1. Overview
在模型从实验室走向生产的过程中,推理性能与部署效率 是决定成本和体验的关键环节。
本文介绍如何将 Hugging Face 的 Transformer 模型导出为 ONNX 格式,并通过 ONNX Runtime (ORT) 在 CPU / GPU 上实现性能优化。主要实践包括:
-
动态量化(INT8)
-
图优化(Graph Optimization)
-
混合精度(FP16)
实验结果显示:
-
CPU 场景下,INT8 动态量化可实现 约 3.5x 加速、4x 模型压缩;
-
GPU 场景下,图优化 + 混合精度可获得 约 2.2x 提速、50% 模型减重;
本文的优化思路将在下一篇用于构建高性能 RAG(检索增强生成)系统,探索向量检索与生成模型的工业级融合。
2. 原理与工程方法
2.1 工程价值
ONNX Runtime 是一个高性能推理引擎,支持多种硬件后端(CPU、GPU、TensorRT 等)。
在本实验中,使用 Hugging Face API - optimum.onnxruntime (集成 ONNX Runtime) 将 PyTorch 导出的 ONNX 模型加载后执行推理。
-
多平台兼容;
-
export 一次即可构建与训练框架无关的计算图;
-
自动选择最优算子实现;
-
支持模型量化、图优化(Graph Optimization);
-
可部署于 CPU、GPU、Edge 等不同硬件。
2.2 量化
目标: 在几乎不损失精度的情况下,减少模型体积、降低带宽占用、提升推理速度。
量化方式分为:
-
动态量化(Dynamic Quantization)
-
实时计算激活值 scale/zero_point。
-
精度更高,适合 Transformer。
-
-
静态量化(Static Quantization)
-
使用校准集预计算参数。
-
推理更快但准备成本高。
-
常见数据格式:
-
U8S8(激活 uint8,权重 int8)在 x86 上表现最佳。
-
TensorRT + GPU INT8 需专门校准与硬件支持。
⚙️ 推荐组合:
-
CPU 环境: 动态量化(INT8)
-
GPU 环境: 图优化 + 混合精度(FP16)
2.3 图优化(Graph Optimization)
ONNX Runtime 在加载模型时,会自动执行一系列图优化(如算子融合、常量折叠、算子替换),这些优化可以在不影响数值结果的情况下减少计算节点、加速执行。它是对计算图 进行等价重写来提升执行效率。
-
算子融合(Operator Fusion): 将 MatMul + Add + Gelu 合并为一个算子
-
常量折叠(Constant Folding): 对常量算子提前计算,减少推理时的冗余计算
-
冗余节点消除/ 内存优化(Elimination & Memory Reuse): 优化计算图执行顺序,减少显存占用
图优化通常能直接带来 GPU 的稳定收益(算子融合、kernel 优化),但在 CPU 上往往收益相对较小或视模型/输入规模而定。
2.4 GPU 推理与 CPU 推理的差异
-
CPU(适合小批量、低延迟场景):优先考虑动态量化(INT8),性价比高。
-
GPU(适合大并发、大批量):优先考虑图优化 + 混合精度(FP16),并使用 IO Binding、Kernel 优化减小数据拷贝成本。
-
工程权衡:在 GPU 上做 INT8 会带来额外部署复杂度(TensorRT,设备差异),因此在没有强烈收益前不作为首选。
3. 实验设置
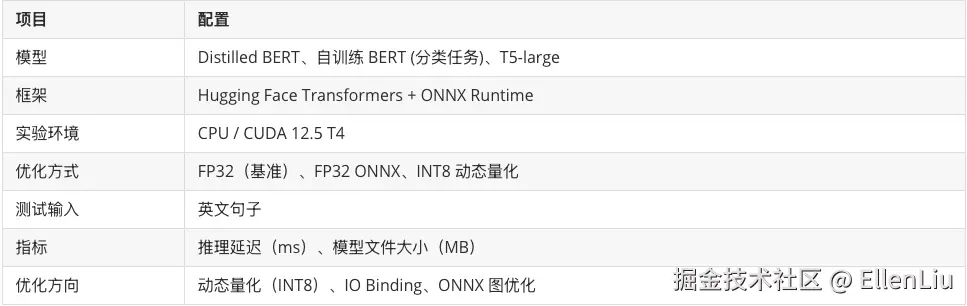
4. 实验结果与性能对比
4.1 CPU
Distilled BERT、batch size = 1
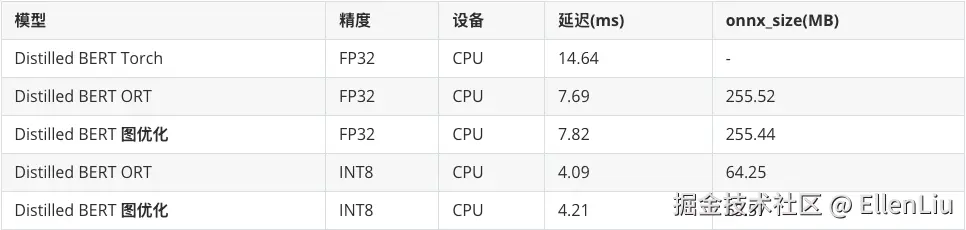
优化收益
-
ONNXRuntime 加速约 1.9 倍
-
动态量化(INT8)再加速约 1.9 倍,总体约 3.5 倍提速
-
模型体积缩小约 4 倍(255 → 64 MB)
-
图优化 收益不显著
分析
CPU设计用于通用计算,擅长复杂逻辑和分支预测。
CPU 的瓶颈在于内存传输限制,INT8 的数据传输量减少 75%,内存传输带宽需求大幅下降,瓶颈转移到计算能力。
图优化:算子融合\减少计算节点数量,减少中间结果的存储和传输开销,对 GPU 大批量并行计算优化效果显著
工程启示
对于在线低延迟场景(如问答、在线分类),ORT + 动态量化是最有价值的工程手段 ------ 成本低、收益高、兼容性好。
4.2 GPU
4.2.1 图优化 & 量化
自训练 BERT (分类任务)、batch size =128

