视频讲解1:https://www.bilibili.com/video/BV1NWSxBqEnf/
视频讲解2:https://www.douyin.com/video/7579139425439911210
论文下载:https://arxiv.org/abs/2306.01851
代码下载:https://www.robots.ox.ac.uk/~vgg/research/countx
算法VLCount详解(VLCounter: Text-aware Visual Representation for Zero-Shot Object Counting)
人群计数中常用数据集的总结以及使用方式(Python/PyTorch)
基于Zero-Shot的计数算法详解(T2ICount: Enhancing Cross-modal Understanding for Zero-Shot Counting)
目录
[2 类别无关计数方法的局限性](#2 类别无关计数方法的局限性)
[3 文本指定计数方法的局限性](#3 文本指定计数方法的局限性)
[1 单阶段文本直接指定架构](#1 单阶段文本直接指定架构)
本文探讨了零样本对象计数方法的发展。现有方法存在三类局限性:类别特定方法无法处理新类别;类别无关方法依赖人工标注示例;文本指定方法采用两阶段流程效率低下。提出的CountTX框架创新性地实现了单阶段文本直接指定计数,利用CLIP模型的跨模态能力,通过图像和文本编码器的交互直接输出对象计数。该方法突破了传统方法对视觉示例的依赖,为开放世界环境下的对象计数提供了更高效的解决方案。相关论文和代码已公开,为研究者提供了实用参考。
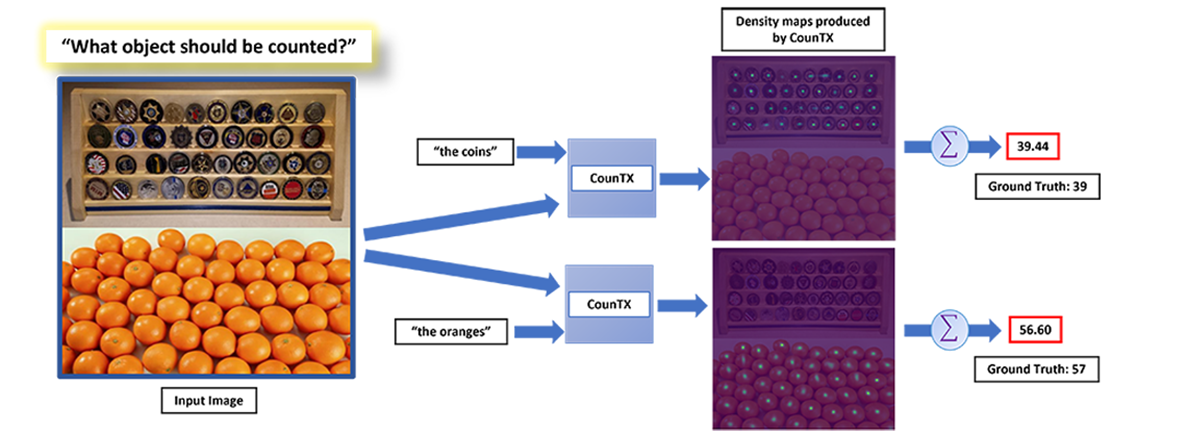
现有统计方法局限性
1.类别特定计数方法的局限性
