前言
OkHttp 是一个非常优秀的网络请求框架,几乎每个 Android 开发人员应该都使用过它。
本文深入介绍了 Okhttp 的整体框架结构,OkhttpClient重点属性深度解释,并且深度分析 了一次完整的的 Http 请求在Okhttp中是如何实现的 ,我个人习惯系统性了解一项技术而不是单纯的罗列源码通篇讲解,因为只有建立出系统,才能理解的更透彻,这样记忆会非常深刻。因此我侧重使用画图的方式来分析 Okhttp(只有关键源码),图是重点,文字是辅助
这篇文章应该是你从未见过的OkHttp 全流程网络请求的深入解读,它同时也可能解惑你在其它博客中找不到答案的疑问。
OkHttp 发展背景
-
诞生背景
在OkHttp出现之前,Android开发者主要使用Apache的
HttpClient和Google自家的HttpURLConnection进行网络请求。但这两者多少都会存在一些问题。美国的移动支付公司Square在开发过程中,深感这些原生网络库难以满足其需求,便在2013年开源了OkHttp。 -
发展之路: 从包装到替代
OkHttp并非一开始就完全另起炉灶,其发展经历了几个阶段:
- 初期包装 :最初,OkHttp是对原生
HttpClient和HttpURLConnection的封装,旨在提供更友好、统一的API。 - 剥离与独立 :随着Apache宣布弃用
HttpClient,OkHttp也移除了对其的支持。后来,Square团队认为HttpURLConnection也不够好用,索性去掉了对它的依赖,转而直接从 Socket 层完全重写整个 Http 网络请求**,实现了真正的独立。 - 反向影响 :OkHttp因其出色的设计和性能,受到了广大开发者的欢迎。Google也注意到了这一点,并在Android 4.4 (KitKat) 系统中,将
HttpURLConnection的底层实现替换成了OkHttp**。这意味着,即使你在代码中使用的是标准的HttpURLConnection,其底层实际使用的 Okhttp的代码。 - 向Kotlin迈进:从OkHttp 4版本开始,Square开始使用Kotlin语言进行重写
- 初期包装 :最初,OkHttp是对原生
OkHttp 整体框架
首先我们先看一下使用 Okhttp 如何完成一个网络请求:
kotlin
//okhttp 网络请求示例(异步)
val client = OkHttpClient()
val request = Request.Builder()
.url("")
.build()
client.newCall(request)
.enqueue(object : Callback {
override fun onFailure(call: Call, e: IOException) {
//处理错误
}
override fun onResponse(call: Call, response: Response) {
//处理 response
}
})代码非常简单,这得益于 Okhttp 优秀的框架设计,以下是以一次网络请求流程的视角来系统的了解 Okhttp 的整体结构:
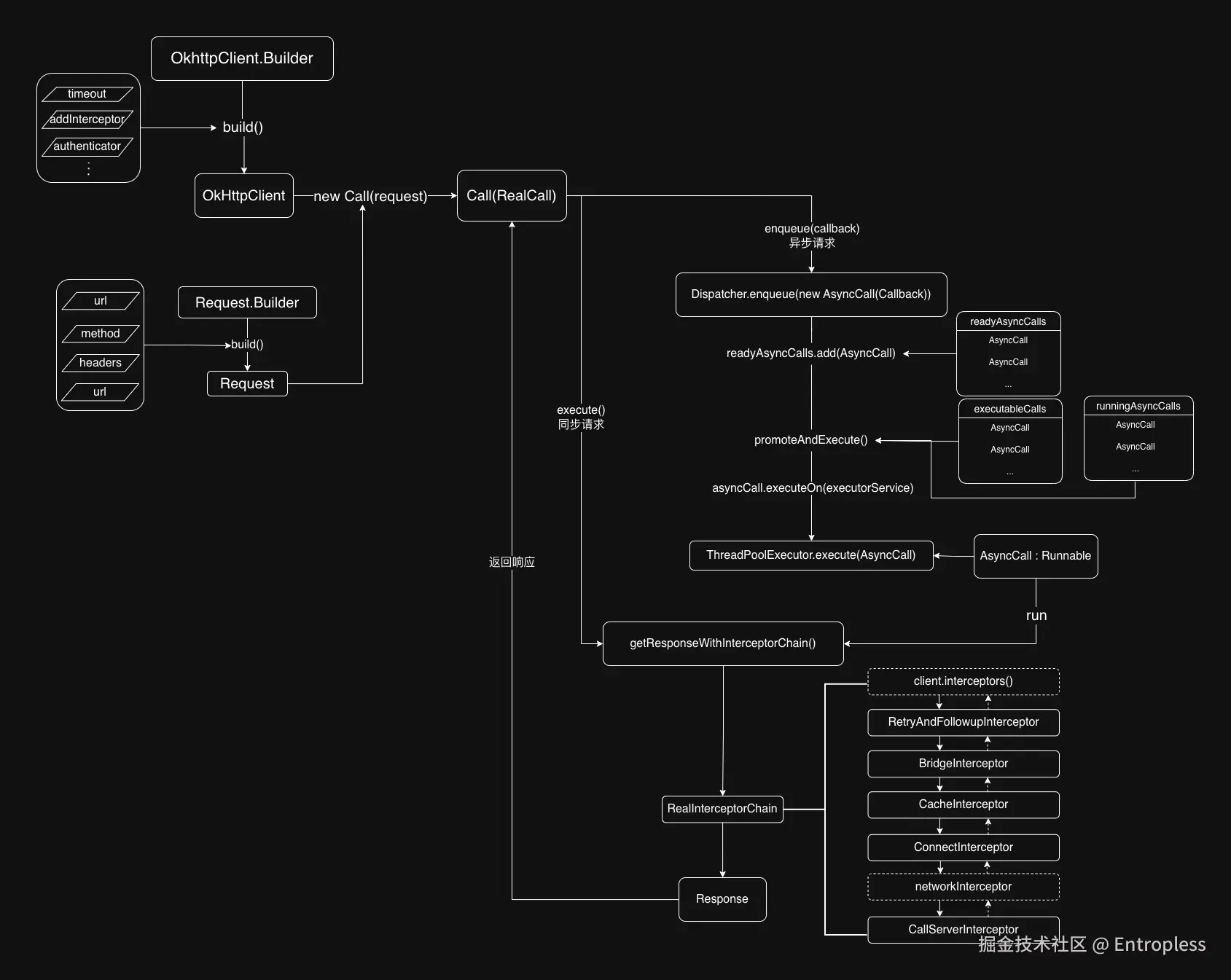
文字说明:
-
通过 OkHttpClient.Builder 来构造出一个 OkHttpClient 实例(这个实例在绝大部分场景都应该是单例的),后面会详细介绍 OkHttpClient 中各个属性配置的作用
-
通过 Request.Builder 来构造出一个 Request 实例,这表示一个 originalRequest(原始请求),开发者需要配置一个请求的基础参数
-
通过 newCall 方法(携带 request 参数)创建一个 Call 对象,实际为 RealCall 实例,它包含了以下参数:
kotlinclass RealCall( val client: OkHttpClient,//开发者创建出来的 OkHttp Client 实例 /** 一个未经重定向或者没有添加认证头的原始请求, 也就是未经OkHttp内部处理的请求,并不是实际发给服务器的请求 */ val originalRequest: Request, val forWebSocket: Boolean //发起的是否是一个WebSocket请求,因为WebSocket也是基于Http的协议 ) : Call { ...... }也就是说我们创建的这个原始请求对象,被转化为 了一个 RealCall,后面的每个 RealCall 就代表了一个请求
-
开始使用 execute(同步)/enqueue(异步)的方式发起一个 Http 请求
-
