背景
项目在进行上云,原先redis是自建的,现需要对自建的redis中的数据迁移到云上的redis中,遂调研当前有哪些工具支持redis的全量部署数据的迁移和增量数据迁移。经过调研当前使用比较多的有 Redis-Shake 以及云厂商提供的商用的同步工具,我们公司当前采购的是阿里云的redis,所以阿里云也提供了DTS的工具,由于阿里云的DTS在增量同步数据这块是按时间收费的,而且 Redis-Shake 当前是能正常满足我们的迁移需求的,所以下面主要介绍Redis-Shake 这个工具的使用以及 Redis 的主从复制的原理等
Redis主从复制以及Redis-Shake架构
和 Mysql 领域的 Canal 的原理类似,Redis-Shake 也是通过伪装成 Redis Master节点的 Slave 节点来获取主节点数据,之后进行主动推送给 需要同步的目标机器Redis, 所以先来了解下 Redis 主从同步的过程,然后再来了解下Redis-Shake 的工作过程。
Redis 主从(Master-Replica)数据同步过程
Redis 的主从同步分为两种主要模式:全量同步(Full Synchronization)和部分同步(Partial Synchronization)。
阶段一:建立连接与协商
当一个副本节点(Replica)要从一个主节点(Master)同步数据时,整个过程开始。
- 设置主节点:副本节点通过执行 REPLICAOF <master_ip> <master_port> 命令(老版本是 SLAVEOF)来指定其主节点。
- 建立网络连接:副本与主节点之间建立一个 TCP socket 连接。
- 发送 PING:副本向主节点发送 PING 命令,如果收到 PONG 响应,说明网络通信正常。
- 身份验证:如果主节点设置了 requirepass,副本需要发送 AUTH 进行验证。
- 端口和能力协商:副本通过 REPLCONF listening-port 告知主节点自己的监听端口,并通过 REPLCONF capa eof capa psync2 等告知主节点自己支持的能力(例如,支持无盘复制、支持 PSYNC2 协议等)。
- 发起同步请求:副本向主节点发送 PSYNC 命令,请求开始同步数据。这是最关键的一步。
阶段二:同步数据(全量或部分)
主节点收到 PSYNC 命令后,会根据副本提供的 runid 和 offset 决定采用哪种同步模式。
场景 A:全量同步 (Full Synchronization)
在以下情况下会触发全量同步:
- 副本是第一次连接主节点。
- 副本的 runid 与主节点的 runid 不匹配(说明主节点重启过或发生了故障转移)。
- 副本请求的 offset 在主节点的复制积压缓冲区(Replication Backlog)中已经不存在(即副本断线时间太长)。
全量同步的详细步骤:
- 主节点响应:主节点回复 +FULLRESYNC ,告知副本需要进行全量同步,并提供自己当前的 runid 和 offset。
- 生成 RDB:主节点执行 BGSAVE 命令,在后台异步生成一个 RDB 快照文件。
- 缓冲写命令:在 BGSAVE 期间,主节点会将所有新的写命令(如 SET, INCR 等)缓存到一个内存缓冲区中。
- 发送 RDB:RDB 文件生成后,主节点将其内容发送给副本。
- 副本接收 RDB:副本接收到 RDB 文件后,会清空自己当前的所有数据,然后加载 RDB文件,将自己的数据库状态恢复到主节点执行 BGSAVE 时的状态。
- 发送缓冲命令:主节点将之前在内存缓冲区中缓存的写命令,逐一发送给副本。
- 副本执行命令:副本执行从主节点发来的所有写命令,使其数据库状态与主节点完全一致。至此,全量同步完成,主从状态达到一致。
场景 B:部分同步 (Partial Synchronization)
如果副本不是第一次连接,并且它请求的 runid 与主节点匹配,且 offset仍在主节点的复制积压缓冲区内,则会触发部分同步。
- 主节点响应:主节点回复 +CONTINUE,表示可以进行部分同步。
- 发送缺失命令:主节点从复制积压缓冲区中,将从副本 offset 之后的所有命令发送给副本。
- 副本执行命令:副本接收并执行这些命令。部分同步非常快,因为它只传输断线期间的少量增量数据,避免了生成和传输庞大 RDB 文件的开销。
阶段三:命令传播 (Command Propagation)
一旦主从状态同步完成,它们就进入了命令传播阶段
- 主节点每执行一个写命令,都会异步地将该命令发送给所有连接的副本。
- 副本接收并执行这些命令,从而实时保持与主节点的数据同步。
- 为了维持连接,主从之间会周期性地发送心跳命令(主节点发 PING,副本回 REPLCONF ACK )
涉及的核心命令详解
-
REPLICAOF <master_ip> <master_port> (或 SLAVEOF)
- 作用:由客户端或副本自己执行,用于设置要复制的主节点。执行 REPLICAOF NO ONE 可以使副本节点变回主节点。这是触发整个复制流程的"用户命令"。
-
PSYNC
-
作用:由副本在内部自动发送给主节点,是复制协议的核心命令。
-
参数:
- runid: 副本所记录的主节点的运行 ID。如果是第一次连接,runid 为 ?。
- offset: 副本已接收到的数据偏移量。如果是第一次连接,offset 为 -1。
-
主节点响应:
- +FULLRESYNC : 强制进行全量同步。
- +CONTINUE: 同意进行部分同步。
- -ERR ...: 拒绝同步(例如,runid 不匹配且无法进行部分同步)
-
-
REPLCONF
-
作用:一个用于配置和确认的内部命令。
