)模式下,只有一个数据节点,所以副本数必须设置为1。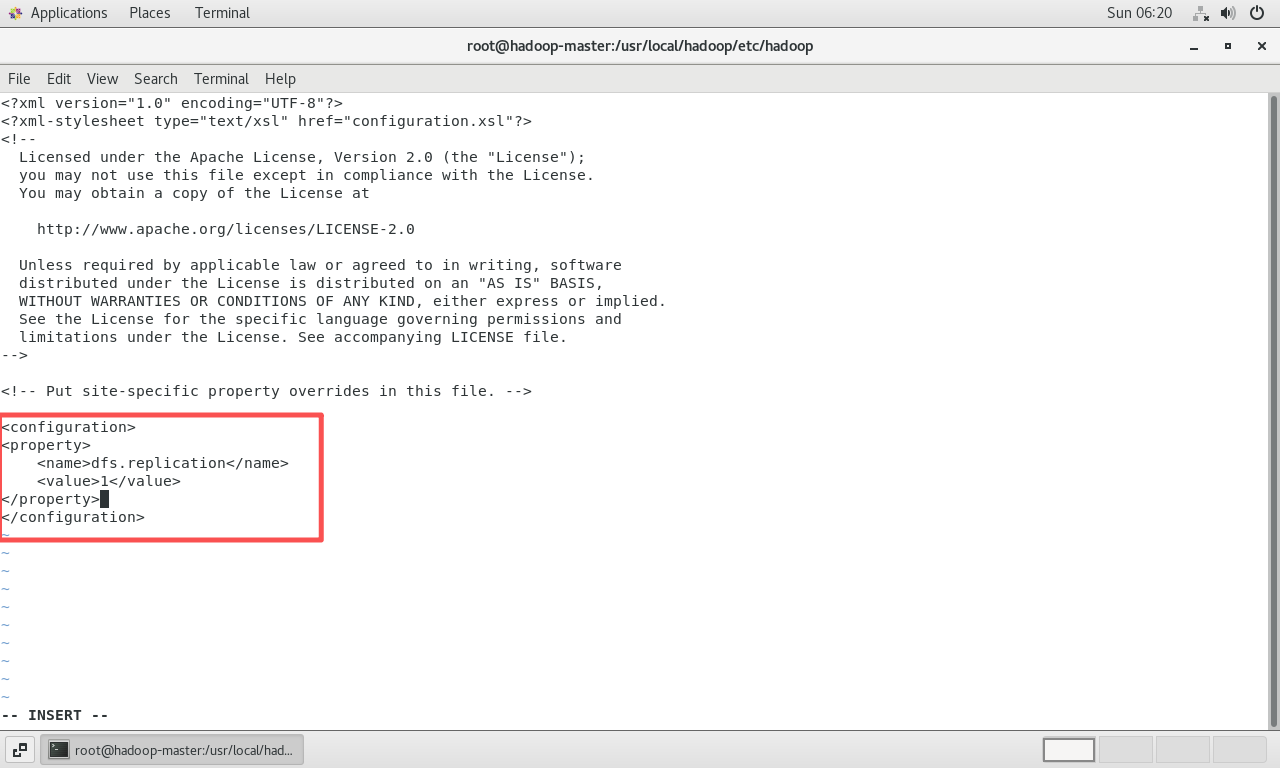
第五章:启动集群与问题排查
配置完成后,可以尝试启动Hadoop集群。这个过程常常会遇到一些典型问题,本章将一一解决。
5.1 首次启动尝试与用户问题
-
格式化NameNode :这是启动HDFS前的初始化步骤,它会创建文件系统的元数据存储结构。此操作只在第一次启动前执行,否则会清空HDFS上的所有数据。
bashhdfs namenode -format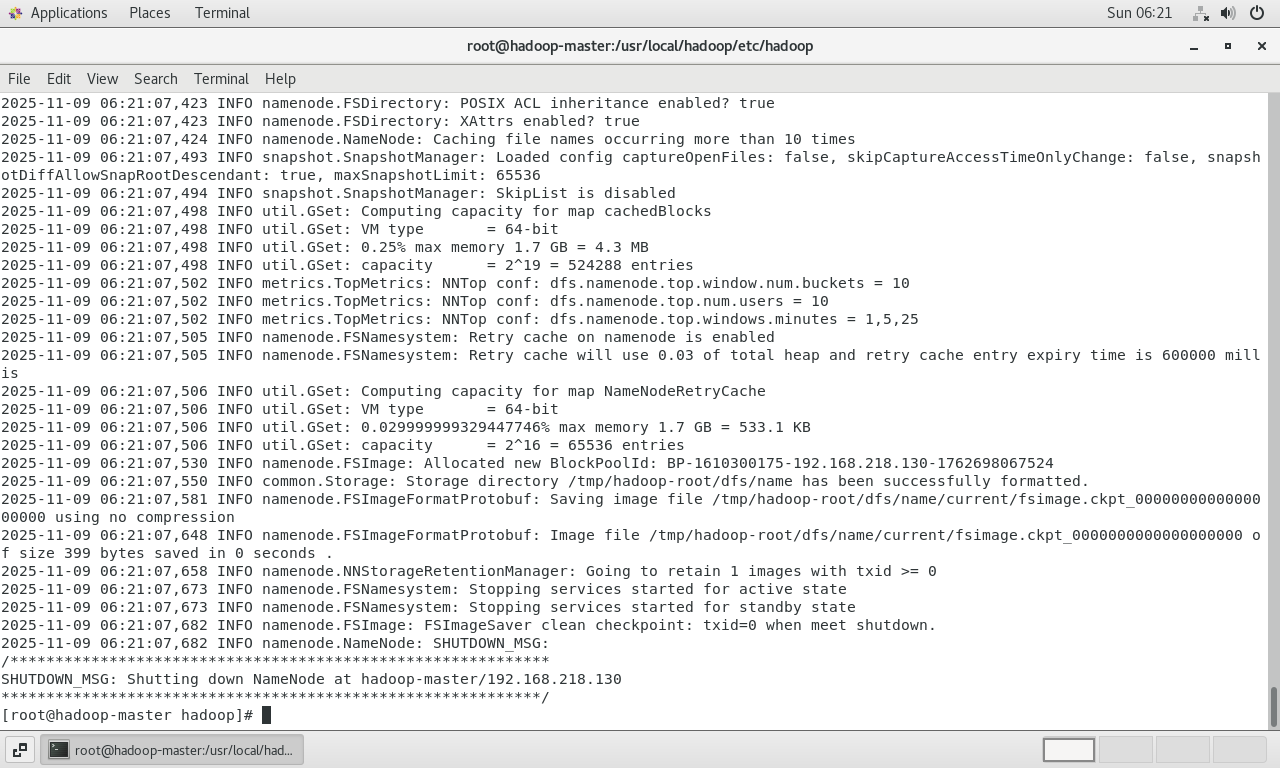
-
启动HDFS和YARN:
bashstart-dfs.sh start-yarn.sh执行后,出现报错。日志提示不允许以
root用户启动NameNode和DataNode。这是Hadoop的一项安全措施,避免以最高权限用户运行服务。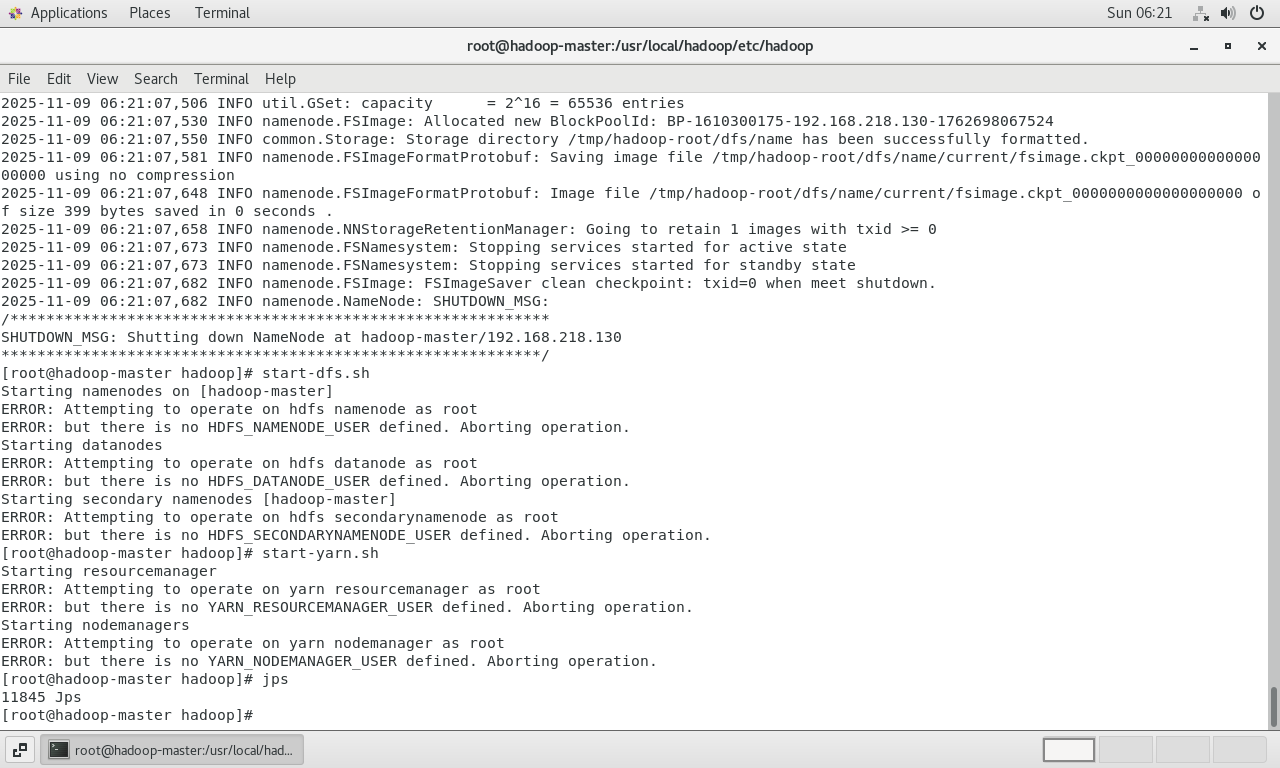
5.2 解决root用户启动问题
解决方案是创建一个专门用于运行Hadoop服务的普通用户,并通过配置告知Hadoop使用该用户。
