1. 实现原理
HashMap底层采用hash表数据结构,即数组和链表或红黑树
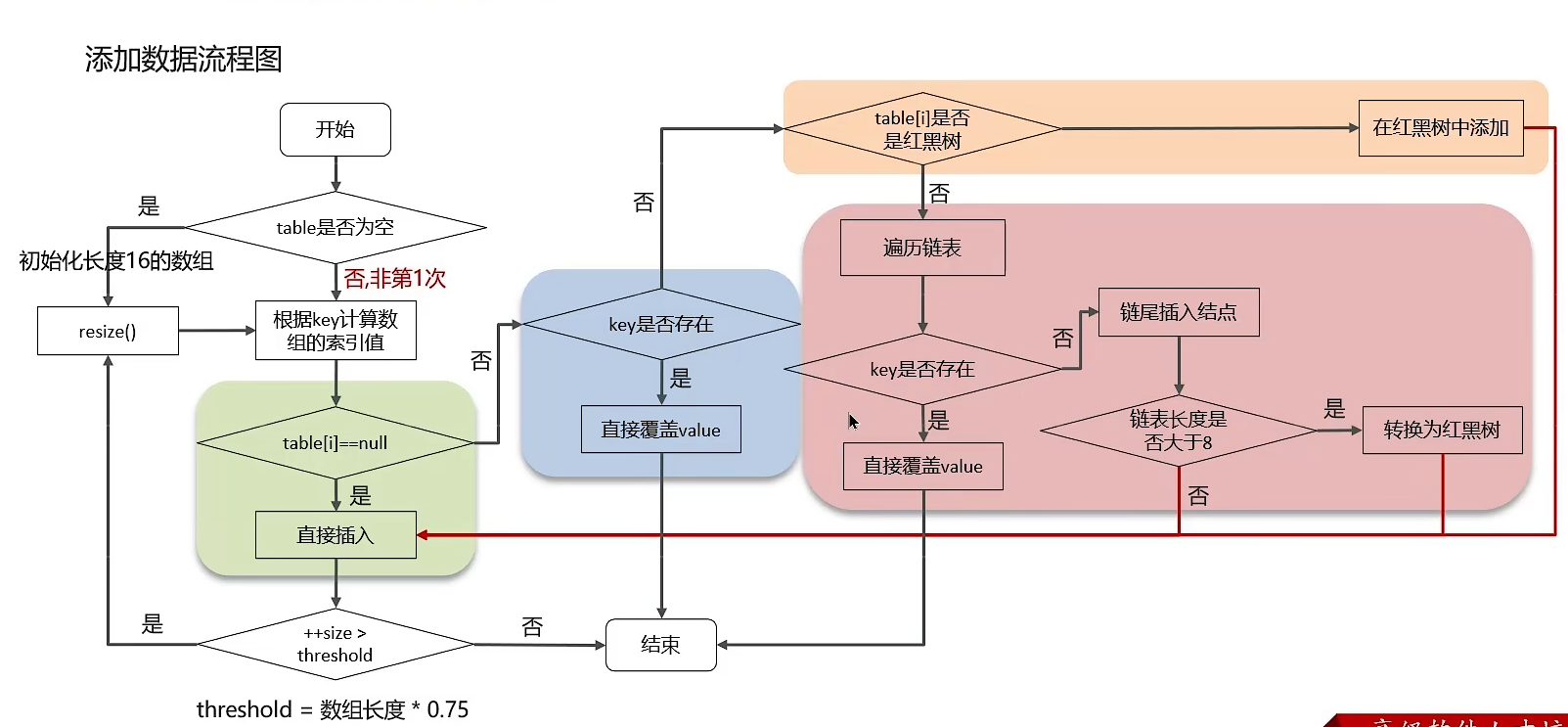
1.1 使用put方法时,利用key的hashCode重新计算hash值得出当前元素在数组中的下标。
1.2 出现hash冲突的情况:
1.2.1 key相同,则覆盖原始值
1.2.2 key不相同,即hash冲突,则将当前的key-value放入链表或红黑树中(当链表的长度大于8且数组的长度大于64时,链表才会进化为红黑树)
