typora-copy-images-to: upload
文章目录
- 1.安装
-
- [1.1 paddle框架安装](#1.1 paddle框架安装)
- [1.2 paddleOCR安装](#1.2 paddleOCR安装)
- 2.制作数据集
-
- 2.1工具下载
- [2.2 数据集制作](#2.2 数据集制作)
- [2.3 划分训练集和测试集](#2.3 划分训练集和测试集)
- 3.训练模型
-
- [3.1 代码下载](#3.1 代码下载)
- [3.2 预训练模型下载](#3.2 预训练模型下载)
- [3.3 文本检测训练](#3.3 文本检测训练)
- [3.4 文本识别模型训练](#3.4 文本识别模型训练)
- 4.验证模型
-
- [4.1 验证文本检测模型](#4.1 验证文本检测模型)
- [4.3 模型导出](#4.3 模型导出)
- [4.2 推理可视化](#4.2 推理可视化)
- [4.3 文本识别模型](#4.3 文本识别模型)
- [4.4 检测和识别一同验证可视化](#4.4 检测和识别一同验证可视化)
- [5 QT部署c++](#5 QT部署c++)
-
- [5.1 编译Opencv](#5.1 编译Opencv)
-
- [5.2.1 freetype2.14.0 编译](#5.2.1 freetype2.14.0 编译)
- [5.3.1 harfbuzz11.0编译](#5.3.1 harfbuzz11.0编译)
- [5.1.3 opencv编译](#5.1.3 opencv编译)
- [5.2 编译Paddle Inference](#5.2 编译Paddle Inference)
- [5.3 编译程序](#5.3 编译程序)
- 6.模型转onnx,部署更简单(新版本目前有bug,不用看了)
- 遇到问题
-
- [1.AssertionError: The length of ratio_list should be the same as the file_list.](#1.AssertionError: The length of ratio_list should be the same as the file_list.)
- 2.验证时候爆显存
- [3.OpenCV was not compiled with the freetype module (opencv_freetype) !](#3.OpenCV was not compiled with the freetype module (opencv_freetype) !)
- 4.opencv部分库下载失败
- [5.opencv编译No SOURCES given to target: ade](#5.opencv编译No SOURCES given to target: ade)
- [6.检测到"_ITERATOR_DEBUG_LEVEL"的不匹配项: 值"2"不匹配值"0"(algorithm.obj 中)](#6.检测到“_ITERATOR_DEBUG_LEVEL”的不匹配项: 值“2”不匹配值“0”(algorithm.obj 中))
- 7.onnx模型转换失败
部署环境, windows10,camke 4.2 freetype 2.14.0 文档未写完
