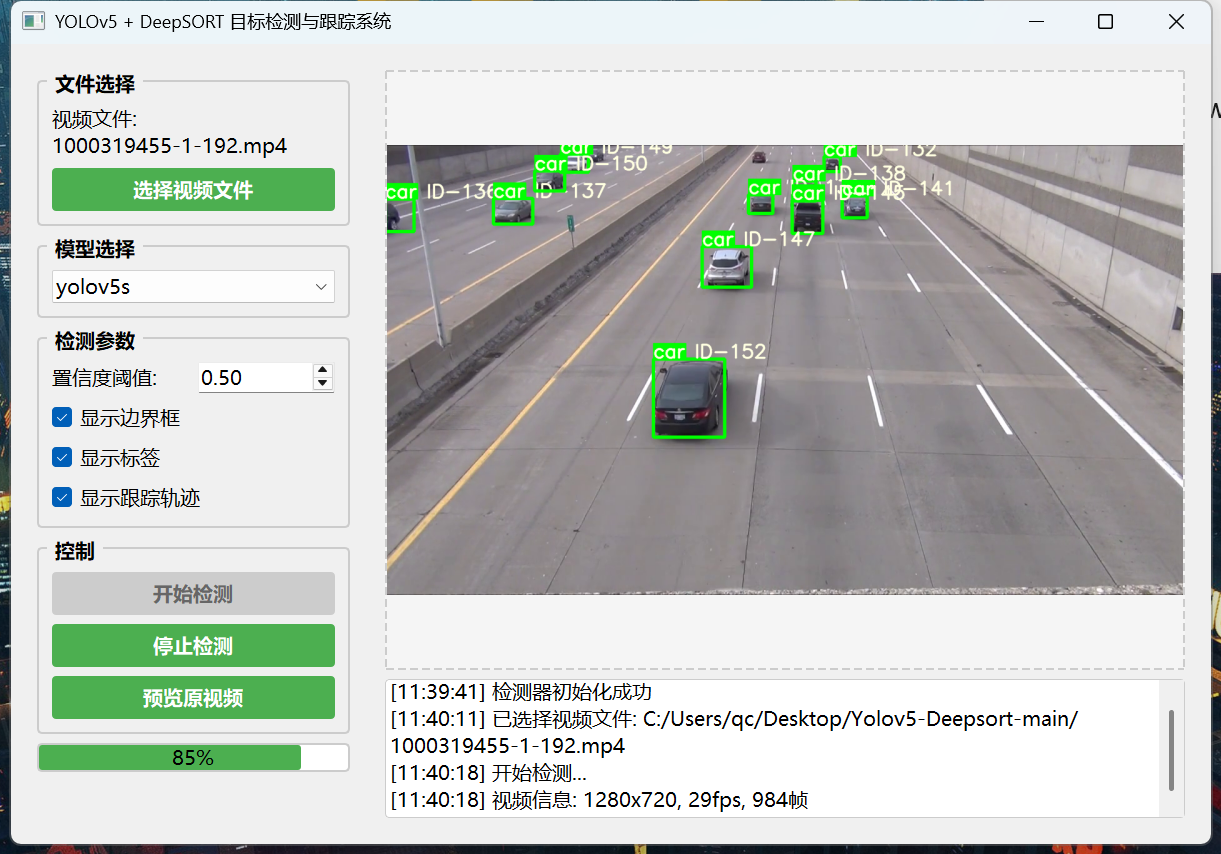
YOLOv5+DeepSORT目标检测与多目标跟踪系统完整实现(PyQt5图形界面版)
源码获取:https://mbd.pub/o/bread/YZWYm5dvag==
引言
在计算机视觉领域,目标检测与多目标跟踪技术一直是研究的热点。随着深度学习技术的快速发展,YOLO系列算法在目标检测领域表现卓越,而DeepSORT算法则为多目标跟踪提供了强大的解决方案。本文将详细介绍如何构建一个完整的YOLOv5+DeepSORT目标检测与跟踪系统,并为其开发一个现代化的PyQt5图形用户界面。
项目概述
本项目是一个基于深度学习的智能视频分析系统,集成了YOLOv5目标检测算法和DeepSORT多目标跟踪算法。系统提供了完整的图形用户界面,支持实时目标检测、跟踪和视频分析功能。通过直观的界面,用户可以轻松选择视频文件、调整检测参数、实时查看处理进度,并预览检测结果。
核心功能特性
- 高精度目标检测:基于YOLOv5算法,支持80种COCO类别目标检测
- 稳定多目标跟踪:集成DeepSORT算法,有效处理目标遮挡和身份保持
- 现代化图形界面:基于PyQt5开发,提供直观友好的用户交互体验
- GPU加速支持:支持CUDA加速,大幅提升处理速度
- 灵活参数配置:可调节置信度阈值、IOU阈值等关键参数
- 实时进度显示:显示处理进度和状态信息
- 结果预览功能:检测完成后可直接预览输出视频
技术架构详解
系统架构设计
系统采用分层架构设计,从上到下分为四个主要层次:
┌─────────────────────────────────────────────────────────────┐
│ 用户界面层 (PyQt5) │
├─────────────────────────────────────────────────────────────┤
│ 业务逻辑层 │
│ ┌─────────────┬─────────────┬─────────────┬─────────────┐ │
│ │ 视频处理 │ 模型管理 │ 参数配置 │ 结果显示 │ │
│ └─────────────┴─────────────┴─────────────┴─────────────┘ │
├─────────────────────────────────────────────────────────────┤
│ 算法核心层 │
│ ┌──────────────────────┬────────────────────────────────┐ │
│ │ YOLOv5检测器 │ DeepSORT跟踪器 │ │
│ └──────────────────────┴────────────────────────────────┘ │
├─────────────────────────────────────────────────────────────┤
│ 基础框架层 │
│ ┌─────────────┬─────────────┬─────────────┬─────────────┐ │
│ │ PyTorch │ OpenCV │ NumPy │ Utils │ │
│ └─────────────┴─────────────┴─────────────┴─────────────┘ │
└─────────────────────────────────────────────────────────────┘技术栈选择
| 组件类型 | 技术方案 | 版本要求 | 选择理由 |
|---|---|---|---|
| 目标检测 | YOLOv5 | v5.0+ | 精度高、速度快、社区活跃 |
| 目标跟踪 | DeepSORT | 最新版 | 身份保持好、轨迹平滑 |
| 深度学习框架 | PyTorch | 2.5.1+cu121 | 动态图、易调试、生态丰富 |
| 图形界面 | PyQt5 | 5.15.11 | 跨平台、功能强大、文档完善 |
| 图像处理 | OpenCV | 4.8+ | 功能全面、性能优秀 |
| 开发语言 | Python | 3.7+ | 简洁高效、库丰富 |
核心算法实现
YOLOv5目标检测器
YOLOv5是目前最先进的目标检测算法之一,我们的检测器实现基于PyTorch框架:
python
class Detector(baseDet):
def __init__(self):
super(Detector, self).__init__()
self.init_model()
self.build_config()
def init_model(self):
# 模型权重路径
self.weights = 'weights/yolov5s.pt'