enqueue 方式: enqueue 需要传入一个 callback 对象来接收返回结果,整体逻辑如下:
kotlinoverride fun enqueue(responseCallback: Callback) { //检查请求的执行状态 check(executed.compareAndSet(false, true)) { "Already Executed" } //事件记录,标记开始执行请求 callStart() //初始化一个异步的 Call,并入队 client.dispatcher.enqueue(AsyncCall(responseCallback)) }💡 PS: 关于check 方法,这是 Kotlin 标准库中的方法,它内部使用的是 Kotlin Contract 这个高级特性
此处简单介绍下这个方法,因为在 Okhttp 中大量使用到了它
kotlin@kotlin.internal.InlineOnly public inline fun check(value: Boolean, lazyMessage: () -> Any): Unit { contract { returns() implies value } if (!value) { val message = lazyMessage() throw IllegalStateException(message.toString()) } }contract 表示契约,implies 表示 暗示,这个方法的作用是 开发者 告诉 编译器 如果 check 方法能够正常返回(也就是不会抛出异常),则暗示检查成功,否则抛出异常信息。
enqueue 方法中 check 的作用就是请求执行状态的检查
-
**
executed**是一个AtomicBoolean,用于标记这个Call是否已被执行过。compareAndSet(false, true)尝试将其值从false设置为true。 -
check函数 :如果传入的表达式结果为false(即设置失败,说明executed已经是true,意味着这个Call已经被执行过),check函数就会抛出一个IllegalStateException,异常信息为 "Already Executed"。 -
这保证了 一个
Call实例只能被执行一次,这是 OkHttp 防止重复请求的重要设计。
🔑 关于 Contract 的更深入理解,后面会单写一篇文章
keep on :
kotlininternal fun enqueue(call: AsyncCall) { synchronized(this) { //将这个请求添加到准备执行的队列中 readyAsyncCalls.add(call) /**下面这两行代码的意思是:找到与当前的这个请求主机名相同的Call, 然后使它们共享「同一个主机请求个数」这个变量。 为何共享?因为 Okhttp 要求同一个主机的请求个数不能大于5个(默认) */ if (!call.call.forWebSocket) { val existingCall = findExistingCallWithHost(call.host) if (existingCall != null) call.reuseCallsPerHostFrom(existingCall) } } //开始推举并执行请求 promoteAndExecute() }kotlin//promote 表示推动,意思就是对readyAsyncCalls中 Call 进行进一步的挑选,然后执行 private fun promoteAndExecute(): Boolean { this.assertThreadDoesntHoldLock() //遍历 readyAsyncCalls,挑选出不会导致超负载的 Call 来添加至 executableCalls //同时也会添加到 runningAsyncCalls中(runningAsyncCalls中也包含已取消单但未执行完的Call) //runningAsyncCalls 主要用于记录正在运行的 Call val executableCalls = mutableListOf<AsyncCall>() val isRunning: Boolean synchronized(this) { val i = readyAsyncCalls.iterator() while (i.hasNext()) { val asyncCall = i.next() if (runningAsyncCalls.size >= this.maxRequests) break // Max capacity. if (asyncCall.callsPerHost.get() >= this.maxRequestsPerHost) continue // Host max capacity. i.remove() asyncCall.callsPerHost.incrementAndGet() executableCalls.add(asyncCall) runningAsyncCalls.add(asyncCall) } isRunning = runningCallsCount() > 0 } //开始遍历 executableCalls 然后执行每个 AsyncCall for (i in 0 until executableCalls.size) { val asyncCall = executableCalls[i] asyncCall.executeOn(executorService) } return isRunning }由于 AsyncCall 继承了 Runnable ,因此它表示一个需要放进线程池中执行的具体任务,这是异步请求的核心(此处仅贴出核心代码)
kotlininternal inner class AsyncCall( private val responseCallback: Callback ) : Runnable { @Volatile var callsPerHost = AtomicInteger(0) private set fun reuseCallsPerHostFrom(other: AsyncCall) { this.callsPerHost = other.callsPerHost } ... fun executeOn(executorService: ExecutorService) { ... executorService.execute(this) ... } override fun run() { ... //这是异步任务的核心,通过拦截器链的链式调用方式执行一个请求并返回结果 val response = getResponseWithInterceptorChain() ... //把返回的 response 传给 callback responseCallback.onResponse(this@RealCall, response) ... } } -
OkHttpClient详解
OkHttpClient 中管理的是Okhttp 网络请求中各种参数配置,因此了解它里面的每个参数含义及作用非常重要
kotlin
class Builder constructor() {
// 基于线程池的管理和分配请求任务的调度器
internal var dispatcher: Dispatcher = Dispatcher()
//连接池,负责批量管理连接对象,功能:查找、创建、复用、存储连接,实际工作对象是 RealConnectionPool
//核心是通过 ConcurrentLinkedQueue 实现的
internal var connectionPool: ConnectionPool = ConnectionPool()
//自定义拦截器,用于添加请求头,修改 URL 打印日志等
internal val interceptors: MutableList<Interceptor> = mutableListOf()
//网络拦截器,主要用于调试服务返回的原始数据
internal val networkInterceptors: MutableList<Interceptor> = mutableListOf()
//网络请求过程中各种事件的监听器
internal var eventListenerFactory: EventListener.Factory = EventListener.NONE.asFactory()
//连接失败重试,重试指的是在有其它可行的路线下才会重试,比如多IP主机一个IP失败会重试其它的IP,
internal var retryOnConnectionFailure = true
//认证器,当服务器返回认证失败 401 or 407 时,会回调这个认证器,如果需要刷新Token则需要重写并在回调中处理
internal var authenticator: Authenticator = Authenticator.NONE
//是否重定向
internal var followRedirects = true
//是否允许协议切换的重定向(Http <=> Https)
internal var followSslRedirects = true
//cookieJar表示cookie存储器,用于在客户端保存一些请求状态信息,默认实现是空,移动端一般不使用
