前言
- 如何设计一个高并发秒杀系统?(CDN + 限流 + Redis 扣库存 + MQ 削峰)
- 分布式 ID 生成方案?(Snowflake、号段模式、UUID 优化)
- 如何设计短链系统?(自增 ID + 62 进制 + 布隆过滤器)
- 接口幂等性如何保证?(Token 机制、唯一索引、状态机)
1、如何设计一个高并发秒杀系统?
核心挑战是 瞬时高并发(10w+ QPS) + 防超卖 + 系统稳定性 。设计原则:层层拦截、异步解耦、多级缓存。
如下所示:
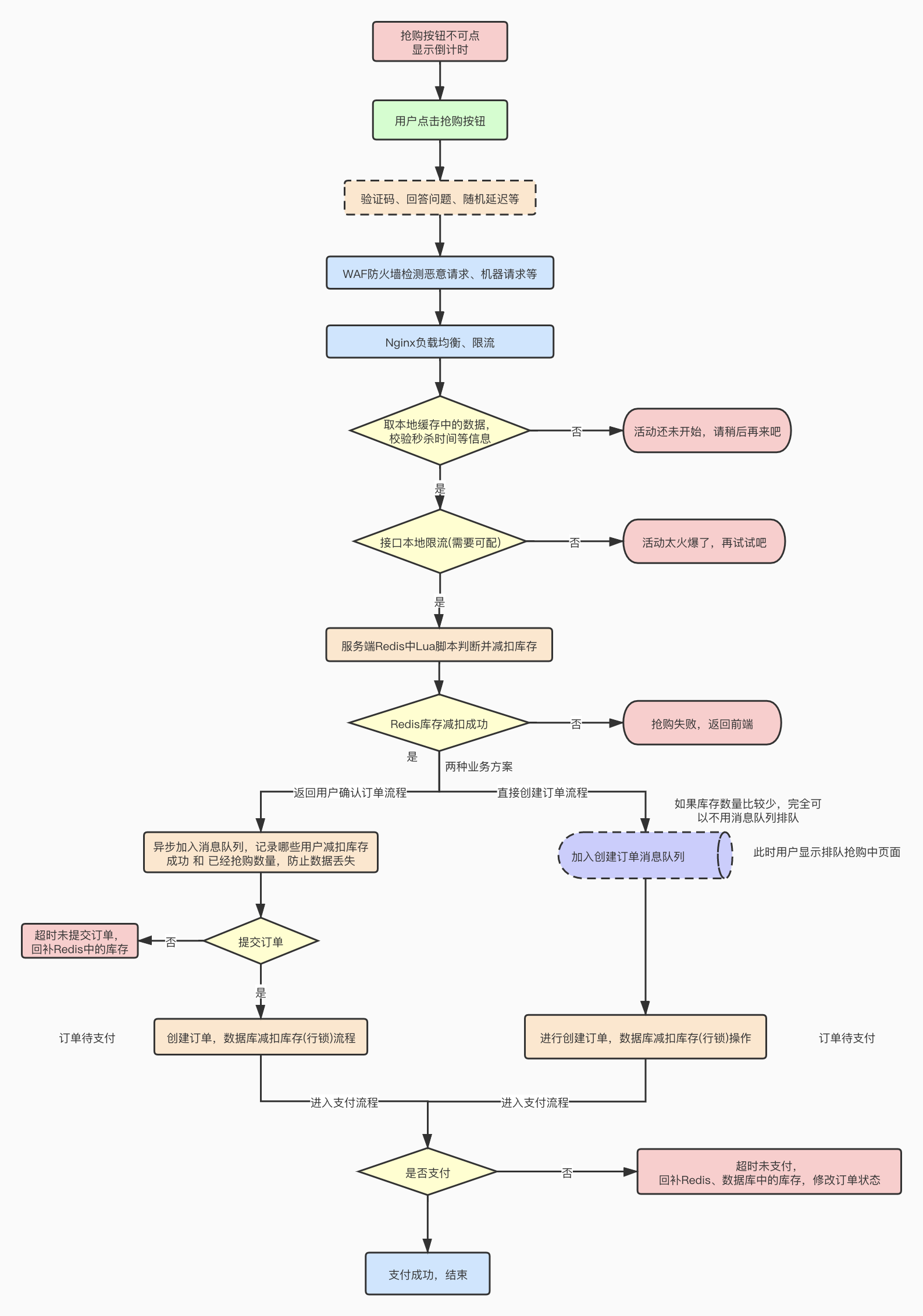
一、整体架构(分层设计)秒杀
rust
[用户]
↓
[CDN] → 静态页面缓存(HTML/JS/CSS)
↓
[Nginx/OpenResty] → IP/用户限流 + 答题验证
↓
[API 网关] → 熔断降级 + 用户鉴权
↓
[秒杀服务] → Redis+Lua 扣库存 + 发 MQ
↓
[订单服务] ← MQ 消费 → 创建订单 + DB 落库
↓
[前端轮询/WebSocket] ← 通知结果二、关键环节详解
- 前端层:静态化 + 按钮控制
-
CDN 缓存:秒杀页面、JS、CSS 全部缓存,减少后端请求;
-
按钮置灰:秒杀开始前禁用,开始后启用;
-
合并请求:下单 + 查询库存合并为一个接口。
-
接入层:限流 + 防刷
-
服务层:原子扣库存
库存预热:秒杀开始前,将库存加载到 Redis:
-
Nginx 限流:
Lualimit_req_zone $binary_remote_addr zone=ip:10m rate=10r/s; limit_req_zone $http_x_user_id zone=user:10m rate=2r/s; -
