在基于大语言模型的RAG系统里,文本分块是非常关键的一步。分块做得好,后续的向量检索、结果召回和生成质量都会更稳更准。除了大家常用的固定大小、递归、语义、按文档等切法,至少还有好几种策略,能显著提升检索准确率、保持上下文连续,并适配不同任务。
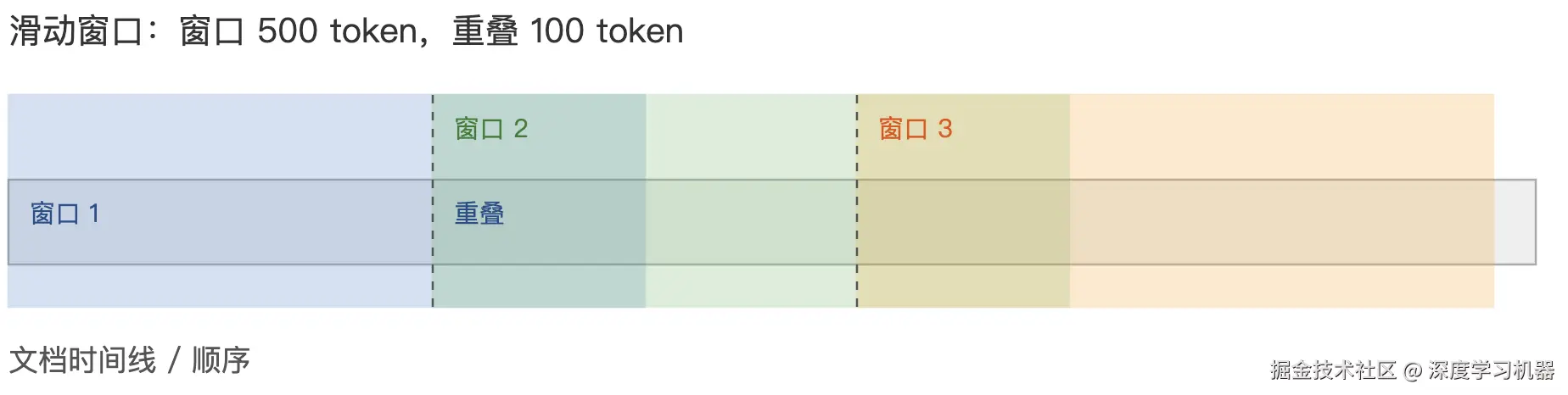
1. 滑动窗口分块
概念
首先设定一个固定大小的窗口,再按设定的重叠量向前滑动,生成一系列重叠块,这样跨块边界的上下文更不容易丢。
使用场景
适合追踪长文档里的「进展」「演变」「关系变化」,比如医疗记录、日志、历史报告等。
Python示例
python
def sliding_window_chunks(text, window_size=500, overlap=100):
words = text.split()
chunks = []
start = 0
while start < len(words):
end = min(start + window_size, len(words))
chunk = " ".join(words[start:end])
chunks.append(chunk)
if end == len(words):
break
start = end - overlap
return chunks
# 用法示例
doc = """...一段非常长的文本..."""
chunks = sliding_window_chunks(doc, window_size=500, overlap=100)
print(f"Generated {len(chunks)} chunks.")重叠比例可按任务重要性调整,比如医疗记录这些高信息密度的可以达到20%左右,而普通文档只需10%左右即可。
2. 自适应分块
概念
不同于固定大小,自适应分块会尽量把自然文档单元(如条款、段落、章节)放在同一个块里,同时遵守最大token数约束。 这种方法典型的应用是法律法规等文档,因为这些文档通常有明确的章节或段落结构,可按「每一章」「每一节」进行分块处理。
使用场景
非常适合结构化文档:法律合同、协议、白皮书、政策文件等。
Python示例
python
import re
def adaptive_chunking(text, min_tokens=800, max_tokens=1200, boundary_pattern=r"SECTION\s+\d+:"):
sections = re.split(boundary_pattern, text)
chunks = []
for sec in sections:
# 简化:如果 sec 很长,进一步拆分
words = sec.split()
if len(words) <= max_tokens:
chunks.append(sec.strip())
else:
# 简单按句子拆
current = []
for w in words:
current.append(w)
if len(current) >= max_tokens:
chunks.append(" ".join(current))
current = []
if current:
chunks.append(" ".join(current))
return chunks
# 用法
contract_text = """SECTION 1: ... SECTION 2: ..."""
