import torch
from torch import nn
from d2l import torch as d2l
########################################################################################################################################
#@save
class AttentionDecoder(d2l.Decoder):
"""带有注意力机制解码器的基本接口"""
def __init__(self, **kwargs):
super(AttentionDecoder, self).__init__(**kwargs)
@property
def attention_weights(self):
raise NotImplementedError
########################################################################################################################################
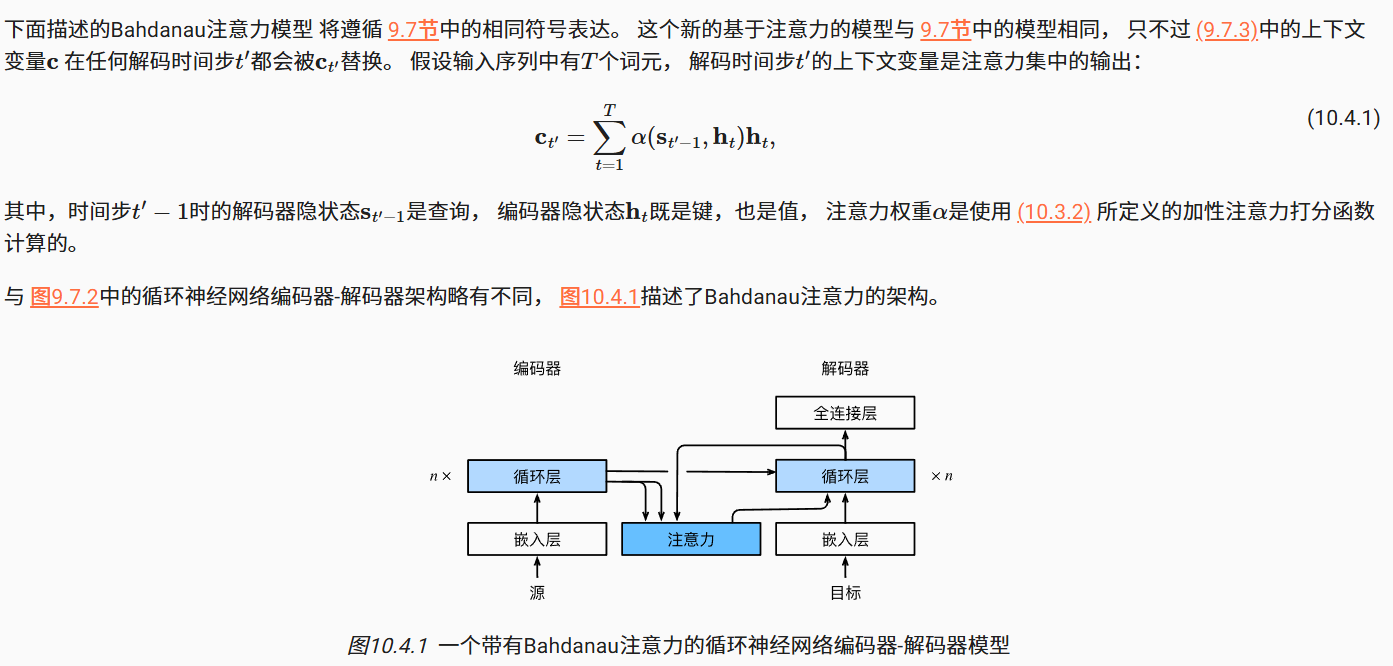
class Seq2SeqAttentionDecoder(AttentionDecoder):
def __init__(self,vocab_size,embed_size,num_hiddens,num_layers,
dropout=0,**kwargs):
super(Seq2SeqAttentionDecoder,self).__init__(**kwargs)
self.attention=d2l.AdditiveAttention(num_hiddens,num_hiddens,num_hiddens,dropout)
self.embedding=nn.Embedding(vocab_size,embed_size)
self.rnn=nn.GRU(embed_size+num_hiddens,num_hiddens,num_layers,dropout=dropout)
self.dense=nn.Linear(num_hiddens,vocab_size)
def init_state(self, enc_outputs, enc_valid_lens, *args):
#enc_outputs:[b,t,h]
#hidden_state:[num_layers,b,h]
outputs, hidden_state = enc_outputs
return (outputs.permute(1, 0, 2), hidden_state, enc_valid_lens)
def forward(self, X, state):
enc_outputs,hidden_state,enc_valid_lens=state
#[B,T,E]->[T,B,E]
X=self.embedding(X).permute(1,0,2)
outputs,self._attention_weights=[],[]
for x in X:
#[B,1,H]
query=torch.unsqueeze(hidden_state[-1],dim=1)
#[B,1,H]
context=self.attention(query,enc_outputs,enc_outputs,enc_valid_lens)
#[B,1,H+H]
x=torch.cat((context,torch.unsqueeze(x,dim=1)),dim=-1)
out,hidden_state=self.rnn(x.permute(1,0,2),hidden_state)
outputs.append(out)
self._attention_weights.append(self.attention.attention_weights)
#(T,B,V)
outputs=self.dense(torch.cat(outputs,dim=0))
