目录
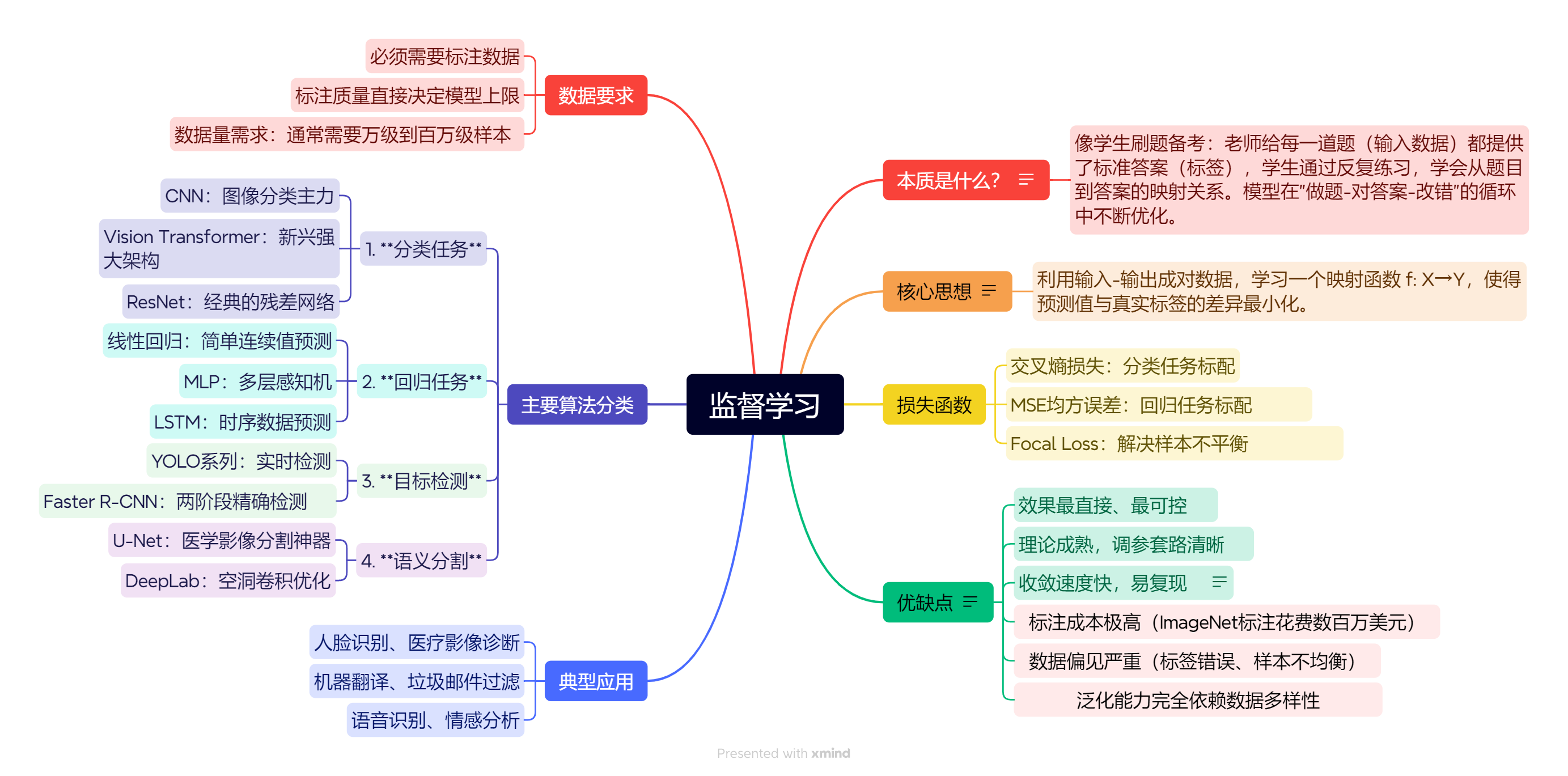