1.安装
1.1 paddle框架安装
conda 创建一个python =3.10的基础环境
根据自己的环境安装paddle框架链接
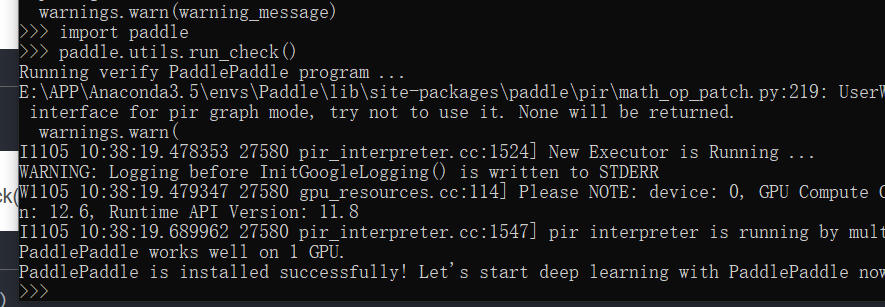
安装完成后进入环境,输入
python
import paddle
paddle.utils.run_check()
如果看到以下输出则没有问题,输入exit()退出
1.2 paddleOCR安装
pip install paddleocr出现以下说明安装成功,不用指定版本,指定了还出错
2.制作数据集
2.1工具下载
下载数据集制作工具下载地址
解压后,进入环境,cd到解压目录
pip3 install "paddlex[ocr]" -i https://pypi.tuna.tsinghua.edu.cn/simple/安装必要库
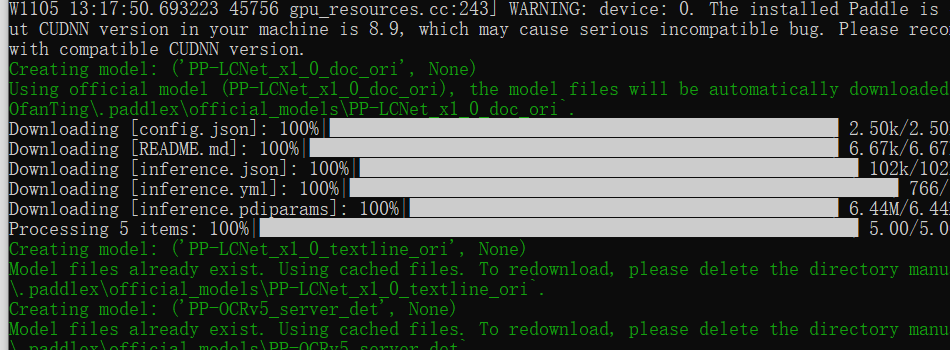
启动插件python ./PPOCRLabel.py,此时会一直下载模型,然后就会打开软件
2.2 数据集制作
打开图片文件夹,矩形框标注,可以更改识别结果,标注完成点击确定
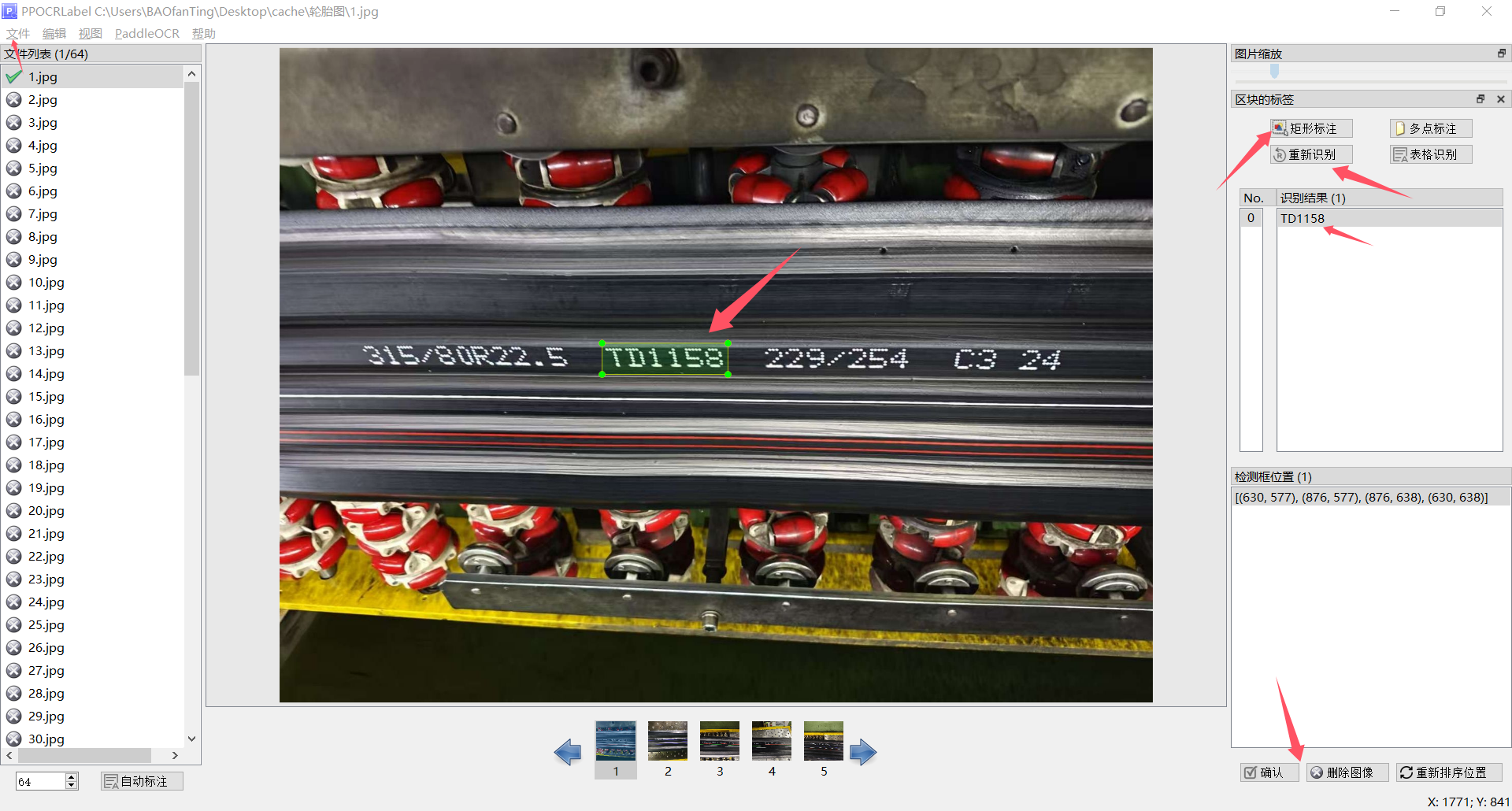
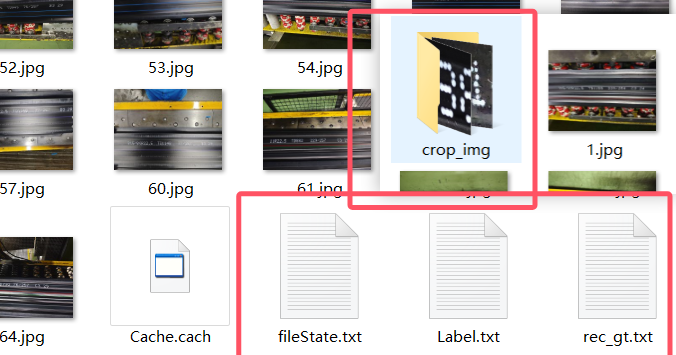
制作完成后,点击文件→导出标记结果 ,点击文件→导出识别结果,得到四个文件
2.3 划分训练集和测试集
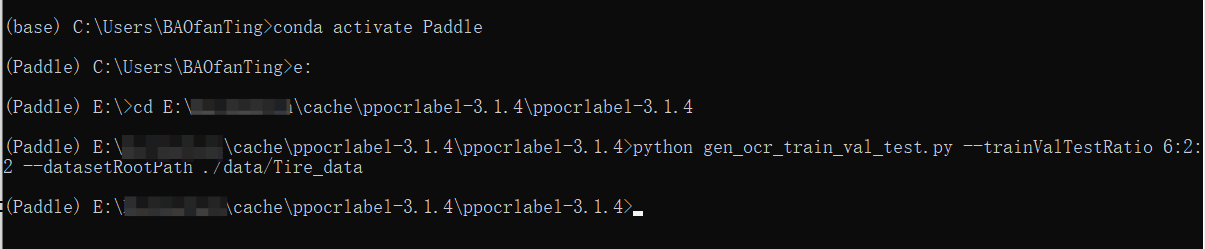
打开conda终端进入环境,cd进入PPOCRLabel文件夹,把图片文件夹复制到data文件夹下,执行划分命令
python gen_ocr_train_val_test.py --trainValTestRatio 6:2:2 --datasetRootPath ./data/Tire_data
--trainValTestRatio 6:2:2 #训练集、验证集和测试集的比例
--datasetRootPath #数据集路径
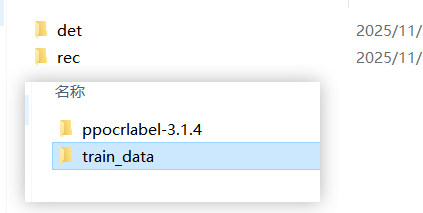
运行完成后再代码的上一级文件夹就会有train_data,里边就是划分好的数据集
3.训练模型
3.1 代码下载
克隆也行,下载也行,下载地址
解压后cd进入,安装必要库pip install -r requirements.txt

3.2 预训练模型下载
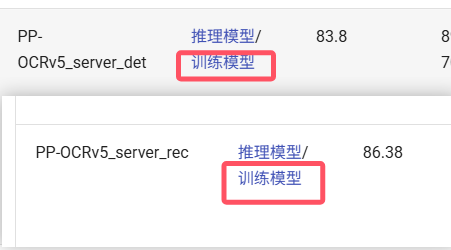
https://www.paddleocr.ai/main/version3.x/module_usage/text_detection.html#411下载文本检测和识别的预训练模型
3.3 文本检测训练
windows 端训练 终端输入指令
python
python tools/train.py -c configs/det/PP-OCRv5/PP-OCRv5_server_det.yml \ # 配置文件路径
-o Global.pretrained_model=./model/PP-OCRv5_server_det_pretrained.pdparams \ #模型路径
