1. 类
对象 = 属性 + 方法
一个对象的静态特征,我们称之为属性
一个对象所能做的事情我们叫方法
在 Python 中,默认情况下,类和对象(实例)的属性是通过字典来存放的

python
t = Person()
print(t.hair)
print(t.eyes)
print(t.legs)
t.a()
t.b()
# red
# blue
# 4
# 我好像是一个在海边玩耍的孩子,不时为拾到更光滑的石子而欢欣。
# 杀不死我的,使我更强大同一个类实例化不同对象,数据之间不共享
为什么方法里面会有self?
因为,我们在进行针对class类,进行实例化,也就是创建对象时候,再去调用这个方法的时候,就会把这个对象传进去这个self里面,让他知道,我创建的哪一个对象创建的方法
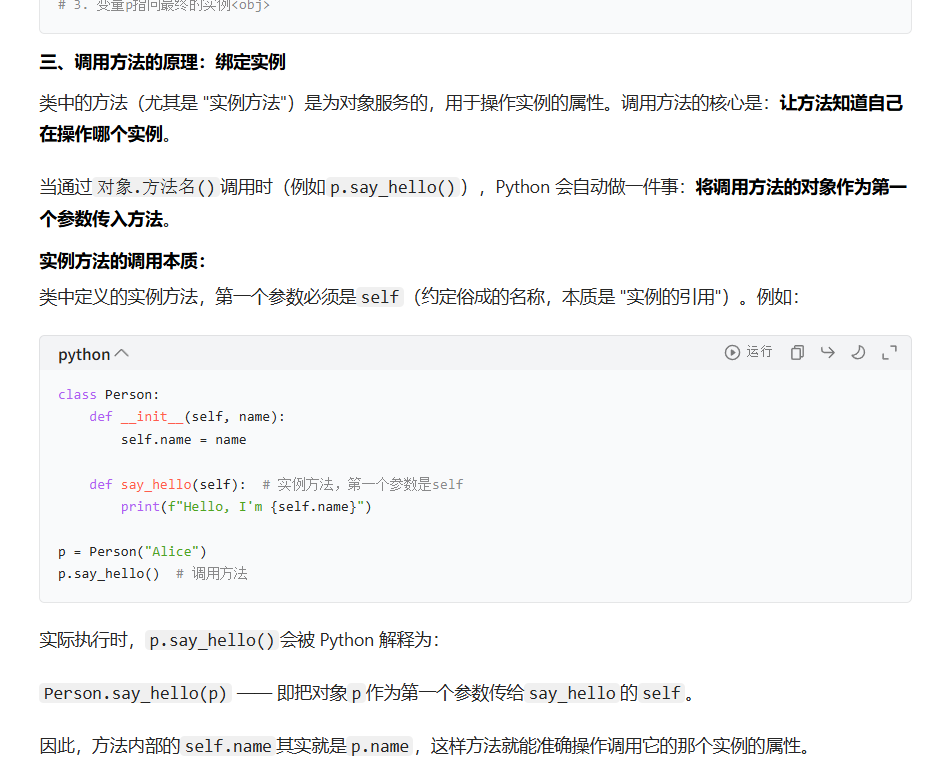
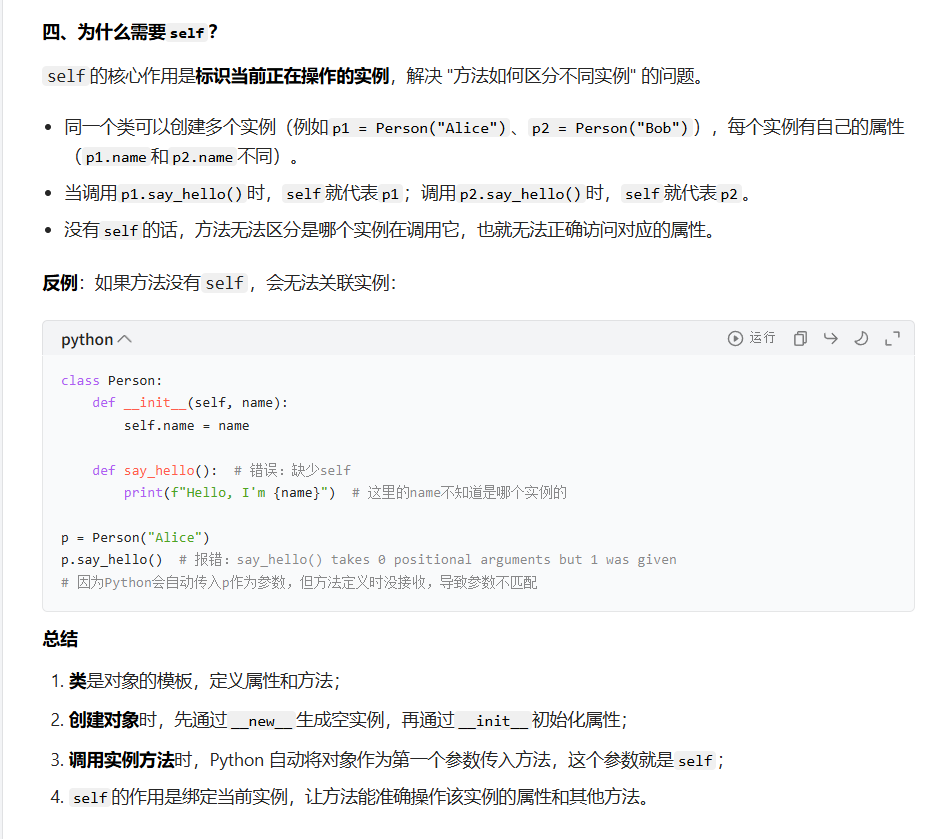
当创建 a = A() 时,a 是 A 的实例。这个实例自己没有定义 x 属性(没有 a.x = ...),所以 self.x 会去它的 "类"(A)中找 x,找到 x = 250
python
class A:
x = 250
def hello(self):
print(self.x)
a = A()
a.hello()如果给 a 单独定义 x,self.x 会优先用实例自己的 x
python
a = A()
a.x = 666 # 给实例a自己定义x属性
a.hello() # 此时self.x取a自己的x,输出:6662 继承
2.1 基本用法
继承是面向对象编程的核心特性之一,它允许一个类(称为 "子类" 或 "派生类")继承另一个类(称为 "父类" 或 "基类")的属性和方法。除非父类的成员是私有成员,即以双下划线__开头,这种情况需要特殊处理
子类无需重新编写父类已有的代码,就能直接使用父类的属性和方法,同时还能在子类中添加新的属性 / 方法,或修改(重写)父类的方法,以满足自身需求
python
class A:
x = 250
def hello(self):
print("hello")
class B(A):
pass
b = B()
b.hello()
print(b.x)
# hello
# 250子类实例可以直接调用父类中定义的属性和方法,无需重新定义
子类可以在继承父类的基础上,新增自己独有的属性或方法,实现功能扩展
python
class A:
x = 250
name = 'tn'
def hello(self):
print("hello")
class B(A):
def bark(self):
print(f"{self.name}在汪汪叫")
b = B()
b.hello()
b.bark()
print(b.x)
# hello
# tn在汪汪叫
# 2502.2 覆盖
子类可以重写父类的方法(覆盖)
如果父类的方法不符合子类的需求,子类可以定义与父类同名的方法,从而 "覆盖" 父类的方法(称为 "方法重写")。调用时,会优先执行子类的方法
python
class A:
x = 250
name = 'tn'
def hello(self):
print("hello")
class B(A):
def bark(self):
print(f"{self.name}在汪汪叫")
def hello(self):
print("我改变了这个方法")
b = B()
b.hello()
b.bark()
print(b.x)
# 我改变了这个方法
# tn在汪汪叫
# 2502.3 super()
子类中调用父类的方法:super()
如果子类重写了父类的方法,但又想在子类方法中复用父类方法的逻辑,可以通过super()函数调用父类的方法。
super()的作用是:获取父类的引用,从而调用父类的属性或方法
python
class A:
x = 250
name = 'tn'
def hello(self):
print("hello")
class B(A):
def bark(self):
print(f"{self.name}在汪汪叫")
def hello(self):
super().hello()
print("我改变了这个方法")
b = B()
b.hello()
b.bark()
print(b.x)
# hello
# 我改变了这个方法
# tn在汪汪叫
# 250**注意:**在__init__方法中,子类如果重写了父类的初始化方法,通常需要用super()调用父类的__init__,以确保父类的属性被正确初始化
python
class Animals():
def __init__(self,name):
self.name = name
class Dog(Animals):
def __init__(self,name,breed):
super().__init__(name)
self.breed = breed
dog = Dog("旺财","金毛")
print(dog.name)
print(dog.breed)
# 旺财
# 金毛当执行 Child().func() 时,会打印 20(而不是父类的默认值 10)。------调用父类方法时,可以传入新参数覆盖默认值
python
class Parent:
def func(self,x = 10):
print(x)
class Child(Parent):
def func(self,x = 20):
super().func()
print(x)
a = Child()
a.func()
# 10
# 202.4 多继承
多继承:一个子类继承多个父类
python 支持 "多继承":一个子类可以同时继承多个父类,从而获得所有父类的属性和方法。语法是在子类名后的括号中列出多个父类,用逗号分隔
python
class A:
print(1)
class B:
print(2)
class C:
print(3)
class D(A,B,C):
pass
a = D()
print(a)
# 1
# 2
# 3
# <__main__.D object at 0x0000025320728590>
# 默认显示地址,是因为你没告诉 Python 该怎么描述这个对象;想换内容,就自己写个描述方法就行继承让 D 拥有了 A、B、C 的 "技能",但 D 本身是一个新的 "身份",这个身份需要通过定义 D 类来创建,所以必须有 D 类才能生成它的实例
不管继承多少父类,只要所有父类都没定义__str__或__repr__,子类就只能用默认的 "地址格式"
