一、消息队列(MQ)
1. 基础概念
为什么要使用消息队列? 消息队列的优缺点是什么? 消息队列的典型应用场景有哪些? 消息队列的常见产品有哪些?
一、为什么要使用消息队列
- 系统解耦
生产者与消费者不直接交互,通过消息队列传递数据,减少系统间的依赖。 - 异步处理
生产者发送消息后即可返回,不必等待消费者处理完成,提升响应速度。 - 流量削峰
在高并发场景(如秒杀、抢购),消息队列能缓冲瞬时大量请求,防止系统崩溃。 - 可靠传输
消息队列通常支持持久化、重试机制,保证消息不丢失。 - 扩展性
新增消费者无需改动生产者逻辑,方便业务扩展。
二、消息队列的优缺点
优点:
- 解耦:降低系统间耦合度,方便维护与扩展。
- 异步:提升系统响应速度。
- 削峰填谷:应对瞬时高并发。
- 可靠性:支持消息持久化与重试。
- 可扩展:方便增加新的业务处理模块。
缺点:
- 系统复杂度增加:引入 MQ 需要额外的部署、运维和监控。
- 延迟:异步处理可能导致数据延迟到达。
- 一致性问题:消息可能重复消费或乱序,需要额外处理。
- 运维成本:需要监控队列积压、消费者状态等。
三、典型应用场景
| 应用场景 | 说明 | 示例 |
|---|---|---|
| 异步处理 | 生产者发送消息后立即返回,消费者异步处理 | 用户注册后发送欢迎邮件 |
| 流量削峰 | 缓冲瞬时高并发请求,平滑系统压力 | 秒杀、抢购活动 |
| 系统解耦 | 不同系统通过 MQ 传递数据,互不影响 | 电商订单系统与库存系统 |
| 数据分发 | 一条消息可被多个消费者订阅处理 | 日志收集与多系统分析 |
| 任务调度 | 定时或延迟执行任务 | 延迟支付、定时通知 |
四、常见消息队列产品
| 产品 | 特点 | 适用场景 |
|---|---|---|
| RabbitMQ | 基于 AMQP 协议,功能丰富,支持多种路由模式 | 企业应用、复杂路由需求 |
| RocketMQ | 高性能、可扩展,支持事务消息 | 电商订单、金融交易 |
| ActiveMQ | 老牌 MQ,支持多协议 | 中小型企业系统集成 |
| Kafka | 高吞吐量、分布式日志系统,适合大数据场景 | 日志收集、流式数据处理 |
| ZeroMQ | 轻量级,嵌入式消息库 | 内部进程通信 |
| Redis/Mysql(简易实现) | 借助数据结构实现队列功能 | 简单任务队列、缓存队列 |
2. RabbitMQ
RabbitMQ 的工作原理?
一、RabbitMQ 的核心工作原理
RabbitMQ 是基于 AMQP(Advanced Message Queuing Protocol) 的消息中间件,核心由 生产者(Producer) 、交换机(Exchange) 、队列(Queue) 、消费者(Consumer) 组成。
基本流程:
- 生产者发送消息到交换机(Exchange)。
- 交换机根据路由规则将消息转发到一个或多个队列(Queue)。
- 消费者从队列中拉取或接收消息进行处理。
- 消息确认(ACK)机制保证消息可靠消费。
二、仲裁队列(Quorum Queue)工作原理
仲裁队列是 RabbitMQ 3.8 引入的新型队列类型,基于 Raft 共识算法,相比传统镜像队列(Mirrored Queue)有更高的可靠性和一致性。
核心机制:
- 强一致性:消息必须在多数节点确认后才算写入成功。
- 自动故障恢复:Leader 节点失效时,自动选举新的 Leader。
- 简化配置 :声明队列时直接指定
x-queue-type=quorum即可。
Raft 算法角色:
- Leader:处理客户端请求,负责日志复制。
- Follower:接收并复制 Leader 的日志条目。
- Candidate:在选举过程中临时角色。
工作流程:
- Leader 选举:集群启动或 Leader 失效时,节点发起选举。
- 日志复制:生产者的消息先写入 Leader 日志,再复制到多数 Follower。
- 确认写入:多数节点确认后,Leader 向生产者返回成功。
- 消费者读取:消费者从 Leader 节点读取消息。
- 消息确认(ACK):消费者处理完成后发送 ACK,Leader 更新状态并同步给 Follower。
三、RabbitMQ 消息流转的详细步骤
| 步骤 | 说明 |
|---|---|
| 1. 连接建立 | Producer 与 Broker 建立 TCP 连接,并创建 Channel |
| 2. 消息发送 | Producer 将消息发送到 Exchange |
| 3. 路由分发 | Exchange 根据绑定的 Routing Key 将消息分发到 Queue |
| 4. 队列存储 | Queue 持久化消息(可选),等待 Consumer 消费 |
| 5. 消息消费 | Consumer 从 Queue 拉取或推送消息 |
| 6. 消息确认 | Consumer 处理完成后发送 ACK,Broker 删除该消息 |
| 7. 异常处理 | 如果 Consumer 发送 NACK 或连接断开,消息可重新入队或丢弃 |
四、仲裁队列关键参数
| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| x-queue-type | string | classic | 设为 "quorum" 启用仲裁队列 |
| x-quorum-initial-group-size | integer | - | 初始组成员数量 |
| x-max-length | integer | - | 队列最大消息数 |
| x-max-length-bytes | integer | - | 队列最大字节数 |
| x-message-ttl | integer | - | 消息存活时间(毫秒) |
| x-delivery-limit | integer | - | 消息最大重试次数 |
| x-overflow | string | drop-head | 队列满时的行为(drop-head/reject-publish) |
五、总结
- 经典队列:简单高效,但在高可用场景下需要镜像队列,存在弱一致性风险。
- 仲裁队列:基于 Raft 算法,保证强一致性和自动故障恢复,适合金融、电商等对数据可靠性要求极高的场景。
- RabbitMQ 工作流程 本质是 生产者 → 交换机 → 队列 → 消费者,仲裁队列只是队列的一种高可用实现方式。
RabbitMQ 的交换机类型有哪些?
RabbitMQ 的交换机(Exchange)是消息路由的核心组件,它负责接收生产者发送的消息,并根据路由规则将消息分发到队列。
RabbitMQ 支持多种交换机类型,每种类型的路由规则不同,适用于不同的业务场景。
一、RabbitMQ 的交换机类型
| 交换机类型 | 路由规则 | 典型应用场景 |
|---|---|---|
| Direct Exchange | 根据完全匹配的 Routing Key将消息路由到队列 | 点对点消息传递,如订单状态更新 |
| Fanout Exchange | 忽略 Routing Key,将消息广播到所有绑定的队列 | 广播通知,如系统公告、日志分发 |
| Topic Exchange | 根据模式匹配的 Routing Key (支持通配符 * 和 #)路由消息 |
多条件匹配,如按地区和业务类型分发消息 |
| Headers Exchange | 根据消息头(Headers)属性匹配路由规则 | 复杂条件路由,如多字段匹配的业务场景 |
| Default Exchange(隐式) | 没有名字的交换机,Routing Key 必须与队列名相同 | 简单直连队列的场景 |
| Dead Letter Exchange(DLX) | 专门接收无法被正常消费的消息(死信) | 消息过期、被拒绝或队列满时的处理 |
二、各类型交换机的路由机制详解
-
Direct Exchange
- 路由规则:
Routing Key完全匹配队列绑定的 Key。 - 示例:
- 队列 A 绑定 Key
order.create - 生产者发送消息时 Routing Key =
order.create→ 消息进入队列 A。
- 队列 A 绑定 Key
- 路由规则:
-
Fanout Exchange
- 路由规则:忽略 Routing Key,消息会被复制到所有绑定的队列。
- 示例:
- 队列 A、B、C 都绑定到同一个 Fanout Exchange → 生产者发一次消息,A、B、C 都收到。
-
Topic Exchange
- 路由规则:支持通配符匹配:
*:匹配一个单词#:匹配零个或多个单词
- 示例:
- 队列 A 绑定 Key
order.*→ 匹配order.create、order.cancel - 队列 B 绑定 Key
order.#→ 匹配order.create.us、order.cancel.cn等。
- 队列 A 绑定 Key
- 路由规则:支持通配符匹配:
-
Headers Exchange
- 路由规则:根据消息头属性匹配(可以是
x-match=any或x-match=all)。 - 示例:
- 队列 A 绑定条件
{x-match=all, format=pdf, type=report} - 只有同时满足
format=pdf且type=report的消息才会进入队列 A。
- 队列 A 绑定条件
- 路由规则:根据消息头属性匹配(可以是
-
Default Exchange
- 路由规则:Routing Key 必须与队列名相同。
- 示例:
- 队列名
task_queue→ 生产者发送消息时 Routing Key =task_queue→ 消息直接进入该队列。
- 队列名
-
Dead Letter Exchange(DLX)
- 路由规则:当消息过期、被拒绝(NACK/Reject)或队列满时,消息会被转发到 DLX。
- 常用于延迟队列 、失败消息处理。
RabbitMQ 的消息路由机制?
RabbitMQ 的消息路由机制 是指消息从生产者发送到交换机(Exchange),再根据路由规则分发到队列(Queue)的全过程。它的核心是 交换机类型 + 绑定关系(Binding) + Routing Key 的组合。
一、消息路由的基本流程
- 生产者发送消息
- 消息包含 Routing Key (路由键)和可选的 Headers(消息头)。
- 交换机接收消息
- 根据自身类型(Direct、Fanout、Topic、Headers 等)决定路由策略。
- 交换机匹配绑定规则
- 交换机与队列之间通过 Binding 建立绑定关系,绑定时可指定 Binding Key 或 Headers 条件。
- 消息进入队列
- 匹配成功的队列会接收到消息,等待消费者处理。
- 消费者消费消息
- 消费者从队列中拉取或接收消息,并进行 ACK 确认。
二、路由机制核心要素
| 要素 | 说明 |
|---|---|
| Exchange(交换机) | 决定消息的分发规则 |
| Queue(队列) | 存储消息,等待消费者消费 |
| Binding(绑定) | 交换机与队列的连接关系 |
| Routing Key(路由键) | 消息的路由标识 |
| Headers(消息头) | 用于 Headers Exchange 的匹配条件 |
三、不同交换机类型的路由规则
| 交换机类型 | 路由规则 | 示例 |
|---|---|---|
| Direct Exchange | Routing Key 完全匹配 Binding Key | Routing Key = order.create → 队列绑定 order.create 才能收到 |
| Fanout Exchange | 忽略 Routing Key,广播到所有绑定队列 | 系统公告、日志分发 |
| Topic Exchange | Routing Key 模式匹配 (* 匹配一个单词,# 匹配多个单词) |
队列绑定 order.* → 匹配 order.create、order.cancel |
| Headers Exchange | 根据消息头属性匹配(x-match=any 或 x-match=all) |
队列绑定 {format=pdf, type=report},消息头满足条件才路由 |
| Default Exchange | Routing Key 必须与队列名相同 | 队列名 task_queue → Routing Key = task_queue |
四、路由匹配过程示例(Direct Exchange)
假设:
- 队列 A 绑定 Key
order.create - 队列 B 绑定 Key
order.cancel
生产者发送:
- 消息 1:Routing Key =
order.create→ 进入队列 A - 消息 2:Routing Key =
order.cancel→ 进入队列 B - 消息 3:Routing Key =
order.update→ 无匹配队列,消息丢弃(或进入备用交换机)
五、特殊路由机制
-
备用交换机(Alternate Exchange)
- 当消息无法路由到任何队列时,可转发到备用交换机处理。
-
死信交换机(DLX)
- 消息过期、被拒绝或队列满时,转发到 DLX。
-
优先级队列
- 根据消息优先级字段决定队列中的消费顺序。
RabbitMQ 如何保证消息可靠性?
RabbitMQ 在设计上提供了多层机制来保证消息可靠性,确保消息在生产、传输、存储、消费的各个环节都尽量不丢失、不重复,并且能被正确处理。下面我给你详细拆解整个过程。
一、消息可靠性的四个关键环节
RabbitMQ 的消息生命周期可以分为 生产者 → Broker(交换机/队列) → 消费者 三个阶段,每个阶段都有对应的可靠性保障机制。
1. 生产者端的可靠性保障
目标:确保消息成功到达 RabbitMQ Broker。
| 机制 | 说明 | 作用 |
|---|---|---|
| Publisher Confirms | 生产者开启确认模式,Broker 在消息成功写入队列后返回 ACK | 确认消息已被 RabbitMQ 接收并持久化 |
| 事务模式(Transactions) | 生产者将消息发送操作放入事务中,提交成功才算发送成功 | 保证消息发送的原子性(性能较低) |
| Mandatory Flag | 如果消息无法路由到任何队列,返回给生产者 | 防止消息被直接丢弃 |
| Return Listener | 配合 Mandatory 使用,监听未路由成功的消息 | 便于生产者做补偿处理 |
2. Broker(RabbitMQ 服务端)的可靠性保障
目标:确保消息在 RabbitMQ 内部存储和转发过程中不丢失。
| 机制 | 说明 | 作用 |
|---|---|---|
| 消息持久化(Message Durability) | 将消息写入磁盘而不是仅存内存 | 防止 Broker 重启导致消息丢失 |
| 队列持久化(Queue Durability) | 队列元数据持久化到磁盘 | 保证队列重启后仍存在 |
| 镜像队列(Mirrored Queue) | 在多个节点上复制队列数据 | 节点宕机时仍可从其他节点读取 |
| 仲裁队列(Quorum Queue) | 基于 Raft 算法的强一致性队列 | 保证多节点一致性和自动故障恢复 |
| 备用交换机(Alternate Exchange) | 无法路由的消息转发到备用交换机 | 防止消息丢弃 |
3. 消费者端的可靠性保障
目标:确保消息被正确处理,不丢失、不重复。
| 机制 | 说明 | 作用 |
|---|---|---|
| ACK 确认机制 | 消费者处理完成后发送 ACK,Broker 才删除消息 | 防止消费者异常退出导致消息丢失 |
| NACK / Reject | 消费者拒绝消息,可选择重新入队或丢弃 | 处理失败时可重试 |
| 手动 ACK | 消费者在业务逻辑完成后手动确认 | 避免自动 ACK 导致未处理消息被删除 |
| 消费端幂等性 | 消费者业务逻辑保证重复消息不会造成数据错误 | 防止重复消费带来的数据污染 |
4. 异常与失败处理机制
目标:在消息无法正常消费或传输时,提供补救措施。
| 机制 | 说明 | 作用 |
|---|---|---|
| 死信队列(DLX) | 消息过期、被拒绝或队列满时转发到 DLX | 便于后续分析和补偿 |
| 延迟队列 | 利用 TTL + DLX 实现延迟重试 | 处理临时失败的业务场景 |
| 消息重试机制 | 消费失败后重新入队或延迟重试 | 提高成功率 |
| 监控与报警 | 监控队列积压、连接状态、节点健康 | 及时发现问题并处理 |
二、RabbitMQ 消息可靠性保障流程图(文字版)
生产者发送消息 ↓ Publisher Confirms / Mandatory 交换机接收消息 ↓ 路由到队列(持久化 / 镜像 / 仲裁) 队列存储消息 ↓ 消费者拉取消息 消费者处理消息 ↓ ACK / NACK / DLX 消息删除或进入死信队列
三、最佳实践建议
-
生产者端
- 开启 Publisher Confirms
- 使用 Mandatory + Return Listener 捕获未路由消息
- 对关键业务使用事务模式(谨慎,性能低)
-
Broker端
- 队列和消息都设置为持久化
- 高可用场景使用 仲裁队列 或 镜像队列
- 配置 备用交换机 防止消息丢弃
-
消费者端
- 使用 手动 ACK
- 业务逻辑保证幂等性
- 消费失败时使用 DLX + 延迟重试
RabbitMQ 如何实现延迟队列?
一、延迟队列的概念
延迟队列 :指消息在队列中等待一段时间后才被消费者消费。
常见应用场景:
- 订单超时取消(如 30 分钟未支付自动取消)
- 延迟通知(如注册后 5 分钟发送提醒邮件)
- 重试机制(如任务失败后延迟重试)
二、RabbitMQ 延迟队列的实现方式
RabbitMQ 本身没有原生延迟队列功能,但可以通过以下两种方式实现:
方式 1:TTL + 死信队列(DLX)
原理:
- 在队列或消息上设置 TTL(Time-To-Live),消息过期后变成死信。
- 死信会被转发到 死信交换机(DLX)。
- DLX 再将消息路由到真正的消费队列,消费者在延迟时间后收到消息。
特点:
- 简单易用,RabbitMQ 原生支持。
- 延迟精度取决于 TTL 设置。
- 适合批量延迟处理。
方式 2:RabbitMQ 延迟插件(x-delayed-message)
原理:
- 安装
rabbitmq_delayed_message_exchange插件。 - 使用特殊的交换机类型
x-delayed-message。 - 生产者在发送消息时指定延迟时间(毫秒)。
- 消息在交换机中延迟一段时间后再路由到队列。
特点:
- 支持精确延迟。
- 不需要死信队列。
- 需要安装插件。
三、TTL + DLX 实现延迟队列示例
1. 队列与交换机配置
java
@Configuration
public class RabbitConfig {
// 死信交换机
@Bean
public DirectExchange dlxExchange() {
return new DirectExchange("dlx.exchange");
}
// 真正消费队列
@Bean
public Queue realQueue() {
return new Queue("real.queue");
}
@Bean
public Binding bindRealQueue() {
return BindingBuilder.bind(realQueue())
.to(dlxExchange())
.with("dlx.routing.key");
}
// 延迟队列(设置 TTL 和 DLX)
@Bean
public Queue delayQueue() {
Map<String, Object> args = new HashMap<>();
args.put("x-dead-letter-exchange", "dlx.exchange"); // 死信交换机
args.put("x-dead-letter-routing-key", "dlx.routing.key"); // 死信路由键
args.put("x-message-ttl", 10000); // TTL 10秒
return new Queue("delay.queue", true, false, false, args);
}
@Bean
public DirectExchange delayExchange() {
return new DirectExchange("delay.exchange");
}
@Bean
public Binding bindDelayQueue() {
return BindingBuilder.bind(delayQueue())
.to(delayExchange())
.with("delay.routing.key");
}
}2. 生产者发送延迟消息
java
@Component
public class DelayProducer {
@Autowired
private RabbitTemplate rabbitTemplate;
public void sendDelayMessage(String msg) {
rabbitTemplate.convertAndSend("delay.exchange", "delay.routing.key", msg);
System.out.println("发送延迟消息: " + msg + " 时间: " + LocalDateTime.now());
}
}3. 消费者接收延迟消息
java
@Component
public class RealConsumer {
@RabbitListener(queues = "real.queue")
public void receiveMessage(String msg) {
System.out.println("接收到延迟消息: " + msg + " 时间: " + LocalDateTime.now());
}
}4. 运行结果示例
发送延迟消息: Hello 延迟队列 时间: 2025-11-10T10:30:00 接收到延迟消息: Hello 延迟队列 时间: 2025-11-10T10:30:10
可以看到,消息延迟了 10 秒 才被消费者接收。
四、最佳实践建议
-
短延迟(秒级)建议用 TTL + DLX,简单稳定。
-
长延迟(分钟/小时级)建议用延迟插件,避免 TTL 队列积压。
-
业务幂等性必须保证,防止延迟消息重复消费。
-
监控队列积压,防止延迟队列中消息过多导致内存压力。
RabbitMQ 如何实现消息确认(ACK)?
一、ACK 机制的作用
RabbitMQ 的 ACK(Acknowledgement)机制 是用来保证消息被消费者正确处理后才从队列中删除,防止因为消费者异常退出或处理失败导致消息丢失。
核心目标:
- 防止消息丢失:只有消费者确认处理完成,Broker 才删除消息。
- 支持消息重试:如果消费者拒绝或未确认,消息可以重新入队。
- 保证可靠性:配合持久化和死信队列,形成完整的可靠性保障。
二、ACK 的类型
| 类型 | 说明 | 场景 |
|---|---|---|
| 自动确认(autoAck=true) | 消息一旦发送给消费者就立即确认,Broker 直接删除消息 | 速度快,但可能丢消息(消费者异常时) |
| 手动确认(autoAck=false) | 消费者处理完成后显式发送 ACK | 推荐,保证消息可靠性 |
| NACK(Negative ACK) | 消费者拒绝消息,可选择是否重新入队 | 处理失败时重试或丢弃 |
| Reject | 拒绝单条消息,可选择是否重新入队 | 单条消息的拒绝处理 |
三、ACK 工作流程
- 消费者接收消息(autoAck=false)
- 执行业务逻辑(如写数据库、调用接口)
- 处理成功 → 发送 ACK
- Broker 删除该消息
- 处理失败 → 发送 NACK 或 Reject
- 可选择重新入队或进入死信队列
- 消费者异常退出且未 ACK
- Broker 会将消息重新投递给其他消费者
四、ACK 的实现方式(Java 示例)
1. 手动 ACK
java
@Component
public class AckConsumer {
@RabbitListener(queues = "ack.queue", ackMode = "MANUAL")
public void receiveMessage(Message message, Channel channel) throws IOException {
String msg = new String(message.getBody());
try {
System.out.println("收到消息: " + msg);
// 模拟业务处理
if (msg.contains("error")) {
throw new RuntimeException("业务处理失败");
}
// 处理成功,发送 ACK
channel.basicAck(message.getMessageProperties().getDeliveryTag(), false);
} catch (Exception e) {
System.out.println("处理失败: " + e.getMessage());
// 发送 NACK,并重新入队
channel.basicNack(message.getMessageProperties().getDeliveryTag(), false, true);
}
}
}2. 自动 ACK
java
@Component
public class AutoAckConsumer {
@RabbitListener(queues = "ack.queue", ackMode = "AUTO")
public void receiveMessage(String msg) {
System.out.println("自动确认消息: " + msg);
}
}自动 ACK 不推荐在关键业务中使用,因为消费者异常会导致消息丢失。
3. Reject 示例
java
channel.basicReject(deliveryTag, false); // false 表示不重新入队五、ACK 机制与可靠性保障结合
- 持久化消息:配合 ACK,防止 Broker 重启丢失消息。
- 死信队列(DLX):处理 NACK/Reject 的消息,便于后续分析。
- 幂等性:防止重复消费导致数据错误。
- 限流(QoS) :配合
channel.basicQos()控制一次拉取的消息数量,避免未确认消息过多。
六、最佳实践
- 关键业务必须使用手动 ACK,并在业务逻辑完成后确认。
- 失败消息进入死信队列,避免无限重试导致队列阻塞。
- 保证消费者幂等性,防止重复消费带来的数据污染。
- 监控未确认消息数量,防止消费者处理过慢导致积压。
七、ACK 流程图(文字版)
消费者接收消息(autoAck=false) ↓ 执行业务逻辑 ↓ 成功 发送 ACK → Broker 删除消息 ↓ 失败 发送 NACK/Reject → 重新入队或进入死信队列
RabbitMQ 如何处理消息堆积?
一、什么是消息堆积
消息堆积是指 RabbitMQ 队列中的消息数量持续增加,消费者无法及时消费,导致队列积压甚至内存、磁盘压力过大。
危害:
- 延迟增加:消息处理时间变长,业务响应慢。
- 内存/磁盘占用过高:可能导致 RabbitMQ 节点崩溃。
- 消息过期或丢失:TTL 消息可能在堆积中直接过期。
- 消费者压力过大:一次性拉取大量消息导致处理失败。
二、消息堆积的常见原因
| 原因类别 | 具体原因 | 说明 |
|---|---|---|
| 消费能力不足 | 消费者数量少、处理速度慢 | 单个消费者处理耗时长,无法跟上生产速度 |
| 生产速度过快 | 短时间内生产大量消息 | 高并发业务场景下生产端压力过大 |
| 消费者异常 | 消费者宕机、网络中断 | 消费端无法正常接收消息 |
| ACK 机制问题 | 未 ACK 或 ACK 过慢 | 消息一直处于未确认状态 |
| 路由设计不合理 | 消息集中到某个队列 | 队列负载不均衡 |
| 限流配置过低 | basicQos 限制过严 | 消费端一次只能拉取少量消息 |
| 消息处理逻辑复杂 | 业务逻辑耗时长 | 如调用外部 API、复杂计算 |
三、RabbitMQ 处理消息堆积的解决方案
1. 提升消费能力
- 增加消费者数量:水平扩展消费端实例。
- 提高消费者并发:多线程/异步消费。
- 优化业务逻辑:减少耗时操作,使用缓存。
- 批量消费:一次处理多条消息,减少 ACK 次数。
2. 控制生产速度
- 生产端限流:控制消息发送速率。
- 消息合并:将多个小消息合并成一个大消息。
- 异步生产:分批发送,避免瞬间压力。
3. 优化 ACK 机制
- 手动 ACK:确保业务完成后再确认。
- 批量 ACK:一次确认多条消息。
- 快速 ACK:业务可异步处理,先确认再处理(需保证幂等性)。
4. 使用优先级队列
- 让重要消息优先被消费,减少关键业务延迟。
5. 队列分片(Sharding)
- 将一个大队列拆分成多个小队列,分布到不同消费者。
6. 使用延迟队列
- 对非紧急消息延迟处理,减少瞬时压力。
7. 死信队列(DLX)+ 重试机制
- 将处理失败的消息转移到 DLX,避免阻塞主队列。
- 延迟重试,防止重复失败导致堆积。
8. 监控与报警
- 监控队列长度、未确认消息数、消费者状态。
- 队列长度超过阈值时报警,自动扩容消费者。
四、实际案例:订单系统消息堆积处理
场景:
- 高峰期订单创建消息暴增,队列积压 50 万条。
- 消费者处理订单需要调用第三方支付接口,耗时 500ms。
解决方案:
- 增加消费者实例:从 5 个增加到 20 个。
- 异步处理支付接口:先 ACK 消息,再异步调用支付接口(保证幂等性)。
- 批量 ACK:一次确认 50 条消息。
- 队列分片:按订单地区拆分成多个队列。
- 监控报警:队列长度超过 10 万条时自动扩容消费者。
结果:
- 队列积压在 5 分钟内消除。
- 高峰期延迟从 30 秒降到 3 秒。
五、RabbitMQ 消息堆积处理流程图(文字版)
发现队列积压 ↓ 监控报警触发 ↓ 分析原因(消费慢 / 生产快 / ACK 问题) ↓ 针对性优化: - 增加消费者 - 优化业务逻辑 - 控制生产速度 - 调整 ACK 策略 - 队列分片 - 使用 DLX ↓ 验证效果 ↓ 持续监控
六、最佳实践总结
- 提前监控:不要等到堆积严重才处理。
- 水平扩展消费者:快速提升消费能力。
- 业务逻辑异步化:减少阻塞。
- 合理使用 ACK:防止未确认消息过多。
- 队列分片与负载均衡:避免单队列压力过大。
- 死信队列与重试机制:防止失败消息阻塞主队列。
3. Kafka
一、Kafka 基础与架构
Kafka 的核心组件有哪些?分别作用是什么?
一、Kafka 核心组件总览
Kafka 是一个分布式流式消息平台,它的核心组件主要包括:
- Producer(生产者)
- Consumer(消费者)
- Broker(代理服务器)
- Topic(主题)
- Partition(分区)
- Offset(位移)
- Consumer Group(消费者组)
- Zookeeper / KRaft(集群协调)
- Replica(副本)与 ISR(同步副本集合)
- Controller(控制器)
二、各组件详细讲解
1. Producer(生产者)
作用:
- 负责将消息发送到 Kafka 集群中的指定 Topic。
- 可以选择消息的分区策略(如轮询、按 key 哈希、指定分区)。
- 支持批量发送、压缩、异步发送等优化方式。
关键特性:
- acks 参数:控制消息发送的确认级别(0、1、all)。
- 重试机制 :
retries参数控制失败重试次数。 - 批量发送 :
batch.size控制批量大小,减少网络开销。
生产环境意义:
- 决定消息的写入速度和可靠性。
- 生产者端优化是 Kafka 高吞吐的关键之一。
2. Consumer(消费者)
作用:
- 从 Kafka 集群中拉取消息进行处理。
- 按 Topic 和 Partition 消费数据。
- 通过 Consumer Group 实现负载均衡和容错。
关键特性:
- 拉模式(Pull):消费者主动从 Broker 拉取消息。
- 自动提交 Offset :
enable.auto.commit控制是否自动提交位移。 - 手动提交 Offset:保证业务处理完成后再提交,防止消息丢失。
生产环境意义:
- 决定消息的消费速度和延迟。
- 消费端的并发和分区数直接影响系统吞吐量。
3. Broker(代理服务器)
作用:
- Kafka 集群中的一个节点,负责存储消息和处理客户端请求。
- 每个 Broker 都有唯一的 ID。
- 负责分区的读写操作。
关键特性:
- 分布式存储:消息分布在多个 Broker 上。
- 副本机制:保证数据高可用。
- 零拷贝:提升数据传输性能。
生产环境意义:
- Broker 数量决定集群的存储能力和并发处理能力。
- 高可用依赖 Broker 的副本机制。
4. Topic(主题)
作用:
- Kafka 中消息的逻辑分类。
- 生产者将消息发送到指定 Topic,消费者订阅 Topic 获取消息。
关键特性:
- 一个 Topic 可以有多个分区。
- Topic 是逻辑概念,实际存储在分区文件中。
生产环境意义:
- 用于区分不同业务的数据流。
- 合理的 Topic 设计有助于数据管理和权限控制。
5. Partition(分区)
作用:
- Topic 的物理存储单元。
- 每个分区是一个有序、不可变的消息序列。
- 分区内消息有唯一的 Offset。
关键特性:
- 分区数影响并发度和吞吐量。
- 分区内保证消息顺序,跨分区不保证。
生产环境意义:
- 分区是 Kafka 高吞吐的核心。
- 分区数设计不合理会导致热点分区或资源浪费。
6. Offset(位移)
作用:
- 消息在分区中的唯一标识(递增的长整型)。
- 消费者通过 Offset 确定消费进度。
关键特性:
- Offset 存储在 Kafka 内部主题
__consumer_offsets。 - 支持自动提交和手动提交。
生产环境意义:
- Offset 管理是保证消息不丢失、不重复消费的关键。
7. Consumer Group(消费者组)
作用:
- 一组消费者共同消费一个或多个 Topic。
- 同一分区的消息只能被组内一个消费者消费。
- 实现负载均衡和容错。
关键特性:
- 组内消费者数量 ≤ 分区数。
- 消费者加入或退出会触发 Rebalance(重新分配分区)。
生产环境意义:
- 方便水平扩展消费能力。
- 组内消费者宕机时,其他消费者可接管分区。
8. Zookeeper / KRaft(集群协调)
作用:
- 早期 Kafka 使用 Zookeeper 管理集群元数据、选举 Controller。
- 新版本(2.8+)引入 KRaft 模式,去掉 Zookeeper,直接由 Kafka 管理元数据。
关键特性:
- 负责 Broker 注册、Topic 元数据管理、分区副本分配。
- 负责 Controller 选举。
生产环境意义:
- 集群稳定运行依赖协调服务。
- KRaft 模式简化部署,减少外部依赖。
9. Replica(副本)与 ISR(同步副本集合)
作用:
- 副本:分区的冗余拷贝,分布在不同 Broker 上。
- ISR:与 Leader 保持同步的副本集合。
关键特性:
- Leader 负责读写,Follower 负责同步。
- ISR 中副本落后太多会被移出集合。
生产环境意义:
- 副本机制保证数据高可用。
- ISR 保证数据一致性。
10. Controller(控制器)
作用:
- Kafka 集群中的一个特殊 Broker,负责管理分区 Leader 选举、分区重新分配等。
- 由 Zookeeper/KRaft 选举产生。
关键特性:
- 集群中只有一个 Controller。
- Controller 宕机时会重新选举。
生产环境意义:
- Controller 是集群管理的"大脑",稳定性非常重要。
三、Kafka 核心组件关系图(文字版)
Producer → Topic → Partition → Broker Consumer ← Topic ← Partition ← Broker Consumer Group 管理多个 Consumer Offset 记录消费进度 Zookeeper/KRaft 管理集群元数据和 Controller Replica + ISR 保证数据高可用
四、最佳实践建议
-
Topic 设计:按业务划分,避免过多分区。
-
分区数:根据消费者并发和吞吐量需求合理设置。
-
副本数:生产环境建议 ≥ 3,保证高可用。
-
ACK 配置 :关键业务使用
acks=all。 -
监控:重点监控 ISR 变化、延迟、堆积情况。
Kafka 中 Topic 、Partition 、Offset 的概念与关系。Kafka 为什么要引入分区(Partition)机制?
一、Topic、Partition、Offset 的概念
1. Topic(主题)
- 定义 :Kafka 中消息的逻辑分类,类似于数据库中的表名。
- 作用:生产者将消息发送到指定 Topic,消费者订阅 Topic 获取消息。
- 特点 :
- 一个 Topic 可以有多个分区(Partition)。
- Topic 是逻辑概念,实际存储在分区文件中。
示例:
Topic: order_events 用途: 存储订单相关的事件消息
2. Partition(分区)
- 定义 :Topic 的物理存储单元 ,每个分区是一个有序、不可变的消息序列。
- 作用 :
- 提高 Kafka 的并行处理能力(不同分区可由不同 Broker 存储、不同消费者消费)。
- 分区内保证消息顺序,跨分区不保证顺序。
- 特点 :
- 每个分区在磁盘上对应一个目录,里面存放消息日志文件(log segment)。
- 分区数在 Topic 创建时指定,后续可扩展(但不能减少)。
示例:
Topic: order_events Partition: 0, 1, 2
3. Offset(位移)
- 定义 :消息在分区中的唯一编号(递增的长整型)。
- 作用 :
- 标识消息在分区中的位置。
- 消费者通过 Offset 确定消费进度。
- 特点 :
- Offset 在不同分区中独立递增。
- Offset 存储在 Kafka 内部主题
__consumer_offsets中(消费者组维度)。
示例:
Partition 0: Offset 0, 1, 2, 3... Partition 1: Offset 0, 1, 2, 3...
二、三者的关系
可以用一个例子来理解:
Topic: order_events ├── Partition 0: [Offset 0] [Offset 1] [Offset 2] ... ├── Partition 1: [Offset 0] [Offset 1] [Offset 2] ... └── Partition 2: [Offset 0] [Offset 1] [Offset 2] ...
- Topic 是消息的逻辑集合。
- Partition 是 Topic 的物理分片,分布在不同 Broker 上。
- Offset 是消息在分区中的唯一编号。
关键点:
- 分区内:消息有序。
- 跨分区:不保证顺序。
- Offset 只在分区内唯一,不同分区的 Offset 可以相同。
三、Kafka 为什么要引入分区(Partition)机制?
