------ 理论前沿、系统工程与应用实践
1. 绪论:计算范式的演进与稀疏性的崛起
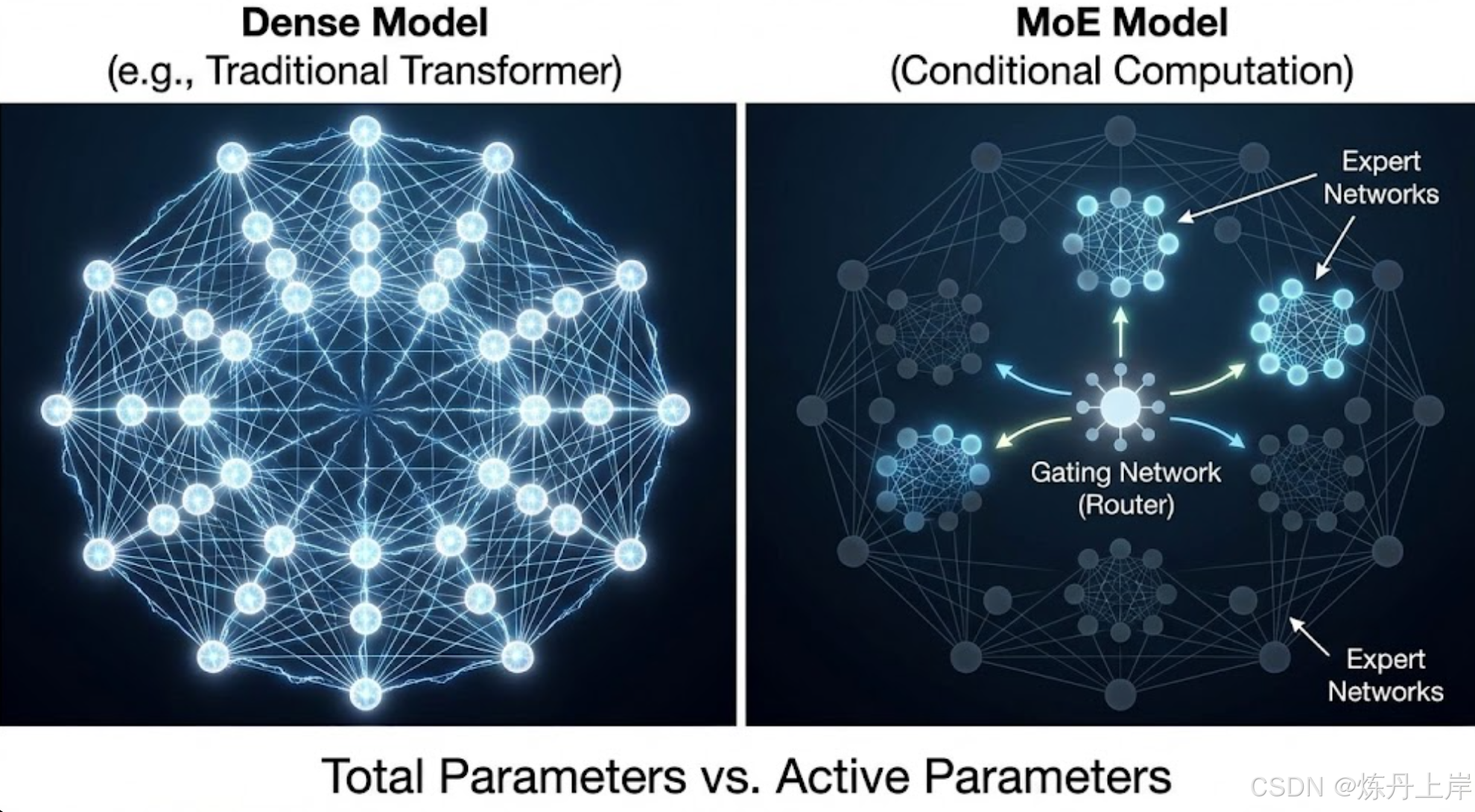
在人工智能的发展历程中,模型规模的扩张(Scaling)已被证实是提升模型性能、解锁涌现能力(Emergent Capabilities)的最有效途径之一。然而,随着模型规模突破千亿(100B+)大关,传统的稠密(Dense)Transformer 架构面临着边际效应递减的挑战。在此背景下,混合专家(Mixture-of-Experts, MoE) 架构作为一种"条件计算"范式,凭借其在扩大模型容量的同时保持计算成本可控的特性,成为了大模型领域的绝对核心技术。
1.1 从稠密全连接到稀疏条件计算
传统的 Transformer 是"稠密"的,即全激活模式。MoE 受到人脑稀疏激活机制的启发,将前馈神经网络(FFN)层替换为多个并行的"专家"网络,并引入"门控网络"动态路由。
这种设计实现了两个关键层面的解耦:
-
参数解耦: 实现了"总参数量"(Total Parameters)与"激活参数量"(Active Parameters)的彻底分离。
-
例: xAI 的 Grok-1 拥有 3140亿 总参数,但推理时仅激活 860亿。
-
算力解耦: 允许在保持 FLOPs 不变的情况下,通过增加专家数量线性扩展模型参数。Switch Transformer 证明在同等算力下,MoE 收敛速度可达稠密模型的 4 倍。
1.2 MoE 的历史脉络与现代复兴
- 起源 (1991): Jacobs 等人提出 Adaptive Mixtures of Local Experts,作为集成学习方法。
- 复兴 (2017-2021): Shazeer 将其引入 LSTM,Google 发布 GShard 和 Switch Transformer,首次训练万亿参数模型。
- 爆发 (2023-2024): Mistral AI (Mixtral 8x7B) 和 DeepSeek (DeepSeek-MoE) 推动工程落地与架构创新,GPT-4 的传闻更是将其推向巅峰。
2. MoE 架构的数学原理与组件解析
MoE 层的核心由 个专家网络 和一个门控网络 组成。
2.1 门控机制 (Gating Mechanism)
MoE 层的输出 是所有被选中专家输出的加权和:
其中:
- :输入向量。
- :第 个专家的非线性变换输出(通常为 MLP)。
- :门控网络的输出向量,绝大多数元素为 0(稀疏性核心)。
2.2 稀疏门控策略 (Sparse Gating)
通常采用 Top-k 选择机制,引入高斯噪声以促进负载均衡:
- Top-1 Gating (Switch Transformer): 速度最快,稀疏性最大。