-
创建hadoop用户:
bashsudo useradd hadoop sudo passwd hadoop根据提示为新用户
hadoop设置密码。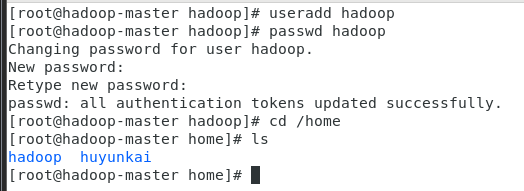
-
修改
hadoop-env.sh:再次编辑hadoop-env.sh,添加环境变量来指定运行HDFS和YARN各组件的用户。bashsudo vi /usr/local/hadoop/etc/hadoop/hadoop-env.sh在文件末尾添加:
bashexport HDFS_NAMENODE_USER="hadoop" export HDFS_DATANODE_USER="hadoop" export HDFS_SECONDARYNAMENODE_USER="hadoop" export YARN_RESOURCEMANAGER_USER="hadoop" export YARN_NODEMANAGER_USER="hadoop"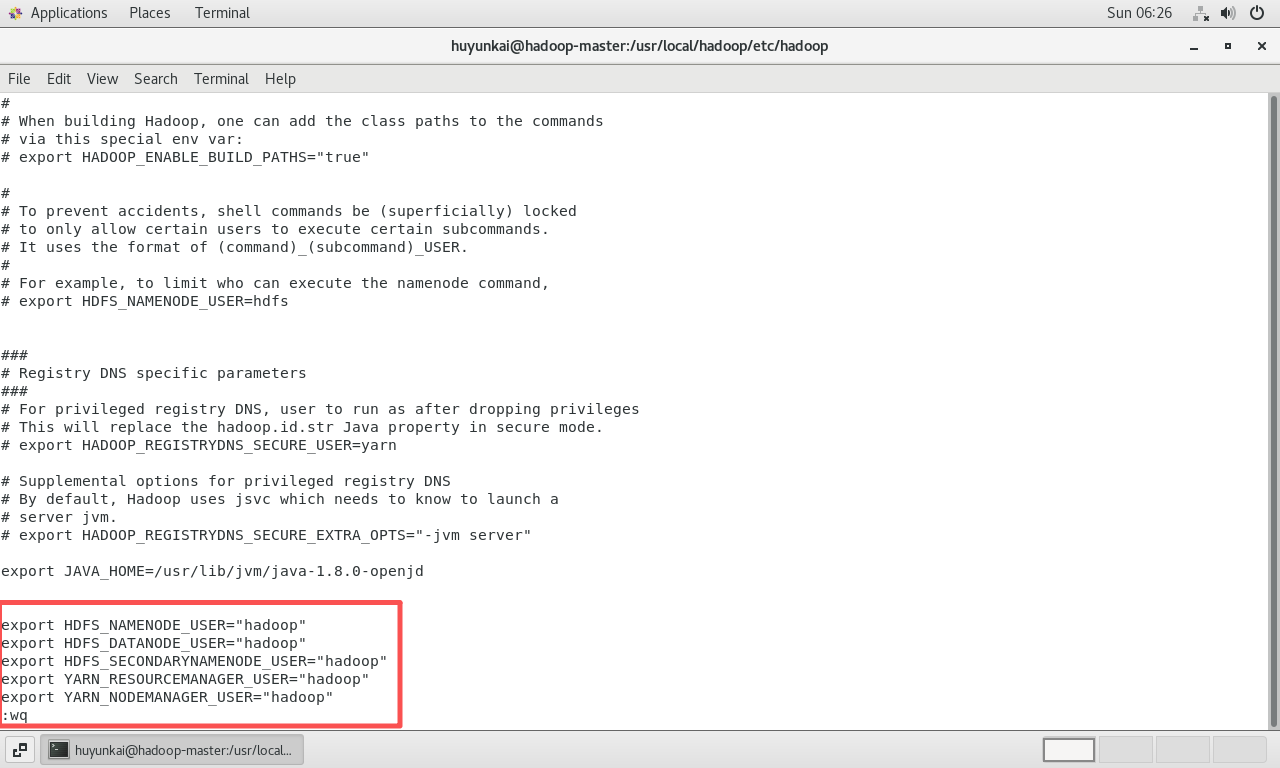
5.3 切换用户后的JAVA_HOME路径问题