-
常见子命令:
- REPLCONF listening-port : 副本告知主节点自己的监听端口。
- REPLCONF ip-address : 副本告知主节点自己的 IP 地址。
- REPLCONF capa : 副本告知主节点自己支持的能力(如 eof, psync2)。
- REPLCONF ACK :非常重要,副本周期性地向主节点报告自己已处理的数据偏移量。这既是心跳,也让主节点知道复制的健康状况,并据此判断复制积压缓冲区中的数据是否可以被覆盖。
-
Redis-Shake 伪装成副本的原理和过程
Redis-shake 的核心原理就是完全遵守并实现了上述的 Redis 复制协议,从主节点的视角来看,Redis-shake
就是一个行为标准的 Redis 副本。
-
配置与启动:您在 redis-shake.toml 中配置源 Redis(即 Master)的地址、端口和密码。
-
模拟连接握手:
- Redis-shake 启动后,会像一个真正的副本一样,与源 Redis 建立 TCP 连接。
- 它会发送 PING、AUTH、REPLCONF listening-port 等一系列命令,完成连接的初始化和身份验证。这个过程与真实副本完全一致。
-
发起同步请求:
- 握手成功后,Redis-shake 向源 Redis 发送 PSYNC ? -1,请求进行数据同步。
-
处理数据流(核心区别):
-
源 Redis 收到请求后,开始进行全量同步,并向 Redis-shake 发送 RDB 文件流。
-
关键区别在于:
- 一个真实的 Redis 副本会接收 RDB 数据,并将其加载到自己的内存中。
- Redis-shake 则在接收 RDB数据流时,实时地解析(Parse)这个数据流。它并不把数据加载到自己的内存里,而是根据解析出的键值对(Key-Value),将其转换成目标端需要的格式。
- 例如,如果目标端是另一个 Redis,它就会为每个键值对生成对应的 RESTORE 命令或 SET、HSET等命令,然后发送给目标 Redis。如果目标端是文件,它就会将键值对格式化后写入文件。
-
-
处理增量命令:
- 当 RDB 同步完成后,源 Redis 会进入命令传播阶段,开始向 Redis-shake 发送增量写命令。
- Redis-shake 接收到这些增量命令后,同样不会在自己身上执行,而是将这些命令转换并应用到目标端。
-
维持心跳:
- 在整个同步过程中,Redis-shake 会像一个好学生一样,周期性地向源 Redis 发送 REPLCONF ACK ,报告自己的同步进度,防止连接因超时而中断。
使用方式
Redis-Shake 非常容易上手,而且提供了相当强大的功能,包括自动的全量数据同步以及增量数据同步,相关文档见下面的参考
下载Redis-Shake工具到Linux服务器
保证 Redis-Shake 所在机器能访问 自建Redis机器 以及 阿里云redis代理地址
bash
## 下载地址
https://github.com/tair-opensource/RedisShake/releases-
配置redis-shake
shake.toml 配置文件修改,主要修改sync_reader 以及 redis_writer的配置
ini
[sync_reader]
cluster = false # Set to true if the source is a Redis cluster
address = "127.0.0.1:6379" # For clusters, specify the address of any cluster node; use the master or slave address in master-slave mode
username = "" # Keep empty if ACL is not in use
password = "local@test" # Keep empty if no authentication is required
tls = false # Set to true to enable TLS if needed
sync_rdb = true # Set to false if RDB synchronization is not required
sync_aof = true # Set to false if AOF synchronization is not required
prefer_replica = false # Set to true to sync from a replica node
try_diskless = false # Set to true for diskless sync if the source has repl-diskless-sync=yes
#[scan_reader]
#cluster = false # set to true if source is a redis cluster
#address = "127.0.0.1:6379" # when cluster is true, set address to one of the cluster node
#username = "" # keep empty if not using ACL
#password = "" # keep empty if no authentication is required
#tls = false
#dbs = [] # set you want to scan dbs such as [1,5,7], if you don't want to scan all