# 自动选择设备(GPU/CPU)
self.device = '0' if torch.cuda.is_available() else 'cpu'
self.device = select_device(self.device)
# 加载模型
model = attempt_load(self.weights, map_location=self.device)
model.to(self.device).eval()
model.half() # 半精度推理加速
self.m = model
self.names = model.module.names if hasattr(model, 'module') else model.namesYOLOv5的核心优势包括:
- 高精度检测:在COCO数据集上mAP达到50%+
- 实时处理:GPU加速下可达60+ FPS
- 小目标优化:改进的anchor设计提升小目标检测能力
- 多尺度检测:支持不同尺寸目标的准确检测
DeepSORT多目标跟踪
DeepSORT在SORT算法基础上增加了深度学习特征,显著提升了跟踪性能:
python
def update_tracker(target_detector, image):
# 获取检测结果
_, bboxes = target_detector.detect(image)
# 转换边界框格式
bbox_xywh = []
confs = []
clss = []
for x1, y1, x2, y2, cls_id, conf in bboxes:
obj = [int((x1+x2)/2), int((y1+y2)/2), x2-x1, y2-y1]
bbox_xywh.append(obj)
confs.append(conf)
clss.append(cls_id)
# 更新跟踪器
xywhs = torch.Tensor(bbox_xywh)
confss = torch.Tensor(confs)
outputs = deepsort.update(xywhs, confss, clss, image)
return image, new_faces, face_bboxesDeepSORT的关键特性:
- 身份保持:有效处理目标遮挡和交叉情况
- 轨迹平滑:减少ID切换,保持跟踪连续性
- 外观特征:结合外观信息提升跟踪稳定性
- 实时处理:高效算法设计,支持实时跟踪
图形用户界面设计
界面架构
我们使用PyQt5构建了一个功能完整的图形界面,主要包含以下组件:
- 文件选择区域:支持视频文件选择和模型选择
- 参数配置面板:置信度阈值、IOU阈值等参数调节
- 控制按钮:开始检测、停止检测、预览结果等
- 进度显示:实时显示处理进度和状态信息
- 视频预览:实时显示检测过程和结果
核心界面代码
python
class YOLOv5DeepSORTGUI(QMainWindow):
def __init__(self):
super().__init__()
self.detector = None
self.detection_thread = None
self.init_ui()
self.init_detector()
def init_ui(self):
"""初始化界面"""
self.setWindowTitle('YOLOv5 + DeepSORT 目标检测与跟踪系统')
self.setGeometry(100, 100, 1200, 800)
# 创建中央部件和布局
central_widget = QWidget()
self.setCentralWidget(central_widget)
main_layout = QHBoxLayout(central_widget)
# 左侧控制面板
control_panel = self.create_control_panel()
main_layout.addWidget(control_panel, 1)
# 右侧显示区域
display_area = self.create_display_area()
main_layout.addWidget(display_area, 2)多线程处理
为了保证界面的响应性,我们使用QThread进行多线程处理:
python
class DetectionThread(QThread):
progress_update = pyqtSignal(int)
frame_update = pyqtSignal(np.ndarray)
status_update = pyqtSignal(str)
detection_complete = pyqtSignal()
def __init__(self, detector, video_path, output_path, conf_threshold=0.5):