答题/验证码:防止机器人刷单;
-
IP 黑名单:实时封禁高频 IP。
Lua
SET stock:1001 100Lua 脚本保证原子性:
Lua
-- 扣减库存
if redis.call('GET', KEYS[1]) >= tonumber(ARGV[1]) then
return redis.call('DECRBY', KEYS[1], ARGV[1])
else
return -1
end- 先扣库存,再发 MQ:避免超卖。
- 异步解耦:MQ 削峰
-
扣库存成功后,发送消息到 RocketMQ/Kafka;
-
后台消费者异步创建订单、扣减 DB 库存;
-
前端通过轮询 or WebSocket 获取结果。
- 数据层:多级缓存 + 最终一致性
-
本地缓存(Caffeine):缓存商品信息;
-
Redis:存储库存、用户资格;
-
MySQL:最终持久化,通过 MQ 保证一致性。
- 稳定性保障
-
熔断降级:库存服务不可用时,返回"稍后再试";
-
独立部署:秒杀服务与主站物理隔离;
-
压测预案:提前全链路压测,准备扩容方案。
三、超时处理
-
延迟队列:订单创建后,加入 Redis ZSet(score=过期时间);
-
定时任务:每秒扫描 ZSet,释放未支付库存(同样用 Lua 原子操作)。
四、最佳实践
-
提到 热点 Key 优化:分库存(stack_1,stack_2...) + 本地缓存兜底;
-
举例:某电商秒杀,QPS 从 2k 提升到 8w,超卖率为 0;
-
强调:秒杀的核心是"库存扣减原子性 + 请求拦截"。
2、分布式 ID 生成方案?
