文章目录
前言
Kafka 在运维领域的价值:作为高吞吐、低延迟的分布式消息队列,其在日志收集、系统解耦、异步通信、流量削峰等运维核心场景中的不可替代性。
本文主要内容是kafka的入门知识与测试环境部署
一、kafka 核心基础认知
应用场景
- 日志收集与集中处理:将分布式系统中各服务的日志统一采集到 kafka,再转发到 ELK(Elasticsearch+Logstash+Kibana)、Grafana Loki 等平台进行存储、检索与分析。
- 系统解耦与流量削峰:在高并发业务(如电商下单、秒杀)中,用 kafka 作为中间件隔离生产端与消费端,避免下游服务因瞬时流量过载崩溃;生产端快速写入消息,消费端按自身能力异步处理。
- 数据同步与 ETL 管道:作为数据传输通道,实现不同系统间数据同步(如数据库 binlog 同步、业务数据备份),或构建 ETL (抽取 - 转换 - 加载)数据管道,为数据仓库、大数据分析平台提供数据源。MySQL 数据库开启 binlog,通过 Canal 解析 binlog 并发送到 Kafka 主题,数据同步服务消费主题数据,将增量数据同步至 MongoDB、Redis 或数据仓库,支撑实时报表分析。
- 实时消息通信与通知:用于系统内部或跨系统的实时消息传递,如业务通知、系统告警、即时通讯。
- 流处理平台核心组件:作为 Apache Flink、Spark Streaming 等流处理框架的输入 / 输出源,支撑实时计算业务(如实时用户行为分析、实时风控、实时数据指标统计)。短视频平台的实时推荐系统,通过 Kafka 采集用户点击、停留、点赞等行为数据,Flink 消费数据进行实时用户画像计算,将结果推送到推荐引擎,实现个性化内容推送。
二、实验环境搭建与操作
环境搭建
我使用docker-compose搭建测试环境,shell脚本与yaml文件如下
start_kafka.sh
shell
#!/bin/bash
# start-kafka.sh - 自动获取 IP 并启动 Kafka
# 获取当前服务器的 IP 地址
echo "正在获取服务器 IP 地址..."
# 方法1: 使用 hostname -I(Linux)
KAFKA_HOST_IP=$(hostname -I | awk '{print $1}')
# 如果方法1失败,尝试方法2: 使用 ip 命令
if [ -z "$KAFKA_HOST_IP" ] || [ "$KAFKA_HOST_IP" == "" ]; then
KAFKA_HOST_IP=$(ip route get 8.8.8.8 2>/dev/null | awk '{print $7; exit}')
fi
# 如果方法2失败,尝试方法3: 使用 ifconfig
if [ -z "$KAFKA_HOST_IP" ] || [ "$KAFKA_HOST_IP" == "" ]; then
KAFKA_HOST_IP=$(ifconfig | grep -Eo 'inet (addr:)?([0-9]*\.){3}[0-9]*' | grep -Eo '([0-9]*\.){3}[0-9]*' | grep -v '127.0.0.1' | head -1)
fi
# 如果所有方法都失败,使用默认值
if [ -z "$KAFKA_HOST_IP" ] || [ "$KAFKA_HOST_IP" == "" ]; then
echo "⚠️ 无法自动获取 IP 地址,使用默认值 192.168.1.100"
KAFKA_HOST_IP=192.168.1.100
else
echo "✅ 检测到 IP 地址: $KAFKA_HOST_IP"
fi
# 设置环境变量
export KAFKA_HOST_IP
# 显示配置信息
echo ""
echo "=========================================="
echo "Kafka 启动配置"
echo "=========================================="
echo "KAFKA_HOST_IP: $KAFKA_HOST_IP"
echo "Kafka Broker 地址:"
echo " - Broker 1: ${KAFKA_HOST_IP}:9092"
echo " - Broker 2: ${KAFKA_HOST_IP}:9093"
echo " - Broker 3: ${KAFKA_HOST_IP}:9094"
echo "=========================================="
echo ""
# 启动 Docker Compose
echo "正在启动 Kafka 集群..."
docker-compose up -d
# 等待服务启动
echo ""
echo "等待服务启动..."
sleep 5
# 显示服务状态
echo ""
echo "服务状态:"
docker-compose ps
echo ""
echo "✅ Kafka 集群启动完成!"