internal var cookieJar: CookieJar = CookieJar.NO_COOKIES
//服务端数据的缓存
internal var cache: Cache? = null
//域名解析
internal var dns: Dns = Dns.SYSTEM
//正向代理配置:DIRECT,HTTP,SOCKS
internal var proxy: Proxy? = null
//代理选择器,它的默认配置是:当 proxy 为空时,ProxySelector会返回NullProxySelector,也就是直连
//当 proxy不为空时,NullProxySelector也会返回NullProxySelector,因为起作用的是proxy,也就是ProxySelector属性失效
internal var proxySelector: ProxySelector? = null
//与authenticator相同,当配置的代理服务器要求认证时也会回调authenticate函数
internal var proxyAuthenticator: Authenticator = Authenticator.NONE
//用于创建 Socket 连接的工厂类
internal var socketFactory: SocketFactory = SocketFactory.getDefault()
//用于创建 TLS连接的工厂类
internal var sslSocketFactoryOrNull: SSLSocketFactory? = null
//证书管理器,验证证书有效性,x509 表示证书格式
internal var x509TrustManagerOrNull: X509TrustManager? = null
//连接规范,用于记录支持的TLS协议版本和加密套件(cipherSuites)
//默认连接规范:Https使用MODERN_TLS(最合适的TLS配置),Http 使用明文传输
internal var connectionSpecs: List<ConnectionSpec> = DEFAULT_CONNECTION_SPECS
//支持的协议 Http 1.0/1.1/2;SPDY(废弃,Http2 的前身);H2_PRIOR_KNOWLEDGE(HTTP2的明文版);QUIC(HTTP3 没有实现只提供拦截器入口)
internal var protocols: List<Protocol> = DEFAULT_PROTOCOLS
//主机名验证器,用于验证证书主机名与请求中的主机名是否一致,无特殊要求不可自定义这个属性
internal var hostnameVerifier: HostnameVerifier = OkHostnameVerifier
//证书固定器,通过硬编码方式将证书固定,也就是除了验证证书合法性之外,还需要确定是指定的那个证书
internal var certificatePinner: CertificatePinner = CertificatePinner.DEFAULT
//证书链清理员,它的作用是:1.操作X509TrustManager 返回证书链列表 2. 清理与TLS握手无关的证书
internal var certificateChainCleaner: CertificateChainCleaner? = null
//整个调用周期的超时时间,默认不限制,但内部的连接,读写有超时限制
internal var callTimeout = 0
internal var connectTimeout = 10_000//连接超时
internal var readTimeout = 10_000//读超时
internal var writeTimeout = 10_000//写超时
internal var pingInterval = 0//http2 和 websocket 的心跳间隔
//websocket 中被压缩的最小的消息大小,默认 1024,即当消息>=1024时会被压缩
internal var minWebSocketMessageToCompress = RealWebSocket.DEFAULT_MINIMUM_DEFLATE_SIZE
//路由数据库,用于记录有故障的路由,便于寻找备用路由
internal var routeDatabase: RouteDatabase? = null
}重点说明的几个属性:
-
connectionPool连接池的原理:
RealConnectionPool是实际的连接池管理类,它内部使用