 主要看的是谁现在前面,就用谁的方法
主要看的是谁现在前面,就用谁的方法
3. 组合
组合的逻辑更自然:电脑包含 CPU 和内存,通过它们的功能实现自己的功能
组合的核心就是:整体包含多个部分,整体的功能靠部分的功能 "拼" 出来
python
class Cpu:
def run(self):
print("CPU开始运行")
class Memory:
def memory(self):
print("内存加载数据")
class Computer:
cpu = Cpu()
memory = Memory()
def start(self):
self.cpu.run()
self.memory.memory()
my_computer = Computer()
my_computer.start()
# self 指的是当前的电脑实例(比如 my_computer)。
# self.cpu 就是 "这台电脑里的 CPU",调用 run() 就是让这个 CPU 工作;
# self.memory 就是 "这台电脑里的内存",调用 memory() 就是让这个内存工作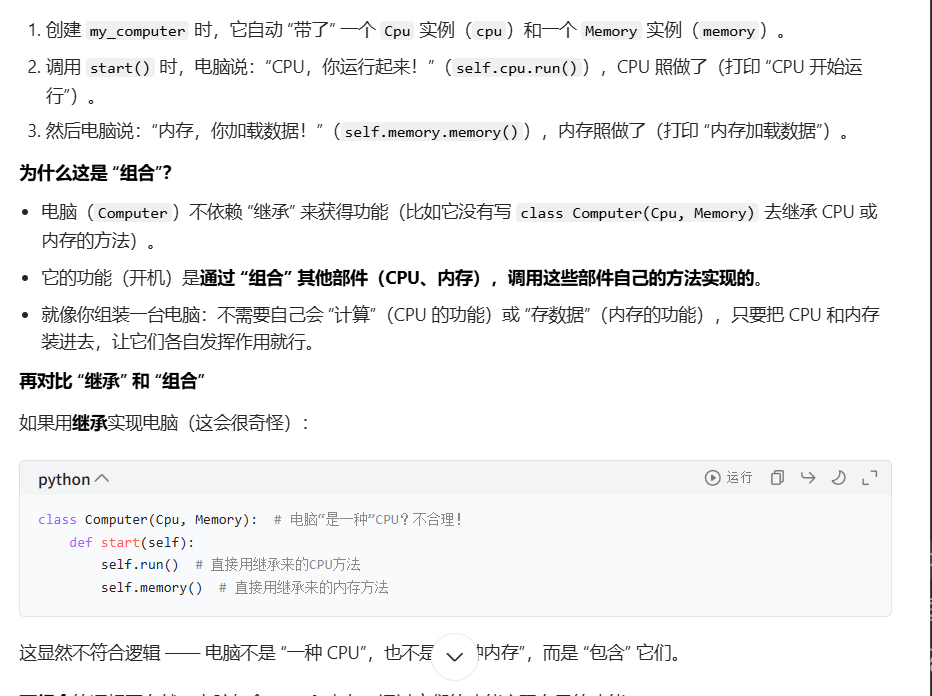

总结:何时用继承,何时用组合
- 继承(is-a):当子类确实是父类的 "一种具体类型" 时使用(比如 "哈士奇是一种狗")
- 组合(has-a):当一个类是 "整体",另一个类是它的 "部分" 时使用(比如 "电脑有一个 CPU")
4 构造函数
构造函数是 init 方法。当你创建一个类的对象时,它会自动执行,用来给对象 "初始化" 属性(比如给对象设置名字、年龄等)
在 Python 中,init 构造函数和 "自己手动给对象定义属性" 的核心区别在于:属性的初始化时机和规范性
python
class Person:
def __init__(self,name,age):
self.name = name # 创建对象时自动给name赋值
self.age = age # 创建对象时自动给age赋值
a = Person("秘密",12) # 创建对象时必须传入参数,否则报错
print(a.name)
print(a.age) # 直接就能用,不用再手动赋值
# 手动给对象添加属性
class Person:
name = 'mimi'
age = 12
a = Person()
print(a.name)
print(a.age)5 钻石继承(菱形继承)
继承结构像 "钻石":有一个共同的基类,中间类都继承它,最终子类同时继承中间类
python
class A:
def func(self):
print("A的方法")
class B(A):
def func(self):
print("B的方法")
class C(A):
def func(self):
print("C的方法")
class D(B, C): # D同时继承B和C,而B、C都继承A
pass
d = D()
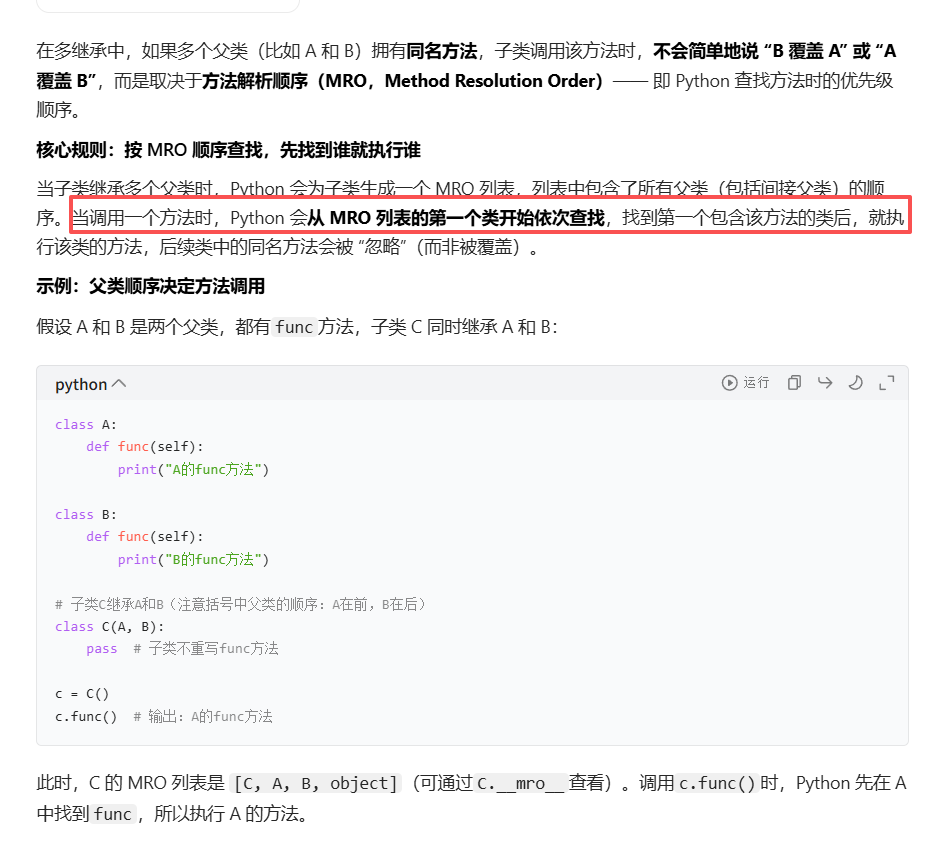
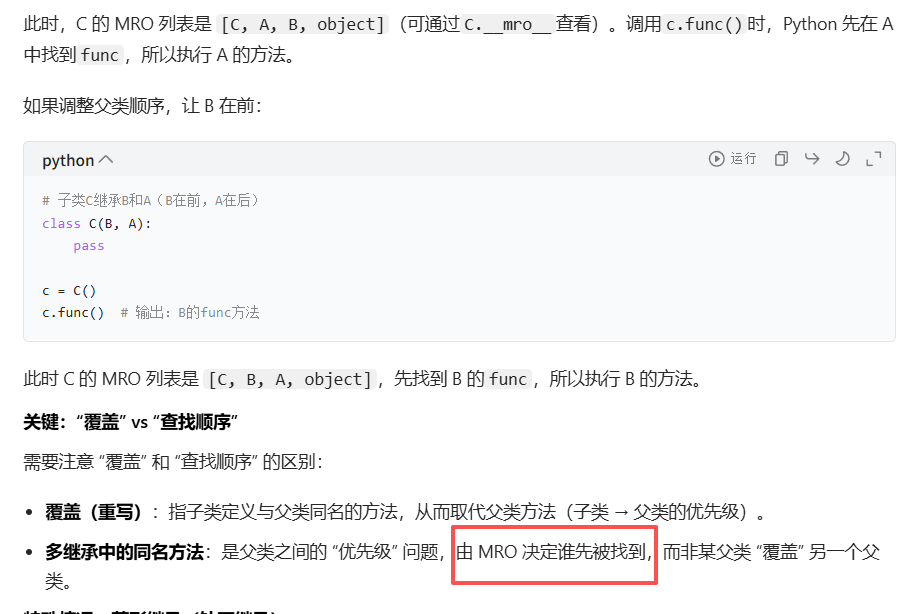
d.func() # 输出啥?Python 会按 "方法解析顺序(MRO)" 找方法:从左到右、深度优先,但避免重复。D的 MRO 顺序是 D → B → C → A,所以调用d.func()时,先找到B的func,输出 "B 的方法"
如果把D的继承改成class D(C, B),MRO 就变成D → C → B → A,调用d.func()会输出 "C 的方法"。这样设计是为了多继承时,方法调用顺序更清晰
6 多态
重写就是实现类继承的多态
在面向对象中,多态通常需要满足 3 个条件
继承关系:不同的类需要继承自同一个父类(或实现同一个接口)
方法重写:子类需要重写父类的方法(即子类对父类的方法有自己的实现)
父类引用指向子类对象:通过父类类型的变量 / 接口,调用子类重写后的方法
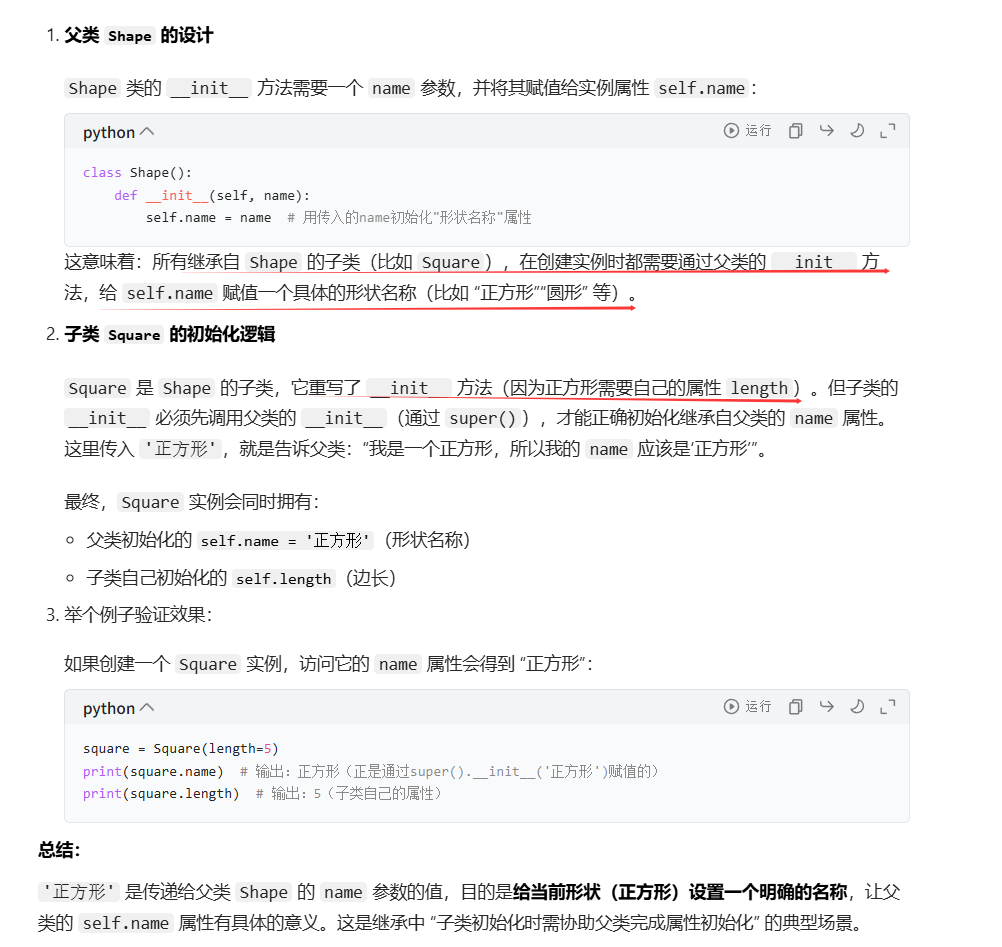
python
class Shape():
def __init__(self,name):
self.name = name
def area(self):
pass
class Square(Shape):
def __init__(self,length):
super().__init__('正方形')
self.length = length
def area(self):
return self.length ** self.length
class Circle(Shape):
def __init__(self,radius):
super().__init__('圆形')
self.radius = radius
def area(self):
return 3.14 * self.radius * self.radius
s = Square(5)
c = Circle(5)
print(s.area())
print(s.name)
print(c.area())
print(c.name)
# 3125
# 正方形
# 78.5
# 圆形在 Square 类的 init 方法中,super().init('正方形') 传入 '正方形',是为了给父类 Shape 的 name 属性赋值,明确当前形状的名称
不同对象通过相同的接口(方法),表现出不同行为
animal(x)函数(统一接口)。功能:接收一个对象x,依次调用x.intro()(让对象自我介绍)和x.say()(让对象发出叫声)。关键:这个函数不限制x的具体类型,只要x有intro和say方法,就能正常工作
python
class Dog():
def __init__(self,name,age):
self.name = name
self.age = age
def intro(self):
print(f'我是一只疯狂小狗,我叫{self.name},今年{self.age}岁了')
def say(self):
print("wangwang")