1.3 获取数据时,直接找到hash值对应的下标,再进一步判断key是否相同,从而找到响应的值。
2. HashMap在jdk1.7和jdk1.8中有何不同
2.1 jdk1.8之前采用的是拉链法,即数组和链表相结合,如果遇到哈希冲突,则直接将数据加到链表中即可。
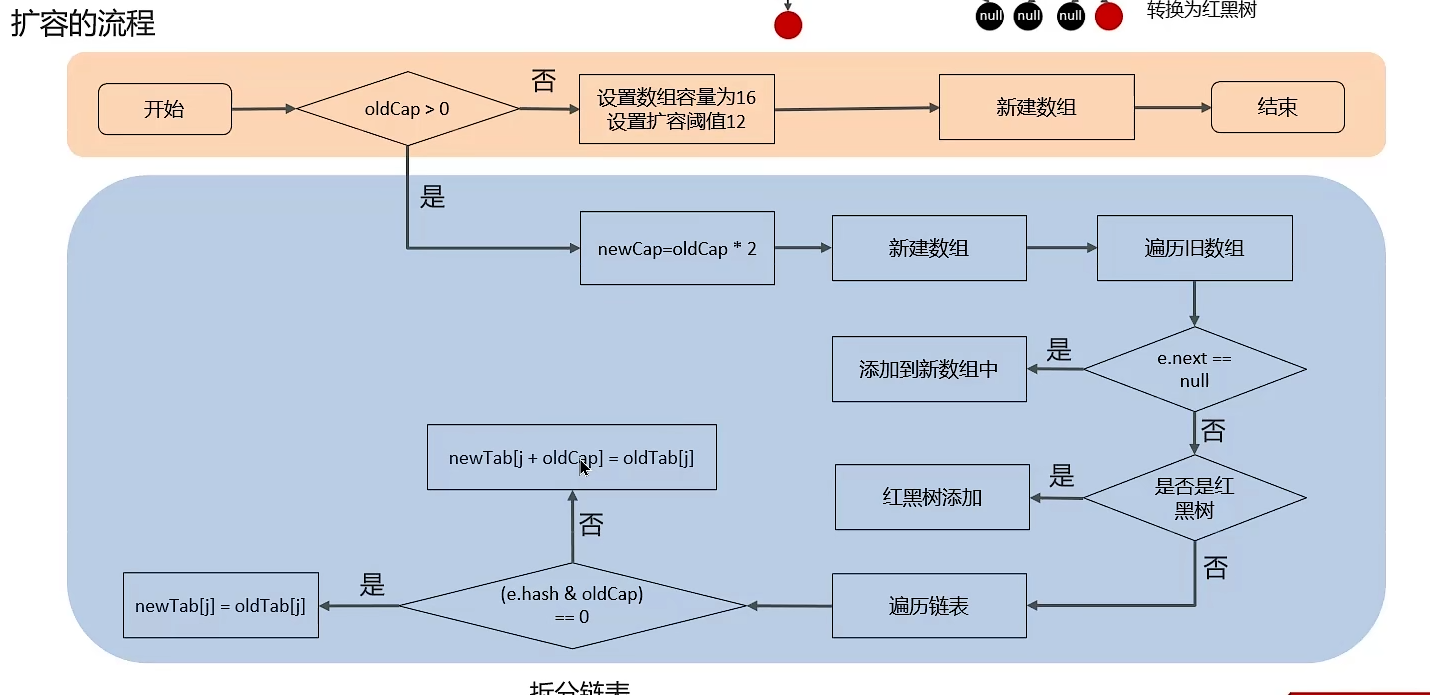
2.2 jdk1.8在解决哈希冲突时有了大变化,当链表长度大于阈值(默认8)时并且数据长度打到64时,则链表会转化为红黑树,以减少搜索数据的时间。