1.BERT编码器(BERTEncoder)

import torch
from torch import nn
from d2l import torch as d2l
#语句输入制作:token=<cls>+xxxxx+<sep>+XXXXXX+<sep>
def get_tokens_and_segments(tokens_a, tokens_b=None):
"""获取输入序列的词元及其片段索引"""
tokens = ['<cls>'] + tokens_a + ['<sep>']
# 0和1分别标记片段A和B
#bert中用0和1来标记第一句和第二句
segments = [0] * (len(tokens_a) + 2)
if tokens_b is not None:
tokens += tokens_b + ['<sep>']
segments += [1] * (len(tokens_b) + 1)
return tokens, segments
#bert的编码器:其实和transformer差不多.
class BERTEncoder(nn.Module):
def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input,
ffn_num_hiddens, num_heads, num_layers, dropout,
max_len=1000, key_size=768, query_size=768, value_size=768,
**kwargs):
super(BERTEncoder, self).__init__(**kwargs)
self.token_embedding=nn.Embedding(vocab_size,num_hiddens)
self.segment_embedding=nn.Embedding(2,num_hiddens)
self.blks=nn.Sequential()
for i in range(num_layers):
self.blks.add_module(f"{i}", d2l.EncoderBlock(
key_size, query_size, value_size, num_hiddens, norm_shape,
ffn_num_input, ffn_num_hiddens, num_heads, dropout, True))
#bert的embedding=token+segment+pos
self.pos_embedding=nn.Parameter(torch.randn(1,max_len,num_hiddens))
def forward(self,tokens,segments,valid_lens):
X=self.token_embedding(tokens)+self.segment_embedding(segments)
X=X+self.pos_embedding.data[:,:X.shape[1],:]
for blk in self.blks:
X=blk(X,valid_lens)
return X
vocab_size, num_hiddens, ffn_num_hiddens, num_heads = 10000, 768, 1024, 4
norm_shape, ffn_num_input, num_layers, dropout = [768], 768, 2, 0.2
encoder = BERTEncoder(vocab_size, num_hiddens, norm_shape, ffn_num_input,ffn_num_hiddens, num_heads, num_layers, dropout)
########################################################################################
#输入测试
tokens = torch.randint(0, vocab_size, (2, 8))
segments = torch.tensor([[0, 0, 0, 0, 1, 1, 1, 1], [0, 0, 0, 1, 1, 1, 1, 1]])
encoded_X = encoder(tokens, segments, None)
encoded_X.shape
########################################################################################
2.掩蔽语言模型(MLM)

import torch
from torch import nn
from d2l import torch as d2l
########################################################################################
#掩蔽语言模型Masked Language Modeling:
class MaskLM(nn.Module):
def __init__(self, vocab_size, num_hiddens, num_inputs=768, **kwargs):
super(MaskLM, self).__init__(**kwargs)
self.mlp=nn.Sequential(nn.Linear(num_inputs, num_hiddens),
nn.ReLU(),
nn.LayerNorm(num_hiddens),
nn.Linear(num_hiddens, vocab_size))
def forward(self,X,pred_positions):
num_pred_positions=pred_positions.shape[1]
pred_positions=pred_positions.reshape(-1)
batch_size=X.shape[0]
batch_idx=torch.arange(0,batch_size)
batch_idx = torch.repeat_interleave(batch_idx, num_pred_positions)
masked_X = X[batch_idx, pred_positions]
masked_X = masked_X.reshape((batch_size, num_pred_positions, -1))
mlm_Y_hat=self.mlp(masked_X)
return mlm_Y_hat
mlm = MaskLM(vocab_size, num_hiddens)
mlm_positions = torch.tensor([[1, 5, 2], [6, 1, 5]])
mlm_Y_hat = mlm(encoded_X, mlm_positions)
mlm_Y = torch.tensor([[7, 8, 9], [10, 20, 30]])
loss = nn.CrossEntropyLoss(reduction='none')
mlm_l = loss(mlm_Y_hat.reshape((-1, vocab_size)), mlm_Y.reshape(-1))
mlm_l.shape