Train.dataset.data_dir=../train_data/det \ # 数据集路径
Train.dataset.label_file_list='[../train_data/det/train.txt]' \ # train.txt路径
Eval.dataset.data_dir=../train_data/det \ # 数据集路径
Eval.dataset.label_file_list='[../train_data/det/val.txt]' # val.txt路径python tools/train.py -c configs/det/PP-OCRv5/PP-OCRv5_server_det.yml -o Global.pretrained_model=./model/PP-OCRv5_server_det_pretrained.pdparams Train.dataset.data_dir=../train_data/det Train.dataset.label_file_list=[../train_data/det/train.txt] Eval.dataset.data_dir=../train_data/det Eval.dataset.label_file_list=[../train_data/det/val.txt]
3.4 文本识别模型训练
同理
4.验证模型
4.1 验证文本检测模型
进入终端,环境,cd到目录
python
python3 tools/eval.py -c configs/det/PP-OCRv5/PP-OCRv5_server_det.yml \
-o Global.pretrained_model=output/PP-OCRv5_server_det/latest.pdparams \ # 保存的模型地址
Eval.dataset.data_dir=./ocr_det_dataset_examples \ # 数据集路径
Eval.dataset.label_file_list='[./ocr_det_dataset_examples/val.txt]' #valtext 路径python tools/eval.py -c configs/det/PP-OCRv5/PP-OCRv5_server_det.yml -o Global.pretrained_model=output/PP-OCRv5_server_det/latest.pdparams Eval.dataset.data_dir=../train_data/det Eval.dataset.label_file_list=[../train_data/det/val.txt]
4.3 模型导出
在训练的output找到你最优的模型
python
python tools/export_model.py -c configs/det/PP-OCRv5/PP-OCRv5_server_det.yml -o \ # 配置文件
Global.pretrained_model=output/PP-OCRv5_server_det/latest.pdparams \ # 模型参数路径
