一、背 景
得物DBA自2020年初开始自建TiDB,5年以来随着NewSQL数据库迭代发展、运维体系逐步完善、产品自身能力逐步提升,接入业务涵盖了多个业务线和关键场景。从第一套TIDB v4.0.9 版本开始,到后来v4.0.11、v5.1.1、v5.3.0,在经历了各种 BUG 踩坑、问题调试后,最终稳定在 TIDB 5.3.3 版本。伴随着业务高速增长、数据量逐步增多,对 TiDB 的稳定性及性能也带来更多挑战和新的问题。为了应对这些问题,DBA团队决定对 TiDB 进行一次版本升级,收敛版本到7.5.x。本文基于内部的实践情况,从架构、新特性、升级方案及收益等几个方向讲述 TiDB 的升级之旅。
二、TiDB 架构
TiDB 是分布式关系型数据库,高度强兼容 MySQL 协议和 MySQL 生态,稳定适配 MySQL 5.7 和MySQL 8.0常用的功能及语法。随着版本的迭代,TiDB 在弹性扩展、分布式事务、强一致性基础上进一步针对稳定性、性能、易用性等方面进行优化和增强。与传统的单机数据库相比,TiDB具有以下优势:
- 分布式架构,拥有良好的扩展性,支持对业务透明灵活弹性的扩缩容能力,无需分片键设计以及开发运维。
- HTAP 架构支撑,支持在处理高并发事务操作的同时,对实时数据进行复杂分析,天然具备事务与分析物理隔离能力。
- 支持 SQL 完整生态,对外暴露 MySQL 的网络协议,强兼容 MySQL 的语法/语义,在大多数场景下可以直接替换 MySQL。