########################################################################################
3.下一句预测(NSP)
import torch
from torch import nn
from d2l import torch as d2l
########################################################################################
#NSP(Next Sentence Prediction)
class NextSentencePred(nn.Module):
"""BERT的下一句预测任务"""
def __init__(self, num_inputs, **kwargs):
super(NextSentencePred, self).__init__(**kwargs)
self.output = nn.Linear(num_inputs, 2)
def forward(self, X):
# X的形状:(batchsize,num_hiddens)
return self.output(X)
encoded_X = torch.flatten(encoded_X, start_dim=1)
# NSP的输入形状:(batchsize,num_hiddens)
nsp = NextSentencePred(encoded_X.shape[-1])
nsp_Y_hat = nsp(encoded_X)
nsp_y = torch.tensor([0, 1])
nsp_l = loss(nsp_Y_hat, nsp_y)
nsp_l
########################################################################################
4.整合BERT模型
import torch
from torch import nn
from d2l import torch as d2l
class BERTModel(nn.Module):
"""BERT模型"""
def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input,
ffn_num_hiddens, num_heads, num_layers, dropout,
max_len=1000, key_size=768, query_size=768, value_size=768,
hid_in_features=768, mlm_in_features=768,
nsp_in_features=768):
super(BERTModel, self).__init__()
self.encoder = BERTEncoder(vocab_size, num_hiddens, norm_shape,
ffn_num_input, ffn_num_hiddens, num_heads, num_layers,
dropout, max_len=max_len, key_size=key_size,
query_size=query_size, value_size=value_size)
self.hidden = nn.Sequential(nn.Linear(hid_in_features, num_hiddens),
nn.Tanh())
self.mlm = MaskLM(vocab_size, num_hiddens, mlm_in_features)
self.nsp = NextSentencePred(nsp_in_features)
def forward(self, tokens, segments, valid_lens=None,
pred_positions=None):
encoded_X = self.encoder(tokens, segments, valid_lens)
if pred_positions is not None:
mlm_Y_hat = self.mlm(encoded_X, pred_positions)
else:
mlm_Y_hat = None
# 用于下一句预测的多层感知机分类器的隐藏层,0是"<cls>"标记的索引
nsp_Y_hat = self.nsp(self.hidden(encoded_X[:, 0, :]))
return encoded_X, mlm_Y_hat, nsp_Y_hat
5.Wikitext-2数据集
#数据集处理:
import os
import random
import torch
from d2l import torch as d2l
import pandas as pd
#下载wikitext-2数据集:
d2l.DATA_HUB['wikitext-2'] = (
'https://s3.amazonaws.com/research.metamind.io/wikitext/'
'wikitext-2-v1.zip', '3c914d17d80b1459be871a5039ac23e752a53cbe')
#大写字母转化为小写
def _read_wiki(data_dir):
file_name = os.path.join(data_dir, 'wiki.train.tokens')
with open(file_name, 'r') as f:
lines = f.readlines()
# 大写字母转换为小写字母
paragraphs = [line.strip().lower().split(' . ')
for line in lines if len(line.split(' . ')) >= 2]
random.shuffle(paragraphs)
return paragraphs
# def _read_wiki(data_dir):
# df = pd.read_parquet(data_dir)
# print(df.columns)
# lines = df['text'].tolist()
# paragraphs = [line.strip().lower().split(' . ')
# for line in lines if len(line.split(' . ')) >= 2]
# random.shuffle(paragraphs)
# return paragraphs
#NSP Task:_get_next_sentence
def _get_next_sentence(sentence, next_sentence, paragraphs):
if random.random() < 0.5:
is_next = True
else:
# paragraphs是三重列表的嵌套
next_sentence = random.choice(random.choice(paragraphs))
is_next = False
return sentence, next_sentence, is_next
#@save
