一、引言
背景
在云原生环境中,复杂数据库集群的高可用性管理是企业的核心挑战之一。KubeBlocks 作为开源的多引擎数据库管理平台,致力于保障数据库服务在各种故障场景下的稳定性。然而,传统测试方法难以模拟真实生产环境中的复杂故障,无法充分验证系统韧性。
解决方案
混沌工程通过主动注入可控故障,帮助提前发现系统弱点,驱动系统加固。基于 Chaos Mesh 的系统化测试,我们验证了 KubeBlocks 在主机异常、进程异常、网络异常、压力异常和系统服务异常等场景下的高可用性表现:主节点秒级切换、数据零丢失,并总结了一系列最佳实践。
本文将介绍如何利用 Chaos Mesh 工具,通过故障注入演练验证并提升 KubeBlocks 的高可用能力。
二、Chaos Mesh 简介
Chaos Mesh 是一个开源的混沌工程平台,用于在 Kubernetes 环境中进行分布式系统的混沌测试。通过模拟故障和异常(如网络延迟、服务故障、资源耗尽等),Chaos Mesh 能够帮助开发者和运维人员验证系统的稳定性、容错性和高可用性。
核心架构
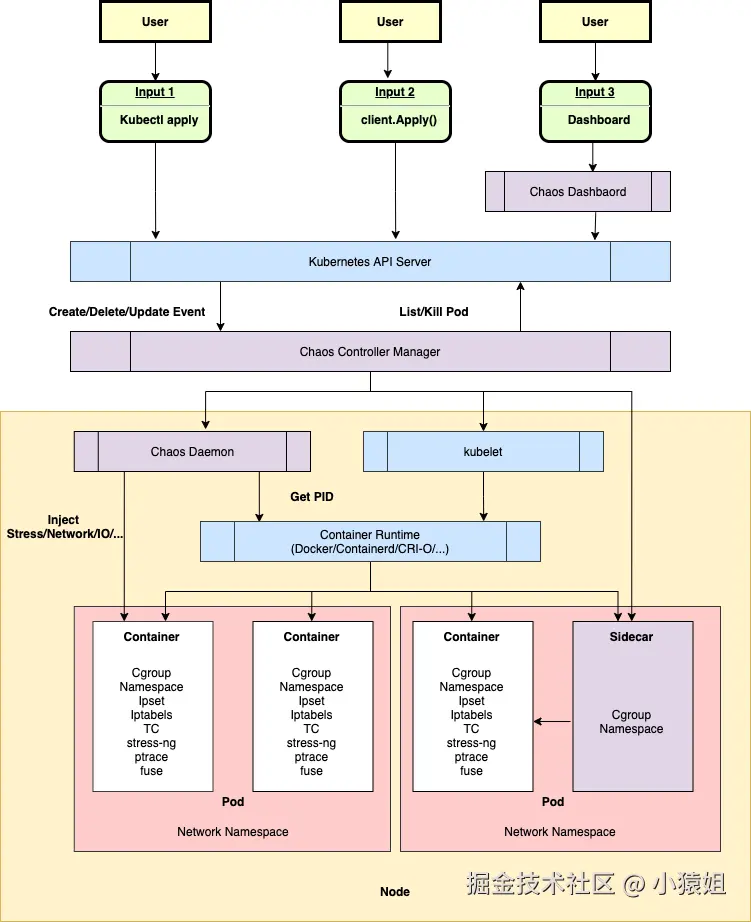
**架构图**
优势
Chaos Mesh 凭借 K8s 原生集成、精细化的故障控制能力及声明式实验管理,与 KubeBlocks 数据库管理场景契合。
- K8s 原生集成:基于 CRD 实现故障注入,直接操作 KubeBlocks 管理的数据库 Pod,无需额外适配。
- 精细化的故障控制能力:直接针对 K8s 资源注入故障(如模拟节点宕机、网络隔离、资源过载),可验证 KubeBlocks 数据库集群的故障切换能力、数据同步机制及脑裂防护。
- 声明式实验管理:通过 YAML 定义故障参数(如丢包率 100%、CPU 负载 100%),适配 KubeBlocks 的声明式数据库管理模型,支持高频、可重复的混沌测试,实验过程自动化,支持与 CI/CD 流水线集成
- 安全隔离性:利用 cgroup 限制资源故障影响范围,确保 CPU/内存压力仅作用于目标容器,保障测试期间 KubeBlocks 数据库集群其他节点不受干扰,避免故障污染生产环境。
通过声明式实验验证了 KubeBlocks 的核心高可用能力:主节点秒级切换、数据零丢失,并驱动多引擎架构持续优化,为云原生数据库的韧性提供了可量化、可复现的故障测试基准。
三、KubeBlocks 引擎高可用测试
测试目标
- 验证 KubeBlocks 管理的各类数据库引擎在真实故障场景下的自愈能力。
- 评估集群数据一致性保障机制的有效性。
- 检测监控告警系统的及时性与准确性。
测试场景
| 故障类型 | 模拟场景 | 预期行为 | 验证目标 |
|---|---|---|---|
| PodChaos | 主节点 Pod 强制删除 | 从节点迅速晋升为新主,应用连接短暂中断后恢复 | 主节点选举、故障切换时间 |
| PodChaos | 单副本 Pod 持续重启 | 服务可用性不受影响,副本集自动恢复 | 副本冗余有效性 |
| NetworkChaos | 主节点网络延迟 (1000ms+) | 触发主节点失联,集群选举新主 | 网络分区容忍性、脑裂防护 |
| NetworkChaos | 主从节点间 100% 丢包 | 主从复制延迟增大,最终一致性保障 | 异步复制健壮性 |
| NetworkChaos | 节点间网络分区 | 形成多数派分区继续服务,少数派分区不可写 | 分区容忍性 (PACELC) |
| StressChaos | 主节点 CPU 过载 (100%) | 主节点响应变慢,可能触发探活超时导致 Failover | 资源隔离、资源过载防护、探活灵敏度 |