#scan = true # set to false if you don't want to scan keys
#ksn = false # set to true to enabled Redis keyspace notifications (KSN) subscription
#count = 1 # number of keys to scan per iteration
# [rdb_reader]
# filepath = "/tmp/dump.rdb"
# [aof_reader]
# filepath = "/tmp/.aof"
# timestamp = 0 # subsecond
[redis_writer]
cluster = false # set to true if target is a redis cluster
address = "云上地址:6379" # when cluster is true, set address to one of the cluster node
username = "" # keep empty if not using ACL
password = "test" # keep empty if no authentication is required
tls = false
off_reply = false # turn off the server reply
# [file_writer]
# filepath = "/tmp/cmd.txt"
# type = "cmd" #cmd,aof,json (default cmd)
[filter]
# Allow keys with specific prefixes or suffixes
# Examples:
# allow_keys = ["user:1001", "product:2001"]
# allow_key_prefix = ["user:", "product:"]
# allow_key_suffix = [":active", ":valid"]
# allow A collection of keys containing 11-digit mobile phone numbers
# allow_key_regex = [":\d{11}:"]
# Leave empty to allow all keys
allow_keys = []
allow_key_prefix = []
allow_key_suffix = []
allow_key_regex = []
# Block keys with specific prefixes or suffixes
# Examples:
# block_keys = ["temp:1001", "cache:2001"]
# block_key_prefix = ["temp:", "cache:"]
# block_key_suffix = [":tmp", ":old"]
# block test 11-digit mobile phone numbers keys
# block_key_regex = [":test:\d{11}:"]
# Leave empty to block nothing
block_keys = []
block_key_prefix = []
block_key_suffix = []
block_key_regex = []
# Specify allowed and blocked database numbers (e.g., allow_db = [0, 1, 2], block_db = [3, 4, 5])
# Leave empty to allow all databases
allow_db = []
block_db = []
# Allow or block specific commands
# Examples:
# allow_command = ["GET", "SET"] # Only allow GET and SET commands
# block_command = ["DEL", "FLUSHDB"] # Block DEL and FLUSHDB commands
# Leave empty to allow all commands
allow_command = []
block_command = []
# Allow or block specific command groups
# Available groups:
# SERVER, STRING, CLUSTER, CONNECTION, BITMAP, LIST, SORTED_SET,
# GENERIC, TRANSACTIONS, SCRIPTING, TAIRHASH, TAIRSTRING, TAIRZSET,
# GEO, HASH, HYPERLOGLOG, PUBSUB, SET, SENTINEL, STREAM
# Examples:
# allow_command_group = ["STRING", "HASH"] # Only allow STRING and HASH commands
# block_command_group = ["SCRIPTING", "PUBSUB"] # Block SCRIPTING and PUBSUB commands
# Leave empty to allow all command groups
allow_command_group = []
block_command_group = []