chunks = adaptive_chunking(contract_text, min_tokens=800, max_tokens=1200)
print(len(chunks))需要根据文档类型,使用正确的正则表达式识别边界,从而来提高质量。 此外,应该尽量避免在逻辑单元中间硬拆,否则上下文容易被破坏。除非块的大小仍旧不满足要求,才允许在逻辑单元中间进行拆分。

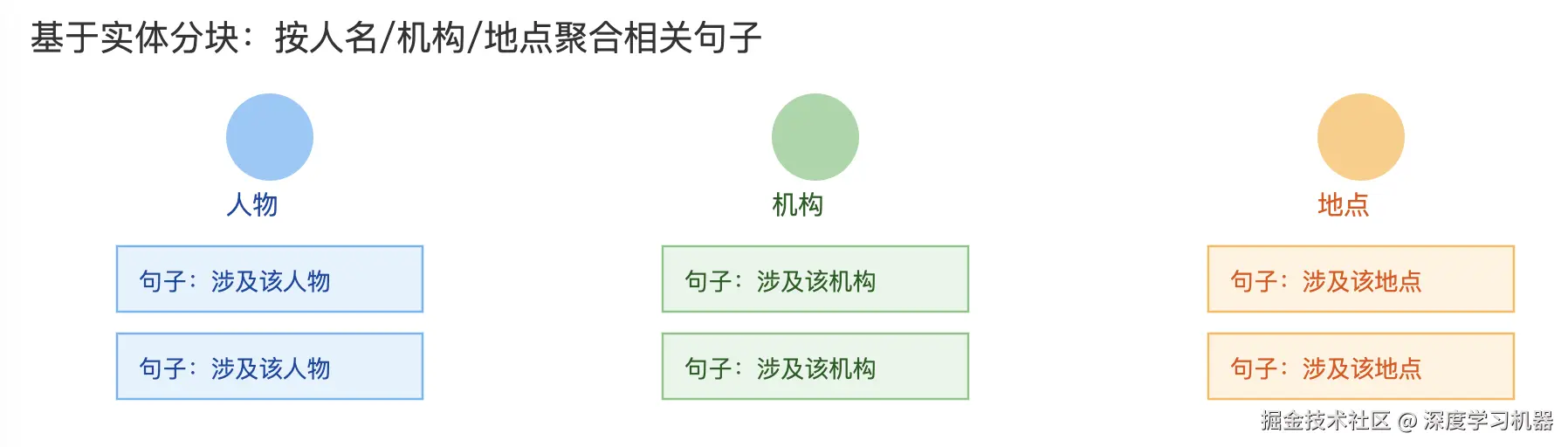
3. 基于实体分块
概念
先做命名实体识别,再按实体把相关句子聚到同一块里,而不是只按原文顺序切。
使用场景
适合知识库、以实体为核心的QA、新闻档案检索等。比如问「某某人这周做了什么?」,事先把该实体相关内容聚到一起,检索更高效。
Python 示例
python
import spacy
from collections import defaultdict
nlp = spacy.load("en_core_web_sm")
def entity_based_chunks(text):
doc = nlp(text)
entity_map = defaultdict(list)
for sent in doc.sents:
ents = {ent.text for ent in sent.ents}
for e in ents:
entity_map[e].append(sent.text)
return {entity: " ".join(sents) for entity, sents in entity_map.items()}
text = """Elon Musk announced a new AI initiative. Tesla unveiled its Model Y refresh. SpaceX launched its Starship test flight."""