切换到hadoop用户,并重新尝试格式化NameNode。
bash
su hadoop
hdfs namenode -format此时出现新的错误:Error: JAVA_HOME is not set and could not be found. 这表明hadoop-env.sh中配置的JAVA_HOME路径不正确或不完整。

-
查找精确的JDK路径 :
yum安装的OpenJDK路径通常带有详细的版本号。使用find命令查找精确路径。bash# 需要在root或有sudo权限的用户下执行 find /usr/lib/jvm -name java-1.8.0-openjdk*
-
修正
hadoop-env.sh:切换回有sudo权限的用户(或root),编辑hadoop-env.sh,将JAVA_HOME的值更新为find命令找到的完整路径。bash# 示例路径,应替换为实际找到的路径 export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.412.b08-1.el7_9.x86_64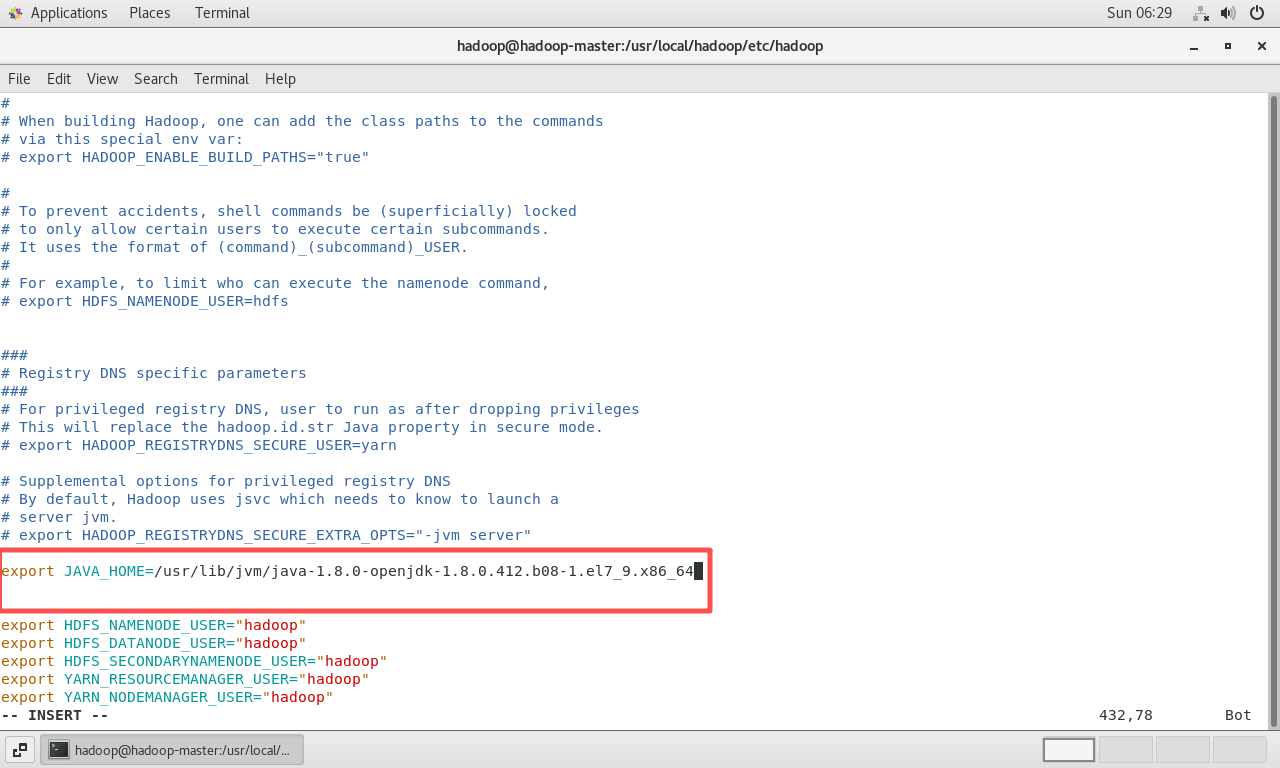