echo ""
echo "查看日志: docker-compose logs -f"
echo "停止服务: docker-compose down"docker-compose.yaml
yaml
services:
# Zookeeper服务
zookeeper:
image: confluentinc/cp-zookeeper:6.2.1
container_name: zookeeper
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
ports:
- "2181:2181"
volumes:
- zookeeper-data:/var/lib/zookeeper/data
- zookeeper-log:/var/lib/zookeeper/log
networks:
- kafka-network
restart: unless-stopped
healthcheck:
test: ["CMD", "nc", "-z", "localhost", "2181"]
interval: 10s
timeout: 5s
retries: 5
# Kafka节点1
kafka1:
image: confluentinc/cp-kafka:6.2.1
container_name: kafka1
depends_on:
zookeeper:
condition: service_healthy
ports:
- "9092:9092"
- "29092:29092"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
# 监听器配置(重要!修复 NodeNotReadyError 的关键)
# LISTENERS: Kafka 监听的地址(0.0.0.0 表示监听所有网络接口)
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:29092,PLAINTEXT_HOST://0.0.0.0:9092
# ADVERTISED_LISTENERS: 客户端连接时使用的地址(必须使用可路由的 IP,不能使用 0.0.0.0)
# 使用环境变量 KAFKA_HOST_IP,如果未设置则使用默认值 192.168.1.100
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka1:29092,PLAINTEXT_HOST://${KAFKA_HOST_IP:-192.168.1.100}:9092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
# 日志配置
KAFKA_LOG_RETENTION_HOURS: 168
KAFKA_LOG_SEGMENT_BYTES: "1073741824" # 1GB
# 网络配置
KAFKA_NUM_NETWORK_THREADS: 8
KAFKA_NUM_IO_THREADS: 16
volumes:
- kafka1-data:/var/lib/kafka/data
networks:
- kafka-network
restart: unless-stopped
healthcheck:
test: ["CMD", "kafka-broker-api-versions", "--bootstrap-server", "localhost:9092"]
interval: 30s
timeout: 10s
retries: 5
start_period: 60s # 给 Kafka 60 秒启动时间
# Kafka节点2
kafka2:
image: confluentinc/cp-kafka:6.2.1
container_name: kafka2
depends_on:
zookeeper:
condition: service_healthy
ports:
- "9093:9093"
- "29093:29093"
environment:
KAFKA_BROKER_ID: 2
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
# 监听器配置(重要!修复 NodeNotReadyError 的关键)
# LISTENERS: Kafka 监听的地址(0.0.0.0 表示监听所有网络接口)
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:29093,PLAINTEXT_HOST://0.0.0.0:9093
# ADVERTISED_LISTENERS: 客户端连接时使用的地址(必须使用可路由的 IP,不能使用 0.0.0.0)
# 使用环境变量 KAFKA_HOST_IP,如果未设置则使用默认值 192.168.1.100
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka2:29093,PLAINTEXT_HOST://${KAFKA_HOST_IP:-192.168.1.100}:9093
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
# 日志配置
KAFKA_LOG_RETENTION_HOURS: 168
KAFKA_LOG_SEGMENT_BYTES: "1073741824" # 1GB
# 网络配置
KAFKA_NUM_NETWORK_THREADS: 8
KAFKA_NUM_IO_THREADS: 16
volumes:
- kafka2-data:/var/lib/kafka/data
networks:
- kafka-network
restart: unless-stopped
healthcheck:
test: ["CMD", "kafka-broker-api-versions", "--bootstrap-server", "localhost:9093"]
interval: 30s
timeout: 10s
retries: 5
start_period: 60s
# Kafka节点3
kafka3:
image: confluentinc/cp-kafka:6.2.1
container_name: kafka3
depends_on:
zookeeper:
condition: service_healthy
ports:
- "9094:9094"
- "29094:29094"
environment:
KAFKA_BROKER_ID: 3
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
# 监听器配置(重要!修复 NodeNotReadyError 的关键)
# LISTENERS: Kafka 监听的地址(0.0.0.0 表示监听所有网络接口)
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:29094,PLAINTEXT_HOST://0.0.0.0:9094
# ADVERTISED_LISTENERS: 客户端连接时使用的地址(必须使用可路由的 IP,不能使用 0.0.0.0)
# 使用环境变量 KAFKA_HOST_IP,如果未设置则使用默认值 192.168.1.100
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka3:29094,PLAINTEXT_HOST://${KAFKA_HOST_IP:-192.168.1.100}:9094
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
# 日志配置
KAFKA_LOG_RETENTION_HOURS: 168
KAFKA_LOG_SEGMENT_BYTES: "1073741824" # 1GB
# 网络配置
KAFKA_NUM_NETWORK_THREADS: 8
KAFKA_NUM_IO_THREADS: 16
volumes:
- kafka3-data:/var/lib/kafka/data
networks:
- kafka-network
restart: unless-stopped
healthcheck:
test: ["CMD", "kafka-broker-api-versions", "--bootstrap-server", "localhost:9094"]
interval: 30s
timeout: 10s
retries: 5
start_period: 60s
networks:
kafka-network:
driver: bridge
volumes:
zookeeper-data:
zookeeper-log:
kafka1-data:
kafka2-data:
kafka3-data:
shell
bash start_kafka.sh
shell
root@DESKTOP-OID70B2:/data/container/kafka# docker compose ps
NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS
kafka1 confluentinc/cp-kafka:6.2.1 "/etc/confluent/dock..." kafka1 13 minutes ago Up 12 minutes (healthy) 0.0.0.0:9092->9092/tcp, [::]:9092->9092/tcp, 0.0.0.0:29092->29092/tcp, [::]:29092->29092/tcp
kafka2 confluentinc/cp-kafka:6.2.1 "/etc/confluent/dock..." kafka2 13 minutes ago Up 12 minutes (healthy) 0.0.0.0:9093->9093/tcp, [::]:9093->9093/tcp, 9092/tcp, 0.0.0.0:29093->29093/tcp, [::]:29093->29093/tcp
kafka3 confluentinc/cp-kafka:6.2.1 "/etc/confluent/dock..." kafka3 13 minutes ago Up 12 minutes (healthy) 0.0.0.0:9094->9094/tcp, [::]:9094->9094/tcp, 9092/tcp, 0.0.0.0:29094->29094/tcp, [::]:29094->29094/tcp