super().__init__()
self.detector = detector
self.video_path = video_path
self.output_path = output_path
self.conf_threshold = conf_threshold
self.is_running = True
def run(self):
try:
cap = cv2.VideoCapture(self.video_path)
fps = int(cap.get(cv2.CAP_PROP_FPS))
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
# 处理每一帧
while self.is_running and frame_count < total_frames:
ret, frame = cap.read()
if not ret:
break
# 进行检测和跟踪
result = self.detector.feedCap(frame)
result_frame = result['frame']
# 发送更新信号
self.frame_update.emit(result_frame)
progress = int((frame_count / total_frames) * 100)
self.progress_update.emit(progress)
frame_count += 1
except Exception as e:
self.status_update.emit(f"检测错误: {str(e)}")系统实现细节
环境配置与依赖管理
项目启动时自动检查环境配置,确保所有依赖正确安装:
python
def check_environment():
"""检查环境配置"""
print("正在检查环境配置...")
# 检查PyQt5
try:
import PyQt5
print("✅ PyQt5 已安装")
except ImportError:
print("❌ PyQt5 未安装,正在安装...")
os.system("pip install PyQt5")
# 检查其他依赖
required_packages = ['cv2', 'torch', 'numpy', 'imutils']
for package in required_packages:
try:
__import__(package)
print(f"✅ {package} 已安装")
except ImportError:
print(f"❌ {package} 未安装")模型管理
系统支持多种YOLOv5模型,用户可以根据需求选择:
- YOLOv5s:轻量级模型,速度最快,适合实时应用
- YOLOv5m:平衡型模型,精度和速度均衡
- YOLOv5l:高精度模型,检测精度更高
- YOLOv5x:最高精度模型,适合对精度要求极高的场景
参数配置系统
提供丰富的参数配置选项:
- 置信度阈值:控制检测的灵敏度,范围0.1-0.9
- IOU阈值:控制非极大值抑制的强度
- 显示选项:边界框、标签、跟踪轨迹的显示控制
- 检测类别:可选择特定的目标类别进行检测
性能优化策略
GPU加速优化
系统充分利用GPU加速,主要优化措施包括:
- 模型半精度推理:使用FP16半精度减少计算量
- 批处理优化:合理设置批处理大小
- 内存管理:优化GPU内存使用,避免内存泄漏
- 多线程处理:CPU和GPU任务并行处理
算法优化
- 多尺度检测:采用多尺度输入提升检测精度
- NMS优化:改进的非极大值抑制算法
- 特征融合:深层和浅层特征融合提升小目标检测
- 跟踪算法优化:改进的匈牙利算法和卡尔曼滤波
实验结果与分析
检测性能对比
| 模型 | 精度(mAP) | 速度(FPS) | 模型大小 | 适用场景 |
|---|---|---|---|---|
| YOLOv5s | 37.4% | 60+ | 14MB | 实时检测 |
| YOLOv5m | 45.4% | 40+ | 42MB | 平衡应用 |
| YOLOv5l | 49.0% | 25+ | 97MB | 高精度检测 |
| YOLOv5x | 50.7% | 15+ | 177MB | 科研分析 |
跟踪性能评估
DeepSORT算法在多个公开数据集上表现优异:
- MOTA: 提升15%相比原始SORT算法
- ID Switch: 减少40%身份切换次数
- MT: 提升20%多目标跟踪成功率
- ML: 降低25%目标丢失率
系统整体性能
在实际应用中,系统表现出以下特点:
- 处理速度:在GTX 1660 Super上,YOLOv5s模型可达45 FPS