5.4 日志目录权限问题
修正JAVA_HOME后,再次切换到hadoop用户并执行格式化,可能还会遇到权限错误,提示无法创建日志目录。这是因为/usr/local/hadoop目录的所有者是root,而hadoop用户没有写入权限。
解决方案是将整个Hadoop安装目录的所有权变更为hadoop用户。
bash
# 在root或有sudo权限的用户下执行
sudo chown -R hadoop:hadoop /usr/local/hadoop(注:原文中只修改了logs目录权限,但修改整个目录的所有权是更彻底、更标准的做法,可以避免后续其他权限问题)
5.5 成功启动并验证集群
所有问题解决后,进行最后的操作。
-
以
hadoop用户重新格式化NameNode:bashsu hadoop hdfs namenode -format在提示
Re-format filesystem? (Y or N)时输入Y并回车。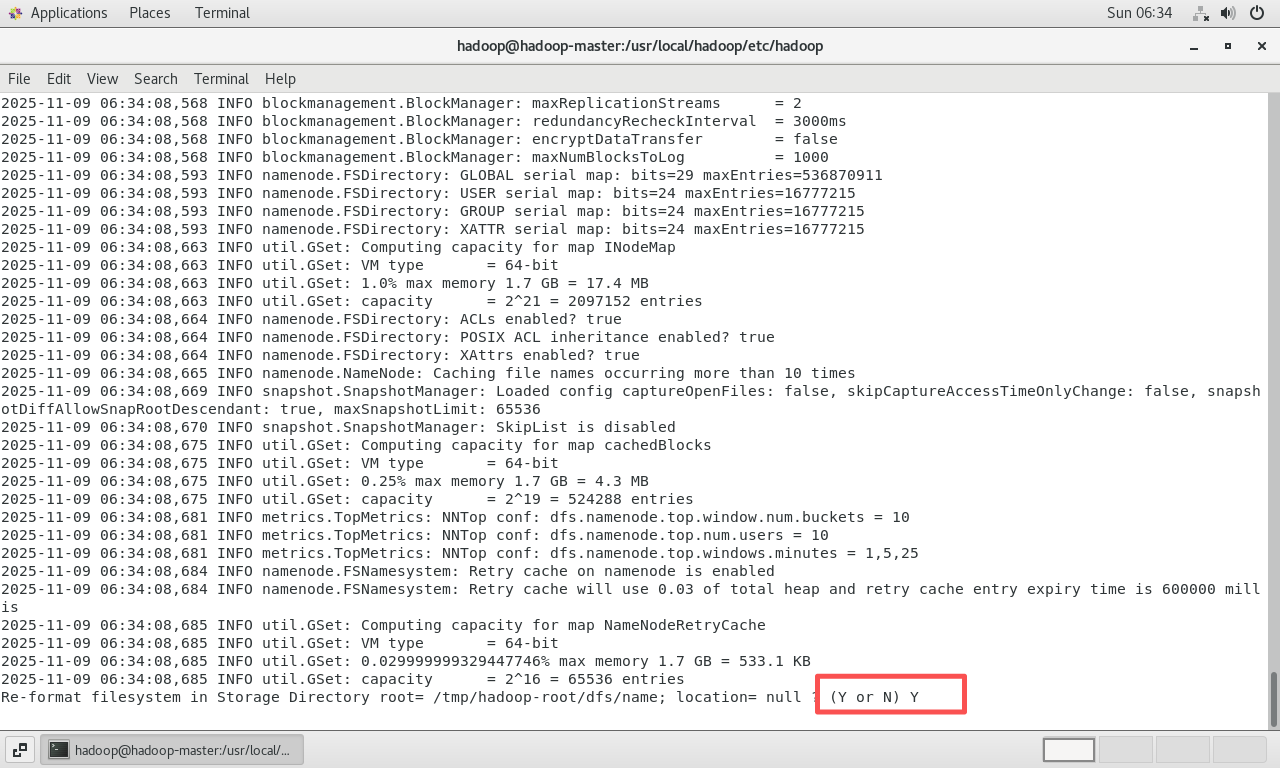
看到