类别特定对象计数方法(Class-specific Object Counting)专注于计数特定类别的对象, 如车辆、行人等。这类方法包括基于检测的方法(如Faster R-CNN、RetinaNet)和基于 回归的方法。它们的核心局限性在于封闭世界假设------只能识别训练过程中见过的类别。 当遇到未知类别时,这些方法完全失效,无法适应开放世界环境中任意类别的计数需求。
2****类别无关计数方法的局限性
类别无关计数方法(Class-agnostic Object Counting)通过视觉示例(visual exemplars) 指定要计数的对象类别,如CounTR、LOCA等方法。虽然这类方法可以处理未知类别,但 它们存在两个关键缺陷:**1.依赖人工标注示例:推理时需要用户提供目标对象的边界框 示例,这在实际应用中增加了操作复杂度;2.**示例质量敏感:计数精度高度依赖于提供 的示例质量,若示例不具代表性会导致计数误差。
3****文本指定计数方法的局限性
文本指定对象计数(Text-specified Object Counting)是较新的研究方向,已有方法提 出了通过类别名称而非视觉示例来指定计数对象的方法。然而,该方法采用两阶段流程: 首先利用文本选择视觉示例;然后将这些示例输入到现有的类别无关计数网络中完成计数。
提出的方法

针对上述局限性,提出一种单阶段开放世界文本指定对象计数框架,实现了从文本描述到对象计数的端到端映射。
1****单阶段文本直接指定架构
CounTX最大的创新在于摒弃了视觉示例,允许用户直接通过自然语言描述指 定要计数的对象。如图1所示,模型直接接收图像和问题"what object should be counted?"的答案,输出预测的物体计数。
2.基于CLIP****的跨模态交互机制
CounTX巧妙利用了CLIP****预训练模型的跨模态理解能力。
图像编码器:采用CLIP的ViT-B-16模型,提取图像块的空间特征;
文本编码器:使用CLIP文本转换器,将类别描述编码为特征向量;
特征交互模块:通过交叉注意力机制计算图像块与文本描述之间的相似度;