return outputs.permute(1,0,2),[enc_outputs,hidden_state,enc_valid_lens]
@property
def attention_weights(self):
return self._attention_weights
########################################################################################################################################
encoder = d2l.Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16,num_layers=2)
encoder.eval()
decoder = Seq2SeqAttentionDecoder(vocab_size=10, embed_size=8, num_hiddens=16,num_layers=2,dropout=0.1)
decoder.eval()
X = torch.zeros((4, 7), dtype=torch.long) # (batch_size,num_steps)
state = decoder.init_state(encoder(X), None)
output, state = decoder(X, state)
#参数测试:
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1
batch_size, num_steps = 64, 10
lr, num_epochs, device = 0.005, 250, d2l.try_gpu()
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = d2l.Seq2SeqEncoder(
len(src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqAttentionDecoder(
len(tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
net = d2l.EncoderDecoder(encoder, decoder)
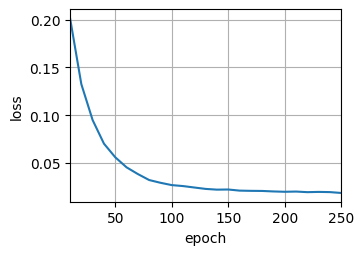
d2l.train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
########################################################################################################################################
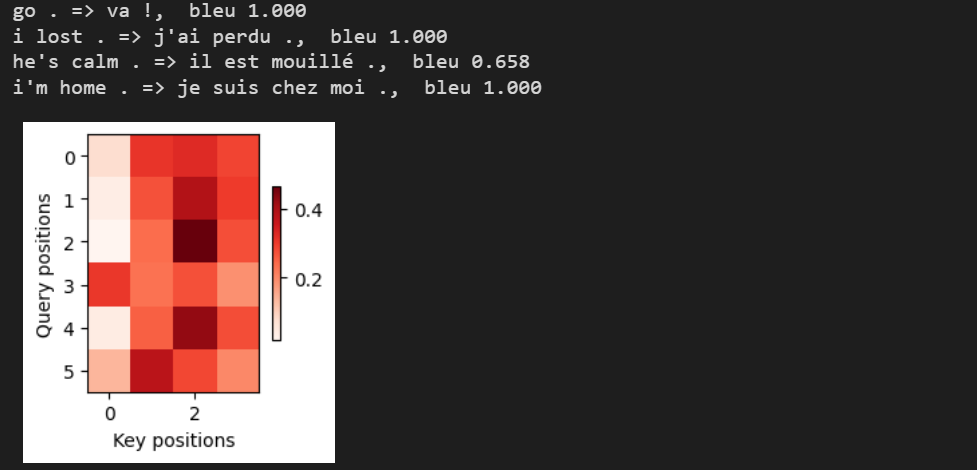
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):
translation, dec_attention_weight_seq = d2l.predict_seq2seq(
net, eng, src_vocab, tgt_vocab, num_steps, device, True)
print(f'{eng} => {translation}, ',
f'bleu {d2l.bleu(translation, fra, k=2):.3f}')
attention_weights = torch.cat([step[0][0][0] for step in dec_attention_weight_seq], 0).reshape((
1, 1, -1, num_steps))
d2l.show_heatmaps(
attention_weights[:, :, :, :len(engs[-1].split()) + 1].cpu(),
xlabel='Key positions', ylabel='Query positions')