Kafka 引入分区机制的原因主要有 3 大核心目标:
1. 提高吞吐量(并行处理)
- 原因:单个队列(类似 RabbitMQ)在高并发下会成为瓶颈。
- 分区优势 :
- 不同分区可以分布在不同 Broker 上,形成分布式存储。
- 多个消费者可以并行消费不同分区的数据。
- 效果 :
- 吞吐量随分区数和 Broker 数量线性扩展。
2. 实现水平扩展(Scalability)
- 原因:业务数据量不断增长,需要动态扩容。
- 分区优势 :
- 增加分区数即可提升并发能力。
- 新分区可以分配到新加入的 Broker 上。
- 效果 :
- Kafka 集群可从几台扩展到上百台,处理 PB 级数据。
3. 保证分区内顺序性
- 原因:有些业务需要保证消息顺序(如订单状态变化)。
- 分区优势 :
- Kafka 保证单个分区内消息严格有序。
- 通过指定消息 key,可以将同一业务数据路由到同一分区,从而保证顺序。
四、面试答题思路(高分版)
如果面试官问:
Kafka 中 Topic、Partition、Offset 的关系?为什么要引入分区?
你可以这样答:
在 Kafka 中,Topic 是消息的逻辑分类,Partition 是 Topic 的物理分片,每个分区是一个有序、不可变的消息序列,Offset 是消息在分区中的唯一编号,用于标识位置和消费进度。
Kafka 引入分区机制主要是为了:
- 提升吞吐量:分区可分布在不同 Broker 上,实现并行读写。
- 支持水平扩展:通过增加分区数扩展集群处理能力。
- 保证分区内顺序性 :同一 key 的消息路由到同一分区,保证顺序。
这样 Kafka 既能处理海量数据,又能在需要时保证顺序性。
Kafka 的消息是如何存储的?文件结构是怎样的?
一、Kafka 消息存储的整体思路
Kafka 的存储设计目标是:
- 高吞吐(顺序写 + 零拷贝)
- 可持久化(磁盘存储)
- 可扩展(分区分布式存储)
- 高可用(副本机制)
核心思想:
- 按 Topic → Partition 存储(分区是最小存储单元)。
- 每个分区对应一个目录(物理文件夹)。
- 分区数据按时间/大小切分成多个日志段(Log Segment)文件。
- 每个日志段包含数据文件(.log)和索引文件(.index / .timeindex)。
- 顺序写磁盘 + 页缓存(Page Cache) 提升性能。
二、Kafka 消息存储的层级结构
假设有一个 Topic:order_events,有 3 个分区(0、1、2),副本数为 2。
Kafka 在磁盘上的存储结构大致如下:
/kafka-logs ├── order_events-0 # 分区 0 │ ├── 00000000000000000000.log │ ├── 00000000000000000000.index │ ├── 00000000000000000000.timeindex │ ├── 00000000000000001000.log │ ├── 00000000000000001000.index │ ├── 00000000000000001000.timeindex │ └── leader-epoch-checkpoint │ ├── order_events-1 # 分区 1 │ ├── ... │ └── order_events-2 # 分区 2 ├── ...
三、Kafka 文件结构详解
1. 日志段(Log Segment)
- 定义:分区数据被切分成多个日志段文件,每个日志段包含一批连续的消息。
- 命名规则 :文件名是该段中第一条消息的 Offset(20 位数字,左补 0)。
- 切分条件 :
- 达到配置的最大大小(
log.segment.bytes,默认 1GB)。 - 达到配置的最大时间(
log.roll.ms)。
- 达到配置的最大大小(
2. 数据文件(.log)
-
作用:存储实际的消息数据。
-
格式 :
+----------------+----------------+----------------+ | offset (8B) | message size | message bytes | +----------------+----------------+----------------+ -
特点 :
- 顺序写入,性能极高。
- 消息体包含 key、value、时间戳、CRC 校验等。
3. 索引文件(.index)
-
作用:根据 Offset 快速定位消息在 .log 文件中的物理位置。
-
结构:
+----------------+----------------+ | relative offset| position | +----------------+----------------+- relative offset:相对于该日志段起始 Offset 的偏移量。
- position:消息在 .log 文件中的字节位置。
-
特点:
- 稀疏索引(不是每条消息都有索引)。
- 减少内存占用,提高查找速度。
4. 时间索引文件(.timeindex)
-
作用:根据时间戳快速查找消息。
-
结构 :
+----------------+----------------+ | timestamp | relative offset| +----------------+----------------+ -
用途 :
- 实现基于时间的日志清理(Log Retention)。
- 支持时间范围查询。
5. leader-epoch-checkpoint 文件
- 作用:记录 Leader Epoch 与起始 Offset 的映射关系。
- 用途 :
- 在 Leader 变更时,帮助 Follower 确定同步位置。
- 防止数据丢失或重复。
四、Kafka 消息存储的工作流程
- 生产者发送消息到 Broker。
- Broker 将消息顺序写入 分区当前活跃的日志段
.log文件。 - 同时更新
.index和.timeindex文件。 - 当日志段达到大小或时间阈值时,滚动生成新日志段。
- 消费者根据 Offset 从
.index定位到.log文件的物理位置,读取消息。 - Kafka 利用 Page Cache + 零拷贝(sendfile) 将数据直接从磁盘发送到网络,减少 CPU 拷贝开销。
五、Kafka 高性能存储的关键原因
-
顺序写磁盘
- Kafka 不做随机写,所有消息追加到日志末尾。
- 顺序写比随机写快几个数量级。
-
页缓存(Page Cache)
- Kafka 依赖操作系统的页缓存,减少磁盘 IO。
-
零拷贝(Zero Copy)
- 使用
sendfile系统调用,直接将数据从内核缓冲区发送到网络。
- 使用
-
分区并行
- 多个分区可分布在不同磁盘/节点上并行读写。
六、日志清理策略
Kafka 提供两种日志清理策略(log.cleanup.policy):
| 策略 | 说明 | 场景 |
|---|---|---|
| delete(默认) | 按时间(log.retention.hours)或大小(log.retention.bytes)删除旧日志段 |
普通消息队列 |
| compact | 仅保留每个 key 的最新消息,删除旧版本 | 需要保留最新状态的场景(如数据库变更日志) |
七、面试高分回答模板
如果面试官问:
Kafka 的消息是如何存储的?文件结构是怎样的?
你可以这样答:
Kafka 的消息以 Topic → Partition → Log Segment 的层级存储,每个分区对应一个目录,目录下包含多个日志段文件,每个日志段由
.log(消息数据)、.index(位移索引)、.timeindex(时间索引)组成。Kafka 采用顺序写磁盘 + 页缓存 + 零拷贝 提升性能,并通过分区机制 实现分布式存储和并行处理。日志段按时间或大小滚动,旧数据可按
delete或compact策略清理。这种设计既保证了高吞吐,又支持海量数据的持久化和快速检索。
Kafka 中的 ISR(In-Sync Replica) 是什么?作用是什么?
一、ISR 的定义
ISR(In-Sync Replica) 全称 同步副本集合,是 Kafka 中用于保证数据一致性和高可用的重要机制。
在 Kafka 中:
- 每个 分区(Partition) 都有一个 Leader 副本 和若干 Follower 副本。
- ISR 是指与 Leader 保持同步的副本集合,包括 Leader 自身和所有同步进度未落后的 Follower。
简单理解:
ISR 就是"当前跟上 Leader 最新数据进度的副本列表"。
二、ISR 的作用
1. 保证数据可靠性
- Kafka 的高可用依赖副本机制。
- 只有 ISR 中的副本才被认为是安全副本,可以在 Leader 宕机时参与选举。
2. 保证数据一致性
- ISR 中的副本与 Leader 的数据差距在可接受范围内(由
replica.lag.time.max.ms控制)。 - 确保新 Leader 选举后不会丢失已确认的消息。
3. 控制消息确认(ACK)
- 当生产者设置
acks=all时,消息必须被 ISR 中所有副本确认后才算成功。 - 这样可以保证消息在多个副本中持久化,防止单点故障导致数据丢失。
三、ISR 的工作机制
1. 副本同步流程
- Leader 副本 负责处理生产者的写请求。
- Follower 副本 从 Leader 拉取数据(Fetch 请求)。
- 当 Follower 追上 Leader 的最新 Offset(或在允许的延迟范围内),它就属于 ISR 集合。
2. ISR 的动态变化
- 加入 ISR :Follower 追上 Leader 的进度(延迟 ≤
replica.lag.time.max.ms)。 - 移出 ISR :Follower 落后 Leader 太多(延迟 >
replica.lag.time.max.ms),或 Follower 宕机。 - Leader 宕机:从 ISR 中选举新的 Leader。
3. 关键参数
| 参数 | 作用 |
|---|---|
replica.lag.time.max.ms |
Follower 落后 Leader 的最大允许时间,超过则移出 ISR |
min.insync.replicas |
最小同步副本数,生产者 acks=all 时必须满足,否则写入失败 |
unclean.leader.election.enable |
是否允许非 ISR 副本成为 Leader(一般生产环境禁用) |
四、ISR 的选举机制
当 Leader 宕机时:
- Kafka Controller 从 ISR 集合中选择一个副本作为新 Leader。
- 因为 ISR 中的副本数据与旧 Leader 几乎一致,所以可以保证数据不丢失。
- 如果 ISR 为空(所有副本都落后),是否允许非 ISR 副本当 Leader 取决于
unclean.leader.election.enable。
五、生产环境中的意义
1. 高可用性
- ISR 确保在 Leader 宕机时,能快速选出一个数据一致的新 Leader。
- 避免数据丢失或回滚。
2. 数据安全
- 配合
acks=all和min.insync.replicas,保证消息在多个副本持久化后才确认。
3. 性能与可靠性的平衡
- ISR 太小:可靠性下降。
- ISR 太大:Follower 同步压力大,可能影响性能。
- 需要根据业务场景调整副本数和同步延迟阈值。
六、示例场景
假设:
- 分区副本数:3(Leader + 2 Follower)
- 当前 ISR:
[Leader, Follower1, Follower2]
正常写入流程(acks=all):
- Producer 发送消息到 Leader。
- Leader 写入本地日志,并等待 Follower1、Follower2 同步。
- 所有 ISR 副本确认后,返回 ACK 给 Producer。
Follower2 落后太多:
- ISR 变为
[Leader, Follower1]。 - 写入时只需等待这两个副本确认。
Leader 宕机:
- 从 ISR 中选举 Follower1 为新 Leader。
- 因为 Follower1 与旧 Leader 数据一致,所以不会丢数据。
七、面试高分回答模板
如果面试官问:
Kafka 中的 ISR 是什么?作用是什么?
你可以这样答:
ISR(In-Sync Replica)是 Kafka 中与 Leader 副本保持同步的副本集合,包括 Leader 自身和所有延迟在允许范围内的 Follower。
它的作用是:
- 保证数据可靠性:只有 ISR 中的副本才可在 Leader 宕机时参与选举,确保数据一致。
- 控制消息确认 :生产者
acks=all时,必须等 ISR 中所有副本确认后才返回 ACK。- 动态调整 :Follower 落后太多会被移出 ISR,追上后可重新加入。
这种机制让 Kafka 在保证高可用的同时,兼顾了性能与数据安全。
Kafka 的 Leader 和 Follower 是如何工作的?
一、Leader 和 Follower 的基本概念
1. Leader
- 每个分区(Partition)都有一个 Leader 副本。
- Leader 负责处理所有客户端的读写请求(Producer 写入、Consumer 读取)。
- 保证分区内消息的顺序性。
2. Follower
- 除 Leader 外的其他副本都是 Follower。
- Follower 不直接处理客户端请求 ,它们的任务是从 Leader 拉取数据并同步。
- 通过保持与 Leader 的数据一致性,确保在 Leader 宕机时可以接管。
二、Leader 和 Follower 的工作流
我们分成几个关键阶段来讲:
阶段 1:消息写入(Producer → Leader)
- Producer 发送消息到分区的 Leader 副本所在的 Broker。
- Leader 将消息顺序写入本地日志文件(.log)。
- Leader 将新写入的消息的 Offset 和数据推送到 ISR(In-Sync Replica)中的 Follower。
- 当生产者设置
acks=all时,Leader 必须等待 ISR 中所有副本确认写入成功后,才返回 ACK 给 Producer。
关键点:
- Leader 是唯一的写入口。
- 写入是顺序追加,性能高。
- 数据安全依赖 ISR 确认机制。
阶段 2:数据同步(Leader → Follower)
- Follower 发送 Fetch 请求给 Leader,拉取最新的消息。
- Leader 返回从 Follower 当前 Offset 开始的消息数据。
- Follower 将数据写入自己的日志文件,并更新自己的高水位(HW, High Watermark)。
- 当 Follower 的 HW 与 Leader 相同,说明它已追上 Leader,可以继续留在 ISR 集合中。
关键点:
- Follower 是主动拉取数据(Pull 模式)。
- 同步延迟超过
replica.lag.time.max.ms会被移出 ISR。 - 高水位(HW)是消费者可见的最大 Offset。
阶段 3:消费者读取(Consumer → Leader)
- Consumer 发送 Fetch 请求到分区的 Leader。
- Leader 返回从 Consumer 当前 Offset 开始的消息。
- Consumer 处理消息并提交 Offset(自动或手动)。
关键点:
- 默认情况下,消费者只从 Leader 读取数据。
- Kafka 2.4+ 支持 Follower 读取(Replica Fetching),用于跨机房部署。
阶段 4:Leader 选举(故障恢复)
当 Leader 宕机时:
- Kafka Controller 检测到 Leader 不可用。
- 从 ISR 集合中选举一个 Follower 作为新 Leader。
- 新 Leader 接管客户端读写请求。
- 其他副本(包括旧 Leader恢复后)作为 Follower 向新 Leader 同步数据。
关键点:
- 只有 ISR 中的副本才有资格成为 Leader(保证数据一致性)。
- 如果 ISR 为空,是否允许非 ISR 副本当 Leader取决于
unclean.leader.election.enable(生产环境建议禁用)。
三、Leader-Follower 工作细节图(文字版)
Producer → Leader(写入日志) → 推送到 ISR 中的 Follower Follower(Fetch 拉取) → 写入日志 → 更新 HW Consumer → Leader(Fetch 拉取) → 返回消息 Leader 宕机 → Controller 从 ISR 中选举新 Leader
四、关键参数与机制
| 参数 | 作用 |
|---|---|
replica.lag.time.max.ms |
Follower 落后 Leader 的最大允许时间 |
min.insync.replicas |
最小同步副本数,配合 acks=all 保证数据安全 |
unclean.leader.election.enable |
是否允许非 ISR 副本当 Leader |
leader.imbalance.check.interval.seconds |
检查 Leader 分布不均的时间间隔 |
leader.imbalance.per.broker.percentage |
每个 Broker 上 Leader 不均衡的阈值 |
五、生产环境中的意义
-
高可用性
- Leader-Follower 架构保证在节点故障时快速恢复。
- ISR 机制确保新 Leader 数据一致。
-
高性能
- Leader 顺序写磁盘,Follower 并行同步。
- 分区分布在不同 Broker 上,提升吞吐量。
-
数据安全
- 配合
acks=all和min.insync.replicas,保证消息在多个副本持久化后才确认。
- 配合
六、面试高分回答模板
如果面试官问:
Kafka 中 Leader 和 Follower 是如何工作的?
你可以这样答:
在 Kafka 中,每个分区都有一个 Leader 副本和若干 Follower 副本。Leader 负责处理所有客户端的读写请求,Follower 通过 Fetch 请求从 Leader 拉取数据并写入本地日志,保持与 Leader 的数据一致。
当生产者写入数据时,Leader 会顺序写入日志并推送给 ISR 中的 Follower,等待它们确认后返回 ACK(当
acks=all时)。消费者默认从 Leader 读取数据。如果 Leader 宕机,Kafka Controller 会从 ISR 集合中选举一个 Follower 作为新 Leader,确保数据一致性和高可用性。这种架构既保证了性能,又保证了数据安全。
Kafka 如何保证消息的顺序性?
一、Kafka 消息顺序性的定义
在 Kafka 中,顺序性指的是:
同一分区(Partition)内的消息,按照写入的顺序被消费。
关键点:
- Kafka 只保证分区内的消息顺序。
- 跨分区不保证顺序,因为不同分区的消息可能并行处理、到达时间不同。
二、Kafka 保证顺序性的原理
1. 分区内顺序写
- Kafka 的分区是一个有序、不可变的消息日志。
- 每条消息在分区内都有一个唯一的 Offset,按写入顺序递增。
- 生产者写入时是顺序追加到日志末尾。
2. 单线程消费
- 消费者从分区读取消息时,按照 Offset 顺序依次读取。
- 如果一个分区只被一个消费者线程处理,顺序就能保证。
3. Key 路由机制
- 生产者可以为消息指定 Key。
- Kafka 会根据 Key 进行分区(默认使用哈希算法),同一 Key 的消息会进入同一个分区,从而保证它们的顺序。
三、顺序性保证的条件
要保证消息顺序,必须满足以下条件:
| 条件 | 说明 |
|---|---|
| 单分区 | 顺序性只在分区内保证,跨分区无法保证 |
| 单生产者线程 | 同一分区的写入必须由单线程或保证顺序的生产者完成 |
| 单消费者线程 | 同一分区的消费必须由单线程处理 |
| 禁用乱序重试 | 生产者开启 max.in.flight.requests.per.connection=1,避免多批次乱序 |
四、生产端的顺序性配置
1. 指定消息 Key
java
ProducerRecord<String, String> record =
new ProducerRecord<>("topic", "orderId-123", "order created");
producer.send(record);- 同一
orderId的消息会进入同一个分区。
2. 限制并发请求
XML
max.in.flight.requests.per.connection=1- 保证在发生重试时,批次不会乱序。
3. 禁用压缩批次乱序
- 如果使用批量发送(batch),要确保批次内消息的顺序。
五、消费端的顺序性配置
1. 保证分区独占
- 一个分区只能被一个消费者线程消费。
- Kafka Consumer Group 会自动分配分区,确保同一分区不会被多个消费者同时处理。
2. 顺序处理消息
- 消费者代码中不要异步乱序处理消息。
- 如果需要并发处理,要在业务层面按 Key 分组。
六、顺序性被打乱的场景
- 跨分区消息
- 不同分区的消息可能乱序到达。
- 生产者多线程写入同一分区
- 如果没有控制并发,可能乱序。
- 生产者重试
- 如果
max.in.flight.requests.per.connection > 1,重试可能导致乱序。
- 如果
- 消费者异步处理
- 异步线程可能打乱处理顺序。
七、生产环境的顺序性策略
-
强顺序场景(如订单状态流转):
- 使用消息 Key 保证同一业务实体进入同一分区。
- 设置
max.in.flight.requests.per.connection=1。 - 消费端单线程处理分区数据。
-
弱顺序场景(如日志收集):
- 不强制 Key 路由,允许跨分区乱序,提高吞吐量。
八、面试高分回答模板
如果面试官问:
Kafka 如何保证消息的顺序性?
你可以这样答:
Kafka 通过分区内顺序写 和单线程消费 来保证消息顺序。每个分区是一个有序日志,消息按 Offset 递增存储,消费者按 Offset 顺序读取。
要保证顺序,需要:
- 同一业务 Key 的消息进入同一分区(生产者指定 Key)。
- 单线程写入和单线程消费分区数据。
- 设置
max.in.flight.requests.per.connection=1避免重试乱序。
Kafka 只保证分区内顺序,跨分区无法保证顺序。
示例场景:订单状态流转
假设我们有一个 Topic :order_events
- 分区数:3
- 每条消息包含
orderId和status(订单状态)。 - 我们希望同一个订单的状态变化消息按顺序被消费。
1. 正确保证顺序的写法
生产者代码(Java 示例):
java
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 保证重试时不乱序
props.put("max.in.flight.requests.per.connection", "1");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
// 同一个 orderId 的消息使用相同的 key
producer.send(new ProducerRecord<>("order_events", "orderId-1001", "CREATED"));
producer.send(new ProducerRecord<>("order_events", "orderId-1001", "PAID"));
producer.send(new ProducerRecord<>("order_events", "orderId-1001", "SHIPPED"));
producer.send(new ProducerRecord<>("order_events", "orderId-1001", "DELIVERED"));
producer.close();关键点:
- Key = orderId,Kafka 会将同一个 Key 的消息路由到同一个分区。
- 分区内是顺序写入的,所以
CREATED → PAID → SHIPPED → DELIVERED的顺序不会乱。
消费者代码(Java 示例):
java
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "order-consumer-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("order_events"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("Order %s status: %s%n", record.key(), record.value());
}
}输出结果(保证顺序):
Order orderId-1001 status: CREATED Order orderId-1001 status: PAID Order orderId-1001 status: SHIPPED Order orderId-1001 status: DELIVERED
2. 顺序被打乱的情况
如果生产者没有指定 Key:
java
producer.send(new ProducerRecord<>("order_events", null, "CREATED"));
producer.send(new ProducerRecord<>("order_events", null, "PAID"));
producer.send(new ProducerRecord<>("order_events", null, "SHIPPED"));
producer.send(new ProducerRecord<>("order_events", null, "DELIVERED"));结果:
- Kafka 会随机将消息分配到不同分区。
- 同一个订单的消息可能分布在多个分区,消费者并行读取时顺序会被打乱。
可能输出:
Order orderId-1001 status: PAID Order orderId-1001 status: CREATED Order orderId-1001 status: DELIVERED Order orderId-1001 status: SHIPPED
(顺序错乱)
3. 总结
- 保证顺序:同一业务实体(如订单)必须进入同一个分区 → 生产者指定 Key。
- 消费端:一个分区只能由一个消费者线程处理。
- 重试乱序 :设置
max.in.flight.requests.per.connection=1。
Kafka 中的 Consumer Group 是什么?有什么作用?
一、Consumer Group 的定义
Consumer Group(消费者组) 是 Kafka 中消费者的逻辑分组,它的核心作用是:
多个消费者协同消费一个或多个 Topic 的数据,并且保证每条消息只会被组内的一个消费者处理一次。
关键点:
- 每个消费者组有一个唯一的 Group ID。
- 同一个组内的消费者共享消费进度(Offset)。
- Kafka 会为组内消费者分配分区,确保同一分区只被组内一个消费者消费。
二、Consumer Group 的作用
1. 实现水平扩展(并行消费)
- 一个 Topic 可以有多个分区。
- Consumer Group 可以有多个消费者实例,每个消费者负责消费部分分区的数据。
- 这样可以并行处理消息,提高吞吐量。
2. 保证消息不重复消费
- Kafka 保证同一分区在同一时间只会分配给组内一个消费者。
- 避免了多消费者重复处理同一条消息。
3. 消费进度管理
- Kafka 会为每个 Consumer Group 维护一个 Offset(消费位移)。
- Offset 存储在 Kafka 内部的
__consumer_offsetsTopic 中。 - 当消费者重启时,可以从上次的 Offset 继续消费。
4. 支持多组独立消费
- 不同的 Consumer Group 可以独立消费同一个 Topic。
- 每个组都有自己的 Offset,不会互相影响。
- 适用于不同业务系统需要消费同一数据源的场景。
三、Consumer Group 的工作机制
1. 分区分配
- 当消费者组启动或成员变化时,Kafka 会进行 Rebalance(再均衡)。
- 分区分配策略:
- Range:按分区范围分配。
- RoundRobin:轮询分配。
- Sticky:尽量保持原有分配,减少数据迁移。
2. 消费流程
- 消费者向 Kafka Broker 发送 JoinGroup 请求。
- Kafka Coordinator(协调者)为组内消费者分配分区。
- 消费者从分配到的分区拉取消息(Fetch 请求)。
- 消费者处理消息并提交 Offset(自动或手动)。
3. Offset 提交
- 自动提交 :
enable.auto.commit=true,定期提交 Offset。 - 手动提交 :
commitSync()或commitAsync(),更灵活,适合精确控制。
四、示例场景
假设:
- Topic:
order_events - 分区数:6
- Consumer Group:
order-consumer-group - 消费者实例数:3
分区分配示意:
Consumer1 → 分区 0, 1 Consumer2 → 分区 2, 3 Consumer3 → 分区 4, 5
- 每个消费者只消费自己分配的分区。
- 同一分区不会被多个消费者同时消费。
五、生产环境中的意义
1. 高吞吐
- 通过增加消费者实例数,实现并行消费,提升处理速度。
2. 高可用
- 如果某个消费者实例宕机,Kafka 会触发 Rebalance,将它的分区分配给其他消费者。
3. 灵活扩展
- 可以根据业务压力动态增加或减少消费者实例。
4. 多业务共享数据
- 不同 Consumer Group 可以独立消费同一个 Topic,互不影响。
六、面试高分回答模板
如果面试官问:
Kafka 中的 Consumer Group 是什么?有什么作用?
你可以这样答:
Consumer Group 是 Kafka 中消费者的逻辑分组,组内消费者协同消费一个或多个 Topic 的数据,并保证每条消息只会被组内一个消费者处理一次。
它的作用包括:
- 水平扩展:多个消费者并行消费不同分区,提高吞吐量。
- 保证不重复消费:同一分区只会分配给组内一个消费者。
- 消费进度管理:Kafka 为每个组维护 Offset,支持断点续消费。
- 多组独立消费 :不同组可以独立消费同一 Topic,互不影响。
在生产环境中,Consumer Group 是实现高吞吐、高可用和灵活扩展的核心机制。
示例场景
假设我们有一个 Topic:order_events
- 分区数:6
- Consumer Group:
order-consumer-group - 消费者实例数:3
目标:让消费者组内的 3 个消费者并行消费订单事件,并且保证每条消息只被组内一个消费者处理一次。
1. 生产者代码(Java 示例)
java
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
// 模拟发送 10 条订单事件
for (int i = 1; i <= 10; i++) {
String orderId = "order-" + i;
String status = "CREATED";
producer.send(new ProducerRecord<>("order_events", orderId, status));
}
producer.close();说明:
- 使用
orderId作为 Key,保证同一订单进入同一分区(方便保持顺序)。 - 发送到
order_eventsTopic。
2. 消费者代码(Java 示例)
java
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "order-consumer-group"); // 同一个组 ID
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("order_events"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("Consumer %s - Order %s status: %s%n",
Thread.currentThread().getName(),
record.key(),
record.value());
}
}说明:
- 所有消费者实例使用相同的
group.id,组成一个 Consumer Group。 - Kafka 会自动为组内消费者分配分区。
3. 分区分配示意
假设 order_events 有 6 个分区,消费者组有 3 个消费者:
| 消费者实例 | 分配的分区 |
|---|---|
| Consumer1 | 分区 0, 1 |
| Consumer2 | 分区 2, 3 |
| Consumer3 | 分区 4, 5 |
特点:
- 每个分区只会被组内一个消费者消费。
- 如果 Consumer2 宕机,Kafka 会触发 Rebalance,将分区 2, 3 分配给其他消费者。
4. 输出示例
Consumer1 - Order order-1 status: CREATED Consumer1 - Order order-2 status: CREATED Consumer2 - Order order-3 status: CREATED Consumer2 - Order order-4 status: CREATED Consumer3 - Order order-5 status: CREATED Consumer3 - Order order-6 status: CREATED ...
可以看到:
- 每条消息只被组内一个消费者处理。
- 分区内的消息顺序被保持。
面试高分答案模板
如果面试官问:
Kafka 中的 Consumer Group 是什么?有什么作用?
你可以这样答:
Consumer Group 是 Kafka 中消费者的逻辑分组,组内消费者协同消费一个或多个 Topic 的数据,并保证每条消息只会被组内一个消费者处理一次。
它的作用包括:
- 水平扩展:多个消费者并行消费不同分区,提高吞吐量。
- 保证不重复消费:同一分区只会分配给组内一个消费者。
- 消费进度管理:Kafka 为每个组维护 Offset,支持断点续消费。
- 多组独立消费 :不同组可以独立消费同一 Topic,互不影响。
例如,order_eventsTopic 有 6 个分区,消费者组有 3 个消费者时,每个消费者会分配到 2 个分区,实现并行处理订单事件,并且保证每条订单事件只被处理一次。
Kafka 的消息是如何被消费的?拉模式(Pull)和推模式(Push)的区别。
一、Kafka 消息消费的整体流程
Kafka 的消费过程可以分为 消费者组管理 、分区分配 、消息拉取 、消息处理 、Offset 提交 这几个阶段。
1. 消费者组管理
- 消费者必须属于一个 Consumer Group (通过
group.id标识)。 - Kafka 的 Group Coordinator 负责管理组成员和分区分配。
- 当消费者加入或离开组时,会触发 Rebalance(再均衡)。
2. 分区分配
- Kafka 会将 Topic 的分区分配给组内的消费者。
- 同一分区在同一时间只会分配给组内一个消费者。
- 分配策略包括:
- Range(按分区范围分配)
- RoundRobin(轮询分配)
- Sticky(尽量保持原有分配)
3. 消息拉取(Pull 模式)
- 消费者主动向 Broker 发送 Fetch 请求,拉取分配到的分区数据。
- 消费者可以指定:
- 起始 Offset(从哪里开始消费)
- 最大拉取条数 / 数据量
- 等待时间(长轮询)
4. 消息处理
- 消费者应用程序对拉取到的消息进行业务处理。
- 处理方式可以是同步、异步、批量等。
5. Offset 提交
- Kafka 通过 Offset 记录消费者的消费进度。
- 提交方式:
- 自动提交 (
enable.auto.commit=true) - 手动提交 (
commitSync()/commitAsync())
- 自动提交 (
- Offset 存储在 Kafka 内部的
__consumer_offsetsTopic 中。
二、Kafka 的拉模式(Pull)与推模式(Push)的区别
| 对比项 | 拉模式(Pull) | 推模式(Push) |
|---|---|---|
| 数据获取方式 | 消费者主动向 Broker 请求数据 | Broker 主动将数据推送给消费者 |
| 消费速率控制 | 消费者可根据自身处理能力控制拉取频率和批量大小 | Broker 按自身速率推送,消费者可能被压垮 |
| 延迟 | 可能存在轮询延迟(可用长轮询优化) | 理论上延迟更低 |
| 复杂度 | 消费者实现更复杂,需要维护 Offset | Broker 实现更复杂,需要管理消费者状态 |
| 适用场景 | 消费者处理能力差异大、需要灵活控制速率 | 消费者处理能力均衡、实时性要求极高 |
| Kafka 选择原因 | 灵活性高、可控性强、易于批量处理 | 推模式在大规模分布式场景下容易造成背压问题 |
三、为什么 Kafka 选择拉模式(Pull)
-
消费者速率差异大
- 不同消费者的处理能力不同,拉模式允许消费者按需拉取,避免被推模式压垮。
-
批量处理优化
- 消费者可以一次拉取多条消息,减少网络开销,提高吞吐量。
-
Offset 灵活控制
- 消费者可以自由选择从哪个 Offset 开始消费(支持回溯消费)。
-
长轮询减少延迟
- Kafka 的拉模式支持长轮询(
fetch.max.wait.ms),在没有数据时等待一段时间再返回,减少空轮询。
- Kafka 的拉模式支持长轮询(
-
简化 Broker 设计
- Broker 不需要维护每个消费者的推送状态,降低复杂度。
四、Kafka 消费流程示意(文字版)
[Consumer] --(JoinGroup)--> [Group Coordinator] [Group Coordinator] --(Assign Partitions)--> [Consumer] [Consumer] --(Fetch Request)--> [Broker Leader Partition] [Broker] --(Messages + Offset)--> [Consumer] [Consumer] --(Process Messages)--> [Business Logic] [Consumer] --(Commit Offset)--> [__consumer_offsets Topic]
五、面试高分回答模板
如果面试官问:
Kafka 的消息是如何被消费的?拉模式和推模式有什么区别?
你可以这样答:
Kafka 的消费过程包括:消费者加入 Consumer Group → 分区分配 → 消费者向 Broker 主动发送 Fetch 请求拉取数据 → 处理消息 → 提交 Offset。
Kafka 采用 拉模式(Pull),即消费者主动向 Broker 请求数据,这样可以:
- 按需拉取,避免推模式下消费者被压垮。
- 支持批量拉取,提高吞吐量。
- 灵活控制 Offset,支持回溯消费。
推模式虽然延迟低,但在大规模分布式场景下容易造成背压问题,Kafka 选择拉模式是为了在高吞吐和灵活性之间取得平衡。
Kafka 中的 Offset 是如何管理的?存储在哪里?
一、Offset 的定义
Offset 是 Kafka 中分区内消息的唯一编号,用来标识消息在分区中的位置。
- 每个分区的 Offset 从 0 开始递增。
- Offset 是分区级别的,不同分区的 Offset 互不影响。
- 消费者通过 Offset 知道从哪里开始消费。
二、Offset 的作用
-
记录消费进度
- 消费者读取消息后,会提交当前消费到的位置(Offset)。
- 下次消费时,可以从上次提交的 Offset 继续读取,支持断点续消费。
-
支持回溯消费
- 消费者可以手动指定 Offset,从历史位置重新消费。
-
保证消息不丢失/不重复
- 正确管理 Offset 可以避免重复消费或漏消费。
三、Offset 的存储位置
Kafka Offset 的存储方式经历了两个阶段:
1. 旧版本(0.9 之前)
- Offset 存储在 Zookeeper 中。
- 缺点:
- Zookeeper 压力大(频繁写入)。
- 不支持高效批量提交。
2. 新版本(0.9 及之后)
- Offset 存储在 Kafka 内部的
__consumer_offsetsTopic 中。 - 特点:
- 分布式存储,高可用。
- 支持批量提交,性能更好。
- 由 Kafka 自己管理,不依赖外部系统。
四、Offset 的提交方式
Kafka 提供两种提交方式:
| 提交方式 | 配置/方法 | 特点 | 优点 | 缺点 |
|---|---|---|---|---|
| 自动提交 | enable.auto.commit=true |
定期自动提交(默认 5 秒) | 简单易用 | 可能在消息未处理完就提交,导致丢数据 |
| 手动提交 | commitSync() / commitAsync() |
业务处理完成后手动提交 | 精确控制提交时机 | 代码复杂度高 |
1. 自动提交示例
java
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "5000"); // 每 5 秒提交一次- Kafka 会在后台定时提交当前消费到的 Offset。
2. 手动提交示例
java
props.put("enable.auto.commit", "false");
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
process(record); // 业务处理
}
consumer.commitSync(); // 处理完成后提交
}- 适合对消息处理可靠性要求高的场景。
五、Offset 的管理机制
-
Offset 提交到
__consumer_offsets- 这是一个内部 Topic,默认有 50 个分区(可配置)。
- 每个分区存储多个 Consumer Group 的 Offset 信息。
-
Offset 的 Key 结构
- Key =
(group.id, topic, partition) - Value = 最新提交的 Offset
- Key =
-
Offset 的读取
- 当消费者启动时,会从
__consumer_offsets中读取上次提交的 Offset。 - 如果没有记录,则根据
auto.offset.reset策略决定:earliest:从最早的消息开始消费latest:从最新的消息开始消费none:如果没有 Offset 记录则抛出异常
- 当消费者启动时,会从
六、生产环境最佳实践
-
高可靠场景
- 关闭自动提交,业务处理完成后手动提交 Offset。
- 使用
commitSync()保证提交成功。
-
高吞吐场景
- 使用
commitAsync()异步提交,减少阻塞。 - 结合批量处理,降低提交频率。
- 使用
-
防止重复消费
- 提交 Offset 要在消息处理完成后进行。
- 如果在处理前提交,消费者宕机会导致消息丢失。
-
回溯消费
- 可以通过
seek()方法手动指定 Offset,实现数据重放。
- 可以通过
七、面试高分回答模板
如果面试官问:
Kafka 中的 Offset 是如何管理的?存储在哪里?