- 默认支持自愈高可用,在少数副本失效的情况下,数据库本身能够自动进行数据修复和故障转移,对业务无感。
- 支持 ACID 事务,对于一些有强一致需求的场景友好,满足 RR 以及 RC 隔离级别,可以在通用开发框架完成业务开发迭代。
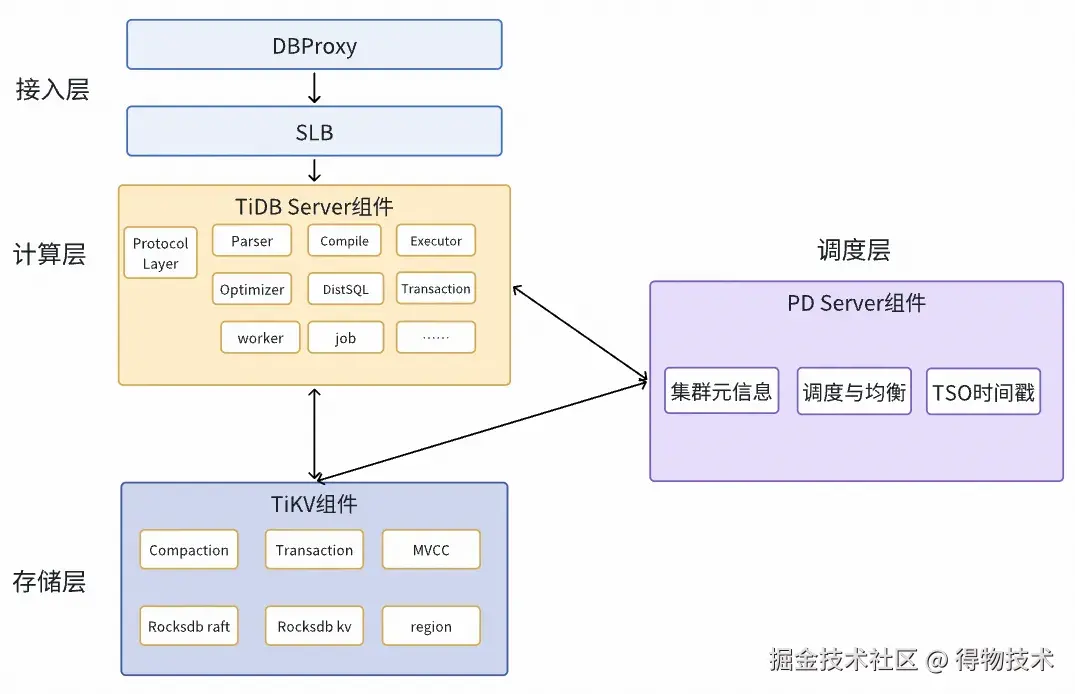
我们使用 SLB 来实现 TiDB 的高效负载均衡,通过调整 SLB 来管理访问流量的分配以及节点的扩展和缩减。确保在不同流量负载下,TiDB 集群能够始终保持稳定性能。在 TiDB 集群的部署方面,我们采用了单机单实例的架构设计。TiDB Server 和 PD Server 均选择了无本地 SSD 的机型,以优化资源配置,并降低开支。TiKV Server则配置在本地 SSD 的机型上,充分利用其高速读写能力,提升数据存储和检索的性能。这样的硬件配置不仅兼顾了系统的性能需求,又能降低集群成本。针对不同的业务需求,我们为各个组件量身定制了不同的服务器规格,以确保在多样化的业务场景下,资源得到最佳的利用,进一步提升系统的运行效率和响应速度。

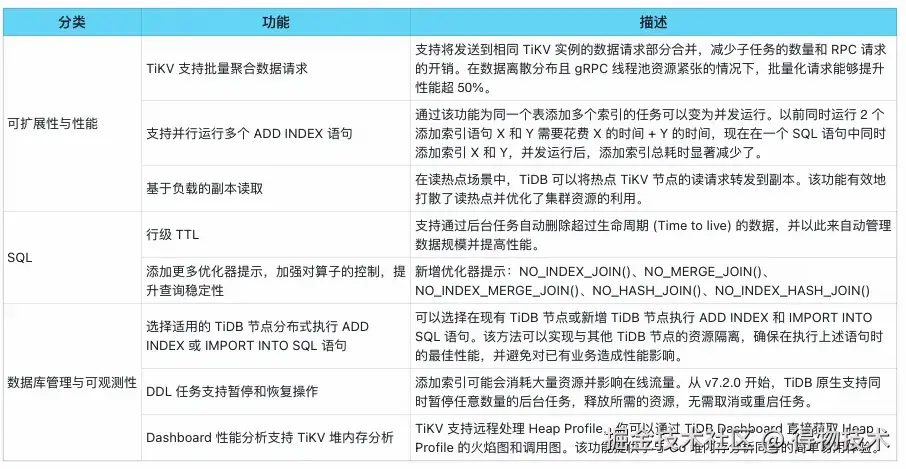
三、TiDB v7 版本新特性