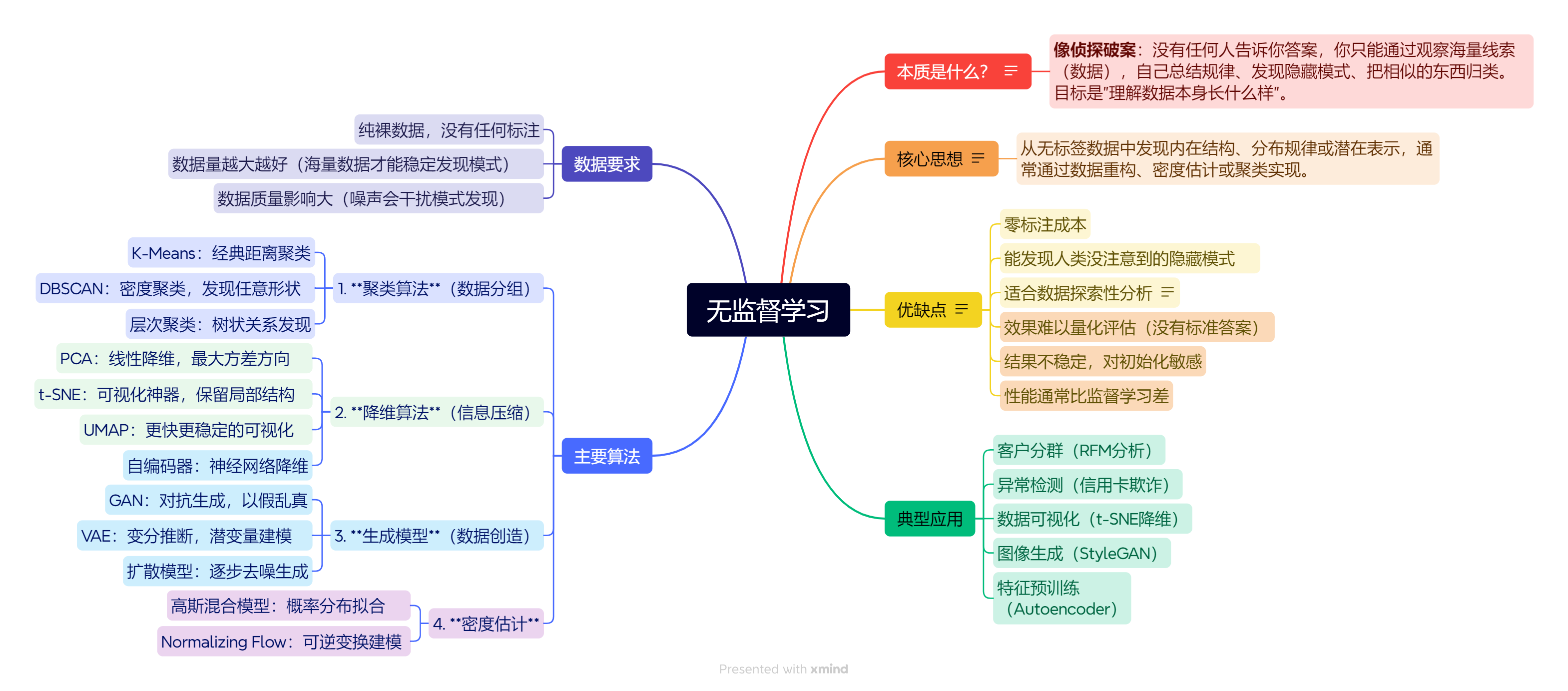
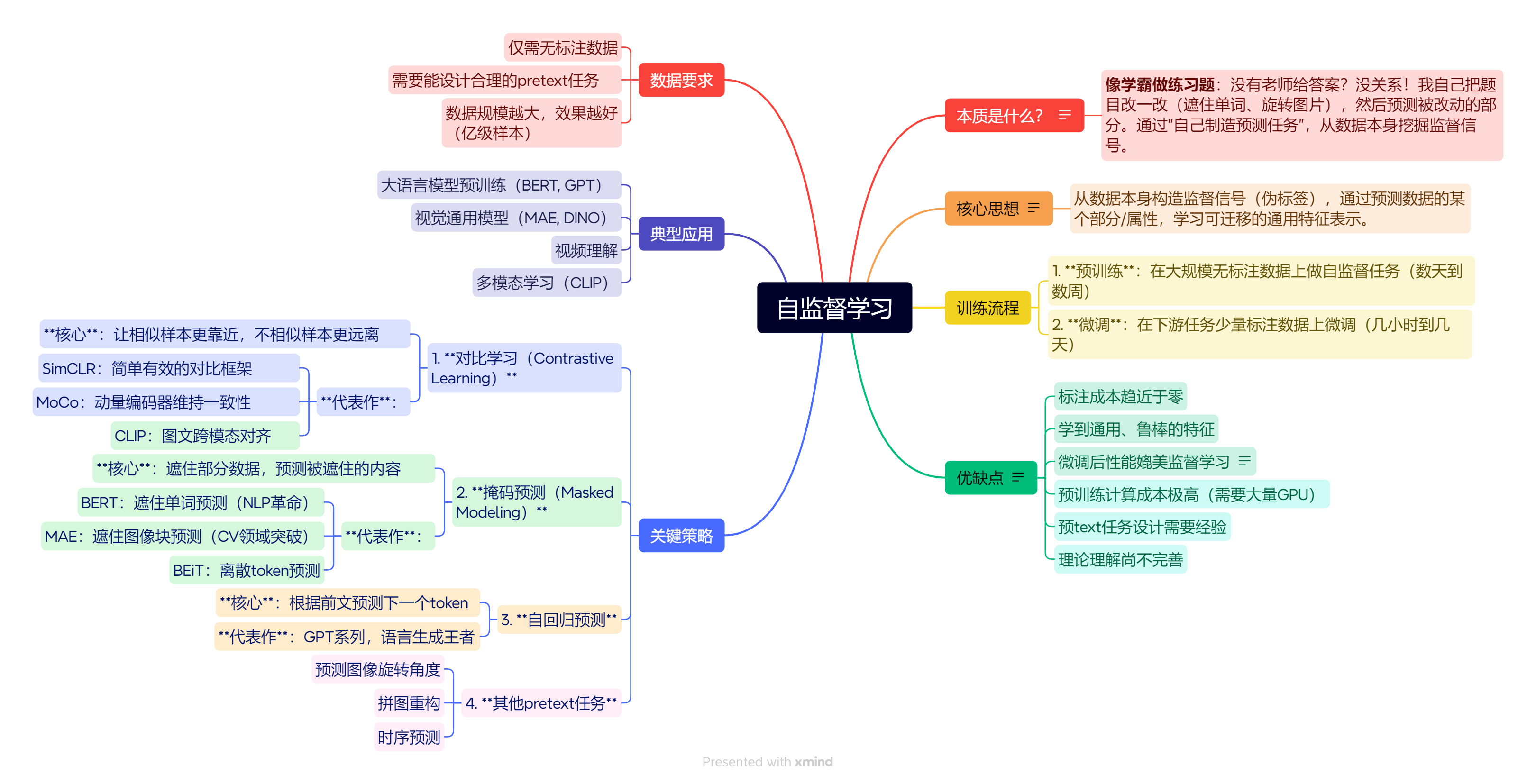