你可以这样答:
Offset 是 Kafka 中分区内消息的唯一编号,用于标识消费进度。
在 Kafka 0.9 之前,Offset 存储在 Zookeeper 中;0.9 之后,存储在 Kafka 内部的
__consumer_offsetsTopic 中,由 Kafka 自行管理。Offset 的提交方式有两种:
- 自动提交:定期提交当前消费到的位置,简单但可能丢数据。
- 手动提交 :业务处理完成后提交,可靠性高。
消费者启动时会从__consumer_offsets读取上次提交的 Offset,如果没有记录,则根据auto.offset.reset策略决定从哪里开始消费。
在生产环境中,通常关闭自动提交,业务处理完成后手动提交 Offset,以保证数据不丢失。
二、消息可靠性与一致性
Kafka 如何保证消息不丢失?
一、Kafka 消息不丢失的核心思想
Kafka 要保证消息不丢失,需要在生产端 → Broker 存储 → 消费端 三个环节都做好可靠性保障。
只要任意一个环节丢了数据,整体就无法保证。
二、三个环节的防丢失机制
1. 生产者(Producer)防丢失
- 确认机制(acks)
acks=0:不等待 Broker 确认(最快,但可能丢数据)acks=1:等待 Leader 写入成功(Leader 宕机可能丢数据)acks=all:等待 Leader 和 ISR(同步副本)全部写入成功(最安全)
- 重试机制
retries:发送失败时自动重试max.in.flight.requests.per.connection=1:避免重试时乱序
- 幂等性
enable.idempotence=true:避免重复发送导致数据重复
生产者防丢失配置示例:
java
props.put("acks", "all");
props.put("retries", Integer.MAX_VALUE);
props.put("max.in.flight.requests.per.connection", "1");
props.put("enable.idempotence", "true");2. Broker(Kafka 服务端)防丢失
- 副本机制
replication.factor >= 3:保证有多个副本min.insync.replicas >= 2:至少有 2 个副本同步成功才算写入成功
- 日志持久化
- Kafka 写入数据后会先写 OS Page Cache,再刷盘
log.flush.interval.messages/log.flush.interval.ms可控制刷盘频率(一般依赖 OS 缓存即可)
- Leader 选举策略
unclean.leader.election.enable=false:防止选举未同步的副本为 Leader,避免数据回滚
Broker 防丢失配置示例(server.properties):
java
replication.factor=3
min.insync.replicas=2
unclean.leader.election.enable=false3. 消费者(Consumer)防丢失
- 关闭自动提交 Offset
- 避免消息还没处理完就提交 Offset,导致宕机后丢数据
- 手动提交 Offset
- 业务处理完成后再提交
- 精确控制提交时机
commitSync():同步提交,确保提交成功commitAsync():异步提交,性能高但可能丢数据(可结合回调重试)
消费者防丢失示例:
java
props.put("enable.auto.commit", "false");
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
process(record); // 业务处理
}
consumer.commitSync(); // 处理完成后提交 Offset
}三、综合防丢失方案(生产级)
| 环节 | 配置/策略 | 作用 |
|---|---|---|
| 生产者 | acks=all + enable.idempotence=true + retries=Integer.MAX_VALUE + max.in.flight.requests.per.connection=1 |
确保消息可靠写入且不重复 |
| Broker | replication.factor=3 + min.insync.replicas=2 + unclean.leader.election.enable=false |
确保副本可靠同步,防止数据回滚 |
| 消费者 | enable.auto.commit=false + 手动 commitSync() |
确保消息处理完成后才提交 Offset |
四、示例:订单系统防丢失实现
生产者发送订单事件
java
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("enable.idempotence", "true");
props.put("retries", Integer.MAX_VALUE);
props.put("max.in.flight.requests.per.connection", "1");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
producer.send(new ProducerRecord<>("order_events", "order-1001", "CREATED"), (metadata, exception) -> {
if (exception != null) {
System.err.println("发送失败:" + exception.getMessage());
} else {
System.out.println("发送成功:" + metadata.offset());
}
});
producer.close();消费者处理订单事件
java
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "order-consumer-group");
props.put("enable.auto.commit", "false");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("order_events"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
processOrder(record.key(), record.value()); // 业务处理
}
consumer.commitSync(); // 确保处理完成后提交
}五、面试高分回答模板
如果面试官问:
Kafka 如何保证消息不丢失?
你可以这样答:
Kafka 要保证消息不丢失,需要在生产者、Broker、消费者三个环节都做好防护:
- 生产者 :
acks=all,enable.idempotence=true,retries无限重试,max.in.flight.requests.per.connection=1,确保消息可靠写入且不重复。- Broker :
replication.factor>=3,min.insync.replicas>=2,unclean.leader.election.enable=false,确保副本同步可靠,防止数据回滚。- 消费者 :关闭自动提交 Offset,业务处理完成后手动提交,确保消息不会因提前提交而丢失。
通过这三方面的配置,可以在生产环境中实现 Kafka 的端到端消息不丢失。
Kafka 如何保证消息不重复消费?
一、为什么会出现消息重复消费?
在 Kafka 中,消息重复消费的常见原因有:
-
生产者重试导致重复发送
- 网络抖动或 Broker 短暂不可用时,生产者重试可能会把同一条消息发送多次。
-
消费者提交 Offset 失败
- 消费者处理完消息,但提交 Offset 时失败,重启后会从旧的 Offset 重新消费。
-
消费者在处理前提交 Offset
- 如果在业务处理前提交 Offset,消费者宕机会导致消息丢失或重复。
-
分区 Rebalance
- 消费者组发生再均衡时,分区可能被重新分配,导致某些消息被再次消费。
二、Kafka 保证消息不重复消费的核心策略
Kafka 本身是至少一次(At-Least-Once)投递模型,天然可能重复消费。
要做到不重复消费(Exactly-Once),需要生产者、Broker、消费者三方面配合。
1. 生产者防重复
- 开启幂等性
enable.idempotence=true
Kafka 会为每个生产者分配一个 Producer ID,并跟踪每个分区的消息序号,避免重复写入。 - 配置示例:
java
props.put("acks", "all");
props.put("enable.idempotence", "true");
props.put("retries", Integer.MAX_VALUE);
props.put("max.in.flight.requests.per.connection", "1");2. Broker 保证顺序与去重
- 副本机制
保证消息在 Leader 和 ISR 副本中一致。 - 事务支持(Kafka Streams / Producer Transaction)
Kafka 支持事务性生产者,将多条消息作为一个原子操作提交,避免部分成功部分失败。
3. 消费者防重复
- 关闭自动提交 Offset
enable.auto.commit=false - 业务处理完成后再提交 Offset
确保只有处理成功的消息才会更新消费进度。 - 幂等消费逻辑
在业务层面保证同一条消息处理多次也不会产生副作用(例如根据唯一业务 ID 去重)。
三、示例:订单系统防重复消费
生产者(开启幂等性)
java
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("enable.idempotence", "true");
props.put("retries", Integer.MAX_VALUE);
props.put("max.in.flight.requests.per.connection", "1");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
// 订单 ID 作为 Key,保证同一订单进入同一分区
producer.send(new ProducerRecord<>("order_events", "order-1001", "CREATED"));
producer.close();消费者(手动提交 Offset + 幂等处理)
java
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "order-consumer-group");
props.put("enable.auto.commit", "false");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("order_events"));
// 模拟一个已处理订单集合(实际可用数据库/Redis)
Set<String> processedOrders = new HashSet<>();
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
String orderId = record.key();
if (!processedOrders.contains(orderId)) {
processOrder(orderId, record.value()); // 业务处理
processedOrders.add(orderId);
} else {
System.out.println("重复消息已忽略:" + orderId);
}
}
consumer.commitSync(); // 处理完成后提交 Offset
}四、Exactly-Once 的实现方式
Kafka 在 0.11 版本引入了 事务(Transaction) 支持,可以实现生产者到消费者的端到端 Exactly-Once:
- 生产者开启事务,将多条消息作为一个事务提交。
- 消费者使用事务性读取,只读取已提交的事务消息。
- Kafka Streams 框架天然支持 Exactly-Once 处理。
事务性生产者示例:
java
props.put("transactional.id", "order-tx-1");
producer.initTransactions();
producer.beginTransaction();
producer.send(new ProducerRecord<>("order_events", "order-1001", "CREATED"));
producer.commitTransaction();五、面试高分回答模板
如果面试官问:
Kafka 如何保证消息不重复消费?
你可以这样答:
Kafka 默认是至少一次投递模型,可能会出现重复消费。要避免重复,需要生产者、Broker、消费者三方面配合:
- 生产者 :开启幂等性(
enable.idempotence=true),确保同一条消息不会被写入多次。- Broker:使用事务性生产者,保证多条消息原子提交,避免部分成功部分失败。
- 消费者 :关闭自动提交 Offset,业务处理完成后手动提交,并在业务层实现幂等逻辑(例如根据唯一业务 ID 去重)。
在 Kafka 0.11 及之后,可以通过事务机制实现端到端的 Exactly-Once 处理,从而彻底避免重复消费。
Kafka 中的 ACK 配置(acks=0、1、all)的区别与适用场景。
一、ACK 是什么?
在 Kafka 中,ACK(Acknowledgment) 是生产者发送消息后,Broker 对消息写入结果的确认机制。
它决定了生产者在发送消息后,等待 Broker 返回确认的条件,从而影响:
- 消息可靠性
- 吞吐量
- 延迟
二、三种 ACK 模式的区别
1. acks=0
- 含义 :生产者发送消息后不等待任何 Broker 确认。
- 流程 :
- Producer 将消息写入网络缓冲区。
- 立即返回成功(不管 Broker 是否收到)。
- 优点 :
- 延迟最低,吞吐量最高。
- 缺点 :
- 可能丢数据(Broker 宕机或网络异常时)。
- 适用场景 :
- 对可靠性要求不高的场景,例如日志收集、监控数据上报。
2. acks=1
- 含义 :生产者等待 Leader 分区写入成功的确认,不等待副本同步完成。
- 流程 :
- Producer 发送消息到 Leader。
- Leader 写入本地日志(Page Cache)。
- Leader 返回 ACK 给 Producer。
- Follower 异步复制数据。
- 优点 :
- 延迟较低,性能较好。
- Leader 写入成功即可返回,吞吐量高。
- 缺点 :
- 如果 Leader 宕机且 Follower 尚未同步该消息,消息会丢失。
- 适用场景 :
- 对性能有要求,但能容忍少量数据丢失的业务,例如实时分析、监控告警。
3. acks=all (或 acks=-1)
- 含义 :生产者等待 Leader 和 ISR(In-Sync Replicas)所有副本写入成功的确认。
- 流程 :
- Producer 发送消息到 Leader。
- Leader 写入本地日志。
- Leader 等待所有 ISR 副本同步完成。
- Leader 返回 ACK 给 Producer。
- 优点 :
- 最高可靠性 ,只要 ISR 副本数 ≥
min.insync.replicas,消息不会丢失。
- 最高可靠性 ,只要 ISR 副本数 ≥
- 缺点 :
- 延迟最高,吞吐量最低(因为要等待副本同步)。
- 适用场景 :
- 对可靠性要求极高的业务,例如金融交易、订单系统、支付系统。
三、ACK 配置对比表
| 配置值 | 等待确认对象 | 延迟 | 吞吐量 | 数据可靠性 | 适用场景 |
|---|---|---|---|---|---|
| 0 | 不等待 | 最低 | 最高 | 最低 | 日志收集、监控数据 |
| 1 | Leader | 较低 | 较高 | 中等 | 实时分析、告警系统 |
| all | Leader + 所有 ISR 副本 | 最高 | 最低 | 最高 | 金融交易、订单系统 |
四、ACK 配置示例
java
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 选择 ACK 模式
props.put("acks", "all"); // 可选:0、1、all
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
producer.send(new ProducerRecord<>("order_events", "order-1001", "CREATED"), (metadata, exception) -> {
if (exception != null) {
System.err.println("发送失败:" + exception.getMessage());
} else {
System.out.println("发送成功,offset=" + metadata.offset());
}
});
producer.close();五、生产环境最佳实践
-
高可靠业务
acks=all- 配合
min.insync.replicas≥ 2 - 开启幂等性
enable.idempotence=true
-
高吞吐业务
acks=1- 配合批量发送
batch.size、压缩compression.type
-
低延迟业务
acks=0- 适合对可靠性要求不高的场景
六、面试高分回答模板
如果面试官问:
Kafka 中 acks=0、1、all 有什么区别?适用场景是什么?
你可以这样答:
Kafka 的 ACK 配置决定了生产者发送消息后等待 Broker 确认的条件:
- acks=0:不等待确认,延迟最低、吞吐量最高,但可能丢数据,适合日志收集等低可靠场景。
- acks=1:等待 Leader 写入成功,性能较好,但 Leader 宕机且副本未同步时可能丢数据,适合实时分析等场景。
- acks=all :等待 Leader 和所有 ISR 副本写入成功,可靠性最高但延迟最大,适合金融交易、订单系统等高可靠场景。
在生产环境中,高可靠业务建议acks=all并配合min.insync.replicas设置,确保消息不会丢失。
Kafka 如何实现 Exactly Once 语义?
一、Exactly Once 是什么?
- At Most Once(至多一次):消息最多被处理一次,可能丢失,但绝不重复。
- At Least Once(至少一次):消息至少被处理一次,不会丢失,但可能重复。
- Exactly Once(精确一次) :消息既不丢失,也不重复 ,每条消息被处理且仅处理一次。
Kafka 默认是 At Least Once ,要实现 Exactly Once 需要额外机制。
二、Kafka 实现 Exactly Once 的核心机制
Kafka 在 0.11 版本 引入了 幂等性生产者(Idempotent Producer) 和 事务(Transactions),配合消费者的事务性读取,实现端到端的 EOS。
1. 幂等性生产者
- 配置
enable.idempotence=true - Kafka 为每个生产者分配一个 Producer ID(PID) ,并为每个分区维护一个 序列号(Sequence Number)。
- 如果同一 PID + 分区 + 序列号的消息重复写入,Broker 会自动去重。
- 解决了生产者端的重复写入问题。
2. 事务性生产者
- 配置
transactional.id(事务 ID) - 支持将多条消息作为一个事务提交到多个分区/Topic。
- 事务提交前,消费者不可见这些消息。
- 解决了跨分区、跨 Topic 的原子性问题。
3. 消费者事务性读取
- 配置
isolation.level=read_committed - 只读取已提交事务的消息,忽略未提交或已中止的事务消息。
- 解决了消费者读取到未提交数据的问题。
4. 消费 Offset 作为事务的一部分
- 消费者在事务中提交 Offset(
sendOffsetsToTransaction),保证:- 消息处理和 Offset 提交是原子操作
- 避免"消息处理成功但 Offset 提交失败"导致的重复消费
三、Exactly Once 实现流程
假设我们要实现 从一个 Topic 读取数据 → 处理 → 写入另一个 Topic,并保证 EOS:
- 生产者开启事务
- 消费者读取消息(read_committed)
- 处理消息
- 生产者发送处理结果到目标 Topic
- 在同一事务中提交消费者的 Offset
- 提交事务
- 如果事务失败 → 回滚事务(消息和 Offset 都不生效)
四、配置示例
生产者配置
java
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 开启幂等性
props.put("enable.idempotence", "true");
// 设置事务 ID(唯一)
props.put("transactional.id", "order-tx-1");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
producer.initTransactions();消费者配置
java
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "order-consumer-group");
props.put("enable.auto.commit", "false");
props.put("isolation.level", "read_committed"); // 只读已提交事务的消息
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("input_topic"));事务性消费 + 生产示例
java
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
if (!records.isEmpty()) {
producer.beginTransaction();
try {
for (ConsumerRecord<String, String> record : records) {
String result = process(record.value()); // 业务处理
producer.send(new ProducerRecord<>("output_topic", record.key(), result));
}
// 在事务中提交 Offset
producer.sendOffsetsToTransaction(
consumerOffsets(consumer, records),
new ConsumerGroupMetadata("order-consumer-group")
);
producer.commitTransaction();
} catch (Exception e) {
producer.abortTransaction(); // 回滚事务
}
}
}五、Exactly Once 的优缺点
优点
- 消息既不丢失,也不重复
- 支持跨分区、跨 Topic 的原子性
- 适合金融、支付、订单等高可靠场景
缺点
- 性能开销大(事务需要协调器)
- 事务超时可能导致阻塞(
transaction.timeout.ms默认 15 分钟) - 仅支持 Kafka 内部的端到端 EOS(外部系统需自己保证幂等性)
六、面试高分回答模板
如果面试官问:
Kafka 如何实现 Exactly Once 语义?
你可以这样答:
Kafka 默认是至少一次投递,要实现 Exactly Once,需要结合幂等性生产者、事务和消费者事务性读取:
- 生产者端 :开启幂等性(
enable.idempotence=true),避免重复写入。- 事务支持 :设置
transactional.id,将消息发送和 Offset 提交放在同一事务中,保证原子性。- 消费者端 :设置
isolation.level=read_committed,只读取已提交事务的消息。 这样可以保证消息处理和 Offset 提交要么都成功,要么都失败,从而实现端到端的 Exactly Once 语义。
需要注意的是,EOS 会带来性能开销,适合对数据一致性要求极高的场景。
Kafka 中的事务消息是如何实现的?
和 Kafka Exactly Once 紧密相关,但事务消息的范围更广,涉及 Kafka 内部的事务协调机制 、生产者事务流程 、消费者事务性读取等。
一、事务消息的作用
Kafka 的事务消息主要解决两个问题:
- 跨分区 / 跨 Topic 的原子性写入
- 保证一组消息要么全部成功,要么全部失败。
- 消息处理与 Offset 提交的原子性
- 保证消费者处理消息并提交 Offset 是一个不可分割的事务,避免重复消费或漏消费。
二、事务消息的核心组件
Kafka 在 0.11 版本引入事务机制,主要依赖以下组件:
-
事务性生产者(Transactional Producer)
- 通过
transactional.id标识唯一事务生产者。 - 负责开启、提交、回滚事务。
- 通过
-
事务协调器(Transaction Coordinator)
- Kafka 内部组件,负责管理事务的生命周期。
- 跟踪事务状态(开始、提交、中止)。
- 存储事务元数据在内部 Topic
__transaction_state中。
-
事务性消费者(Transactional Consumer)
- 配置
isolation.level=read_committed。 - 只读取已提交事务的消息,忽略未提交或已中止的事务消息。
- 配置
三、事务消息的实现原理
1. 事务开始
- 生产者调用
initTransactions()向事务协调器注册事务 ID。 - 协调器分配一个 Producer ID(PID) 并初始化事务状态。
2. 事务写入
- 生产者调用
beginTransaction()开启事务。 - 在事务中发送的消息会被标记为未提交,消费者不可见。
3. 提交事务
- 生产者调用
commitTransaction()。 - 协调器将事务状态更新为 COMMITTED。
- 已提交事务的消息对
read_committed消费者可见。
4. 回滚事务
- 生产者调用
abortTransaction()。 - 协调器将事务状态更新为 ABORTED。
- 已中止事务的消息会被标记为无效,消费者不可见。
四、事务消息的关键点
-
事务超时
transaction.timeout.ms默认 15 分钟。- 超时未提交事务会被自动中止。
-
幂等性
- 事务性生产者自动开启幂等性(
enable.idempotence=true)。
- 事务性生产者自动开启幂等性(
-
Offset 提交
- 消费者可以在事务中提交 Offset(
sendOffsetsToTransaction),保证消息处理与 Offset 提交的原子性。
- 消费者可以在事务中提交 Offset(
五、事务消息的流程图(文字版)
Producer.initTransactions() ↓ Producer.beginTransaction() ↓ 发送消息到多个分区/Topic(未提交状态) ↓ sendOffsetsToTransaction()(提交消费进度) ↓ Producer.commitTransaction() 或 abortTransaction() ↓ Transaction Coordinator 更新事务状态 ↓ 消费者(read_committed)读取已提交事务的消息
六、事务消息的配置与示例
生产者配置
java
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 设置事务 ID(唯一)
props.put("transactional.id", "order-tx-1");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
producer.initTransactions();消费者配置
java
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "order-consumer-group");
props.put("enable.auto.commit", "false");
props.put("isolation.level", "read_committed"); // 只读已提交事务的消息
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("input_topic"));事务性消费 + 生产示例
java
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
if (!records.isEmpty()) {
producer.beginTransaction();
try {
for (ConsumerRecord<String, String> record : records) {
String result = process(record.value()); // 业务处理
producer.send(new ProducerRecord<>("output_topic", record.key(), result));
}
// 在事务中提交 Offset
producer.sendOffsetsToTransaction(
consumerOffsets(consumer, records),
new ConsumerGroupMetadata("order-consumer-group")
);
producer.commitTransaction();
} catch (Exception e) {
producer.abortTransaction(); // 回滚事务
}
}
}七、事务消息的优缺点
优点
- 支持跨分区、跨 Topic 的原子性写入
- 保证消息处理与 Offset 提交的原子性
- 实现端到端的 Exactly Once 语义
缺点
- 性能开销大(事务协调器参与)
- 事务超时可能导致阻塞
- 仅支持 Kafka 内部的 EOS(外部系统需自己保证幂等性)
八、面试高分回答模板
如果面试官问:
Kafka 中的事务消息是如何实现的?
你可以这样答:
Kafka 在 0.11 版本引入事务机制,通过事务性生产者、事务协调器和事务性消费者实现:
- 事务性生产者 :设置
transactional.id,开启事务(beginTransaction),在事务中发送消息和提交 Offset。- 事务协调器 :管理事务生命周期,存储事务状态在
__transaction_stateTopic 中。- 事务性消费者 :设置
isolation.level=read_committed,只读取已提交事务的消息。
这样可以保证跨分区、跨 Topic 的原子性写入,并实现消息处理与 Offset 提交的原子性,从而支持端到端的 Exactly Once 语义。
Kafka 如何处理消息积压?
尤其是高峰期或者消费者性能不足时,消息积压(Backlog) 会直接影响业务的实时性甚至导致数据丢失。
一、什么是消息积压?
消息积压 指的是 Kafka Topic 中的消息生产速度远高于消费速度,导致未被消费的消息在 Broker 中堆积。
积压过多可能导致:
- 消费延迟增加
- Broker 磁盘压力过大
- 消息过期被删除(
retention.ms到期)
二、消息积压的常见原因
- 消费者处理速度慢
- 单条消息处理耗时长(复杂业务逻辑、外部调用慢)
- 消费者数量不足
- 分区数多,消费者线程少,无法并行消费
- 消费端阻塞
- 数据库写入慢、网络延迟高
- 生产端突发流量
- 短时间内生产速度暴增
- 分区分配不均
- 某些分区数据量大,导致部分消费者压力过大
三、如何监控消息积压
Kafka 提供了 Lag(消费延迟) 指标:
- Lag = 最新生产的消息位点(Log End Offset) - 已消费的位点(Committed Offset)
- 可以通过:
- Kafka 自带命令
kafka-consumer-groups.sh --describe - JMX 指标
records-lag-max - 监控系统(Prometheus + Grafana)
- Kafka 自带命令
四、处理消息积压的策略
1. 增加消费者并行度
- 增加消费者实例或线程数
- 注意:消费者数量 ≤ 分区数,否则多余的消费者会空闲
示例:多线程消费
java
ExecutorService executor = Executors.newFixedThreadPool(4);
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
executor.submit(() -> process(record)); // 并行处理
}
}2. 增加分区数
- 增加 Topic 分区数,让更多消费者并行消费
- 注意:增加分区会影响消息顺序(同 Key 保证顺序)
bash
kafka-topics.sh --alter --topic my_topic --partitions 12 --bootstrap-server localhost:90923. 提高消费者处理速度
- 优化业务逻辑(减少外部调用、批量处理)
- 使用批量消费:
java
for (ConsumerRecord<String, String> record : records) {
batch.add(record.value());
}
processBatch(batch); // 一次处理多条4. 临时跳过旧消息
- 如果积压太多且旧消息已无业务价值,可以直接从最新 Offset 开始消费:
java
consumer.seekToEnd(partitions);- 风险:会丢弃未处理的旧消息
5. 增加 Broker 资源
- 扩容 Kafka 集群,提升吞吐能力
- 增加磁盘空间,避免积压导致数据被删除
6. 调整生产端速率
- 在生产端做流量控制(Rate Limit)
- 使用消息队列中间层做削峰填谷
五、生产环境处理流程
当发现消息积压时:
- 监控告警
- 通过 Lag 指标触发告警
- 定位原因
- 消费者性能不足?分区数不够?生产端流量暴增?
- 临时措施
- 增加消费者实例
- 跳过无价值的旧消息
- 长期优化
- 增加分区数
- 优化消费者逻辑
- 增加 Broker 资源
- 在生产端做限流
六、面试高分回答模板
如果面试官问:
Kafka 如何处理消息积压?
你可以这样答:
消息积压是生产速度大于消费速度导致的,可以通过以下方式处理:
- 增加消费者并行度:增加实例或线程数,确保消费者数量 ≤ 分区数。
- 增加分区数:让更多消费者并行消费,但要注意消息顺序。
- 优化消费者处理速度:减少外部调用、批量处理消息。
- 临时跳过旧消息:从最新 Offset 开始消费,适用于旧消息无业务价值的场景。
- 增加 Broker 资源:扩容集群,提升吞吐能力。
- 生产端限流 :削峰填谷,避免突发流量压垮消费者。
在生产环境中,建议配合 Lag 监控和告警,做到积压问题可视化和快速响应。
Kafka 如何保证高可用性(HA)?
一、Kafka 高可用性的核心目标
Kafka 的高可用性主要是为了保证:
- 消息不丢失(数据可靠性)
- 服务不中断(节点故障时仍能提供服务)
- 快速恢复(故障节点恢复后自动加入集群)
二、Kafka 高可用的核心机制
1. 分区副本机制(Replication)
- 每个分区有 1 个 Leader 和 多个 Follower(副本)。
- Leader 负责读写请求,Follower 从 Leader 异步复制数据。
- 副本数由
replication.factor决定(建议 ≥ 3)。
2. ISR(In-Sync Replicas)机制
- ISR 是与 Leader 保持同步的副本集合。
- 只有 ISR 中的副本才有资格在 Leader 宕机时成为新的 Leader。
- 保证数据一致性和可靠性。
3. Leader 选举
- 当 Leader 宕机时,Kafka 会从 ISR 中选出新的 Leader。
- 选举由 Controller 节点负责(集群中有一个 Controller)。
- 选举过程快速,通常在几百毫秒到几秒内完成。
4. min.insync.replicas
- 配置最少同步副本数,保证消息写入时至少有 N 个副本确认。
- 配合
acks=all使用,确保高可靠性。 - 示例:
bash
min.insync.replicas=25. 多 Broker 部署
- Kafka 集群由多个 Broker 组成,分区副本分布在不同 Broker 上。
- 即使某个 Broker 宕机,其他 Broker 仍能提供服务。
6. ZooKeeper / KRaft 元数据管理
- Kafka 早期依赖 ZooKeeper 管理集群元数据和选举 Controller。
- 新版本(KRaft 模式)去掉 ZooKeeper,由 Kafka 自身管理元数据。
- 保证集群状态一致性和故障恢复。
三、Kafka 高可用的关键配置
| 配置项 | 作用 | 建议值 |
|---|---|---|
replication.factor |
分区副本数 | ≥ 3 |
min.insync.replicas |
最少同步副本数 | 2 |
acks |
生产者确认机制 | all |
unclean.leader.election.enable |
是否允许非 ISR 副本当选 Leader | false(保证数据一致性) |
enable.auto.leader.rebalance |
自动 Leader 重新分配 | true |
四、故障场景下的高可用处理
1. Leader Broker 宕机
- Controller 检测到 Leader 宕机。
- 从 ISR 中选出新的 Leader。
- 客户端自动感知并切换到新 Leader。
2. Follower Broker 宕机
- 该副本暂时移出 ISR。
- 恢复后重新同步数据,加入 ISR。
3. Controller 宕机
- 集群选举新的 Controller。
- 不影响数据读写,只影响管理操作短暂延迟。
五、生产环境高可用最佳实践
- 副本数 ≥ 3
保证至少有两个副本可用。 - min.insync.replicas ≥ 2 + acks=all
确保写入时至少两个副本确认。 - 跨机房部署
副本分布在不同机房,防止单机房故障。 - 关闭非 ISR Leader 选举
unclean.leader.election.enable=false - 监控与告警
监控 ISR 数量、Leader 变化、Broker 存活状态。
六、面试高分回答模板
如果面试官问:
Kafka 如何保证高可用性?
你可以这样答:
Kafka 通过分区副本机制、ISR 集合和 Leader 选举来保证高可用性:
- 分区副本机制:每个分区有多个副本,Leader 负责读写,Follower 异步复制。
- ISR 机制:只有与 Leader 保持同步的副本才有资格选为新的 Leader,保证数据一致性。
- Leader 选举:Leader 宕机时,Controller 从 ISR 中快速选出新的 Leader。
- 关键配置 :
replication.factor≥3、min.insync.replicas≥2、acks=all、unclean.leader.election.enable=false。
通过这些机制,即使部分 Broker 宕机,Kafka 仍能保证消息不丢失、服务不中断,从而实现高可用性。
三、性能优化与调优
Kafka 高吞吐量的原因是什么?
一、Kafka 高吞吐量的核心原因
Kafka 的高吞吐量并不是单一技术点,而是多种架构设计和优化机制叠加的结果,主要包括以下几个方面:
1. 顺序写磁盘(Sequential Disk Write)
- Kafka 将消息顺序写入分区的日志文件(Log Segment)。
- 顺序写磁盘的速度接近内存写入,因为磁盘顺序写避免了磁头频繁寻道。
- Kafka 依赖 操作系统 Page Cache,写入数据先进入 OS 缓存,再批量刷盘。
2. 零拷贝(Zero Copy)
- Kafka 发送数据时使用 sendfile 系统调用,直接将文件数据从 Page Cache 发送到 Socket 缓冲区。
- 避免了用户态与内核态之间的多次数据拷贝,减少 CPU 消耗。
- 数据流路径:磁盘 → Page Cache → Socket(不经过用户空间)。
3. 批量处理(Batching)
- Kafka 将多条消息打包成一个批次(Batch)发送,减少网络请求次数。
- 批量发送降低了网络 IO 和系统调用的开销。
- 生产者参数:
batch.size:批次大小linger.ms:等待时间,允许更多消息聚合成批次
4. 分区并行(Partition Parallelism)
- Topic 被划分为多个分区(Partition),每个分区可以独立读写。
- 多个分区可以分布在不同 Broker 上,实现水平扩展。
- 消费者组内的多个消费者可以并行消费不同分区的数据。
5. 简单的存储结构
- Kafka 的消息存储是追加写的日志文件,不需要复杂的索引更新。
- 旧数据通过日志段(Log Segment)和索引文件管理,删除过期数据只需删除整个文件,效率高。
6. 消费者拉取模式(Pull Model)
- Kafka 消费者主动拉取数据(Pull),而不是 Broker 推送(Push)。
- 消费者可以根据自身处理能力控制拉取速率,避免被推送压垮。
- 拉取模式更容易批量获取数据,提高吞吐量。
7. 高效的网络模型
- Kafka 基于 NIO(Java New I/O) 实现多路复用(Selector)。
- 单个线程可以管理多个 Socket 连接,减少线程上下文切换。
8. 数据压缩(Compression)
- Kafka 支持批量压缩(GZIP、Snappy、LZ4、ZSTD)。
- 压缩在生产端完成,减少网络传输数据量,提升吞吐量。
二、Kafka 高吞吐量的关键配置
| 配置项 | 作用 | 建议值(高吞吐场景) |
|---|---|---|
batch.size |
批次大小(字节) | 32KB~64KB |
linger.ms |
批次等待时间 | 5~10ms |
compression.type |
压缩算法 | lz4 / zstd |
replication.factor |
副本数 | 2 或 3(高可用) |
acks |
确认机制 | 1(追求吞吐)或 all(追求可靠) |
num.partitions |
分区数 | 根据并行度调整 |
socket.send.buffer.bytes |
发送缓冲区 | 128KB~512KB |
三、面试高分回答模板
如果面试官问:
Kafka 为什么能实现高吞吐量?