新版本带来了更强大的扩展能力和更快的性能,能够支持超大规模的工作负载,优化资源利用率,从而提升集群的整体性能。在 SQL 功能方面,它提升了兼容性、灵活性和易用性,从而助力复杂查询和现代应用程序的高效运行。此外,网络 IO 也进行了优化,通过多种批处理方法减少网络交互的次数,并支持更多的下推算子。同时,优化了Region 调度算法,显著提升了性能和稳定性。
四、TiDB升级之旅
4.1 当前存在的痛点
- 集群版本过低:当前 TiDB 生产环境(现网)最新版本为 v5.3.3,目前官方已停止对 4.x 和 5.x 版本的维护及支持,TiDB 内核最新版本为 v8.5.3,而被用户广泛采用且最为稳定的版本是 v7.5.x。
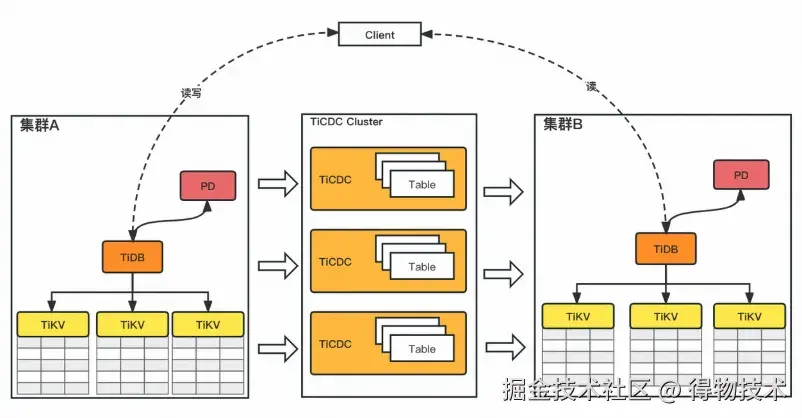
- TiCDC组件存在风险:TiCDC 作为增量数据同步工具,在 v6.5.0 版本以前在运行稳定性方面存在一定问题,经常出现数据同步延迟问题或者 OOM 问题。
- 备份周期时间长:集群每天备份时间大于8小时,在此期间,数据库备份会导致集群负载上升超过30%,当备份时间赶上业务高峰期,会导致应用RT上升。
- 集群偶发抖动及BUG:在低版本集群中,偶尔会出现基于唯一键查询的慢查询现象,同时低版本也存在一些影响可用性的BUG。比如在 TiDB v4.x 的集群中,TiKV 节点运行超过 2 年会导致节点自动重启。
4.2 升级方案:升级方式
TiDB的常见升级方式为原地升级和迁移升级,我们所有的升级方案均采用迁移升级的方式。
原地升级
- 优势:方式较为简单,不需要额外的硬件,升级过程中集群仍然可以对外提供服务。