- Top-2 Gating (GShard, Mixtral, Grok-1): 梯度传递更平滑,困惑度表现通常更好。
2.3 专家容量与 Token 丢弃
分布式训练中,单设备处理能力有限,需设定专家容量 (Expert Capacity, ):
- Capacity Factor (CF): 通常设为 1.0 - 1.25。
- Token Dropping: 若路由给某专家的 Token 数超过 ,多余 Token 将被丢弃(输出设为 0 或透传),导致性能下降。
3. 路由算法的分类学与演进
路由算法直接决定了参数利用率和负载均衡。
3.1 基于 Token 的选择路由 (Token-Choice)
- 机制: 每个 Token 独立选择最适合自己的专家。
- 痛点: 容易导致马太效应。常见词的专家过载(导致 Dropping),长尾词专家饥饿(计算浪费)。
3.2 基于专家的选择路由 (Expert-Choice)
- 机制: Google DeepMind 提出。由专家选择与其亲和度最高的 Top-k 个 Token。
- 优势: 天然保证负载均衡。
- 挑战: 推理时需全局排序,不适合流式生成,延迟高。
3.3 软路由 (Soft MoE)
- 机制: 完全可微,不进行硬性分配。专家处理所有 Token 的加权组合(Slots)。
- 优势: 彻底消除 Token Dropping,训练稳定,在 ViT 任务中表现优异。
3.4 DeepSeek-MoE:细粒度与共享隔离
DeepSeek 团队针对"知识混合"痛点提出的创新架构:
- 细粒度专家分割 (Fine-grained Segmentation): 将大专家拆分为多个小专家,增加组合灵活性。
- 共享专家隔离 (Shared Expert Isolation): 设立常驻激活的"共享专家"处理通用知识,路由专家专注于稀疏专业知识。
4. 训练动力学:稳定性与负载均衡
MoE 训练极易出现路由崩溃 (Routing Collapse),即所有 Token 涌向少数专家。
4.1 辅助负载均衡损失 (Auxiliary Load Balancing Loss)
在总 Loss 中加入 以惩罚专家间的负载方差:
- :实际分配比例。
- :门控网络的概率输出。
- 趋势: DeepSeek-V3 等开始探索无辅助损失策略,通过动态 Bias 调整路由。
4.2 Router Z-Loss (ST-MoE)
解决低精度训练(BF16)时的 Logits 爆炸问题:
通过惩罚大的 Logits 值,提高数值稳定性,避免 NaN 错误。
5. 分布式训练系统的工程实现
训练万亿参数 MoE 是高性能计算 (HPC) 的极致挑战。
5.1 混合并行策略