zookeeper confluentinc/cp-zookeeper:6.2.1 "/etc/confluent/dock..." zookeeper 13 minutes ago Up 13 minutes (healthy) 2888/tcp, 0.0.0.0:2181->2181/tcp, [::]:2181->2181/tcp, 3888/tcp有些环境是用docker-compose 的命令是
docker-compose up -d,有些则是docker compose up -d;根据自己的环境进行修改 start_kafka.sh 就行。
环境验证
我的集群信息为
192.168.1.100:9092,192.168.1.100:9093,192.168.1.100:9094,将 192.168.1.100 这个IP 换成你们自己服务器的IP就行,是服务器的IP,不是容器的。
创建topic
shell
kafka-topics --bootstrap-server 192.168.1.100:9092,192.168.1.100:9093,192.168.1.100:9094 --create --topic test-topic --partitions 3 --replication-factor 2查看结果
shell
kafka-topics --bootstrap-server 192.168.1.100:9092,192.168.1.100:9093,192.168.1.100:9094 --list | grep test-topic创建消息
- python 版本为 3.11
- 安装第三方库:pip install kafka-python
注意将代码中的集群地址(BOOTSTRAP_SERVERS)换成自己的
confluentinc/cp-kafka:6.2.1中 kafka 的版本为 2.13
生产者 produce.py
python
"""
Kafka 消息堆积测试 - 快速生产者
用于模拟消息堆积场景,快速发送大量消息
"""
import json
import time
from kafka import KafkaAdminClient, KafkaProducer
from kafka.errors import KafkaError, KafkaTimeoutError, NoBrokersAvailable
# Kafka集群地址
BOOTSTRAP_SERVERS = "192.168.1.100:9092,192.168.1.100:9093,192.168.1.100:9094"
# 创建生产者(快速发送模式)
producer = KafkaProducer(
bootstrap_servers=BOOTSTRAP_SERVERS,
# JSON序列化器
value_serializer=lambda v: json.dumps(v).encode('utf-8'),
key_serializer=lambda k: k.encode('utf-8') if k else None,
# 确认机制:使用0(最快,不等待确认)
acks='all', # 快速发送模式
# 不重试,快速失败
retries=3,
# 批量发送配置(提高发送速度)
batch_size=32768, # 32KB,更大的批次
linger_ms=0, # 立即发送,不等待
# 压缩方式
compression_type='gzip',
# 超时配置
request_timeout_ms=30000,
# 提高吞吐量
buffer_memory=67108864, # 64MB
)
def send_batch_messages(topic, num_messages, interval=0.01, batch_size=100):
"""
批量快速发送消息
参数:
topic: Topic名称
num_messages: 要发送的消息总数
interval: 每条消息之间的间隔(秒),默认0.01秒(每秒100条)
batch_size: 每批发送的消息数
"""
print(f"开始快速发送 {num_messages} 条消息到 Topic: {topic}")
print(f"发送间隔: {interval} 秒 (约 {int(1/interval)} 条/秒)")
print(f"批量大小: {batch_size}")
print("=" * 60)
start_time = time.time()
sent_count = 0
failed_count = 0
try:
for i in range(num_messages):
# 生成消息数据
message_data = {
"message_id": f"msg_{i:06d}",
"content": f"这是第 {i} 条消息 - 用于测试消息堆积",
"timestamp": time.time(),
"batch_id": i // batch_size,
"sequence": i % batch_size
}
try:
# 异步发送(不等待确认)
future = producer.send(topic, value=message_data, key=f"key_{i % 10}")
# 每 batch_size 条消息刷新一次
if (i + 1) % batch_size == 0:
producer.flush()
sent_count += batch_size
elapsed = time.time() - start_time
rate = sent_count / elapsed if elapsed > 0 else 0
print(f"📤 已发送 {sent_count}/{num_messages} 条消息 "
f"(速率: {rate:.1f} 条/秒, 耗时: {elapsed:.2f}秒)")
# 发送间隔(控制发送速度)
if interval > 0:
time.sleep(interval)
except Exception as e:
failed_count += 1
if failed_count <= 5: # 只打印前5个错误
print(f"❌ 发送消息失败: {e}")
# 最后刷新一次,确保所有消息都发送
producer.flush()
sent_count = num_messages - failed_count
total_time = time.time() - start_time
avg_rate = sent_count / total_time if total_time > 0 else 0
print("\n" + "=" * 60)
print("✅ 发送完成")
print(f" 总消息数: {num_messages}")
print(f" 成功发送: {sent_count}")
print(f" 失败: {failed_count}")
print(f" 总耗时: {total_time:.2f} 秒")
print(f" 平均速率: {avg_rate:.1f} 条/秒")
print("=" * 60)
except KeyboardInterrupt:
print("\n\n⚠️ 用户中断发送")
producer.flush()
except Exception as e:
print(f"\n❌ 发送过程中出错: {e}")
producer.flush()
def send_continuous_messages(topic, rate_per_second=100, duration=60):
"""
持续发送消息(持续一段时间)
参数:
topic: Topic名称
rate_per_second: 每秒发送的消息数
duration: 持续时间(秒)
"""
interval = 1.0 / rate_per_second
estimated_messages = int(rate_per_second * duration)
print(f"开始持续发送消息")
print(f"Topic: {topic}")
print(f"发送速率: {rate_per_second} 条/秒")
print(f"持续时间: {duration} 秒")
print(f"预计发送: {estimated_messages} 条消息")
print("=" * 60)
start_time = time.time()
sent_count = 0
next_report_time = start_time + 10 # 每10秒报告一次
try:
while time.time() - start_time < duration:
message_data = {
"message_id": f"cont_msg_{sent_count:08d}",
"content": f"持续发送消息 #{sent_count} - 用于测试消息堆积",
"timestamp": time.time(),
"elapsed": time.time() - start_time
}
try:
producer.send(topic, value=message_data, key=f"key_{sent_count % 10}")
sent_count += 1
# 每100条刷新一次
if sent_count % 100 == 0:
producer.flush()
# 定期报告
current_time = time.time()
if current_time >= next_report_time:
elapsed = current_time - start_time
rate = sent_count / elapsed if elapsed > 0 else 0
print(f"📊 [{elapsed:.0f}s] 已发送 {sent_count} 条消息 "
f"(速率: {rate:.1f} 条/秒)")
next_report_time = current_time + 10
time.sleep(interval)
except Exception as e:
print(f"❌ 发送消息失败: {e}")
time.sleep(1) # 出错后等待1秒
# 最后刷新
producer.flush()
total_time = time.time() - start_time
avg_rate = sent_count / total_time if total_time > 0 else 0
print("\n" + "=" * 60)
print("✅ 持续发送完成")