Global.save_inference_dir="./PP-OCRv5_server_det_infer/" #导出地址python tools/export_model.py -c configs/det/PP-OCRv5/PP-OCRv5_server_det.yml -o Global.pretrained_model=output/PP-OCRv5_server_det/latest.pdparams Global.save_inference_dir="./PP-OCRv5_server_det_infer/"
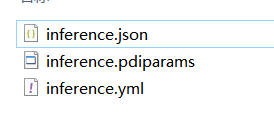
会得到这三个文件,然后就可以推理
4.2 推理可视化
python
python tools\infer\predict_det.py \
--image_dir "../train_data/det/test/" \ # 预测图像路径
--det_model_dir "./output/PP-OCRv5_server_det/" \ # 模型路径
--use_gpu truepython tools\infer\predict_det.py --image_dir "../train_data/det/test/" --det_model_dir "./PP-OCRv5_server_det_infer/" --use_gpu true
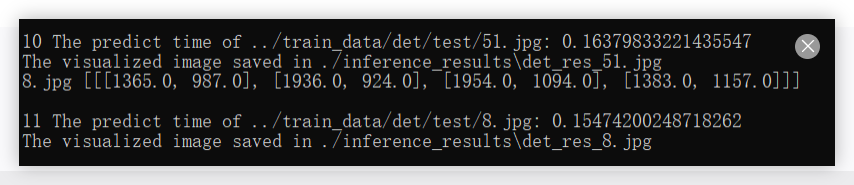
在这个路径下就能看到识别后的可视化结果
4.3 文本识别模型
同理
4.4 检测和识别一同验证可视化
python
python tools/infer/predict_system.py
--det_model_dir=./ch_PP-OCRv2_det_infer/ \ # 检测模型目录
--rec_model_dir=./ch_PP-OCRv2_rec_infer/ \ # 识别模型目录
--image_dir=./datasets/img_dir/ \ # 测试图片目录
--draw_img_save_dir=./ch_PP-OCRv2_results/ \ # 可视化结果保存目录
--is_visualize=True5 QT部署c++
5.1 编译Opencv
下载cmake安装下载链接
下载opencv原码和对应的第三方库下载 opencv-4.7.0 下载 opencv_contrib-4.7.0(版本可以自己选择我这边是官方教程的版本)
下载pkg-config解压 pkg-config 后添加其 bin 目录到系统 PATH 环境变量。
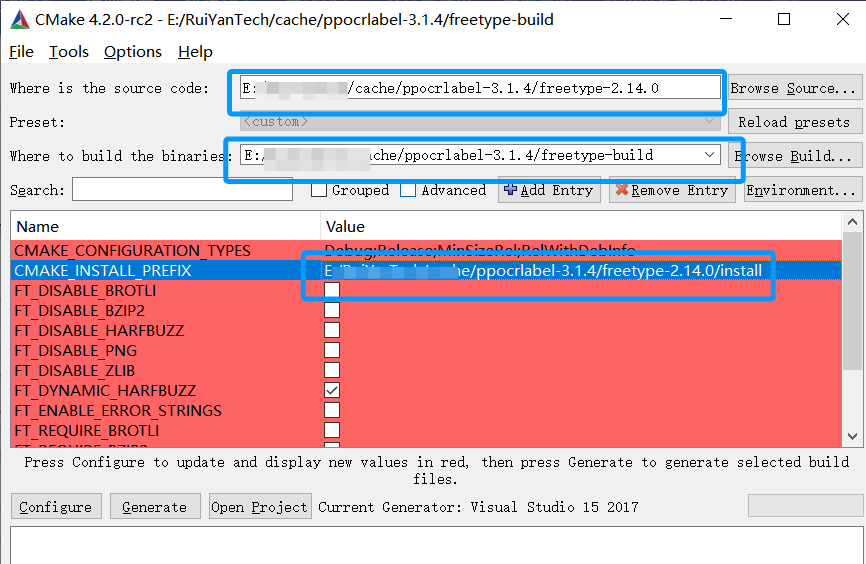
5.2.1 freetype2.14.0 编译
下载freetype2下载解压后打开cmake,我选择2.14版本,选择路径和编译导出路径,点击config,选择你的vs版本,x64,最后点击Generate,完成后,点击 Open Project 按钮,打开 VS ,编译。 VS里ALL_BUILD, INSTALL. 会在构建文件夹的 install 目录下生成所需的 include 和 lib 文件。
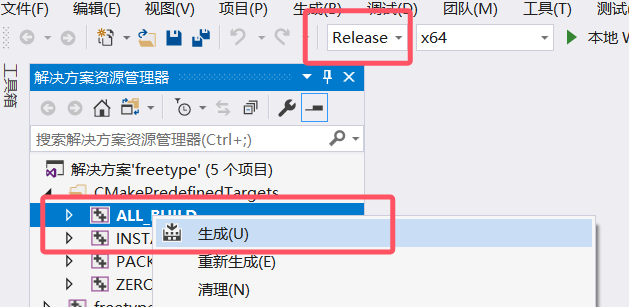
debug和release都运行一下install生成,然后将 freetype 的install路径添加至系统环境变量,重启电脑.