你可以这样答:
Kafka 的高吞吐量主要得益于以下几点:
- 顺序写磁盘:消息顺序写入日志文件,利用 OS Page Cache,写入速度接近内存。
- 零拷贝:使用 sendfile 直接从 Page Cache 发送到网络,减少数据拷贝和 CPU 开销。
- 批量处理:生产者和消费者都支持批量发送/拉取,减少网络请求次数。
- 分区并行:Topic 分区可分布在多个 Broker 上,支持水平扩展和并行消费。
- 简单存储结构:追加写日志 + 批量删除旧文件,存储操作高效。
- 消费者拉取模式:消费者按需拉取数据,避免推送带来的压力。
- 高效网络模型:基于 NIO 多路复用,减少线程切换。
- 数据压缩 :批量压缩减少网络传输量。
这些机制叠加,使 Kafka 在普通硬件上也能轻松达到百万级 TPS。
Kafka 中的批量发送(Batch)和压缩(Compression)机制。
一、批量发送(Batch)机制
1. 原理
- Kafka 生产者不会每来一条消息就立即发送,而是会将多条消息**聚合成一个批次(Batch)**再发送。
- 批量发送减少了网络请求次数 和系统调用开销,提升吞吐量。
- 批次是按分区聚合的:同一个分区的消息会放在同一个 Batch 中。
2. 关键参数
| 参数 | 作用 | 示例值 |
|---|---|---|
batch.size |
单个批次的最大字节数 | 32KB~64KB |
linger.ms |
等待时间(延迟发送以聚合更多消息) | 5~10ms |
buffer.memory |
生产者缓冲区总大小 | 32MB |
3. 工作流程
- 生产者将消息写入内存缓冲区(RecordAccumulator)。
- 按分区聚合成批次(Batch)。
- 如果批次达到
batch.size或等待时间超过linger.ms,则发送到 Broker。 - Broker 按批次写入日志文件。
4. 示例代码
java
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 批次大小
props.put("batch.size", 32768); // 32KB
// 等待时间
props.put("linger.ms", 5);
// 缓冲区大小
props.put("buffer.memory", 33554432); // 32MB
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 1000; i++) {
producer.send(new ProducerRecord<>("test-topic", "key-" + i, "value-" + i));
}
producer.close();二、压缩(Compression)机制
1. 原理
- Kafka 支持对批次数据进行压缩(不是单条消息)。
- 压缩在生产者端完成,消费者端解压。
- 压缩减少网络传输数据量,提高吞吐量,但会增加 CPU 开销。
2. 支持的压缩算法
| 压缩类型 | 特点 | 适用场景 |
|---|---|---|
gzip |
压缩率高,CPU开销大 | 网络带宽紧张 |
snappy |
压缩速度快,压缩率中等 | 高吞吐场景 |
lz4 |
压缩速度快,延迟低 | 实时场景 |
zstd |
压缩率高且速度快 | 大数据量传输 |
3. 关键参数
| 参数 | 作用 | 示例值 |
|---|---|---|
compression.type |
压缩算法 | snappy / lz4 / zstd |
batch.size |
批次大小(影响压缩效果) | 32KB~64KB |
4. 工作流程
- 生产者将同一分区的消息聚合成批次。
- 对批次数据进行压缩(按
compression.type)。 - 将压缩后的批次发送到 Broker。
- Broker 存储压缩数据,消费者拉取后解压。
5. 示例代码
java
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 批量发送
props.put("batch.size", 32768);
props.put("linger.ms", 5);
// 压缩算法
props.put("compression.type", "lz4");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 1000; i++) {
producer.send(new ProducerRecord<>("test-topic", "key-" + i, "value-" + i));
}
producer.close();三、批量 + 压缩的协同作用
- 批量发送:减少网络请求次数,提高吞吐量。
- 压缩:减少网络传输数据量,进一步提升吞吐量。
- 协同效果:批量越大,压缩效果越好(因为数据冗余更多)。
四、生产环境注意事项
- 批量大小与延迟的平衡
- 批量大 → 吞吐高,但延迟增加。
- 批量小 → 延迟低,但吞吐下降。
- 压缩算法选择
- 高吞吐场景:
lz4或snappy - 网络带宽紧张:
zstd或gzip
- 高吞吐场景:
- 消费者端 CPU 开销
- 压缩会增加消费者解压的 CPU 负载。
- 监控延迟与吞吐
- 调整
batch.size和linger.ms时要监控延迟变化。
- 调整
五、面试高分回答模板
如果面试官问:
Kafka 中的批量发送和压缩机制是怎样的?
你可以这样答:
Kafka 生产者会将同一分区的多条消息聚合成一个批次(Batch)再发送,减少网络请求次数,提高吞吐量。批量大小由
batch.size控制,等待时间由linger.ms控制。在批量的基础上,Kafka 支持对批次数据进行压缩(
compression.type),减少网络传输数据量,提升吞吐量。压缩在生产端完成,消费者端解压。批量和压缩结合使用可以显著提升吞吐量,但需要在延迟、CPU 开销和压缩率之间做平衡。
Kafka 中的零拷贝(Zero Copy)是如何实现的?
一、背景:为什么需要零拷贝?
在传统的文件传输中(例如从磁盘读取数据并通过网络发送),数据会在**用户空间(User Space)和内核空间(Kernel Space)**之间多次拷贝:
传统流程(4 次拷贝 + 2 次上下文切换):
- 磁盘 → 内核缓冲区(DMA 拷贝)
- 内核缓冲区 → 用户缓冲区(CPU 拷贝)
- 用户缓冲区 → Socket 缓冲区(CPU 拷贝)
- Socket 缓冲区 → 网卡(DMA 拷贝)
这种方式会:
- 增加 CPU 开销
- 增加上下文切换次数
- 降低吞吐量
二、零拷贝的核心思想
**零拷贝(Zero Copy)**的目标是:
- 减少数据在用户态和内核态之间的拷贝次数
- 让数据直接从磁盘缓冲区发送到网络缓冲区,不经过用户空间
三、Kafka 中零拷贝的实现方式
Kafka 使用 Linux 的 sendfile() 系统调用 来实现零拷贝:
-
sendfile()可以直接将文件数据从内核缓冲区(Page Cache)发送到 Socket 缓冲区。 -
数据流路径:
磁盘 → Page Cache → Socket 缓冲区 → 网卡 -
用户空间只发起调用,不参与数据搬运。
四、Kafka 零拷贝的工作流程
Kafka Broker 发送消息给消费者时:
- 消息存储在磁盘的日志文件(Log Segment)中。
- 消息被 OS Page Cache 缓存(顺序写磁盘时自动进入)。
- Broker 调用
sendfile(),直接将 Page Cache 中的数据发送到 Socket。 - 数据通过网卡发送给消费者。
数据拷贝次数对比:
| 方式 | 用户态参与 | 拷贝次数 | CPU 开销 |
|---|---|---|---|
| 传统方式 | 是 | 4 次 | 高 |
| 零拷贝 | 否 | 2 次(DMA 磁盘→内核缓冲区,DMA 内核缓冲区→网卡) | 低 |
五、Kafka 源码中的零拷贝
在 Kafka 源码中,零拷贝主要出现在 FileChannel.transferTo() 方法:
java
// Kafka 使用 NIO FileChannel 的 transferTo 方法
fileChannel.transferTo(position, count, socketChannel);transferTo()底层会调用 Linux 的sendfile()。- 直接在内核空间完成数据传输。
六、零拷贝的优势
- 减少 CPU 开销
不需要在用户空间进行数据拷贝。 - 减少上下文切换
用户态和内核态切换次数减少。 - 提升吞吐量
在普通硬件上也能轻松达到百万级 TPS。 - 降低延迟
数据传输路径更短。
七、生产环境注意事项
- 操作系统支持
- 零拷贝依赖 Linux 内核的
sendfile(),Windows 不支持。
- 零拷贝依赖 Linux 内核的
- Page Cache 命中率
- 如果数据不在 Page Cache 中,仍需从磁盘读取。
- 大文件传输优化
- 零拷贝对大批量数据传输效果更明显。
- 网络瓶颈
- 零拷贝减少 CPU 开销,但网络带宽仍可能成为瓶颈。
八、面试高分回答模板
如果面试官问:
Kafka 中的零拷贝是如何实现的?
你可以这样答:
Kafka 在 Broker 向消费者发送消息时,使用了 Linux 的
sendfile()系统调用实现零拷贝。传统方式需要将数据从磁盘读到内核缓冲区,再拷贝到用户缓冲区,然后再拷贝到 Socket 缓冲区,最后发送到网卡,涉及 4 次拷贝和多次上下文切换。
零拷贝通过
sendfile()让数据直接从内核缓冲区(Page Cache)发送到 Socket 缓冲区,不经过用户空间,只需要两次 DMA 拷贝,减少 CPU 开销和上下文切换,从而显著提升 Kafka 的吞吐量。
Kafka 如何进行生产者端的性能优化?Kafka 如何进行消费者端的性能优化?
一、生产者端性能优化
生产者端优化的目标是:提升吞吐量、降低延迟、减少资源消耗。
1. 批量发送(Batching)
-
原理:将多条消息聚合成一个批次发送,减少网络请求次数。
-
关键参数 :
参数 作用 建议值 batch.size单批次最大字节数 32KB~64KB linger.ms等待时间(聚合更多消息) 5~10ms -
示例:
java
props.put("batch.size", 32768); // 32KB
props.put("linger.ms", 5);2. 压缩(Compression)
-
原理:对批次数据进行压缩,减少网络传输量。
-
关键参数 :
参数 作用 建议值 compression.type压缩算法 lz4 / snappy / zstd -
示例:
java
props.put("compression.type", "lz4");3. 异步发送(Async Send)
-
原理:生产者默认异步发送,减少等待 Broker 响应的时间。
-
关键参数 :
参数 作用 建议值 acks确认机制 1(追求吞吐)或 all(追求可靠) max.in.flight.requests.per.connection每连接最大未确认请求数 5~10 -
示例:
java
props.put("acks", "1");
props.put("max.in.flight.requests.per.connection", 5);4. 缓冲区优化
-
原理:增大生产者内存缓冲区,减少阻塞。
-
关键参数 :
参数 作用 建议值 buffer.memory缓冲区总大小 32MB~64MB -
示例:
java
props.put("buffer.memory", 33554432); // 32MB5. 并行分区写入
- 原理:增加分区数,让生产者并行写入多个分区。
- 注意:分区数过多会增加管理开销。
生产者端优化总结
- 批量发送 + 压缩:提升吞吐量
- 合理 acks:平衡可靠性与性能
- 增大缓冲区:减少阻塞
- 分区并行:提升并发能力
二、消费者端性能优化
消费者端优化的目标是:提升消费速度、减少延迟、避免积压。
1. 批量拉取(Batch Fetch)
-
原理:一次拉取多条消息,减少网络请求次数。
-
关键参数 :
参数 作用 建议值 fetch.min.bytes最小拉取字节数 1KB~50KB fetch.max.bytes最大拉取字节数 1MB~50MB max.poll.records每次 poll 最大消息数 500~1000 -
示例:
java
props.put("fetch.min.bytes", 1024);
props.put("max.poll.records", 500);2. 并行消费
- 原理:增加消费者线程或实例数,提高并发处理能力。
- 注意:消费者数量 ≤ 分区数,否则多余消费者会空闲。
3. 异步处理
- 原理:poll 拉取后,将消息交给线程池异步处理,避免阻塞拉取。
- 示例:
java
ExecutorService executor = Executors.newFixedThreadPool(4);
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
executor.submit(() -> process(record));
}
}4. 提交位点优化
-
原理:减少位点提交频率,降低开销。
-
关键参数 :
参数 作用 建议值 enable.auto.commit自动提交位点 false(手动提交更灵活) auto.commit.interval.ms自动提交间隔 5s~10s -
示例:
java
props.put("enable.auto.commit", "false");5. 反压控制
- 原理:根据处理能力控制拉取速率,避免积压。
- 方法 :调整
max.poll.records和fetch.min.bytes。
消费者端优化总结
- 批量拉取:减少网络开销
- 并行消费:提升处理速度
- 异步处理:避免阻塞
- 合理提交位点:减少开销
- 反压控制:防止积压
三、生产者端 vs 消费者端优化对比
| 优化方向 | 生产者端 | 消费者端 |
|---|---|---|
| 批量处理 | batch.size + linger.ms | fetch.min.bytes + max.poll.records |
| 压缩 | compression.type | 自动解压 |
| 并行 | 分区并行写入 | 多线程/多实例消费 |
| 缓冲区 | buffer.memory | 内存队列 |
| 确认机制 | acks | 位点提交策略 |
四、面试高分回答模板
如果面试官问:
Kafka 如何优化生产者端和消费者端性能?
你可以这样答:
生产者端优化主要包括:批量发送(
batch.size、linger.ms)、压缩(compression.type)、合理确认机制(acks)、增大缓冲区(buffer.memory)、分区并行写入。消费者端优化主要包括:批量拉取(
fetch.min.bytes、max.poll.records)、并行消费、多线程异步处理、合理位点提交策略、反压控制。生产者端重点是减少网络请求和 CPU 开销,消费者端重点是提升处理速度和防止积压。
Kafka 中的分区数(Partition)对性能的影响。
Kafka 分区数(Partition) 是影响性能、吞吐量、并发能力和延迟的核心参数之一。
一、分区的作用
在 Kafka 中:
- Topic 被划分为多个 Partition。
- 每个 Partition 是一个有序、不可变的消息队列。
- 分区是 Kafka 并行处理 和水平扩展的基础。
二、分区数对性能的影响
1. 吞吐量(Throughput)
- 分区数增加 → 吞吐量提升
因为多个分区可以分布在不同 Broker 上,生产者和消费者可以并行读写。 - 原因:分区是并行度的单位,更多分区意味着更多并行写入和读取通道。
2. 并发能力(Parallelism)
- 生产者端:可以同时向多个分区写入数据。
- 消费者端:消费者组内的多个消费者可以并行消费不同分区的数据。
- 规则:消费者数量 ≤ 分区数,否则多余消费者会空闲。
3. 延迟(Latency)
- 分区数增加 → 延迟可能降低(并行度提升,处理更快)
- 但如果分区数过多:
- 元数据管理开销增加
- Leader 选举耗时增加
- 可能导致延迟反而升高
4. 存储与管理开销
- 每个分区对应一个日志文件目录,分区数多会增加:
- 文件句柄数量
- 内存占用(索引、元数据)
- Controller 管理复杂度
5. Leader 选举与故障恢复
- 分区数多 → Leader 数量多 → 故障恢复时需要选举的 Leader 多 → 恢复时间可能变长。
三、分区数调优建议
| 场景 | 分区数建议 | 原因 |
|---|---|---|
| 高吞吐写入 | 分区数多(≥ 6) | 提升并行写入能力 |
| 高并发消费 | 分区数 ≥ 消费者数 | 保证每个消费者有分区可消费 |
| 低延迟实时处理 | 分区数适中(4~8) | 避免元数据开销过大 |
| 小数据量 | 分区数少(1~3) | 减少管理开销 |
经验公式
如果目标是最大化吞吐量,可以用经验公式估算分区数:
分区数≈生产者并发数×每个生产者线程数分区数≈生产者并发数×每个生产者线程数
或者:
分区数≈消费者组内消费者数量×1.5分区数≈消费者组内消费者数量×1.5
四、生产环境注意事项
- 分区数不可减少
Kafka 不支持减少分区数,只能增加。 - 增加分区会影响消息顺序
同一个 Key 的消息可能会被分配到新的分区,导致顺序变化。 - 分区数过多的风险
- 元数据同步慢
- Leader 选举耗时长
- 文件句柄占用高
- 跨 Broker 分布
分区应均匀分布在不同 Broker 上,避免热点。
五、面试高分回答模板
如果面试官问:
Kafka 分区数对性能有什么影响?
你可以这样答:
分区是 Kafka 并行处理的基本单位,分区数直接影响吞吐量、并发能力和延迟:
- 吞吐量:分区数增加可以提升生产者和消费者的并行度,从而提高吞吐量。
- 并发能力:消费者组内的消费者数量不能超过分区数,否则多余消费者会空闲。
- 延迟:适当增加分区数可以降低延迟,但分区过多会增加元数据管理和 Leader 选举开销,反而可能提高延迟。
- 存储与管理开销 :分区数多会增加文件句柄、内存占用和 Controller 管理复杂度。
调优时应根据生产者并发数、消费者数量和业务延迟要求来设置分区数,并确保分区均匀分布在不同 Broker 上。
Kafka 如何进行消息压缩?支持哪些压缩算法?
一、Kafka 消息压缩的原理
-
压缩对象
- Kafka 压缩的是批次(Batch),而不是单条消息。
- 批量压缩比单条压缩效果好,因为批次内数据冗余更多。
-
压缩位置
- 压缩在生产者端完成。
- 消费者端在拉取消息时解压。
-
存储方式
- Broker 存储的是压缩后的数据,不会解压再存储。
- 这样可以减少磁盘占用和网络传输量。
二、Kafka 支持的压缩算法
| 压缩类型 | 特点 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| gzip | 压缩率高,CPU开销大 | 节省带宽 | 压缩/解压速度慢 | 网络带宽紧张 |
| snappy | 压缩速度快,压缩率中等 | 延迟低 | 压缩率一般 | 高吞吐场景 |
| lz4 | 压缩速度快,延迟低 | 高性能 | 压缩率略低于 gzip | 实时场景 |
| zstd | 压缩率高且速度快 | 性能与压缩率平衡好 | 需要较新版本 Kafka | 大数据量传输 |
三、Kafka 消息压缩的工作流程
生产者端:
- 将同一分区的多条消息聚合成一个批次(Batch)。
- 按
compression.type对批次数据进行压缩。 - 将压缩后的批次发送到 Broker。
Broker 端:
- 接收压缩后的批次。
- 直接存储压缩数据(不解压)。
- 将压缩数据发送给消费者。
消费者端:
- 拉取压缩数据。
- 按压缩算法解压。
- 处理解压后的消息。
四、Kafka 消息压缩的配置方法
生产者端配置:
java
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 压缩算法
props.put("compression.type", "lz4"); // 可选:gzip, snappy, lz4, zstd
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 1000; i++) {
producer.send(new ProducerRecord<>("test-topic", "key-" + i, "value-" + i));
}
producer.close();消费者端无需配置压缩算法,Kafka 会自动解压。
五、生产环境注意事项
-
批量大小影响压缩效果
- 批次越大,压缩率越高。
- 建议配合
batch.size和linger.ms使用。
-
CPU 开销
- 压缩和解压会增加 CPU 使用率。
- 高吞吐场景建议使用
lz4或snappy。
-
网络与磁盘优化
- 压缩减少网络传输量和磁盘占用,但会增加 CPU 负载。
-
版本兼容性
zstd需要 Kafka 2.1+ 支持。
六、面试高分回答模板
如果面试官问:
Kafka 如何进行消息压缩?支持哪些压缩算法?
你可以这样答:
Kafka 对消息批次(Batch)进行压缩,而不是单条消息。压缩在生产者端完成,消费者端自动解压,Broker 存储的是压缩后的数据。
Kafka 支持的压缩算法包括:
- gzip:压缩率高,CPU开销大,适合带宽紧张场景。
- snappy:压缩速度快,压缩率中等,适合高吞吐场景。
- lz4:压缩速度快,延迟低,适合实时场景。
- zstd :压缩率高且速度快,适合大数据量传输(Kafka 2.1+)。
在生产环境中,通常配合批量发送(batch.size、linger.ms)使用,以获得更好的压缩效果,同时需要在压缩率和 CPU 开销之间做平衡。
四、运维与监控
Kafka 如何进行集群扩容?
Kafka 的集群扩容是保证系统可持续承载更高吞吐量和数据量的关键运维能力。
一、扩容的目的
Kafka 集群扩容主要是为了:
- 提升吞吐量
- 增加 Broker 节点,分担生产者和消费者的负载。
- 增加存储容量
- 新节点提供更多磁盘空间,存储更多消息。
- 提升高可用性
- 增加副本分布的多样性,减少单点故障风险。
- 降低延迟
- 分区分布更均匀,减少热点 Broker。
二、扩容的类型
| 类型 | 说明 | 适用场景 |
|---|---|---|
| 增加 Broker 节点 | 增加集群机器数量 | 吞吐量不足、磁盘空间不足 |
| 增加分区数 | 增加 Topic 的分区数量 | 提升并行度 |
| 增加副本数 | 增加分区副本数量 | 提升容灾能力 |
三、Kafka 集群扩容步骤
1. 增加 Broker 节点
- 准备新机器
- 安装 Kafka 和 Zookeeper(或 KRaft 模式下只安装 Kafka)。
- 配置
server.properties:broker.id:唯一 IDlog.dirs:数据存储路径zookeeper.connect:Zookeeper 地址(KRaft 模式则配置controller.quorum.voters)
- 启动新 Broker
- 确保新节点能加入集群。
- 验证集群状态
- 使用
kafka-broker-api-versions.sh或kafka-topics.sh --describe查看新节点是否正常。
- 使用
2. 重新分配分区(Rebalance Partitions)
- 新 Broker 加入后,原有分区不会自动迁移,需要手动重新分配:
-
生成分区分配方案 :
bashkafka-reassign-partitions.sh \ --zookeeper zk_host:2181 \ --generate \ --topics-to-move-json-file topics.json \ --broker-list "1,2,3,4" -
执行分区迁移 :
bashkafka-reassign-partitions.sh \ --zookeeper zk_host:2181 \ --execute \ --reassignment-json-file reassignment.json -
验证迁移完成 :
bashkafka-reassign-partitions.sh \ --zookeeper zk_host:2181 \ --verify \ --reassignment-json-file reassignment.json
3. 增加分区数
- 提升并行度(注意:分区数只能增加,不能减少):
bash
kafka-topics.sh \
--zookeeper zk_host:2181 \
--alter \
--topic my-topic \
--partitions 12- 注意:增加分区可能会影响消息顺序(同 Key 的消息可能分到新分区)。
4. 增加副本数
- 提升容灾能力:
bash
kafka-reassign-partitions.sh \
--zookeeper zk_host:2181 \
--execute \
--reassignment-json-file increase-replica.json四、生产环境注意事项
- 分区迁移的负载影响
- 分区迁移会占用网络和磁盘 IO,建议在低峰期执行。
- 副本同步时间
- 新节点加入后,副本同步可能耗时较长。
- 监控扩容过程
- 使用 Kafka 的 JMX 或 Prometheus 监控迁移进度和负载。
- 版本兼容性
- 新节点 Kafka 版本应与集群一致。
- 数据均衡
- 扩容后要确保分区均匀分布,避免热点。
五、面试高分回答模板
如果面试官问:
Kafka 如何进行集群扩容?
你可以这样答:
Kafka 集群扩容主要有三种方式:增加 Broker 节点、增加分区数、增加副本数。
增加 Broker 节点的步骤是:准备新机器并配置唯一
broker.id,启动新节点加入集群,然后通过kafka-reassign-partitions.sh工具重新分配分区,使数据均衡分布。增加分区数可以提升并行度,但可能影响消息顺序;增加副本数可以提升容灾能力,但会增加存储和网络开销。
扩容过程中需要注意迁移负载、版本一致性和分区均衡,最好在业务低峰期执行。
Kafka 如何进行分区重分配(Rebalance)?
一、什么是分区重分配(Rebalance)
在 Kafka 中,分区重分配 是指将 Topic 的分区 Leader 和副本从一个 Broker 迁移到另一个 Broker,以实现负载均衡 或资源优化 。
它不会改变分区数量,但会改变分区与 Broker 的映射关系。
二、触发分区重分配的常见场景
- 集群扩容
- 新增 Broker 后,需要将部分分区迁移到新节点。
- 集群缩容
- 下线 Broker 前,需要将分区迁移到其他节点。
- 负载均衡
- 某些 Broker 负载过高,需要重新分配分区。
- 磁盘空间不足
- 将分区迁移到磁盘空间更充足的 Broker。
- 故障恢复
- Broker 恢复后,需要重新分配分区。
三、Kafka 分区重分配操作步骤
Kafka 提供了 kafka-reassign-partitions.sh 工具来执行分区重分配。
1. 确定需要迁移的 Topic
创建一个 JSON 文件(topics.json):
java
{
"topics": [
{"topic": "my-topic"}
],
"version": 1
}2. 生成分配方案
bash
kafka-reassign-partitions.sh \
--zookeeper zk_host:2181 \
--generate \
--topics-to-move-json-file topics.json \
--broker-list "1,2,3,4"--broker-list:目标 Broker ID 列表- 输出会生成一个新的分配方案 JSON(
reassignment.json)
3. 执行分区迁移
bash
kafka-reassign-partitions.sh \
--zookeeper zk_host:2181 \
--execute \
--reassignment-json-file reassignment.json- Kafka 会开始将分区副本迁移到新的 Broker。
4. 验证迁移结果
bash
kafka-reassign-partitions.sh \
--zookeeper zk_host:2181 \
--verify \
--reassignment-json-file reassignment.json- 如果迁移完成,会显示
Reassignment of partition(s) completed successfully。
四、生产环境注意事项
- 迁移负载影响
- 分区迁移会占用网络和磁盘 IO,建议在业务低峰期执行。
- 分批迁移
- 大规模迁移建议分批执行,避免集群压力过大。
- 副本同步时间
- 大分区迁移可能耗时较长,需监控 ISR(In-Sync Replica)状态。
- 版本兼容性
- 新旧 Broker 版本应一致,避免协议不兼容。
- 均衡性检查
- 迁移完成后,检查分区是否均匀分布在各 Broker。
五、面试高分回答模板
如果面试官问:
Kafka 如何进行分区重分配?
你可以这样答:
Kafka 分区重分配是通过
kafka-reassign-partitions.sh工具实现的,主要步骤是:
- 创建包含需要迁移 Topic 的 JSON 文件。
- 使用
--generate生成新的分配方案。- 使用
--execute执行迁移。- 使用
--verify验证迁移结果。
分区重分配常见于集群扩容、缩容、负载均衡和故障恢复。执行时要注意迁移对网络和磁盘的压力,建议在低峰期分批进行,并在迁移完成后检查分区均衡性。
Kafka 如何监控消息延迟?
Kafka 消息延迟(Message Latency) 是衡量系统实时性和健康度的核心指标之一。
一、Kafka 消息延迟的类型
Kafka 的延迟主要分为两类:
| 延迟类型 | 含义 | 影响因素 |
|---|---|---|
| 生产延迟(Producer Latency) | 生产者发送消息到 Broker 被确认的时间 | 网络延迟、批量参数、压缩算法、acks 设置 |
| 消费延迟(Consumer Lag) | 消费者读取消息的进度落后于最新消息的程度 | 消费速度、分区数、批量拉取参数、消费逻辑耗时 |
二、监控消息延迟的核心指标
1. 生产延迟
- 指标来源:生产者端 JMX 指标
- 关键指标:
request-latency-avg:平均请求延迟request-latency-max:最大请求延迟record-send-rate:消息发送速率
2. 消费延迟(Lag)
- Lag 计算公式:
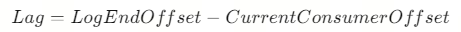
-
LogEndOffset:分区最新消息的偏移量
-
CurrentConsumerOffset:消费者已提交的偏移量
-
Lag 越大 → 消费延迟越高,可能导致实时性下降。
三、Kafka 消息延迟的监控方法
方法 1:Kafka 自带工具
- 查看 Lag:
bash
kafka-consumer-groups.sh \
--bootstrap-server broker:9092 \
--describe \
--group my-consumer-group输出示例:
TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG my-topic 0 1050 1100 50
- 优点:简单直接
- 缺点:只能手动查看,不适合实时监控
方法 2:JMX 监控
Kafka Producer、Consumer、Broker 都暴露了 JMX 指标,可以通过 Prometheus + Grafana 采集和可视化:
- 生产者端 :
producer-metrics: request-latency-avg
- 消费者端 :
consumer-fetch-manager-metrics: records-lag-maxrecords-lag-avg
- Broker 端 :
kafka.server:type=FetcherLagMetrics,name=ConsumerLag,clientId=...
方法 3:Burrow(LinkedIn 开源)
- 专门用于 Kafka 消费延迟监控的工具
- 特点:
- 自动计算 Lag
- 提供 HTTP API
- 可配置告警
- 部署后可直接监控所有消费者组的延迟
方法 4:Prometheus + Kafka Exporter
- Kafka Exporter 会采集:
kafka_consumergroup_lagkafka_consumergroup_lag_sum
- 配合 Grafana 可实时展示 Lag 曲线,并设置告警阈值。
四、生产环境监控建议
- 实时监控 Lag
- 使用 Prometheus + Kafka Exporter 或 Burrow
- 设置告警阈值
- 例如:Lag > 1000 持续 5 分钟触发告警
- 区分延迟原因
- 网络问题 → 生产延迟高
- 消费逻辑慢 → 消费延迟高
- 优化参数
- 生产端:
batch.size、linger.ms、compression.type - 消费端:
fetch.min.bytes、max.poll.records、多线程消费
- 生产端:
五、面试高分回答模板
如果面试官问:
Kafka 如何监控消息延迟?
你可以这样答:
Kafka 消息延迟主要分为生产延迟和消费延迟(Lag)。
生产延迟可以通过生产者端 JMX 指标(如
request-latency-avg)监控;消费延迟可以通过计算Lag = LogEndOffset - CurrentConsumerOffset得到。常用的监控方法包括:
- 使用
kafka-consumer-groups.sh手动查看 Lag。- 通过 JMX + Prometheus + Grafana 实时采集和可视化。
- 使用 Burrow 自动监控消费者组延迟并告警。 生产环境建议实时监控 Lag,并设置告警阈值,结合参数优化减少延迟。
Kafka 常见的监控指标有哪些?
一、Kafka 监控指标分类
Kafka 的监控指标可以分为 Broker 端、生产者端、消费者端 三大类:
| 分类 | 监控目标 | 主要关注点 |
|---|---|---|
| Broker 端 | 集群健康、吞吐量、存储、延迟 | 负载均衡、磁盘空间、网络流量 |
| 生产者端 | 消息发送性能 | 请求延迟、发送速率、失败率 |
| 消费者端 | 消费进度与延迟 | Lag、消费速率、反序列化耗时 |
二、Kafka 常见关键监控指标
1. Broker 端指标
| 指标名称 | 说明 | 作用 |
|---|---|---|
| MessagesInPerSec | 每秒进入 Broker 的消息数 | 监控写入吞吐量 |
| BytesInPerSec / BytesOutPerSec | 每秒入站/出站字节数 | 网络流量监控 |
| UnderReplicatedPartitions | 副本未同步的分区数 | 高可用性风险预警 |
| ActiveControllerCount | 当前活跃 Controller 数 | 正常应为 1 |
| OfflinePartitionsCount | 离线分区数 | 数据不可用风险 |
| RequestHandlerAvgIdlePercent | 请求处理线程空闲比例 | 负载评估 |
| LogEndOffset | 分区最新消息偏移量 | 消费延迟计算基础 |
2. 生产者端指标
| 指标名称 | 说明 | 作用 |
|---|---|---|
| request-latency-avg / max | 平均/最大请求延迟 | 网络与 Broker 响应性能 |
| record-send-rate | 每秒发送消息数 | 生产吞吐量 |
| record-size-avg | 平均消息大小 | 评估批量与压缩效果 |
| error-rate | 发送失败率 | 网络或 Broker 异常检测 |
3. 消费者端指标
| 指标名称 | 说明 | 作用 |
|---|---|---|
| records-lag-max | 最大消费延迟(Lag) | 实时性监控 |
| records-consumed-rate | 每秒消费消息数 | 消费吞吐量 |
| fetch-rate | 每秒拉取请求数 | 消费端性能评估 |
| fetch-latency-avg | 拉取延迟 | 网络与 Broker 响应性能 |
| commit-latency-avg | 提交偏移延迟 | 消费端事务性能 |
三、Kafka 监控指标采集方式
-
JMX(Java Management Extensions)
- Kafka 原生支持 JMX 暴露指标
- 可用 Prometheus JMX Exporter 采集
-
Kafka Exporter
- 专门采集 Kafka 消费延迟(Lag)、分区状态等指标
- 与 Prometheus + Grafana 配合可视化
-
Burrow
- LinkedIn 开源的 Kafka 消费延迟监控工具
- 自动计算 Lag 并提供告警 API
-
命令行工具
kafka-consumer-groups.sh查看消费者延迟kafka-topics.sh --describe查看分区状态
四、生产环境监控建议
- 核心指标必须告警
UnderReplicatedPartitions > 0OfflinePartitionsCount > 0records-lag-max持续高于阈值
- 延迟与吞吐量结合分析
- 延迟升高同时吞吐下降 → 可能是网络或磁盘瓶颈
- 分区均衡性监控
- 避免某个 Broker 负载过高
- 磁盘与网络监控
- Kafka 对磁盘 IO 和网络带宽依赖极高
五、面试高分回答模板
如果面试官问:
Kafka 常见的监控指标有哪些?
你可以这样答:
Kafka 的监控指标主要分为 Broker 端、生产者端和消费者端三类:
- Broker 端 :
MessagesInPerSec、BytesInPerSec、UnderReplicatedPartitions、ActiveControllerCount、OfflinePartitionsCount。- 生产者端 :
request-latency-avg、record-send-rate、error-rate。- 消费者端 :
records-lag-max、records-consumed-rate、fetch-latency-avg。
这些指标可以通过 JMX、Kafka Exporter、Burrow 等工具采集,并在生产环境中设置告警阈值,确保集群稳定运行。
Kafka 如何处理节点宕机?
Kafka 节点宕机处理机制 是保证高可用(HA)和数据可靠性的核心能力。
一、节点宕机的类型
在 Kafka 集群中,节点宕机主要分为两类:
| 宕机类型 | 说明 | 影响范围 |
|---|---|---|
| Broker 宕机 | 存储分区数据的 Kafka 节点不可用 | 影响该 Broker 上的分区 Leader 和副本 |
| Controller 宕机 | 负责集群元数据管理的特殊 Broker 宕机 | 影响分区 Leader 选举和元数据更新 |
二、Kafka 处理节点宕机的机制
1. Broker 宕机处理
- 副本机制(Replication)
- 每个分区有多个副本(
replication.factor≥ 2) - 一个副本是 Leader,其余是 Follower
- 每个分区有多个副本(
- ISR(In-Sync Replica)同步副本集
- 只有 ISR 内的副本才有资格成为 Leader
- Leader 自动切换
- Broker 宕机 → 该 Broker 上的 Leader 分区失效
- Controller 触发 Leader 选举,从 ISR 中选出新的 Leader
- 客户端自动感知
- 生产者和消费者通过元数据更新,自动连接新的 Leader
2. Controller 宕机处理
- Kafka 集群中只有一个 Controller(由 Broker 选举产生)
- Controller 宕机时:
- 其他 Broker 通过 Zookeeper(或 KRaft 模式下的 Raft 协议)检测到失联
- 触发 Controller 重新选举
- 新 Controller 接管元数据管理和 Leader 选举
三、节点恢复流程
- 宕机检测
- 通过 Zookeeper 会话超时(默认 6 秒)或 KRaft 心跳检测
- Leader 选举
- Controller 从 ISR 中选出新的 Leader
- 客户端重连
- 生产者/消费者更新元数据,连接新的 Leader
- 宕机节点恢复上线
- 节点重新加入 ISR
- 进行数据同步(Catch-up)
- 恢复为正常副本
四、生产环境注意事项
- 副本数设置
- 建议
replication.factor >= 3,保证容忍至少 1 台 Broker 宕机
- 建议
- ISR 监控
- 监控
UnderReplicatedPartitions,防止副本不同步
- 监控
- Leader 分布均衡
- 避免 Leader 集中在少数 Broker 上
- 宕机恢复速度
- 调整
replica.lag.time.max.ms控制副本同步超时时间
- 调整
- 避免频繁选举
- 网络抖动可能导致误判宕机 → 调整
zookeeper.session.timeout.ms
- 网络抖动可能导致误判宕机 → 调整
五、面试高分回答模板
如果面试官问:
Kafka 如何处理节点宕机?