# Function for custom data processing
# For best practices and examples, visit:
# https://tair-opensource.github.io/RedisShake/zh/filter/function.html
function = ""
[advanced]
dir = "data"
ncpu = 0 # runtime.GOMAXPROCS, 0 means use runtime.NumCPU() cpu cores
pprof_port = 0 # pprof port, 0 means disable
status_port = 0 # status port, 0 means disable
# log
log_file = "shake.log"
log_level = "info" # debug, info or warn
log_interval = 5 # in seconds
log_rotation = true # enable log rotation
log_max_size = 512 # MiB, logs max size to rotate, default 512 MiB
log_max_age = 7 # days, logs are kept, default 7 days
log_max_backups = 3 # number of log backups, default 3
log_compress = true # enable log compression after rotate, default true
# redis-shake gets key and value from rdb file, and uses RESTORE command to
# create the key in target redis. Redis RESTORE will return a "Target key name
# is busy" error when key already exists. You can use this configuration item
# to change the default behavior of restore:
# panic: redis-shake will stop when meet "Target key name is busy" error.
# rewrite: redis-shake will replace the key with new value.
# skip: redis-shake will skip restore the key when meet "Target key name is busy" error.
rdb_restore_command_behavior = "panic" # panic, rewrite or skip
# redis-shake uses pipeline to improve sending performance.
# Adjust this value based on the destination Redis performance:
# - Higher values may improve performance for capable destinations.
# - Lower values are recommended for destinations with poor performance.
# 1024 is a good default value for most cases.
pipeline_count_limit = 1024
# This setting corresponds to the 'client-query-buffer-limit' in Redis configuration.
# The default value is typically 1GB.
# It's recommended not to modify this value unless absolutely necessary.
target_redis_client_max_querybuf_len = 1073741824 # 1GB in bytes
# This setting corresponds to the 'proto-max-bulk-len' in Redis configuration.
# It defines the maximum size of a single string element in the Redis protocol.
# The value must be 1MB or greater. Default is 512MB.
# It's recommended not to modify this value unless absolutely necessary.
target_redis_proto_max_bulk_len = 512_000_000
# If the source is Elasticache, you can set this item. AWS ElastiCache has custom
# psync command, which can be obtained through a ticket.
aws_psync = "" # example: aws_psync = "10.0.0.1:6379@nmfu2sl5osync,10.0.0.1:6379@xhma21xfkssync"