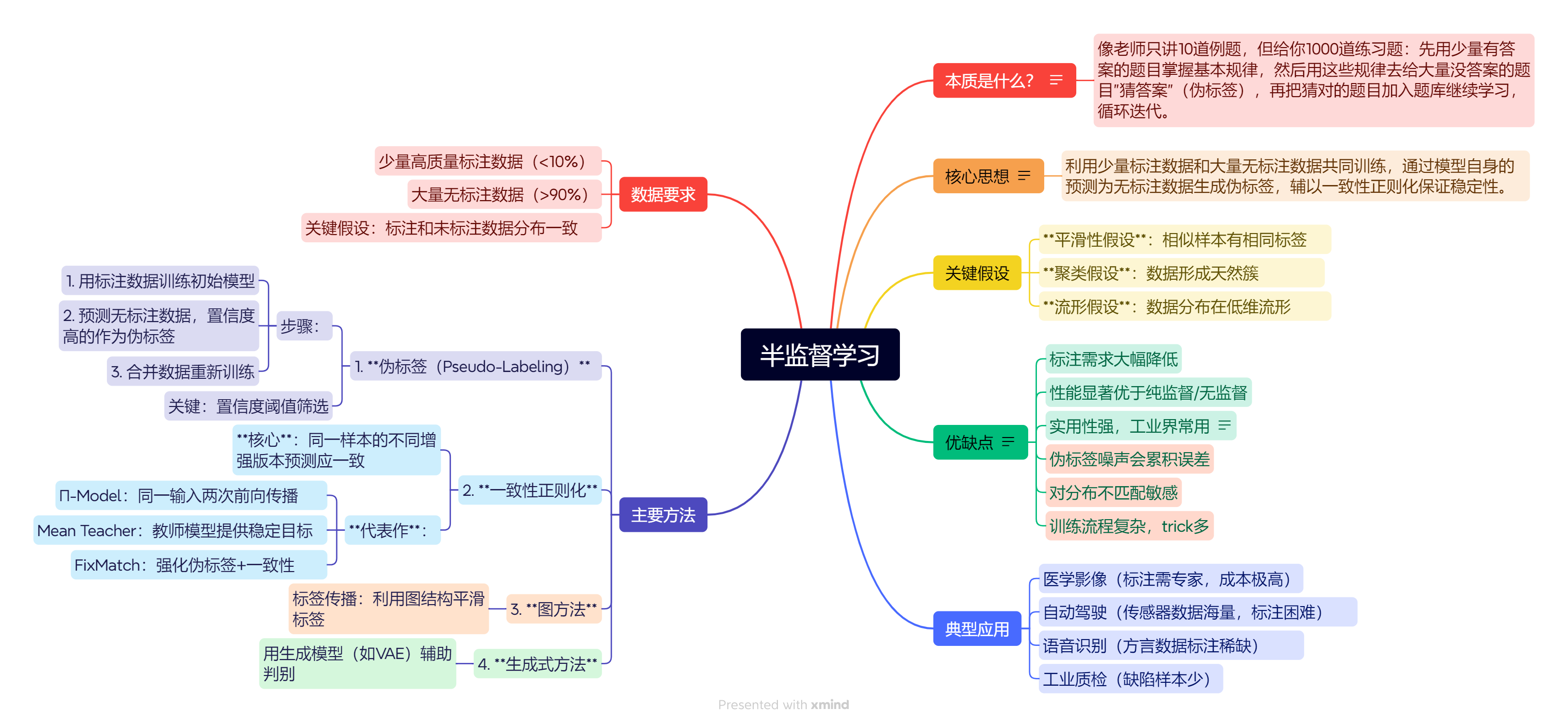