successfully formatted和Exiting with status 0表示格式化成功。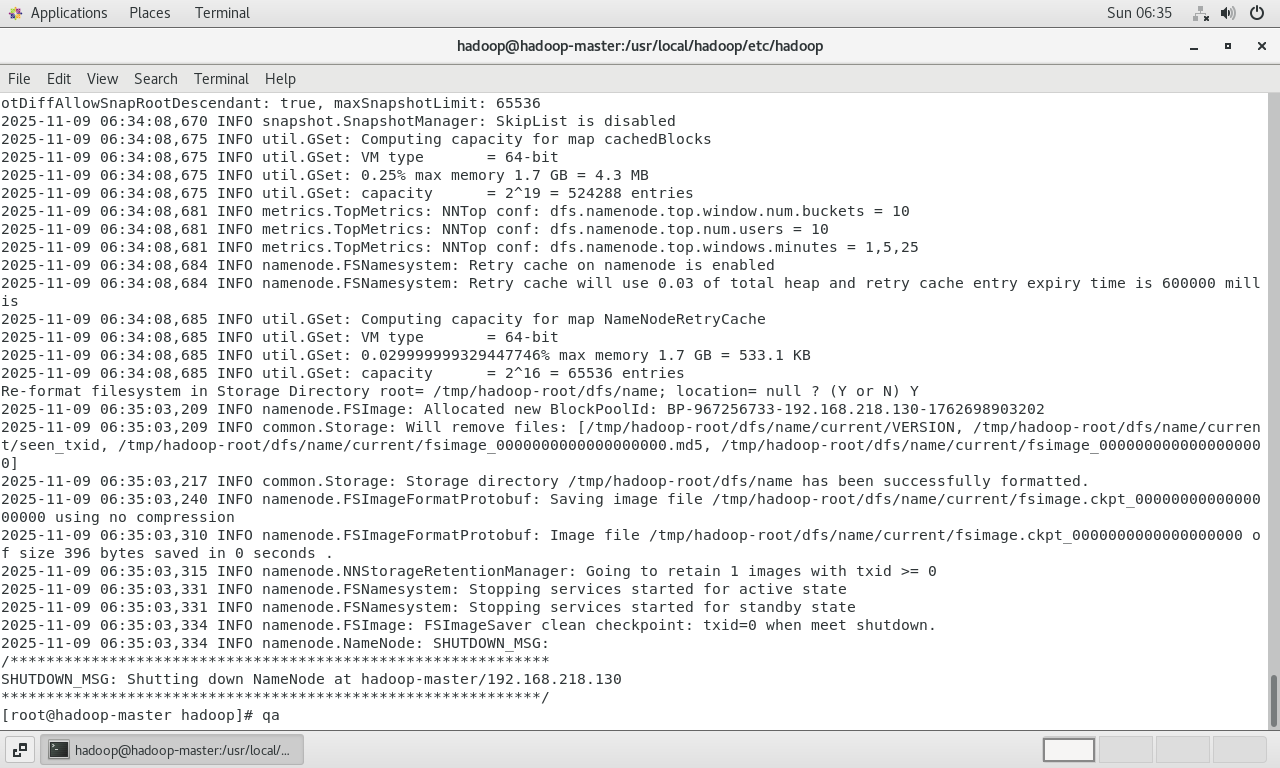
-
启动HDFS和YARN服务 (确保当前是
hadoop用户):bashstart-dfs.sh bash
bashstart-yarn.sh
-
验证服务进程 :使用
jps命令可以查看Java进程,如果看到NameNode,DataNode,SecondaryNameNode,ResourceManager,NodeManager等进程,说明集群已成功启动。 -
命令行验证 :通过
hdfs dfs命令与HDFS进行交互,测试文件系统的可用性。-
在HDFS上创建一个目录:
hdfs dfs -mkdir /test -
在本地创建一个测试文件:
echo "Hello Hadoop" > test.txt -
将本地文件上传到HDFS:
hdfs dfs -put test.txt /test -
查看HDFS上的文件列表和内容:
bashhdfs dfs -ls /test hdfs dfs -cat /test/test.txt

成功显示文件内容,证明HDFS功能正常。