print(f" 总消息数: {sent_count}")
print(f" 总耗时: {total_time:.2f} 秒")
print(f" 平均速率: {avg_rate:.1f} 条/秒")
print("=" * 60)
except KeyboardInterrupt:
print("\n\n⚠️ 用户中断发送")
producer.flush()
if __name__ == "__main__":
import sys
topic_name = "test-topic"
# 检查 Topic 是否存在
try:
admin = KafkaAdminClient(
bootstrap_servers=BOOTSTRAP_SERVERS,
request_timeout_ms=10000
)
topics = admin.list_topics()
if topic_name not in topics:
print(f"⚠️ Topic '{topic_name}' 不存在")
print(" 请先创建 Topic: python create_topic.py")
admin.close()
exit(1)
admin.close()
except Exception as e:
print(f"❌ 检查 Topic 失败: {e}")
exit(1)
print("\n" + "=" * 60)
print("Kafka 消息堆积测试 - 快速生产者")
print("=" * 60)
print("\n请选择发送模式:")
print("1. 批量发送模式(快速发送指定数量的消息)")
print("2. 持续发送模式(持续发送一段时间)")
try:
choice = input("\n请输入选择 (1 或 2,默认1): ").strip()
if choice == "2":
# 持续发送模式
rate = input("请输入每秒发送的消息数 (默认100): ").strip()
rate = int(rate) if rate else 100
duration = input("请输入持续时间(秒,默认60): ").strip()
duration = int(duration) if duration else 60
send_continuous_messages(topic_name, rate_per_second=rate, duration=duration)
else:
# 批量发送模式(默认)
num_messages = input("请输入要发送的消息数量 (默认1000): ").strip()
num_messages = int(num_messages) if num_messages else 1000
interval = input("请输入发送间隔(秒,默认0.01,即每秒100条): ").strip()
interval = float(interval) if interval else 0.01
send_batch_messages(topic_name, num_messages=num_messages, interval=interval)
except KeyboardInterrupt:
print("\n\n用户中断")
except ValueError:
print("❌ 输入格式错误,请使用数字")
except Exception as e:
print(f"\n❌ 发生错误: {e}")
finally:
producer.close()
print("\n生产者已关闭")消费组 consumer.py
python
"""
Kafka 消息堆积测试 - 慢速消费者
用于模拟消费速度慢于生产速度的场景,观察消息堆积
设计原则:
1. 每次只处理1条消息,处理完立即回到主循环调用 poll()
2. 确保主循环的 poll() 调用间隔不超过 max_poll_interval_ms
3. 避免批量处理期间长时间阻塞主线程
"""
from kafka import KafkaConsumer
from kafka.errors import KafkaError
try:
from kafka.consumer.subscription_state import ConsumerRebalanceListener
except ImportError:
try:
from kafka.consumer import ConsumerRebalanceListener
except ImportError:
class ConsumerRebalanceListener:
def on_partitions_revoked(self, revoked):
pass
def on_partitions_assigned(self, assigned):
pass
import json
import time
# Kafka集群地址
BOOTSTRAP_SERVERS = "192.168.1.100:9092,192.168.1.100:9093,192.168.1.100:9094"
def safe_deserialize(value_bytes):
"""
安全的反序列化函数
尝试解析 JSON,如果失败则返回原始字符串
"""
if value_bytes is None:
return None
try:
decoded = value_bytes.decode('utf-8')
try:
return json.loads(decoded)
except json.JSONDecodeError:
return decoded
except Exception as e:
return str(value_bytes)
class RebalanceListener(ConsumerRebalanceListener):
"""重平衡事件监听器"""
def __init__(self):
self.rebalance_count = 0
self.rebalance_events = []
def on_partitions_revoked(self, revoked):
"""分区被撤销时调用"""
self.rebalance_count += 1
event_time = time.time()
self.rebalance_events.append(('revoked', event_time, revoked))
print(f"\n{'='*60}")
print(f"⚠️ [重平衡 #{self.rebalance_count}] 分区被撤销 ({time.strftime('%H:%M:%S', time.localtime(event_time))}):")
if revoked:
for p in revoked:
print(f" - {p.topic}[{p.partition}]")
else:
print(" (无分区)")
print(f"{'='*60}\n")
def on_partitions_assigned(self, assigned):
"""分区被分配时调用"""
event_time = time.time()
self.rebalance_events.append(('assigned', event_time, assigned))
print(f"\n{'='*60}")
print(f"✅ [重平衡 #{self.rebalance_count}] 分区被分配 ({time.strftime('%H:%M:%S', time.localtime(event_time))}):")
if assigned:
for p in assigned:
print(f" - {p.topic}[{p.partition}]")
else:
print(" (无分区)")
print(f"{'='*60}\n")
def create_consumer(topic, group_id, consume_delay=1.0, manual_commit=False):
"""
创建消费者
参数:
topic: Topic名称
group_id: 消费者组ID
consume_delay: 每条消息处理延迟(秒)
manual_commit: 是否手动提交
"""
rebalance_listener = RebalanceListener()
consumer = KafkaConsumer(
topic,
bootstrap_servers=BOOTSTRAP_SERVERS,
group_id=group_id,
auto_offset_reset='earliest',
enable_auto_commit=not manual_commit,
auto_commit_interval_ms=3000 if not manual_commit else None, # ✅ 3秒提交一次(更频繁的提交有助于保持连接活跃)
value_deserializer=safe_deserialize,
key_deserializer=lambda k: k.decode('utf-8') if k else None,
# 关键配置:确保不会超时
session_timeout_ms=30000, # 30秒会话超时
heartbeat_interval_ms=10000, # ✅ 10秒心跳间隔(session_timeout_ms 的 1/3,避免心跳压力过大)
max_poll_records=1, # ✅ 每次只拉取1条消息
max_poll_interval_ms=300000, # 5分钟最大轮询间隔(处理1条消息约1秒,远小于5分钟)
request_timeout_ms=40000, # 必须大于 session_timeout_ms
metadata_max_age_ms=300000,
)
consumer.subscribe([topic], listener=rebalance_listener)
return consumer, rebalance_listener
def process_message(message_data, delay, verbose=False):
"""
处理消息(模拟业务处理)
参数:
message_data: 消息内容
delay: 处理延迟(秒)
verbose: 是否详细输出
"""
if verbose:
if isinstance(message_data, dict):
msg_id = message_data.get('message_id', 'N/A')
print(f" ⏳ 处理中: {msg_id}...")