扩容resize()时,红黑树拆分成的树节点数小于等于临界值6时,则退化为链表。
3. HashMap的put方法的具体过程
3.1 常见属性


HashMap是懒惰加载的,在创建对象时并没有初始化数组。在无参构造器中设置了默认的加载因子为0.75。
3.2 添加数据的具体过程
4. HashMap的扩容机制
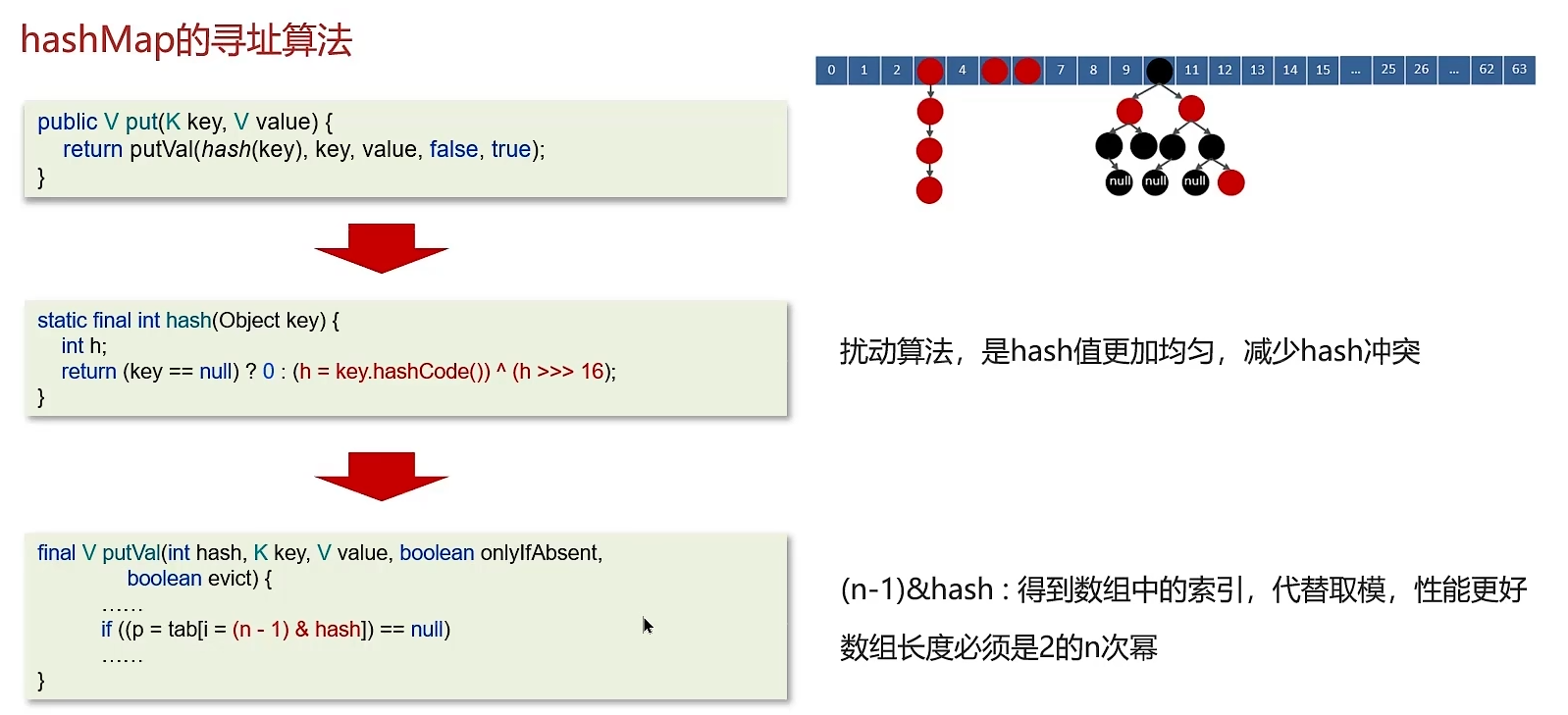