chunks = entity_based_chunks(text)
for entity, chunk in chunks.items():
print(f"Entity: {entity}\nChunk: {chunk}\n")可用特定的NER模型来识别实体。 每个实体生成一个块时,注意句子可能属于多个实体,存在重叠,可以按照重要性或者其他策略进行归类。
4. 混合分块
概念
从名字就可以看出来,可以把多种分块策略组成Pipeline:先按结构拆分,再做语义聚类,最后做实体保留。这样能兼顾结构、语义和实体三方面的优势。
使用场景
适合技术文档、API 文档、软件说明、混合内容(文本 + 代码)等。单一策略很难同时兼顾结构完整性、语义聚合和实体识别时,可以使用混合策略。
Python 示例
python
def hybrid_chunking(text):
# Step1: Recursive split by headings
sections = text.split("\n## ")
chunks_stage1 = [sec for sec in sections]
# Step2: Within each section, semantic cluster paragraphs (reuse previous code)
paragraphs = [sec.split("\n") for sec in chunks_stage1]
chunks_stage2 = []
for paras in paragraphs:
chunks_stage2.extend(topic_based_chunks(paras, n_clusters=2))
# Step3: Entity preservation: ensure entity sentences stay with their chunk
final_chunks = []
for chunk in chunks_stage2:
# simple heuristic: if entity appears, include nearby sentences
final_chunks.append(chunk)
return final_chunks
text = """## Authentication Methods ... ## Error Handling ... ## Rate Limiting ... """
chunks = hybrid_chunking(text)
print(len(chunks))Pipeline可以按照这种顺序处理:结构 → 语义 → 实体,由简到难。

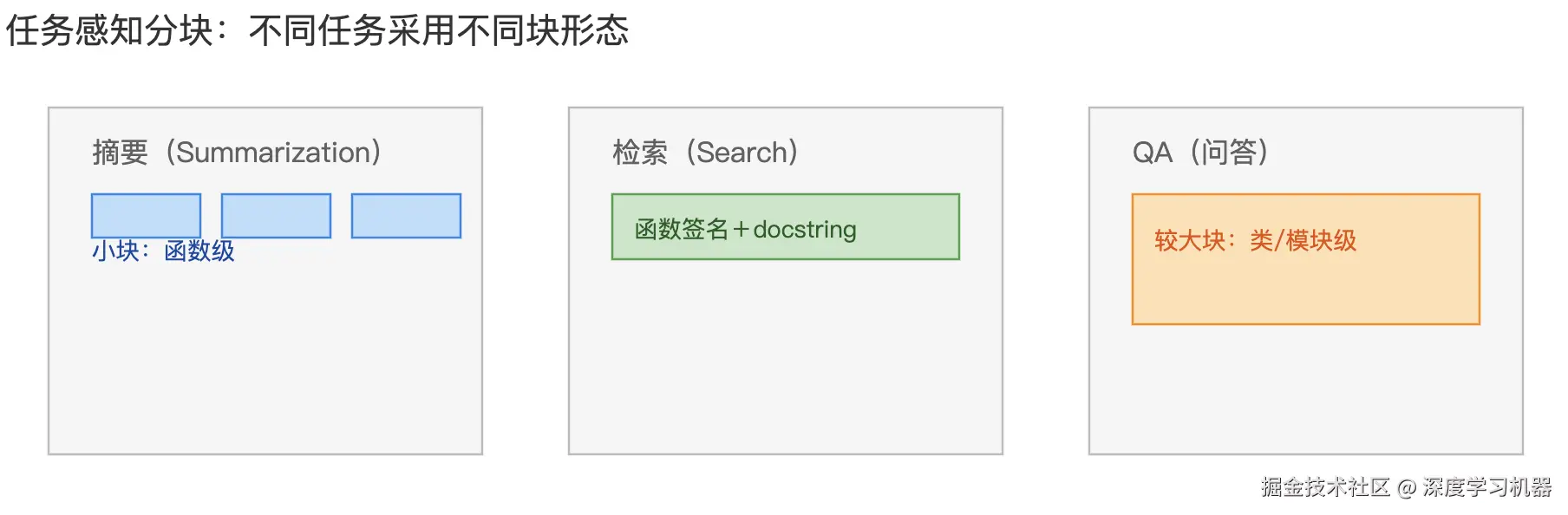
5. 任务感知分块
概念
根据下游任务类型(如摘要、检索、问答等不同需求)选择不同分块规则。同一内容可以针对不同任务生成不同的分块方案。
使用场景
比如对代码库做摘要时,用更小的函数级分块;做检索时,按函数签名+文档字符串成块;做QA时,按类或模块级别成块。
Python 示例
python
def task_aware_chunking(code_text, task='search'):
if task == 'summarization':
# chunk size small: 20-30 lines per function
return code_text.split("\n\n") # 简化版
elif task == 'search':
# chunk: function signature + docstring
chunks = []
for func in code_text.split("def "):
if not func.strip(): continue
chunks.append("def " + func.split("\n")[0])
return chunks
elif task == 'qa':
# chunk: entire class definitions (~100-200 lines)
return code_text.split("class ")
else:
return [code_text]
code = """class AuthenticationManager: ... def authenticate ... def refresh_token ..."""