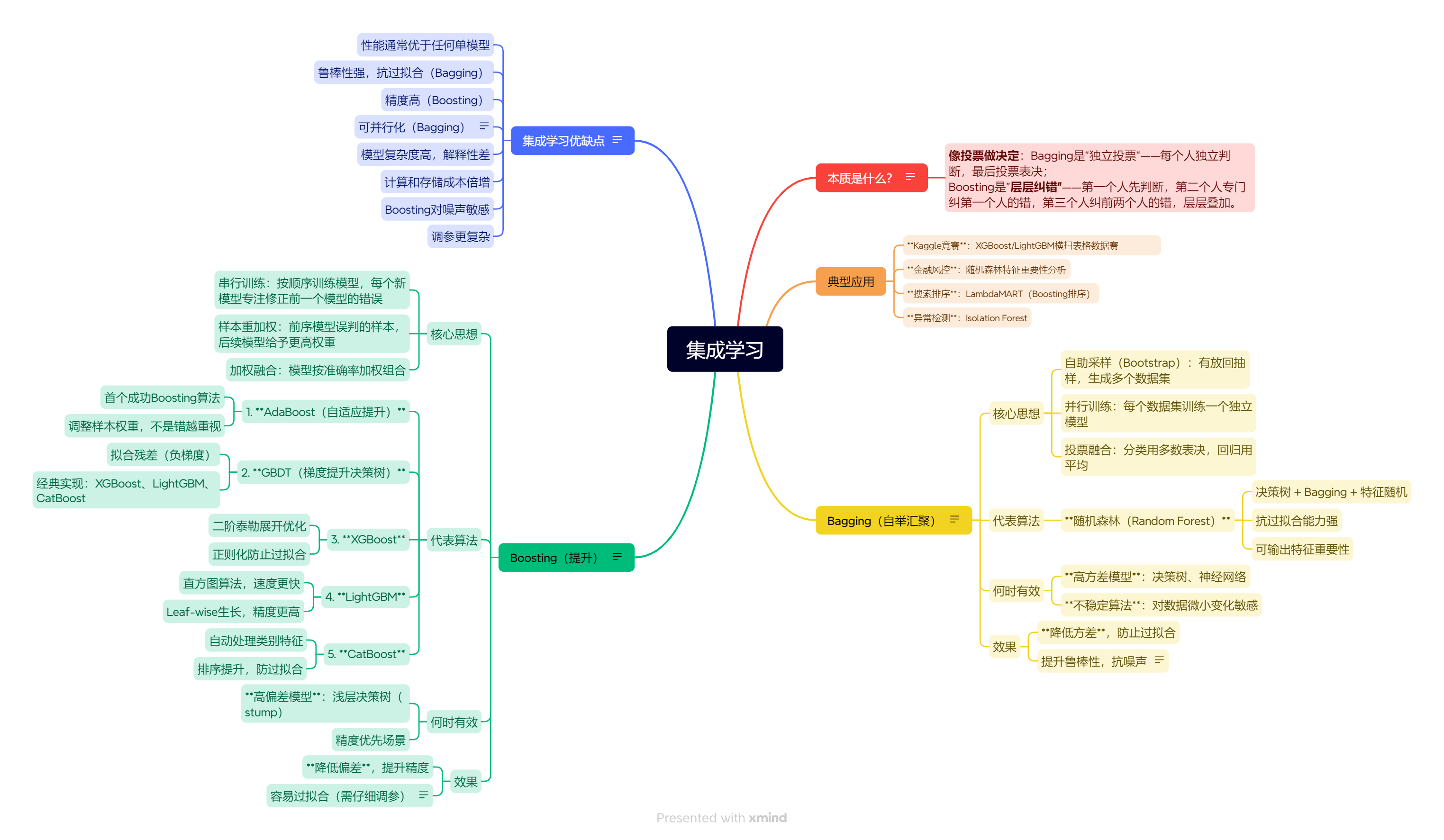
1.深度学习在干啥?