class Wolf():
def __init__(self,name,age):
self.name = name
self.age = age
def intro(self):
print(f'我是一只勇敢狼狼,我叫{self.name},今年{self.age}岁了')
def say(self):
print("aowu")
c = Cat("咪咪",4)
d = Dog("旺财",5)
w = Wolf("招财",6)
def animal(x):
x.intro()
x.say()
animal(c)
animal(d)
animal(w)背后的核心原因是 Python 的 "鸭子类型"(Duck Typing) 和 动态类型特性------Python 不强制检查对象的 "类型",只关心对象 "有没有需要的方法"

7 私有变量
只能在特定的作用域(通常是定义它的类或函数内部)中被访问和修改,外部无法直接操作
Python 没有严格意义上的 "私有变量",而是通过命名约定实现类似效果
Python 中通过变量命名前缀区分 "私有程度",主要有两种形式
7.1 单下划线前缀(_var):"弱私有"(约定性私有)
只是一种开发者之间的约定,外部可以直接访问、修改
python
class Person:
def __init__(self):
self._name = "amy"
p = Person()
print(p._name)
p._name = 'lily'
print(p._name)
# amy
# lily7.2 双下划线前缀(__var):"强私有"(名称修饰机制)
外部无法直接通过 __变量名 访问,但仍可通过修饰后的名称**(_类名__变量名)访问**(不推荐)
python
class Student:
def __init__(self):
self.__score = 0
s = Student()
# print(s.__score)
# AttributeError: 'Student' object has no attribute '__score'
# 通过修饰后的名称访问(可行,但不推荐)
print(s._Student__score)
# 甚至可以通过修饰后的名称修改(破坏封装,强烈不推荐)
s._Student__score = 100
print(s._Student__score)
# 0
# 100双下划线的设计目的是避免子类意外覆盖父类的私有变量,而非完全禁止外部访问
python
class Parent:
def __init__(self):
# 父类的 __value 会被修饰为 _Parent__value
self.__vslue = 10
class Child(Parent):
def __init__(self):
super().__init__()
# 子类的 __value 会被修饰为 _Child__value(与父类不冲突)
self.__value = 20
c = Child()
print(c._Parent__vslue)
# 10
print(c._Child__value)
# 20
class Parent:
def __init__(self):
# 父类的 __value 会被修饰为 _Parent__value
self.__vslue = 10
class Child(Parent):
def __init__(self):
super().__init__()
# 子类的 __value 会被修饰为 _Child__value(与父类不冲突)
self.value = 20
c = Child()
# print(c._Parent__vslue)
# 10
print(c.value)
# 20子类实例 c 能够访问 _Parent__vslue 的核心原因是:
父类的初始化方法被执行时,会在实例中创建经过名称修饰的私有变量,而子类实例会继承这些属性
Python 对双下划线变量的 "名称修饰" 只是改变了变量名,并没有禁止这些变量被存储在实例中。只要知道修饰后的变量名(如 _Parent__vslue),就可以通过实例直接访问(尽管不推荐)
8 动态给对象添加属性
字典是拿空间换时间
python
class C:
def __init__(self,x):
self.x = x
c = C(250)
print(c.x)
print(c.__dict__)
# 250
# {'x': 250}
c.y = 520
print(c.__dict__)
# {'x': 250, 'y': 520}
c.__dict__['z'] = 1314
print(c.__dict__)
# {'x': 250, 'y': 520, 'z': 1314}8.1 slots
slots 是一个类级别的特殊属性,用于限制实例可拥有的属性集合,并通过取消实例的动态属性字典(dict)来优化内存占用和属性访问效率。它的设计初衷是解决大量实例创建时的内存开销问题,同时增强代码的规范性(避免意外添加无关属性)
slots 需在类定义中声明,其值可以是字符串列表、元组或单个字符串,用于指定该类的实例只能拥有的属性名称。一旦声明,实例无法动态添加__slots__ 中未列出的属性(除非 slots 包含 dict,见后文)
python
class Person:
__slots__ = ['name','age']
def __init__(self,name,age):
self.name = name
self.age = age
p = Person('lily',3)
print(p.name)
print(p.age)
# lily
# 3
p.gender = 'male'
print(p.gender)
# 'Person' object has no attribute 'gender'
class Person:
def __init__(self,name,age):
self.name = name
self.age = age
p = Person('lily',3)
p.gender = 'male'
print(p.gender)
# maleslots 的核心作用:

8.2 slots 不影响类属性的动态添加
slots 仅限制实例属性,类本身仍可动态添加属性或方法
python
