1. 系统概述
DeepHunt是南开大学与阿里巴巴、华为等机构联合提出的基于图自编码器的可解释微服务故障定位方法,解决了传统方法面临的三大挑战:
- 挑战1:缺乏可解释的根因量化方法
- 挑战2:模型缺乏持续学习能力
- 挑战3:需要大量历史训练数据
2. 整体架构与代码流程
2.1 主函数执行流程
python
# 1. 配置加载 → 论文第5.1节实验设置
config = yaml.load(open(f'config/{dataset}.yaml', 'r'))
# 2. 样本加载 → 论文第4.1-4.2节SBG构建
train_samples, test_samples = load_samples(config['path']['sample_dir'])
# 3. 初始模型训练 → 论文第4.3节离线训练
model = train(input_samples, config['model_param'])
# 4. 反馈调优评估 → 论文第4.5节反馈机制
fd_model, test_df, fd_test_df, res_dict = get_eval_df(model, cases, test_samples, config)2.2 核心配置文件
配置文件包含的关键参数对应论文中的超参数分析:
yaml
model_param:
hidden_dim: 64 # 隐藏层维度(图10a分析)
noise_rate: 0.2 # 掩码率(图10b分析)
num_layers: 1 # 网络层数(图10c分析)
window_size: 10 # 时间窗口大小(图10d分析)
aug_multiple: 10 # 数据增强倍数(第4.3.2节)
learning_rate: 0.01 # 学习率(图10f分析)3. 核心训练机制详解
3.1 GraphSAGE图神经网络
理论基础:论文第4.3.1节模型结构,对应公式(1):
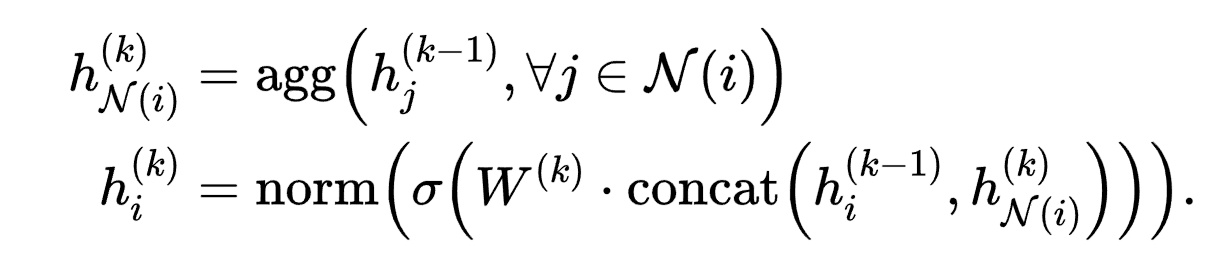
在DeepHunt中的实现特点:
- 归纳式学习:能够泛化到未见过的节点,适应动态微服务架构
- 邻居采样:避免内存爆炸,适合大规模系统
- 均值聚合:捕捉故障传播的局部模式
- 多层传播:学习深层次的依赖关系
代码实现:
python
model = GraphSAGE(in_dim, hidden_dim, out_dim, dropout, mask_rate, num_layers, norm)3.2 数据增强机制
理论基础:论文第4.3.2节,通过特征掩码解决训练数据不足问题。
核心实现策略:
python
def data_aug(graphs, inputs, mask_rate):
# 保持图结构不变,仅增强节点特征
aug_graphs = graphs
# 随机特征掩码 - 核心增强方法
mask = torch.rand_like(inputs) > mask_rate
aug_inputs = inputs * mask.float()
return aug_graphs, aug_inputs增强策略优势:
- ✅ 模拟真实场景中的数据缺失
- ✅ 防止模型过度依赖特定特征
- ✅ 提高模型的泛化能力
- ✅ 缓解新系统数据稀缺问题
3.3 自监督训练流程
python
for epoch in range(epochs):
for batch_samples in dataloader:
for _ in range(aug_multiple): # 多次数据增强
# 数据增强
aug_gs, aug_inputs = data_aug(graphs, inputs, model.mask_rate)
# 前向传播:重构增强后的输入
outputs = model(aug_gs, aug_inputs)
# 损失计算:多模态特征重构误差
loss = modal_loss(outputs, aug_inputs)
# 反向传播
loss.backward()
opt.step()训练特点:
- 零标签训练:仅使用正常时期数据,无需故障标签
- 多轮增强:每个批次进行多次数据增强
- 重构目标:最小化输入与输出的差异
- 提前停止:防止过拟合,提高训练效率
4. 技术创新点对应
4.1 解决挑战3:数据不足
- 数据增强:通过特征掩码扩充训练样本
- 自监督学习:不依赖标注数据,从正常模式学习
- 零标签冷启动:新系统部署即可使用
4.2 核心理论支撑
- 图自编码器:学习系统正常行为模式
- 重构误差:作为异常检测的关键指标
- 多模态融合:整合trace、log、metric数据
5. 实验效果验证
根据论文第5.2节结果,DeepHunt在零标签情况下:
- D1数据集:A@5达到95.9%,Avg@5达到88.9%
- D2数据集:A@5达到90.3%,Avg@5达到71.6%
- 仅1%标签:性能接近或超越全监督基线方法
6. 总结
DeepHunt的训练机制通过:
- GraphSAGE图神经网络有效建模微服务依赖关系
- 数据增强策略解决历史数据稀缺问题
- 自监督学习实现零标签冷启动
- 多模态特征融合提供全面的系统观测
这些技术共同构成了一个高效、可解释且自适应的微服务故障定位系统,为工业级微服务系统的智能运维提供了重要解决方案。
参考论文:Sun et al. "Interpretable Failure Localization for Microservice Systems Based on Graph Autoencoder" (2025)