| StressChaos | 从节点内存压力 (OOM 模拟) | 从进程崩溃,K8s 自动重启副本 | 资源隔离、进程恢复能力 |
| DNSChaos | 集群内部 DNS 解析随机失败 | 副本间通信偶发失败,依赖重试机制恢复 | 服务发现可靠性、客户端重试 |
| TimeChaos | 主节点时钟向前跳跃 2 小时 | 可能导致 Raft Term 混乱或过期事务,触发主节点驱逐 | 时钟漂移敏感性、逻辑时钟保障 |
测试执行
以主节点 Pod 强制删除场景为例:
- 环境部署**:**KubeBlocks 部署目标数据库集群 (如 MySQL Cluster)。

- 故障定义**:**编写对应故障场景的
chaos-experiment.yaml
YAML
apiVersion: chaos-mesh.org/v1alpha1
kind: PodChaos
metadata:
name: test-primary-pod-kill
namespace: default
spec:
action: pod-kill
mode: one
selector:
namespaces:
- kubeblocks-cloud-ns
labelSelectors:
app.kubernetes.io/instance: mysql-875777cc4
kubeblocks.io/role: primary- 注入故障**:**
kubectl apply -f chaos-experiment.yaml。
YAML
kubectl describe PodChaos test-primary-pod-kill
Status:
Experiment:
Container Records:
Events:
Operation: Apply
Timestamp: <span style="color: #FBBFBC">**2025-07-18T07:55:17Z**</span>
Type: Succeeded
Id: kubeblocks-cloud-ns/mysql-875777cc4-mysql-0
Injected Count: 1
Phase: Injected
Recovered Count: 0
Selector Key: .
Desired Phase: Run
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal FinalizerInited 15m initFinalizers Finalizer has been inited
Normal Updated 15m initFinalizers Successfully update finalizer of resource
Normal Updated 15m desiredphase Successfully update desiredPhase of resource
Normal Applied 15m records Successfully apply chaos for kubeblocks-cloud-ns/mysql-875777cc4-mysql-0
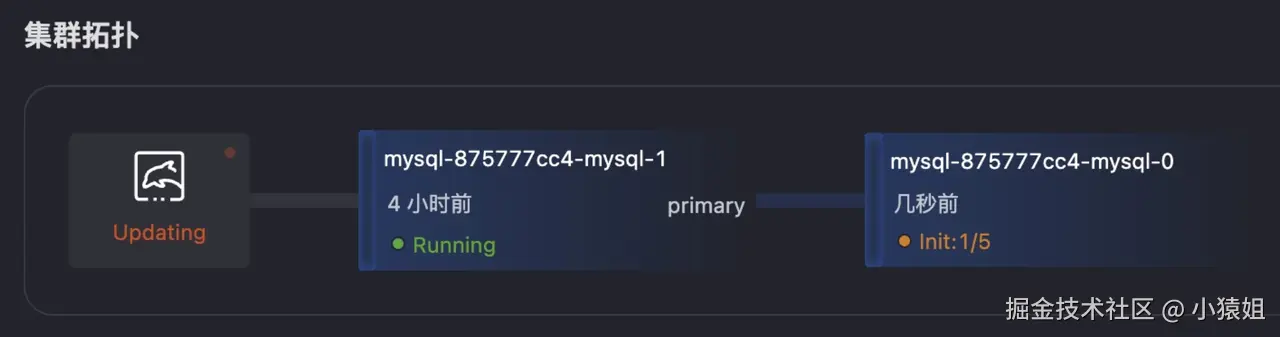
Normal Updated 15m records Successfully update records of resource- 集群监控**:**能看到从节点迅速切换为主节点,故障节点自动恢复后服务正常。
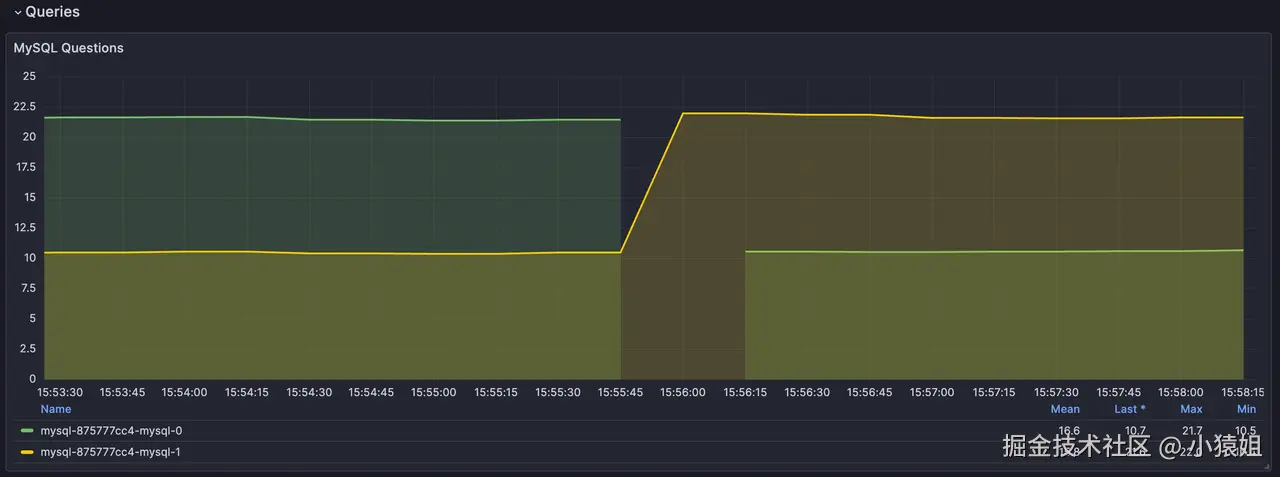