5.3.1 harfbuzz11.0编译
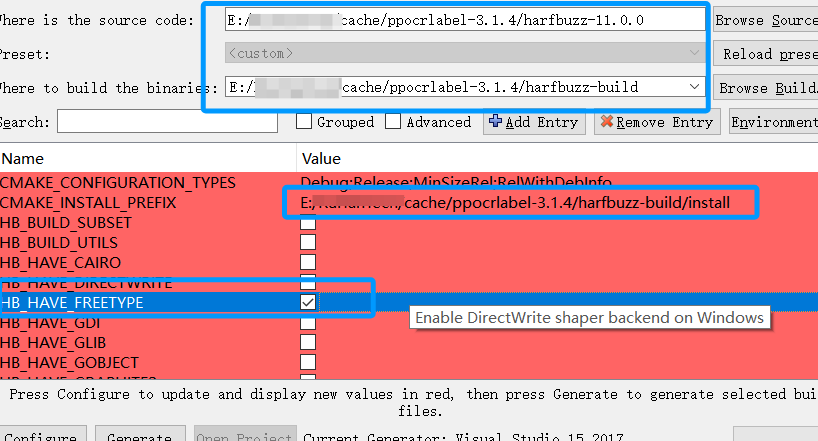
设置好上面两项后,再次点击 Configure 按钮,选择 Advanced Options ,填写 freetype 安装路径, 再次点击Configure 按钮,最后点击Generate,完成后,点击 Open Project 按钮,打开 VS ,install 生成。
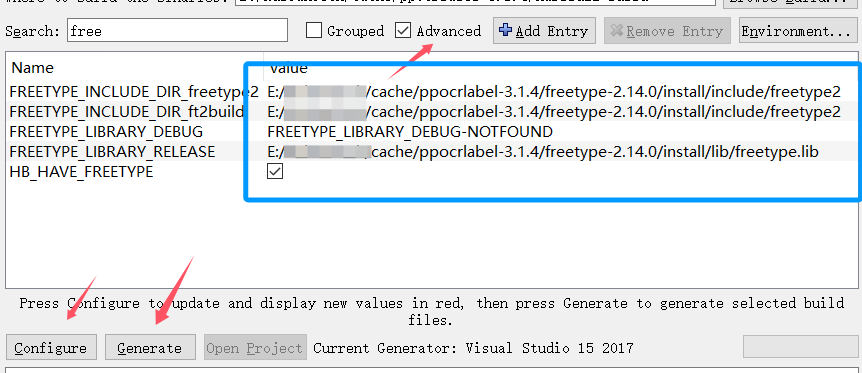
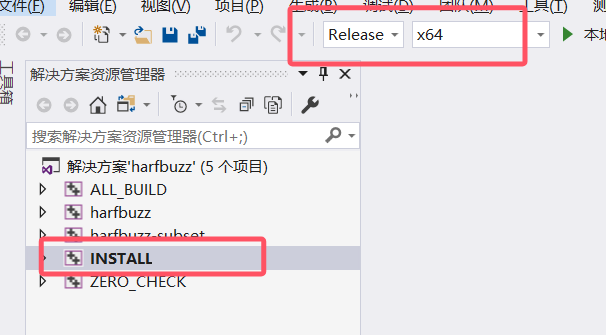
然后将 harbuzz 的install路径添加至系统环境变量,重启电脑.
5.1.3 opencv编译
修改 opencv_contrib-4.7.0 下的 modules/freetype/CMakeLists.txt
set(the_description "FreeType module. It enables to draw strings with outlines and mono-bitmaps/gray-bitmaps.")