ConcurrentLinkedQueue<RealConnection>的来存储连接对象,这表明对于连接池的单个操作是线程安全的,连接池负责 OkHttpClient 实例整个生命周期内TCP 连接的查找、复用、创建、存储、清理等工作PS :
ConcurrentLinkedQueue只能保证多线程操作中对它的单个操作是安全的,但如果是复合操作仍然需要加锁,这是多线程开发中要注意的点,OkHttp 源码注释中也强调了这一点:kotlin/** * Holding the lock of the connection being added or removed when mutating this, and check its * [RealConnection.noNewExchanges] property. This defends against races where a connection is * simultaneously adopted and removed. */ private val connections = ConcurrentLinkedQueue<RealConnection>()其中 OkHttp 的连接复用机制是体现 OkHttp 性能的重点技术,它的复用逻辑主要有两种:
- 对于 Http1.1 ,由于 Http 1.1 开始支持
Keep-Alive,因此一个当一个 Http 请求结束时,TCP 连接并不会立即释放,如果有新的请求发起,会经过一系列条件判断是否可以复用已有的连接,如果符合复用条件,这样就减少了一次 TCP 的握手动作,同时也减少了连接对象的创建,减少了内存开销。 - 对于 Http2,由于 Http2 支持Multiplexing(多路复用),也就是Http2支持在同一个 TCP 连接上同时可以发起多个 Http 请求,这样新请求也可以复用符合条件的TCP 连接,并且不需要等待连接空闲(不超负载)
- 对于 Http1.1 ,由于 Http 1.1 开始支持
-
followRedirects与followSslRedirects的关系followRedirects表示是否允许重定向,默认值是true,followSslRedirects表示在followRedirects=true的前提下,是否允许进行协议切换(Http ↔ Https)的重定向,默认值也是 true,但是在一些高安全场景要求下,需要将followSslRedirects设置为 false,以防止协议攻击 -
certificatePinner证书固定器,通过硬编码方式将证书的哈希信息固定,也就是除了验证证书合法性之外,还需要确定是指定的那个证书,否则也不能通过验证
使用方式:
java//1. 先使用错误的哈希值测试一下,把服务器证书正确的哈希值打印出来 String hostname = "publicobject. com"; CertificatePinner certificatePinner = new CertificatePinner.Builder() .add(hostname, "sha256/ AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA=") .build(); OkHttpClient client = OkHttpClient. Builder() .certificatePinner(certificatePinner) .build(); Request request = new Request. Builder() .url("https://" + hostname) .build(); client.newCall(request).execute(); //2.打印出正确哈希值 //3.再把正确的哈希值替换过去⚠️注意:使用它比较危险,如果服务器证书更换了,可能导致客户端无法使用,因为由于是硬编码了证书哈希, 所以无法访问服务器了
PS: CertificatePinner 也可以用于防止那些基于 VPN 的抓包软件(如 Drony),因为抓包软件 原理是让用户主动信任证书,如果固定了证书签名,也就无法通过它们直接抓包了 -
pingIntervalQ:为什么H2 & ws 协议才需要心跳间隔,Http1.1 也是长连接,为什么不需要?
A:因为 Http1.1 中的请求是单个执行的,同一个 TCP 连接上两个请求之间的间隔时间超过限制,连接允许被释放,但在H2 中由于多个请求是并行的,TCP 长连接维持时间需要更久
OkHttp 网络请求全过程深度解构
okhttp拦截器运行原理
以下是一个请求过程中拦截器的运行机制,用时序图的方式解释拦截器原理,一目了然,过目不忘!