分布式 ID 需满足:全局唯一、趋势递增、高性能、高可用。
1、主流方案对比
| 方案 | 原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| UUID | 128 位随机 | 全球唯一、无中心 | 无序、长(36 字符) | 日志 ID、非 DB 主键 |
| Snowflake | 时间戳 + 机器 ID + 序列号 | 趋势递增、高性能 | 依赖时钟、需分配 workerId | 订单 ID、消息 ID |
| 号段模式 | DB 预取一段 ID | 高性能、DB 依赖低 | 有 DB 依赖 | 用户 ID、业务 ID |
| ULID | 时间戳 + 随机 | 有序、兼容 UUID | 新方案,生态少 | 替代 UUID |
二、详细方案
- Snowflake(雪花算法)
-
结构(64 位):
-
1 bit:符号位(固定 0)
-
41 bit:时间戳(毫秒,可用 69 年)
-
10 bit:机器 ID(1024 节点)
-
12 bit:序列号(4096/毫秒)
-
-
问题 :时钟回拨 → ID 重复;
-
解决方案:
-
等待时钟追上;
-
抛异常(美团 Leaf);
-
使用 NTP 服务 保证时钟同步。
-
- 号段模式(Segment)
-
原理:
-
从 DB 获取一段 ID(如 [1000, 2000));
-
缓存在内存中分配;
-
用完再取。
-
-
优势:
-
减少 DB 访问(1 次 DB → 1000 个 ID);
-
性能高(≈ Snowflake)。
-
-
优化 :双 buffer(用到 80% 时异步加载下一段)。
- UUID 优化:ULID
-
结构:48 位时间戳 + 80 位随机;
-
优点:
-
字符串有序(按时间排序);
-
兼容 UUID 格式(26 字符);
-
无中心。
-
三、工业级方案
-
美团 Leaf:支持号段模式 + Snowflake;
-
百度 uid-generator:基于 Snowflake,解决时钟回拨;
-
滴滴 TinyID:基于号段,提供 HTTP 接口。
四、最佳实践
-
提到 ZooKeeper 分配 workerId(Snowflake);
-
举例:用号段模式生成用户 ID,QPS 达 50w+;
-
强调:Snowflake 适合趋势递增场景,号段模式适合强顺序场景。
3、如何设计短链系统?
短链系统目标:**将长 URL 转为短字符串(如 https://t.cn/abc12)。要求:唯一、短、高性能。
如下所示: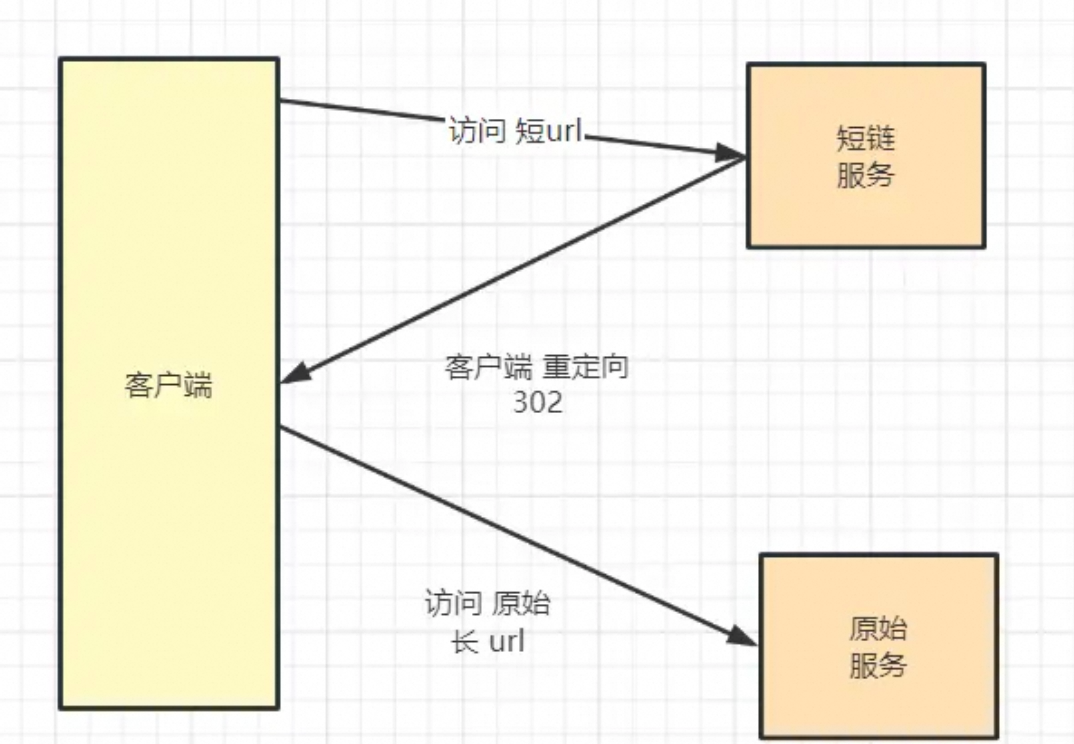
一、核心流程
rust
[用户] → POST /shorten { "url": "https://..." }
↓
[服务] → 1. 生成唯一 ID(自增 or Snowflake)
2. 转 62 进制 → 短码(如 abc123)
3. 存 Redis(短码 → 长 URL)
4. 返回 https://t.cn/abc123
↓
[用户] → GET /abc123
↓
[服务] → Redis 查询 → 302 重定向二、关键技术
- ID 生成
-
自增 ID(MySQL):
-
简单,但单点瓶颈;
-
可分库分表(user_id % 1024)。
-
-
Snowflake:无 DB 依赖,趋势递增。