你可以这样答:
Kafka 通过副本机制和 ISR 集合保证节点宕机时的高可用性。
当 Broker 宕机时,Controller 会检测到失联,并从 ISR 中选出新的 Leader,客户端会自动更新元数据连接新的 Leader;当 Controller 宕机时,集群会重新选举新的 Controller 接管元数据管理。
宕机节点恢复后会进行数据同步,重新加入 ISR。生产环境建议设置
replication.factor >= 3,监控UnderReplicatedPartitions,并在低峰期进行节点维护,避免频繁选举。
Kafka 如何进行数据迁移?
数据迁移 涉及到集群扩容、缩容、硬件更换、分区均衡等场景。
一、Kafka 数据迁移的类型
| 类型 | 说明 | 常见场景 |
|---|---|---|
| 分区迁移(Reassign Partitions) | 将分区副本从一个 Broker 移动到另一个 Broker | 集群扩容、缩容、负载均衡 |
| Topic 数据迁移 | 将整个 Topic 的数据迁移到新集群或新磁盘 | 集群迁移、磁盘更换 |
| 跨集群迁移(MirrorMaker) | 将数据从一个 Kafka 集群复制到另一个集群 | 灾备、跨机房同步 |
二、分区迁移(最常用)
Kafka 提供 kafka-reassign-partitions.sh 工具来进行分区迁移。
1. 确定迁移的 Topic
创建一个 JSON 文件(topics.json):
java
{
"topics": [
{"topic": "my-topic"}
],
"version": 1
}2. 生成迁移方案
bash
kafka-reassign-partitions.sh \
--zookeeper zk_host:2181 \
--generate \
--topics-to-move-json-file topics.json \
--broker-list "1,2,3,4"--broker-list:目标 Broker ID 列表- 输出会生成一个新的分配方案 JSON(
reassignment.json)
3. 执行迁移
bash
kafka-reassign-partitions.sh \
--zookeeper zk_host:2181 \
--execute \
--reassignment-json-file reassignment.json- Kafka 会开始将分区副本迁移到新的 Broker
4. 验证迁移结果
bash
kafka-reassign-partitions.sh \
--zookeeper zk_host:2181 \
--verify \
--reassignment-json-file reassignment.json- 如果迁移完成,会显示:
Reassignment of partition(s) completed successfully
三、跨集群数据迁移(MirrorMaker)
如果需要将数据迁移到另一个 Kafka 集群,可以使用 MirrorMaker:
bash
bin/kafka-mirror-maker.sh \
--consumer.config consumer.properties \
--producer.config producer.properties \
--whitelist "my-topic"- consumer.properties:源集群配置
- producer.properties:目标集群配置
- whitelist:指定迁移的 Topic
四、生产环境注意事项
- 迁移负载影响
- 分区迁移会占用网络和磁盘 IO,建议在业务低峰期执行
- 分批迁移
- 大规模迁移建议分批执行,避免集群压力过大
- 副本同步时间
- 大分区迁移可能耗时较长,需监控 ISR 状态
- 版本兼容性
- 新旧 Broker 版本应一致,避免协议不兼容
- 均衡性检查
- 迁移完成后,检查分区是否均匀分布在各 Broker
五、面试高分回答模板
如果面试官问:
Kafka 如何进行数据迁移?
你可以这样答:
Kafka 数据迁移主要有三种方式:分区迁移、Topic 数据迁移和跨集群迁移。
分区迁移是最常用的,通过
kafka-reassign-partitions.sh工具生成迁移方案并执行,适用于集群扩容、缩容和负载均衡;跨集群迁移可以用 MirrorMaker,将数据从一个集群复制到另一个集群。迁移过程中需要注意网络和磁盘负载,建议在低峰期分批执行,并在迁移完成后检查分区均衡性和 ISR 状态。
五、常见问题与场景题
Kafka 与 RabbitMQ、RocketMQ 的区别与优劣势。
Kafka 如何实现延迟消息?
Kafka 本身并不原生支持延迟消息 (Delayed Message),但我们可以通过一些设计模式 和组件扩展来实现。
一、延迟消息的概念
延迟消息 :指消息在生产后,不立即被消费,而是延迟一段时间再被消费者处理。
常见场景:
- 订单超时取消(延迟 30 分钟)
- 支付结果回查(延迟 5 分钟)
- 定时任务触发
二、Kafka 延迟消息的实现原理
Kafka 没有像 RabbitMQ 那样的 TTL + DLX(死信队列)机制,所以需要在应用层或借助外部组件实现延迟消费。
三、常见实现方式
方式 1:延迟 Topic + 定时消费
原理:
- 将需要延迟的消息发送到一个专用的延迟 Topic
- 消费者不立即消费,而是定时任务在延迟时间到达后再拉取并处理
实现步骤:
- 生产者发送消息到
delay-topic - 消费端使用定时任务(如 Quartz、ScheduledExecutorService)定期检查消息时间戳
- 延迟时间到达后再处理
优点:
- 简单易实现
- 不依赖 Kafka 额外功能
缺点:
- 定时任务精度受限
- 延迟精度不高(秒级)
方式 2:时间轮(Timing Wheel)+ Kafka
原理:
- 使用时间轮算法在内存中管理延迟任务
- 到期后将消息重新发送到正常消费 Topic
实现步骤:
- 消息进入延迟 Topic
- 延迟服务(独立进程)使用时间轮管理到期时间
- 到期后将消息发送到正常 Topic
- 消费者正常消费
优点:
- 高性能(时间复杂度 O(1))
- 延迟精度高(毫秒级)
缺点:
- 需要额外的延迟服务组件
方式 3:Kafka Streams + 时间戳过滤
原理:
- Kafka Streams 可以基于消息时间戳进行流处理
- 在流中判断是否到达延迟时间,未到期的消息暂存状态存储(state store)
优点:
- 与 Kafka 原生集成
- 支持复杂流计算
缺点:
- 开发复杂度高
- 需要额外的状态存储
方式 4:借助外部组件(如 Apache Pulsar、RocketMQ)
原理:
- 使用支持延迟消息的消息中间件作为延迟层
- 到期后再写入 Kafka
优点:
- 延迟功能由外部组件提供
- 精度高
缺点:
- 系统架构更复杂
- 需要维护额外组件
四、生产环境建议
- 延迟精度要求高 → 时间轮或外部组件
- 延迟精度要求低 → 延迟 Topic + 定时消费
- 延迟时间长(>1小时)
- 建议使用数据库存储到期时间,定时扫描后写入 Kafka
- 监控延迟队列堆积
- 避免延迟 Topic 消息过多导致磁盘压力
五、面试高分回答模板
如果面试官问:
Kafka 如何实现延迟消息?
你可以这样答:
Kafka 本身不支持延迟消息,但可以通过应用层设计实现。常见方式包括:
- 延迟 Topic + 定时消费:将消息写入延迟 Topic,定时任务到期后再消费。
- 时间轮算法:延迟服务管理到期时间,到期后将消息写入正常 Topic。
- Kafka Streams 时间戳过滤:基于消息时间戳判断是否到期,未到期的消息暂存。 如果延迟精度要求高,可以使用时间轮或外部支持延迟消息的组件;如果延迟时间长,可以用数据库存储到期时间再写入 Kafka。
Kafka 如何保证跨分区的消息顺序?
Kafka 默认只能保证单分区内的消息顺序,跨分区的消息顺序需要额外设计。
一、Kafka 消息顺序的原理
- 单分区内 :Kafka 保证消息按照写入顺序存储,消费者按偏移量顺序读取 → 天然有序。
- 跨分区:不同分区的消息是并行处理的,Kafka 不保证全局顺序。
二、跨分区保证顺序的常见方式
方式 1:强制单分区
- 原理:将所有需要保证顺序的消息发送到同一个分区。
- 实现 :生产者指定固定的
key,Kafka 根据key的哈希值映射到同一分区。 - 优点:简单,天然保证顺序。
- 缺点:吞吐量受限(单分区性能瓶颈)。
方式 2:业务分区(Key 分区)
- 原理 :按业务唯一标识(如订单 ID、用户 ID)作为
key,保证同一业务的消息进入同一分区。 - 优点:既保证单业务顺序,又能利用多分区并行处理。
- 缺点:无法保证全局顺序,只保证同一业务内的顺序。
方式 3:消费端排序
- 原理:消费者拉取多分区消息后,在应用层按时间戳或序列号排序。
- 优点:可以实现全局顺序。
- 缺点:增加延迟,需要缓存消息,复杂度高。
方式 4:中间排序层
- 原理:在 Kafka 与最终消费者之间增加一个排序服务(如 Flink、Spark Streaming),按业务规则排序后再输出。
- 优点:灵活,可实现复杂排序逻辑。
- 缺点:架构复杂,增加维护成本。
三、示例代码(按业务 Key 保证顺序)
生产者端:
java
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
String topic = "order-topic";
String orderId = "ORDER_123"; // 保证同一订单进入同一分区
for (int i = 1; i <= 5; i++) {
String message = "Order step " + i;
producer.send(new ProducerRecord<>(topic, orderId, message));
}
producer.close();说明:
orderId作为key,Kafka 会将同一key的消息映射到同一分区。- 消费者读取该分区时,消息顺序与发送顺序一致。
消费者端:
java
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "order-consumer-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("order-topic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("OrderId=%s, Step=%s%n", record.key(), record.value());
}
}输出示例:
OrderId=ORDER_123, Step=Order step 1 OrderId=ORDER_123, Step=Order step 2 OrderId=ORDER_123, Step=Order step 3 OrderId=ORDER_123, Step=Order step 4 OrderId=ORDER_123, Step=Order step 5
保证:同一订单的消息顺序一致。
四、生产环境建议
- 明确顺序范围
- 如果只需要保证单业务顺序 → 按业务 ID 分区即可。
- 如果需要全局顺序 → 考虑单分区或排序层。
- 吞吐量与顺序的权衡
- 单分区顺序好,但吞吐低;多分区吞吐高,但需额外排序。
- 幂等性处理
- 顺序依赖幂等性,避免重复消费导致顺序错乱。
- 监控分区负载
- 避免某个分区过载导致延迟。
五、面试高分回答模板
如果面试官问:
Kafka 如何保证跨分区的消息顺序?
你可以这样答:
Kafka 默认只保证单分区内的消息顺序,跨分区需要额外设计。常见方式包括:
- 强制单分区:所有消息发送到同一分区,保证全局顺序,但吞吐受限。
- 按业务 Key 分区:同一业务 ID 的消息进入同一分区,保证业务内顺序。
- 消费端排序:拉取多分区消息后按时间戳或序列号排序。
- 中间排序层:使用流处理框架在消费前排序。 生产环境中,通常按业务 Key 分区是最优方案,既保证顺序又能利用多分区并行处理。
Kafka 如何防止消费端重复处理消息?
一、消费端重复处理的常见原因
| 原因 | 场景示例 |
|---|---|
| 消费者提交位移(offset)延迟 | 消费者处理完消息但还没提交 offset 就宕机,重启后会从旧 offset 重新消费 |
| 消费者提交位移过早 | 消费者先提交 offset 再处理消息,处理失败后无法重试 |
| 分区重平衡(rebalance) | 消费者组成员变化导致分区重新分配,可能重复消费部分消息 |
| 幂等性缺失 | 消费端业务逻辑没有去重机制,重复消费会导致数据重复写入 |
二、防止重复处理的常见策略
策略 1:业务幂等性
- 原理:即使同一消息被处理多次,结果也一致。
- 实现方式 :
- 数据库唯一约束(如订单号唯一)
- Redis
SETNX(只在不存在时写入) - 版本号控制(乐观锁)
策略 2:手动提交 offset(enable.auto.commit=false)
- 原理:只有在消息处理成功后才提交 offset。
- 实现步骤 :
- 关闭自动提交:
enable.auto.commit=false - 处理成功后调用
commitSync()或commitAsync()提交 offset
- 关闭自动提交:
策略 3:事务性消费(Kafka + 数据库事务)
- 原理:将消息处理和 offset 提交放在同一个事务中,保证原子性。
- 实现方式 :
- Kafka Streams 支持事务性处理
- 业务代码中先处理数据,再提交 offset
策略 4:去重表 / 消息唯一 ID
- 原理:每条消息带唯一 ID,消费端记录已处理的 ID,重复的直接丢弃。
- 实现方式 :
- Redis
SET存储已处理 ID - 数据库去重表(主键为消息 ID)
- Redis
三、示例代码(手动提交 offset + 幂等性)
java
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "order-consumer-group");
props.put("enable.auto.commit", "false"); // 关闭自动提交
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("order-topic"));
Set<String> processedIds = new HashSet<>(); // 模拟去重记录
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
String messageId = record.key(); // 假设 key 是唯一消息 ID
if (processedIds.contains(messageId)) {
System.out.println("重复消息,跳过:" + messageId);
continue;
}
try {
// 处理业务逻辑
System.out.printf("处理消息:ID=%s, Value=%s%n", messageId, record.value());
// 记录已处理 ID
processedIds.add(messageId);
// 处理成功后提交 offset
consumer.commitSync();
} catch (Exception e) {
System.err.println("处理失败,稍后重试:" + messageId);
}
}
}说明:
- 关闭自动提交 offset
- 处理成功后手动提交
- 用
processedIds模拟去重(生产环境可用 Redis 或数据库)
四、生产环境建议
- 优先保证业务幂等性
- 即使重复消费,也不会影响最终结果
- 关闭自动提交 offset
- 避免处理失败后 offset 已提交导致消息丢失
- 使用唯一消息 ID
- 生产者生成全局唯一 ID(如 UUID、雪花算法)
- 监控分区重平衡
- 减少消费者组频繁变动
- 结合事务
- 对资金、库存等敏感业务,建议用事务性消费
五、面试高分回答模板
如果面试官问:
Kafka 如何防止消费端重复处理消息?
你可以这样答:
Kafka 可能因为 offset 提交延迟、分区重平衡等原因导致重复消费。防重的核心是业务幂等性 和正确的 offset 提交策略 。
常见方法包括:
- 业务幂等性:数据库唯一约束、Redis SETNX、版本号控制。
- 手动提交 offset:关闭自动提交,处理成功后再提交。
- 唯一消息 ID 去重:消费端记录已处理的 ID。
- 事务性消费 :将业务处理与 offset 提交放在同一事务中。
在生产环境中,通常会结合幂等性和手动提交 offset 来保证数据一致性。
Kafka 如何处理热点分区问题?
热点分区(Hot Partition) 会导致部分 Broker 负载过高,从而影响整个集群的吞吐和稳定性。
一、什么是热点分区?
热点分区:指某些分区的消息量远高于其他分区,导致所在 Broker 的 CPU、磁盘、网络负载过高。
二、热点分区的常见原因
| 原因 | 说明 |
|---|---|
| Key 分布不均 | 生产者发送消息时,Key 的哈希值集中到少数分区 |
| 单 Key 业务量过大 | 某个业务 ID(如热门商品、热点用户)产生大量消息 |
| 分区数过少 | 分区数量不足,导致单分区压力过大 |
| Leader 分布不均 | Leader 集中在少数 Broker 上,导致负载不均 |
| 消费组并行度不足 | 消费者数量少于分区数,导致部分分区消费压力大 |
三、热点分区的危害
- 单 Broker 负载过高 → CPU、磁盘、网络瓶颈
- 消息延迟增加 → ISR 同步变慢
- 集群不稳定 → 可能触发频繁 Leader 选举
- 消费者延迟 → 消费速度跟不上生产速度
四、解决热点分区的常见方法
方法 1:优化 Key 分布
- 原理:让 Key 的哈希值更均匀地映射到分区
- 实现 :
- 使用更随机的 Key(如 UUID)
- 对热点 Key 加随机前缀/后缀(如
user123#1、user123#2)
- 适用场景:热点 Key 导致分区集中
方法 2:增加分区数
-
原理:分区越多,负载越容易分散
-
实现 :
bashkafka-topics.sh --alter --topic my-topic --partitions 12 --bootstrap-server localhost:9092 -
注意 :
- 增加分区会打破原有的消息顺序(跨分区无序)
- 消费者组需要重新分配分区
方法 3:均衡 Leader 分布
-
原理:让 Leader 均匀分布在不同 Broker 上
-
实现 :
bashkafka-preferred-replica-election.sh --bootstrap-server localhost:9092 -
适用场景:Leader 集中在少数 Broker
方法 4:分流热点数据
- 原理:将热点数据拆分到多个 Topic 或分区
- 实现 :
- 热点业务单独一个 Topic
- 其他业务走普通 Topic
- 适用场景:热点业务占比极高
方法 5:生产端分区器优化
-
原理 :自定义分区器(
Partitioner)实现更均匀的分区分配 -
示例 :
javapublic class RandomPartitioner implements Partitioner { @Override public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { List<PartitionInfo> partitions = cluster.partitionsForTopic(topic); return ThreadLocalRandom.current().nextInt(partitions.size()); } } -
适用场景:默认分区器导致分布不均
方法 6:消费端扩容
- 原理:增加消费者数量,提高消费并行度
- 适用场景:消费端处理能力不足
五、生产环境建议
- 监控分区流量
- 监控每个分区的 QPS、字节流量,及时发现热点
- 提前规划分区数
- 根据峰值流量和消费能力预估分区数
- 避免单 Key 高并发
- 对热点 Key 做 hash 扰动
- 定期执行 Leader 重新分配
- 保证 Leader 均衡分布
- 分批增加分区
- 避免一次性增加过多分区导致 rebalance 压力
六、面试高分回答模板
如果面试官问:
Kafka 如何处理热点分区问题?
你可以这样答:
热点分区是指部分分区流量过高导致所在 Broker 负载过重。常见原因包括 Key 分布不均、单 Key 业务量大、分区数不足、Leader 分布不均等。
解决方法有:
- 优化 Key 分布:对热点 Key 加随机前缀/后缀。
- 增加分区数:分散负载,但要注意顺序问题。
- 均衡 Leader 分布:执行 Preferred Replica Election。
- 分流热点数据:热点业务单独 Topic。
- 自定义分区器:实现更均匀的分区分配。
- 消费端扩容 :提高消费并行度。
生产环境中,通常会结合 Key 扰动 + Leader 均衡 + 消费端扩容来解决热点分区问题。
Kafka 如何实现消息过滤?
因为很多时候消费者并不需要处理所有消息 ,而是只关心符合条件的那部分,这就涉及到消息过滤(Message Filtering)。
一、Kafka 消息过滤的原理
Kafka 本身不支持 Broker 端的消息过滤 (即不在服务端做条件筛选),过滤逻辑通常在消费端或流处理层 实现。
原因:Kafka 设计理念是高吞吐 + 简单存储,不做复杂的条件查询。
二、常见实现方式
方式 1:消费端过滤(最常用)
- 原理:消费者拉取消息后,在应用层判断是否符合条件,不符合的直接丢弃。
- 优点:实现简单,不需要改 Kafka 配置。
- 缺点:会拉取所有消息,网络和反序列化有额外开销。
方式 2:多 Topic 分流
- 原理:生产端根据业务条件将消息写入不同的 Topic,消费者只订阅需要的 Topic。
- 优点:消费者只接收需要的消息,减少网络和反序列化开销。
- 缺点:需要生产端改造,Topic 数量可能增加。
方式 3:Kafka Streams 过滤
- 原理 :使用 Kafka Streams API 在流处理中做
filter()操作,只保留符合条件的消息。 - 优点:与 Kafka 原生集成,支持复杂过滤逻辑。
- 缺点:需要额外的流处理应用,增加架构复杂度。
方式 4:外部流处理框架(Flink / Spark Streaming)
- 原理:用 Flink 或 Spark Streaming 从 Kafka 读取数据,在流计算中做过滤,再写回 Kafka。
- 优点:支持复杂条件、实时计算。
- 缺点:需要额外的计算集群。
三、示例代码
消费端过滤示例(Java)
java
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "filter-consumer-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("order-topic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
// 假设只处理金额大于100的订单
String[] parts = record.value().split(",");
double amount = Double.parseDouble(parts[1]);
if (amount > 100) {
System.out.printf("处理订单:ID=%s, 金额=%.2f%n", parts[0], amount);
} else {
System.out.printf("过滤订单:ID=%s, 金额=%.2f%n", parts[0], amount);
}
}
}Kafka Streams 过滤示例
java
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "filter-streams");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> orders = builder.stream("order-topic");
orders.filter((key, value) -> {
String[] parts = value.split(",");
double amount = Double.parseDouble(parts[1]);
return amount > 100;
}).to("filtered-order-topic");
KafkaStreams streams = new KafkaStreams(builder.build(), props);
streams.start();说明:
- 从
order-topic读取消息 - 过滤金额大于 100 的订单
- 将符合条件的消息写入
filtered-order-topic
四、生产环境建议
- 过滤逻辑尽量前置
- 如果可能,在生产端或流处理层过滤,减少消费者无效拉取
- 避免复杂反序列化
- 如果过滤条件简单,可以在反序列化前用原始字节判断
- 监控过滤比例
- 如果过滤掉的消息比例很高,考虑改为多 Topic 分流
- 流处理层可复用
- 多个业务共享一个 Kafka Streams/Flink 过滤服务,减少重复开发
五、面试高分回答模板
如果面试官问:
Kafka 如何实现消息过滤?
你可以这样答:
Kafka 本身不支持 Broker 端过滤,过滤通常在消费端或流处理层实现。常见方法包括:
- 消费端过滤:拉取消息后在应用层判断是否符合条件。
- 多 Topic 分流:生产端按条件写入不同 Topic,消费者只订阅需要的 Topic。
- Kafka Streams 过滤 :在流处理中用
filter()操作筛选消息。- 外部流处理框架 :用 Flink/Spark Streaming 从 Kafka 读取并过滤。
生产环境中,如果过滤比例高,建议在生产端或流处理层过滤,减少网络和反序列化开销。
Kafka 如何实现多租户隔离?
多租户(Multi-Tenant)场景下,不同业务线、不同团队需要资源隔离、权限隔离、流量控制 ,否则会出现互相影响、数据泄露、性能下降等问题。
一、多租户隔离的目标
在 Kafka 中,多租户隔离主要包括:
| 隔离类型 | 目标 |
|---|---|
| 数据隔离 | 不同租户的数据互不可见 |
| 权限隔离 | 不同租户只能访问授权的 Topic |
| 资源隔离 | 不同租户的流量、存储、带宽互不影响 |
| 监控隔离 | 不同租户的监控指标独立可查 |
二、Kafka 多租户隔离的常见实现方式
方式 1:Topic 级隔离(最基础)
- 原理:为每个租户创建独立的 Topic(或 Topic 前缀)
- 示例 :
tenantA_order_topictenantB_order_topic
- 优点:简单直观,数据天然隔离
- 缺点:Topic 数量多时管理复杂
方式 2:ACL 权限控制
-
原理 :使用 Kafka ACL(Access Control List) 控制用户对 Topic 的读写权限
-
示例 :
bash# 允许用户 tenantA_user 读取 tenantA 的 Topic kafka-acls.sh --authorizer-properties zookeeper.connect=localhost:2181 \ --add --allow-principal User:tenantA_user --operation Read --topic tenantA_* # 允许用户 tenantA_user 写入 tenantA 的 Topic kafka-acls.sh --authorizer-properties zookeeper.connect=localhost:2181 \ --add --allow-principal User:tenantA_user --operation Write --topic tenantA_* -
优点:安全性高,防止跨租户访问
-
缺点:ACL 配置多时维护成本高
方式 3:Quota 流量限速
-
原理 :使用 Kafka Quota 限制每个租户的生产/消费速率,防止单租户占满带宽
-
示例 :
bash# 限制用户 tenantA_user 生产速率为 10MB/s,消费速率为 20MB/s kafka-configs.sh --alter --add-config 'producer_byte_rate=10485760,consumer_byte_rate=20971520' \ --entity-type users --entity-name tenantA_user --bootstrap-server localhost:9092 -
优点:防止"资源抢占"
-
缺点:需要合理评估限速值
方式 4:Broker 级隔离(物理隔离)
- 原理:为不同租户分配不同的 Broker 节点(或 Broker 组)
- 实现 :
- 使用 Broker 标签(Broker Rack Awareness) 将租户 Topic 分配到指定 Broker
- 甚至可以为大租户部署独立 Kafka 集群
- 优点:物理隔离,性能影响最小
- 缺点:成本高,运维复杂
方式 5:命名空间管理(Confluent / Strimzi)
- 原理:使用 Kafka Operator(如 Strimzi)或 Confluent Platform 提供的多租户命名空间功能
- 优点:支持 Topic、ACL、Quota 的统一管理
- 缺点:依赖额外平台
三、生产环境多租户隔离示例
假设我们有两个租户:tenantA 和 tenantB,我们可以这样做:
-
Topic 命名规范
tenantA_order tenantA_payment tenantB_order tenantB_payment -
ACL 权限
bashkafka-acls.sh --add --allow-principal User:tenantA_user --operation All --topic tenantA_* kafka-acls.sh --add --allow-principal User:tenantB_user --operation All --topic tenantB_* -
Quota 限速
bashkafka-configs.sh --alter --add-config 'producer_byte_rate=5242880,consumer_byte_rate=10485760' \ --entity-type users --entity-name tenantA_user --bootstrap-server localhost:9092 -
监控隔离
- 使用 Prometheus + Grafana 按租户维度展示生产/消费速率、延迟、堆积量
四、生产环境建议
- Topic 命名规范化
- 统一使用
tenantId_topicName格式
- 统一使用
- ACL + Quota 必须配合使用
- ACL 保证安全,Quota 保证公平
- 大租户可考虑物理隔离
- 避免大租户影响小租户
- 监控与告警
- 按租户维度监控流量、延迟、堆积
- 自动化管理
- 用脚本或平台自动创建 Topic、配置 ACL、Quota
五、面试高分回答模板
如果面试官问:
Kafka 如何实现多租户隔离?
你可以这样答:
Kafka 多租户隔离主要包括数据隔离、权限隔离、资源隔离和监控隔离。常见方法有:
- Topic 级隔离:每个租户独立 Topic。
- ACL 权限控制:限制用户只能访问自己的 Topic。
- Quota 限速:限制生产/消费速率,防止资源抢占。
- Broker 级隔离:为大租户分配独立 Broker 或集群。
- 命名空间管理 :使用 Strimzi/Confluent 等平台统一管理。
生产环境中,通常会结合 Topic 命名规范 + ACL + Quota 来实现逻辑隔离,大租户再配合物理隔离。
4. RocketMQ
RocketMQ 的架构原理?
RocketMQ 的消息存储机制?
RocketMQ 的顺序消息实现原理?
RocketMQ 的事务消息原理?
RocketMQ 如何实现延迟消息?
RocketMQ 如何保证消息不丢失?
二、缓存中间件
1. Redis(有单独一篇文章介绍redis)
Redis 的数据结构有哪些?
Redis 的持久化机制(RDB、AOF)?
Redis 的过期策略?
Redis 的内存淘汰策略?
Redis 的事务机制?
Redis 的主从复制原理?
Redis 的哨兵模式原理?
Redis 的集群模式原理?
Redis 如何实现分布式锁?
## **Redis 如何防止缓存穿透、击穿、雪崩?**## **Redis 与 Memcached 的区别?**三、数据库中间件
1. MySQL(有单独一篇文章介绍MySQL)
MySQL 的存储引擎有哪些?
InnoDB 与 MyISAM 的区别?
MySQL 的事务隔离级别?
MySQL 的索引类型?
MySQL 的慢查询优化方法?
MySQL 的主从复制原理?
MySQL 的读写分离实现方法?
MySQL 的分库分表方案?
MySQL 的分布式事务解决方案?
2. 数据库中间件
ShardingSphere 的原理?
MyCat 的原理?
分库分表后的主键 ID 如何生成?
分布式事务的常见解决方案(2PC、TCC、Saga)?
四、搜索引擎中间件
一、基础概念类
Elasticsearch 的核心概念有哪些?(Index、Document、Shard、Replica)
1. Index(索引)
-
定义 :Elasticsearch 中存储数据的逻辑集合,相当于关系型数据库中的 表(Table)。
-
特点 :
- 一个索引由多个 分片(Shard) 组成
- 索引有自己的 Mapping (字段类型定义)和 Settings(分片、副本配置)
-
类比:在 MySQL 中,一个表存储一类数据;在 Elasticsearch 中,一个索引存储一类文档。
-
示例 :
bash# 创建一个索引 PUT /products { "settings": { "number_of_shards": 3, "number_of_replicas": 1 } }
2. Document(文档)
-
定义 :Elasticsearch 中的最小数据单元,相当于关系型数据库中的 一行记录(Row)。
-
特点 :
- 文档以 JSON 格式存储
- 每个文档有一个唯一的
_id - 文档属于某个索引
-
类比:在 MySQL 中,一行记录是结构化的;在 Elasticsearch 中,一个文档是 JSON 对象。
-
示例 :
bash# 向索引 products 添加一个文档 POST /products/_doc/1 { "name": "iPhone 15", "price": 9999, "brand": "Apple" }
3. Shard(分片)
- 定义 :Elasticsearch 将索引数据拆分成多个部分,每个部分称为 分片。
- 作用 :
- 水平扩展:分片可以分布在不同节点上,提升存储和查询能力
- 并行处理:多个分片可同时处理查询,提高性能
- 类型 :
- Primary Shard(主分片):存储原始数据
- Replica Shard(副本分片):存储主分片的副本,用于容错和负载均衡
- 类比:一本书(索引)拆成几章(分片),不同人可以同时看不同章节。
- 示例 :
- 如果一个索引有 3 个主分片,每个分片可以放在不同节点上。
4. Replica(副本)
-
定义 :主分片的拷贝,用于高可用 和查询负载均衡。
-
作用 :
- 容错:主分片所在节点宕机时,副本可以提升为主分片
- 读扩展:副本可以参与查询,提高并发能力
-
注意 :
- 副本分片不能与对应的主分片放在同一个节点
- 副本数量可以动态调整
-
类比:一本书的复印件(副本),原书丢了还能用复印件继续看。
-
示例 :
bash# 修改副本数量 PUT /products/_settings { "number_of_replicas": 2 }
核心关系总结表
| 概念 | 类比 | 作用 | 关键点 |
|---|---|---|---|
| Index | 数据库表 | 存储一类文档 | 有 Mapping 和 Settings |
| Document | 数据库行 | 最小数据单元 | JSON 格式,唯一 _id |
| Shard | 书的章节 | 数据拆分与分布 | 主分片存原始数据 |
| Replica | 书的复印件 | 容错与读扩展 | 不与主分片同节点 |
面试高分回答示例
Elasticsearch 的核心概念包括:
- Index:存储一类文档的逻辑集合,相当于数据库表。
- Document:最小数据单元,JSON 格式,相当于数据库行。
- Shard:索引数据的物理拆分单元,分为主分片和副本分片,用于水平扩展和并行处理。
- Replica :主分片的副本,用于容错和读扩展。
这些概念共同保证了 Elasticsearch 的高可用性、可扩展性和高性能搜索能力。
什么是倒排索引?它在 Elasticsearch 中的作用是什么?
1. 什么是倒排索引(Inverted Index)?
- 定义 :倒排索引是一种数据结构,用于快速全文检索。它的核心思想是从"词 → 文档"的映射,而不是传统的"文档 → 词"。
- 原理 :
- 传统索引(正排索引):存储每个文档包含的词,查询时需要扫描所有文档。
- 倒排索引:存储每个词在哪些文档中出现,查询时直接定位到相关文档。
- 类比 :
- 正排索引:一本书的目录,按章节列出内容。
- 倒排索引:一本书的词汇表,每个词后面标注它出现在哪些页。
2. 倒排索引在 Elasticsearch 中的作用
- 快速全文搜索:通过词到文档的映射,快速定位包含该词的文档。
- 支持复杂查询:如布尔查询、短语匹配、模糊搜索等。
- 高效排序与相关性计算:结合 TF-IDF、BM25 等算法计算匹配度。
- 节省存储空间:词典 + 文档列表的结构比全文扫描更高效。
3. 示例
假设我们有三个文档:
| 文档ID | 内容 |
|---|---|
| 1 | Elasticsearch 是一个搜索引擎 |
| 2 | 搜索引擎 可以用 Elasticsearch 实现 |
| 3 | 我喜欢 搜索引擎 |
构建倒排索引的过程:
-
分词(假设用中文分词器):
- 文档1:
Elasticsearch、是、一个、搜索引擎 - 文档2:
搜索引擎、可以、用、Elasticsearch、实现 - 文档3:
我、喜欢、搜索引擎
- 文档1:
-
建立词 → 文档列表映射:
| 词 | 文档列表 |
|---|---|
| Elasticsearch | 1, 2 |
| 是 | 1 |
| 一个 | 1 |
| 搜索引擎 | 1, 2, 3 |
| 可以 | 2 |
| 用 | 2 |
| 实现 | 2 |
| 我 | 3 |
| 喜欢 | 3 |
查询示例:
- 查询
"搜索引擎"→ 直接返回文档[1, 2, 3] - 查询
"Elasticsearch AND 搜索引擎"→ 取交集 →[1, 2]
4. 面试高分回答模板
倒排索引 是一种用于全文检索的数据结构,它存储的是词到文档的映射关系 ,而不是文档到词的关系。
在 Elasticsearch 中,倒排索引是核心机制,它通过分词器将文档拆分成词条,并记录每个词条在哪些文档中出现,从而实现快速全文搜索 。
例如,文档中出现"搜索引擎"这个词,倒排索引会记录该词对应的文档ID列表,查询时直接定位到这些文档,而不需要扫描所有数据。
这种结构结合 BM25 等相关性算法,可以在毫秒级返回搜索结果,是 Elasticsearch 高性能的关键。
Elasticsearch 的数据是如何存储的?