-
-
Web UI验证:Hadoop提供了Web界面来监控集群状态。
- HDFS NameNode Web UI :
http://<虚拟机的IP地址>:9870 - YARN ResourceManager Web UI :
http://<虚拟机的IP地址>:8088
在虚拟机的火狐浏览器中访问
http://localhost:9870和http://localhost:8088。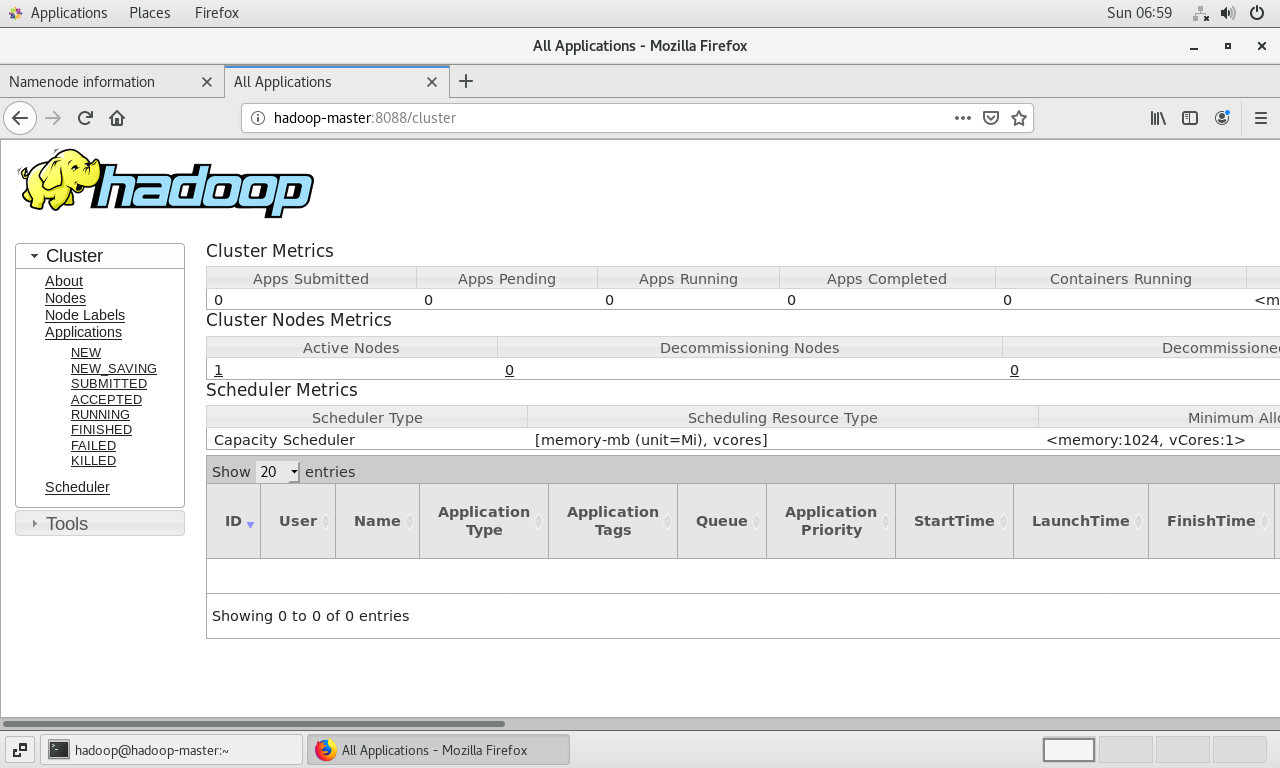
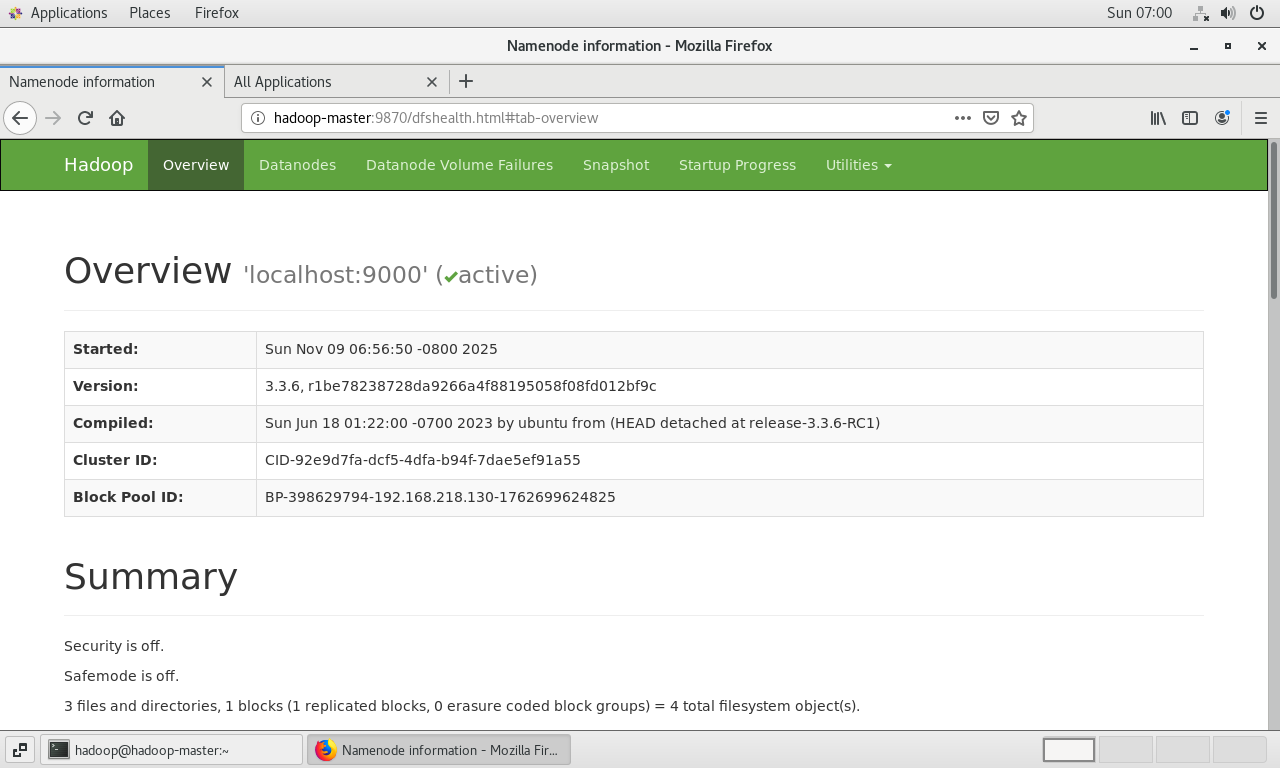
看到这两个Web界面正常显示,标志着Hadoop伪分布式集群已成功部署并处于可用状态。
- HDFS NameNode Web UI :
第六章:Hadoop核心概念与后续步骤
6.1 Hadoop核心构成
Hadoop是一个用于分布式存储和分布式处理大规模数据集的开源框架。它主要解决两个核心问题:
- 海量数据存储(Storage Problem): 当数据量超过单台计算机的存储能力时,需要一种能够横向扩展的存储方案。Hadoop通过其**HDFS(Hadoop Distributed File System)**组件解决了这个问题。HDFS将大文件切分成数据块(Block),并将这些块的多个副本存储在集群的不同机器上,提供了高容错性和高吞吐量的数据访问。
- 海量数据计算(Computation Problem) : 对存储在多台机器上的海量数据进行分析计算,效率低下。Hadoop通过其MapReduce计算模型和**YARN(Yet Another Resource Negotiator)**资源管理框架解决了这个问题。YARN负责集群资源的调度和管理,而MapReduce(或其他计算框架如Spark、Flink)则是在YARN之上运行的分布式计算程序,实现了"计算向数据移动",大大提高了处理效率。
6.2 准备实际应用:MovieLens数据集
为了进行实际的数据分析任务,可以准备一个公开的数据集,例如MovieLens。
-
重新启动Hadoop(如果已关闭):
bash# 确保是hadoop用户 start-dfs.sh start-yarn.sh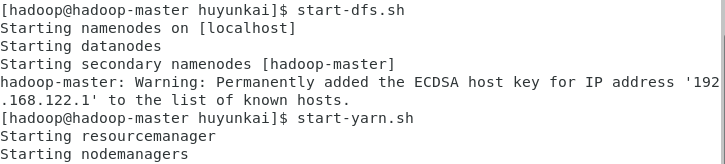
-
下载并解压数据集 :这里使用
ml-latest-small版本,它包含约10万条电影评分数据,非常适合入门练习。bashwget https://files.grouplens.org/datasets/movielens/ml-latest-small.zip unzip ml-latest-small.zip cd ml-latest-small下载并解压后,主要会用到
movies.csv(电影信息)和ratings.csv(评分信息)这两个文件。后续的数据分析任务,例如编写MapReduce程序来统计电影平均分,就可以基于这些数据展开。首先需要将这些数据文件通过hdfs dfs -put命令上传到HDFS中,然后便可以启动计算任务。
总结
通过以上六个章节的详细步骤,一个功能完备的Hadoop伪分布式环境已经成功搭建在VMware虚拟机中。这个过程不仅涵盖了从零开始的每一步操作,还深入探讨了权限配置、网络DNS、环境变量设置等环节中常见的错误及其排查方法。这个稳定运行的Hadoop环境,为后续学习MapReduce编程、HDFS操作以及探索更复杂的Hadoop生态系统组件打下了坚实的基础。