# 类属性是属于类本身的属性,所有该类的实例(对象)会共享这个属性,
# 不会因实例不同而改变(除非直接修改类本身)
# 定义方式:
# 在类的内部、所有方法之外直接定义(无需通过self)
class Person:
species = '人类'
class Person:
__slots__ = ["name"]
# 给类动态添加属性:合法
Person.species = "人类"
print(Person.species) # 输出:人类
p = Person()
p.name = "张三"
print(p.species) # 输出:人类(实例可访问类属性)8.3 子类与父类的 __slots__ 关系
若父类定义 slots,子类未定义:子类实例会自动拥有 dict(可动态添加属性),但同时会继承父类 slots 中的属性(即子类实例可拥有父类的 slots 属性 + 自己的 dict 动态属性)
会继承父类__slots__中允许的属性(即父类限制的属性可以在子类实例中使用,且这些属性不会存入__dict__)
同时,子类实例会自动拥有__dict__,用于存储父类__slots__之外的动态属性(包括在__init__中定义的或后续添加的属性)
python
class Parent:
__slots__ = ('a') # 父类限制只能有属性a
class Child(Parent):
def __init__(self,b):
self.b = b
c = Child(1)
c.a = 1 # 父类slots允许的属性a(不存于__dict__)
c.b = 2 # 新增动态属性c(存于__dict__)
print(c.__dict__)
print(c.a) # 输出:20(父类slots允许的属性,正常访问)
# {'b': 2}
# 1
8.4 slots 的适用场景
- 需要创建大量实例的场景(如数据处理、批量对象生成):此时内存优化效果显著(例如,处理百万级用户数据时)
- 属性固定且明确的类:通过限制属性避免误操作(如配置类、数据模型类)
- 对属性访问速度有要求的高频操作场景:如游戏中的角色属性、实时数据更新等
8.5 __slots__ 的局限性
- 失去动态属性灵活性:无法像普通类那样随意添加新属性,可能限制代码扩展性
- 内存优化并非万能:对于少量实例(如几百个),slots 的内存优势不明显,反而可能增加代码复杂度
- 继承场景需谨慎:子类若未定义 slots,会重新获得 dict,可能抵消父类的内存优化
9 魔法方法
它们的核心作用是让自定义类能够模拟 Python 内置类型的行为(如操作符运算、字符串表示、容器特性等),从而让代码更符合 "Pythonic" 风格
- 命名格式:均以__开头和结尾(例如__xxx__)
- 隐式调用:通常不需要手动调用(如obj.str()),而是在特定场景下由 Python 解释器自动触发(如print(obj)会自动调用obj.str())
- 扩展能力:通过重写魔法方法,可让自定义类支持内置函数(如len())、操作符(如+)、容器特性(如\[\]索引)等
9.1 new
1. 本质:类方法,负责 "创建" 实例
new(cls, *args, **kwargs),cls 是 __new__ 方法的第一个参数,代表当前正在被实例化的类本身(是一个类对象)
python
class PositiveInt(int):
def __new__(cls, value): # 这里的 cls 就是 PositiveInt 类本身
#value 是 __new__ 方法的第二个参数,是创建实例时传入的具体数据(即用户调用类时传入的参数)。
#例如执行 a = PositiveInt(10) 时,10 会被传递给 __new__ 方法的 value 参数;如果执行 b = PositiveInt(20),则 value 就是 20当你执行 a = PositiveInt(10) 时,new 中的 cls 就指向 PositiveInt 这个类
new 是类级别的方法(区别于实例方法),第一个参数必须是 cls(代表当前类本身)。它的核心职责是生成一个全新的实例对象,并将这个实例返回
当我们执行 obj = 类名(参数) 创建实例时,Python 会先调用该类的 new 方法,由它完成实例的 "物理创建"(比如在内存中分配空间)
2. 与 init 的分工:先创建,后初始化
new 和 init 是实例化过程的两个关键步骤,但职责完全不同:
- new:负责 "创建" 实例(返回一个实例对象),是实例化的第一步
- init:负责 "初始化" 实例(给实例设置属性等),它在 new 返回实例后被调用,第一个参数是 self(即 new 返回的实例)
- 简单说:new 造 "空盒子",init 往盒子里装东西
3. 核心特性
- 必须返回实例:new 的返回值必须是当前类(或其子类)的实例,否则 init 不会被调用(因为 init 需要 new 返回的实例作为 self)
- 参数传递:new 的 *args, **kwargs 会接收创建实例时传入的所有参数(比如 obj = 类名(1, x=2) 中,1 和 x=2 会传给 new),通常会通过父类的 new 传递下去
- 默认实现 :如果不手动重写 new,Python 会使用父类(通常是 object)的 new 方法,它会自动创建并返回一个实例。
4. 典型使用场景
- new 通常用于控制实例的创建过程,比如: 单例模式 :确保一个类只能创建一个实例(通过判断是否已有实例,有则返回已有实例,否则创建新的)
- 限制不可变类型的子类 :对于 int、str、tuple 等不可变类型,它们的实例创建后无法修改,因此需要通过 new 控制创建逻辑(比如限制值的范围)
python
class PositiveInt(int):
# 重写__new__,确保创建的int实例只能是正数
def __new__(cls,value): # 这里的 cls 就是 PositiveInt 类本身
if value < 0:
raise ValueError("必须是正数")
# 调用父类(int)的__new__创建实例并返回
# 调用父类的__new__方法,让父类来完成实例的实际创建工作
return super().__new__(cls,value)
a = PositiveInt(1)
b = PositiveInt(-2)