- 劣势:该升级方案不支持回退、并且升级过程会有长时间的性能抖动。大版本(v4/v5 原地升级到 v7)跨度较大时,需要版本递增升级,抖动时间翻倍。
迁移升级
- 优势:业务影响时间较短、可灰度可回滚、不受版本跨度的影响。
- 劣势:搭建新集群将产生额外的成本支出,同时,原集群还需要部署TiCDC组件用于增量同步。
4.3 升级方案:集群调研
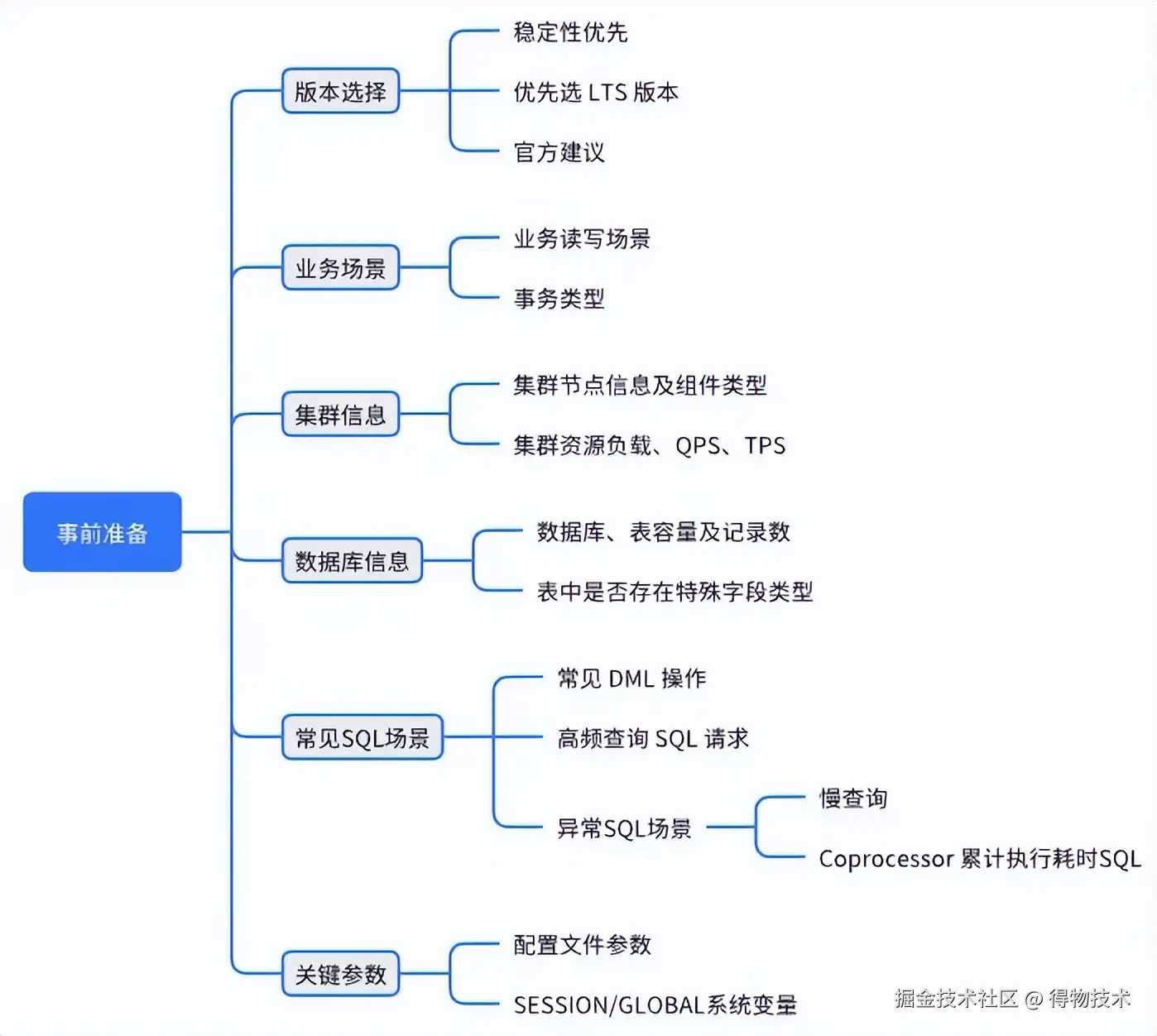
4.4 升级方案:升级前准备环境
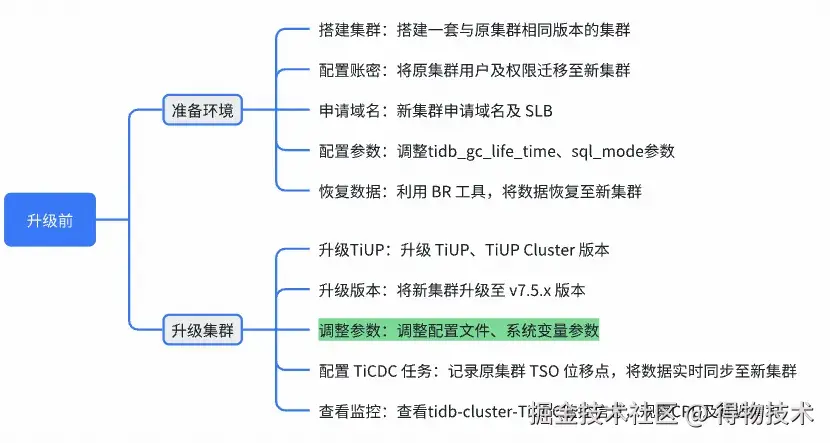
4.5 升级方案:升级前验证集群

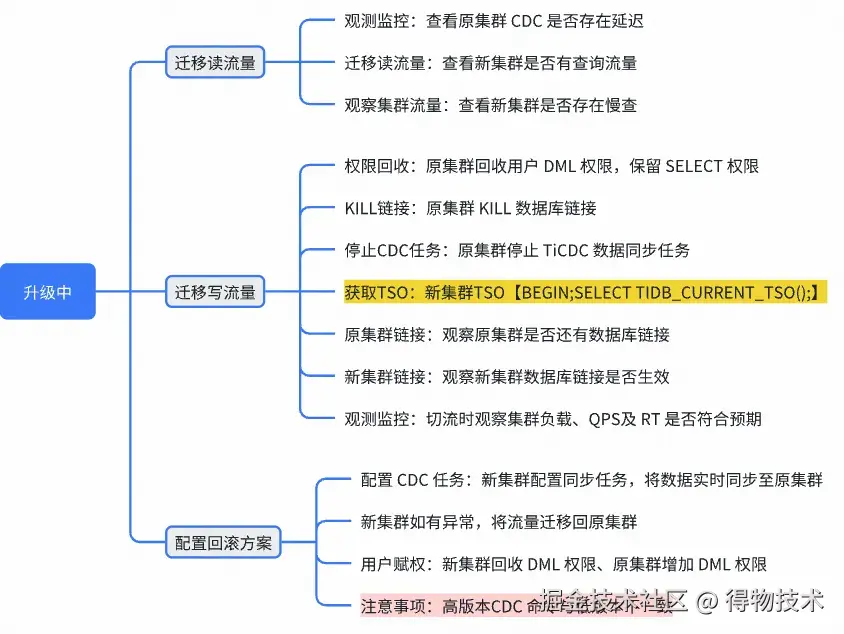
4.6 升级方案:升级中流量迁移
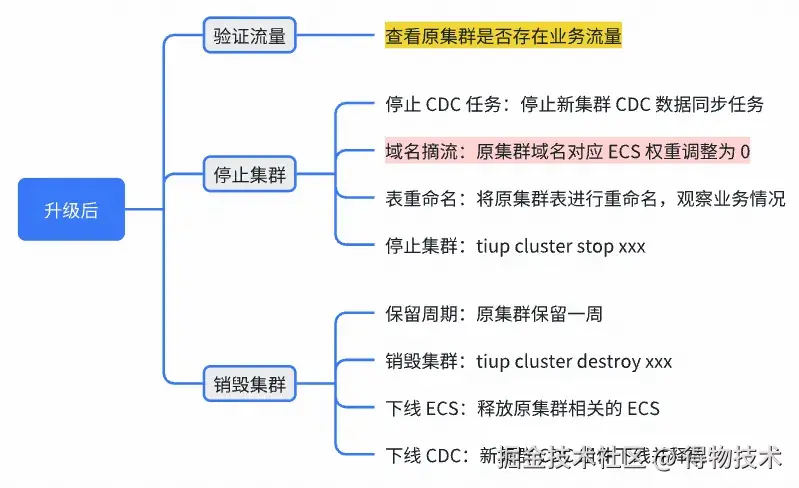
4.7 升级方案:升级后销毁集群
五、升级遇到的问题
5.1 v7.5.x版本查询SQL倾向全表扫描
表中记录数 215亿,查询 SQL存在合理的索引,但是优化器更倾向走全表扫描,重新收集表的统计信息后,执行计划依然为全表扫描。
走全表扫描执行60秒超时KILL,强制绑定索引仅需0.4秒。
ini
-- 查询SQL
SELECT
*
FROM
fin_xxx_xxx
WHERE
xxx_head_id = 1111111111111111