1. 总体原理
Elasticsearch 的数据存储基于 Lucene ,它是一个高性能的全文检索库。
在 Elasticsearch 中,数据存储的核心思想是:
- 文档(Document) 以 JSON 格式存储
- 每个文档属于一个 索引(Index)
- 索引被拆分成多个 分片(Shard)
- 每个分片是一个独立的 Lucene 索引,存储在磁盘上
2. 数据存储流程
当你向 Elasticsearch 写入数据时,流程如下:
-
接收请求
客户端发送
PUT或POST请求,包含 JSON 文档。 -
路由到分片
Elasticsearch 根据文档
_id计算哈希值,确定该文档属于哪个 主分片(Primary Shard)。 -
写入主分片
主分片所在节点将文档写入 Lucene 索引:
- 分词(Analyzer):将文本拆分成词条
- 建立倒排索引:记录词条 → 文档ID映射
- 存储正排数据:保存原始字段值(用于返回结果)
-
同步到副本分片
主分片写入成功后,将数据复制到对应的 副本分片(Replica Shard),保证高可用。
-
刷新(Refresh)
默认每秒刷新一次,将内存中的段(Segment)写入磁盘,使数据可被搜索。
3. 数据结构
在磁盘上,每个分片是一个 Lucene 索引,包含:
- 倒排索引(Inverted Index):用于快速搜索
- 正排存储(Stored Fields):存储原始字段值
- Doc Values:用于排序、聚合等
- Segments(段) :
- Lucene 索引由多个不可变的段组成
- 新数据写入时会生成新的段
- 段合并(Merge)会减少段数量,提高查询性能
4. 示例
假设我们有一个索引 products,分片数为 3,副本数为 1:
-
写入文档:
bashPOST /products/_doc/1 { "name": "iPhone 15", "price": 9999, "brand": "Apple" } -
存储过程:
-
_id=1→ 哈希计算 → 分配到主分片 P2 -
P2 分词
"iPhone 15"→["iphone", "15"] -
建立倒排索引:
iphone → docID=1 15 → docID=1 -
存储正排数据(原始 JSON)
-
同步到副本分片 R2
-
刷新后可搜索
-
5. 面试高分回答模板
Elasticsearch 的数据存储基于 Lucene,每个索引被拆分成多个分片,每个分片是一个独立的 Lucene 索引。
写入流程是:客户端发送 JSON 文档 → 路由到主分片 → 分词并建立倒排索引 → 存储原始字段值 → 同步到副本分片 → 刷新使数据可搜索。
在磁盘上,分片由多个不可变的段(Segment)组成,段中包含倒排索引、正排存储和 Doc Values。
这种结构保证了 Elasticsearch 的高性能搜索、可扩展性和高可用性。
什么是 Mapping?它的作用是什么?
1. 什么是 Mapping?
- 定义 :
Mapping 是 Elasticsearch 中定义文档字段类型和索引方式的规则 ,相当于关系型数据库中的 表结构(Schema) 。
它告诉 Elasticsearch:- 每个字段的数据类型(如
text、keyword、date、integer等) - 字段是否需要分词
- 使用哪种分词器(Analyzer)
- 是否存储原始值(Stored Fields)
- 是否启用 Doc Values(用于排序、聚合)
- 每个字段的数据类型(如
2. Mapping 的作用
-
定义字段类型
- 确保数据按正确的方式存储和索引
- 例如:
price应该是float,created_at应该是date
-
控制分词行为
text类型会分词(适合全文搜索)keyword类型不分词(适合精确匹配)
-
影响搜索和排序
- 只有启用 Doc Values 的字段才能用于排序和聚合
-
提高查询性能
- 合理的 Mapping 可以减少存储空间、加快搜索速度
3. Mapping 的类型
-
动态映射(Dynamic Mapping)
- 默认开启,Elasticsearch 会自动推断字段类型
- 例如:插入
"price": 100→ 自动识别为long - 优点:方便快速开发
- 缺点:可能推断错误(如数字型字符串被识别为
text)
-
显式映射(Explicit Mapping)
- 手动定义字段类型和属性
- 优点:可控性强,避免类型错误
- 缺点:需要提前设计
4. 示例
创建索引并定义 Mapping
bash
PUT /products
{
"mappings": {
"properties": {
"name": {
"type": "text", # 支持全文搜索
"analyzer": "ik_max_word" # 使用中文分词器
},
"brand": {
"type": "keyword" # 精确匹配
},
"price": {
"type": "float" # 数值类型
},
"created_at": {
"type": "date", # 日期类型
"format": "yyyy-MM-dd HH:mm:ss"
}
}
}
}动态映射示例
bash
POST /products/_doc
{
"name": "iPhone 15",
"price": 9999,
"brand": "Apple"
}- 如果没有显式 Mapping,Elasticsearch 会自动推断:
name→textprice→longbrand→text
5. 面试高分回答模板
Mapping 是 Elasticsearch 中定义文档字段类型和索引方式的规则,相当于数据库的表结构。
它的作用包括:
- 定义字段类型(如 text、keyword、date、integer 等)
- 控制分词行为(全文搜索 vs 精确匹配)
- 决定字段是否可用于排序、聚合
- 提高存储和查询性能
Mapping 分为动态映射和显式映射,生产环境中通常建议显式定义 Mapping,以避免自动推断带来的类型错误。
Elasticsearch 中的分片(Shard)和副本(Replica)有什么区别?
1. 分片(Shard)
- 定义 :
分片是 Elasticsearch 索引数据的物理存储单元 。
每个分片是一个独立的 Lucene 索引,可以存储部分数据并独立处理搜索请求。 - 类型 :
- 主分片(Primary Shard):存储原始数据,是数据的唯一来源。
- 副本分片(Replica Shard):主分片的拷贝,用于容错和读扩展。
- 作用 :
- 水平扩展:将数据分布到多个节点
- 并行处理:多个分片可同时处理查询
2. 副本(Replica)
- 定义 :
副本是 主分片的完整拷贝,用于保证高可用性和提升查询性能。 - 作用 :
- 容错:主分片所在节点宕机时,副本可以提升为主分片
- 读扩展:副本可以参与查询,提高并发能力
- 注意 :
- 副本分片不能与对应的主分片放在同一个节点
- 副本数量可以动态调整
3. 分片 vs 副本 对比表
| 对比项 | 分片(Shard) | 副本(Replica) |
|---|---|---|
| 定义 | 索引数据的物理存储单元 | 主分片的拷贝 |
| 类型 | 主分片 / 副本分片 | 仅副本分片 |
| 作用 | 存储原始数据,支持写入 | 容错、读扩展 |
| 数据来源 | 原始数据 | 来自主分片 |
| 可写性 | 主分片可写,副本不可写 | 不可写(只读) |
| 位置限制 | 可在任意节点 | 不与主分片同节点 |
| 数量 | 创建索引时固定 | 可动态调整 |
4. 示例
假设我们创建一个索引:
bash
PUT /products
{
"settings": {
"number_of_shards": 3, # 主分片数量
"number_of_replicas": 1 # 每个主分片有1个副本
}
}-
总分片数:
- 主分片:3
- 副本分片:3(每个主分片一个副本)
- 总分片数 = 3 主分片 + 3 副本分片 = 6
-
分布示例:
节点1:P1, R2 节点2:P2, R3 节点3:P3, R1- P = 主分片(Primary)
- R = 副本分片(Replica)
5. 面试高分回答模板
在 Elasticsearch 中,**分片(Shard)**是索引数据的物理存储单元,每个分片是一个独立的 Lucene 索引。分片分为主分片和副本分片,主分片存储原始数据并支持写入。
**副本(Replica)**是主分片的拷贝,用于容错和读扩展,副本分片不可写,只能参与查询。
分片数量在索引创建时固定,副本数量可以动态调整。副本分片不能与对应的主分片放在同一个节点,以保证高可用性。
什么是 Analyzer?分词器的作用是什么?
1. 什么是 Analyzer(分析器)?
- 定义 :
Analyzer(分析器) 是 Elasticsearch 中处理文本字段的组件 ,它的作用是将文本分解成一个个词条(Token)并进行标准化处理,以便建立倒排索引和进行搜索匹配。 - 工作阶段 :
- 索引阶段:将文档字段的文本分词并建立倒排索引
- 搜索阶段:将用户输入的查询语句分词,并与倒排索引匹配
2. Analyzer 的组成
一个 Analyzer 由 三个部分组成:
| 组件 | 作用 | 示例 |
|---|---|---|
| Character Filter(字符过滤器) | 在分词前处理文本,如去掉 HTML 标签、替换字符 | 把 & 替换成 and |
| Tokenizer(分词器) | 将文本切分成一个个词条(Token) | "I love Elasticsearch" → ["I", "love", "Elasticsearch"] |
| Token Filter(词元过滤器) | 对分词结果进行处理,如转小写、去停用词、同义词扩展 | ["I", "love", "Elasticsearch"] → ["i", "love", "elasticsearch"] |
3. 分词器的作用
- 建立倒排索引
- 将文本拆分成词条,记录词条 → 文档ID 的映射
- 提升搜索准确度
- 通过大小写归一化、去停用词、同义词扩展等方式,让搜索更智能
- 支持多语言搜索
- 不同语言使用不同分词器(如英文用
standard,中文用ik_max_word)
- 不同语言使用不同分词器(如英文用
- 提高搜索性能
- 分词后的倒排索引查询速度远快于全文扫描
4. 示例及结果
示例 1:英文分词(standard analyzer)
bash
POST _analyze
{
"analyzer": "standard",
"text": "I Love Elasticsearch 8.0!"
}分词结果:
["i", "love", "elasticsearch", "8.0"]
- 特点:自动转小写,按空格和标点切分
示例 2:中文分词(ik_max_word 分词器)
bash
POST _analyze
{
"analyzer": "ik_max_word",
"text": "我喜欢学习Elasticsearch搜索引擎"
}分词结果:
["我", "喜欢", "学习", "elasticsearch", "搜索", "搜索引擎", "引擎"]
- 特点:最大化切分,适合搜索召回率高的场景
示例 3:同义词扩展
假设我们定义了同义词:
bash
PUT /my_index
{
"settings": {
"analysis": {
"filter": {
"my_synonym_filter": {
"type": "synonym",
"synonyms": [
"iphone,苹果手机"
]
}
},
"analyzer": {
"my_synonym_analyzer": {
"tokenizer": "ik_max_word",
"filter": ["my_synonym_filter"]
}
}
}
}
}测试:
bash
POST /my_index/_analyze
{
"analyzer": "my_synonym_analyzer",
"text": "我想买苹果手机"
}分词结果:
["我", "想", "买", "苹果手机", "iphone"]
- 特点:搜索"苹果手机"时,也能匹配"iphone"
5. 面试高分回答模板
Analyzer(分析器) 是 Elasticsearch 中用于处理文本字段的组件,它在索引和搜索阶段都会执行,将文本分解成词条并进行标准化处理。
一个分析器由 字符过滤器(Character Filter) 、分词器(Tokenizer) 和 词元过滤器(Token Filter) 组成。
它的作用包括:
- 将文本拆分成词条,建立倒排索引
- 提升搜索准确度(大小写归一化、去停用词、同义词扩展)
- 支持多语言搜索
- 提高搜索性能
例如,使用ik_max_word分词器处理"我喜欢学习Elasticsearch搜索引擎",会得到["我", "喜欢", "学习", "elasticsearch", "搜索", "搜索引擎", "引擎"],这样搜索"搜索引擎"时就能快速匹配到相关文档。
Elasticsearch 的版本控制机制是怎样的?
1. 定义
Elasticsearch 的版本控制机制(Version Control)是用来保证文档在并发更新时的数据一致性 的。
它的核心思想是:
- 每个文档都有一个 版本号(_version)
- 每次更新文档时,版本号都会递增
- 更新操作会检查版本号是否匹配,避免**"最后写入覆盖"**的问题
2. 原理
- 乐观并发控制(Optimistic Concurrency Control, OCC)
Elasticsearch 使用 乐观锁,假设并发冲突很少发生,不加锁直接执行更新,但在提交时检查版本号。 - 版本号来源 :
- 内部版本号(默认):由 Elasticsearch 自动维护
- 外部版本号(External Versioning):由客户端提供(适合从外部系统同步数据)
3. 机制
内部版本控制
- 每个文档有一个
_version字段 - 新增文档时
_version=1 - 每次更新或删除
_version+ 1 - 更新时可以指定
if_seq_no和if_primary_term来确保版本匹配(ES 7.x 之后推荐这种方式)
外部版本控制
- 使用
version和version_type=external - 客户端提供版本号,ES 只在新版本号大于当前版本号时才更新
4. 示例
内部版本控制示例
bash
# 创建文档
PUT /products/_doc/1
{
"name": "iPhone 15",
"price": 9999
}返回:
java
{
"_version": 1
}
bash
# 更新文档,指定版本号
PUT /products/_doc/1?if_seq_no=0&if_primary_term=1
{
"name": "iPhone 15 Pro",
"price": 10999
}- 如果
if_seq_no和if_primary_term不匹配,则更新失败,返回version_conflict_engine_exception
外部版本控制示例
bash
PUT /products/_doc/1?version=5&version_type=external
{
"name": "iPhone 15 Pro Max",
"price": 12999
}- 如果当前版本号 < 5,则更新成功
- 如果当前版本号 ≥ 5,则更新失败
5. 面试高分回答模板
Elasticsearch 的版本控制机制用于保证文档在并发更新时的数据一致性,核心是乐观并发控制 。
每个文档都有一个
_version字段,每次更新或删除都会递增版本号。更新时可以使用
if_seq_no和if_primary_term(推荐方式)来确保只有在版本匹配时才执行更新,从而避免并发冲突。另外,Elasticsearch 还支持外部版本控制(
version_type=external),由客户端提供版本号,适合与外部系统同步数据。这种机制保证了在高并发环境下,数据不会被旧版本覆盖。
二、查询与索引类
Elasticsearch 支持哪些类型的查询?(Term、Match、Range 等)
1. Elasticsearch 查询类型分类
Elasticsearch 的查询主要分为两大类:
-
精确匹配(Term-level queries)
- 不分词,直接匹配字段值
- 适合
keyword、数值、日期等类型字段 - 常见:
term、terms、range、exists
-
全文搜索(Full-text queries)
- 会分词,适合
text类型字段 - 常见:
match、match_phrase、multi_match
- 会分词,适合
2. 常见查询类型详解
2.1 Term 查询(精确匹配)
- 特点:不分词,直接匹配字段值
- 适用场景 :
keyword、数值、日期 - 示例:
bash
GET /products/_search
{
"query": {
"term": {
"brand": "Apple"
}
}
}结果 :只返回 brand 字段值完全等于 "Apple" 的文档
注意 :如果 brand 是 text 类型,会匹配不到,因为 text 会分词并转小写
2.2 Match 查询(全文搜索)
- 特点 :会分词,适合
text类型字段 - 适用场景:模糊匹配、全文搜索
- 示例:
bash
GET /products/_search
{
"query": {
"match": {
"name": "iPhone 15"
}
}
}分词过程 (standard analyzer):
"iPhone 15" → ["iphone", "15"]
结果 :返回 name 字段中包含 "iphone" 或 "15" 的文档
2.3 Match Phrase 查询(短语匹配)
- 特点:分词后要求词条顺序和位置都匹配
- 适用场景:搜索固定短语
- 示例:
bash
GET /products/_search
{
"query": {
"match_phrase": {
"name": "iPhone 15"
}
}
}结果 :只返回 name 中连续出现 "iphone" 和 "15" 的文档
2.4 Range 查询(范围匹配)
- 特点:匹配数值、日期、IP 范围
- 适用场景:价格区间、时间区间
- 示例:
bash
GET /products/_search
{
"query": {
"range": {
"price": {
"gte": 5000,
"lte": 10000
}
}
}
}结果 :返回 price 在 5000 到 10000 之间的文档
2.5 Terms 查询(多值精确匹配)
- 特点:匹配多个值之一
- 示例:
bash
GET /products/_search
{
"query": {
"terms": {
"brand": ["Apple", "Huawei"]
}
}
}结果 :返回 brand 为 "Apple" 或 "Huawei" 的文档
2.6 Exists 查询(字段存在性)
- 特点:判断字段是否存在
- 示例:
bash
GET /products/_search
{
"query": {
"exists": {
"field": "price"
}
}
}结果 :返回所有包含 price 字段的文档
3. 查询类型对比表
| 查询类型 | 是否分词 | 适用字段类型 | 匹配规则 | 示例场景 |
|---|---|---|---|---|
| term | 否 | keyword、数值、日期 | 精确匹配 | 搜索品牌等于 Apple |
| terms | 否 | keyword、数值、日期 | 多值精确匹配 | 搜索品牌为 Apple 或 Huawei |
| match | 是 | text | 分词后匹配任意词条 | 搜索标题包含"iPhone" |
| match_phrase | 是 | text | 分词后顺序和位置都匹配 | 搜索短语"iPhone 15" |
| range | 否 | 数值、日期、IP | 范围匹配 | 搜索价格 5000-10000 |
| exists | 否 | 任意 | 字段存在性 | 搜索有价格的商品 |
4. 面试高分回答模板
Elasticsearch 支持两大类查询:精确匹配 (term-level)和 全文搜索 (full-text)。
精确匹配包括
term、terms、range、exists,不分词,适合 keyword、数值、日期等字段;全文搜索包括
match、match_phrase、multi_match,会分词,适合 text 类型字段。例如,
term查询"brand": "Apple"会精确匹配品牌为 Apple 的文档,而match查询"name": "iPhone 15"会分词成["iphone", "15"]并匹配包含任意词条的文档。合理选择查询类型可以提高搜索的准确性和性能。
Term Query 和 Match Query 的区别是什么?
1. 定义
-
Term Query
- 精确匹配查询
- 不分词,直接匹配字段值
- 适合
keyword、数值、日期类型字段
-
Match Query
- 全文搜索查询
- 会分词(使用字段的 analyzer),匹配分词后的任意词条
- 适合
text类型字段
2. 核心区别
| 对比项 | Term Query | Match Query |
|---|---|---|
| 是否分词 | 否 | 是 |
| 适用字段类型 | keyword、数值、日期 | text |
| 匹配规则 | 字段值必须完全相等 | 分词后匹配任意词条 |
| 搜索场景 | 精确匹配(ID、标签、状态) | 模糊匹配、全文搜索 |
| 性能 | 高(直接匹配) | 相对低(需要分词和评分计算) |
3. 示例及结果对比
假设索引中有以下文档:
bash
{ "name": "iPhone 15 Pro Max", "brand": "Apple" }
{ "name": "Apple iPhone 15", "brand": "Apple" }
{ "name": "Huawei Mate 60", "brand": "Huawei" }Term Query 示例
bash
GET /products/_search
{
"query": {
"term": {
"brand": "Apple"
}
}
}结果:
- 返回
brand字段值完全等于"Apple"的文档 - 如果
brand是text类型,可能匹配不到,因为text会分词并转小写
Match Query 示例
bash
GET /products/_search
{
"query": {
"match": {
"name": "iPhone 15"
}
}
}分词过程 (standard analyzer):
"iPhone 15" → ["iphone", "15"]
结果:
- 返回
name中包含"iphone"或"15"的文档 - 匹配到
"iPhone 15 Pro Max"和"Apple iPhone 15"
4. 对比表
| 查询类型 | 是否分词 | 适用字段类型 | 匹配规则 | 示例场景 |
|---|---|---|---|---|
| term | 否 | keyword、数值、日期 | 精确匹配 | 搜索品牌等于 Apple |
| match | 是 | text | 分词后匹配任意词条 | 搜索标题包含"iPhone 15" |
5. 面试高分回答模板
Term Query 是精确匹配查询,不分词,适合 keyword、数值、日期类型字段,性能高,常用于 ID、标签、状态等精确匹配场景。
Match Query 是全文搜索查询,会分词并匹配分词后的任意词条,适合 text 类型字段,常用于模糊匹配和全文搜索。例如,
term查询"brand": "Apple"会精确匹配品牌为 Apple 的文档,而match查询"name": "iPhone 15"会分词成["iphone", "15"]并匹配包含任意词条的文档。
如何实现模糊搜索(Fuzzy Search)?
1. 定义
模糊搜索(Fuzzy Search) 是一种允许搜索词与索引中的词条存在一定差异的搜索方式,常用于拼写错误、输入不完整、同音词 等场景。
在 Elasticsearch 中,模糊搜索主要依赖 fuzziness 参数,它基于 Levenshtein 编辑距离(即两个字符串之间的最少编辑操作次数)。
2. 原理
- 编辑距离(Levenshtein Distance)
衡量两个字符串的相似度,计算需要多少次插入、删除、替换才能将一个字符串变成另一个。 - fuzziness 参数
控制允许的最大编辑距离:fuzziness: 0→ 精确匹配fuzziness: 1→ 允许 1 次编辑fuzziness: 2→ 允许 2 次编辑
3. 实现方式
Elasticsearch 中实现模糊搜索的常用方式:
- Match Query + fuzziness
- Fuzzy Query(更底层的模糊匹配)
- Wildcard Query(通配符匹配,性能较差)
- Regexp Query(正则匹配,性能较差)
4. 示例及结果
假设索引中有以下文档:
bash
{ "name": "Elasticsearch" }
{ "name": "Elastic Search" }
{ "name": "Elasticsarch" }
{ "name": "Elasticserch" }方式 1:Match Query + fuzziness
bash
GET /products/_search
{
"query": {
"match": {
"name": {
"query": "Elastcisearch",
"fuzziness": 2
}
}
}
}结果:
- 匹配
"Elasticsearch"、"Elastic Search"、"Elasticsarch"、"Elasticserch" - 因为
fuzziness: 2允许最多 2 次编辑距离
方式 2:Fuzzy Query
bash
GET /products/_search
{
"query": {
"fuzzy": {
"name": {
"value": "Elastcisearch",
"fuzziness": 2
}
}
}
}结果:
- 与方式 1 类似,但
fuzzy是更底层的 API,功能更单一
方式 3:Wildcard Query
bash
GET /products/_search
{
"query": {
"wildcard": {
"name": "Elastic*"
}
}
}结果:
- 匹配所有以
"Elastic"开头的文档 - 缺点:性能差,不适合大数据量
5. 注意事项
- 性能影响:模糊搜索需要计算编辑距离,性能比精确匹配差
- 字段类型 :模糊搜索适合
text类型字段(会分词) - fuzziness 建议值 :一般设置为
1或2,过大可能导致匹配过多无关结果 - 避免滥用:在高并发、大数据量场景下,建议结合前缀匹配或自动补全优化
6. 面试高分回答模板
在 Elasticsearch 中,模糊搜索主要通过 fuzziness 参数 实现,它基于 Levenshtein 编辑距离,允许搜索词与索引词条存在一定差异。
常用方式包括:
match查询 +fuzzinessfuzzy查询(底层 API)wildcard或regexp查询(性能较差)
例如,match查询"Elastcisearch"并设置fuzziness: 2,可以匹配"Elasticsearch"、"Elastic Search"等相似词条。
模糊搜索适合处理拼写错误和输入不完整的场景,但需要注意性能开销。
Elasticsearch 中的分页是如何实现的?
1. 定义
Elasticsearch 的分页是指在查询结果中按页获取数据 ,常用于前端列表展示、数据浏览等场景。
它的核心是通过 from 和 size 参数控制返回的结果范围。
2. 原理
-
from:跳过的文档数量(偏移量) -
size:返回的文档数量(每页大小) -
分页公式:
-
Elasticsearch 会先根据查询条件匹配所有符合的文档,然后在内存中跳过
from条,再返回size条。
3. 实现方式
方式 1:from + size(普通分页)
bash
GET /products/_search
{
"from": 0,
"size": 10,
"query": {
"match_all": {}
}
}- 结果:返回第 1 页(前 10 条)
- 缺点:深度分页性能差,因为需要跳过大量数据
方式 2:Scroll API(深度分页)
- 特点:适合一次性导出大量数据(如批量处理)
- 原理:保持一个快照上下文,滚动获取数据
bash
# 第一次请求
GET /products/_search?scroll=1m
{
"size": 100,
"query": {
"match_all": {}
}
}
# 后续请求
GET /_search/scroll
{
"scroll": "1m",
"scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAA..."
}- 缺点:占用集群资源,不适合实时分页
方式 3:Search After(实时深度分页)
- 特点 :基于排序字段的游标分页,性能优于
from+size - 原理:使用上一页最后一条数据的排序值作为下一页的起点
bash
GET /products/_search
{
"size": 10,
"query": {
"match_all": {}
},
"sort": [
{ "price": "asc" },
{ "_id": "asc" }
],
"search_after": [5000, "doc_id_123"]
}- 优点:适合实时数据浏览
- 缺点:必须有唯一且稳定的排序字段
4. 示例结果对比
假设有 30 条商品数据,size=10:
| 页码 | from | size | 返回数据范围 |
|---|---|---|---|
| 第 1 页 | 0 | 10 | 1-10 |
| 第 2 页 | 10 | 10 | 11-20 |
| 第 3 页 | 20 | 10 | 21-30 |
5. 性能注意事项
- 深度分页问题 :
from越大,性能越差,因为 ES 需要先取出所有匹配数据再跳过 - 优化建议 :
- 小数据量用
from+size - 大数据量用
search_after或scroll - 尽量限制最大页数
- 使用稳定的排序字段(如
_id)
- 小数据量用
6. 面试高分回答模板
Elasticsearch 的分页主要通过
from和size参数实现,from表示跳过的文档数量,size表示返回的文档数量。普通分页适合小数据量,但深度分页性能差,因为 ES 需要先获取所有匹配数据再跳过。
对于大数据量,可以使用
scrollAPI(批量导出)或search_after(基于排序的游标分页)来优化性能。例如,第 3 页、每页 10 条数据的
from值为(3-1)*10=20,返回第 21-30 条数据。
什么是 Scroll API?它适用于什么场景?
1. 定义
Scroll API 是 Elasticsearch 提供的一种批量获取大量数据 的机制,
它并不是用来做实时分页的,而是用于一次性遍历整个结果集(类似数据库的游标 Cursor)。
2. 原理
- 快照机制 :第一次执行 Scroll 查询时,ES 会创建一个数据快照(snapshot),即使后续数据发生变化,快照中的数据也不会变。
- 游标滚动 :通过
scroll_id标识快照位置,每次请求返回下一批数据,直到取完。 - 保持上下文 :
scroll参数指定快照在内存中保持的时间(如1m表示 1 分钟)。
3. 使用方式
第一次请求(创建快照)
bash
GET /products/_search?scroll=1m
{
"size": 100,
"query": {
"match_all": {}
}
}返回结果中包含:
bash
{
"_scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAA...",
"hits": {
"hits": [
{ "_id": "1", "_source": { "name": "iPhone 15" } },
...
]
}
}**后续请求(滚动获取)**
bash
GET /_search/scroll
{
"scroll": "1m",
"scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAA..."
}- 每次返回下一批数据
- 直到
hits.hits为空,表示数据取完
清理 Scroll 上下文
bash
DELETE /_search/scroll
{
"scroll_id": ["DnF1ZXJ5VGhlbkZldGNoBQAAAAAAA..."]
}- 避免占用内存资源
4. 适用场景
Scroll API 适合:
- 批量导出数据(如全量同步到数据仓库)
- 离线分析(如大数据统计)
- 批量处理任务(如批量更新、批量删除)
不适合:
- 实时分页(因为 Scroll 返回的是快照,不会反映最新数据)
5. 注意事项
- 性能消耗:Scroll 会在内存中保存快照,数据量大时占用资源多
- 快照过期 :
scroll时间到期后,快照会被清理 - 不适合实时数据:快照不会包含创建后的新数据
- 替代方案 :实时深度分页可用
search_after
6. 面试高分回答模板
Scroll API 是 Elasticsearch 用于批量获取大量数据的机制,它通过创建数据快照并使用
scroll_id滚动获取数据,直到遍历完整个结果集。它适合批量导出、离线分析、批量处理等场景,不适合实时分页,因为返回的是快照数据。
使用时要注意内存占用和快照过期问题,实时深度分页建议使用
search_after。
如何在 Elasticsearch 中实现聚合(Aggregation)?
1. 定义
Aggregation(聚合) 是 Elasticsearch 提供的数据分析功能 ,
它可以在搜索的同时,对数据进行分组、统计、计算 ,类似 SQL 中的 GROUP BY、COUNT、AVG 等操作。
2. 原理
- 聚合是在 倒排索引 的基础上,对匹配的文档进行**桶(Bucket)和指标(Metric)**计算。
- Bucket(桶):按条件分组文档(如按品牌分组)
- Metric(指标):对桶内文档计算统计值(如数量、平均值、最大值)
3. 聚合类型
Elasticsearch 聚合主要分为 4 类:
- Metric Aggregations(指标聚合)
- 计算数值统计:
avg、sum、min、max、stats
- 计算数值统计:
- Bucket Aggregations(桶聚合)
- 按条件分组:
terms(类似 SQL GROUP BY)、range、date_histogram
- 按条件分组:
- Pipeline Aggregations(管道聚合)
- 对聚合结果再计算:
derivative、moving_avg
- 对聚合结果再计算:
- Matrix Aggregations(矩阵聚合)
- 多字段矩阵运算(较少用)
4. 实现方式与示例
假设有以下商品数据:
bash
{ "name": "iPhone 15", "brand": "Apple", "price": 8999 }
{ "name": "iPhone 14", "brand": "Apple", "price": 6999 }
{ "name": "Mate 60", "brand": "Huawei", "price": 5999 }
{ "name": "P60", "brand": "Huawei", "price": 4999 }4.1 指标聚合(Metric Aggregation)
需求:计算所有商品的平均价格
bash
GET /products/_search
{
"size": 0,
"aggs": {
"avg_price": {
"avg": { "field": "price" }
}
}
}结果:
bash
"aggregations": {
"avg_price": { "value": 6749 }
}4.2 桶聚合(Bucket Aggregation)
需求:按品牌分组,并统计每组商品数量
bash
GET /products/_search
{
"size": 0,
"aggs": {
"by_brand": {
"terms": { "field": "brand.keyword" }
}
}
}结果:
bash
"aggregations": {
"by_brand": {
"buckets": [
{ "key": "Apple", "doc_count": 2 },
{ "key": "Huawei", "doc_count": 2 }
]
}
}4.3 嵌套聚合(Bucket + Metric)
需求:按品牌分组,并计算每组的平均价格
bash
GET /products/_search
{
"size": 0,
"aggs": {
"by_brand": {
"terms": { "field": "brand.keyword" },
"aggs": {
"avg_price": { "avg": { "field": "price" } }
}
}
}
}结果:
bash
"aggregations": {
"by_brand": {
"buckets": [
{ "key": "Apple", "doc_count": 2, "avg_price": { "value": 7999 } },
{ "key": "Huawei", "doc_count": 2, "avg_price": { "value": 5499 } }
]
}
}4.4 日期直方图聚合(Date Histogram)
需求:按月份统计销售数量
bash
GET /sales/_search
{
"size": 0,
"aggs": {
"sales_over_time": {
"date_histogram": {
"field": "sale_date",
"calendar_interval": "month"
}
}
}
}5. 注意事项
size: 0:聚合查询时通常不需要返回文档,只返回聚合结果- 字段类型 :
terms聚合字段必须是keyword或未分词字段 - 性能优化 :
- 限制
terms聚合的size - 使用
composite聚合做分页分组 - 对大数据量聚合可用
doc_values优化
- 限制
6. 面试高分回答模板
Elasticsearch 的聚合功能类似 SQL 的
GROUP BY和聚合函数,分为 指标聚合 (如avg、sum)、桶聚合 (如terms、range)、管道聚合 和 矩阵聚合 。聚合的核心是先将文档分到不同的桶(Bucket),再在桶内计算指标(Metric)。
例如,按品牌分组并计算平均价格,可以用
terms聚合品牌,再嵌套avg聚合价格。聚合适合做统计分析,但要注意字段类型和性能优化。
Elasticsearch 中的 Highlight 高亮搜索是如何实现的?
1. 定义
Highlight(高亮搜索) 是 Elasticsearch 提供的一种功能,用于在搜索结果中标记匹配的关键词 ,通常用于前端展示搜索结果时,让用户快速定位匹配内容。
它会在返回的 _source 数据之外,额外返回一个 highlight 字段,包含带标记的文本片段。
2. 原理
- 匹配词定位:在查询阶段,ES 会记录匹配的词条位置。
- 文本片段提取:根据匹配位置,从原文中截取一定长度的片段。
- 标记包装 :用指定的标签(如
<em>)包裹匹配词。 - 返回结果 :高亮内容放在
highlight字段中,原文不受影响。
3. 实现方式
基本用法
bash
GET /products/_search
{
"query": {
"match": {
"description": "iPhone"
}
},
"highlight": {
"fields": {
"description": {}
}
}
}结果:
bash
"hits": {
"hits": [
{
"_source": { "description": "Apple iPhone 15 Pro Max" },
"highlight": {
"description": [
"Apple <em>iPhone</em> 15 Pro Max"
]
}
}
]
}自定义标签
bash
"highlight": {
"pre_tags": ["<strong>"],
"post_tags": ["</strong>"],
"fields": {
"description": {}
}
}结果:
bash
"description": [
"Apple <strong>iPhone</strong> 15 Pro Max"
]多字段高亮
bash
"highlight": {
"fields": {
"title": {},
"description": {}
}
}控制片段长度
bash
"highlight": {
"fields": {
"description": {
"fragment_size": 50,
"number_of_fragments": 3
}
}
}fragment_size:每个高亮片段的最大字符数number_of_fragments:返回的片段数量
4. 注意事项
- 字段类型 :高亮通常用于
text类型字段(会分词) - 性能影响:高亮需要额外的文本分析,数据量大时会增加查询耗时
- 标签安全:前端渲染时要注意 HTML 转义,防止 XSS
- 高亮器类型 :
plain:简单高亮,性能好fvh(Fast Vector Highlighter):适合大文本,需开启term_vectorunified(默认):综合性能与准确性
5. 面试高分回答模板
Elasticsearch 的 Highlight 功能用于在搜索结果中标记匹配的关键词,提升用户体验。
它的原理是:在查询阶段记录匹配词位置 → 截取片段 → 用标签包裹 → 返回到
highlight字段。常用配置包括自定义标签、控制片段长度、多字段高亮等。
例如,搜索
"iPhone"并高亮description字段,可以返回"Apple <em>iPhone</em> 15 Pro Max"。高亮适合
text类型字段,但在大数据量场景下要注意性能优化。
如何在 Elasticsearch 中实现多字段搜索?