for task in ['summarization','search','qa']:
print(task, len(task_aware_chunking(code, task)))- 为不同任务维护不同配置(chunk 大小、策略、优先级)更稳。
- 同一语料可以面向多任务同时生成多个索引,每个任务一套策略。
6. 基于HTML/XML标签拆分
概念
解析 HTML 或 XML 的 DOM 结构,根据标签(如 <h2>、<section>、<div>)来确定chunk的边界,更好地保留页面结构。
使用场景
适合处理爬虫网页、博客文章、在线文档等含结构化标记的内容。优点是能保留页面结构,而不是盲目按词或句拆分。
Python 示例
python
from bs4 import BeautifulSoup
def tag_based_splitting(html, boundary_tags=["h2", "section"]):
soup = BeautifulSoup(html, "html.parser")
chunks = []
for tag in soup.find_all(boundary_tags):
# get text of this section
section_text = tag.get_text(separator="\n")
chunks.append(section_text)
return chunks
html = """<article><h2>Introduction</h2><p>...</p><h2>Supervised Learning</h2><p>...</p></article>"""
chunks = tag_based_splitting(html)
for i, c in enumerate(chunks): print(i, c[:50])注意标签嵌套:例如
<h3>是否作为子块,还是合并到<h2>,可以根据实际需求来定。

7. 基于抽象语法树的代码文件拆分
概念
针对代码文本,使用AST或语言特定模式识别函数、类、模块等逻辑边界来拆分。这种方法在很多Coding Agent出现,如Cursor,Trae等。
使用场景
适合开发文档、代码审查、自动生成文档、代码问答等场景。往往把整个类或函数作为一个 chunk,而不是简单按行数来切。
Python 示例
python
import ast
def code_specific_chunks(code):
tree = ast.parse(code)
chunks = []
for node in tree.body:
if isinstance(node, ast.ClassDef) or isinstance(node, ast.FunctionDef):
start = node.lineno - 1
end = node.end_lineno
chunk = "\n".join(code.splitlines()[start:end])
chunks.append(chunk)
return chunks
code = """
class UserManager:
def __init__(self):
pass
def add_user(self, name, email):
pass
def helper_function(x, y):
return x + y
"""
chunks = code_specific_chunks(code)
for c in chunks:
print("Chunk:", c.splitlines()[0])可用
ast来处理Python,或更通用的Tree-Sitter以支持更多的编程语言。 可以适当保留注释和docstring,以增强可读性和语义。

8. 正则表达式分块
概念
基于可预测的文本模式(时间戳、分隔符、标记等),用正则表达式定位拆分边界。每次匹配产生一个新块。
比如Jina-AI之前发布过的一个正则模板,号称使用正则表达式解析整本书《爱丽丝梦游仙境》只需要2毫秒,总共产生了1204个块。
使用场景
这种方法理论上能提取所有格式,但是需要根据实际情况调整正则表达式模式。
Python 示例
python
# 比如可以从日志记录中按时间戳进行切分
import re
def regex_chunking(text, pattern=r"\[\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}\]"):
parts = re.split(pattern, text)
chunks = []
for part in parts:
if part.strip():
chunks.append(part.strip())
return chunks
log = """[2025-01-15 10:23:45] INFO: User john logged in
[2025-01-15 10:24:12] ERROR: DB connection failed
[2025-01-15 10:24:15] INFO: Retrying..."""
chunks = regex_chunking(log)
for c in chunks:
print("Chunk:", c[:50])一些实践经验
在选择文本分块策略时,一般需要从最简单的入手,如按照固定的chunk size进行切分,待效果稳定后再逐步升级到更复杂的方案。 在评估环节,需要通过检索准确率和响应质量等指标衡量实际效果,必要时可进行A/B测试。
此外,可以按照如下的技巧来快速选择合适的分块策略:
| 类型 | 分块策略 |
|---|---|
| 需要保留跨边界上下文 | 滑动窗口 |
| 处理合同、协议类文档 | 自适应分块 |
| 构建实体知识库 | 实体分块 |
| 内容复杂、结构多样 | 混合分块 |
| 任务不同 | 任务感知分块 |
| 结构化 HTML/XML 网页 | 标签拆分 |
| 代码内容 | 代码专用拆分 |
| 日志/流水/带标记文本 | 正则分块 |
总结
对于实际的应用来说,并没有包罗万象的分块方法,包括上面的提到这些分块策略,也并不能保证能够完美提升RAG的效果,只是在不同场景下的一种折衷方案而已。
好的分块策略不只是「把文本切成块」,而是要同时考虑 内容类型/任务类型/文档结构,再选择或组合合适的方法, 让RAG系统更好地利用上下文、提供更准的答案,并提升整体体验。
掌握上面的几种策略,并结合自己正在做的场景做一些实验,通常都能带来很可观的提升。