find_package(Freetype REQUIRED)
# find_package(HarfBuzz) is not included in cmake
set(HARFBUZZ_DIR "$ENV{HARFBUZZ_DIR}" CACHE PATH "HarfBuzz directory")
find_path(HARFBUZZ_INCLUDE_DIRS
NAMES hb-ft.h PATH_SUFFIXES harfbuzz
HINTS ${HARFBUZZ_DIR}/include)
find_library(HARFBUZZ_LIBRARIES
NAMES harfbuzz
HINTS ${HARFBUZZ_DIR}/lib)
find_package_handle_standard_args(HARFBUZZ
DEFAULT_MSG HARFBUZZ_LIBRARIES HARFBUZZ_INCLUDE_DIRS)
if(NOT FREETYPE_FOUND)
message(STATUS "freetype2: NO")
else()
message(STATUS "freetype2: YES")
endif()
if(NOT HARFBUZZ_FOUND)
message(STATUS "harfbuzz: NO")
else()
message(STATUS "harfbuzz: YES")
endif()
if(FREETYPE_FOUND AND HARFBUZZ_FOUND)
ocv_define_module(freetype opencv_core opencv_imgproc PRIVATE_REQUIRED ${FREETYPE_LIBRARIES} ${HARFBUZZ_LIBRARIES} WRAP python)
ocv_include_directories(${FREETYPE_INCLUDE_DIRS} ${HARFBUZZ_INCLUDE_DIRS})
else()
ocv_module_disable(freetype)
endif()- 设置
OPENCV_EXTRA_MODULES_PATH项,填入 opencv-contrib-4.7.0 的目录下的 modules 目录。 - 勾选
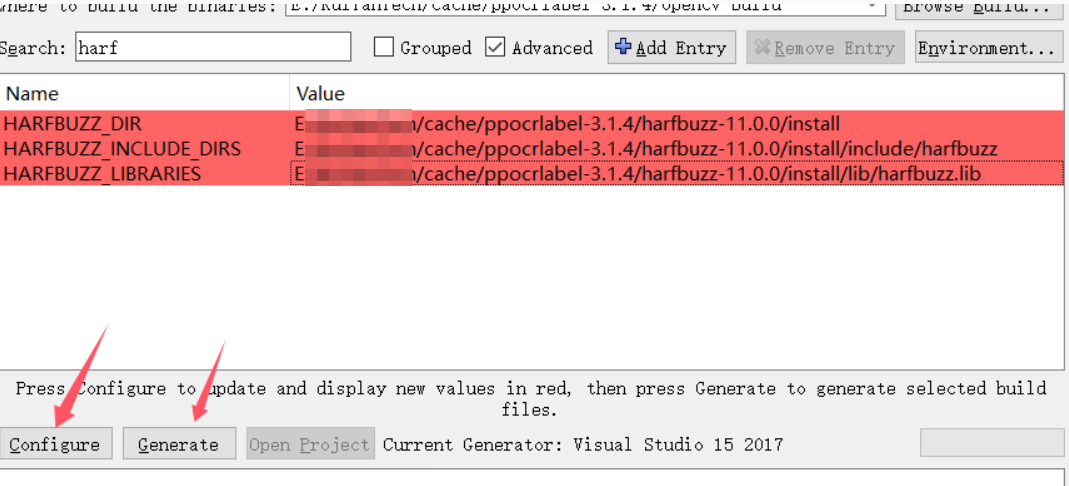
WITH_FREETYPE项,必须先编译 freetype 和 harfbuzz。再次点击config
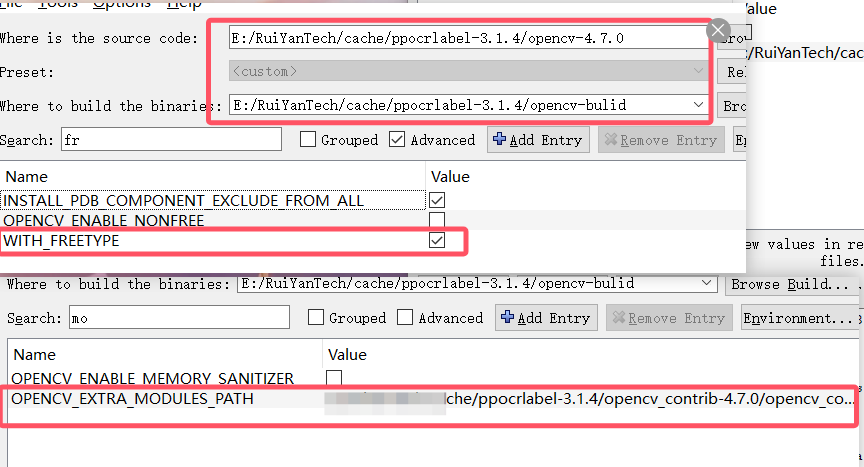
确定freetype的路径正确
填入harfbuzz路径
打开qt,world,opengl,nonfree
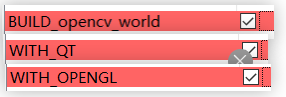
取消勾选test,wechat_qrcode,java,js,python,cvv的所有勾选
完成后,再次在 Cmake 界面,点击 configure, 确定没报错后,点击 Generate,最后点击 Open Project,打开 Visual studio,将 Debug 切换为 Release, 找到 INSTALL 右键 Build。没有报错即为编译成功
opencv部分库下载不下,看问题4,5
5.2 编译Paddle Inference
参考官方教材,直接安装编译包就行,省去编译过程官方教程
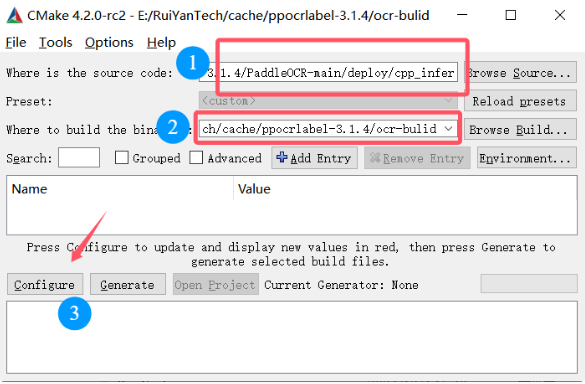
5.3 编译程序
source code填入PaddleOcr的deploy的cpp_infer路径