AND xxx_type = 'XX0002'
AND xxx_user_id = 11111111
AND xxx_pay_way = 'XXX00000'
AND is_del IN ('N', 'Y')
LIMIT
1;
-- 涉及索引
KEY `idx_xxx` (`xxx_head_id`,`xxx_type`,`xxx_status`),解决方案:
- 方式一:通过 SPM 进行 SQL 绑定。
- 方式二:调整集群参数 tidb_opt_prefer_range_scan,将该变量值设为 ON 后,优化器总是偏好区间扫描而不是全表扫描。
5.2 v7.5.x版本聚合查询执行计划不准确
集群升级后,在新集群上执行一些聚合查询或者大范围统计查询时无法命中有效索引。而低版本v4.x、5.x集群,会根据统计信息选择走合适的索引。
v4.0.11集群执行耗时:12秒,新集群执行耗时2分32.78秒
sql
-- 查询SQL
select
statistics_date,count(1)
from
merchant_assessment_xxx
where
create_time between '2025-08-20 00:00:00' and '2025-09-09 00:00:00'
group by
statistics_date order by statistics_date;
-- 涉及索引
KEY `idx_create_time` (`create_time`)解决方案:
方式一:调整集群参数tidb_opt_objective,该变量设为 determinate后,TiDB 在生成执行计划时将不再使用实时统计信息,这会让执行计划相对稳定。
六、升级带来的收益
版本升级稳定性增强:v7.5.x 版本的 TiDB 提供了更高的稳定性和可靠性,高版本改进了SQL优化器、增强的分布式事务处理能力等,加快了响应速度和处理大量数据的能力。升级后相比之前整体性能提升40%。特别是在处理复杂 SQL 和多索引场景时,优化器的性能得到了极大的增强,减少了全表扫描的发生,从而显著降低了 TiKV 的 CPU 消耗和 TiDB 的内存使用。
应用平均RT提升44.62%
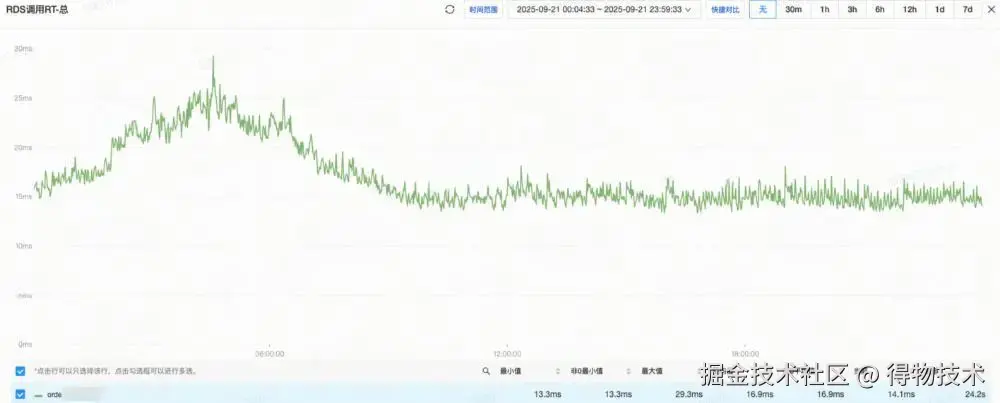
原集群RT(平均16.9ms)
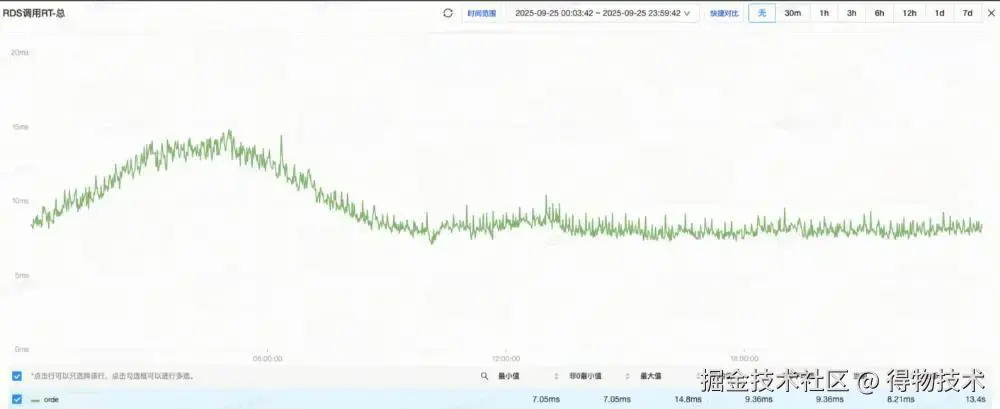
新集群RT(平均9.36ms)
新集群平均RT提升50%,并且稳定性增加,毛刺大幅减少
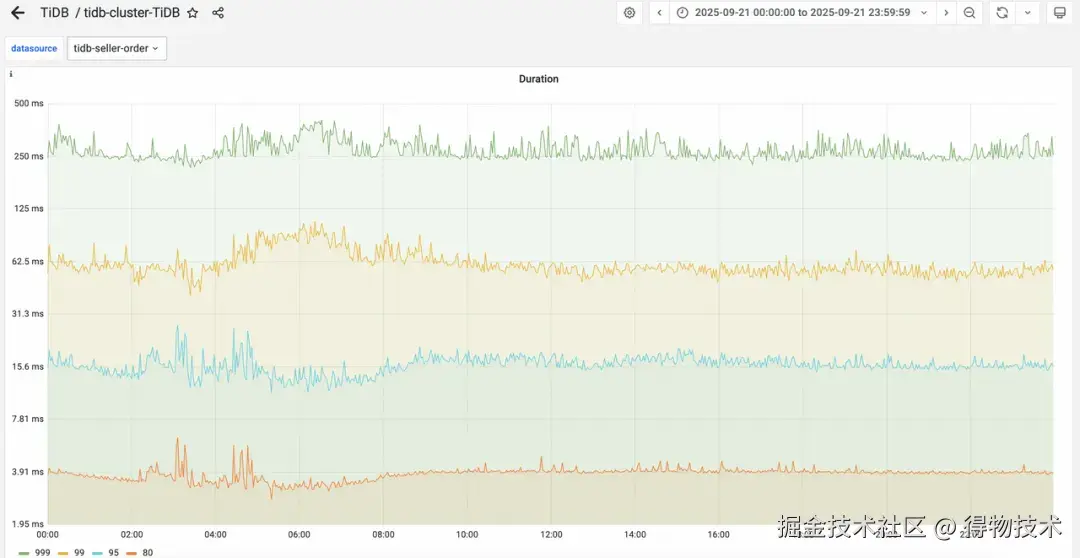
老集群RT(平均250ms)
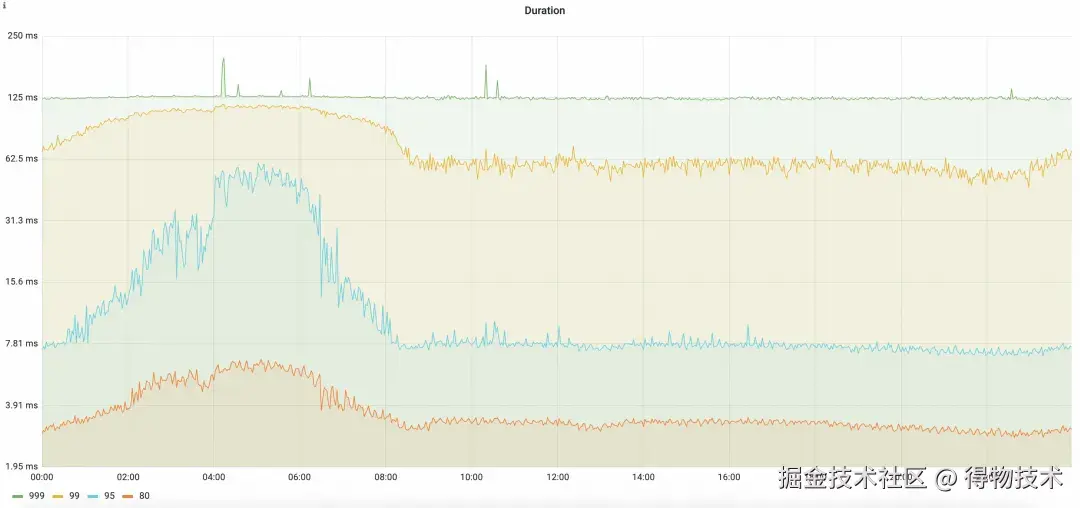
新集群RT(平均125ms)
提升TiCDC同步性能:新版本在数据同步方面有了数十倍的提升,有效解决了之前版本中出现的同步延迟问题,提供更高的稳定性和可靠性。当下游需要订阅数据至数仓或风控平台时,可以使用TiCDC将数据实时同步至Kafka,提升数据处理的灵活性与响应能力。