现在有这样一个任务,科学家收集了50万条 巴基斯坦的食物价格数据,想要借助此数据来预测各个食物的每公斤价格,其中部分数据如下所示:
|----------------|--------------|------------|---------------------|-----------|------------------|
| Item | Category | City | Source | Month | Price_per_Kg |
| Milk | Dairy | Lahore | Wholesale Market | June | 188.93 |
| Beef (Local) | Meat | Sialkot | Wholesale Market | April | 866.6 |
| Mango | Fruit | Karachi | Municipal Report | October | 243.67 |
| Flour (Atta) | Grain | Quetta | Retailer Listing | June | 121.4 |
| Tomato | Vegetable | Karachi | Retailer Listing | June | 127.83 |
| Fish (Pomfret) | Meat | Rawalpindi | Online Retailer | May | 1109.04 |
| Ghee | Oil | Quetta | Local Market Survey | December | 1010.15 |
| Potato | Vegetable | Quetta | Retailer Listing | January | 65.6 |
| Mango | Fruit | Hyderabad | Municipal Report | January | 281.27 |
| ... | ... | ... | ... | ... | ... |
从传统的人工角度来看,这个问题几乎不可能解决,原因在于数据量太过于庞大,很难发现食物价格与各个因素之间的潜在关系,并且计算也不方便。针对这么个情况,深度学习由此而生。
从本质上而言,深度学习的过程,就是不断训练一个函数模型的过程,使得这个模型依据我们已知的数据,得到一个函数,使得这个函数能够较为准确的得到我们想要预测值的输出。

现在回到我们最初的表格数据,我们可以发现该数据集,包括5个特征 ,1个标签 ,表格中的每一行即为数据集当中的一个样本 。
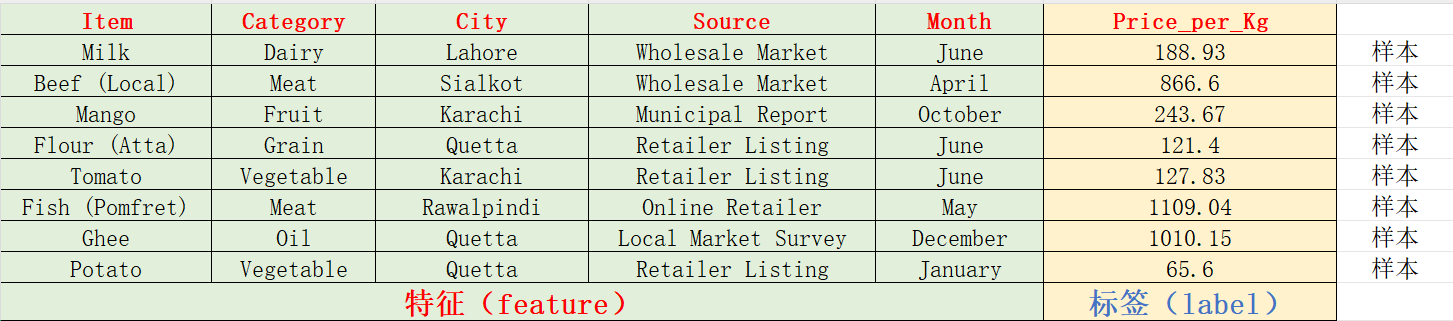
我们通过每个样本的特征输入,不断让模型产生输出,与我们的真实情况对比,通过模型自我不断调整内部的参数,减少预测值与实际值的误差,从而最终实现我们的深度模型。
而针对预测值为连续值的任务,我称之为回归(Regression)任务 ,如果预测值为离散值,我们称之为分类(classify)任务
2.几种学习范式