- 62 进制转换
-
字符集:
0-9+a-z+A-Z(62 个); -
算法:
javapublic static String toBase62(long id) { char[] chars = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ".toCharArray(); StringBuilder sb = new StringBuilder(); while (id > 0) { sb.append(chars[(int) (id % 62)]); id /= 62; } return sb.reverse().toString(); } -
长度:6 位可支持 568 亿(62^6)。
-
Redis Hash:
- 存储
- Redis Hash:
java
HSET short_urls abc123 "https://original.com"- 过期时间 :
EXPIREshort_urls365d(按需)。
- 防重复
-
布隆过滤器:
-
初始化时加载所有短码;
-
生成前先 check,避免碰撞。
-
-
唯一索引:DB 中 short_code 唯一。
三、高可用设计
-
缓存穿透:布隆过滤器 + 空值缓存;
-
热点短链:本地缓存(Caffeine)兜底;
-
扩容:ID 生成器支持分段。
四、最佳实践
- 提到 自定义进制 (如 64 进制,加
-和_); - 举例:短链系统支持 10 亿 URL,6 位短码;
- 强调:62 进制比 36 进制更短,比 16 进制更紧凑。
4、接口幂等性如何保证?
幂等性:同一请求执行多次,结果与执行一次相同 。在分布式系统中,因网络超时、重试、MQ 重投,必须保证幂等。
一、四大方案
- Token 机制(防重 Token)
-
下单前,GET /token → 返回唯一 token;
-
提交订单时,携带 token;
-
服务端校验 token(Redis 原子操作):
Lua
if (redis.setex("token:" + token, 300, "1", SET_IF_NOT_EXIST)) {
// 处理业务
} else {
return "重复提交";
}- 唯一索引
适用:表单提交、支付。
原理:DB 唯一约束防止重复插入;
sql
CREATE UNIQUE INDEX uk_order_user ON orders(user_id, product_id);- 状态机
原理:业务有明确状态流转,重复请求因状态不符被忽略;
java
if (order.getStatus() == PAID) {
return; // 已支付,忽略重复
}- 去重表
原理:消息带唯一 ID,消费前查去重表;
sql
CREATE TABLE dedup (
msg_id VARCHAR(64) PRIMARY KEY,
create_time DATETIME
);- 适用:MQ 消费、回调接口。
二、MQ 场景幂等
-
Kafka/RocketMQ:消息可能重复投递;
-
必须业务层幂等,不能依赖 offset。
三、最佳实践
-
提到 Redis 原子操作 :
SET token EX 300 NX; -
举例:支付系统用订单号 + 唯一索引,0 重复扣款;
-
强调:幂等性是分布式系统的基石,必须前置设计。