else:
print(f" ⏳ 处理中...")
# 模拟业务处理时间
time.sleep(delay)
if verbose:
if isinstance(message_data, dict):
msg_id = message_data.get('message_id', 'N/A')
print(f" ✅ 完成: {msg_id}")
else:
print(f" ✅ 完成")
def consume_slowly(topic, group_id='slow-consumer-group', consume_delay=1.0, manual_commit=False):
"""
慢速消费消息
核心设计:
- 每次只拉取1条消息
- 处理完立即回到主循环调用 poll()
- 确保主循环的 poll() 调用间隔不超过1秒(处理时间)+ 网络延迟
参数:
topic: Topic名称
group_id: 消费者组ID
consume_delay: 每条消息处理延迟(秒)
manual_commit: 是否手动提交
"""
consumer, rebalance_listener = create_consumer(topic, group_id, consume_delay, manual_commit)
print("=" * 60)
print("Kafka 消息堆积测试 - 慢速消费者")
print("=" * 60)
print(f"Topic: {topic}")
print(f"消费者组: {group_id}")
print(f"处理延迟: {consume_delay} 秒/条")
print(f"预计消费速率: {1/consume_delay:.2f} 条/秒")
print(f"提交方式: {'手动提交' if manual_commit else '自动提交(每3秒)'}")
print(f"配置:")
print(f" max_poll_records: 1(每次1条)")
print(f" max_poll_interval_ms: 300000(5分钟)")
print(f" session_timeout_ms: 30000(30秒)")
print("=" * 60)
# 等待分区分配
print("\n等待分区分配...")
time.sleep(3)
assigned = consumer.assignment()
print(f"\n✅ 分配到的分区: {len(assigned)} 个")
for p in assigned:
print(f" - {p.topic}[{p.partition}]")
if not assigned:
print(" ⚠️ 警告: 未分配到任何分区!")
print(" 可能原因:")
print(" 1. Topic 不存在")
print(" 2. 有其他消费者占用了所有分区")
print(" 3. 正在重平衡中...")
print("\n开始消费消息...")
print("提示: 按 Ctrl+C 停止")
print("=" * 60)
# 统计变量
message_count = 0
start_time = time.time()
last_poll_time = start_time
poll_intervals = []
process_times = []
try:
while True:
# ✅ 核心设计:每次只拉取1条消息
poll_start = time.time()
# 计算两次 poll() 之间的间隔
if message_count > 0:
poll_interval = poll_start - last_poll_time
poll_intervals.append(poll_interval)
if poll_interval > 2.0: # 如果间隔超过2秒,发出警告
print(f"\n⚠️ [调试] poll() 间隔: {poll_interval:.2f}秒")
# 拉取消息(最多等待1秒)
message_batch = consumer.poll(timeout_ms=1000, max_records=1)
poll_end = time.time()
last_poll_time = poll_end
# 如果没有消息,继续下一次 poll()(保持心跳)
if not message_batch:
continue
# 处理消息(每次只有1条)
for topic_partition, messages in message_batch.items():
for message in messages:
message_count += 1
process_start = time.time()
# 显示消息信息
if message_count <= 5 or message_count % 50 == 0:
print(f"\n📨 消息 #{message_count}: Partition={message.partition}, Offset={message.offset}")
# 处理消息
try:
process_message(
message.value,
consume_delay,
verbose=(message_count <= 5 or message_count % 50 == 0)
)
except Exception as e:
print(f"⚠️ 处理失败: {e}")
process_end = time.time()
process_time = process_end - process_start
process_times.append(process_time)
# 手动提交(如果启用)
if manual_commit:
try:
consumer.commit()
except Exception as e:
print(f"⚠️ 提交失败: {e}")
# ✅ 关键:处理完1条消息后,立即回到主循环调用 poll()
# 这样确保主循环的 poll() 调用间隔不超过(处理时间 + 网络延迟)
# 每10条消息报告一次统计
if message_count % 10 == 0:
elapsed = time.time() - start_time
rate = message_count / elapsed if elapsed > 0 else 0
avg_process = sum(process_times[-10:]) / len(process_times[-10:]) if process_times else 0
avg_poll_interval = sum(poll_intervals[-10:]) / len(poll_intervals[-10:]) if poll_intervals else 0
print(f"\n📊 统计 (#{message_count}):")
print(f" 消费速率: {rate:.2f} 条/秒")
print(f" 平均处理时间: {avg_process:.3f}秒/条")
print(f" 平均poll间隔: {avg_poll_interval:.3f}秒")
print(f" 重平衡次数: {rebalance_listener.rebalance_count}")
if rebalance_listener.rebalance_count > 0 and rebalance_listener.rebalance_events:
last_event = rebalance_listener.rebalance_events[-1]
time_since_rebalance = time.time() - last_event[1]
print(f" 距上次重平衡: {time_since_rebalance:.2f}秒")
except KeyboardInterrupt:
print("\n\n⚠️ 收到停止信号...")