def _get_nsp_data_from_paragraph(paragraph, paragraphs, vocab, max_len):
nsp_data_from_paragraph = []
for i in range(len(paragraph) - 1):
tokens_a, tokens_b, is_next = _get_next_sentence(
paragraph[i], paragraph[i + 1], paragraphs)
# 考虑1个'<cls>'词元和2个'<sep>'词元
if len(tokens_a) + len(tokens_b) + 3 > max_len:
continue
tokens, segments = d2l.get_tokens_and_segments(tokens_a, tokens_b)
nsp_data_from_paragraph.append((tokens, segments, is_next))
return nsp_data_from_paragraph
#mlm Task:
#80%的时间将词用<mask>进行替换,10%的时间保持不变,10%的时间用随机词来替换:
def _replace_mlm_tokens(tokens, candidate_pred_positions, num_mlm_preds,
vocab):
# 为遮蔽语言模型的输入创建新的词元副本,其中输入可能包含替换的"<mask>"或随机词元
mlm_input_tokens = [token for token in tokens]
pred_positions_and_labels = []
# 打乱后用于在遮蔽语言模型任务中获取15%的随机词元进行预测
random.shuffle(candidate_pred_positions)
for mlm_pred_position in candidate_pred_positions:
if len(pred_positions_and_labels) >= num_mlm_preds:
break
masked_token = None
# 80%的时间:将词替换为"<mask>"词元
if random.random() < 0.8:
masked_token = '<mask>'
else:
# 10%的时间:保持词不变
if random.random() < 0.5:
masked_token = tokens[mlm_pred_position]
# 10%的时间:用随机词替换该词
else:
masked_token = random.choice(vocab.idx_to_token)
mlm_input_tokens[mlm_pred_position] = masked_token
pred_positions_and_labels.append(
(mlm_pred_position, tokens[mlm_pred_position]))
return mlm_input_tokens, pred_positions_and_labels
#@save
def _get_mlm_data_from_tokens(tokens, vocab):
candidate_pred_positions = []
# tokens是一个字符串列表
for i, token in enumerate(tokens):
# 在遮蔽语言模型任务中不会预测特殊词元
if token in ['<cls>', '<sep>']:
continue
candidate_pred_positions.append(i)
# 遮蔽语言模型任务中预测15%的随机词元
num_mlm_preds = max(1, round(len(tokens) * 0.15))
mlm_input_tokens, pred_positions_and_labels = _replace_mlm_tokens(
tokens, candidate_pred_positions, num_mlm_preds, vocab)
pred_positions_and_labels = sorted(pred_positions_and_labels,
key=lambda x: x[0])
pred_positions = [v[0] for v in pred_positions_and_labels]
mlm_pred_labels = [v[1] for v in pred_positions_and_labels]
return vocab[mlm_input_tokens], pred_positions, vocab[mlm_pred_labels]
#将文本转化成预训练数据集:
#@save
def _pad_bert_inputs(examples, max_len, vocab):
max_num_mlm_preds = round(max_len * 0.15)
all_token_ids, all_segments, valid_lens, = [], [], []
all_pred_positions, all_mlm_weights, all_mlm_labels = [], [], []
nsp_labels = []
for (token_ids, pred_positions, mlm_pred_label_ids, segments,
is_next) in examples:
all_token_ids.append(torch.tensor(token_ids + [vocab['<pad>']] * (
max_len - len(token_ids)), dtype=torch.long))
all_segments.append(torch.tensor(segments + [0] * (
max_len - len(segments)), dtype=torch.long))
# valid_lens不包括'<pad>'的计数
valid_lens.append(torch.tensor(len(token_ids), dtype=torch.float32))
all_pred_positions.append(torch.tensor(pred_positions + [0] * (
max_num_mlm_preds - len(pred_positions)), dtype=torch.long))
# 填充词元的预测将通过乘以0权重在损失中过滤掉
all_mlm_weights.append(
torch.tensor([1.0] * len(mlm_pred_label_ids) + [0.0] * (
max_num_mlm_preds - len(pred_positions)),
dtype=torch.float32))
all_mlm_labels.append(torch.tensor(mlm_pred_label_ids + [0] * (
max_num_mlm_preds - len(mlm_pred_label_ids)), dtype=torch.long))
nsp_labels.append(torch.tensor(is_next, dtype=torch.long))