解码器:将交互后的特征上采样生成密度图,求和即可得到对象计数。
具体方法
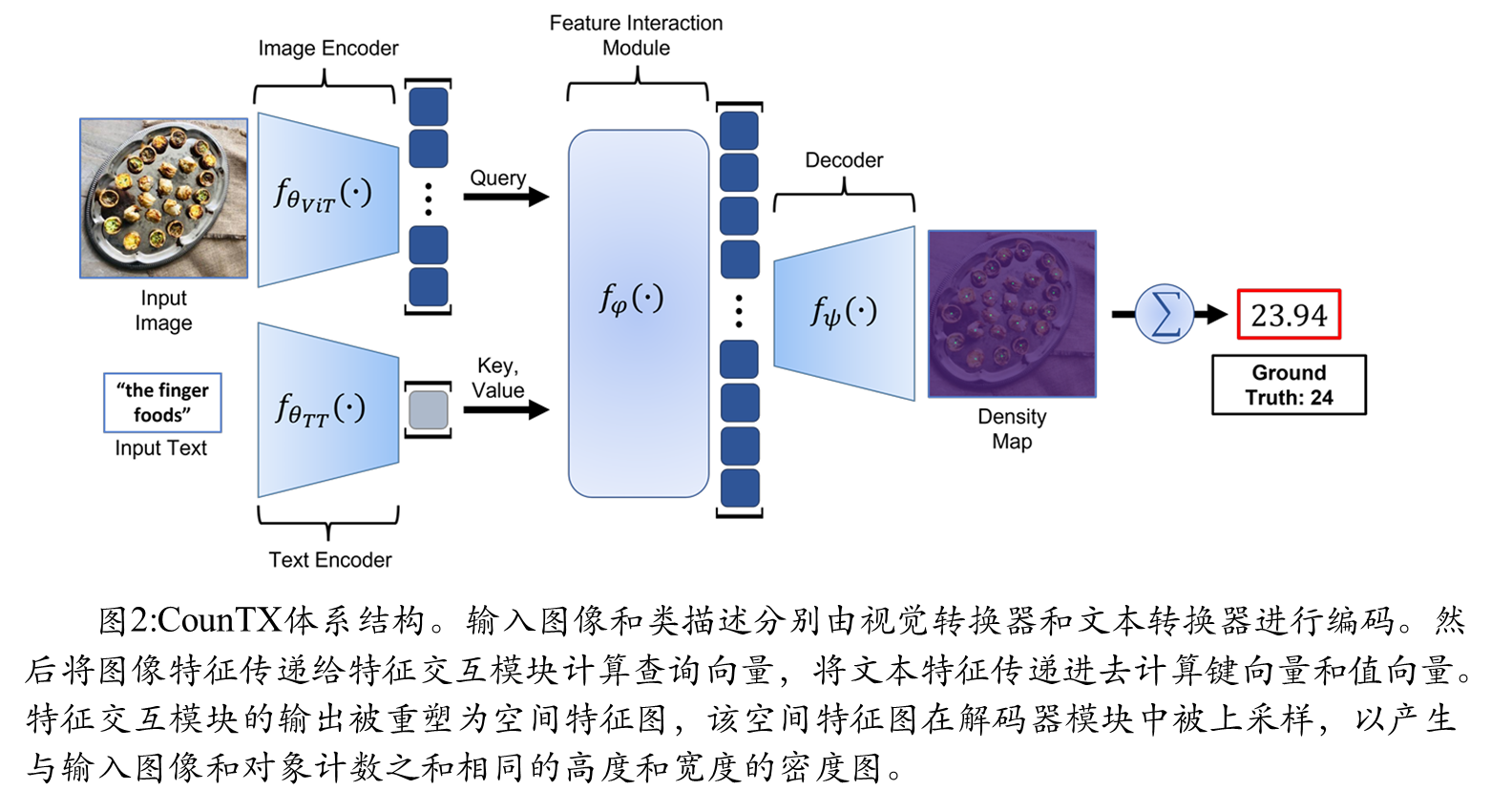
框架流程

图像编码器和文本编码器

特征交互模块和解码器模块

损失函数
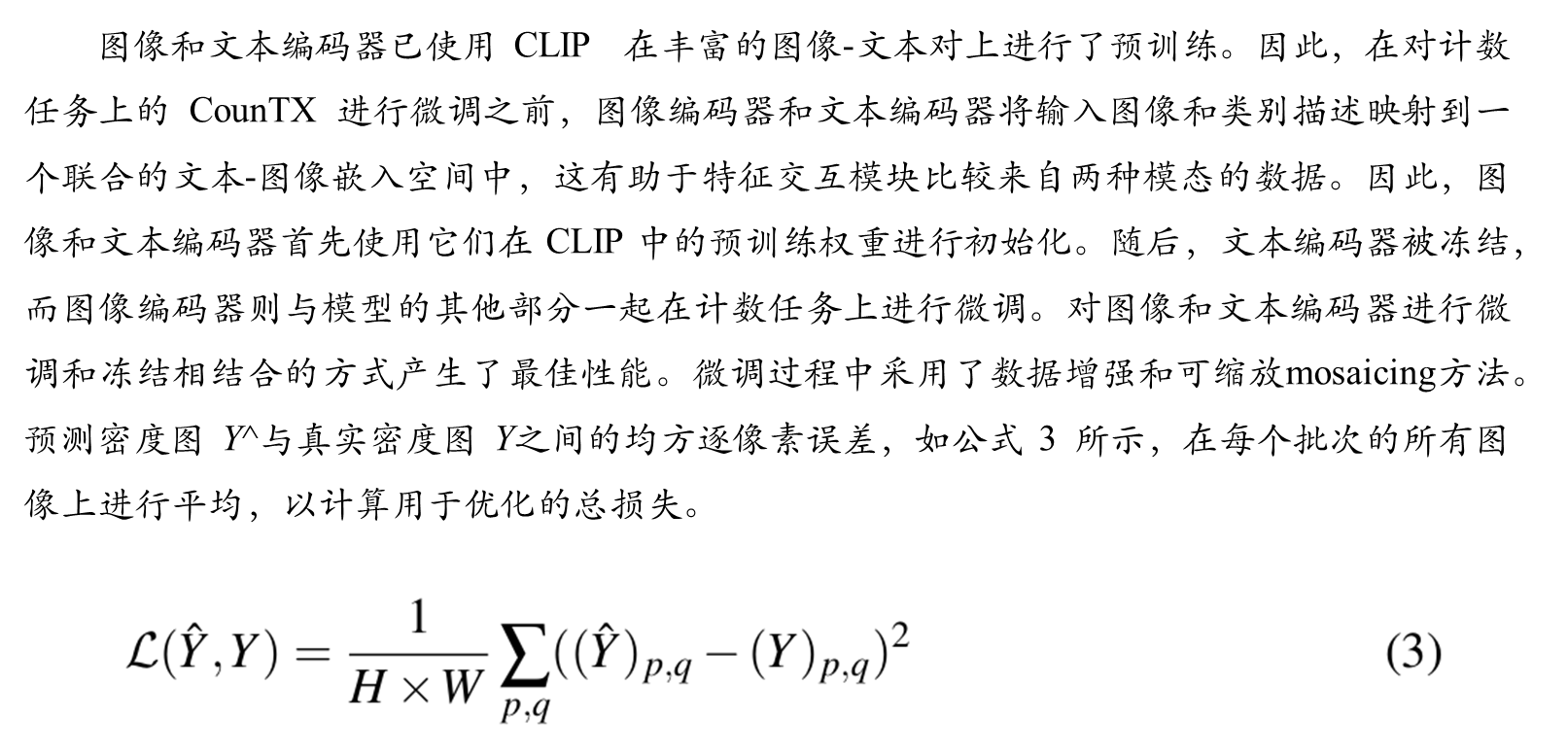
FSC_147数据集介绍
1 数据集背景与定位
FSC-147(Few-Shot Counting 147)是第一个大规模类别无关计数数据集 ,专门为推进少样本和零样本物体计数研究而创建。该数据集突破了传统类别特定计数(如只计数人群、车辆)的限制,使模型能够计数任意类别的物体实例。其核心目标是开发通用型物体计数器,仅需少量示例(甚至零示例)即可计数从未见过的新类别。
2 数据内容与统计信息
根据文档内容,FSC-147数据集包含6,135张图像 ,覆盖了147个完全不同的物体类别。这些类别具有极高的多样性,涵盖了动物、厨房用具、交通工具等各种日常物品。