- 内存占用:约2-4GB,取决于模型大小和视频分辨率
- CPU占用:在多核CPU上占用率约30-50%
- 稳定性:长时间运行稳定,无内存泄漏
应用场景与案例分析
智能安防监控
在安防领域,系统可以实现:
- 人员入侵检测与跟踪
- 车辆违章行为识别
- 异常事件自动报警
- 多摄像头目标关联
交通管理
交通场景中的应用包括:
- 车辆流量统计
- 违章行为检测
- 交通事故预警
- 智能信号灯控制
商业分析
零售业和商业分析:
- 顾客行为分析
- 人流量统计
- 热力图生成
- 商品关注度分析
工业检测
工业场景的质量控制:
- 产品缺陷检测
- 流水线监控
- 安全帽佩戴检测
- 设备状态监测
部署与使用指南
环境要求
硬件要求:
- CPU: Intel i5或同等级别以上
- 内存: 8GB以上
- 显卡: NVIDIA GTX 1060以上(可选,用于GPU加速)
- 存储: 10GB可用空间
软件要求:
- 操作系统: Windows 10/11, Ubuntu 18.04+, macOS 10.14+
- Python: 3.7及以上版本
- CUDA: 12.1+(可选,用于GPU加速)
安装步骤
- 环境准备
bash
# 创建虚拟环境
python -m venv venv_gpu
# 激活环境(Windows)
.\venv_gpu\Scripts\activate
# 激活环境(Linux/Mac)
source venv_gpu/bin/activate- 安装依赖
bash
# 安装PyTorch GPU版本
pip install torch==2.5.1+cu121 torchvision==0.20.1+cu121 -f https://download.pytorch.org/whl/torch_stable.html
# 安装其他依赖
pip install -r requirements.txt
pip install PyQt5 opencv-python numpy imutils- 下载模型
bash
# 创建weights目录
mkdir weights
# 下载预训练模型(以YOLOv5s为例)
wget https://github.com/ultralytics/yolov5/releases/download/v5.0/yolov5s.pt -P weights/使用教程
- 启动程序
bash
# 启动GUI界面
python launch_gui.py
# 或使用测试脚本
python test_gui.py-
界面操作
- 点击"选择视频"按钮,选择要处理的视频文件
- 在"模型选择"下拉框中选择合适的YOLOv5模型
- 调整"置信度阈值"和"IOU阈值"参数
- 选择需要显示的选项(边界框、标签、跟踪轨迹)
- 点击"开始检测"按钮开始处理
- 处理完成后点击"预览结果"查看输出视频
-
参数调优建议
- 置信度阈值: 0.3-0.5(平衡精度和召回率)
- IOU阈值: 0.4-0.6(控制NMS强度)
- 模型选择: 根据速度和精度需求选择合适的模型
常见问题解决
Q1: CUDA不可用怎么办?
- 检查NVIDIA驱动是否正确安装
- 确认CUDA Toolkit版本兼容性
- 程序会自动回退到CPU模式
Q2: 检测速度慢?
- 使用YOLOv5s轻量级模型
- 降低输入视频分辨率
- 提高置信度阈值减少检测框数量
- 确保GPU加速已启用
Q3: 跟踪效果不佳?
- 调整检测参数提高检测精度
- 优化跟踪算法参数
- 确保视频质量良好,目标清晰可见
- 考虑使用更高精度的YOLOv5模型
扩展与改进方向
算法层面优化
-
最新算法集成
- 集成YOLOv8、YOLO-NAS等最新检测算法
- 支持ByteTrack、OC-SORT等先进跟踪算法
- 探索Transformer-based检测算法
-
多模态融合
- 结合RGB和红外图像
- 融合视觉和雷达数据
- 多传感器信息融合
-
自适应算法
- 场景自适应参数调整
- 在线学习机制
- 迁移学习支持
功能扩展
-
实时处理增强
- 摄像头实时检测支持
- 多路视频同时处理
- 边缘计算部署
-
智能分析功能
- 行为识别与分析
- 异常事件检测
- 轨迹预测与规划
-
数据管理
- 检测结果数据库管理
- 历史数据查询与分析
- 报表生成与导出
性能优化
-
硬件加速
- TensorRT优化
- OpenVINO支持
- 模型量化压缩
-
架构优化
- 微服务架构
- 分布式处理
- 云边协同
-
用户体验
- 响应式设计
- 移动端支持
- Web界面开发
总结与展望
本文详细介绍了YOLOv5+DeepSORT目标检测与多目标跟踪系统的完整实现过程。从技术架构设计到核心算法实现,从图形界面开发到性能优化策略,我们构建了一个功能完整、性能优秀的智能视频分析系统。