- 数据并行 (DP): 门控及 Non-MoE 层。
- 专家并行 (EP): 不同专家放置在不同 GPU,Token 需跨卡传输。
- 张量并行 (TP): 单个超大专家内部切分。
5.2 全对全通信 (All-to-All) 瓶颈
MoE 前向传播包含两次 All-to-All 通信(Dispatch 分发与 Combine 聚合)。
- 优化技术:
- Overlap: 计算与通信重叠(DeepSpeed-MoE)。
- 分层通信: 先节点内聚合,再跨节点传输,利用 NVLink 高带宽。
6. 推理挑战与部署优化
MoE 推理通常是 显存带宽受限 (Memory Bandwidth Bound)。
-
vLLM 与连续批处理 (Continuous Batching): 动态插入请求,解决 MoE 静态 Batching 效率低的问题。
-
量化技术 (QMoE & AWQ):
-
AWQ: 保护 1% 的显著权重(Salient Weights),对其余 99% 进行 INT4 量化。
-
指令微调 (Instruction Tuning): MoE 在指令微调中表现出更强的抗干扰能力(Flan-MoE),适合多任务。
7. 前沿 MoE 模型案例全景解析
| 模型 | 总参数量 | 激活参数 (Per Token) | 专家数量 | 路由策略 | 核心特点 |
|---|---|---|---|---|---|
| Switch-C | 1.6T | ~XX B | 2048 | Top-1 | 极度稀疏,海量小专家,收敛快 |
| Mixtral 8x7B | 46.7B | 12.9B | 8 | Top-2 | 高性价比,共享 Attention,开源里程碑 |
| Grok-1 | 314B | 86B | 8 | Top-2 | 巨大专家设计,JAX/Rust 训练栈 |
| DeepSeek-V2 | 236B | 21B | 160 (routed) | Top-6 + Shared | 细粒度+共享专家,MLA 技术,极高参数效率 |
| GPT-4 (传闻) | ~1.8T | ~280B | 16 | Top-2 | 多模态能力,商业化验证的终极形态 |
8. 总结与未来展望
核心洞察:
- 规模杠杆: MoE 是目前实现 10T+ 参数规模且经济可行的唯一路径。
- 专业化胜利: "通用共享 + 领域路由"将成为架构主流。
未来方向:
- 端侧 MoE: 利用 NPU 实现低功耗高性能推理。
- 异构专家: 混合 Transformer、Mamba、查表甚至外部工具 API。
- 动态计算深度: 根据问题难度动态选择经过多少层专家(Early Exit)。
MoE 正在引领 AI 从"暴力美学"走向"精细化运营"的新时代。