数据集划分特点:
- 训练集:包含来自89个类别的图像
- 验证集:包含来自29个类别的图像
- 测试集:包含来自29个类别的图像
- 关键特性 :训练集、验证集和测试集中的类别是完全不相交的,这确保了评估的公平性,能够真实反映模型对全新类别的泛化能力。
标注信息:
- 每张图像都标注了物体中心的点级标注,可用于生成真实密度图(npy格式)
- 提供每个图像的类别名称信息
- 为每张图像提供3个视觉示例(边界框box),用于指定要计数的物体
实验结果
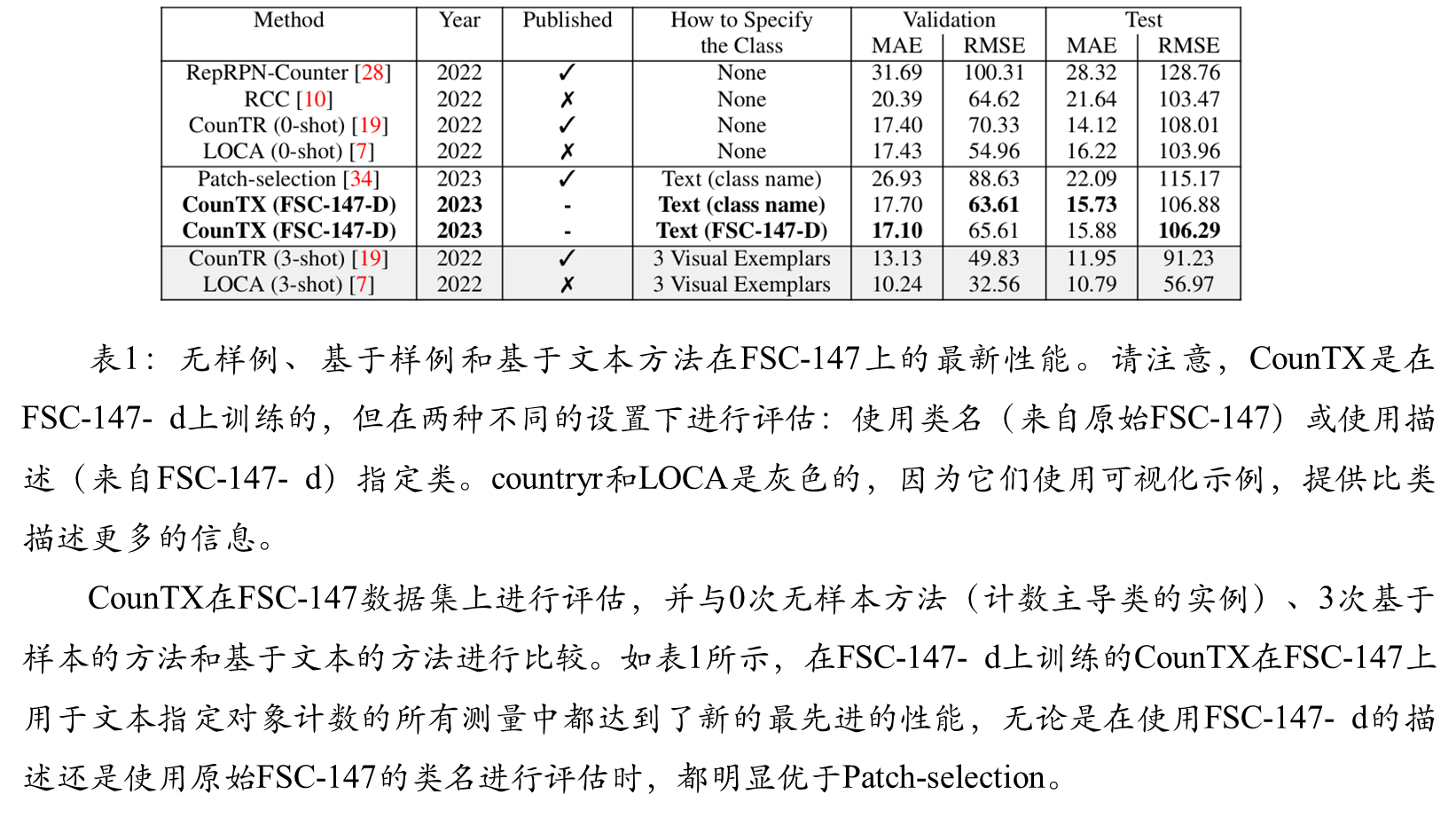
综合比较
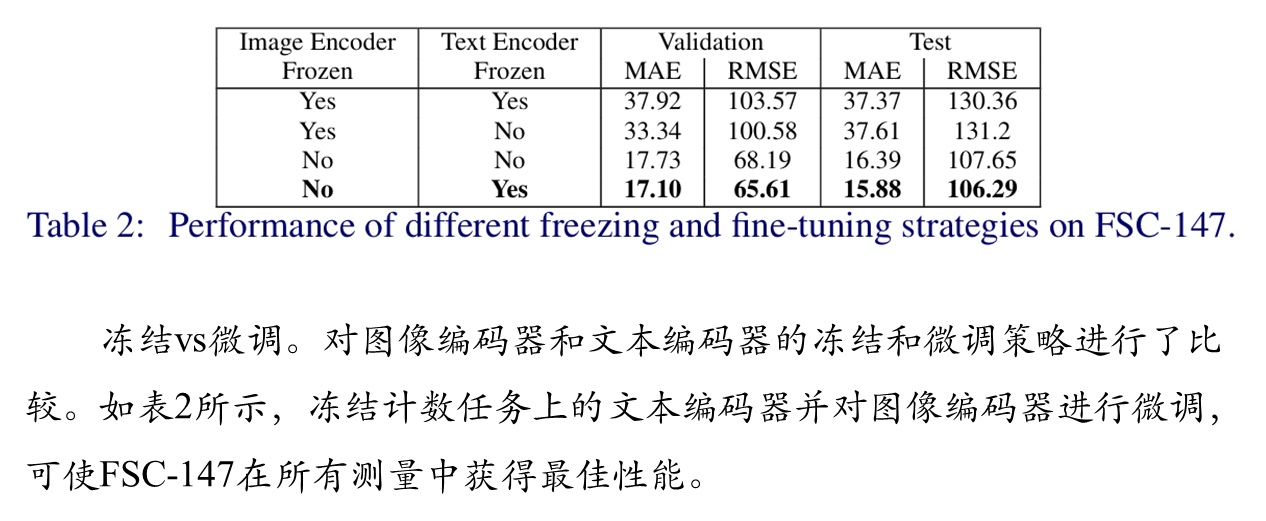
消融实验
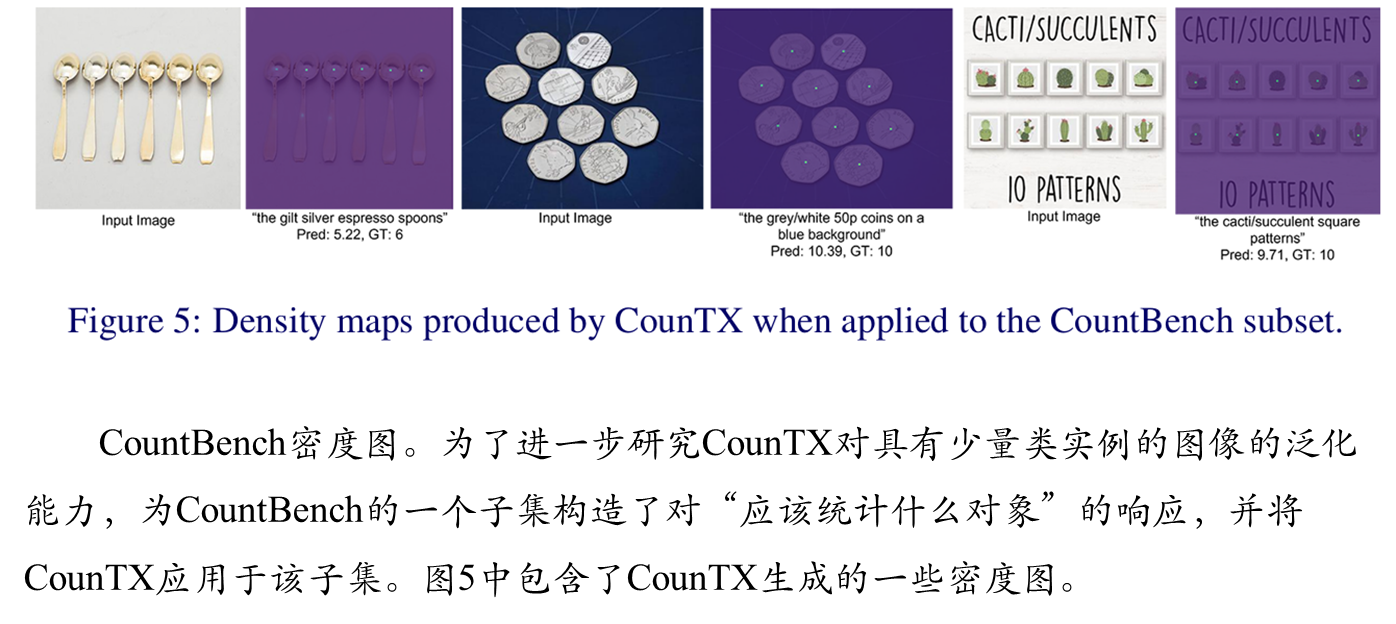
可视化


附录
附录部分是更多实验细节,大家理解主要思想之后看后面附录应该没有什么问题了。