build填入任意地址即可,存放编译的文件,完成后点击configure
VS的版本根据你安装的来,平台选择x64
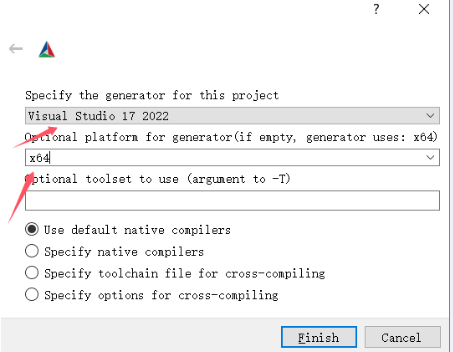
第一次点击 Configure 报错是正常的,在后续弹出的编译选项中,添加 OpenCV 的安装路径和 Paddle Inference 预测库路径。
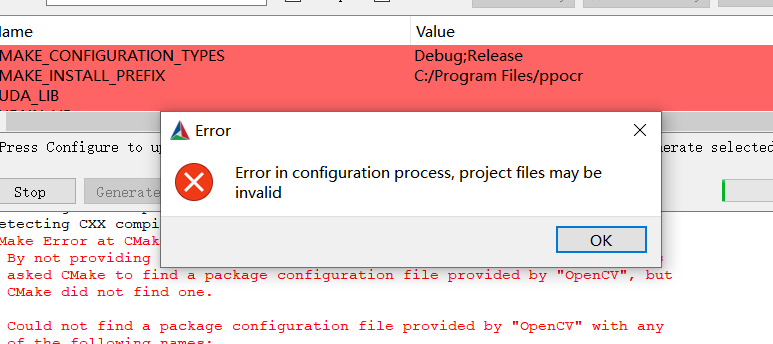
- OPENCV_DIR:填写 OpenCV 安装路径。
- OpenCV_DIR:同 OPENCV_DIR。
- PADDLE_LIB:Paddle Inference 预测库路径。

6.模型转onnx,部署更简单(新版本目前有bug,不用看了)
进入conda环境,执行如下命令,通过 PaddleX CLI 安装 PaddleX 的 Paddle2ONNX 插件:
# Windows 用户需使用以下命令安装 paddlepaddle dev版本
pip install --pre paddlepaddle -i https://www.paddlepaddle.org.cn/packages/nightly/cpu/
paddlex --install paddle2onnxERROR: Could not find a version that satisfies the requirement onnx<=1.17.0,>=1.16 (from paddle2onnx) (from versions: none)
ERROR: No matching distribution found for onnx<=1.17.0,>=1.16
Installation failed
遇到报错onnx版本不对,直接卸载安装
pip uninstall paddle2onnx onnx onnxruntime -y
pip install paddle2onnx onnx==1.17.0 onnxruntime==1.17.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
执行如下命令完成模型转换:需要使用导出后的推理模型,训练的不可以
paddlex \
--paddle2onnx \ # 使用paddle2onnx功能
--paddle_model_dir /your/paddle_model/dir \ # 指定 Paddle 模型所在的目录
--onnx_model_dir /your/onnx_model/output/dir \ # 指定转换后 ONNX 模型的输出目录
--opset_version 7 # 指定要使用的 ONNX opset 版本paddlex --paddle2onnx --paddle_model_dir ./PP-OCRv5_server_det_infer --onnx_model_dir ./output/PP-OCRv5_server_det --opset_version 11
遇到问题
1.AssertionError: The length of ratio_list should be the same as the file_list.
去掉'','[../train_data/det/train.txt]'变为[../train_data/det/train.txt]
2.验证时候爆显存
打开配置文件,关闭使用gpuuse-gpu=false
3.OpenCV was not compiled with the freetype module (opencv_freetype) !