1. 定义
多字段搜索 是指在一次查询中,同时在多个字段上匹配用户输入的关键词,
常用于全文搜索 、跨字段匹配 、综合评分排序 等场景。
例如,用户搜索 "iPhone" 时,希望在 title、description、brand 等字段中都能匹配到。
2. 原理
- Elasticsearch 会在多个字段上分别执行匹配,然后将结果合并 并计算相关性评分 (
_score)。 - 可以控制:
- 匹配方式(是否必须全部字段匹配)
- 字段权重(某些字段匹配更重要)
- 分词规则(不同字段可能有不同的分词器)
3. 常用实现方式
方式 1:multi_match 查询(最常用)
bash
GET /products/_search
{
"query": {
"multi_match": {
"query": "iPhone",
"fields": ["title", "description", "brand"]
}
}
}- 在
title、description、brand三个字段中搜索"iPhone"
方式 2:multi_match + 字段权重
bash
GET /products/_search
{
"query": {
"multi_match": {
"query": "iPhone",
"fields": ["title^3", "description", "brand^2"]
}
}
}title^3表示title字段的权重是 3 倍brand^2表示brand字段的权重是 2 倍- 这样可以让标题匹配的结果排在更前面
方式 3:multi_match + type 控制匹配策略
bash
GET /products/_search
{
"query": {
"multi_match": {
"query": "iPhone",
"fields": ["title", "description"],
"type": "best_fields"
}
}
}常用 type:
- best_fields(默认):取匹配度最高的字段评分
- most_fields:多个字段匹配时累加评分
- cross_fields:跨字段匹配(适合拆分的词在不同字段中)
- phrase / phrase_prefix:短语匹配
方式 4:bool 查询组合
bash
GET /products/_search
{
"query": {
"bool": {
"should": [
{ "match": { "title": "iPhone" } },
{ "match": { "description": "iPhone" } },
{ "match": { "brand": "iPhone" } }
]
}
}
}should表示任意字段匹配即可- 可以灵活组合不同字段的查询方式
4. 示例结果
假设有以下数据:
bash
{ "title": "Apple iPhone 15", "description": "Latest smartphone from Apple", "brand": "Apple" }
{ "title": "Huawei Mate 60", "description": "Flagship phone from Huawei", "brand": "Huawei" }搜索 "iPhone":
multi_match会在title、description、brand中查找- Apple iPhone 15 会得到最高
_score - Huawei Mate 60 不会匹配
5. 注意事项
- 字段类型 :多字段搜索通常用于
text类型字段(会分词) - 权重设置:合理设置字段权重可以优化排序
- 性能优化 :
- 限制搜索字段数量
- 使用
keyword类型字段做精确匹配
- 分词器一致性:不同字段分词规则不一致可能影响匹配效果
6. 面试高分回答模板
在 Elasticsearch 中,多字段搜索可以通过
multi_match查询实现,它会在多个字段上执行匹配并合并评分。可以通过
fields参数指定字段,并用^设置权重,例如title^3表示标题匹配更重要。
multi_match的type参数可以控制匹配策略,如best_fields、most_fields、cross_fields等。也可以用
bool查询组合多个match查询实现更灵活的多字段搜索。多字段搜索适合全文检索和跨字段匹配,但要注意字段类型、权重和性能优化。
如何在 Elasticsearch 中实现权重(Boost)调整?
1. 定义
Boost(权重调整) 是 Elasticsearch 中用于影响相关性评分 _score 的机制。
通过给某些字段、查询条件或文档设置更高的权重,可以让它们在搜索结果中排名更靠前 。
Boost 值通常是一个 大于 1 的浮点数(也可以小于 1 来降低权重)。
2. 原理
-
Elasticsearch 的相关性评分基于 BM25 算法(改进版 TF-IDF)。
-
Boost 会在计算
_score时乘以一个系数:final_score=BM25_score×boostfinal_score=BM25_score×boost
-
Boost 可以作用在:
- 字段级别(某字段匹配更重要)
- 查询级别(某个条件更重要)
- 文档级别(某些文档整体更重要)
3. 常用实现方式
方式 1:字段级 Boost(multi_match)
bash
GET /products/_search
{
"query": {
"multi_match": {
"query": "iPhone",
"fields": ["title^3", "description", "brand^2"]
}
}
}title^3表示标题匹配的权重是 3 倍brand^2表示品牌匹配的权重是 2 倍
方式 2:查询级 Boost(match + boost)
bash
GET /products/_search
{
"query": {
"bool": {
"should": [
{ "match": { "title": { "query": "iPhone", "boost": 3 } } },
{ "match": { "description": "iPhone" } }
]
}
}
}boost直接作用在某个查询条件上
方式 3:文档级 Boost(function_score)
bash
GET /products/_search
{
"query": {
"function_score": {
"query": {
"match": { "title": "iPhone" }
},
"functions": [
{
"filter": { "term": { "brand.keyword": "Apple" } },
"weight": 2
}
],
"boost_mode": "multiply"
}
}
}- 对品牌为 Apple 的文档整体加权 2 倍
boost_mode控制权重与原始_score的结合方式(multiply、sum、replace等)
方式 4:索引时 Boost(已不推荐)
- 旧版本 ES 支持在索引文档时设置字段 Boost,但现在推荐在查询阶段调整权重,因为索引时 Boost 是固定的,无法动态调整。
4. 示例结果
假设有以下数据:
bash
{ "title": "Apple iPhone 15", "description": "Latest smartphone from Apple", "brand": "Apple" }
{ "title": "Huawei Mate 60", "description": "Flagship phone from Huawei", "brand": "Huawei" }搜索 "iPhone":
- 如果
title^3,则标题匹配的 Apple iPhone 15 会得到更高_score - Huawei Mate 60 不匹配,排名靠后
5. 注意事项
- Boost 值过大可能导致结果排序失衡
- 字段类型 :Boost 通常用于
text类型字段(会分词) - 性能影响 :Boost 本身不会显著影响性能,但复杂的
function_score可能增加计算开销 - 调优建议 :
- 先用默认评分查看结果,再逐步调整 Boost
- 结合业务场景设置权重(如标题 > 描述 > 标签)
6. 面试高分回答模板
在 Elasticsearch 中,Boost 是用于调整相关性评分的系数,可以作用在字段、查询条件或文档上。
字段级 Boost 可以在
multi_match中用^设置权重,查询级 Boost 可以在match中用boost参数,文档级 Boost 可以用function_score根据条件加权。例如,
title^3表示标题匹配的权重是 3 倍,这样标题匹配的结果会排在更前面。Boost 调整要结合业务场景,避免权重过大导致排序失衡。
三、集群与性能类
Master 节点的作用是什么?
1. 定义
在 Elasticsearch 集群中,Master 节点 是负责集群管理和元数据维护 的节点。
它不直接参与数据的存储和搜索,而是负责集群的"大脑"功能,确保整个集群的稳定运行。
2. 核心职责
Master 节点主要负责 集群级别的管理任务,包括:
-
集群状态管理
- 维护集群的元数据(节点列表、索引信息、分片分配等)
- 将最新的集群状态同步给所有节点
-
节点管理
- 监控节点的加入和退出
- 触发分片的重新分配(Reallocation)
-
索引管理
- 创建、删除索引
- 更新索引的映射(Mapping)和设置(Settings)
-
分片分配
- 决定主分片和副本分片分配到哪些节点
- 在节点故障时重新分配分片
-
选举机制
- 集群启动或 Master 节点故障时,通过 Zen Discovery 选举新的 Master 节点
3. 工作流程
- 集群启动 → 节点互相发现(Discovery)
- Master 选举 → 选出一个 Master 节点
- Master 分配分片 → 将主分片和副本分片分配到各个 Data 节点
- 集群运行中 :
- 如果有新节点加入 → Master 更新集群状态并分配分片
- 如果节点宕机 → Master 触发分片迁移
- 集群状态变更 → Master 将最新状态广播给所有节点
4. 注意事项
- Master 节点不一定存数据 :可以通过
node.master: true、node.data: false配置成专用 Master 节点,提升稳定性 - 建议至少 3 个 Master-eligible 节点:保证选举时能有多数派(Quorum)
- Master 节点故障 :
- 如果没有可选 Master 节点,集群会进入 red 状态
- 数据节点仍可提供部分查询,但无法进行索引创建、分片迁移等操作
- 选举条件 :
discovery.zen.minimum_master_nodes(7.x 之前)- 7.x 之后自动处理多数派选举
5. 面试高分回答模板
在 Elasticsearch 中,Master 节点是集群的大脑,负责集群状态管理、节点管理、索引管理和分片分配等任务。
它不直接处理数据读写,而是维护元数据并协调集群运行。
Master 节点故障时,集群会通过选举机制产生新的 Master 节点。
为了保证高可用,建议部署至少 3 个 Master-eligible 节点,并在生产环境中使用专用 Master 节点配置(
node.master: true,node.data: false)。
如何设置分片和副本的数量?
1. 定义
在 Elasticsearch 中,分片(Shard) 和 副本(Replica) 是数据存储的基本单元:
- 主分片(Primary Shard):存储原始数据,负责写入。
- 副本分片(Replica Shard):主分片的拷贝,负责容错和分担查询压力。
2. 设置方式
创建索引时设置
分片和副本数量是在索引创建时 通过 number_of_shards 和 number_of_replicas 设置的:
bash
PUT /my_index
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}number_of_shards: 主分片数量(创建后不可更改)number_of_replicas: 每个主分片的副本数量(可动态调整)
创建后调整副本数量
bash
PUT /my_index/_settings
{
"number_of_replicas": 2
}- 这里将副本数改为 2,表示每个主分片有 2 个副本
3. 示例
假设:
- 主分片数:
3 - 副本数:
1
那么:
- 总分片数 = 主分片数 × (1 + 副本数)
=3×(1+1)=6=3×(1+1)=6 个分片 - 分布方式(假设有 3 个节点):
- 每个节点存储 2 个分片(主分片或副本分片)
4. 调整规则
- 主分片数 :只能在新建索引时设置,后续无法直接修改(除非重建索引)
- 副本数:可随时调整,ES 会自动在集群中重新分配副本
- 副本数为 0:没有容错能力,但写入性能更高
- 副本数 ≥ 1:支持高可用和负载均衡查询
5. 注意事项
- 分片过多 :
- 会增加集群管理开销(每个分片都是一个 Lucene 实例)
- 建议单个分片大小控制在 10GB~50GB(视业务情况)
- 分片过少 :
- 可能导致后续无法水平扩展
- 副本作用 :
- 容错:主分片宕机时,副本可提升为主分片
- 查询加速:副本可分担查询请求
- 规划建议 :
- 预估数据量 → 计算分片大小 → 决定分片数
- 生产环境建议至少 1 个副本
6. 面试高分回答模板
在 Elasticsearch 中,分片和副本数量通过
number_of_shards和number_of_replicas设置。主分片数只能在索引创建时设置,副本数可以随时调整。
例如,
number_of_shards: 3,number_of_replicas: 1表示有 3 个主分片,每个主分片有 1 个副本,总共 6 个分片。分片数影响扩展能力和性能,副本数影响容错和查询性能,生产环境建议至少 1 个副本,并合理规划分片大小。
Elasticsearch 的写入流程是怎样的?
1. 定义
Elasticsearch 的写入流程 是指从客户端发送写入请求,到数据最终持久化到磁盘并对外可查询的全过程。
它涉及 路由、分片、主副本同步、刷新(refresh) 等关键环节。
2. 写入步骤流程
步骤 1:客户端发送请求
- 客户端通过 REST API 或 SDK 发送写入请求(
index、update、delete)。 - 请求可以发送到集群中的任意节点(协调节点)。
步骤 2:协调节点路由请求
-
协调节点根据文档的
_id和索引的分片数,使用公式计算目标主分片:
-
将请求转发到对应的主分片所在节点。
步骤 3:主分片写入
- 主分片所在节点执行写入操作:
- 将数据写入 内存缓冲区(Indexing Buffer)
- 同时写入 事务日志(Translog),用于故障恢复
步骤 4:副本分片同步
- 主分片将写入请求转发给所有副本分片所在节点
- 副本分片执行相同的写入操作(内存缓冲区 + Translog)
步骤 5:确认写入成功
- 当主分片和所有副本分片都写入成功后,主分片返回成功响应给协调节点
- 协调节点再返回给客户端
步骤 6:刷新(Refresh)
- 默认每隔 1 秒 ,ES 会执行一次
refresh:- 将内存缓冲区的数据写入 Lucene 段文件(Segment)
- 新数据变为可搜索
- 也可以手动调用:
bash
POST /my_index/_refresh步骤 7:持久化(Flush)
- 默认每隔 30 分钟 或 Translog 太大时,执行一次
flush:- 清空 Translog
- 将数据完全持久化到磁盘
3. 写入流程示意
客户端 → 协调节点 → 主分片 → 副本分片 → 返回成功 → 定时刷新 → 持久化
4. 注意事项
- 写入延迟可搜索性 :数据写入后不是立即可搜索,需要等到
refresh执行 - 副本数影响写入性能:副本越多,写入延迟越高
- 批量写入优化 :使用
_bulkAPI 可以减少网络开销 - Translog 作用:保证数据在节点宕机时可恢复
- 路由优化 :可以使用
routing参数将相关数据写入同一分片,减少跨分片查询
5. 面试高分回答模板
Elasticsearch 的写入流程是:客户端发送请求到协调节点 → 协调节点根据
_id路由到目标主分片 → 主分片写入内存缓冲区和事务日志 → 同步到副本分片 → 所有分片确认成功后返回响应 → 定时刷新使数据可搜索 → 定时持久化到磁盘。写入性能受副本数量、刷新频率、批量写入等因素影响,生产环境中可以通过调整
refresh_interval和使用_bulkAPI 来优化。
Elasticsearch 的搜索流程是怎样的?
1. 定义
Elasticsearch 的搜索流程 是指从客户端发起查询,到集群返回排序后的结果的全过程。
它采用 分布式并行搜索 ,并通过 两阶段(Query + Fetch) 来完成。
2. 两阶段搜索流程
阶段 1:Query Phase(查询阶段)
-
客户端发送请求
- 请求可以发送到集群中的任意节点(该节点称为协调节点)。
-
协调节点广播查询
- 协调节点将查询请求发送到所有包含相关分片的节点(主分片和副本分片都可以参与查询)。
-
分片本地查询
- 每个分片在本地执行查询(Lucene 搜索),计算匹配文档的
_score。 - 每个分片只返回Top N(例如前 10 条)匹配结果的文档 ID 和评分,不返回完整文档内容。
- 每个分片在本地执行查询(Lucene 搜索),计算匹配文档的
-
协调节点合并结果
- 协调节点收集所有分片的 Top N 结果,合并并重新排序,得到全局 Top N 文档 ID。
阶段 2:Fetch Phase(取回阶段)
-
协调节点请求文档内容
- 协调节点根据全局排序结果,向对应分片请求文档的完整内容。
-
分片返回文档
- 分片将文档内容返回给协调节点。
-
协调节点返回给客户端
- 协调节点将最终排序好的完整文档列表返回给客户端。
3. 搜索流程示意
客户端 → 协调节点 → 广播查询 → 分片本地搜索 → 返回Top N ID → 合并排序 → 请求文档内容 → 返回结果
4. 示例
假设:
- 索引有 3 个主分片,每个分片有 1 个副本
- 客户端请求:
GET /products/_search?q=iPhone&size=5
执行过程:
- 协调节点将查询发送到 6 个分片(3 主 + 3 副)
- 每个分片返回本地 Top 5 的文档 ID 和
_score - 协调节点合并所有分片的结果,得到全局 Top 5
- 协调节点向对应分片请求这 5 条文档的完整内容
- 返回给客户端
5. 注意事项
- 副本分片参与查询:可以分担查询压力,提高并发性能
- 分片数量影响性能:分片过多会增加合并开销
- 深度分页性能差 :
from + size大时,协调节点需要从每个分片取更多数据再合并- 解决方案:使用
search_after或scroll
- 解决方案:使用
- 查询优化 :
- 使用
filter代替must来减少评分计算 - 控制返回字段(
_source)减少网络传输
- 使用
6. 面试高分回答模板
Elasticsearch 的搜索流程分为两个阶段:
Query Phase :协调节点将查询请求广播到所有相关分片,每个分片执行本地搜索并返回 Top N 文档 ID 和评分;协调节点合并并全局排序这些结果。
Fetch Phase :协调节点根据排序结果向分片请求文档内容,并返回给客户端。副本分片可以参与查询以提高性能,深度分页会导致性能下降,建议使用
search_after或scroll优化。
什么是路由(Routing)?它的作用是什么?
1. 定义
在 Elasticsearch 中,路由(Routing) 是一种分片定位机制 ,用于决定某个文档应该存储到哪个主分片 。
它的核心是通过一个路由值 (默认是文档的 _id)计算分片编号,从而将数据分布到不同分片。
2. 原理
Elasticsearch 使用以下公式来确定文档所属分片:
shard_number=hash(routing_value)mod number_of_primary_shards
- routing_value :路由值(默认是
_id,也可以自定义) - number_of_primary_shards:主分片数量(索引创建时确定)
3. 作用
-
分片定位
- 确定文档写入时的目标主分片
- 确定查询时需要访问的分片(减少跨分片查询)
-
性能优化
- 如果查询只针对某个路由值,可以直接定位到对应分片,减少查询范围,提高性能
-
数据分组
- 可以将同一业务实体的数据(如同一个用户的所有订单)路由到同一个分片,方便聚合和查询
4. 示例
默认路由(使用 _id)
bash
PUT /orders/_doc/1
{
"user_id": 1001,
"product": "iPhone"
}- 路由值 =
_id=1 - 通过公式计算分片编号,存储到对应主分片
自定义路由
bash
PUT /orders/_doc/1?routing=1001
{
"user_id": 1001,
"product": "iPhone"
}- 路由值 =
1001(用户 ID) - 所有
user_id=1001的订单都会存储到同一个分片 - 查询时也需要指定相同的路由值:
bash
GET /orders/_search?routing=1001
{
"query": {
"match": { "user_id": 1001 }
}
}- 这样只会查询一个分片,性能更高
5. 注意事项
- 主分片数固定:路由计算依赖主分片数,主分片数在索引创建后不可更改
- 查询必须指定相同路由值:否则无法保证只查一个分片
- 路由值分布要均匀:避免数据倾斜(某个分片数据过多)
- 批量写入时 :可以通过
routing参数减少跨分片写入
6. 面试高分回答模板
在 Elasticsearch 中,路由(Routing)是用于确定文档所属主分片的机制,默认使用文档的
_id作为路由值,也可以自定义。路由值通过
hash(routing_value) mod number_of_primary_shards计算分片编号。自定义路由可以将相关数据存储到同一分片,从而减少跨分片查询,提高性能,但需要注意数据倾斜问题。
如何避免 Elasticsearch 的热点分片问题?
1. 定义
热点分片(Hot Shard) 指的是某个分片的写入或查询压力远高于其他分片,导致该分片所在节点负载过高,从而影响整个集群性能。
2. 原因
常见导致热点分片的原因:
- 路由值不均匀
- 自定义
routing时,某些路由值对应的数据量特别大
- 自定义
- 时间序列数据集中写入
- 日志、监控等场景中,所有新数据都写入到最新的分片
- 分片数量过少
- 数据集中到少量分片,无法分散负载
- 查询集中在某个分片
- 业务查询条件导致只访问某个分片
3. 解决方案
方案 1:增加分片数量
- 在索引创建时合理设置
number_of_shards,让数据分布更均匀 - 注意:主分片数创建后不可更改,需提前规划
方案 2:优化路由策略
- 避免使用单一字段作为路由值(如用户 ID),可以使用复合路由值:
bash
routing_value = user_id + "_" + random_suffix- 这样同一用户的数据会分散到多个分片
方案 3:时间序列索引分拆
- 对日志、监控等时间序列数据,使用按时间创建索引(Index per day/week)
- 结合 Index Lifecycle Management (ILM) 自动管理旧索引
方案 4:使用索引模板 + 别名轮转
- 创建多个索引,通过别名写入,定期轮换别名指向新的索引
- 这样写入压力会分散到多个分片
方案 5:查询优化
- 对查询集中在某个分片的情况,优化业务查询条件,让查询分布更均匀
- 使用
routing精确定位分片,减少跨分片查询
4. 注意事项
- 分片过多也有问题:会增加集群管理开销(每个分片都是一个 Lucene 实例)
- 路由值分布要均匀:避免数据倾斜
- 时间序列场景:热点分片几乎不可避免,需要通过索引轮转来缓解
- 监控集群负载 :使用
_cat/shards和_cat/nodes查看分片大小和节点负载
5. 面试高分回答模板
Elasticsearch 的热点分片问题是指某个分片的写入或查询压力远高于其他分片,导致节点负载不均衡。
主要原因包括路由值不均匀、时间序列数据集中写入、分片数量过少等。
解决方案包括:合理规划分片数量、优化路由策略(如复合路由值)、按时间拆分索引、使用索引别名轮转、优化查询条件等。
在生产环境中,还需要监控分片负载并结合 ILM 自动管理索引。
Elasticsearch 的性能优化有哪些方法?
1. 性能优化分类
Elasticsearch 的性能优化可以分为 写入优化 、查询优化 、集群架构优化 三大类:
- 写入优化 → 提高数据索引速度,减少写入延迟
- 查询优化 → 提高搜索响应速度,减少资源消耗
- 架构优化 → 提高集群稳定性和可扩展性
2. 写入优化方法
| 方法 | 说明 | 示例 |
|---|---|---|
| 批量写入 | 使用 _bulk API 减少网络开销 |
POST /_bulk |
| 关闭自动刷新 | 增加 refresh_interval,减少频繁刷新 |
"refresh_interval": "30s" |
| 减少副本数 | 写入阶段将 number_of_replicas 设为 0,完成后再增加 |
PUT /index/_settings |
| 禁用不必要的字段存储 | 关闭 _source 或不需要的字段存储 |
"store": false |
| 使用合适的分片数 | 避免分片过多或过少 | 创建索引时合理设置 |
3. 查询优化方法
| 方法 | 说明 | 示例 |
|---|---|---|
| 使用 filter 代替 must | filter 不计算评分,速度更快 | "filter": { "term": { "status": "active" } } |
| 限制返回字段 | 使用 _source 控制返回字段 |
"_source": ["id", "name"] |
| 避免深度分页 | 使用 search_after 或 scroll |
POST /index/_search |
| 预热查询 | 使用 request_cache 缓存结果 |
"request_cache": true |
| 路由查询 | 使用 routing 精确定位分片 |
GET /index/_search?routing=123 |
4. 集群架构优化方法
| 方法 | 说明 | 示例 |
|---|---|---|
| 冷热分离 | 热节点存储近期数据,冷节点存储历史数据 | 使用 ILM 策略 |
| 节点角色分离 | 专用 master 节点、数据节点、协调节点 | node.roles 配置 |
| 监控与告警 | 使用 _cat API 或 Kibana 监控分片和节点负载 |
_cat/shards |
| 避免热点分片 | 优化路由值分布,按时间拆分索引 | routing 参数 |
| 定期合并段文件 | 使用 force_merge 减少段数量 |
POST /index/_forcemerge |
5. 注意事项
- 分片规划要提前:主分片数创建后不可更改
- 副本数影响写入性能:副本越多,写入延迟越高
- 刷新频率影响可搜索性 :
refresh_interval太大可能导致数据延迟可查 - 深度分页要避免:会导致协调节点内存和 CPU 压力大
- 监控是关键:性能优化必须结合监控数据进行
6. 面试高分回答模板
Elasticsearch 的性能优化可以从写入、查询和架构三个方面入手。
写入优化包括批量写入、调整
refresh_interval、减少副本数、关闭不必要的字段存储等;查询优化包括使用 filter 代替 must、限制返回字段、避免深度分页、使用路由查询等;
架构优化包括冷热分离、节点角色分离、监控分片负载、避免热点分片、定期合并段文件等。
在生产环境中,性能优化必须结合业务场景和监控数据进行动态调整。
如何处理 Elasticsearch 的慢查询?
1. 定义
慢查询(Slow Query) 指的是 Elasticsearch 查询响应时间明显高于预期,通常会影响用户体验或导致系统超时。
ES 提供了 慢查询日志(Slow Log) 来帮助定位问题。
2. 常见原因
- 深度分页
- 使用
from + size获取大量数据,导致协调节点和分片返回大量结果再合并
- 使用
- 查询条件复杂
- 多层嵌套、正则匹配、通配符查询等
- 未使用过滤
- 所有条件都计算
_score,增加 CPU 负载
- 所有条件都计算
- 分片过多或数据分布不均
- 查询需要跨多个分片,增加合并开销
- 字段未建立合适的映射
- 例如 keyword 类型未建立索引,导致全表扫描
- 硬件瓶颈
- 节点 CPU、内存、磁盘 IO 压力过高
3. 排查步骤
步骤 1:开启慢查询日志
bash
PUT /my_index/_settings
{
"index.search.slowlog.threshold.query.warn": "2s",
"index.search.slowlog.threshold.query.info": "1s",
"index.search.slowlog.threshold.fetch.warn": "2s",
"index.search.slowlog.threshold.fetch.info": "1s"
}- Query 阶段:查询匹配文档 ID 的耗时
- Fetch 阶段:获取文档内容的耗时
步骤 2:分析查询语句
- 使用
_explainAPI 查看查询执行计划 - 检查是否有不必要的评分计算、通配符、正则等
步骤 3:查看分片与节点负载
bash
GET /_cat/shards?v
GET /_cat/nodes?v- 检查是否存在热点分片或节点负载过高
步骤 4:查看字段映射
bash
GET /my_index/_mapping- 确认查询字段类型是否合适(keyword、text、numeric)
4. 优化方法
查询优化
- 使用 filter 代替 must (filter 不计算
_score) - 限制返回字段 :
_source只返回必要字段 - 避免深度分页 :使用
search_after或scroll - 预热查询 :开启
request_cache - 路由查询 :使用
routing精确定位分片
索引优化
- 合理分片数:避免分片过多或过少
- 字段映射优化:keyword 用于精确匹配,text 用于全文检索
- 关闭不必要的字段索引:减少索引大小
架构优化
- 冷热分离:近期数据放在热节点,历史数据放在冷节点
- 节点角色分离:协调节点、数据节点分开
- 增加硬件资源:CPU、内存、SSD 磁盘
5. 注意事项
- 慢查询优化必须结合 慢查询日志 和 监控数据,不要盲目改配置
- 深度分页是慢查询的常见原因,必须用
search_after或scroll替代 - 复杂查询要考虑拆分成多个简单查询再合并结果
- 索引映射设计阶段就要考虑查询模式,避免后期大规模重建索引
6. 面试高分回答模板
Elasticsearch 的慢查询通常由深度分页、复杂查询条件、分片过多、字段映射不合理等原因引起。
排查步骤包括:开启慢查询日志、分析查询语句、查看分片与节点负载、检查字段映射。
优化方法包括:使用 filter 代替 must、限制返回字段、避免深度分页、合理分片数、优化字段映射、冷热分离、节点角色分离等。
在生产环境中,慢查询优化必须结合慢查询日志和监控数据进行针对性调整。
Elasticsearch 的缓存机制有哪些?
1. 缓存机制分类
Elasticsearch 主要有 三类缓存机制:
| 缓存类型 | 作用 | 适用场景 |
|---|---|---|
| Filter Cache(过滤缓存) | 缓存过滤条件的匹配结果(文档 ID 集合) | 频繁使用的过滤条件 |
| Query Cache(查询缓存 / Request Cache) | 缓存整个查询的结果集 | 频繁执行且结果稳定的查询 |
| Field Data Cache(字段数据缓存) | 缓存字段值到内存,用于排序、聚合 | 排序、聚合操作 |
2. 原理与作用
(1) Filter Cache
- 原理:将过滤条件的匹配结果(文档 ID 集合)缓存到内存
- 作用:避免重复计算过滤条件,提高查询速度
- 特点 :
- 只缓存过滤条件,不缓存评分
- 适合
term、range等过滤查询
- 示例:
bash
{
"query": {
"bool": {
"filter": [
{ "term": { "status": "active" } }
]
}
}
}- 如果
status=active查询频繁出现,ES 会缓存其匹配的文档 ID 集合
(2) Query Cache / Request Cache
- 原理:缓存整个查询的结果集(包括排序后的文档列表)
- 作用:重复执行相同查询时直接返回缓存结果
- 特点 :
- 适合静态数据或不频繁更新的索引
- 对实时更新的索引效果有限
- 开启方式:
bash
{
"query": { "match_all": {} },
"request_cache": true
}(3) Field Data Cache
- 原理:将字段值加载到内存(JVM heap)中,用于排序和聚合
- 作用:加快排序和聚合计算速度
- 特点 :
- 占用大量内存
- 适合 keyword、numeric 类型字段
- 优化建议 :
- 对 text 类型字段使用
doc_values或 keyword 类型 - 控制聚合字段数量,避免内存溢出
- 对 text 类型字段使用
3. 注意事项
- 缓存命中率:缓存只有在查询条件完全相同的情况下才会命中
- 内存占用:Field Data Cache 占用 JVM heap,需监控内存使用
- 实时性影响:缓存可能返回旧数据,适合静态或低更新频率的场景
- 缓存清理:ES 会自动清理不常用的缓存,但在内存紧张时可能影响性能
- 查询优化:使用 filter 查询可以更好地利用 Filter Cache
4. 面试高分回答模板
Elasticsearch 有三种主要缓存机制:
Filter Cache :缓存过滤条件的匹配结果,适合频繁使用的过滤查询;
Query Cache / Request Cache :缓存整个查询结果集,适合静态数据或低更新频率的索引;
Field Data Cache :缓存字段值到内存,用于排序和聚合,适合 keyword 和 numeric 类型字段。使用缓存可以显著提升查询性能,但需要注意内存占用和缓存命中率。
四、运维与优化类
如何监控 Elasticsearch 集群的健康状态?
1. 关键监控指标
在 Elasticsearch 集群健康监控中,需要重点关注以下指标:
| 指标类别 | 关键指标 | 说明 |
|---|---|---|
| 集群健康 | status(green/yellow/red) |
绿色:所有分片正常;黄色:副本未分配;红色:主分片丢失 |
| 节点状态 | 节点数量、角色、负载 | 检查节点是否掉线、负载是否均衡 |
| 分片状态 | 分片数量、分布、大小 | 检查是否存在未分配分片或热点分片 |
| 索引性能 | 写入速率、查询速率、延迟 | 监控索引和搜索的响应时间 |
| 资源使用 | CPU、内存(JVM heap)、磁盘、IO | 防止资源耗尽导致集群不可用 |
| GC 情况 | GC 次数与耗时 | 频繁 GC 可能导致性能下降 |
2. 监控工具与方法
(1) Elasticsearch 内置 API
- 集群健康
GET /_cluster/health
- 节点状态
GET /_cat/nodes?v
- 分片状态
GET /_cat/shards?v
- 索引统计
GET /_stats
(2) Kibana Monitoring
- 在 Kibana 中开启 Stack Monitoring
- 可视化查看集群、节点、索引的健康状态和性能指标
(3) 外部监控工具
- Prometheus + Grafana:采集 ES 指标并可视化
- Elastic APM:监控应用与 ES 的交互性能
- Zabbix / Nagios:传统监控工具,可结合 API 获取 ES 状态
3. 告警机制
- 阈值告警:如集群状态变为 yellow/red、磁盘使用率超过 80%、JVM heap 超过 75%
- 趋势告警:如查询延迟持续升高、写入速率异常下降
- 事件告警:如节点掉线、分片未分配
4. 注意事项
- 磁盘水位限制:ES 默认在磁盘使用率超过 85% 时停止分片分配
- JVM heap 使用率:超过 75% 可能触发频繁 GC
- 分片规划:分片过多会增加管理开销,分片过少可能导致热点分片
- 定期检查慢查询日志:防止查询性能下降
- 监控要覆盖所有节点:包括 master、data、ingest、coordinating 节点
5. 面试高分回答模板
监控 Elasticsearch 集群健康状态需要关注集群健康、节点状态、分片分布、索引性能、资源使用和 GC 情况等指标。
可以通过 Elasticsearch 内置 API(如
_cluster/health、_cat/nodes、_cat/shards)、Kibana Stack Monitoring、Prometheus+Grafana 等工具进行监控。告警机制应包括阈值告警、趋势告警和事件告警,确保在问题发生前及时发现并处理。
在生产环境中,还需要结合磁盘水位限制、JVM heap 使用率和慢查询日志进行综合监控。
如何查看 Elasticsearch 的索引大小?
1. 使用 _cat/indices API(命令行方式)
在终端执行:
curl -X GET "http://localhost:9200/_cat/indices?v"
返回结果示例:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size green open my_index 0x8F3... 5 1 123456 789 1.2gb 600mb
关键字段说明:
- index:索引名称
- docs.count:文档总数
- store.size:索引占用的磁盘空间(包含副本)
- pri.store.size:主分片占用的磁盘空间
如果只想看索引名和大小,可以加参数:
curl -X GET "http://localhost:9200/_cat/indices?h=index,store.size"
2. 在 Kibana 中查看
- 打开 Kibana → Stack Management → Index Management
- 搜索目标索引
- 在索引详情中查看 Store size (磁盘占用)和 Document count(文档数量)
3. 注意事项
- store.size 包含主分片和副本的总占用空间
- 如果索引有多个副本,磁盘占用会成倍增加
- 删除文档不会立即减少磁盘占用,需要等到段合并(
force_merge)后才会释放空间 - 对于时间序列索引,可以结合 ILM(Index Lifecycle Management)自动删除旧索引,减少存储压力
✅ 高效实践 :
在生产环境中,可以定期执行:
curl -s "http://localhost:9200/_cat/indices?h=index,docs.count,store.size" | sort -k3 -h
按索引大小排序,快速定位占用空间最多的索引,方便做容量规划。
如何进行索引的备份与恢复?
1. 原理
Elasticsearch 的备份与恢复是通过 Snapshot & Restore API 实现的。
- Snapshot(快照) :将索引或整个集群的元数据和分片数据保存到一个 仓库(Repository) 中
- Restore(恢复):从快照仓库中读取数据并还原到集群
- 快照是增量的:第一次是全量,之后只保存变化的部分
- 快照是可在线执行的:不会阻塞索引和查询
2. 备份步骤
步骤 1:注册快照仓库
支持多种类型:fs(本地/共享文件系统)、s3、hdfs 等
bash
PUT _snapshot/my_backup
{
"type": "fs",
"settings": {
"location": "/mount/backups/my_backup",
"compress": true
}
}注意:
location必须是所有数据节点都能访问的路径,并且在elasticsearch.yml中配置path.repo
步骤 2:创建快照
bash
PUT _snapshot/my_backup/snapshot_1?wait_for_completion=true
{
"indices": "index_1,index_2",
"ignore_unavailable": true,
"include_global_state": false
}indices:指定要备份的索引(不写则备份全部)ignore_unavailable:忽略不存在的索引include_global_state:是否备份集群全局状态(模板、别名等)
步骤 3:查看快照状态
GET _snapshot/my_backup/_all
3. 恢复步骤
步骤 1:查看可用快照
GET _snapshot/my_backup/_all
步骤 2:恢复快照
bash
POST _snapshot/my_backup/snapshot_1/_restore
{
"indices": "index_1",
"ignore_unavailable": true,
"include_global_state": false,
"rename_pattern": "index_(.+)",
"rename_replacement": "restored_index_$1"
}rename_pattern/rename_replacement:恢复时重命名索引,避免覆盖原索引
4. 注意事项
- 快照仓库必须所有数据节点可访问
- 不能备份到本地节点磁盘(除非是单节点测试环境)
- 快照是增量的,但删除快照不会影响其他快照的数据
- 恢复时索引必须关闭(除非使用重命名方式恢复到新索引)
- 跨版本恢复:只能在相同或兼容版本的 ES 中恢复
- 安全性:生产环境建议使用对象存储(如 S3)并开启访问控制
5. 面试高分回答模板
Elasticsearch 的索引备份与恢复通过 Snapshot & Restore API 实现。
备份步骤包括:注册快照仓库(支持 fs、s3、hdfs 等)、创建快照、查看快照状态;
恢复步骤包括:查看可用快照、执行恢复操作(可重命名索引避免覆盖)。
快照是增量的、可在线执行,但需要保证快照仓库所有节点可访问,并注意跨版本兼容性和安全性。
什么是 Index Lifecycle Management(ILM)?