- 结果分析**:主节点秒级切换(**在主节点 Pod 被删除之后,从节点 2s 切换为主节点)。
YAML
kubectl logs -n kubeblocks-cloud-ns mysql-875777cc4-mysql-1 lorry
2025-07-18T07:55:17Z INFO DCS-K8S pod selector: app.kubernetes.io/instance=mysql-875777cc4,app.kubernetes.io/managed-by=kubeblocks,apps.kubeblocks.io/component-name=mysql
2025-07-18T07:55:18Z INFO DCS-K8S podlist: 2
2025-07-18T07:55:18Z INFO DCS-K8S members count: 2
2025-07-18T07:55:18Z DEBUG checkrole check member {"member": "mysql-875777cc4-mysql-0", "role": ""}
2025-07-18T07:55:18Z DEBUG checkrole check member {"member": "mysql-875777cc4-mysql-1", "role": "secondary"}
2025-07-18T07:55:18Z INFO event send event: map[event:Success operation:checkRole originalRole:secondary role:{"term":"1752825318001682","PodRoleNamePairs":[{"podName":"mysql-875777cc4-mysql-1","roleName":"primary","podUid":"ccf5126a-4784-4841-b238-4bf30f98b172"}]}]
2025-07-18T07:55:18Z INFO event send event success {"message": "{\"event\":\"Success\",\"operation\":\"checkRole\",\"originalRole\":\"secondary\",\"role\":\"{\\\"term\\\":\\\"1752825318001682\\\",\\\"PodRoleNamePairs\\\":[{\\\"podName\\\":\\\"mysql-875777cc4-mysql-1\\\",\\\"roleName\\\":\\\"primary\\\",\\\"podUid\\\":\\\"ccf5126a-4784-4841-b238-4bf30f98b172\\\"}]}\"}"}测试结果
基于 KubeBlocks 对多种数据库引擎(包括 MySQL、PostgreSQL、Redis、MongoDB 和 SQLServer 等)的 Chaos Mesh 故障注入测试,测试结果验证了 KubeBlocks 在保障数据库高可用性方面的有效性。
| 测试场景 | 测试指标 | 测试结果 |
|---|---|---|
| PodChaos - 主节点 Pod 强制删除 | 故障切换时间 | MySQL/PostgreSQL/Redis/MongoDB ≤ 10 秒SQLServer Always On ≤ 30 秒 |
| 服务恢复 | 新主节点自动接管,应用连接中断 ≤ 2 秒 | |
| 数据一致性 | 数据零丢失(通过 WAL/Raft 等日志同步保障) | |