4.X版本的opencv都没有,需要自己编译,官方写的很详细,参考官方就行参考链接

4.opencv部分库下载失败
打开build文件夹下,有一个download_with_curl.sh,里边是下载的链接
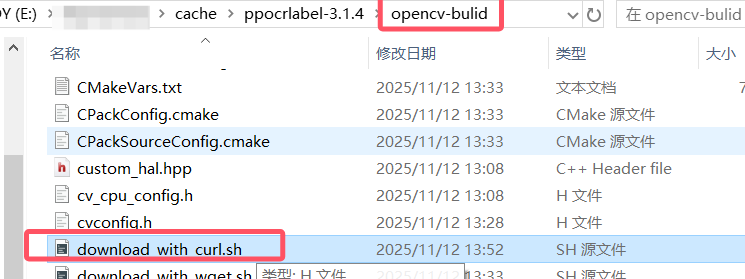
使用科学上网,下载链接,把文件放入对应文件夹

保存的时候名字前缀对应,直接替换就行
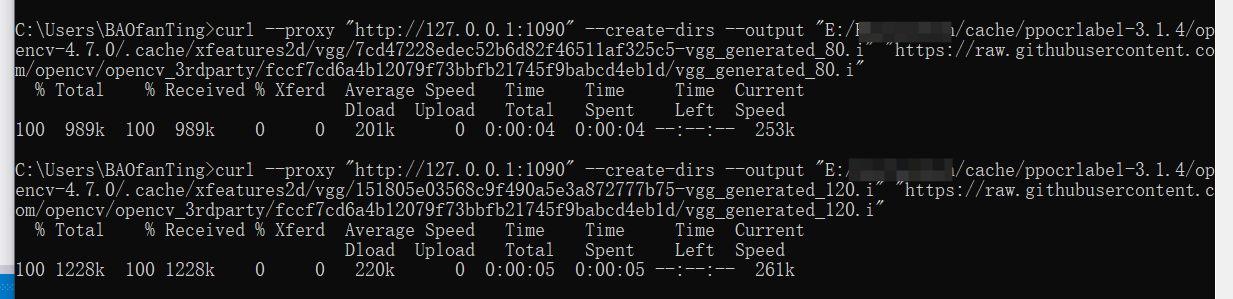
推荐使用以下方式,复制到cmd下载
curl --proxy "http://127.0.0.1:端口号" --create-dirs --output "E:/RuiYanTech/cache/ppocrlabel-3.1.4/opencv-4.7.0/.cache/xfeatures2d/boostdesc/98ea99d399965c03d555cef3ea502a0b-boostdesc_binboost_128.i" "https://raw.githubusercontent.com/opencv/opencv_3rdparty/34e4206aef44d50e6bbcd0ab06354b52e7466d26/boostdesc_binboost_128.i"
5.opencv编译No SOURCES given to target: ade
自行下载下载v0.1.2a.zip 替换名字放入
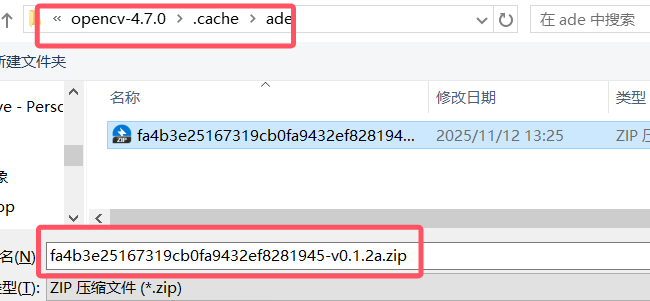
并将opencv-4.7.0\modules\gapi\cmake\DownloadADE.cmake的下载函数注释,再次config就能够编译通过了
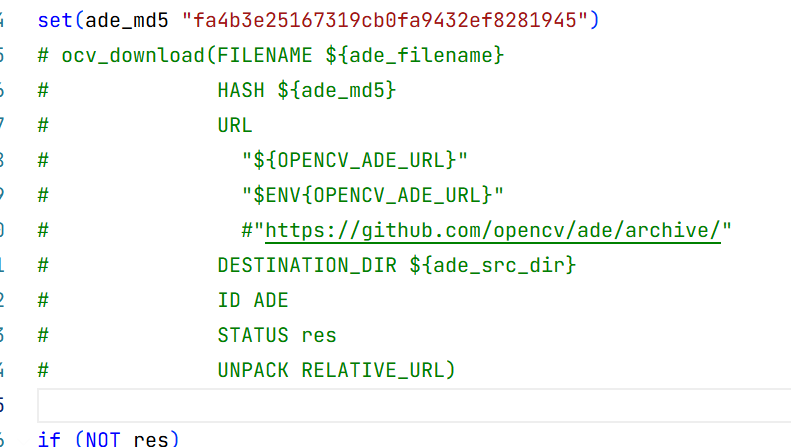
6.检测到"_ITERATOR_DEBUG_LEVEL"的不匹配项: 值"2"不匹配值"0"(algorithm.obj 中)
生成opencv时报错,需要确保所有项目(opencv_world 和 harfbuzz)都使用相同的配置(Debug 或 Release)
7.onnx模型转换失败
运行后发现模型为0kb,转换失败
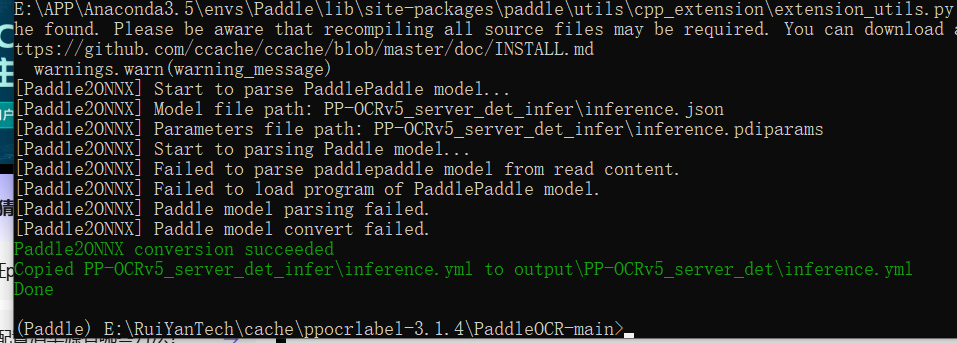
查询了相关资料,是导出模型的时候少了文件,新版的paddle改了只导出json,不使用.pdmodel,目前好像还没有修复这个bug,推荐使用老版本的吧