5. HashMap的寻址算法
5.1 计算key的hashCode()
5.2 再进行调用hash()方法进行二次哈希运算,hashCode值右移16位。
5.3 最后 (容量 - 1 ) & hash 得到索引
6. 为何HashMap的数组长度一定是2的n次幂
6.1 计算索引 时效率更高,如果是2的n次幂可以使用位与运算取代取模
6.2 扩容时重新计算索引效率更高: hash & oldCap == 0 的元素留在原位,否则 新位置 = 旧位置 + oldCap。
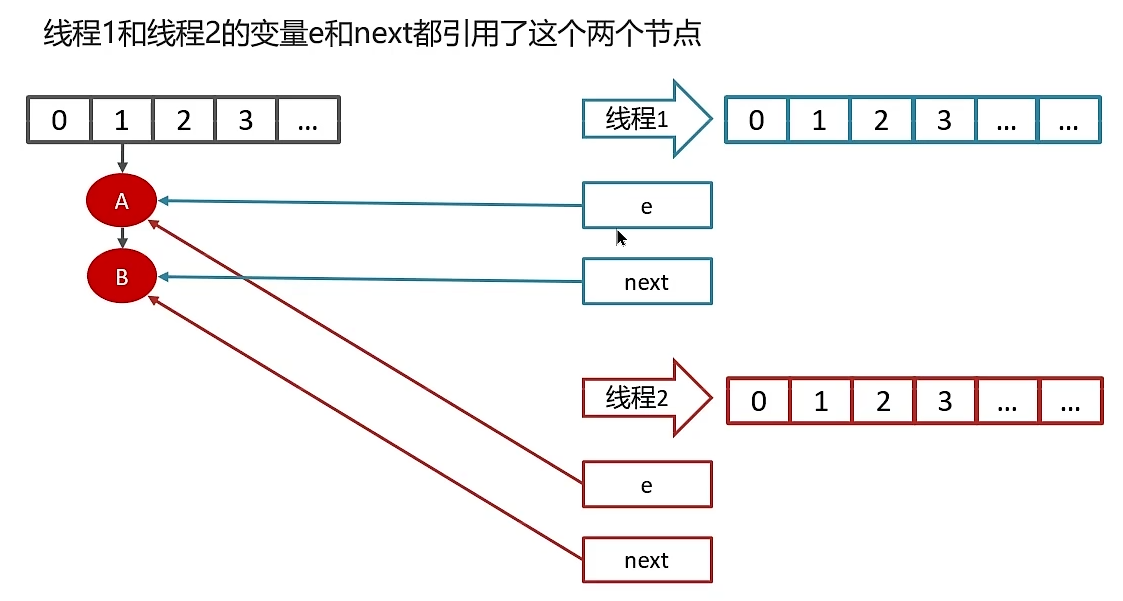
7. JDK 1.7 HashMap的在多线程出现死循环的问题
数据进行扩容时,由于链表使用的是头插法,在数据迁移的过程中有可能出现死循环。
如下:
线程一 : 读取到当前hashMap的数据,数据中有一个链表,在准备扩容时,线程二接入;
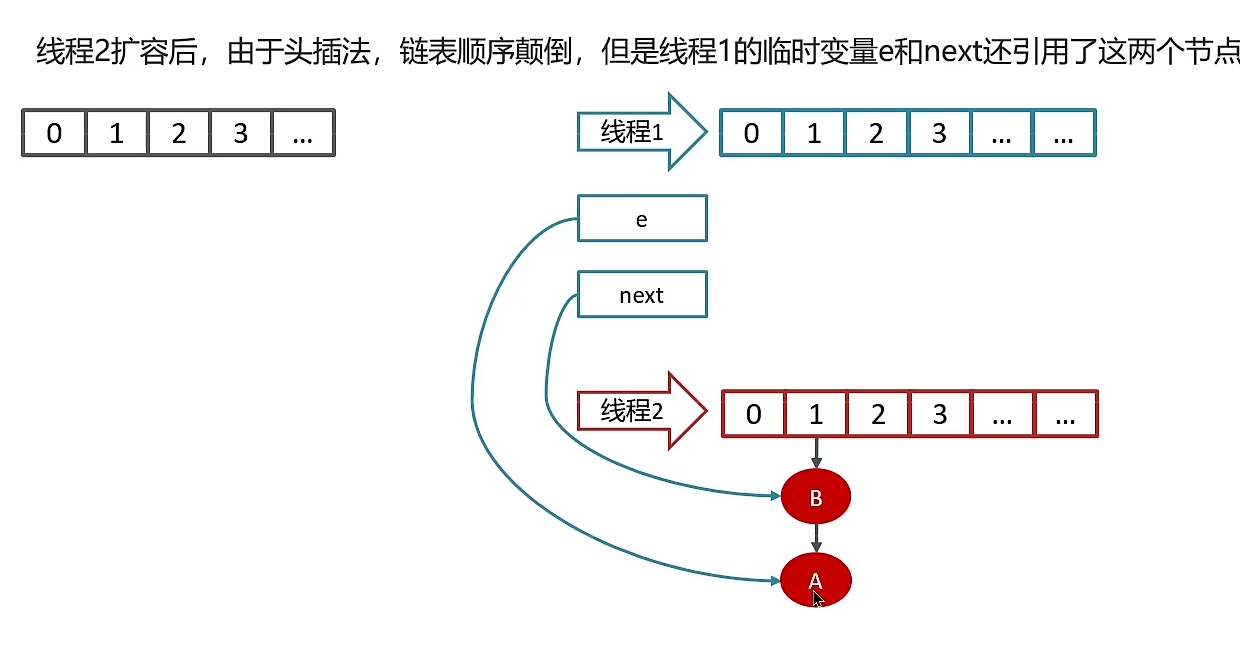
线程二: 读取该map,直接进行扩容,根据头插法,链表数据迁移后会颠倒过来,顺序由A->B改为B->A,线程二结束。