1. 定义
Index Lifecycle Management(ILM) 是 Elasticsearch 提供的一种 自动化索引管理机制 ,用于根据预设策略自动执行索引的 滚动(rollover)、迁移、优化、删除 等操作,从而减少人工维护成本、优化存储和性能。
2. 作用
- 自动化索引管理:根据时间或文档数量自动创建新索引
- 节省存储空间:自动删除过期索引
- 性能优化:将旧数据迁移到低性能节点(冷热分离)
- 减少人工操作:避免手动管理大量时间序列索引
3. 生命周期阶段
ILM 策略通常包含 四个阶段:
| 阶段 | 作用 | 常见操作 |
|---|---|---|
| Hot(热阶段) | 存储最新数据,支持高频写入和查询 | Rollover(滚动)、分片优化 |
| Warm(温阶段) | 存储不再写入但仍需查询的数据 | 分片合并、迁移到温节点 |
| Cold(冷阶段) | 存储很少访问的数据 | 迁移到冷节点、关闭索引 |
| Delete(删除阶段) | 删除不再需要的数据 | 删除索引 |
4. 配置方法
步骤 1:创建 ILM 策略
bash
PUT _ilm/policy/my_policy
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_size": "50gb",
"max_age": "30d"
}
}
},
"delete": {
"min_age": "90d",
"actions": {
"delete": {}
}
}
}
}
}max_size:索引达到指定大小时滚动max_age:索引达到指定时间时滚动min_age:索引达到指定时间后进入删除阶段
步骤 2:创建索引模板并绑定策略
bash
PUT _template/my_template
{
"index_patterns": ["logs-*"],
"settings": {
"index.lifecycle.name": "my_policy",
"index.lifecycle.rollover_alias": "logs_alias"
}
}步骤 3:使用别名写入数据
bash
POST logs_alias/_doc
{
"message": "test log",
"timestamp": "2025-11-10T17:30:00"
}ILM 会根据策略自动滚动到新索引,例如
logs-000001→logs-000002
5. 注意事项
- 必须使用 rollover alias 才能自动滚动索引
- 冷热分离需要节点角色配置(hot/warm/cold)
- 策略变更不会影响已创建的索引,只影响新索引
- 删除阶段不可恢复,需谨慎设置
- 监控 ILM 执行状态 :
GET _ilm/explain
6. 面试高分回答模板
Index Lifecycle Management(ILM)是 Elasticsearch 的自动化索引管理机制,用于根据策略自动执行索引的滚动、迁移、优化和删除。
生命周期通常分为 Hot、Warm、Cold、Delete 四个阶段,分别对应不同的数据访问频率和存储策略。
配置 ILM 需要创建策略、绑定索引模板、使用 rollover alias 写入数据。
在生产环境中,ILM 可以显著减少人工维护成本,并优化存储和查询性能,但需要注意别名配置、节点角色和删除阶段的不可恢复性。
如何进行索引的滚动(Rollover)?
1. 原理
Rollover(索引滚动) 是 Elasticsearch 提供的一种机制,用于在索引达到一定 大小 、文档数量 或 时间 时,自动或手动创建一个新的索引,并将写入别名指向新索引。
- 旧索引变为只读(可查询)
- 新索引继续接收写入
- 常用于 日志、监控、时间序列数据 管理
2. 前提条件
- 必须使用写入别名(write alias)
- 别名指向当前活跃的索引
- 滚动后别名会自动指向新索引
- 索引命名需符合模式
- 例如:
logs-000001、logs-000002(数字部分固定宽度)
- 例如:
- 索引模板中配置别名(推荐)
- 可结合 ILM 自动滚动,也可手动执行
3. 操作步骤
步骤 1:创建初始索引和别名
bash
PUT logs-000001
{
"aliases": {
"logs_write": {
"is_write_index": true
}
}
}is_write_index: true表示该索引是别名的写入目标
步骤 2:写入数据
bash
POST logs_write/_doc
{
"message": "test log",
"timestamp": "2025-11-10T17:30:00"
}所有写入操作都通过别名
logs_write进行
步骤 3:执行 Rollover
bash
POST logs_write/_rollover
{
"conditions": {
"max_age": "30d",
"max_docs": 1000000,
"max_size": "50gb"
}
}- 条件说明 :
max_age:索引创建时间超过指定天数max_docs:文档数量超过指定值max_size:索引大小超过指定值
- 满足任一条件即触发滚动
步骤 4:查看结果
GET _cat/indices?v
会看到新索引
logs-000002已创建,并且logs_write别名指向它
4. 注意事项
- 别名必须唯一指向一个写入索引
- 旧索引不会自动删除,需配合 ILM 或手动删除
- 滚动条件是"或"关系,满足任一条件就会滚动
- 命名必须有递增数字,否则 Rollover 会失败
- 生产环境建议结合 ILM 自动化,减少人工操作
5. 面试高分回答模板
Elasticsearch 的 Rollover 是一种索引切换机制,用于在索引达到指定大小、文档数或时间时创建新索引,并将写入别名指向新索引。
使用 Rollover 需要先创建带写入别名的初始索引,然后通过
_rolloverAPI 手动或结合 ILM 自动执行滚动。滚动不会删除旧索引,需配合 ILM 或手动清理。
这种机制常用于日志、监控等时间序列数据管理,可以避免单个索引过大导致性能下降。
如何删除旧数据而不影响新数据?
1. 原理
在 Elasticsearch 中,删除旧数据 通常有两种方式:
- 按索引删除 (推荐)
- 针对时间序列数据(如日志、监控数据),直接删除整个旧索引
- 不会影响新索引,因为它们是独立的
- 按查询条件删除文档
- 用
Delete By Query删除符合条件的文档 - 适合非时间序列数据,但会触发段合并,可能影响性能
- 用
2. 方法选择
| 场景 | 推荐方法 | 原因 |
|---|---|---|
| 日志、监控、时间序列数据 | 按索引删除 | 快速、安全,不影响新索引 |
| 混合数据(同一索引包含新旧数据) | Delete By Query | 精确删除旧数据 |
| 自动化清理 | ILM(Index Lifecycle Management) | 按策略自动删除旧索引 |
3. 操作步骤
方法 1:按索引删除(最快)
DELETE /logs-2025.09.01
- 删除整个旧索引,立即释放空间
- 适合按日期命名的索引(如
logs-YYYY.MM.DD)
方法 2:按条件删除文档
bash
POST /my_index/_delete_by_query
{
"query": {
"range": {
"timestamp": {
"lt": "2025-09-01T00:00:00"
}
}
}
}- 删除
timestamp小于指定日期的文档 - 删除后不会立即释放磁盘空间,需要段合并(
force_merge)
方法 3:使用 ILM 自动删除
bash
PUT _ilm/policy/logs_policy
{
"policy": {
"phases": {
"delete": {
"min_age": "90d",
"actions": {
"delete": {}
}
}
}
}
}- 自动删除超过 90 天的索引
- 结合索引模板和 rollover alias 使用
4. 注意事项
- 按索引删除最快,但必须确保新数据在其他索引中
- Delete By Query 会影响性能,建议在低峰期执行
- 删除不会立即释放磁盘空间,需要段合并
- ILM 删除不可恢复,需谨慎设置
- 建议先备份(Snapshot)再删除,防止误删
5. 面试高分回答模板
在 Elasticsearch 中删除旧数据而不影响新数据,推荐使用按索引删除的方式,尤其是时间序列数据,可以直接删除旧索引而不影响新索引的写入与查询。
如果旧数据与新数据混在同一索引中,可以使用
_delete_by_query按条件删除,但需要注意性能影响。在生产环境中,建议结合 ILM 自动化删除旧索引,并在删除前做好快照备份。
如何处理 Elasticsearch 集群的磁盘空间不足问题?
如果磁盘空间不足不及时处理,集群会进入 只读模式 (read-only_allow_delete),导致无法写入数据。
1. 常见原因
- 旧索引占用过多空间(日志、监控数据未清理)
- 副本数过多(副本占用额外磁盘空间)
- 段文件未合并(删除数据后空间未释放)
- 快照仓库占用本地磁盘
- 数据节点磁盘容量不足(硬件限制)
2. 处理方案
| 方案 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 删除旧索引 | 时间序列数据 | 快速释放空间 | 数据不可恢复(需备份) |
| 减少副本数 | 副本占用过多 | 立即减少占用 | 降低容灾能力 |
| 段合并(force merge) | 删除数据后空间未释放 | 释放已删除文档空间 | 会影响性能,需低峰期执行 |
| 扩容磁盘或节点 | 硬件不足 | 根本解决问题 | 成本高 |
| 冷热分离 | 大量历史数据 | 节省热节点空间 | 需额外冷节点 |
3. 操作步骤
步骤 1:查看索引占用空间
GET _cat/indices?v
重点关注 store.size 最大的索引
步骤 2:删除旧索引
DELETE /logs-2025.09.01
删除前建议先做 Snapshot 备份
步骤 3:减少副本数
bash
PUT /my_index/_settings
{
"number_of_replicas": 0
}仅在临时应急时使用,恢复后建议重新设置副本
步骤 4:段合并释放空间
bash
POST /my_index/_forcemerge?max_num_segments=1会占用大量 IO,建议在低峰期执行
步骤 5:扩容磁盘或节点
- 增加数据节点
- 使用更大容量的磁盘
- 结合 ILM 自动删除旧索引,避免再次空间不足
4. 注意事项
- 当磁盘使用率超过 90%,ES 会自动将索引设置为只读
- 删除索引是最快的释放空间方式,但需提前备份
- force merge 会影响性能,必须在低峰期执行
- 扩容是根本解决方案,但需要硬件和预算支持
- 建议设置 磁盘水位阈值 (
cluster.routing.allocation.disk.watermark.low/high)提前告警
5. 面试高分回答模板
当 Elasticsearch 集群磁盘空间不足时,可以通过删除旧索引、减少副本数、段合并、扩容磁盘或节点等方式解决。
删除旧索引是最快的释放空间方法,但需提前做快照备份;减少副本数可以临时缓解压力;段合并可以释放已删除文档的空间,但会影响性能;扩容是根本解决方案。
在生产环境中,建议结合 ILM 自动删除旧索引,并设置磁盘水位阈值提前告警,避免集群进入只读模式。
如何进行跨集群搜索(Cross Cluster Search)?
1. 原理
跨集群搜索(CCS) 允许一个 Elasticsearch 集群(本地集群)直接查询另一个或多个远程集群的数据,就像查询本地索引一样。
- 本地集群通过 远程集群连接 获取数据
- 查询时使用
<remote_cluster_name>:<index_name>语法 - 常用于 多数据中心、环境隔离、日志集中查询
2. 前提条件
- 集群版本兼容(建议相同或兼容版本)
- 网络互通(本地集群能访问远程集群的节点)
- 安全认证配置(如果开启了 X-Pack Security,需要配置证书或 API Key)
- 远程集群必须开启
search.remote.*配置
3. 配置步骤
步骤 1:在本地集群注册远程集群
bash
PUT _cluster/settings
{
"persistent": {
"search.remote.my_remote_cluster.seeds": [
"192.168.10.21:9300",
"192.168.10.22:9300"
]
}
}my_remote_cluster:远程集群的别名seeds:远程集群的节点地址(transport 端口,默认 9300)
步骤 2:验证连接
GET _remote/info
返回远程集群的连接状态和节点信息
步骤 3:执行跨集群搜索
bash
GET my_remote_cluster:logs-2025.11/_search
{
"query": {
"match": {
"message": "error"
}
}
}my_remote_cluster:logs-2025.11表示查询远程集群的logs-2025.11索引- 可以同时查询本地和远程索引:
GET my_remote_cluster:logs-2025.11,local_index/_search
4. 注意事项
- 跨集群搜索是查询功能,不会复制数据
- 性能依赖网络延迟,建议在低延迟网络环境使用
- 安全性:开启 X-Pack Security 时需配置证书或 API Key
- 索引模式匹配 :支持通配符,如
my_remote_cluster:logs-* - 跨集群搜索不支持写入,只能查询
- 远程集群的节点必须是
data节点
5. 面试高分回答模板
Elasticsearch 的跨集群搜索(CCS)允许一个集群直接查询另一个或多个远程集群的数据。
配置步骤包括:在本地集群注册远程集群(指定 seeds 节点)、验证连接、使用
<remote_cluster_name>:<index_name>语法执行查询。CCS 仅支持查询,不会复制数据,性能依赖网络延迟,适合多数据中心或环境隔离场景。
在生产环境中,建议结合安全认证和低延迟网络,确保查询稳定性。
五、高级特性类
什么是 Pipeline?它的作用是什么?
1. 什么是 Pipeline?
在 Elasticsearch 中,Pipeline (通常指 Ingest Pipeline )是一种 数据预处理机制 ,用于在数据写入索引之前 对文档进行自动化处理和转换。
它由一系列 处理器(Processors) 组成,每个处理器按顺序执行特定任务,例如:
- 删除字段
- 提取文本中的值
- 格式化日期
- 添加或修改字段
- 数据丰富(Enrichment)
处理完成后,Elasticsearch 会将转换后的文档写入目标索引或数据流。
2. 作用
Pipeline 的核心作用是让数据在进入 Elasticsearch 之前就变得更干净、更结构化,从而:
- 减少后续查询和分析的复杂度
- 统一数据格式(例如时间戳格式化)
- 自动化数据清洗(去除无用字段、修正错误值)
- 丰富数据内容(添加地理位置、用户信息等)
- 提升索引质量,避免脏数据影响搜索结果
3. 工作原理
- 数据通过 API 或 Beats/Logstash 发送到 Elasticsearch
- 如果指定了
pipeline参数,数据会先进入对应的 Ingest Node - Ingest Node 按顺序执行 Pipeline 中的各个 Processor
- 处理完成后,将文档写入目标索引
4. 示例
创建一个简单的 Pipeline,在写入前删除 debug 字段并格式化 timestamp:
bash
PUT _ingest/pipeline/remove_debug_format_time
{
"description": "Remove debug field and format timestamp",
"processors": [
{
"remove": {
"field": "debug"
}
},
{
"date": {
"field": "timestamp",
"formats": ["yyyy-MM-dd HH:mm:ss"],
"target_field": "@timestamp"
}
}
]
}写入数据时指定 Pipeline:
bash
POST my_index/_doc?pipeline=remove_debug_format_time
{
"message": "User login",
"timestamp": "2025-11-10 17:44:00",
"debug": "temp info"
}写入后,
debug字段会被删除,timestamp会被转换为标准的@timestamp格式。
5. 注意事项
- 必须有 Ingest Node 才能执行 Pipeline
- 高吞吐场景建议使用专用 Ingest 节点,避免影响数据节点性能
- 安全权限 :需要
manage_pipeline集群权限才能创建/修改 Pipeline - 调试 :可用
_simulateAPI 测试 Pipeline 效果 - Pipeline 存储在集群状态中,所有节点都会同步
6. 面试高分回答模板
在 Elasticsearch 中,Pipeline(尤其是 Ingest Pipeline)是一种数据预处理机制,用于在文档写入索引之前执行一系列处理器任务,例如删除字段、格式化日期、提取值或丰富数据。
它的作用是自动化数据清洗和转换,统一数据格式,提升索引质量,从而简化后续查询和分析。
Pipeline 由多个处理器按顺序执行,必须在具有 Ingest 角色的节点上运行,并可通过
_simulateAPI 进行调试。在生产环境中,Pipeline 常与 Beats、Logstash 配合使用,实现端到端的数据处理链路。
什么是 Ingest Node?它的作用是什么?
1. 什么是 Ingest Node?
Ingest Node 是 Elasticsearch 集群中的一种 特殊节点角色 ,它的主要职责是在文档写入索引之前,对数据进行预处理。
- 它会执行 Ingest Pipeline 中定义的各个 Processor(处理器)
- 处理完成后,将数据传递给数据节点进行存储
- 可以与其他节点角色(如
data、master)共存,也可以单独部署
2. 作用
Ingest Node 的核心作用是:
- 数据清洗:删除无用字段、修正错误值
- 数据转换:格式化日期、解析 JSON、提取文本内容
- 数据丰富:添加地理位置、用户信息等额外字段
- 统一数据结构:确保不同来源的数据格式一致
- 减轻客户端负担:让数据处理逻辑在集群内部完成,而不是在发送端处理
3. 工作原理
- 客户端(如 Beats、Logstash、API)发送数据到 Elasticsearch
- 如果请求中指定了
pipeline参数,数据会先进入 Ingest Node - Ingest Node 按顺序执行 Pipeline 中的 Processor
- 处理完成后,将文档交给数据节点进行索引存储
4. 示例
假设我们有一个 Pipeline 用于删除 debug 字段并格式化时间:
bash
PUT _ingest/pipeline/clean_data
{
"description": "Remove debug and format timestamp",
"processors": [
{
"remove": { "field": "debug" }
},
{
"date": {
"field": "timestamp",
"formats": ["yyyy-MM-dd HH:mm:ss"],
"target_field": "@timestamp"
}
}
]
}写入数据时指定 Pipeline:
bash
POST my_index/_doc?pipeline=clean_data
{
"message": "User login",
"timestamp": "2025-11-10 17:44:00",
"debug": "temp info"
}Ingest Node 会执行 Pipeline,删除
debug字段并格式化timestamp,然后再存储到索引。
5. 注意事项
- 必须有 Ingest Node 才能执行 Pipeline
- 高吞吐场景建议部署专用 Ingest 节点,避免影响数据节点性能
- 可以与其他角色共存,但在大规模数据处理场景中建议分离
- 需要
manage_pipeline权限才能创建或修改 Pipeline - 可用
_simulateAPI 测试 Pipeline 效果
6. 面试高分回答模板
Ingest Node 是 Elasticsearch 中负责数据预处理的节点角色,它在文档写入索引之前执行 Ingest Pipeline 中的处理器任务,例如数据清洗、转换和丰富。
它的作用是让数据在进入索引前就变得结构化和干净,从而简化后续查询和分析。
Ingest Node 可以与其他节点角色共存,也可以单独部署,在高吞吐场景中建议使用专用 Ingest 节点以避免性能瓶颈。
如何在 Elasticsearch 中实现同义词搜索?
1. 原理
在 Elasticsearch 中,同义词搜索 是通过 同义词过滤器(synonym filter) 实现的。
- 在 分析器(Analyzer) 中添加同义词过滤器
- 在索引阶段或查询阶段,将词语替换或扩展为同义词集合
- 这样,用户搜索某个词时,可以匹配到它的同义词对应的文档
2. 配置方法
方法 1:索引时扩展同义词(推荐)
在索引阶段就将同义词加入倒排索引,查询时无需额外处理,性能更好。
bash
PUT my_index
{
"settings": {
"analysis": {
"filter": {
"my_synonym_filter": {
"type": "synonym",
"synonyms": [
"tv, television",
"notebook, laptop",
"mobile, cellphone, smartphone"
]
}
},
"analyzer": {
"my_synonym_analyzer": {
"tokenizer": "standard",
"filter": [
"lowercase",
"my_synonym_filter"
]
}
}
}
},
"mappings": {
"properties": {
"product_name": {
"type": "text",
"analyzer": "my_synonym_analyzer"
}
}
}
}方法 2:查询时扩展同义词
适合已有索引,不需要重新索引数据,但查询性能稍差。
bash
POST my_index/_search
{
"query": {
"match": {
"product_name": {
"query": "tv",
"analyzer": "my_synonym_analyzer"
}
}
}
}方法 3:使用同义词文件
如果同义词很多,可以放在文件中(config/synonyms.txt),便于维护:
tv, television notebook, laptop mobile, cellphone, smartphone
然后在过滤器中引用:
bash
"my_synonym_filter": {
"type": "synonym",
"synonyms_path": "synonyms.txt"
}3. 查询示例
假设同义词配置为:
tv, television
当用户搜索 "television" 时,Elasticsearch 会同时匹配 "tv" 的文档。
4. 注意事项
- 索引时扩展性能更好,但修改同义词需要重新索引
- 查询时扩展灵活,但会增加查询开销
- 同义词文件修改后需要关闭并重新打开索引 或重启节点才能生效
- 同义词匹配是单向的 ,需要双向配置才能互相匹配(如
tv, television) - 建议结合 停用词过滤器 避免无意义词扩展
5. 面试高分回答模板
在 Elasticsearch 中,同义词搜索是通过同义词过滤器(synonym filter)实现的,可以在索引阶段或查询阶段扩展词语集合。
索引时扩展性能更好,但修改同义词需要重新索引;查询时扩展灵活,但会增加查询开销。
同义词可以直接在配置中定义,也可以放在外部文件中维护。
在生产环境中,建议使用索引时扩展,并结合停用词过滤器和外部同义词文件,确保搜索结果的准确性和可维护性。
如何在 Elasticsearch 中实现拼写纠错(Spell Correction)?
1. 原理
Elasticsearch 本身没有直接的"自动纠错"功能,但可以通过 Suggest API (建议器)来实现类似拼写纠错的效果。
核心思路:
- 用户输入的词可能拼写错误
- Elasticsearch 使用 Term Suggest 或 Phrase Suggest 根据索引中的词条,给出最可能的正确拼写
- 前端根据建议结果提示用户或自动替换
2. 实现方法
方法 1:Term Suggest(单词级纠错)
适合单个词的拼写纠错。
bash
POST my_index/_search
{
"suggest": {
"text": "televison",
"term_suggestion": {
"term": {
"field": "product_name"
}
}
}
}text:用户输入的可能错误的词field:用于匹配的字段- 返回最接近的词,例如
"television"
方法 2:Phrase Suggest(短语级纠错)
适合多个词的拼写纠错。
bash
POST my_index/_search
{
"suggest": {
"phrase_suggestion": {
"text": "smrt phone",
"phrase": {
"field": "product_name.trigram",
"size": 1,
"gram_size": 3,
"direct_generator": [
{
"field": "product_name.trigram",
"suggest_mode": "always"
}
]
}
}
}
}- 需要在索引中为字段创建 trigram 分词器(三元分词),提高短语匹配的准确度
- 返回最可能的短语,例如
"smart phone"
方法 3:结合 Edge N-gram 实现模糊匹配
适合在搜索时直接匹配相似词,而不是单独纠错。
bash
PUT my_index
{
"settings": {
"analysis": {
"tokenizer": {
"edge_ngram_tokenizer": {
"type": "edge_ngram",
"min_gram": 2,
"max_gram": 10,
"token_chars": ["letter"]
}
},
"analyzer": {
"edge_ngram_analyzer": {
"tokenizer": "edge_ngram_tokenizer",
"filter": ["lowercase"]
}
}
}
},
"mappings": {
"properties": {
"product_name": {
"type": "text",
"analyzer": "edge_ngram_analyzer",
"search_analyzer": "standard"
}
}
}
}- 用户输入
"televison"时,也能匹配"television"
3. 查询示例
假设索引中有 "television",用户输入 "televison":
- Term Suggest 会返回建议:
"television" - Phrase Suggest 会返回建议:
"smart television"(如果短语匹配) - Edge N-gram 会直接匹配到
"television"
4. 注意事项
- Term Suggest 适合单词纠错,性能好
- Phrase Suggest 适合短语纠错,但需要额外分词器支持
- Edge N-gram 会增加索引大小,但能提升模糊匹配体验
- 拼写纠错依赖索引中的词条,如果索引数据不足,建议效果会差
- 在生产环境中,建议结合 同义词过滤器 和 拼写纠错,提升搜索体验
5. 面试高分回答模板
在 Elasticsearch 中,拼写纠错可以通过 Suggest API 实现,包括 Term Suggest(单词级纠错)和 Phrase Suggest(短语级纠错)。
Term Suggest 适合单词纠错,性能好;Phrase Suggest 适合短语纠错,需要 trigram 分词器支持。
另外,可以使用 Edge N-gram 分词器实现模糊匹配,让用户输入的近似词也能匹配到正确结果。
在生产环境中,建议结合同义词过滤器和拼写纠错,确保搜索结果的准确性和用户体验。
如何在 Elasticsearch 中实现地理位置搜索(Geo Search)?
1. 原理
Elasticsearch 支持基于地理位置的搜索,主要依赖 geo_point 和 geo_shape 两种数据类型:
geo_point:用于存储单个经纬度坐标(点),适合距离计算、范围过滤geo_shape:用于存储复杂的几何形状(多边形、线、圆等),适合区域匹配
Geo Search 的核心是:
- 在索引中存储地理位置数据
- 使用 Geo Query (如
geo_distance、geo_bounding_box、geo_shape)进行空间过滤或排序
2. 数据类型
geo_point
bash
PUT locations
{
"mappings": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}- 存储方式:
bash
POST locations/_doc
{
"name": "Store A",
"location": {
"lat": 39.9042,
"lon": 116.4074
}
}geo_shape
bash
PUT regions
{
"mappings": {
"properties": {
"area": {
"type": "geo_shape"
}
}
}
}- 存储方式:
bash
POST regions/_doc
{
"name": "Beijing Area",
"area": {
"type": "polygon",
"coordinates": [
[
[116.3, 39.9],
[116.5, 39.9],
[116.5, 40.0],
[116.3, 40.0],
[116.3, 39.9]
]
]
}
}3. 查询示例
3.1 按距离搜索(geo_distance)
查找距离某点 5km 内的商店:
bash
GET locations/_search
{
"query": {
"bool": {
"filter": {
"geo_distance": {
"distance": "5km",
"location": {
"lat": 39.9042,
"lon": 116.4074
}
}
}
}
}
}3.2 按矩形范围搜索(geo_bounding_box)
查找在指定矩形范围内的商店:
bash
GET locations/_search
{
"query": {
"bool": {
"filter": {
"geo_bounding_box": {
"location": {
"top_left": {
"lat": 40.0,
"lon": 116.3
},
"bottom_right": {
"lat": 39.8,
"lon": 116.5
}
}
}
}
}
}
}3.3 按形状匹配(geo_shape)
查找在某个多边形区域内的商店:
bash
GET locations/_search
{
"query": {
"bool": {
"filter": {
"geo_shape": {
"location": {
"shape": {
"type": "polygon",
"coordinates": [
[
[116.3, 39.9],
[116.5, 39.9],
[116.5, 40.0],
[116.3, 40.0],
[116.3, 39.9]
]
]
},
"relation": "within"
}
}
}
}
}
}4. 注意事项
- 坐标顺序 :Geo JSON 格式是
[lon, lat],不要写反 - 性能优化 :大量地理数据建议使用
geo_point并开启索引优化(如doc_values) - 精度 :
geo_point精度有限,复杂区域建议用geo_shape - 排序 :可以用
sort按距离排序,提升用户体验 - 单位 :距离支持
m、km、mi等
5. 面试高分回答模板
Elasticsearch 的地理位置搜索依赖
geo_point和geo_shape两种数据类型。
geo_point适合单点坐标,用于距离计算和范围过滤;geo_shape适合复杂几何形状,用于区域匹配。常用查询包括
geo_distance(按距离过滤)、geo_bounding_box(矩形范围过滤)和geo_shape(形状匹配)。在生产环境中,建议根据数据类型选择合适的字段类型,并注意坐标顺序和性能优化。
如何在 Elasticsearch 中实现数据的实时更新?
1. 原理
在 Elasticsearch 中,实时更新 并不是直接修改已有文档,而是通过重新索引(Reindex)或替换文档来实现的。
- Elasticsearch 的文档是不可变的
- 当你更新文档时,实际上是写入一个新版本,旧版本会被标记为删除
- 由于 Elasticsearch 是近实时(Near Real-Time, NRT)系统,更新后的数据通常会在 1 秒左右 对搜索可见(由
refresh_interval控制)
2. 实现方法
方法 1:直接替换文档(Index API)
适合全量更新文档内容。
bash
PUT my_index/_doc/1
{
"name": "Store A",
"status": "open",
"updated_at": "2025-11-10T17:55:00"
}- 如果文档 ID 已存在,会覆盖旧文档
- 适合更新整个文档
方法 2:部分更新文档(Update API)
适合只修改部分字段。
bash
POST my_index/_update/1
{
"doc": {
"status": "closed",
"updated_at": "2025-11-10T18:00:00"
}
}- 只更新指定字段,不影响其他字段
- 内部仍是新版本替换,但更高效
方法 3:脚本更新(Update API + Script)
适合基于现有值进行计算更新。
bash
POST my_index/_update/1
{
"script": {
"source": "ctx._source.visit_count += params.count",
"params": {
"count": 1
}
}
}- 可以做数值累加、字符串拼接等操作
- 适合计数器、状态更新等场景
方法 4:批量更新(Bulk API)
适合高频更新,减少网络开销。
bash
POST _bulk
{ "update": { "_index": "my_index", "_id": "1" } }
{ "doc": { "status": "open" } }
{ "update": { "_index": "my_index", "_id": "2" } }
{ "doc": { "status": "closed" } }- 一次请求更新多个文档
- 适合日志、IoT 数据等高吞吐场景
方法 5:实时数据流更新(Beats / Logstash / Kafka)
适合持续接收外部数据并更新索引。
- Filebeat / Metricbeat:采集日志或指标,直接写入 Elasticsearch
- Logstash:可做数据清洗、转换后写入
- Kafka Connect:从 Kafka 消费数据并更新 Elasticsearch
3. 示例:实时库存更新
假设我们有一个商品库存索引:
bash
POST products/_update/1001
{
"doc": {
"stock": 50,
"updated_at": "2025-11-10T18:05:00"
}
}- 用户下单后,库存会立即更新
- 结合
refresh_interval设置为1s,几乎实时对搜索可见
4. 注意事项
- 近实时特性 :默认
refresh_interval为 1s,更新不会立即可见 - 高频更新性能 :频繁刷新会影响性能,可在批量更新后手动调用
_refresh - 并发冲突 :可使用
version或seq_no+primary_term控制并发更新 - 脚本更新风险:脚本执行会增加 CPU 开销,需谨慎使用
- 批量更新建议:高吞吐场景优先使用 Bulk API
5. 面试高分回答模板
在 Elasticsearch 中,实时更新是通过替换文档实现的,因为文档是不可变的。
可以使用 Index API 全量更新、Update API 部分更新、脚本更新或 Bulk API 批量更新。
Elasticsearch 是近实时系统,更新后的数据通常在 1 秒左右可见,由
refresh_interval控制。在生产环境中,高频更新建议使用 Bulk API 或数据流管道(如 Logstash、Kafka),并注意并发冲突和性能优化。
Elasticsearch 与 Kibana 的关系是什么?
1. 定义与定位
-
Elasticsearch
是一个分布式搜索与分析引擎 ,用于存储、检索和分析海量结构化与非结构化数据。它是 Elastic Stack 的核心组件,负责数据的索引与查询。
-
Kibana
是一个可视化与管理工具,用于与 Elasticsearch 交互。它提供图形化界面,让用户可以可视化数据、构建仪表盘、运行查询、管理索引和配置 Elastic Stack。
2. 关系
- Kibana 依赖 Elasticsearch:Kibana 本身不存储业务数据,它所有的数据查询、分析、可视化都依赖 Elasticsearch 提供的 API。
- Elasticsearch 是数据引擎,Kibana 是展示层:Elasticsearch 负责数据存储与计算,Kibana 负责将结果以图表、表格、地图等形式呈现给用户。
- 交互方式:Kibana 通过 REST API 与 Elasticsearch 通信,执行搜索、聚合、索引管理等操作。
3. 工作流程
- 数据采集:通过 Beats、Logstash 或 API 将数据写入 Elasticsearch
- 数据存储与分析:Elasticsearch 对数据进行索引、搜索和聚合
- 数据可视化:Kibana 连接到 Elasticsearch,读取数据并生成图表、仪表盘
- 管理与监控:Kibana 提供索引管理、集群监控、安全配置等功能
4. 对比表
| 组件 | 主要功能 | 是否存储业务数据 | 面向对象 |
|---|---|---|---|
| Elasticsearch | 数据存储、搜索、分析 | 是 | 开发者、后端系统 |
| Kibana | 数据可视化、管理、监控 | 否 | 运维、分析师、业务人员 |
5. 面试高分回答模板
Elasticsearch 是 Elastic Stack 的核心搜索与分析引擎,负责存储和处理数据;Kibana 是与 Elasticsearch 配套的可视化和管理工具,负责展示数据、构建仪表盘和执行管理任务。
Kibana 依赖 Elasticsearch 提供的数据和 API,两者的关系是"引擎与仪表盘",Elasticsearch 负责计算,Kibana 负责展示。
五、注册中心与配置中心
1. 注册中心
Eureka 的原理与自我保护机制?
Zookeeper 的原理与应用场景?
Nacos 的原理与应用场景?
Consul 的原理与应用场景?
注册中心的 CAP 特性如何体现?
2. 配置中心
Spring Cloud Config 的原理?
Nacos Config 的原理?
Apollo 的原理与应用场景?
配置中心如何实现动态刷新?
六、API 网关
-
Zuul 与 Spring Cloud Gateway 的区别?
-
API 网关的作用是什么?
-
API 网关的路由与过滤机制?
-
API 网关如何实现限流?
-
API 网关如何实现鉴权?
-
API 网关如何实现灰度发布?
七、分布式协调与锁
Zookeeper 的选举机制?
Zookeeper 如何实现分布式锁?
Redis 如何实现分布式锁?
分布式锁的可靠性问题与解决方案?
分布式锁的超时与续期机制?
八、日志与链路追踪
-
ELK(Elasticsearch + Logstash + Kibana)的原理?
-
SkyWalking 的原理与应用场景?
-
Zipkin 的原理与应用场景?
-
分布式链路追踪的实现原理?
-
如何在微服务中实现全链路日志?
✅ 总结
这份清单基本覆盖了 中间件篇的所有常见面试题 ,从消息队列、缓存、数据库、搜索引擎到注册中心、网关、分布式锁、日志追踪都有涉及。
建议你复习时:
- 先掌握高频中间件(MQ、Redis、MySQL) → 面试必问。
- 再学习分布式组件(注册中心、配置中心、网关) → 微服务岗位必备。
- 最后补充搜索引擎与链路追踪 → 加分项。