分析
ONNXRuntime 提速显著
-
FP32 模型提速约 2.2x;
-
在 GPU 上,ONNX Runtime 的图优化(算子融合 + Kernel 优化)依旧有效;
INT8 性能下降
-
BERT ORT INT8 延迟 18.57 ms > FP32 3.63 ms;
-
ONNXRuntime 的 CUDA Execution Provider 对 INT8 的支持限制
-
TensorRT 环境部署暂时遇阻;下一步尝试 GPU TensorRT / cuBLAS 混合精度;
混合精度优化:
-
BERT ORT 混合精度图优化模型在延迟上与BERT ORT FP32接近,但模型大小显著减小。 -
性能与精度平衡较好,在 GPU 保持性能的同时有效减小了模型体积。
4.2.2 GPU IO Binding

IO Binding: 避免多次 Host↔Device 拷贝,可进一步减少 CPU-GPU 间的数据拷贝开销。特别对于生成式任务,其解码过程通常涉及多次小批量的前向传播和数据传输。但是在此次测试中,T5 Large 模型在 batch size = 512 时,IO Binding on/off 差异不明显或略有下降;
5. 结论(NLP)

6. 附:代码片段
动态量化
ini
def bert_quantize(model_checkpoint, save_directory, providers, device):
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
onnx_model = ORTModelForSequenceClassification.from_pretrained(
model_checkpoint,
export=True,
providers = providers)
# Create quantizer from model
quantizer = ORTQuantizer.from_pretrained(onnx_model)
# Define the dynamic quantization strategy by creating the configuration
dqconfig = AutoQuantizationConfig.avx512_vnni(is_static=False, per_channel=False)
# Quantize the model
quantizer.quantize(
save_dir=save_directory,
quantization_config=dqconfig
)
# inference
model_dyn_u8s8 = ORTModelForSequenceClassification.from_pretrained(
save_directory,
file_name="model_quantized.onnx",
providers = providers)图优化 + 混合精度
ini
def bert_optimize(model_checkpoint, save_directory, providers, device):
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
model = ORTModelForSequenceClassification.from_pretrained(
model_checkpoint,
export=True,
providers = providers)
# Load the optimization configuration detailing the optimization we wish to apply
optimization_config = AutoOptimizationConfig.O4()
optimizer = ORTOptimizer.from_pretrained(model)
optimizer.optimize(save_dir=save_directory, optimization_config=optimization_config)
optimized_model = ORTModelForSequenceClassification.from_pretrained(
save_directory,
file_name="model_optimized.onnx",
providers=providers)感谢你阅读这篇实践型笔记 --- 这是我在AI方向的工程沉淀之一。下一篇我会把这套推理基座实际接入到 RAG pipeline 中,展示 end-to-end 的延迟/精度权衡与向量优化策略。
欢迎同行交流 / 合作 / 招聘联系
💼 专业方向:AI 工程化、智能金融系统