拦截器运行原理详解
-
RealInterceptorChain
它是管理所有拦截器的的类,链式调用就是由它实现的,
getResponseWithInterceptorChain是拦截器运行的核心方法,内部将所有的拦截器都放在了一个 list 中,然后初始化了RealInterceptorChain的一个实例,并将拦截器列表添加进去,最后通过chain.proceed(originalRequest)方法传入原始请求,启动这个链条,然后经过拦截器对这个originalRequest的层层处理,最终得到一个发往服务器的targetRequestjava@Throws(IOException::class) internal fun getResponseWithInterceptorChain(): Response { // 构建完整的拦截器堆栈 val interceptors = mutableListOf<Interceptor>() interceptors += client.interceptors interceptors += RetryAndFollowUpInterceptor(client) interceptors += BridgeInterceptor(client.cookieJar) interceptors += CacheInterceptor(client.cache) interceptors += ConnectInterceptor if (!forWebSocket) { interceptors += client.networkInterceptors } interceptors += CallServerInterceptor(forWebSocket) val chain = RealInterceptorChain( call = this, interceptors = interceptors,//将拦截器列表添加到拦截器链 index = 0, exchange = null, request = originalRequest, connectTimeoutMillis = client.connectTimeoutMillis, readTimeoutMillis = client.readTimeoutMillis, writeTimeoutMillis = client.writeTimeoutMillis ) var calledNoMoreExchanges = false try { //启动拦截器链 val response = chain.proceed(originalRequest) if (isCanceled()) { response.closeQuietly() throw IOException("Canceled") } return response } catch (e: IOException) { calledNoMoreExchanges = true throw noMoreExchanges(e) as Throwable } finally { if (!calledNoMoreExchanges) { noMoreExchanges(null) } } }首次执行proceed 方法时,从传入的 interceptors 中拿到 index = 0的 Interceptor,然后调用它的
intercept方法执行第一个拦截器,同时将index + 1 ,copy 出一个新的 RealInterceptorChain,传入 intercept 方法中,以此类推,推动整个链条连续执行。java@Throws(IOException::class) override fun proceed(request: Request): Response { check(index < interceptors.size) calls++ if (exchange != null) { check(exchange.finder.sameHostAndPort(request.url)) { "network interceptor ${interceptors[index - 1]} must retain the same host and port" } check(calls == 1) { "network interceptor ${interceptors[index - 1]} must call proceed() exactly once" } } //将 index+1 并拷贝一个新的 RealInterceptorChain 对象 val next = copy(index = index + 1, request = request) //找到当前需要执行的拦截器对象 val interceptor = interceptors[index] @Suppress("USELESS_ELVIS") val response = interceptor.intercept(next) ?: throw NullPointerException( "interceptor $interceptor returned null") if (exchange != null) { check(index + 1 >= interceptors.size || next.calls == 1) { "network interceptor $interceptor must call proceed() exactly once" } } check(response.body != null) { "interceptor $interceptor returned a response with no body" } return response } -