# 正常创建,a=10
# 报错:ValueError: 必须是正数
# 为什么要这么写?
# 我们重写 __new__ 方法时,通常只是想在 "实例创建前" 添加一些自定义逻辑(比如在 PositiveInt 中检查 value 是否为正数),
# 但实际创建实例的底层工作(比如在内存中分配空间、初始化基础数据等)并不需要自己实现------ 因为父类(比如 int)已经帮我们做好了。
python
class Single:
# 用一个类属性存储唯一实例
#_instance = None 通常是类内部定义的一个变量
_instance = None
# _instance的作用:
# 它用于存储该类的唯一实例。具体逻辑通常如下:当第一次创建类的实例时,_instance是None,
# 此时会创建新对象并赋值给_instance。后续再尝试创建实例时,会直接返回_instance中存储的已有对象,而不新建
def __new__(cls, *args, **kwargs):
# 如果实例还没创建,就调用父类的__new__创建
if cls._instance is None:
cls._instance = super().__new__(cls)
# super().__new__(cls):调用父类的 "创建实例" 方法
# super().__new__(cls) 翻译过来就是:"请父类(比如 object)帮我创建一个 cls 类的实例"。
# 这里不需要额外参数,因为只需要一个空实例
# 无论是否新建,都返回已有的实例
# 如果去掉 cls._instance = ...,只写 return super().__new__(cls),
# 那么每次调用 Singleton() 都会创建新实例,就不是单例了:
return cls._instance
# 无论是否新建,都返回已有的实例
def __init__(self,name):
self.name = name
# 注意:__init__会在每次调用类时执行(即使实例已存在),所以可能需要控制初始化逻辑
# self.name = name # 多次创建时,name会被覆盖
a = Single("示例一")
b = Single("示例2")
print(a is b)
print(a.name) #输出 "实例2"(被第二次初始化覆盖了)
print(b.name) # 输出 "实例2"(被第二次初始化覆盖了)
# True
# 示例2
# 示例2
class Single:
# 用一个类属性存储唯一实例
#_instance = None 通常是类内部定义的一个变量
_instance = None
# _instance的作用:
# 它用于存储该类的唯一实例。具体逻辑通常如下:当第一次创建类的实例时,_instance是None,
# 此时会创建新对象并赋值给_instance。后续再尝试创建实例时,会直接返回_instance中存储的已有对象,而不新建
def __new__(cls, *args, **kwargs):
# 如果实例还没创建,就调用父类的__new__创建
if cls._instance is None:
cls._instance = super().__new__(cls)
# super().__new__(cls):调用父类的 "创建实例" 方法
# super().__new__(cls) 翻译过来就是:"请父类(比如 object)帮我创建一个 cls 类的实例"。
# 这里不需要额外参数,因为只需要一个空实例
# 无论是否新建,都返回已有的实例
# 如果去掉 cls._instance = ...,只写 return super().__new__(cls),
# 那么每次调用 Singleton() 都会创建新实例,就不是单例了:
return cls._instance
# 无论是否新建,都返回已有的实例
def __init__(self,name):
self.name = name
# 注意:__init__会在每次调用类时执行(即使实例已存在),所以可能需要控制初始化逻辑
# self.name = name # 多次创建时,name会被覆盖
a = Single("示例一")
b = Single("示例2")
print(a is b)
print(a.name) #输出 "实例2"(被第二次初始化覆盖了)
print(b.name) # 输出 "实例2"(被第二次初始化覆盖了)
# True
# 示例2
# 示例2
python
class LimitedInstances:
_max_instances = 3 # 最多3个实例
_instances = [] # 存储已创建的实例
def __new__(cls,*args,**kwargs):
# 如果实例数量已达上限,返回None(或抛出异常)
if len(cls._instances) >= cls._max_instances :
print("已达最大实例数,无法创建新实例")
return None
## 否则创建新实例,并加入列表
instance = super().__new__(cls)
cls._instances.append(instance)
return instance
def __init__(self,n):
self.n = n
# 测试
obj1 = LimitedInstances(1)
obj2 = LimitedInstances(2)
obj3 = LimitedInstances(3)
obj4 = LimitedInstances(4) # 打印:已达最大实例数,无法创建新实例
print(obj1.n) # 1
print(obj4) # None(创建失败)
# 已达最大实例数,无法创建新实例
# 1
# None在 Python 中,cls(*args, **kwargs) 是创建并初始化类实例的 "常规方式",它本质上会自动触发 new 和 init 两个方法的调用,是对实例化流程的完整封装
当你执行 cls(*args, **kwargs) 时,Python 内部会按顺序做两件事:
- 先调用 cls.new(cls, *args, **kwargs) 创建实例(分配内存,生成空对象)
- 再调用实例的 init(*args, **kwargs) 初始化实例(给对象设置属性)
python
def singleton(cls):
"""单例装饰器:被装饰的类只能创建一个实例"""
instance = {} # 用字典缓存实例(支持多个类的单例)
def wrapper(*args, **kwargs):
# 如果类还没创建过实例,就创建并缓存;否则直接返回缓存的实例
if cls not in instance:
instance[cls] = cls(*args, **kwargs) # 这里会调用类的__new__和__init__
return instance[cls] #确保每次实例化被装饰的类时,返回的都是同一个实例
return wrapper #用 wrapper 函数替换被装饰的类,接管实例化逻辑
@singleton
class A:
def __init__(self,a):
self.a = a
print(a)
c = A("1")
d = A("2") # 不打印(复用已有实例)
print(c is d)9.2 init
init 是一个特殊的实例初始化方法,用于在创建类的实例(对象)时,对实例进行初始化操作(如设置初始属性、执行必要的准备工作等)
当通过类创建新实例时(如 obj = 类名(参数)),init 会被自动调用,用于初始化该实例的属性或状态
class 类名:
def __init__(self, 参数1, 参数2, ...):
# 初始化逻辑(通常是给实例绑定属性)
self.属性1 = 参数1
self.属性2 = 参数2
...- self 是 init 方法的第一个参数,且必须存在(否则会报错)。它代表当前正在创建的实例对象本身,用于将属性或方法绑定到该实例上
- self.属性1 = 参数1 的含义是:给当前实例绑定一个名为 属性1 的属性,并赋值为 参数1
- self 不是 Python 的关键字,只是约定俗成的命名(符合 PEP8 规范),理论上可以用其他名称(如 this),但不建议(会降低代码可读性)
很多人会误以为 init 是 Python 的 "构造函数",但严格来说:
- Python 中真正负责创建实例的是另一个魔术方法 new(它会返回一个新的实例对象)
- init 是 "初始化方法",它的作用是对 new 创建的实例进行初始化(设置属性等),因此 init 没有返回值(或说必须返回 None,否则会报错)
继承中的__init__:
当子类继承父类时,若子类定义了 __init__,需要手动调用父类的 __init__(否则父类的初始化逻辑不会执行),通常通过 super() 实现
python
class Animal:
def __init__(self, name):
self.name = name
print(f"动物名称:{self.name}")
class Dog(Animal): # 继承Animal
def __init__(self, name, breed):
# 调用父类的__init__,初始化name属性
super().__init__(name)
self.breed = breed # 子类自己的属性
# 创建Dog实例
dog = Dog("旺财", "金毛")
# 输出:动物名称:旺财(父类__init__被调用)
print(dog.breed) # 输出:金毛(子类属性)init 必须返回None:
若尝试让 init 返回其他值(如整数、字符串),Python 会抛出 TypeError:
python
class Test:
def __init__(self):
return 1 # 错误!__init__不能返回非None值
t = Test() # 报错:TypeError: __init__() should return None, not 'int'- 调用 init 时,self 参数不需要手动传递,Python 会自动将当前创建的实例作为 self 传入。例如 Person("Alice", 30) 中,实际传递给 init 的参数是 (p1, "Alice", 30)(p1 是创建的实例)
- init 中通过 self.属性 定义的是实例属性(每个实例独立拥有);而直接定义在类中的属性是类属性(所有实例共享)
9.3 del
- del 是一个特殊的魔法方法(也称为析构方法),用于定义对象被垃圾回收器销毁时自动执行的操作
- 它与构造方法 init 相对:init 负责对象的初始化,而 del 负责对象销毁前的清理工作
- del 方法会在对象的引用计数变为 0(即没有任何变量引用该对象),即将被垃圾回收器回收时自动调用。其主要用途是释放对象占用的资源(如文件句柄、网络连接、数据库连接等)
调用时机:
- 当对象的引用计数降至 0 时,垃圾回收器会触发 del 方法,随后销毁对象
- del 语句的作用是减少对象的引用计数,而非直接调用 del。只有当引用计数减为 0 时,del 才可能被调用
( 如果列表 1,2,3 原本被 a 和 b 同时引用(引用计数为 2),执行 del a 后引用计数变为 1(仍被 b 引用),此时不会调用 del;只有再执行 del b 使引用计数变为 0 时,才可能触发 del)
- 程序退出时,未被回收的对象会被强制销毁,此时 del 可能会被调用(但顺序不确定)
(如果有两个循环引用的对象 A 和 B , A 引用 B,B 引用 A,导致两者引用计数始终不为 0,程序退出时销毁它们,可能先调用 A 的 del,也可能先调用 B 的 del,无法预测。这也是不建议过度依赖 del 的原因之一(可能因顺序问题导致资源释放异常))
python
class Resource:
def __init__(self,name):
self.name = name
print(f"[{self.name}] 初始化完成,占用资源")
def __del__(self):
print(f"[{self.name}] 销毁,释放资源")
# 创建对象(引用计数为 1)
a = Resource("资源") # 输出:[资源A] 初始化完成,占用资源
# 增加引用(引用计数为 2)
b = a
del b # 删除一个引用(引用计数为 1,不触发__del__)
del a # 删除最后一个引用(引用计数为 0,触发__del__)
# 输出:[资源A] 销毁,释放资源
# 要理解 "引用计数增加",可以先简单理解:
# "引用" 就像给对象贴标签,一个对象被多少个变量 "贴了标签",它的引用计数就是多少。
# 当你把一个变量赋值给另一个变量时,相当于给同一个对象多贴了一个标签,引用计数自然就会增加变量(a、b)本身不是对象,它们只是 "指向对象的指针"。当多个变量指向同一个对象时,就相当于多个指针指向同一个地址,这个对象的 "被引用次数"(引用计数)就会增加。只有当所有指针都断开(引用计数为 0),对象才会被销毁
Resource("资源")会创建一个实例对象,就会产生一个地址,a和b都会指向这个地址
在 Python 中,所有数据类型(包括 int、str、list 等)都是对象,变量始终是 "指向对象的引用(指针)"
python
a = 5 # 创建一个 int 对象(值为 5),变量 a 指向这个对象(引用计数 = 1)这里的 5 是一个 int 类型的对象,a 是指向这个对象的引用(类似指针),而非 a 本身 "存储" 了 5
如果给其中一个变量重新赋值,它会指向新的对象,原对象的引用计数减少
python
a = 5 # a 指向 5(计数 1)
b = a # b 指向 5(计数 2)
a = 6 # a 改为指向新的 int 对象 6(5 的计数 -1 → 1;6 的计数 = 1)
print(b) # 输出 5(b 仍指向原来的 5)此时 a 指向新对象 6,b 仍指向旧对象 5,两者互不影响
特殊点:小整数池(优化机制)
Python 为了优化性能,会对 -5 到 256 之间的整数创建 "小整数池"------ 这些整数对象会被提前创建并缓存,所有引用它们的变量都会直接指向指向同一个对象(避免重复创建)
python
a = 100
b = 100
print(id(a) == id(b)) # True(a 和 b 指向同一个 100 对象)
c = 1000
d = 1000
print(id(c) == id(d)) # 通常为 False(1000 不在小整数池,会创建两个不同对象)
python
a = 20000000
b = 20000000
print(a is b)
print(id(a) == id(b))a is b 返回 True:这是 Python 解释器的编译期优化行为,在同一代码块中,对相同的大整数可能复用内存对象(属于实现细节,不同环境 / 版本可能有差异)
- ==:比较 "值是否相等"。
- is 用于判断两个变量是否指向内存中的同一个对象(即判断两个对象的身份是否相同)。它本质上是比较两个对象的 id(内存地址)是否一致(a is b 等价于 id(a) == id(b))
10 property