except Exception as e:
print(f"\n❌ 错误: {e}")
import traceback
traceback.print_exc()
finally:
# 关闭前提交
if manual_commit:
try:
consumer.commit()
except:
pass
consumer.close()
# 最终统计
total_time = time.time() - start_time
avg_rate = message_count / total_time if total_time > 0 else 0
print("\n" + "=" * 60)
print("✅ 消费者已关闭")
print(f" 总消费: {message_count} 条")
print(f" 总耗时: {total_time:.2f} 秒")
print(f" 平均速率: {avg_rate:.2f} 条/秒")
print(f" 重平衡次数: {rebalance_listener.rebalance_count}")
if poll_intervals:
print(f"\n[调试] poll() 间隔统计:")
print(f" 平均: {sum(poll_intervals)/len(poll_intervals):.3f}秒")
print(f" 最大: {max(poll_intervals):.3f}秒")
print(f" 最小: {min(poll_intervals):.3f}秒")
if process_times:
print(f"\n[调试] 处理时间统计:")
print(f" 平均: {sum(process_times)/len(process_times):.3f}秒/条")
print(f" 最大: {max(process_times):.3f}秒")
print(f" 最小: {min(process_times):.3f}秒")
if rebalance_listener.rebalance_events:
print(f"\n[调试] 重平衡事件(最后5次):")
for i, (event_type, event_time, partitions) in enumerate(rebalance_listener.rebalance_events[-5:], 1):
time_str = time.strftime('%H:%M:%S', time.localtime(event_time))
parts_str = ', '.join([f'{p.topic}[{p.partition}]' for p in partitions]) if partitions else '(无)'
print(f" {i}. {event_type.upper()}: {time_str} - {parts_str}")
print("=" * 60)
if __name__ == "__main__":
topic_name = "test-topic"
print("\n" + "=" * 60)
print("Kafka 消息堆积测试 - 慢速消费者")
print("=" * 60)
try:
group_id = input("请输入消费者组ID (默认: slow-consumer-group): ").strip()
group_id = group_id if group_id else 'slow-consumer-group'
delay_str = input("请输入每条消息处理延迟(秒,默认1.0): ").strip()
consume_delay = float(delay_str) if delay_str else 1.0
commit_mode = input("偏移量提交方式 (1=自动提交, 2=手动提交,默认1): ").strip()
manual_commit = (commit_mode == "2")
print(f"\n配置:")
print(f" Topic: {topic_name}")
print(f" 消费者组: {group_id}")
print(f" 处理延迟: {consume_delay} 秒/条")
print(f" 提交方式: {'手动提交' if manual_commit else '自动提交'}")
confirm = input("\n确认开始? (y/n,默认y): ").strip().lower()
if confirm and confirm != 'y':
print("已取消")
exit(0)
consume_slowly(topic_name, group_id=group_id, consume_delay=consume_delay, manual_commit=manual_commit)
except KeyboardInterrupt:
print("\n\n用户中断")
except ValueError:
print("❌ 输入格式错误")
except Exception as e:
print(f"\n❌ 错误: {e}")
import traceback
traceback.print_exc()运行
shell
>> python product.py
============================================================
Kafka 消息堆积测试 - 快速生产者
============================================================
请选择发送模式:
1. 批量发送模式(快速发送指定数量的消息)
2. 持续发送模式(持续发送一段时间)
请输入选择 (1 或 2,默认1): 2
请输入每秒发送的消息数 (默认100): 10
请输入持续时间(秒,默认60): 5
开始持续发送消息
Topic: test-topic
发送速率: 10 条/秒
持续时间: 5 秒
预计发送: 50 条消息
============================================================
============================================================
✅ 持续发送完成
总消息数: 50
总耗时: 5.06 秒
平均速率: 9.9 条/秒
============================================================
生产者已关闭
>> python consumer.py
============================================================
Kafka 消息堆积测试 - 慢速消费者
============================================================
请输入消费者组ID (默认: slow-consumer-group):
请输入每条消息处理延迟(秒,默认1.0):
偏移量提交方式 (1=自动提交, 2=手动提交[推荐],默认1):
配置信息:
Topic: test-topic
消费者组: slow-consumer-group
处理延迟: 1.0 秒/条
预计消费速率: 1.00 条/秒
偏移量提交: 自动提交(每1秒提交一次)
确认开始消费? (y/n,默认y):
============================================================
Kafka 消息堆积测试 - 慢速消费者
============================================================
Topic: test-topic
消费者组: slow-consumer-group
处理延迟: 1.0 秒/条
预计消费速率: 1.00 条/秒
偏移量提交: 自动提交(每1秒提交一次)
============================================================
开始消费消息...
提示: 按 Ctrl+C 停止消费
============================================================
📨 收到消息 #1:
Topic: test-topic
Partition: 1
Offset: 2508
Key: key_1
Timestamp: 1762478359024
⏳ 正在处理消息: cont_msg_00000001...
