大家好,我是小米,今年 31 岁,干 Java 也干了不少年头。
前阵子我在公司排查一次线上事故,事情特别"离谱":
Redis 正常、代码没改、数据库却 CPU 100%,连接数飙升,服务雪崩式超时。
当时我第一反应是:"是不是缓存挂了?是不是缓存雪崩?"
结果一查 Redis:稳如老狗,命中率还挺高。
那数据库为啥还能被打爆?最后答案四个字:缓存穿透。
这也是 Java 社招面试里,Redis 相关问题出现频率极高的一道题。
先讲个故事:快递站被"查不存在的包裹"查垮了
为了把缓存穿透讲清楚,我先给你讲个生活中的故事。
假设你家楼下有一个快递站:
- 前台:小哥(缓存 Redis)
- 仓库:后面的仓储区(数据库 MySQL)
- 你:用户发起查询请求
正常流程是这样的:
- 你问小哥:"有我这个包裹吗?"
- 小哥一查系统(Redis)
-
- 有 → 直接给你
-
- 没有 → 去仓库查(数据库)
- 仓库查到了 → 拿出来给你
- 同时小哥把信息记下来,下次就不用再跑仓库
但有一天,事情开始不对劲了......突然来了一群人,天天问:
- "有单号 -1 的包裹吗?"
- "有单号 999999999999 的包裹吗?"
- "有单号 0 的包裹吗?"
这些包裹 根本不存在。结果发生了什么?
- 小哥查不到(缓存没有)
- 每次都得跑仓库
- 仓库也查不到
- 但你没有任何机制告诉小哥:这玩意本来就不存在
于是:所有请求,100% 穿过前台,全部打到仓库, 仓库再大,也扛不住这种"查空气"的请求。这,就是缓存穿透。
什么是缓存穿透(面试标准答案)
缓存穿透是指:查询的数据在缓存和数据库中都不存在,导致每次请求都会绕过缓存,直接访问数据库,从而在高并发下对数据库造成巨大压力,甚至导致数据库崩溃。
特点非常明显:
- 查的是 不存在的数据
- 缓存里没有
- 数据库里也没有
- 缓存失效策略对它完全没用
缓存穿透为什么这么危险?
我们用一张表来对比一下几种常见缓存问题:

缓存穿透最恶心的一点是:它是"可被人为制造"的攻击。
只要有人不断请求不存在的 ID,你的数据库就会被持续消耗。
解决方案一:接口层增加基础校验(第一道防线)
先说一句非常现实的话:
很多缓存穿透,本来就不应该进系统。
1、常见的非法请求长这样:
- id <= 0
- id 不是数字
- 用户未登录
- token 非法
- 参数明显不合理
2、在接口层直接拦截
这是最便宜、最有效的一层防护。

如果你连 id <= 0 都放进 Redis 和数据库里查:
- 那不是技术问题
- 是态度问题
3、这一层的特点

但注意: 这一层 永远不够。
解决方案二:缓存空值(key-null 策略)
这是面试里必考的一种方案。
1、核心思想一句话
既然这个数据不存在,那我就明确告诉缓存:它不存在。
2、查询流程升级版
- 查 Redis
-
- 有值 → 返回
-
- 是 null → 直接返回空
- Redis 没有 → 查数据库
- 数据库也没有?
-
- 把 key-null 写进 Redis
-
- 设置较短过期时间,比如 30 秒
3、示例代码

4、为什么过期时间要短?
因为:
- 这个数据 可能未来会被创建
- 如果你缓存 null 一小时
- 那真实数据出现后,用户一小时都查不到
5、优缺点分析

解决方案三:布隆过滤器(终极方案,面试加分项)
如果你在面试中能把 Bloom Filter 讲清楚,面试官大概率会在心里默默给你加分。
1、先回到刚才的快递故事
如果快递站门口有一块 超大的白板:
- 所有可能存在的包裹单号
- 都提前在白板上"打过标记"
那么:
- 你来查一个单号
- 白板一看:根本没标记
- 小哥直接告诉你:不用进站,肯定没有
这块白板,就是 布隆过滤器。
Bitmap 与 Bloom Filter 的极致空间利用
1、Bitmap 是什么?
Bitmap 本质上是:用 1 bit 表示一个元素是否存在

典型应用:
- 用户是否签到
- 某天是否打卡
- 某个 ID 是否出现过
2、Bitmap 的问题

布隆过滤器(Bloom Filter)原理详解
1、核心思想
用多个 Hash 函数,降低冲突概率。 不是一个 Hash,而是 k 个 Hash 函数。
2、工作流程
插入元素时:
- 用 k 个 Hash 函数计算
- 得到 k 个位置
- 把 bitmap 对应位置全部置为 1
查询元素时:
- 只要有 一个 bit 为 0,一定不存在
- 如果全部为 1,可能存在
3、关键结论(面试必背)
- 不存在 → 一定准确
- 存在 → 有一定误判率
为什么 Bloom Filter 能防缓存穿透?
因为:
- 所有 可能存在的数据
- 在系统启动时就已经加入 Bloom Filter
- 请求来了先过 Bloom Filter
请求流程变成:
- 请求进来
- 先查 Bloom Filter
- 不存在 → 直接返回
- 可能存在 → 再查 Redis / DB
数据库终于可以喘口气了。
Bloom Filter 的优缺点总结

Redis 中使用 Bloom Filter(实践建议)
在实际项目中,一般有两种方式:
- 自己实现 Bitmap + Hash
- 使用 RedisBloom 插件
示意代码(简化):

在接口最前面加一层:

三种方案如何组合使用?(标准答案)
真正的生产环境,从来不是"选一个"。 而是:
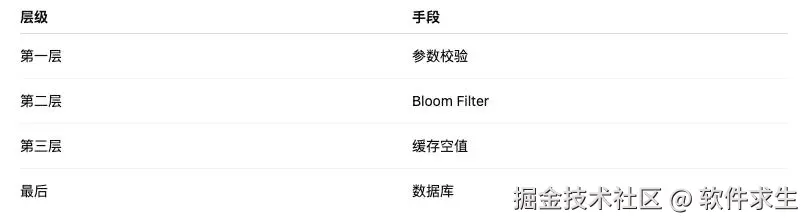
一句话总结:层层过滤,让请求越早死越好。
面试时怎么一句话总结缓存穿透?
你可以这么说:
缓存穿透是指查询缓存和数据库中都不存在的数据,导致请求绕过缓存直接访问数据库。
我通常通过接口参数校验、缓存空值以及使用布隆过滤器三种方式结合解决。
其中布隆过滤器用于从源头拦截不存在的数据,是大规模系统中最常见的方案。
如果你这么说,面试官基本会点头。
总结
缓存穿透这件事,本质上不是 Redis 的问题,而是你有没有认真思考过:哪些请求根本不该进数据库。
数据库很贵,也很脆弱。Redis 再快,也扛不住"查空气"。
END
希望这篇文章,能帮你在面试中稳稳拿下这一题,也能在真实项目里,少踩一次坑。
我是小米,一个喜欢分享技术的31岁程序员。如果你喜欢我的文章,欢迎关注我的微信公众号"软件求生",获取更多技术干货!