return (all_token_ids, all_segments, valid_lens, all_pred_positions,
all_mlm_weights, all_mlm_labels, nsp_labels)
#dwikitext数据集class构建:
class _WikiTextDataset(torch.utils.data.Dataset):
def __init__(self, paragraphs, max_len):
# 输入paragraphs[i]是代表段落的句子字符串列表;
# 而输出paragraphs[i]是代表段落的句子列表,其中每个句子都是词元列表
paragraphs = [d2l.tokenize(
paragraph, token='word') for paragraph in paragraphs]
sentences = [sentence for paragraph in paragraphs
for sentence in paragraph]
self.vocab = d2l.Vocab(sentences, min_freq=5, reserved_tokens=[
'<pad>', '<mask>', '<cls>', '<sep>'])
# 获取下一句子预测任务的数据
examples = []
for paragraph in paragraphs:
examples.extend(_get_nsp_data_from_paragraph(
paragraph, paragraphs, self.vocab, max_len))
# 获取遮蔽语言模型任务的数据
examples = [(_get_mlm_data_from_tokens(tokens, self.vocab)
+ (segments, is_next))
for tokens, segments, is_next in examples]
# 填充输入
(self.all_token_ids, self.all_segments, self.valid_lens,
self.all_pred_positions, self.all_mlm_weights,
self.all_mlm_labels, self.nsp_labels) = _pad_bert_inputs(
examples, max_len, self.vocab)
def __getitem__(self, idx):
return (self.all_token_ids[idx], self.all_segments[idx],
self.valid_lens[idx], self.all_pred_positions[idx],
self.all_mlm_weights[idx], self.all_mlm_labels[idx],
self.nsp_labels[idx])
def __len__(self):
return len(self.all_token_ids)
#加载wikitext数据集
def load_data_wiki(batch_size, max_len):
"""加载WikiText-2数据集"""
num_workers = d2l.get_dataloader_workers()
data_dir = "/data1/zhongyan/deepl/pytorch/12_预训练自然语言模型/wikitext-2"
paragraphs = _read_wiki(data_dir)
train_set = _WikiTextDataset(paragraphs, max_len)
train_iter = torch.utils.data.DataLoader(train_set, batch_size,
shuffle=True, num_workers=num_workers)
return train_iter, train_set.vocab
# def load_data_wiki(batch_size, max_len):
# "加载WikiText-2数据集"
# num_workers = d2l.get_dataloader_workers()
# dir_data="/data1/zhongyan/deepl/pytorch/12_预训练自然语言模型/train-00000-of-00001.parquet"
# paragraphs = _read_wiki(dir_data)
# train_set = _WikiTextDataset(paragraphs, max_len)#返回数据集
# train_iter = torch.utils.data.DataLoader(train_set, batch_size,
# shuffle=True, num_workers=0)
# print("done")
# return train_iter, train_set.vocab
batch_size, max_len = 512, 64
train_iter, vocab = load_data_wiki(batch_size,max_len)
for (tokens_X, segments_X, valid_lens_x, pred_positions_X, mlm_weights_X,mlm_Y, nsp_y) in train_iter:
print(tokens_X.shape, segments_X.shape, valid_lens_x.shape,
pred_positions_X.shape, mlm_weights_X.shape, mlm_Y.shape,
nsp_y.shape)
break
6.BERT模型训练
#bert模型训练预测:
#设置一个小型的BERT:2*128*2self-attention
##############################################################################################
#定义个辅助函数:
def _get_batch_loss_bert(net,loss,vocab_size,tokens_X,
segments_X,valid_lens_x,
pred_positions_X,mlm_weights_X,
mlm_Y,nsp_y):
_,mlm_Y_hat,nsp_Y_hat=net(tokens_X, segments_X,
valid_lens_x.reshape(-1),
pred_positions_X)
#mlm_loss:
#做交叉熵损失函数之后
#weight是做加权位置的loss计算
mlm_l=loss(mlm_Y_hat.reshape(-1, vocab_size), mlm_Y.reshape(-1)) *\
mlm_weights_X.reshape(-1, 1)
mlm_l=mlm_l.sum()/(mlm_weights_X.sum()+1e-8)
#nsp_loss
nsp_l=loss(nsp_Y_hat,nsp_y)
l=mlm_l+nsp_l
return mlm_l,nsp_l,l
##############################################################################################