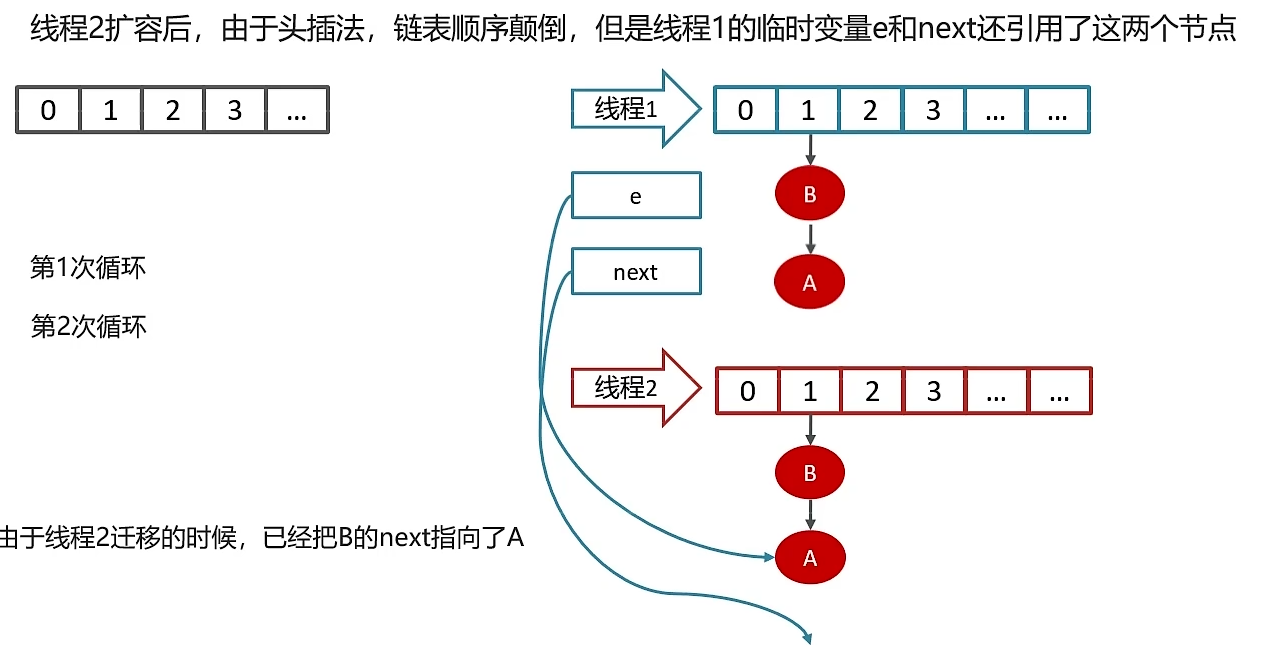
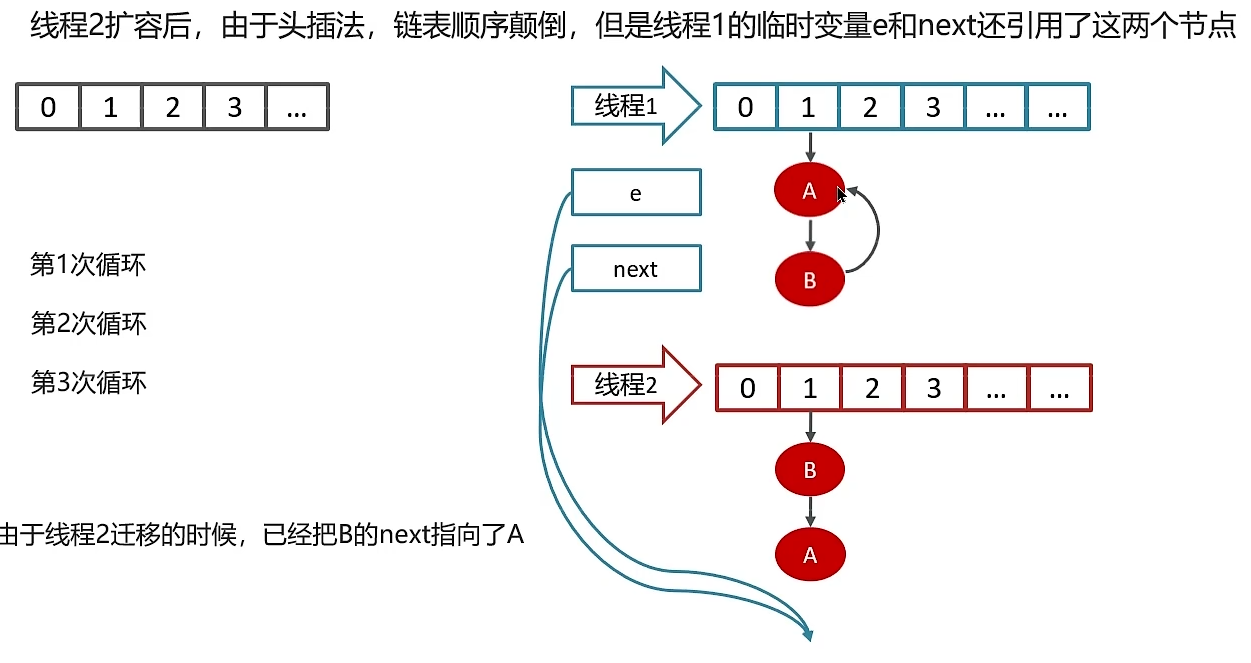
线程一继续执行,再次使用头插法,将链表改为A->B,由于刚才线程二的原因,B的next指向了A,链表就会变成 A->B->A的情况,后期其他线程访问该map时,就会出现链表的死循环。
JDK1.8 中将扩容算法改为了尾插法,从而避免了该问题。