# destination will delete itself entire database before fetching files
# from source during full synchronization.
# This option is similar redis replicas RDB diskless load option:
# repl-diskless-load on-empty-db
empty_db_before_sync = false
[module]
# The data format for BF.LOADCHUNK is not compatible in different versions. v2.6.3 <=> 20603
target_mbbloom_version = 20603-
启动redis-shake
bash
nohup redis-shake ./shake.toml &-
全量数据同步验证
进程启动之后,会自动进行全量数据同步,如上面的原理分析一样,redis-shake会请求源redis进行数据同步,这次因为相当于是新增的redis副本,所以是一次全量的数据同步,源redis会后台进行bgsave生成rdb文件,之后传输给redis-shake, 同时源redis的增量数据会被源redis保存缓存,等待全量数据同步之后,自动会进行增量数据同步
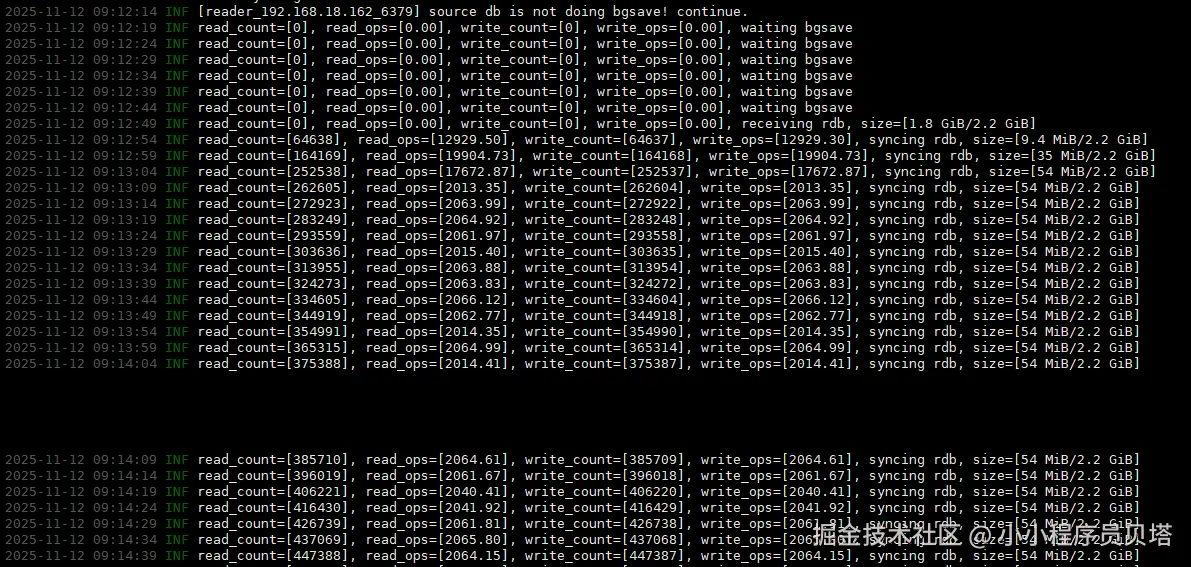
增量数据同步验证
使用 redis-benchmark 模拟增量数据过程,往测试的162的redis 发送1000w的redis的写,
bash
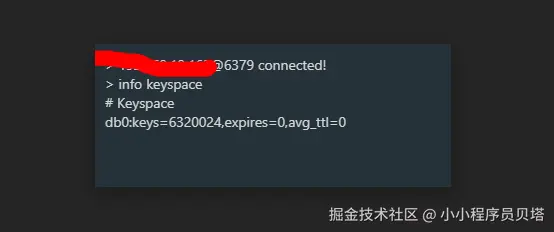
taskset -c 0-7 /usr/local/redis/bin/redis-benchmark -r 10000000 -n 10000000 -t set -h 127.0.0.1 -a 'local@test' -c 8 -d 8 -P 2 本地的redis 实际生成 6320024
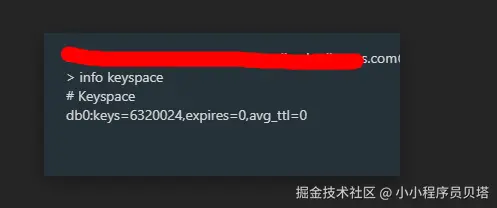
云上redis通过 redis-shake的增量同步也有了 6320024
总结
本文通过一个 Redis 的数据迁移的需求,深入了解了redis的主从同步的过程以及原理,之后调研Redis的数据同步工具,包括 Redis-Shake 和 云厂商提供的同步工具,最后经过动手搭建一个本地的redis ,然后通过redis-shake 工具成功进行数据的全量和增量同步。最后感谢下开源贡献者吧,然后作为开发者的一员,咱们也要多多参与开源
参考
1、Use Redis-shake To Migrate Self-built Redis To Alibaba Cloud