拦截器实例:每个拦截器实例可以分为三部分工作
- Before Proceed:这是拦截器对请求 进行处理的阶段。每个拦截器在调用
chain.proceed(request)方法将请求传递给下一个拦截器之前,会执行自己专属的任务。这通常包括对请求的修改或增强 - Call Proceed:这是责任链的推动环节 。通过调用
chain.proceed(request),当前拦截器将请求控制权交给下一个拦截器,并等待其返回响应。这个调用是拦截器链执行的枢纽 。 - After Proceed:当下一个拦截器返回响应后,当前拦截器对响应进行处理的阶段。拦截器可以检查、修改甚至完全替换返回的响应数据,然后再将其返回给上一个拦截器。
- Before Proceed:这是拦截器对请求 进行处理的阶段。每个拦截器在调用
拦截器拆解分析
-
RetryAndFollowupInterceptor
顾名思义,这是一个用来重试和重定向的拦截器,前置工作主要是初始化一个
ExchangeFinder实例,用于后续查找可用的 TCP 连接,后置工作是判断是否有错误或者是否需要重定向 -
BridgeInterceptor
很简单,Bridge 是桥,表示这是原始请求与实际请求桥接的拦截器,前置工作是用于补全各种请求头,其中会默认添加要求服务器对 返回内容进行 gzip 压缩的请求头;后置工作是对响应头做处理,包括解压缩响应内容
-
CacheInterceptor
前置工作:首先查看有没有本地缓存,有则查看是否过期(根据 Expires/max-age) , 如果没有过期并且可用,则直接返回不再执行后续的拦截器,如果没有或者过期就执行下一个拦截器。 后置工作:如果服务端返回的是304(服务器根据 Etag 或者 Last-Modified) 表示之前缓存的本地请求依然有效可以使用,或者判断是否需要缓存新的请求信息
-
ConnectInterceptor
这是实际查找和建立 TCP 连接的拦截器 前置工作就是使用之前创建的ExchangeFinder 来查找连接池中是否有可用连接(没有后置工作):
- 对于全新请求(未重定向或重试):
-
由于每个 Call 都关联了一个连接对象,所以先尝试重用这个连接,由于是全新请求,因此肯定是 null
-
然后以最快的速度在连接池中查找下有没有可用连接(不使用 Route),不使用 Route 表示只需要连接没有超过负载,并且Address 中的所有配置一致(包括Host、port、proxy、protocol、证书等等)就可重用,
requireMultiplexed=false表示http1.1和 Http2都包括 -
如果找不到,那就通过 Route 来深度查找,OkHttp通过解析 DNS 来获取到 IP 地址列表(List),这次查找的目的是找到可以支持coalescing(连接合并) 的连接,这次
requireMultiplexed依然是 false -
如果还是找不到,那就只能新建一个 TCP 连接
-
在一些特殊情况下,可能有多个请求在极短时间内同时发起,并且同时创建了新的连接,这种情况下如果都是 Http2的请求,那这两个请求可以合并放在同一个 TCP 连接中执行,这样就可以省去一个连接,因此,需要再次查找一遍,这次要求
requireMultiplexed=true,也就是只查找Http2 的连接
-
对于重定向或者重试的连接
由于 Call 中可能已经有了一个连接,因此先检查下是否可以重用,后续步骤与👆一致
以下是findConnection 函数的代码(仅展示核心代码):
kotlinprivate fun findConnection(...): RealConnection { // ... 参数和初始检查已省略 ... // 1. 尝试复用当前请求中已有的连接(如果是重试或者重定向的请求) val callConnection = call.connection if (callConnection != null && /* ... 复用条件检查 ... */) { return callConnection // 复用成功 } // 2. 尝试从连接池中获取一个可用连接(Http1.1 或者 Http2的连接但不会拿到**coalescing** 的连接) if (connectionPool.callAcquirePooledConnection(address, call, null, false)) { return call.connection!! } // 3. 进行路由选择 // ... 路由选择逻辑(可能阻塞)... val route = // ... 确定最终要尝试的路线 (Route) ... // 4. 前两种方式都失败,就创建新的 TCP 连接 val newConnection = RealConnection(connectionPool, route) newConnection.connect(...) // 关键的连接建立过程 // 5. 连接建立后,针对特殊竞争状态,再次尝试查询一次连接池(连接合并) if (!connectionPool.callAcquirePooledConnection(address, call, null, false)) { connectionPool.put(newConnection) // 将新连接放入池中 call.acquireConnectionNoEvents(newConnection) } return call.connection ?: newConnection }以上是 OKHttp 的连接池核心机制的介绍,它确保了连接复用效率的最大化!
其中从连接池获取连接的核心方法是