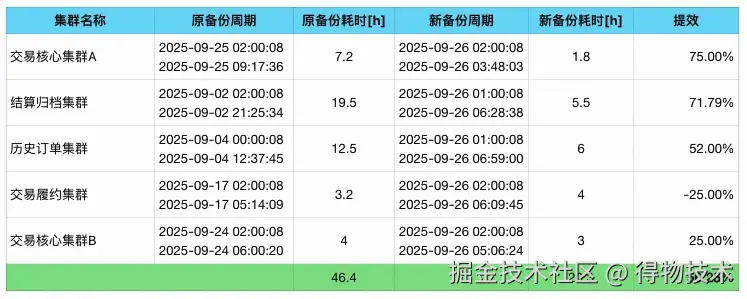
缩短备份时间:数据库备份通常会消耗大量的CPU和IO资源。此前,由于备份任务的结束时间恰逢业务高峰期,经常导致应用响应时间(RT)上升等问题。通过进行版本升级将备份效率提升了超过50%。
高压缩存储引擎:新版本采用了高效的数据压缩算法,能够显著减少存储占用。同时,通过优化存储结构,能够快速读取和写入数据,提升整体性能。相同数据在 TiDB 中的存储占用空间更低,iDB 的3副本数据大小仅为 MySQL(主实例数据大小)的 55%。

完善的运维体验:新版本引入更好的监控工具、更智能的故障诊断机制和更简化的运维流程,提供了改进的 Dashboard 和 Top SQL 功能,使得慢查询和问题 SQL 的识别更加直观和便捷,降低 DBA 的工作负担。
更秀更实用的新功能:TiDB 7.x版本提供了TTL定期自动删除过期数据,实现行级别的生命周期控制策略。通过为表设置 TTL 属性,TiDB 可以周期性地自动检查并清理表中的过期数据。此功能在一些场景可以有效节省存储空间、提升性能。TTL 常见的使用场景:
- 定期删除验证码、短网址记录
- 定期删除不需要的历史订单
- 自动删除计算的中间结果
docs.pingcap.com/zh/tidb/v7....