✅ 消息处理完成: cont_msg_00000001
内容摘要: 持续发送消息 #1 - 用于测试消息堆积...若生产者成功生产了消息,消费者成功消费了消息则环境搭建完成
核心组件认知
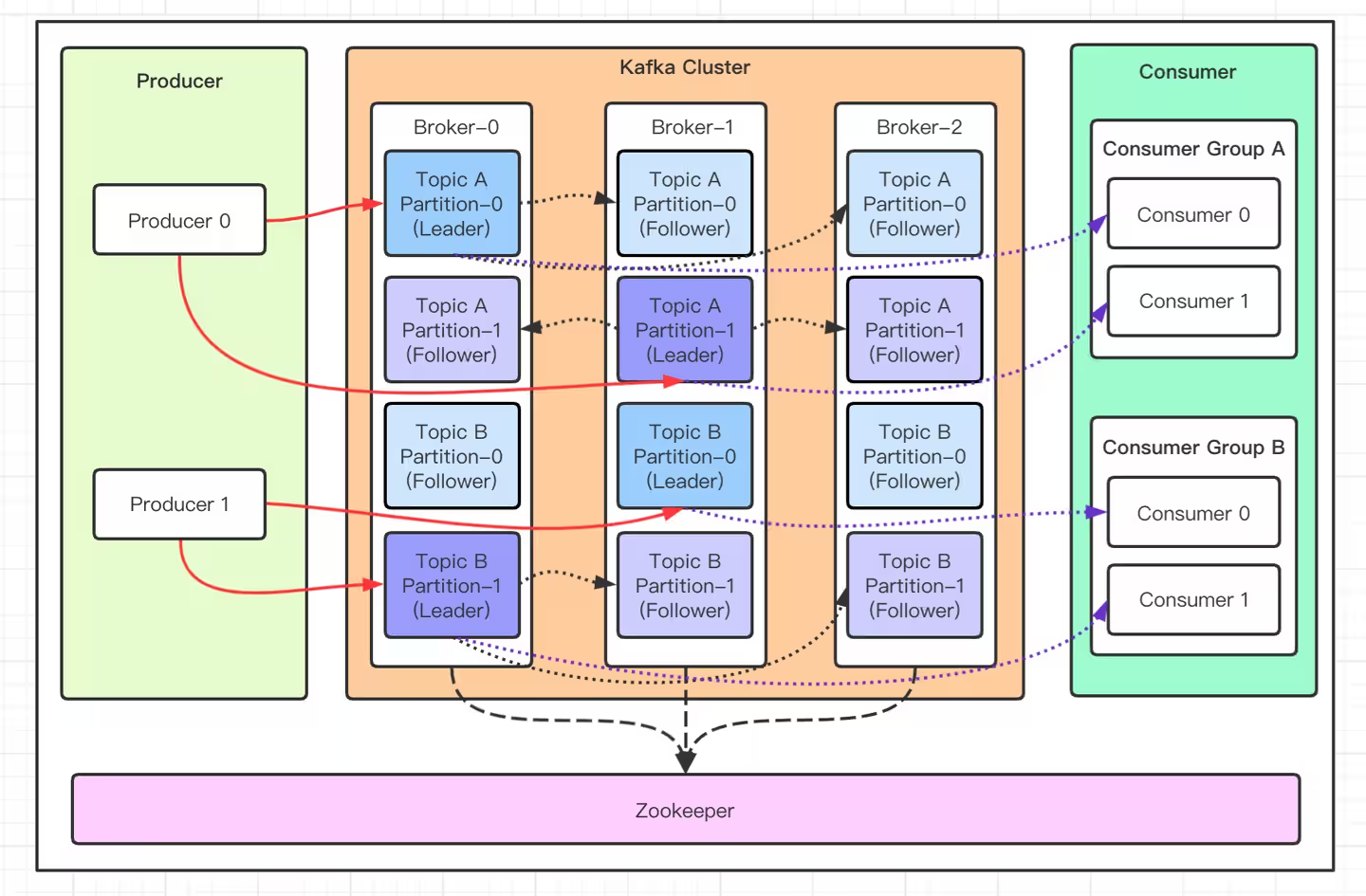
- Broker:单个 Kafka 节点,就是一个完整的、运行的 kafka 程序。
命令行中 --bootstrap-server 或 --broker-list 指的就是这个,有多个节点则用
,隔开
- 生产者与消费者:
生产者指的是像kafka发送消息的部分,常见的就有手机中的软件客户端,当我们下单、订购商品时都是在产生消息并发完服务端。
消费者指的是下单、订购业务的后端程序,部署在服务器上
kafka 只是一个中转站,在我们搭建环境时给了一个示例程序,可以用那个简单的程序理解kafka是如何工作的。
- 首先手动在kafka集群上手动创建一个topic
- 执行 produce.py 在指定 topic 上发送消息
- 执行 consumer.py 在指定 topic 上读取消息并处理
- Topic 与分区:
以上面我创建的topic为例
shell
[appuser@a9cbf226832f ~]$ kafka-topics --bootstrap-server 192.168.1.100:9092,192.168.1.100:9093,192.168.1.100:9094 --describe --topic test-topic
Topic: test-topic TopicId: fC5exNTCTkm5QORGIPiDfA PartitionCount: 3 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: test-topic Partition: 0 Leader: 2 Replicas: 2,3,1 Isr: 2,1,3
Topic: test-topic Partition: 1 Leader: 3 Replicas: 3,1,2 Isr: 2,3,1
Topic: test-topic Partition: 2 Leader: 1 Replicas: 1,2,3 Isr: 2,3,1topic 是一类消息的集合,假设事先指定 test-topic 为存储下单业务的请求信息,每当有下单信息,生产者则将其发送到 test-topic 上,然后消费者就 读取test-topic 的消息并处理。
分区(Partition) :分区是 Kafka 并行处理和存储的基本单位。一个主题的多个分区可以分布在不同的 Broker 上,实现负载均衡和水平扩展。消息被顺序写入分区,并以分区为单位进行复制。这个topic的分区有三个,意味着 topic 的消息被 分成了三个独立的、并行的 "数据通道" 来存储和处理。
副本(Replicas):副本是 Kafka 保证高可用性和数据冗余的关键,Kafka 会为每个分区创建多个副本。当一个副本所在的 Broker 宕机时,其他正常的副本可以接替其工作,确保服务不中断。
副本是以分区为单位的,在该例子中,配置了三个分区、三个副本,意思是一个分区有三个副本,总共有 3 x 3 = 9 个副本
另外副本也有主副本(Leader Replicas)与从副本(Follower Replicas)的区别,平时生产者与消费者操作的都是主副本,从副本用于备份,在主副本不可用时,则使用从副本,防止数据的丢失。
以下面这个为例
Topic: test-topic Partition: 0 Leader: 2 Replicas: 2,3,1 Isr: 2,1,3这代表test-topic 的0号分区的主副本存储在 broker ID 为 2 的kakfa节点上,Replicas 后面则是表示该分区的所有 副本所在的broker ID 列表 (定义了该分区的数据需要同步到哪些 Broker 上),ISR 则表示与主副本保持了正常同步的副本所在的 broker ID 列表
- 消费者与消费者组:消费者是以消费者组(由一个或者多个消费者组成)为基本单元与服务端进行交互的。
在实际使用中,为了有更高的并发处理能力,通常会有很多个消费者一起消费消息。为了让各个消费者可以更好地合作,通常手动将功能一样的消费者放到一个组中,统一进行管理。如test-topic 的消费组名指定为 slow-consumer-group,后面的 CONSUMER-ID 标识着一个消费者实例。
消费者组的作用是将分区分配给消费者与管理消费者,一个消费者通常会有若干个分区,但一个分区只能被分配给一个消费者(防止重复消费)。
shell
[appuser@a9cbf226832f ~]$ kafka-consumer-groups --bootstrap-server 192.168.1.100:9092,192.168.1.100:9093,192.168.1.100:9094 --describe --group slow-consumer-group
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
slow-consumer-group test-topic 0 7227 7227 0 kafka-python-2.2.15-7e03695c-aa38-47bf-b9b1-58410f08fa02 /192.168.1.4 kafka-python-2.2.15