property 是一个内置装饰器(或函数),用于将类的方法 "伪装" 成属性。它允许你在访问、修改或删除属性时,隐藏底层的方法调用逻辑,让使用者感觉像是在直接操作普通属性,同时又能在背后添加验证、计算、日志等额外逻辑
python
def func1(self):
print(self.a)
class A:
def __init__(self):
self._n = 10
self.a = 100
self.c = func1
def __getattr__(self, name):
if name == "n":
return self._n
return super().__getattr__(name)
a = A()
print(a.__dict__)
print(getattr(a,"n"))
print(getattr(a,"a"))
python
class A:
def __init__(self,x,y):
self.x = x
self.y = y
@property
def m(self):
return self.x * self.y
def mj(self):
return self.x * self.y
@m.deleter
def m(self):
del self.x
del self.y
instance = A(5,6)
print(instance.m)
print(instance.mj())
del instance.m这个代码为什么property里面的参数不用 加self?
python
class A:
_a = 0
def test1(self):
print(123)
def geta(self):
return self._a
def seta(self,aa):
self._a = aa
a = property(geta, seta)
instance = A()
instance.a = 1
print(instance.a)
instance.test1()
A.test1(instance)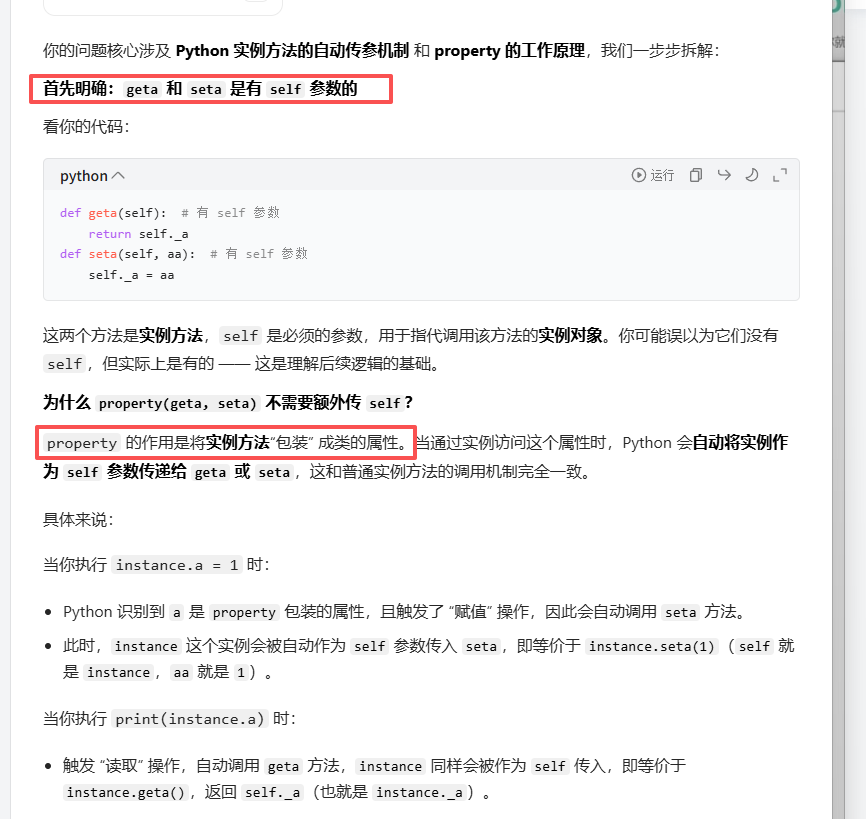
11 类方法、静态方法
11.1 类方法
类方法(Class Method)和静态方法(Static Method)是定义在类中的两种特殊方法,它们与普通的实例方法(第一个参数为 self 的方法)不同,不依赖于类的实例,而是与类本身相关
类方法是与类本身绑定的方法,通过 @classmethod 装饰器定义,其第一个参数固定为 cls(代表类本身,类似实例方法中的 self,但 self 指向实例,cls 指向类)
python
class A:
@classmethod
def class_method(cls,*args,**kwargs):
pass- 参数固定:第一个参数必须是 cls(名称约定,也可以用其他名字,但推荐用 cls),cls 自动绑定到当前类(调用时无需手动传递)
- 访问权限:通过 cls 可以直接访问 / 修改类的属性(如 cls.class_attr),或调用其他类方法(如 cls.other_class_method()),但无法直接访问实例属性(除非显式传入实例)
- 调用方式:可以通过类名直接调用(推荐),也可以通过实例调用(此时 cls 仍指向实例所属的类)
python
class A:
name = "lily"
@classmethod
def func1(cls):
cls.name = 'amy'
return cls.name
print(A.name)
print(A.func1())
# lily
# amy
class A:
name = "lily"
@classmethod
def func1(cls,new):
cls.name = new
return cls.name
print(A.name)
print(A.func1('wang'))
class A:
@classmethod
def func1(cls):
print(1,2,3)
@classmethod
def func2(cls):
cls.func1()
A.func2()实例属性是属于具体实例的(通常在 init 中用 self.xxx 定义),而 cls 指向类,不关联任何具体实例,因此无法直接访问实例属性。如果要访问,必须手动传入一个实例作为参数,再通过实例访问。
python
class A:
def __init__(self):
self.a = 1 # 实例属性(属于实例)
@classmethod
def func1(cls,x): # 显式传入实例o
return x.a # 通过实例访问实例属性
c = A()
# 调用类方法时传入实例
print(A.func1(c))
python
class P:
count = 0
@classmethod
def func(cls):
cls.count += 1
def func2(self):
print(f"打印出了{self.count}次")
class C(P):
count = 0
p = P()
p.func()
p.func2()
# 打印出了1次
c = C()
c.func()
c.func2()
# 打印出了1次11.2 静态方法
静态方法是与类相关但不依赖于类或实例状态的方法,通过 @staticmethod 装饰器定义,没有类似 self 或 cls 的特殊参数,本质上是 "定义在类内部的普通函数"
python
class A:
@staticmethod
def static_method(*t,**d):
# 方法体中无法直接访问类属性或实例属性(除非显式传入)
pass- 无特殊参数 :不需要 self 或 cls,参数列表与普通函数完全一致
- 访问限制 :无法直接访问类属性或实例属性(除非通过参数显式传入类或实例)
- 调用方式 :可以通过类名直接调用(推荐),也可以通过实例调用,但调用时不会自动传递类或实例
当某个函数的逻辑上属于该类(与类相关),但不需要访问类或实例的任何属性时,用静态方法封装(避免污染全局命名空间)
python
class Mathutils:
@staticmethod
def is_even(num):
return num % 2 ==0
@staticmethod
def add(a,b):
return a + b
# 通过类调用静态方法(推荐)
print(Mathutils.is_even(4))
print(Mathutils.add(1,1))
a = Mathutils()
b = a.add(2,1)
print(b)
# True
# 2
# 312 类属性和实例属性
类属性(Class Attribute)
- 定义位置:在类的内部、所有方法之外定义
- 所属对象:属于类本身,而非类的实例(对象)
- 共享性:所有该类的实例共享同一个类属性,修改类属性会影响所有实例
- 访问方式:可以通过类名直接访问,也可以通过实例访问(不推荐,易混淆)
python
class Person:
# 类属性:所有Person实例共享
species = "人类" # 定义在类内、方法外
def __init__(self, name):
self.name = name # 实例属性(见下文)
# 1. 通过类名访问类属性
print(Person.species) # 输出:人类
# 2. 通过实例访问类属性(不推荐,但语法允许)
p1 = Person("张三")
print(p1.species) # 输出:人类(本质是找类的属性)
# 3. 修改类属性(影响所有实例)
Person.species = "智人"
p2 = Person("李四")
print(p1.species) # 输出:智人(p1受类属性修改影响)