connectionPool.callAcquirePooledConnectionkotlinfun callAcquirePooledConnection( address: Address, call: RealCall, routes: List<Route>?, requireMultiplexed: Boolean ): Boolean { for (connection in connections) { synchronized(connection) { //希望查找多路复用连接但这个连接不支持多路复用,就放弃掉 if (requireMultiplexed && !connection.isMultiplexed) return@synchronized //这个连接是可用的 if (!connection.isEligible(address, routes)) return@synchronized //获得这个符合要求的连接 call.acquireConnectionNoEvents(connection) return true } } return false }其中的
isEligible方法是根据传入的 address 以及 route 来判断是否符合要求kotlininternal fun isEligible(address: Address, routes: List<Route>?): Boolean { // If this connection is not accepting new exchanges, we're done. if (calls.size >= allocationLimit || noNewExchanges) return false // If the non-host fields of the address don't overlap, we're done. if (!this.route.address.equalsNonHost(address)) return false // If the host exactly matches, we're done: this connection can carry the address. if (address.url.host == this.route().address.url.host) { return true // This connection is a perfect match. } // At this point we don't have a hostname match. But we still be able to carry the request if // our connection coalescing requirements are met. See also: // https://hpbn.co/optimizing-application-delivery/#eliminate-domain-sharding // https://daniel.haxx.se/blog/2016/08/18/http2-connection-coalescing/ // 1. This connection must be HTTP/2. if (http2Connection == null) return false // 2. The routes must share an IP address. if (routes == null || !routeMatchesAny(routes)) return false // 3. This connection's server certificate's must cover the new host. if (address.hostnameVerifier !== OkHostnameVerifier) return false if (!supportsUrl(address.url)) return false // 4. Certificate pinning must match the host. try { address.certificatePinner!!.check(address.url.host, handshake()!!.peerCertificates) } catch (_: SSLPeerUnverifiedException) { return false } return true // The caller's address can be carried by this connection. }我用一张图来解释这个方法的判断逻辑:
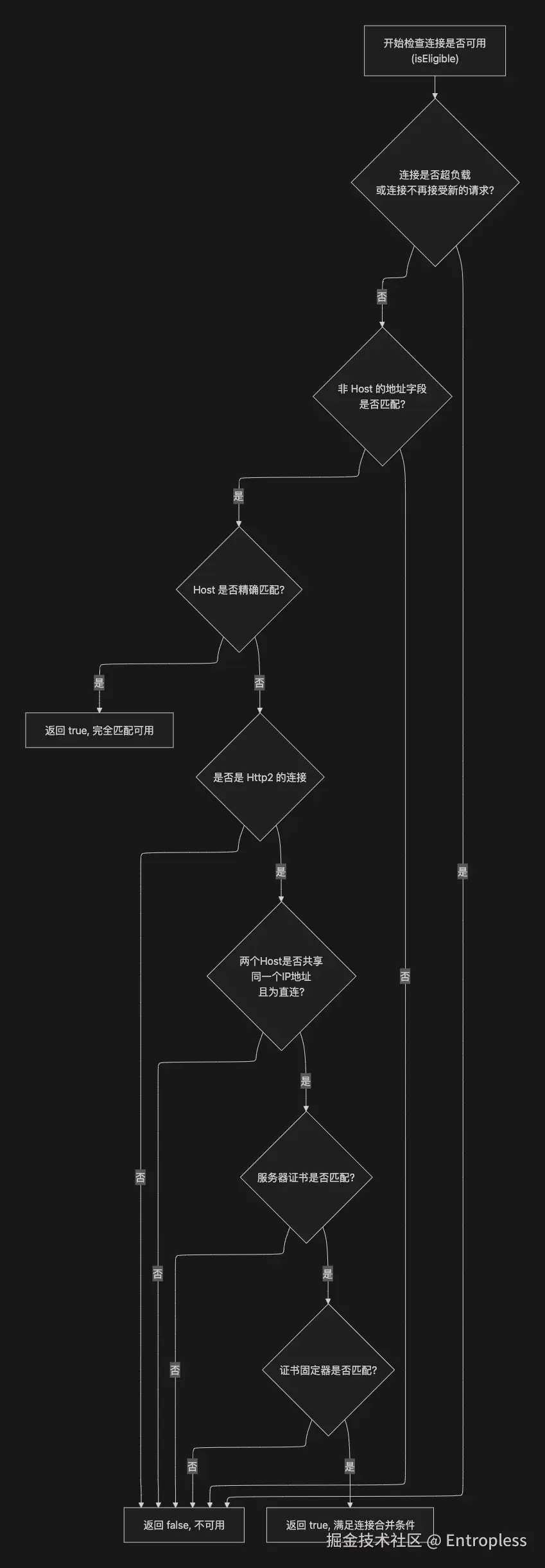
PS:关于 coalescing
它表示连接合并,也就是允许不同主机名的请求合并到同一个 TCP 连接中,这是针对「虚拟主机」的一项优化策略,所谓虚拟主机就是在一台物理主机上有多个虚拟的服务,它们 IP 地址相同,但域名不同,因此在 isEligible 方法中会判断当主机名不一致时,仍然尝试去查找合适的连接,这样可以最大限度的复用 TCP 连接。
可能有人会产生疑问:Http1.1也支持虚拟主机,为什么 OkHttp 中要求只有 Http2 的连接才可以尝试 coalescing, 这是因为 Http1.1 中同一个 TCP 连接不支持跨主机名的连接合并,因为这会产生很多问题(具体原因较多),因此虽然 Http1.1的协议中并未明确禁止连接合并,但在实际应用中所有的客户端的实现中都会禁用 Http1.1 的连接合并策略。
-
CallServerInterceptor
这是整个拦截器链的最后一环,因此它是实际负责执行网络 I/O 的,写入请求头/体,读取响应头/体,它没有中置和后置工作。
以上就是我对 OkHttp 的全部解读,希望可以帮到大家,如有疑问或者问题欢迎指正!