| PodChaos - 单副本 Pod 持续重启 | 服务可用性 | ≥ 99.9%(副本自动重建期间请求自动路由到健康节点) |
| 副本恢复时间 | K8s 30 秒内重启 Pod,数据同步延迟 ≤ 5 秒 | |
| NetworkChaos - 主节点网络延迟 | 故障转移触发 | MySQL Raft Group 数据库引擎探活超时(默认 15 秒)触发自动选主 |
| 脑裂防护 | Raft 共识协议阻止双主,仅多数派分区可写 | |
| 性能影响 | 请求延迟峰值 ≤ 35%,切换后恢复正常 | |
| NetworkChaos - 主从节点间 100% 丢包 | 数据同步 | 异步复制中断期间无数据丢失,恢复后自动追增 |
| NetworkChaos - 节点间网络分区 | 分区容忍性 | 多数派分区服务持续可用,少数派分区拒绝写入 |
| StressChaos - 主节点 CPU 过载 (100%) | Failover 触发 | Redis Sentinel 主节点 CPU 持续过载 2 分钟后,触发 failover,新主接管,旧主恢复后自动加入为备库 |
| 资源隔离 | 从节点性能不受影响(K8s cgroup 隔离生效) | |
| StressChaos - 从节点内存压力 (OOM 模拟) | 进程恢复 | K8s 60 秒内自动重启 Pod,服务自愈 |
| 数据同步 | 重启后主从节点全量同步,无状态泄漏 | |
| DNSChaos - 集群内部 DNS 解析随机失败 | 服务发现 | 客户端重试机制保障请求成功率 ≥ 99.9% |
| TimeChaos - 主节点时钟向前跳跃 2 小时 | 事务完整性 | 已提交事务无回滚,时钟校准后集群状态一致 |
四、总结与展望
通过将 Chaos Mesh 深度集成并实践,KubeBlocks 已初步建立起一套标准化的数据库高可用验证体系,成功应对了 Pod 故障、网络故障、资源压力、时间故障、DNS 故障等核心故障场景的挑战。然而,保障数据库服务的持续高可用性是一个永无止境的征程。未来,我们计划在以下方向进行更深层次的探索与实践,以持续提升 KubeBlocks 的可用性保障能力:
短期计划
- 场景精细化:混合故障注入(如网络延迟+节点重启),更贴近真实生产环境中复杂的、连锁发生的故障模式。
- 复杂度提升:模拟区域性故障(如可用区级网络隔离),验证 KubeBlocks 在多 AZ/Region 部署架构下的跨域容灾与恢复能力。
- 覆盖度:将混沌工程实践覆盖 KubeBlocks 自身的管控面组件,确保平台本身的健壮性。
长期目标
- 生态扩展:探索与更广泛的云原生可观测性、告警、自愈工具链(如 Prometheus, AlertManager, Argo Rollouts)的深度集成,构建闭环的韧性保障体系。
- 智能化演进:探索基于 AIOps 的智能故障预测与演练编排,根据历史监控数据、拓扑关系和风险模型,自动生成并执行最具价值的混沌实验。
最佳实践
- 通过渐进式混沌演练(从单点故障到混合场景)暴露系统弱点。结合三大黄金指标监控(SLA/RTO/RPO)量化韧性。将关键故障测试集成至 CI/CD 流水线实现常态化验证。
- 依据测试数据调整部署拓扑与参数,联动监控系统实现分钟级故障感知,定期验证恢复预案有效性,并通过跨团队演练驱动架构持续优化,最终构建"故障暴露-预案执行-数据驱动优化"的高可用闭环。
参考资料
Chaos Mesh 简介:chaos-mesh.org/zh/docs/
KubeBlocks 简介:kubeblocks.io/docs/previe...
KubeBlocks v1.0.0 高可用测试报告:kubeblocks.io/reports/kub...