print(p2.species) # 输出:智人(p2也受影响)实例属性(Instance Attribute)
- 定义位置:通常在类的 init 方法中,通过 self.属性名 定义
- 所属对象:属于类的单个实例(对象),每个实例的实例属性独立存储
- 共享性:每个实例的实例属性互不干扰,修改一个实例的属性不影响其他实例
- 访问方式:只能通过实例对象访问,不能通过类名访问
python
class Person:
species = "人类" # 类属性
def __init__(self, name, age):
# 实例属性:每个实例独立拥有
self.name = name # 姓名(每个实例不同)
self.age = age # 年龄(每个实例不同)
# 创建两个实例
p1 = Person("张三", 18)
p2 = Person("李四", 20)
# 访问实例属性(只能通过实例)
print(p1.name) # 输出:张三
print(p2.age) # 输出:20
# 修改实例属性(仅影响当前实例)
p1.age = 19
print(p1.age) # 输出:19(p1的年龄变了)
print(p2.age) # 输出:20(p2不受影响)
# 错误:不能通过类名访问实例属性
print(Person.name) # 报错:AttributeError13 模块和包
- 模块:一个 .py 文件就是一个模块,里面可以定义变量、函数、类等
- 包:多个相关模块的集合,本质是一个包含 init.py 文件的文件夹(Python 3.3+ 允许省略,但建议保留以明确标识为包)。
当你用 import 语句导入一个模块时,Python 会做三件事:
- 查找模块:根据 "模块搜索路径" 找到对应的 .py 文件(后面会讲搜索路径)
- 执行模块:将找到的模块文件从头到尾执行一遍(包括所有顶级代码,比如直接写在函数外的 print、变量定义等)
- 缓存模块:将执行后的模块对象存入 sys.modules 字典(一个全局缓存),后续再导入该模块时,直接从缓存中取,不会重复执行
sys.modules是 Python 的全局字典,用于存储已导入的模块对象,是模块导入的 "全局缓存区"。当再次导入同一模块时,Python 会直接从sys.modules中读取已存在的模块对象,不再重复执行模块内的语句,以此提升导入效率
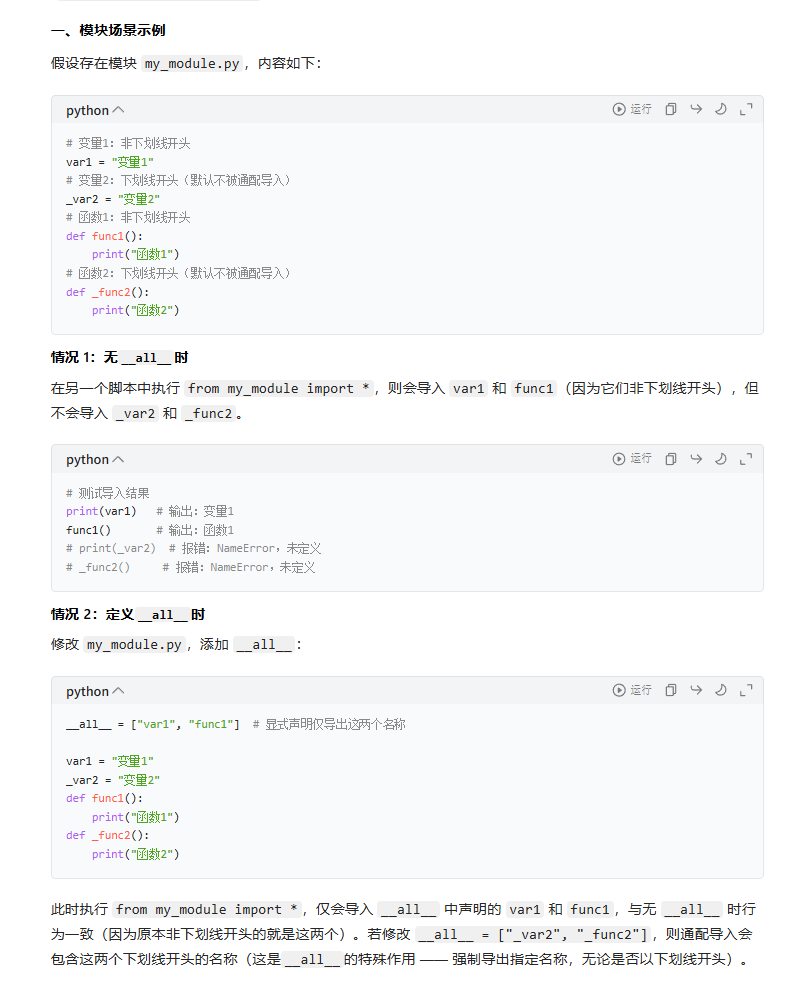
以下面大的代码为例
第一次执行import demo_module:执行模块内所有语句(如打印 "模块执行中..."、定义变量a和函数greet),并将demo_module对象存入sys.modules。
第二次执行import demo_module:直接从sys.modules中获取已存在的demo_module对象,不会再执行模块内的打印语句,直接可用a和greet()。
第一个文件名为 three
def c2f(c):
f = c *1.8 + 32
return f
def f2c(f):
c = (f-32) / 1.8
return c
print(f"测试,0摄氏度 = {c2f(0):.2f}华氏度")
print(f"测试,0华氏度 = {c2f(0):.2f}华氏度")
import three
print(f"测试,0摄氏度 = {three.c2f(0):.2f}华氏度")
print(f"测试,0华氏度 = {three.c2f(0):.2f}华氏度")
# 测试,0摄氏度 = 32.00华氏度
# 测试,0华氏度 = 32.00华氏度
# 测试,0摄氏度 = 32.00华氏度
# 测试,0华氏度 = 32.00华氏度之所以会出现4个print,是因为在 Python 中,使用import语句导入模块时,解释器会从头到尾执行该导入模块中的所有语句,包括变量定义、函数 / 类定义、可执行代码(如打印、赋值等操作)。
13.1 import
最基础的导入方式,导入整个模块,使用时需通过 "模块名。资源名" 访问
# demo.py
name = "demo模块"
print("demo模块被执行了") # 顶级代码,导入时会执行
def say_hello():
print(f"Hello from {name}")
python
# main.py
import demo # 导入时会执行demo.py的顶级代码(打印"demo模块被执行了")
import demo # 第二次导入,直接用缓存,不会重复执行
demo.say_hello() # 输出:Hello from demo模块
python
import sys
# 检查demo模块是否在缓存中
print("demo" in sys.modules) # 第一次导入后就会返回True,第二次导入时依然为True,说明模块已被缓存,未重复执行13.2 from 模块名 import 资源
python
# main.py
from demo import name, say_hello # 导入时仍会执行demo.py的顶级代码
print(name) # 直接用资源名,输出:demo模块
say_hello() # 输出:Hello from demo模块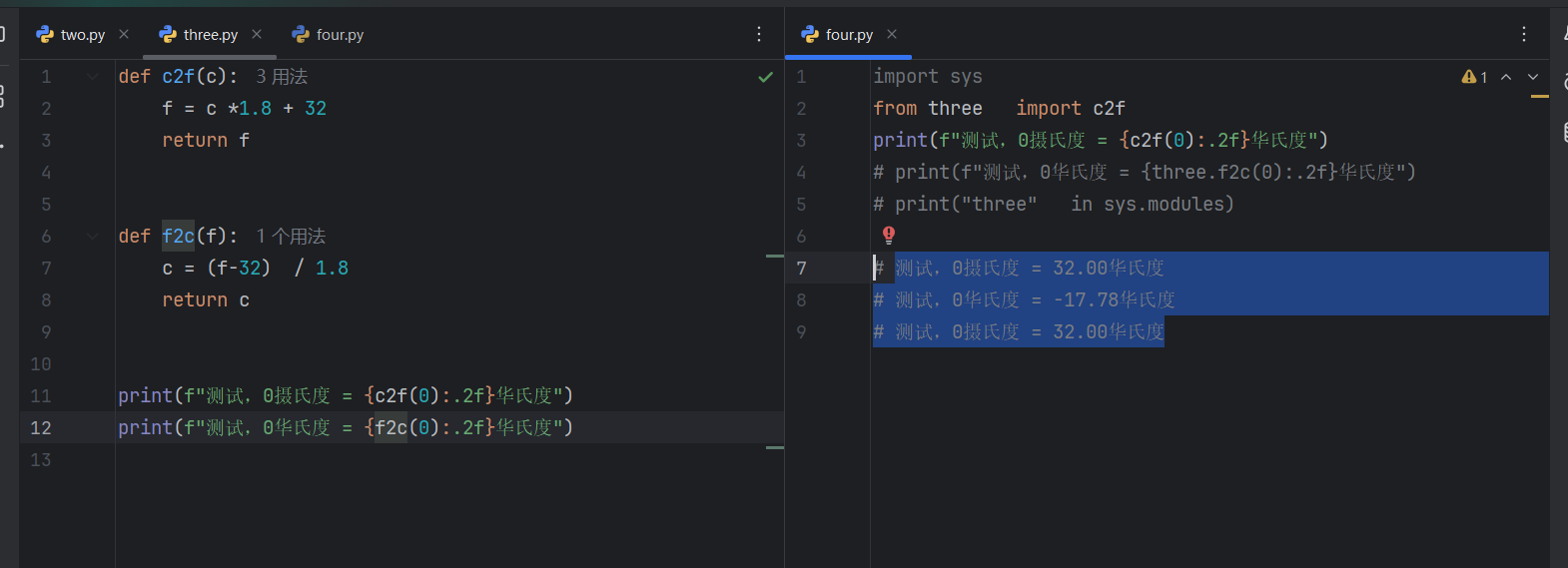
导入时仍会执行demo.py的顶级代码
13.3 from 模块名 import *
导入模块中所有 "公开" 资源(即非以下划线 _ 开头的资源)。不推荐:容易导致名称冲突,且不清楚导入了哪些资源
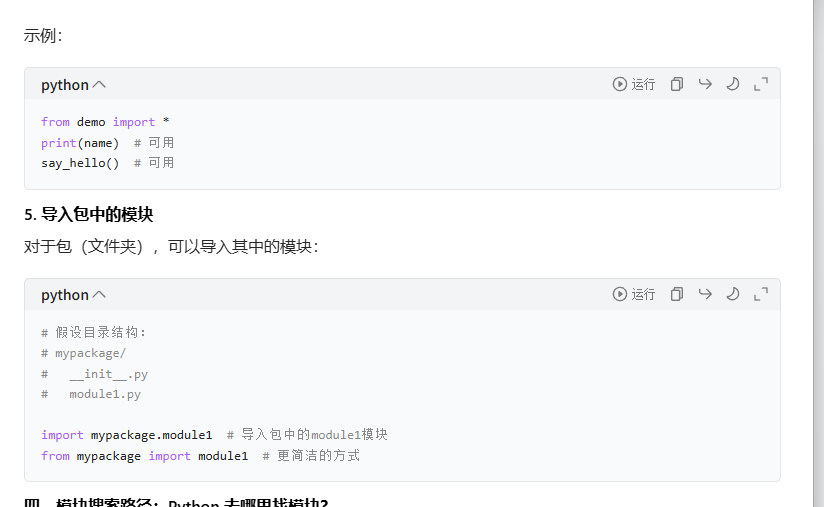


当你执行 import xxx 时,Python 会按以下顺序查找 xxx.py(或包):
- 当前执行脚本所在的目录(即 main 模块的目录)
- 环境变量 PYTHONPATH 中指定的目录
- Python 安装目录下的标准库路径(比如 site-packages)
如果模块不在这些路径中,导入会报错 ModuleNotFoundError,此时可手动将模块所在目录添加到 sys.path
模块中的顶级代码(不在函数 / 类内的代码)会在导入时执行(如之前问题中 three.py 的 print 语句)。这是 "打印四个结果" 的核心原因:被导入模块的 print 执行了一次,当前模块的 print 又执行了一次。
解决办法:如果不希望模块导入时执行某些代码,可将其放入if name == "main": 块中(仅当模块被直接运行时执行,导入时不执行):
python
# three.py
def c2f(c):
return c * 1.8 + 32
# 仅当直接运行three.py时执行,被导入时不执行
if __name__ == "__main__":
print(f"测试,0摄氏度 = {c2f(0):.2f}华氏度")**缓存机制(sys.modules)**模块导入后会被缓存到 sys.modules,重复导入不会重复执行代码。如果需要重新执行模块,可先从缓存中删除:
python
import sys
if "demo" in sys.modules:
del sys.modules["demo"]
import demo # 此时会重新执行demo.py若模块 A 导入模块 B,同时模块 B 又导入模块 A,会导致循环导入,可能报错。解决办法:尽量避免循环依赖,或在函数内部延迟导入(而非顶级导入)
总结:Python 的导入本质是 "执行模块代码并缓存",理解这一点能帮你解释大部分导入相关的现象(比如重复执行、变量覆盖等)。合理使用导入语法和 if name == "main" 块,可让代码更规范