#训练loss
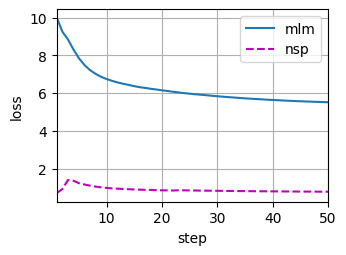
def train_bert(train_iter, net, loss, vocab_size, devices, num_steps):
net = net.to(devices)
trainer = torch.optim.Adam(net.parameters(), lr=0.01)
step, timer = 0, d2l.Timer()
animator = d2l.Animator(xlabel='step', ylabel='loss',
xlim=[1, num_steps], legend=['mlm', 'nsp'])
# 遮蔽语言模型损失的和,下一句预测任务损失的和,句子对的数量,计数
metric = d2l.Accumulator(4)
num_steps_reached = False
while step < num_steps and not num_steps_reached:
for tokens_X, segments_X, valid_lens_x, pred_positions_X,\
mlm_weights_X, mlm_Y, nsp_y in train_iter:
tokens_X = tokens_X.to(devices)
segments_X = segments_X.to(devices)
valid_lens_x = valid_lens_x.to(devices)
pred_positions_X = pred_positions_X.to(devices)
mlm_weights_X = mlm_weights_X.to(devices)
mlm_Y, nsp_y = mlm_Y.to(devices), nsp_y.to(devices)
trainer.zero_grad()
timer.start()
mlm_l, nsp_l, l = _get_batch_loss_bert(
net, loss, vocab_size, tokens_X, segments_X, valid_lens_x,
pred_positions_X, mlm_weights_X, mlm_Y, nsp_y)
l.backward()
trainer.step()
metric.add(mlm_l, nsp_l, tokens_X.shape[0], 1)
timer.stop()
animator.add(step + 1,
(metric[0] / metric[3], metric[1] / metric[3]))
step += 1
if step == num_steps:
num_steps_reached = True
break
print(f'MLM loss {metric[0] / metric[3]:.3f}, '
f'NSP loss {metric[1] / metric[3]:.3f}')
print(f'{metric[2] / timer.sum():.1f} sentence pairs/sec on '
f'{str(devices)}')
##############################################################################################
batch_size, max_len = 512, 64
train_iter, vocab = load_data_wiki(batch_size,max_len)
net = d2l.BERTModel(len(vocab), num_hiddens=128, norm_shape=[128],
ffn_num_input=128, ffn_num_hiddens=256, num_heads=2,
num_layers=2, dropout=0.2, key_size=128, query_size=128,
value_size=128, hid_in_features=128, mlm_in_features=128,
nsp_in_features=128)
devices = torch.device('cuda:7' if torch.cuda.is_available() else 'cpu')
loss = nn.CrossEntropyLoss()
train_bert(train_iter, net, loss, len(vocab), devices, 50)
##############################################################################################
def get_bert_encoding(net, tokens_a, tokens_b=None):
tokens, segments = d2l.get_tokens_and_segments(tokens_a, tokens_b)
token_ids = torch.tensor(vocab[tokens], device=devices).unsqueeze(0)
segments = torch.tensor(segments, device=devices).unsqueeze(0)
valid_len = torch.tensor(len(tokens), device=devices).unsqueeze(0)
encoded_X, _, _ = net(token_ids, segments, valid_len)
return encoded_X
tokens_a = ['a', 'crane', 'is', 'flying']
encoded_text = get_bert_encoding(net, tokens_a)
# 词元:'<cls>','a','crane','is','flying','<sep>'
encoded_text_cls = encoded_text[:, 0, :]
encoded_text_crane = encoded_text[:, 2, :]
encoded_text.shape, encoded_text_cls.shape, encoded_text_crane[0][:3]

tokens_a, tokens_b = ['a', 'crane', 'driver', 'came'], ['he', 'just', 'left']
encoded_pair = get_bert_encoding(net, tokens_a, tokens_b)
# 词元:'<cls>','a','crane','driver','came','<sep>','he','just',
# 'left','<sep>'
encoded_pair_cls = encoded_pair[:, 0, :]
encoded_pair_crane = encoded_pair[:, 2, :]
encoded_pair.shape, encoded_pair_cls.shape, encoded_pair_crane[0][:3]