slow-consumer-group test-topic 1 4836 4836 0 kafka-python-2.2.15-7e03695c-aa38-47bf-b9b1-58410f08fa02 /192.168.1.4 kafka-python-2.2.15
slow-consumer-group test-topic 2 12028 12028 0 kafka-python-2.2.15-7e03695c-aa38-47bf-b9b1-58410f08fa02 /192.168.1.4 kafka-python-2.2.15而且通过消费者组可以看到下面这些
- 偏移量(Offset):Kafka 中每个 Topic 的分区是有序的消息队列,偏移量(Offset)是分区内每条消息的唯一序号(从 0 开始递增),用于标记消息在分区中的位置,也是消费者组记录消费进度的核心依据。
- CURRENT-OFFSET(当前偏移量) :代表当前消费者组针对该分区,下一条要读取的消息对应的偏移量。注意:它不是 "最后一条已消费消息" 的偏移量 ------ 比如若已消费到偏移量 7226 的消息,下一条要读 7227,此时该字段值就是 7227。
- LOG-END-OFFSET(日志末端偏移量): 代表该分区在 Broker 端最新一条已写入消息的偏移量,也就是分区当前的消息 "末尾位置",反映了生产者最新的消息写入进度。
- LAG(消费滞后量) 即消费端与生产端的消息差距,计算公式为:
LAG = LOG-END-OFFSET - CURRENT-OFFSET。
该字段是衡量消费能力的核心指标,值越小说明消费越及时,值为 0 是理想状态。
其实kafka底层工作原理本质就是生成者与消费者模型,运行过程中,生产者发送消息到kafka服务端,kafka会将其暂时保存下来(默认保存7天),消费者准备好后就会从kafka获取消息并消费。
三、基础操作
- Topic 管理:创建(指定分区数、副本数)、修改(扩容分区)、删除、查看详情命令
shell
# 创建 topic
kafka-topics.sh \
--bootstrap-server 192.168.1.100:9092,192.168.1.100:9093,192.168.1.100:9094 \
--create \
--topic 目标Topic名 \
--partitions 分区数 \
--replication-factor 副本数
# 修改 topic
kafka-topics.sh \
--bootstrap-server 192.168.1.100:9092,192.168.1.100:9093,192.168.1.100:9094 \
--alter \
--topic 目标Topic名 \
--partitions 新分区数(需大于原分区数)
# 删除 topic
kafka-topics.sh \
--bootstrap-server 192.168.1.100:9092,192.168.1.100:9093,192.168.1.100:9094 \
--delete \
--topic 目标Topic名
# 查看 topic
kafka-topics.sh \
--bootstrap-server 192.168.1.100:9092,192.168.1.100:9093,192.168.1.100:9094 \
--describe \
--topic 目标Topic名- 消费者组管理:查看消费组列表、查询消费进度(Lag 值)、删除无效消费组命令
shell
# 查看消费组列表
kafka-consumer-groups.sh \
--bootstrap-server 192.168.1.100:9092,192.168.1.100:9093,192.168.1.100:9094 \
--list
# 查看消费进度
kafka-consumer-groups.sh \
--bootstrap-server 192.168.1.100:9092,192.168.1.100:9093,192.168.1.100:9094 \
--describe \
--group 目标消费组名
# 删除消费组
kafka-consumer-groups.sh \
--bootstrap-server 192.168.1.100:9092,192.168.1.100:9093,192.168.1.100:9094 \
--delete \
--group 目标消费组名- 消息操作:消费指定 Topic 消息、查看分区消息偏移量范围
shell
# 消费指定 topic 的消息
kafka-console-consumer.sh \
--bootstrap-server 192.168.1.100:9092,192.168.1.100:9093,192.168.1.100:9094 \
--topic 目标Topic名
# 查看所有分区的最大偏移量(-1 表示最大偏移量(最新消息),-2 表示最小偏移量(最早消息))
# 用于计算当前服务器存储的日志量
kafka-run-class.sh kafka.tools.GetOffsetShell \
--broker-list 192.168.1.100:9092,192.168.1.100:9093,192.168.1.100:9094 \
--topic test-topic \
--time -1