七、选择 TiDB 的原因
我们不是为了使用TiDB而使用,而是去解决一些MySQL无法满足的场景,关系型数据库我们还是优先推荐MySQL。能用分库分表能解决的问题尽量选择MySQL,毕竟运维成本相对较低、数据库版本更加稳定、单点查询速度更快、单机QPS性能更高这些特性是分布式数据库无法满足的。
- 非分片查询场景:上游 MySQL 采用了分库分表的设计,但部分业务查询无法利用分片。通过自建 DTS 将 MySQL 数据同步到 TiDB 集群,非分片/聚合查询则使用 TiDB 处理,能够在不依赖原始分片结构的情况下,实现高效的数据查询和分析。
- 分析 SQL 多场景:业务逻辑比较复杂,往往存在并发查询和分析查询的需求。通过自建 DTS 将 MySQL 数据同步到 TiDB,复杂查询在TiDB执行、点查在MySQL执行。TiDB支持水平扩展,其分布式计算和存储能力使其能够高效处理大量的并发查询请求。既保障了MySQL的稳定性,又提升了整体的查询能力。
- 磁盘使用大场景:在磁盘使用率较高的情况下,可能会出现 CPU 和内存使用率低,但磁盘容量已达到 MySQL 的瓶颈。TiDB 能够自动进行数据分片和负载均衡,将数据分布在多个节点上, 缓解单一节点的磁盘压力,避免了传统 MySQL 中常见的存储瓶颈问题,从而提高系统的可扩展性和灵活性。
- 数据倾斜场景:在电商业务场景上,每个电商平台都会有一些销量很好的头部卖家,数据量会很大。即使采取了进行分库分表的策略,仍难以避免大卖家的数据会存储在同一实例中,这样会导致热点查询和慢 SQL 问题,尽管可以通过添加索引或进一步分库分表来优化,但效果有限。采用分布式数据库能够有效解决这一问题。可以将数据均匀地分散存储在多个节点上,在查询时则能够并发执行,从而将流量分散,避免热点现象的出现。随着业务的快速发展和数据量的不断增长,借助简单地增加节点,即可实现水平扩展,满足海量数据及高并发的需求。
八、总结
综上所述,在本次 TiDB 集群版本升级到 v7.5.x 版本过程中,实现了性能和稳定性提升。通过优化的查询计划和更高效的执行引擎,数据读取和写入速度显著提升,大幅度降低了响应延迟,提升了在高并发操作下的可靠性。通过直观的监控界面和更全面的性能分析工具,能够更快速地识别和解决潜在问题,降低 DBA 的工作负担。也为未来的业务扩展和系统稳定性提供了强有力的支持。
后续依然会持续关注 TiDB 在 v8.5.x 版本稳定性、性能以及新产品特性带来应用开发以及运维人效收益进展。目前 TiDB 内核版本 v8.5.x 已经具备多模数据库 Data + AI 能力,在JSON函数、ARRAY 索引以及 Vector Index 实现特性。同时已经具备 Resource Control 资源管理能力,适合进行多业务系统数据归集方案,实现数据库资源池化多种自定义方案。技术研究方面我们数据库团队会持续投入,将产品最好的解决方案引入现网环境。
往期回顾
-
得物管理类目配置线上化:从业务痛点到技术实现
-
大模型如何革新搜索相关性?智能升级让搜索更"懂你"|得物技术
-
RAG---Chunking策略实战|得物技术
-
告别数据无序:得物数据研发与管理平台的破局之路
-
从一次启动失败深入剖析:Spring循环依赖的真相|得物技术
文 /岱影
关注得物技术,每周更新技术干货
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
未经得物技术许可严禁转载,否则依法追究法律责任。